Wie praktisch alle Kunden möchten Sie möglichst wenig ausgeben und gleichzeitig die bestmögliche Leistung erzielen. Das bedeutet, dass Sie auf das Preis-Leistungs-Verhältnis achten müssen. Mit Amazon RedShift, du kannst deinen Kuchen haben und ihn auch essen! Amazon Redshift bietet bis zu 4.9-mal niedrigere Kosten pro Benutzer und ein bis zu 7.9-mal besseres Preis-Leistungs-Verhältnis als andere Cloud-Data-Warehouses für reale Arbeitslasten, indem es fortschrittliche Techniken wie Parallelitätsskalierung zur Unterstützung Hunderter gleichzeitiger Benutzer und verbesserte String-Kodierung für eine schnellere Abfrageleistung nutzt , Und Amazon Redshift ohne Server Leistungssteigerungen. Lesen Sie weiter, um zu verstehen, warum das Preis-Leistungs-Verhältnis wichtig ist und wie das Preis-Leistungs-Verhältnis von Amazon Redshift ein Maß dafür ist, wie viel es kostet, ein bestimmtes Maß an Workload-Leistung zu erzielen, nämlich den Leistungs-ROI (Return on Investment).
Da sowohl der Preis als auch die Leistung in die Preis-Leistungs-Rechnung einfließen, gibt es zwei Möglichkeiten, über Preis-Leistung nachzudenken. Die erste Möglichkeit besteht darin, den Preis konstant zu halten: Wie viel Leistung erhalten Sie von Ihrem Data Warehouse, wenn Sie 1 US-Dollar ausgeben müssen? Eine Datenbank mit einem besseren Preis-Leistungs-Verhältnis liefert eine bessere Leistung für jeden ausgegebenen Dollar. Wenn Sie also beim Vergleich zweier Data Warehouses mit den gleichen Kosten den Preis konstant halten, führt die Datenbank mit dem besseren Preis-Leistungs-Verhältnis Ihre Abfragen schneller aus. Die zweite Möglichkeit, das Preis-Leistungs-Verhältnis zu betrachten, besteht darin, die Leistung konstant zu halten: Wenn Ihr Arbeitspensum in 10 Minuten erledigt sein muss, was kostet es dann? Eine Datenbank mit besserem Preis-Leistungs-Verhältnis führt Ihre Arbeitslast in 10 Minuten zu geringeren Kosten aus. Wenn Sie also beim Vergleich zweier Data Warehouses, die für die Bereitstellung derselben Leistung ausgelegt sind, die Leistung konstant halten, kostet die Datenbank mit dem besseren Preis-Leistungs-Verhältnis weniger und Sie sparen Geld.
Ein weiterer wichtiger Aspekt des Preis-Leistungs-Verhältnisses ist schließlich die Vorhersehbarkeit. Für die Planung ist es von entscheidender Bedeutung zu wissen, wie viel Ihr Data Warehouse kosten wird, wenn die Anzahl der Data Warehouse-Benutzer wächst. Es sollte nicht nur heute das beste Preis-Leistungs-Verhältnis bieten, sondern auch vorhersehbar skalieren und das beste Preis-Leistungs-Verhältnis bieten, wenn mehr Benutzer und Arbeitslasten hinzukommen. Ein ideales Data Warehouse sollte vorhanden sein lineare Skalierung– Die Skalierung Ihres Data Warehouse zur Bereitstellung des doppelten Abfragedurchsatzes sollte im Idealfall doppelt so viel (oder weniger) kosten.
In diesem Beitrag teilen wir Leistungsergebnisse, um zu veranschaulichen, wie Amazon Redshift im Vergleich zu führenden alternativen Cloud-Data-Warehouses ein deutlich besseres Preis-Leistungs-Verhältnis bietet. Das bedeutet, dass Sie mit Amazon Redshift eine bessere Leistung erzielen, wenn Sie für Amazon Redshift den gleichen Betrag ausgeben wie für eines dieser anderen Data Warehouses. Wenn Sie Ihren Redshift-Cluster alternativ so dimensionieren, dass er die gleiche Leistung liefert, werden Sie im Vergleich zu diesen Alternativen geringere Kosten feststellen.
Preis-Leistungs-Verhältnis für reale Workloads
Sie können Amazon Redshift verwenden, um eine Vielzahl von Arbeitslasten zu unterstützen, von der Stapelverarbeitung komplexer ETL-basierter Berichte (Extrahieren, Transformieren und Laden) über Echtzeit-Streaming-Analysen bis hin zu Business Intelligence (BI)-Dashboards mit geringer Latenz Sie müssen Hunderte oder sogar Tausende von Benutzern gleichzeitig mit Reaktionszeiten von weniger als einer Sekunde und allem dazwischen bedienen. Eine Möglichkeit, das Preis-Leistungs-Verhältnis für unsere Kunden kontinuierlich zu verbessern, besteht darin, die Software- und Hardware-Leistungstelemetrie der Redshift-Flotte ständig zu überprüfen und nach Möglichkeiten und Kundenanwendungsfällen zu suchen, bei denen wir die Leistung von Amazon Redshift weiter verbessern können.
