AWS-basierte Data Lakes, unterstützt durch die unübertroffene Verfügbarkeit von Amazon Simple Storage-Service (Amazon S3) kann die erforderliche Skalierung, Agilität und Flexibilität bewältigen, um verschiedene Daten- und Analyseansätze zu kombinieren. Da Data Lakes immer größer und ausgereifter genutzt werden, kann ein erheblicher Aufwand betrieben werden, um die Daten mit den Geschäftsereignissen in Einklang zu bringen. Um sicherzustellen, dass Dateien transaktionskonsistent aktualisiert werden, verwenden immer mehr Kunden Open-Source-Transaktionstabellenformate wie z Apache Eisberg, Apache Hudi und Linux Foundation Delta Lake die Ihnen helfen, Daten mit hohen Komprimierungsraten zu speichern, nativ mit Ihren Anwendungen und Frameworks zu kommunizieren und die inkrementelle Datenverarbeitung in Data Lakes zu vereinfachen, die auf Amazon S3 basieren. Diese Formate ermöglichen ACID-Transaktionen (Atomizität, Konsistenz, Isolation, Haltbarkeit), Upserts und Löschungen sowie erweiterte Funktionen wie Zeitreisen und Snapshots, die bisher nur in Data Warehouses verfügbar waren. Jedes Speicherformat implementiert diese Funktionalität auf leicht unterschiedliche Weise; Einen Vergleich finden Sie unter Wählen Sie ein offenes Tabellenformat für Ihren Transaktionsdatensee auf AWS.
In 2023, AWS gab die allgemeine Verfügbarkeit bekannt für Apache Iceberg, Apache Hudi und Linux Foundation Delta Lake in Amazon Athena für Apache SparkDadurch entfällt die Notwendigkeit, einen separaten Connector oder zugehörige Abhängigkeiten zu installieren und Versionen zu verwalten, und die für die Verwendung dieser Frameworks erforderlichen Konfigurationsschritte werden vereinfacht.
In diesem Beitrag zeigen wir Ihnen, wie Sie Spark SQL verwenden Amazonas Athena Notebooks und arbeiten mit den Tischformaten Iceberg, Hudi und Delta Lake. Wir demonstrieren gängige Vorgänge wie das Erstellen von Datenbanken und Tabellen, das Einfügen von Daten in die Tabellen, das Abfragen von Daten und das Betrachten von Snapshots der Tabellen in Amazon S3 mit Spark SQL in Athena.
Voraussetzungen:
Erfüllen Sie die folgenden Voraussetzungen:
Laden Sie Beispielnotizbücher von Amazon S3 herunter und importieren Sie sie
Um mitzumachen, laden Sie die in diesem Beitrag besprochenen Notizbücher von den folgenden Orten herunter:
Nachdem Sie die Notizbücher heruntergeladen haben, importieren Sie sie in Ihre Athena Spark-Umgebung, indem Sie den folgenden Schritten folgen So importieren Sie ein Notizbuch Abschnitt in Notizbuchdateien verwalten.
Navigieren Sie zu einem bestimmten Abschnitt „Open Table Format“.
Wenn Sie sich für das Iceberg-Tabellenformat interessieren, navigieren Sie zu Arbeiten mit Apache Iceberg-Tabellen .
Wenn Sie sich für das Hudi-Tabellenformat interessieren, navigieren Sie zu Arbeiten mit Apache Hudi-Tabellen .
Wenn Sie sich für das Delta-Lake-Tabellenformat interessieren, navigieren Sie zu Arbeiten mit Linux Foundation Delta Lake-Tabellen .
Arbeiten mit Apache Iceberg-Tabellen
Wenn Sie Spark-Notebooks in Athena verwenden, können Sie SQL-Abfragen direkt ausführen, ohne PySpark verwenden zu müssen. Dies erreichen wir durch den Einsatz von Cell Magics, das sind spezielle Header in einer Notebook-Zelle, die das Verhalten der Zelle ändern. Für SQL können wir Folgendes hinzufügen %%sql magic, das den gesamten Zellinhalt als SQL-Anweisung interpretiert, die auf Athena ausgeführt werden soll.
In diesem Abschnitt zeigen wir, wie Sie SQL auf Apache Spark für Athena verwenden können, um Apache Iceberg-Tabellen zu erstellen, zu analysieren und zu verwalten.
Richten Sie eine Notebook-Sitzung ein
Um Apache Iceberg in Athena zu verwenden, wählen Sie beim Erstellen oder Bearbeiten einer Sitzung die Option aus Apache Eisberg Option durch Erweitern der Apache Spark-Eigenschaften Abschnitt. Die Eigenschaften werden vorab ausgefüllt, wie im folgenden Screenshot gezeigt.