Einige aktuelle Beispiele für Leistungsoptimierungen durch Flottentelemetrie sind:
- Optimierungen von String-Abfragen – Durch die Analyse, wie Amazon Redshift verschiedene Datentypen in der Redshift-Flotte verarbeitet, haben wir herausgefunden, dass die Optimierung stringlastiger Abfragen erhebliche Vorteile für die Arbeitslasten unserer Kunden bringen würde. (Wir besprechen dies später in diesem Beitrag ausführlicher.)
- Automatisierte materialisierte Ansichten – Wir haben festgestellt, dass Amazon Redshift-Kunden häufig viele Abfragen ausführen, die gemeinsame Unterabfragemuster aufweisen. Beispielsweise können mehrere unterschiedliche Abfragen dieselben drei Tabellen unter Verwendung derselben Join-Bedingung verknüpfen. Amazon Redshift ist jetzt in der Lage, automatisch materialisierte Ansichten zu erstellen und zu verwalten und anschließend Abfragen transparent umzuschreiben, um die materialisierten Ansichten mithilfe maschinell erlernter Daten zu verwenden automatisierte materialisierte Ansicht Autonomics-Funktion in Amazon Redshift. Wenn automatisierte materialisierte Ansichten aktiviert sind, können sie die Abfrageleistung bei sich wiederholenden Abfragen ohne Benutzereingriff transparent steigern. (Beachten Sie, dass automatisierte materialisierte Ansichten in keinem der in diesem Beitrag besprochenen Benchmark-Ergebnisse verwendet wurden.)
- Workloads mit hoher Parallelität – Ein wachsender Anwendungsfall, den wir sehen, ist die Verwendung von Amazon Redshift zur Bereitstellung von Dashboard-ähnlichen Workloads. Diese Workloads zeichnen sich durch gewünschte Abfrageantwortzeiten im einstelligen Sekundenbereich oder weniger aus, wobei Dutzende oder Hunderte von gleichzeitigen Benutzern gleichzeitig Abfragen ausführen, mit einem spitzen und oft unvorhersehbaren Nutzungsmuster. Das prototypische Beispiel hierfür ist ein von Amazon Redshift unterstütztes BI-Dashboard, das am Montagmorgen, wenn eine große Anzahl von Benutzern ihre Woche beginnt, einen Anstieg des Datenverkehrs verzeichnet.
Insbesondere Workloads mit hoher Parallelität haben ein sehr breites Anwendungsspektrum: Die meisten Data Warehouse-Workloads werden parallel ausgeführt, und es ist nicht ungewöhnlich, dass Hunderte oder sogar Tausende von Benutzern gleichzeitig Abfragen auf Amazon Redshift ausführen. Amazon Redshift wurde entwickelt, um die Antwortzeiten für Abfragen vorhersehbar und schnell zu halten. Redshift Serverless erledigt dies automatisch für Sie, indem es je nach Bedarf Rechenleistung hinzufügt und entfernt, um die Antwortzeiten für Abfragen schnell und vorhersehbar zu halten. Dies bedeutet, dass ein von Redshift Serverless unterstütztes Dashboard, das schnell geladen wird, wenn ein oder zwei Benutzer darauf zugreifen, auch dann schnell geladen wird, wenn viele Benutzer es gleichzeitig laden.
Um diese Art von Arbeitslast zu simulieren, haben wir einen von TPC-DS abgeleiteten Benchmark mit einem 100-GB-Datensatz verwendet. TPC-DS ist ein Branchenstandard-Benchmark, der eine Vielzahl typischer Data Warehouse-Abfragen umfasst. Bei diesem relativ kleinen Maßstab von 100 GB werden Abfragen in diesem Benchmark auf Redshift Serverless im Durchschnitt in wenigen Sekunden ausgeführt, was repräsentativ für das ist, was Benutzer beim Laden eines interaktiven BI-Dashboards erwarten würden. Wir führten zwischen 1 und 200 gleichzeitige Tests dieses Benchmarks durch und simulierten zwischen 1 und 200 Benutzer, die gleichzeitig versuchten, ein Dashboard zu laden. Wir haben den Test auch mit mehreren beliebten alternativen Cloud-Data-Warehouses wiederholt, die auch die automatische Skalierung unterstützen (falls Sie mit dem Beitrag vertraut sind). Amazon Redshift setzt seine Preis-Leistungs-Führerschaft fort, wir haben Mitbewerber A nicht einbezogen, da er keine automatische Skalierung unterstützt). Wir haben die durchschnittliche Antwortzeit auf Anfragen gemessen, d. h. wie lange ein Benutzer auf den Abschluss seiner Anfragen (oder auf das Laden seines Dashboards) warten würde. Die Ergebnisse sind in der folgenden Tabelle dargestellt.