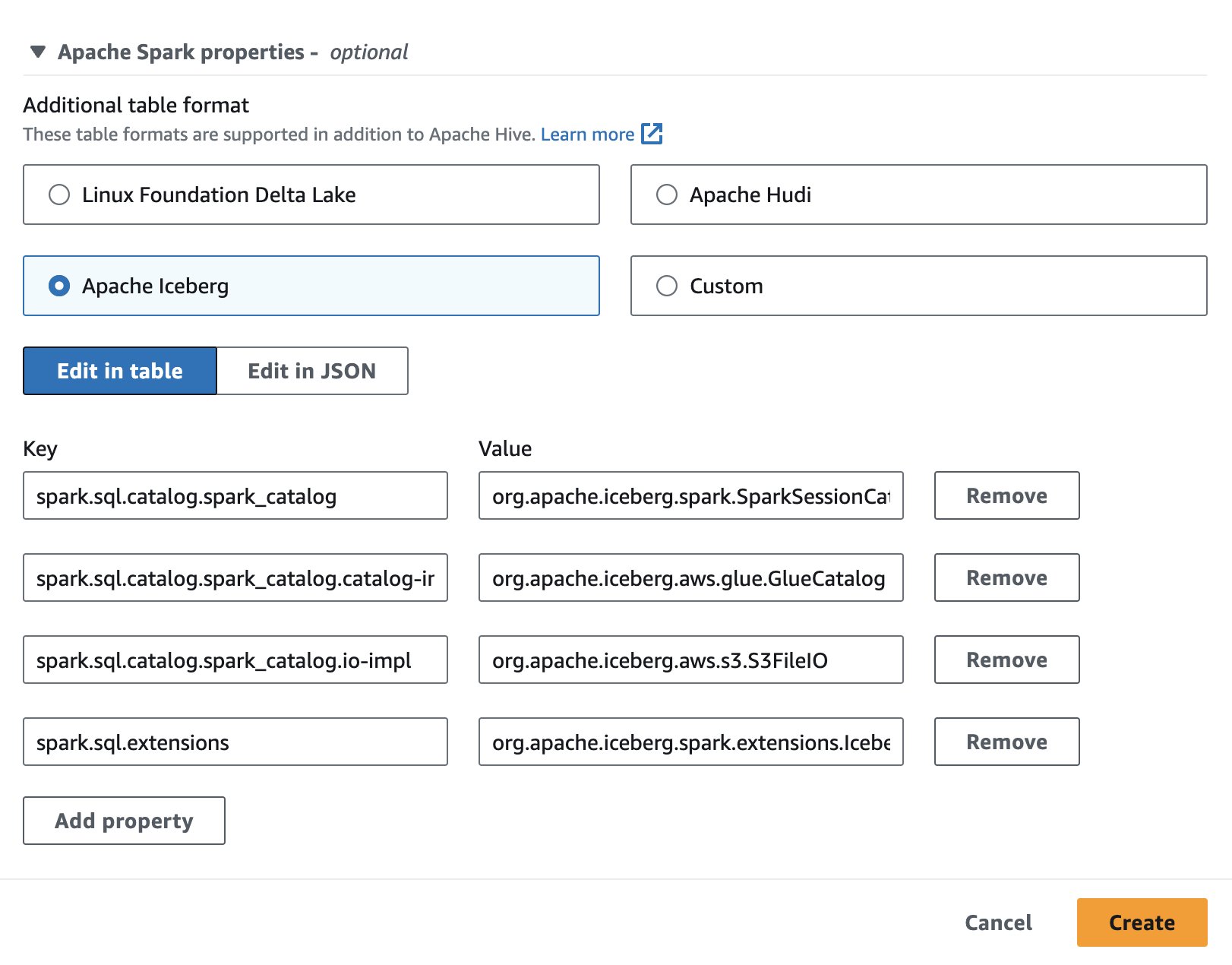
Schritte finden Sie unter Sitzungsdetails bearbeiten or Erstellen Sie Ihr eigenes Notizbuch.
Der in diesem Abschnitt verwendete Code ist im verfügbar SparkSQL_iceberg.ipynb Datei zum Mitmachen.
Erstellen Sie eine Datenbank und eine Iceberg-Tabelle
Zuerst erstellen wir eine Datenbank im AWS Glue Data Catalog. Mit dem folgenden SQL können wir eine Datenbank namens erstellen icebergdb:
Als nächstes in der Datenbank icebergdberstellen wir eine Iceberg-Tabelle mit dem Namen noaa_iceberg Zeigt auf einen Speicherort in Amazon S3, an den wir die Daten laden. Führen Sie die folgende Anweisung aus und ersetzen Sie den Speicherort s3://<your-S3-bucket>/<prefix>/ mit Ihrem S3-Bucket und Präfix:
Fügen Sie Daten in die Tabelle ein
Um die zu bevölkern noaa_iceberg In der Iceberg-Tabelle fügen wir Daten aus der Parquet-Tabelle ein sparkblogdb.noaa_pq das im Rahmen der Voraussetzungen erstellt wurde. Sie können dies mit einem tun INSERT INSERT Aussage in Spark:
Alternativ können Sie auch verwenden TABELLE ALS AUSWAHL ERSTELLEN mit der USING-Iceberg-Klausel, um in einem Schritt eine Iceberg-Tabelle zu erstellen und Daten aus einer Quelltabelle einzufügen:
Fragen Sie die Iceberg-Tabelle ab
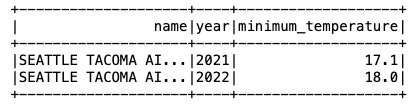
Nachdem die Daten nun in die Iceberg-Tabelle eingefügt wurden, können wir mit der Analyse beginnen. Lassen Sie uns ein Spark-SQL ausführen, um die minimale aufgezeichnete Temperatur pro Jahr für zu ermitteln 'SEATTLE TACOMA AIRPORT, WA US' Standort:
Wir erhalten folgende Ausgabe.
Aktualisieren Sie die Daten in der Iceberg-Tabelle
Sehen wir uns an, wie Sie die Daten in unserer Tabelle aktualisieren. Wir möchten den Sendernamen aktualisieren 'SEATTLE TACOMA AIRPORT, WA US' zu 'Sea-Tac'. Mit Spark SQL können wir eine ausführen AKTUALISIEREN Stellungnahme gegen den Iceberg-Tisch:
Anschließend können wir die vorherige SELECT-Abfrage ausführen, um die minimal aufgezeichnete Temperatur für zu ermitteln 'Sea-Tac' Standort:
Wir erhalten die folgende Ausgabe.

Kompakte Datendateien
Offene Tabellenformate wie Iceberg funktionieren, indem sie Delta-Änderungen im Dateispeicher erstellen und die Versionen von Zeilen über Manifestdateien verfolgen. Mehr Datendateien führen dazu, dass mehr Metadaten in Manifestdateien gespeichert werden, und kleine Datendateien verursachen oft eine unnötige Menge an Metadaten, was zu weniger effizienten Abfragen und höheren Amazon S3-Zugriffskosten führt. Laufende Icebergs rewrite_data_files Die Prozedur in Spark für Athena komprimiert Datendateien und kombiniert viele kleine Delta-Änderungsdateien zu einem kleineren Satz leseoptimierter Parquet-Dateien. Das Komprimieren von Dateien beschleunigt den Lesevorgang bei Abfragen. Um die Komprimierung für unsere Tabelle auszuführen, führen Sie das folgende Spark SQL aus:
rewrite_data_files bietet Optionen um Ihre Sortierstrategie anzugeben, die dabei helfen kann, Daten neu zu organisieren und zu komprimieren.
Tabellen-Snapshots auflisten
Bei jedem Schreib-, Aktualisierungs-, Lösch-, Upsert- und Komprimierungsvorgang für eine Iceberg-Tabelle wird ein neuer Snapshot einer Tabelle erstellt, während die alten Daten und Metadaten zur Snapshot-Isolierung und Zeitreise beibehalten werden. Um die Snapshots einer Iceberg-Tabelle aufzulisten, führen Sie die folgende Spark SQL-Anweisung aus:
Alte Snapshots verfallen lassen
Es wird empfohlen, Snapshots regelmäßig ablaufen zu lassen, um nicht mehr benötigte Datendateien zu löschen und die Größe der Tabellenmetadaten klein zu halten. Es werden niemals Dateien entfernt, die für einen nicht abgelaufenen Snapshot noch erforderlich sind. Führen Sie in Spark für Athena die folgende SQL aus, um Snapshots für die Tabelle ablaufen zu lassen icebergdb.noaa_iceberg die älter als ein bestimmter Zeitstempel sind:
Beachten Sie, dass der Zeitstempelwert im Format als Zeichenfolge angegeben wird yyyy-MM-dd HH:mm:ss.fff. Die Ausgabe gibt eine Zählung der Anzahl der gelöschten Daten- und Metadatendateien an.
Löschen Sie die Tabelle und die Datenbank
Sie können das folgende Spark SQL ausführen, um die Iceberg-Tabellen und die zugehörigen Daten in Amazon S3 aus dieser Übung zu bereinigen:
Führen Sie den folgenden Spark SQL aus, um die Datenbank „icebergdb“ zu entfernen:
Weitere Informationen zu allen Vorgängen, die Sie mit Spark für Athena an Iceberg-Tischen ausführen können, finden Sie unter Spark-Abfragen machen Spark-Prozeduren in der Iceberg-Dokumentation.
Arbeiten mit Apache Hudi-Tabellen
Als Nächstes zeigen wir, wie Sie SQL on Spark für Athena zum Erstellen, Analysieren und Verwalten von Apache Hudi-Tabellen verwenden können.
Richten Sie eine Notebook-Sitzung ein
Um Apache Hudi in Athena zu verwenden, wählen Sie beim Erstellen oder Bearbeiten einer Sitzung die Option aus Apache Hudi Option durch Erweitern der Apache Spark-Eigenschaften .