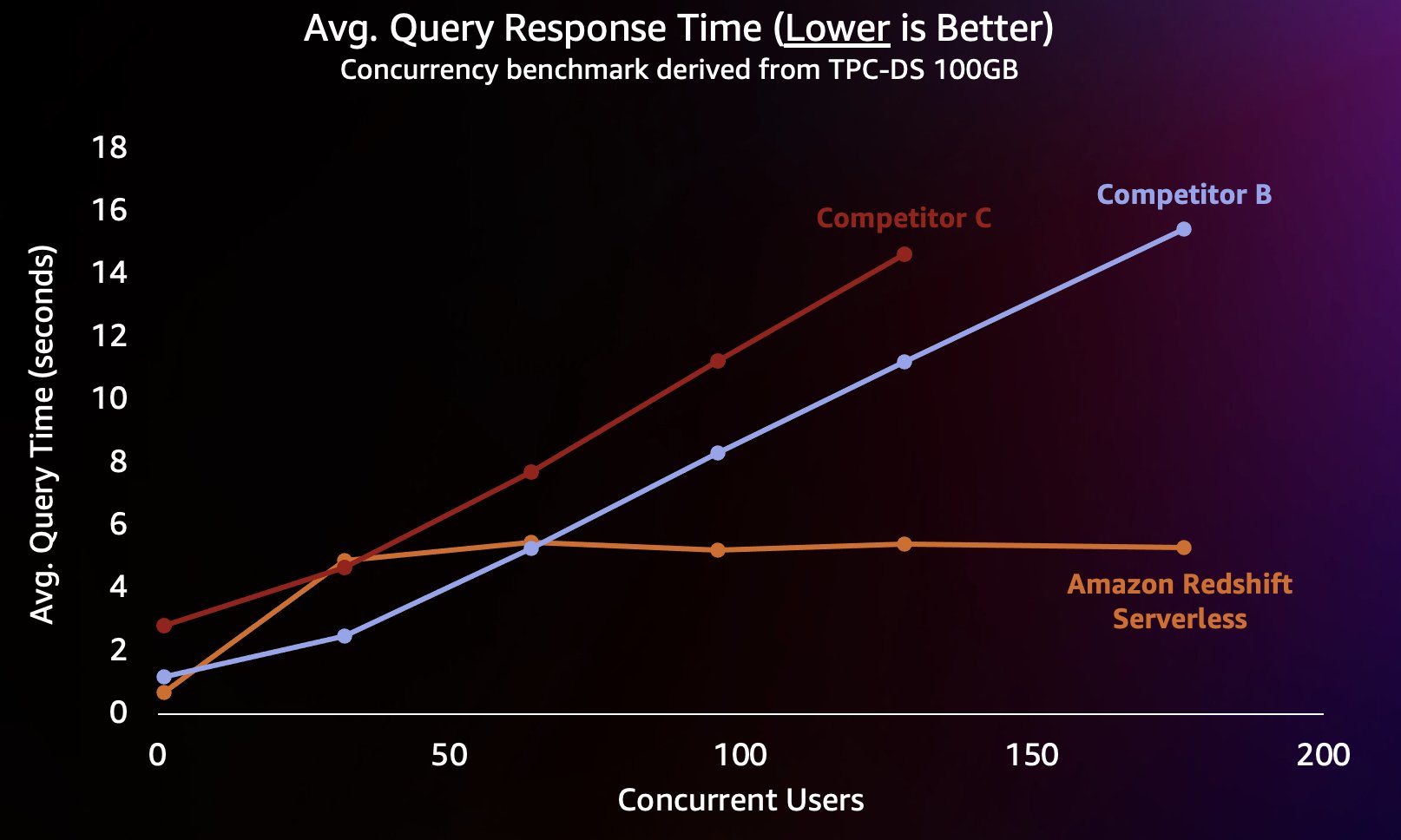
Konkurrent B skaliert bis zu etwa 64 gleichzeitigen Abfragen gut. Ab diesem Zeitpunkt ist er nicht mehr in der Lage, zusätzliche Rechenleistung bereitzustellen, und die Abfragen beginnen in der Warteschlange zu stehen, was zu längeren Abfrageantwortzeiten führt. Obwohl Wettbewerber C in der Lage ist, automatisch zu skalieren, skaliert er auf einen geringeren Abfragedurchsatz als Amazon Redshift und Wettbewerber B und ist nicht in der Lage, die Abfragelaufzeiten niedrig zu halten. Darüber hinaus werden Abfragen nicht in die Warteschlange gestellt, wenn die Rechenleistung erschöpft ist, was eine Skalierung auf mehr als etwa 128 gleichzeitige Benutzer verhindert. Darüber hinausgehende weitere Anfragen werden vom System abgelehnt.
Hier ist Redshift Serverless in der Lage, die Abfrageantwortzeit relativ konstant bei etwa 5 Sekunden zu halten, selbst wenn Hunderte von Benutzern gleichzeitig Abfragen ausführen. Die durchschnittlichen Abfrageantwortzeiten für die Wettbewerber B und C nehmen mit zunehmender Auslastung der Warehouses stetig zu, was dazu führt, dass Benutzer länger (bis zu 16 Sekunden) auf die Antwort ihrer Abfragen warten müssen, wenn das Data Warehouse ausgelastet ist. Das heißt, wenn ein Benutzer versucht, ein Dashboard zu aktualisieren (das beim erneuten Laden möglicherweise sogar mehrere gleichzeitige Abfragen sendet), wäre Amazon Redshift in der Lage, die Ladezeiten des Dashboards weitaus konsistenter zu halten, selbst wenn das Dashboard von Dutzenden oder Hunderten anderen geladen wird Benutzer gleichzeitig.
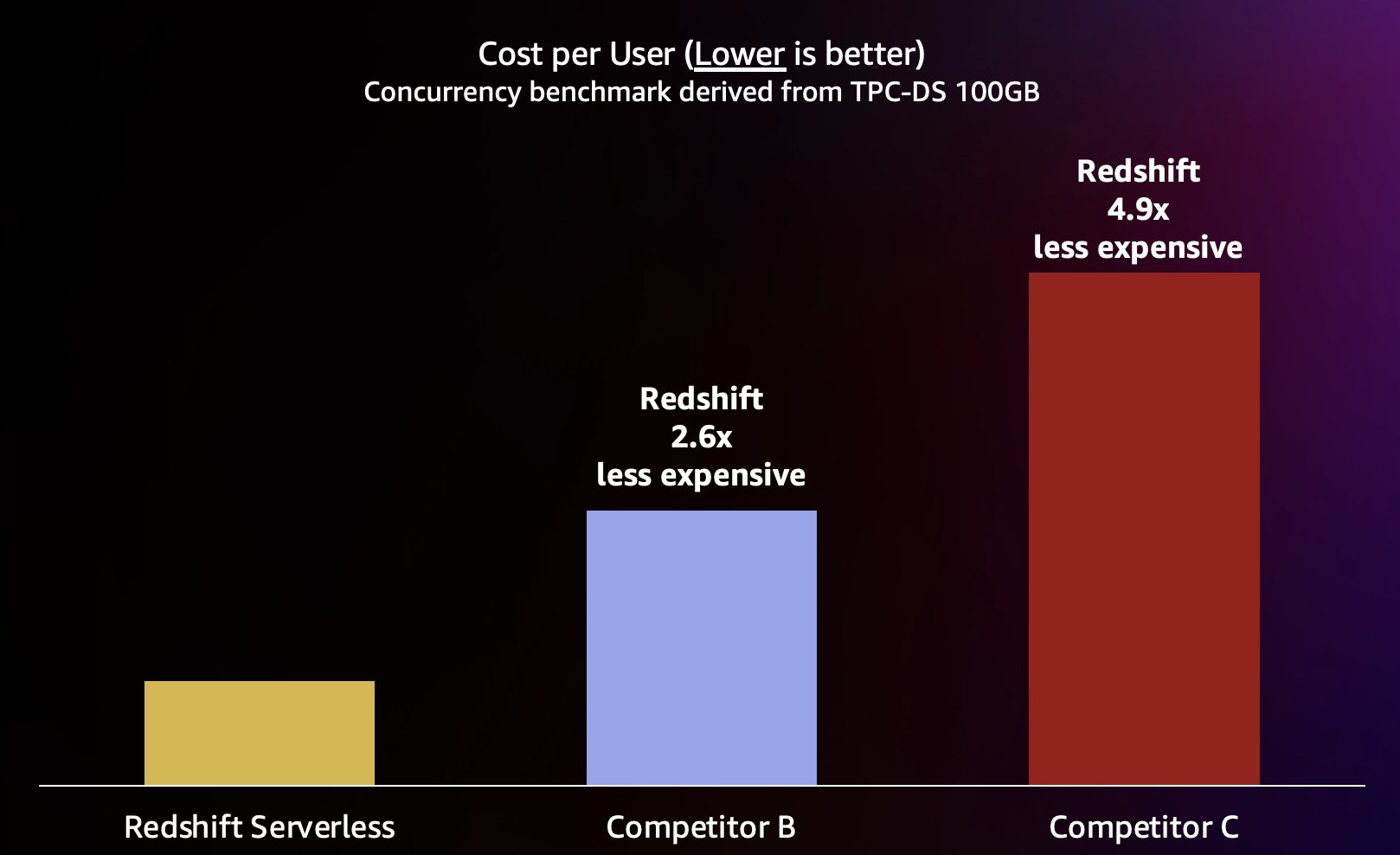
Weil Amazon Redshift in der Lage ist, einen sehr hohen Abfragedurchsatz für kurze Abfragen zu liefern (wie wir in geschrieben haben). Amazon Redshift setzt seine Preis-Leistungs-Führerschaft fort), ist es auch in der Lage, diese höheren Parallelitäten bei der Skalierung effizienter und damit zu deutlich geringeren Kosten zu bewältigen. Um dies zu quantifizieren, betrachten wir das Preis-Leistungs-Verhältnis anhand veröffentlichter Preisgestaltung auf Abruf für jedes der Lager im vorherigen Test, wie in der folgenden Tabelle dargestellt. Es ist erwähnenswert, dass die Verwendung Reservierte Instanzen (RIs)RIs, insbesondere 3-Jahres-RIs, die mit der Option „Komplette Vorauszahlung“ erworben wurden, haben die niedrigsten Kosten für die Ausführung von Amazon Redshift auf bereitgestellten Clustern, was zu dem besten relativen Preis-Leistungs-Verhältnis im Vergleich zu On-Demand- oder anderen RI-Optionen führt.

Daher ist Amazon Redshift nicht nur in der Lage, bei höheren Parallelitäten eine bessere Leistung zu liefern, sondern dies auch zu deutlich geringeren Kosten. Jeder Datenpunkt im Preis-Leistungs-Diagramm entspricht den Kosten für die Ausführung des Benchmarks bei der angegebenen Parallelität. Da das Preis-Leistungs-Verhältnis linear ist, können wir die Kosten für die Ausführung des Benchmarks bei jeder Parallelität durch die Parallelität (Anzahl der gleichzeitigen Benutzer in diesem Diagramm) dividieren, um zu erfahren, wie viel das Hinzufügen jedes neuen Benutzers für diesen bestimmten Benchmark kostet.