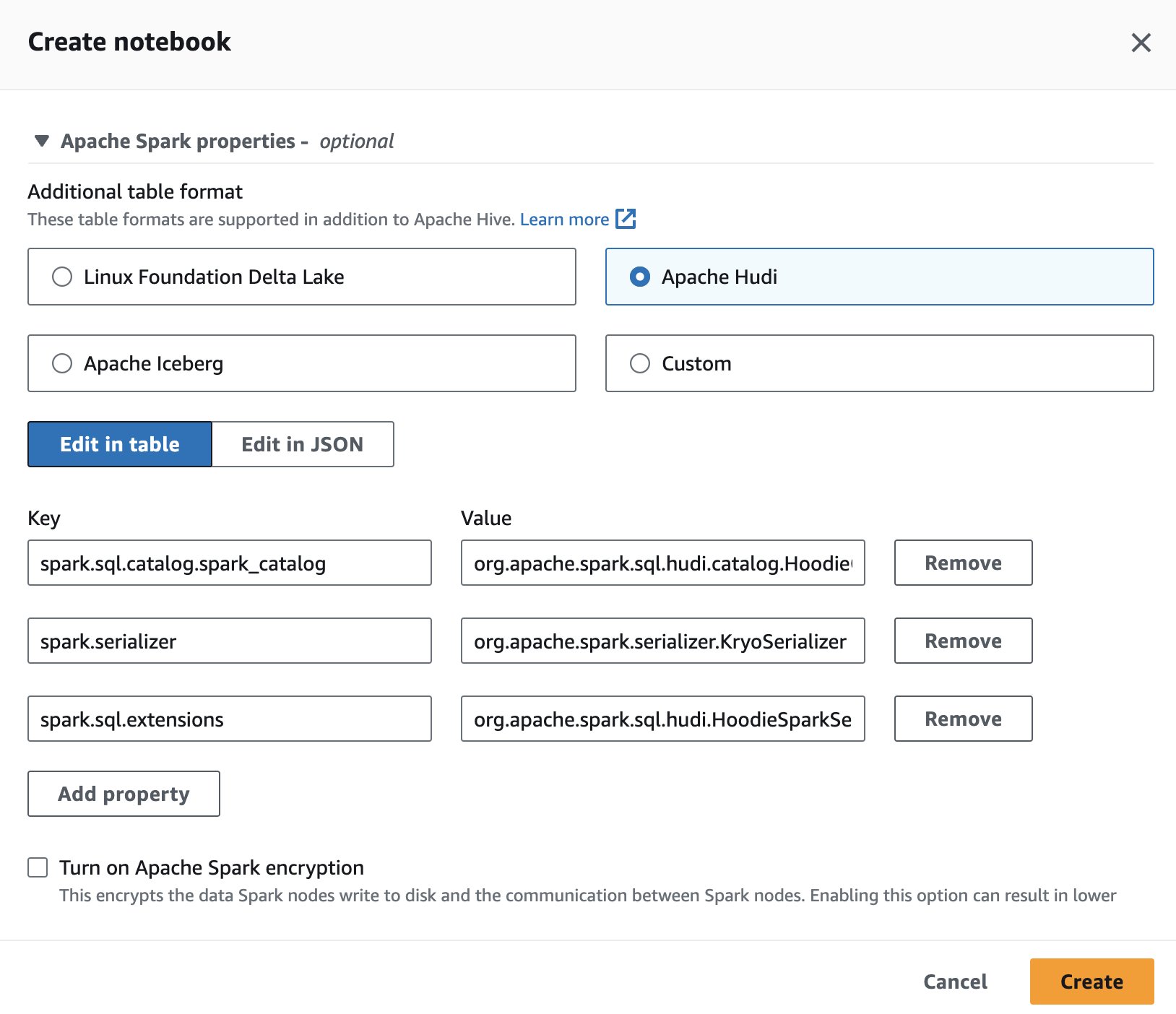
Schritte finden Sie unter Sitzungsdetails bearbeiten or Erstellen Sie Ihr eigenes Notizbuch.
Der in diesem Abschnitt verwendete Code sollte im verfügbar sein SparkSQL_hudi.ipynb Datei zum Mitmachen.
Erstellen Sie eine Datenbank und eine Hudi-Tabelle
Zuerst erstellen wir eine Datenbank namens hudidb Dies wird im AWS Glue-Datenkatalog gespeichert, gefolgt von der Erstellung einer Hudi-Tabelle:
Wir erstellen eine Hudi-Tabelle, die auf einen Speicherort in Amazon S3 verweist, an den wir die Daten laden. Beachten Sie, dass die Tabelle von ist copy-on-write Typ. Es ist definiert durch type= 'cow' in der Tabelle DDL. Wir haben Station und Datum als mehrere Primärschlüssel und preCombinedField als Jahr definiert. Außerdem ist die Tabelle nach Jahr unterteilt. Führen Sie die folgende Anweisung aus und ersetzen Sie den Speicherort s3://<your-S3-bucket>/<prefix>/ mit Ihrem S3-Bucket und Präfix:
Fügen Sie Daten in die Tabelle ein
Wie bei Iceberg verwenden wir das INSERT INSERT Anweisung zum Auffüllen der Tabelle durch Lesen von Daten aus sparkblogdb.noaa_pq Tabelle, die im vorherigen Beitrag erstellt wurde:
Fragen Sie die Hudi-Tabelle ab
Nachdem die Tabelle nun erstellt ist, führen wir eine Abfrage aus, um die maximal aufgezeichnete Temperatur für zu ermitteln 'SEATTLE TACOMA AIRPORT, WA US' Standort:
Aktualisieren Sie die Daten in der Hudi-Tabelle
Lassen Sie uns den Sendernamen ändern 'SEATTLE TACOMA AIRPORT, WA US' zu 'Sea–Tac'. Wir können eine UPDATE-Anweisung auf Spark für Athena ausführen Aktualisierung die Aufzeichnungen der noaa_hudi Tabelle:
Wir führen die vorherige SELECT-Abfrage aus, um die maximal aufgezeichnete Temperatur für zu ermitteln 'Sea-Tac' Standort:
Führen Sie Zeitreiseabfragen aus
Wir können Zeitreiseabfragen in SQL auf Athena verwenden, um vergangene Datenschnappschüsse zu analysieren. Zum Beispiel:
Diese Abfrage überprüft die Temperaturdaten des Flughafens Seattle zu einem bestimmten Zeitpunkt in der Vergangenheit. Mit der Zeitstempelklausel können wir zurückreisen, ohne die aktuellen Daten zu ändern. Beachten Sie, dass der Zeitstempelwert im Format als Zeichenfolge angegeben wird yyyy-MM-dd HH:mm:ss.fff.