Die vorangehenden Ergebnisse lassen sich problemlos reproduzieren. Alle im Benchmark verwendeten Abfragen sind in unserem verfügbar GitHub-Repository und die Leistung wird gemessen, indem ein Data Warehouse gestartet, Concurrency Scaling auf Amazon Redshift (oder die entsprechende automatische Skalierungsfunktion in anderen Warehouses) aktiviert, die Daten sofort geladen werden (keine manuelle Optimierung oder datenbankspezifische Einrichtung) und dann ein ausgeführt wird gleichzeitiger Abfragestrom mit Parallelitäten von 1–200 in 32er-Schritten in jedem Data Warehouse. Das gleiche GitHub-Repo verweist auf vorgenerierte (und unveränderte) TPC-DS-Daten in Amazon Simple Storage-Service (Amazon S3) in verschiedenen Maßstäben mit dem offiziellen TPC-DS-Datengenerierungskit.
Optimierung stringlastiger Workloads
Wie bereits erwähnt, ist das Team von Amazon Redshift ständig auf der Suche nach neuen Möglichkeiten, um unseren Kunden ein noch besseres Preis-Leistungs-Verhältnis zu bieten. Eine kürzlich eingeführte Verbesserung, die die Leistung erheblich steigert, ist eine Optimierung, die die Leistung von Abfragen über Zeichenfolgendaten beschleunigt. Beispielsweise möchten Sie möglicherweise mit einer Abfrage wie „den Gesamtumsatz ermitteln, der von Einzelhandelsgeschäften in New York City generiert wird“. SELECT sum(price) FROM sales WHERE city = ‘New York’. Diese Abfrage wendet ein Prädikat auf Zeichenfolgendaten an (city = ‘New York’). Wie Sie sich vorstellen können, ist die Verarbeitung von Zeichenfolgendaten in Data Warehouse-Anwendungen allgegenwärtig.
Um zu quantifizieren, wie oft die Workloads der Kunden auf Strings zugreifen, haben wir eine detaillierte Analyse der Verwendung von String-Datentypen mithilfe von Flottentelemetrie von Zehntausenden von Kundenclustern durchgeführt, die von Amazon Redshift verwaltet werden. Unsere Analyse zeigt, dass in 90 % der Cluster Zeichenfolgenspalten mindestens 30 % aller Spalten ausmachen und dass in 50 % der Cluster Zeichenfolgenspalten mindestens 50 % aller Spalten ausmachen. Darüber hinaus greifen die meisten Abfragen, die auf der Cloud-Data-Warehouse-Plattform Amazon Redshift ausgeführt werden, auf mindestens eine Zeichenfolgenspalte zu. Ein weiterer wichtiger Faktor ist, dass Zeichenfolgendaten sehr oft eine niedrige Kardinalität aufweisen, was bedeutet, dass die Spalten einen relativ kleinen Satz eindeutiger Werte enthalten. Obwohl zum Beispiel ein orders Eine Tabelle mit Verkaufsdaten kann Milliarden von Zeilen enthalten order_status Die Spalte in dieser Tabelle enthält möglicherweise nur wenige eindeutige Werte in diesen Milliarden Zeilen, z pending, in process und completed.
Zum jetzigen Zeitpunkt sind die meisten Zeichenfolgenspalten in Amazon Redshift mit komprimiert LZO or ZSTD Algorithmen. Dabei handelt es sich um gute Allzweck-Komprimierungsalgorithmen, die jedoch nicht darauf ausgelegt sind, Zeichenfolgendaten mit geringer Kardinalität auszunutzen. Sie erfordern insbesondere, dass Daten vor der Bearbeitung dekomprimiert werden, und nutzen die Hardware-Speicherbandbreite weniger effizient. Für Daten mit geringer Kardinalität gibt es eine andere Art der Codierung, die optimaler sein kann: BYTEDIKT. Diese Codierung verwendet ein Wörterbuch-Codierungsschema, das es der Datenbank-Engine ermöglicht, direkt mit komprimierten Daten zu arbeiten, ohne diese zuerst dekomprimieren zu müssen.
Um das Preis-Leistungs-Verhältnis für stringlastige Workloads weiter zu verbessern, führt Amazon Redshift jetzt zusätzliche Leistungsverbesserungen ein, die Scans und Prädikatauswertungen gegenüber Stringspalten mit niedriger Kardinalität, die als BYTEDICT codiert sind, um das 5- bis 63-fache beschleunigen (siehe Ergebnisse in). im nächsten Abschnitt) im Vergleich zu alternativen Komprimierungskodierungen wie LZO oder ZSTD. Amazon Redshift erreicht diese Leistungsverbesserung durch die Vektorisierung von Scans über schlanke, CPU-effiziente, BYTEDICT-codierte String-Spalten mit niedriger Kardinalität. Diese String-Verarbeitungsoptimierungen nutzen effektiv die Speicherbandbreite, die moderne Hardware bietet, und ermöglichen Echtzeitanalysen über String-Daten. Diese neu eingeführten Leistungsfunktionen sind optimal für Zeichenfolgenspalten mit niedriger Kardinalität (bis zu einigen hundert eindeutigen Zeichenfolgenwerten).
Durch die Aktivierung können Sie automatisch von dieser neuen Hochleistungs-String-Verbesserung profitieren automatische Tabellenoptimierung in Ihrem Amazon Redshift Data Warehouse. Wenn Sie für Ihre Tabellen keine automatische Tabellenoptimierung aktiviert haben, können Sie Empfehlungen von erhalten Amazon Redshift-Berater in der Amazon Redshift-Konsole auf die Eignung einer Zeichenfolgenspalte für die BYTEDICT-Codierung. Sie können auch neue Tabellen mit Zeichenfolgenspalten mit niedriger Kardinalität mit BYTEDICT-Codierung definieren. String-Verbesserungen in Amazon Redshift sind jetzt in allen AWS-Regionen verfügbar Amazon Redshift ist verfügbar.
Leistungsergebnisse
Um die Leistungsauswirkungen unserer String-Verbesserungen zu messen, haben wir einen 10 TB (Tera Byte) großen Datensatz generiert, der aus String-Daten mit niedriger Kardinalität bestand. Wir haben drei Versionen der Daten mit kurzen, mittleren und langen Zeichenfolgen generiert, die dem 25., 50. und 75. Perzentil der Zeichenfolgenlängen aus der Flottentelemetrie von Amazon Redshift entsprechen. Wir haben diese Daten zweimal in Amazon Redshift geladen und sie einmal mit LZO-Komprimierung und einmal mit BYTEDICT-Komprimierung kodiert. Schließlich haben wir die Leistung scanlastiger Abfragen gemessen, die viele Zeilen (90 % der Tabelle), eine mittlere Anzahl von Zeilen (50 % der Tabelle) und einige Zeilen (1 % der Tabelle) über diesen niedrigen Werten zurückgeben -Kardinalitäts-String-Datensätze. Die Leistungsergebnisse sind in der folgenden Tabelle zusammengefasst.

Bei Abfragen mit Prädikaten, die einem hohen Prozentsatz an Zeilen entsprechen, wurden mit der neuen vektorisierten BYTEDICT-Codierung im Vergleich zu LZO Verbesserungen um das 5- bis 30-fache erzielt, während bei Abfragen mit Prädikaten, die einem geringen Prozentsatz an Zeilen entsprechen, in diesem internen Benchmark Verbesserungen um das 10- bis 63-fache erzielt wurden.
Redshift Serverless Preis-Leistung
Zusätzlich zu den in diesem Beitrag vorgestellten Ergebnissen zur Leistung bei hoher Parallelität haben wir auch den von TPC-DS abgeleiteten Cloud Data Warehouse-Benchmark verwendet, um das Preis-Leistungs-Verhältnis von Redshift Serverless mit anderen Data Warehouses zu vergleichen, die einen größeren 3-TB-Datensatz verwenden. Wir haben Data Warehouses mit ähnlichen Preisen ausgewählt, in diesem Fall innerhalb von 10 % von 32 US-Dollar pro Stunde unter Verwendung öffentlich verfügbarer On-Demand-Preise. Diese Ergebnisse zeigen, dass Redshift Serverless, genau wie Amazon Redshift RA3-Instanzen, im Vergleich zu anderen führenden Cloud-Data-Warehouses ein besseres Preis-Leistungs-Verhältnis bietet. Wie immer können diese Ergebnisse durch die Verwendung unserer SQL-Skripte in unserem repliziert werden GitHub-Repository.

Wir empfehlen Ihnen, Amazon Redshift selbst auszuprobieren Proof of Concept Workloads als beste Möglichkeit zu sehen, wie Amazon Redshift Ihre Datenanalyseanforderungen erfüllen kann.
Finden Sie das beste Preis-Leistungs-Verhältnis für Ihre Workloads
Die in diesem Beitrag verwendeten Benchmarks sind vom branchenüblichen TPC-DS-Benchmark abgeleitet und weisen die folgenden Merkmale auf:
- Das Schema und die Daten werden unverändert von TPC-DS verwendet.
- Die Abfragen werden mit dem offiziellen TPC-DS-Kit generiert, wobei die Abfrageparameter mit dem standardmäßigen Zufallsstartwert des TPC-DS-Kits generiert werden. Von TPC genehmigte Abfragevarianten werden für ein Warehouse verwendet, wenn das Warehouse den SQL-Dialekt der Standard-TPC-DS-Abfrage nicht unterstützt.
- Der Test umfasst die 99 TPC-DS SELECT-Abfragen. Es umfasst keine Wartungs- und Durchsatzschritte.
- Für den einzelnen 3-TB-Parallelitätstest wurden drei Power-Runs ausgeführt, und für jedes Data Warehouse wird der beste Run durchgeführt.
- Das Preis-Leistungs-Verhältnis für die TPC-DS-Abfragen wird berechnet als Kosten pro Stunde (USD) multipliziert mit der Benchmark-Laufzeit in Stunden, was den Kosten für die Ausführung des Benchmarks entspricht. Für alle Data Warehouses werden die zuletzt veröffentlichten On-Demand-Preise verwendet und nicht die Preise für Reserved Instances, wie bereits erwähnt.
Wir nennen dies den Cloud Data Warehouse-Benchmark, und Sie können die vorherigen Benchmark-Ergebnisse mithilfe der in unserem verfügbaren Skripts, Abfragen und Daten problemlos reproduzieren GitHub-Repository. Es wird aus den in diesem Beitrag beschriebenen TPC-DS-Benchmarks abgeleitet und ist daher nicht mit veröffentlichten TPC-DS-Ergebnissen vergleichbar, da die Ergebnisse unserer Tests nicht der offiziellen Spezifikation entsprechen.