Optimieren Sie die Abfragegeschwindigkeit mit Clustering
Um die Abfrageleistung zu verbessern, können Sie Folgendes durchführen: Clustering zu Hudi-Tabellen mit SQL in Spark für Athena:
Kompakte Tische
Komprimierung ist ein Tabellendienst, der von Hudi speziell in MOR-Tabellen (Merge On Read) eingesetzt wird, um Aktualisierungen von zeilenbasierten Protokolldateien in regelmäßigen Abständen mit der entsprechenden spaltenbasierten Basisdatei zusammenzuführen, um eine neue Version der Basisdatei zu erstellen. Die Komprimierung gilt nicht für COW-Tabellen (Copy On Write), sondern nur für MOR-Tabellen. Sie können die folgende Abfrage in Spark für Athena ausführen, um eine Komprimierung für MOR-Tabellen durchzuführen:
Löschen Sie die Tabelle und die Datenbank
Führen Sie den folgenden Spark SQL aus, um die von Ihnen erstellte Hudi-Tabelle und die zugehörigen Daten vom Amazon S3-Speicherort zu entfernen:
Führen Sie den folgenden Spark SQL aus, um die Datenbank zu entfernen hudidb:
Weitere Informationen zu allen Vorgängen, die Sie mit Spark für Athena an Hudi-Tabellen ausführen können, finden Sie unter SQL-DDL machen Verfahren in der Hudi-Dokumentation.
Arbeiten mit Linux Foundation Delta Lake-Tabellen
Als Nächstes zeigen wir, wie Sie SQL auf Spark für Athena verwenden können, um Delta Lake-Tabellen zu erstellen, zu analysieren und zu verwalten.
Richten Sie eine Notebook-Sitzung ein
Um Delta Lake in Spark für Athena zu verwenden, wählen Sie beim Erstellen oder Bearbeiten einer Sitzung aus Linux Foundation Delta Lake durch Erweiterung der Apache Spark-Eigenschaften .
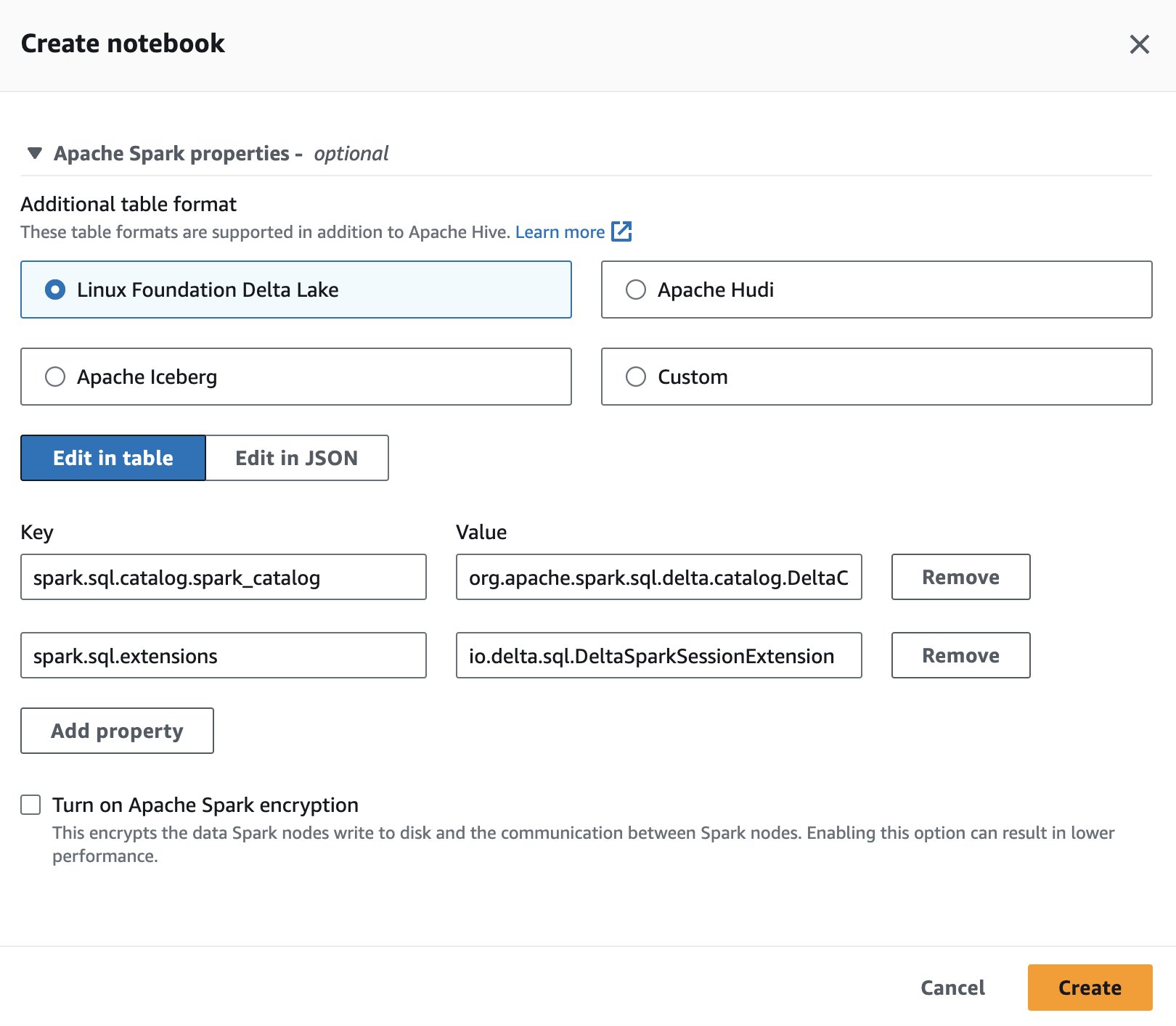
Schritte finden Sie unter Sitzungsdetails bearbeiten or Erstellen Sie Ihr eigenes Notizbuch.
Der in diesem Abschnitt verwendete Code sollte im verfügbar sein SparkSQL_delta.ipynb Datei zum Mitmachen.
Erstellen Sie eine Datenbank und eine Delta-Lake-Tabelle
In diesem Abschnitt erstellen wir eine Datenbank im AWS Glue Data Catalog. Mit folgendem SQL können wir eine Datenbank namens erstellen deltalakedb:
Als nächstes in der Datenbank deltalakedberstellen wir eine Delta-Lake-Tabelle mit dem Namen noaa_delta Zeigt auf einen Speicherort in Amazon S3, an den wir die Daten laden. Führen Sie die folgende Anweisung aus und ersetzen Sie den Speicherort s3://<your-S3-bucket>/<prefix>/ mit Ihrem S3-Bucket und Präfix:
Fügen Sie Daten in die Tabelle ein
Wir verwenden eine INSERT INSERT Anweisung zum Auffüllen der Tabelle durch Lesen von Daten aus sparkblogdb.noaa_pq Tabelle, die im vorherigen Beitrag erstellt wurde:
Sie können CREATE TABLE AS SELECT auch verwenden, um eine Delta Lake-Tabelle zu erstellen und Daten aus einer Quelltabelle in eine Abfrage einzufügen.
Fragen Sie die Delta Lake-Tabelle ab
Nachdem die Daten nun in die Delta-Lake-Tabelle eingefügt wurden, können wir mit der Analyse beginnen. Lassen Sie uns Spark SQL ausführen, um die minimal aufgezeichnete Temperatur für zu ermitteln 'SEATTLE TACOMA AIRPORT, WA US' Standort:
Aktualisieren Sie die Daten in der Delta Lake-Tabelle
Lassen Sie uns den Sendernamen ändern 'SEATTLE TACOMA AIRPORT, WA US' zu 'Sea–Tac'. Wir können eine durchführen AKTUALISIEREN Erklärung zu Spark für Athena, um die Aufzeichnungen der zu aktualisieren noaa_delta Tabelle:
Wir können die vorherige SELECT-Abfrage ausführen, um die minimal aufgezeichnete Temperatur für zu ermitteln 'Sea-Tac' Ort, und das Ergebnis sollte das gleiche wie zuvor sein:
Kompakte Datendateien
In Spark für Athena können Sie OPTIMIZE für die Delta Lake-Tabelle ausführen, wodurch die kleinen Dateien in größere Dateien komprimiert werden, sodass die Abfragen nicht durch den kleinen Datei-Overhead belastet werden. Führen Sie die folgende Abfrage aus, um den Komprimierungsvorgang durchzuführen:
Beziehen auf Optimierungen In der Delta Lake-Dokumentation finden Sie verschiedene Optionen, die beim Ausführen von OPTIMIZE verfügbar sind.
Entfernen Sie Dateien, auf die nicht mehr von einer Delta-Lake-Tabelle verwiesen wird
Sie können in Amazon S3 gespeicherte Dateien entfernen, auf die nicht mehr von einer Delta Lake-Tabelle verwiesen wird und die älter als der Aufbewahrungsschwellenwert sind, indem Sie den VACCUM-Befehl für die Tabelle mit Spark für Athena ausführen:
Beziehen auf Entfernen Sie Dateien, auf die in einer Delta-Tabelle nicht mehr verwiesen wird Informationen zu den mit VACUUM verfügbaren Optionen finden Sie in der Delta Lake-Dokumentation.