Zusammenfassung
Amazon Redshift ist bestrebt, das branchenweit beste Preis-Leistungs-Verhältnis für die unterschiedlichsten Workloads zu bieten. Redshift Serverless skaliert linear mit dem besten (niedrigsten) Preis-Leistungs-Verhältnis und unterstützt Hunderte von gleichzeitigen Benutzern bei gleichzeitiger Beibehaltung konsistenter Antwortzeiten auf Abfragen. Basierend auf den in diesem Beitrag besprochenen Testergebnissen bietet Amazon Redshift bei gleicher Parallelität ein bis zu 2.6-mal besseres Preis-Leistungs-Verhältnis im Vergleich zum nächsten Konkurrenten (Konkurrent B). Wie bereits erwähnt, bietet Ihnen die Verwendung von Reserved Instances mit der 3-Jahres-Option „Alle im Voraus“ die niedrigsten Kosten für den Betrieb von Amazon Redshift, was zu einem noch besseren relativen Preis-Leistungs-Verhältnis im Vergleich zu den On-Demand-Instance-Preisen führt, die wir in diesem Beitrag verwendet haben. Unser Ansatz zur kontinuierlichen Leistungsverbesserung umfasst eine einzigartige Kombination aus der Besessenheit der Kunden, Kundenanwendungsfälle und die damit verbundenen Skalierbarkeitsengpässe zu verstehen, gepaart mit einer kontinuierlichen Flottendatenanalyse, um Möglichkeiten für erhebliche Leistungsoptimierungen zu identifizieren.
Jeder Workload hat einzigartige Eigenschaften. Wenn Sie also gerade erst anfangen, a Proof of Concept Dies ist der beste Weg, um zu verstehen, wie Amazon Redshift Ihre Kosten senken und gleichzeitig eine bessere Leistung liefern kann. Wenn Sie Ihren eigenen Proof of Concept durchführen, ist es wichtig, sich auf die richtigen Kennzahlen zu konzentrieren – Abfragedurchsatz (Anzahl der Abfragen pro Stunde), Antwortzeit und Preis-Leistungs-Verhältnis. Sie können eine datengesteuerte Entscheidung treffen, indem Sie selbst einen Proof of Concept durchführen oder mit hilfe von AWS oder a Systemintegrations- und Beratungspartner.
Um über die neuesten Entwicklungen bei Amazon Redshift auf dem Laufenden zu bleiben, folgen Sie der Was ist neu in Amazon Redshift? zu ernähren.
Über die Autoren
 Stefan Gromoll ist Senior Performance Engineer beim Amazon Redshift-Team, wo er für die Messung und Verbesserung der Redshift-Leistung verantwortlich ist. In seiner Freizeit kocht er gerne, spielt mit seinen drei Jungs und hackt Feuerholz.
Stefan Gromoll ist Senior Performance Engineer beim Amazon Redshift-Team, wo er für die Messung und Verbesserung der Redshift-Leistung verantwortlich ist. In seiner Freizeit kocht er gerne, spielt mit seinen drei Jungs und hackt Feuerholz.
 Ravi Animi ist Senior Product Management Leader im Amazon Redshift-Team und verwaltet mehrere Funktionsbereiche des Amazon Redshift Cloud Data Warehouse-Dienstes, einschließlich Leistung, räumliche Analyse, Streaming-Aufnahme und Migrationsstrategien. Er verfügt über Erfahrung mit relationalen Datenbanken, mehrdimensionalen Datenbanken, IoT-Technologien, Speicher- und Recheninfrastrukturdiensten und in jüngerer Zeit als Startup-Gründer mit KI/Deep Learning, Computer Vision und Robotik.
Ravi Animi ist Senior Product Management Leader im Amazon Redshift-Team und verwaltet mehrere Funktionsbereiche des Amazon Redshift Cloud Data Warehouse-Dienstes, einschließlich Leistung, räumliche Analyse, Streaming-Aufnahme und Migrationsstrategien. Er verfügt über Erfahrung mit relationalen Datenbanken, mehrdimensionalen Datenbanken, IoT-Technologien, Speicher- und Recheninfrastrukturdiensten und in jüngerer Zeit als Startup-Gründer mit KI/Deep Learning, Computer Vision und Robotik.
 Aamer Shah ist Senior Engineer im Amazon Redshift Service-Team.
Aamer Shah ist Senior Engineer im Amazon Redshift Service-Team.
 Sanket Hase ist Software Development Manager im Amazon Redshift Service-Team.
Sanket Hase ist Software Development Manager im Amazon Redshift Service-Team.
 Orestis Polychroniou ist Principal Engineer im Amazon Redshift Service-Team.