Löschen Sie die Tabelle und die Datenbank
Führen Sie den folgenden Spark SQL aus, um die von Ihnen erstellte Delta Lake-Tabelle zu entfernen:
Führen Sie den folgenden Spark SQL aus, um die Datenbank zu entfernen deltalakedb:
Wenn Sie DROP TABLE DDL für die Delta Lake-Tabelle und -Datenbank ausführen, werden die Metadaten für diese Objekte gelöscht, die Datendateien in Amazon S3 werden jedoch nicht automatisch gelöscht. Sie können den folgenden Python-Code in der Zelle des Notebooks ausführen, um die Daten vom S3-Speicherort zu löschen:
Weitere Informationen zu den SQL-Anweisungen, die Sie mit Spark für Athena auf einer Delta Lake-Tabelle ausführen können, finden Sie unter Schnellstart in der Delta Lake-Dokumentation.
Zusammenfassung
In diesem Beitrag wurde gezeigt, wie Sie Spark SQL in Athena-Notebooks verwenden, um Datenbanken und Tabellen zu erstellen, Daten einzufügen und abzufragen und allgemeine Vorgänge wie Aktualisierungen, Komprimierungen und Zeitreisen für Hudi-, Delta Lake- und Iceberg-Tabellen durchzuführen. Offene Tabellenformate fügen ACID-Transaktionen, Upserts und Löschungen zu Data Lakes hinzu und überwinden so die Einschränkungen der Rohobjektspeicherung. Da die Installation separater Konnektoren entfällt, reduziert die integrierte Integration von Spark on Athena Konfigurationsschritte und Verwaltungsaufwand bei der Verwendung dieser beliebten Frameworks zum Aufbau zuverlässiger Data Lakes auf Amazon S3. Weitere Informationen zur Auswahl eines offenen Tabellenformats für Ihre Data Lake-Workloads finden Sie unter Wählen Sie ein offenes Tabellenformat für Ihren Transaktionsdatensee auf AWS.
Über die Autoren
![]() Pathik Schah ist Sr. Analytics Architect bei Amazon Athena. Er kam 2015 zu AWS und konzentriert sich seitdem auf den Bereich der Big-Data-Analyse. Dabei hilft er Kunden beim Aufbau skalierbarer und robuster Lösungen mithilfe von AWS-Analysediensten.
Pathik Schah ist Sr. Analytics Architect bei Amazon Athena. Er kam 2015 zu AWS und konzentriert sich seitdem auf den Bereich der Big-Data-Analyse. Dabei hilft er Kunden beim Aufbau skalierbarer und robuster Lösungen mithilfe von AWS-Analysediensten.
![]() Raj Devnath ist Produktmanager bei AWS auf Amazon Athena. Seine Leidenschaft besteht darin, Produkte zu entwickeln, die Kunden lieben, und Kunden dabei zu helfen, Mehrwert aus ihren Daten zu ziehen. Sein Hintergrund liegt in der Bereitstellung von Lösungen für mehrere Endmärkte wie Finanzen, Einzelhandel, intelligente Gebäude, Hausautomation und Datenkommunikationssysteme.
Raj Devnath ist Produktmanager bei AWS auf Amazon Athena. Seine Leidenschaft besteht darin, Produkte zu entwickeln, die Kunden lieben, und Kunden dabei zu helfen, Mehrwert aus ihren Daten zu ziehen. Sein Hintergrund liegt in der Bereitstellung von Lösungen für mehrere Endmärkte wie Finanzen, Einzelhandel, intelligente Gebäude, Hausautomation und Datenkommunikationssysteme.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- Über uns
- Zugang
- hinzufügen
- advanced
- gegen
- Flughafen
- Alle
- entlang
- ebenfalls
- Amazon
- Amazonas Athena
- Amazon Web Services
- Betrag
- an
- Analytik
- analysieren
- Analyse
- machen
- angekündigt
- Apache
- Apache Funken
- anwendbar
- Anwendungen
- gilt
- Ansätze
- SIND
- um
- AS
- damit verbundenen
- At
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Automation
- Verfügbarkeit
- verfügbar
- AWS
- AWS-Kleber
- Zurück
- Hintergrund
- Base
- BE
- war
- Verhalten
- Big
- Big Data
- bauen
- Building
- erbaut
- eingebaut
- Geschäft
- aber
- by
- rufen Sie uns an!
- namens
- CAN
- Katalog
- Verursachen
- Zelle
- Übernehmen
- Änderungen
- Schecks
- reinigen
- Code
- kombinieren
- Vereinigung
- gemeinsam
- Kommunikation
- Kommunikationssysteme
- kompakt
- Vergleich
- Konfiguration
- konsistent
- Inhalt
- Dazugehörigen
- Kosten
- zählen
- erstellen
- erstellt
- schafft
- Erstellen
- Schaffung
- Strom
- Kunden
- technische Daten
- Datenanalyse
- Datensee
- Datenverarbeitung
- Data Warehouse
- Datenbase
- Datenbanken
- Datum
- definiert
- liefern
- Delta
- zeigen
- weisen nach, dass
- Abhängigkeiten
- anders
- Direkt
- diskutiert
- do
- Dokumentation
- Tut nicht
- herunterladen
- Drop
- Haltbarkeit
- jeder
- Früher
- Bearbeitung
- effizient
- Anstrengung
- beschäftigt
- ermöglichen
- Ende
- gewährleisten
- Ganz
- Arbeitsumfeld
- Äther (ETH)
- Veranstaltungen
- Beispiel
- Training
- Ausbau
- Extrakt
- Eigenschaften
- Reichen Sie das
- Mappen
- Finanzen
- Finden Sie
- Vorname
- Flexibilität
- Fokussierung
- folgen
- gefolgt
- Folgende
- Aussichten für
- Format
- Foundation
- Gerüste
- für
- Funktionalität
- Allgemeines
- bekommen
- ABSICHT
- Gruppe an
- persönlichem Wachstum
- gewachsen
- Griff
- Haben
- mit
- he
- Überschriften
- Hilfe
- Unternehmen
- hh
- GUTE
- höher
- seine
- Startseite
- Home Automation
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- Image
- implementiert
- importieren
- zu unterstützen,
- in
- inkremental
- installieren
- Integration
- interessiert
- Schnittstelle
- in
- Isolierung
- IT
- beigetreten
- jpg
- Behalten
- Aufbewahrung
- Tasten
- See
- Seen
- größer
- Breite
- umwandeln
- LERNEN
- weniger
- Lasst uns
- Gefällt mir
- Einschränkungen
- linux
- Linux-Stiftung
- Liste
- Belastung
- Standorte
- Standorte
- Log
- länger
- aussehen
- suchen
- ich liebe
- Magie
- verwalten
- Management
- Manager
- Weise
- viele
- Märkte
- max
- maximal
- Merge
- Metadaten
- Min.
- Minimum
- mehr
- mehrere
- Name
- nativ
- Navigieren
- Need
- erforderlich
- hört niemals
- Neu
- nicht
- beachten
- Notizbuch
- Laptops
- Anzahl
- Objekt
- Objektspeicher
- Objekte
- of
- Angebote
- vorgenommen,
- Alt
- Telefongebühren sparen
- on
- EINEM
- einzige
- OP
- XNUMXh geöffnet
- Open-Source-
- Betrieb
- Einkauf & Prozesse
- Optimieren
- Option
- Optionen
- or
- Auftrag
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- Überwindung
- besitzen
- Teil
- leidenschaftlich
- passt
- ausführen
- Leistung
- Plato
- Datenintelligenz von Plato
- PlatoData
- Beliebt
- Post
- Voraussetzungen
- früher
- vorher
- primär
- Verfahren
- Verarbeitung
- produziert
- Produkt
- Produkt-Manager
- Produkte
- immobilien
- Python
- Abfragen
- Honorar
- Roh
- Lesen Sie mehr
- Lesebrillen
- empfohlen
- aufgezeichnet
- Aufzeichnungen
- reduziert
- siehe
- referenziert
- zuverlässig
- entfernen
- entfernt
- Entfernen
- ersetzen
- falls angefordert
- Folge
- was zu
- Einzelhandel
- Beibehaltung
- robust
- Führen Sie
- Laufen
- gleich
- skalierbaren
- Skalieren
- Seattle
- Zweite
- Abschnitt
- sehen
- wählen
- Auswahl
- getrennte
- Dienstleistungen
- Sitzung
- kompensieren
- sollte
- erklären
- gezeigt
- Konzerte
- signifikant
- Einfacher
- Vereinfacht
- vereinfachen
- da
- Größe
- geringfügig
- SLP
- klein
- kleinere
- smart
- Schnappschuss
- So
- Lösungen
- Quelle
- Raumfahrt
- Spark
- besondere
- spezifisch
- speziell
- angegeben
- Geschwindigkeit
- Geschwindigkeiten
- verbrachte
- SQL
- Anfang
- Erklärung
- Aussagen
- Station
- Schritt
- Shritte
- Immer noch
- Lagerung
- speichern
- gelagert
- Strategie
- Schnur
- so
- Unterstützte
- System
- Systeme und Techniken
- Tabelle
- Tacoma
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Diese
- fehlen uns die Worte.
- Schwelle
- Durch
- Zeit
- Zeitreise
- Zeitstempel
- zu
- Tracking
- Transaktion
- Transaktionen
- reisen
- tippe
- Unerreicht
- Aktualisierung
- aktualisiert
- Updates
- us
- Anwendungsbereich
- -
- benutzt
- Verwendung von
- Vakuum
- Wert
- Version
- Versionen
- wollen
- wurde
- Wege
- we
- Netz
- Web-Services
- waren
- wann
- welche
- während
- werden wir
- mit
- ohne
- Arbeiten
- schreiben
- Jahr
- U
- Ihr
- Zephyrnet