Orestis Polychroniou ist Principal Engineer im Amazon Redshift Service-Team.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Fähig
- Über Uns
- beschleunigt
- Zugang
- Zugriff
- Erreicht
- über
- hinzugefügt
- Hinzufügen
- Zusatz
- Zusätzliche
- advanced
- Vorteil
- gewährt
- gegen
- Algorithmen
- Alle
- erlaubt
- ebenfalls
- Alternative
- Alternativen
- Obwohl
- immer
- Amazon
- Amazon Web Services
- Betrag
- an
- Analyse
- Analytik
- Analyse
- und
- Ein anderer
- jedem
- Anwendungen
- Anwendung
- Ansatz
- SIND
- Bereiche
- um
- AS
- Aussehen
- damit verbundenen
- At
- Aufmerksamkeit
- Auto
- Automatisiert
- automatische
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- durchschnittlich
- AWS
- b
- Bandbreite
- basierend
- BE
- weil
- Bevor
- beginnen
- Sein
- Benchmark
- Benchmarks
- Nutzen
- BESTE
- Besser
- zwischen
- Beyond
- Milliarden
- beide
- Engpässe
- Box
- bringen
- breit
- Geschäft
- Business Intelligence
- beschäftigt
- aber
- by
- CAKE
- berechnet
- Berechnung
- rufen Sie uns an!
- CAN
- Fähigkeiten
- Häuser
- Fälle
- Charakteristik
- dadurch gekennzeichnet
- Chart
- hacken
- wählten
- Stadt
- Cloud
- Cluster
- Kolonne
- Spalten
- Kombination
- begangen
- gemeinsam
- vergleichbar
- vergleichen
- verglichen
- Vergleich
- Wettbewerber
- Konkurrenz
- Komplex
- entsprechen
- Berechnen
- Computer
- Computer Vision
- konzept
- Wettbewerber
- Zustand
- durchgeführt
- konsistent
- Konsul (Console)
- konstante
- ständig
- bilden
- Consulting
- enthalten
- ständig
- fortsetzen
- weiter
- kontinuierlich
- ständig
- Kochen
- Dazugehörigen
- Kosten
- Kosten
- gekoppelt
- erstellen
- wichtig
- Kunde
- Kunden
- Armaturenbrett
- Dashboards
- technische Daten
- Datenanalyse
- Datenanalyse
- Datenverarbeitung
- Datensatz
- Data Warehouse
- Data Warehouse
- datengesteuerte
- Datenbase
- Datenbanken
- Datensätze
- Datum
- Entscheidung
- Standard
- definieren
- Übergeben
- liefern
- liefert
- Abgeleitet
- beschrieben
- entworfen
- erwünscht
- Detail
- detailliert
- Entwicklung
- Entwicklungen
- anders
- Direkt
- diskutieren
- diskutiert
- Diversität
- aufteilen
- do
- die
- Tut nicht
- Nicht
- angetrieben
- jeder
- Früher
- leicht
- essen
- Effektiv
- effizient
- effizient
- freigegeben
- ermöglichen
- ermutigen
- Motor
- Ingenieur
- verbesserte
- Erweiterung
- Verbesserungen
- Enter
- Äquivalent
- insbesondere
- Äther (ETH)
- Auswertungen
- Sogar
- alles
- Beispiel
- Beispiele
- erwarten
- ERFAHRUNGEN
- Extrakt
- Faktor
- vertraut
- weit
- FAST
- beschleunigt
- Merkmal
- wenige
- Endlich
- Finden Sie
- Fertig
- Vorname
- FLOTTE
- Setzen Sie mit Achtsamkeit
- folgen
- Folgende
- Aussichten für
- gefunden
- Gründer
- für
- funktional
- weiter
- allgemeiner Zweck
- erzeugt
- Generation
- bekommen
- bekommen
- GitHub
- gibt
- gehen
- gut
- persönlichem Wachstum
- Wächst
- Griff
- Hardware
- Haben
- mit
- he
- GUTE
- höher
- seine
- Halten
- Stunde
- STUNDEN
- Ultraschall
- HTML
- http
- HTTPS
- hundert
- hunderte
- ideal
- im Idealfall
- identifizieren
- if
- veranschaulichen
- Bild
- Impact der HXNUMXO Observatorien
- wichtig
- wichtiger Aspekt
- zu unterstützen,
- verbessert
- Verbesserung
- Verbesserungen
- Verbesserung
- in
- das
- Dazu gehören
- Einschließlich
- Erhöhung
- hat
- Steigert
- zeigt
- Industrie
- Infrastruktur
- Instanz
- Instanzen
- Integration
- Intelligenz
- interaktive
- intern
- Intervention
- in
- eingeführt
- Einführung
- Investition
- beinhaltet
- iot
- IT
- SEINE
- join
- jpg
- nur
- Behalten
- Ausrüstung
- Wissend
- grosse
- größer
- später
- neueste
- neueste Entwicklungen
- ins Leben gerufen
- Start
- Führer
- führenden
- lernen
- am wenigsten
- weniger
- Niveau
- leicht
- Gefällt mir
- wenig
- Belastung
- Laden
- Belastungen
- located
- Lang
- länger
- aussehen
- suchen
- Sneaker
- senken
- niedrigste
- halten
- Aufrechterhaltung
- Wartung
- Mehrheit
- um
- verwaltet
- Management
- Manager
- Managed
- manuell
- viele
- Spiel
- Angelegenheiten
- Kann..
- Bedeutung
- Mittel
- messen
- gemessen
- Messen
- mittlere
- Triff
- Memory
- erwähnt
- könnte
- Migration
- Minuten
- modern
- Montag
- Geld
- mehr
- Zudem zeigt
- vor allem warme
- viel
- nämlich
- Need
- erforderlich
- Bedürfnisse
- Neu
- New York
- New York City
- neu
- weiter
- nicht
- beachten
- bekannt
- Bemerkens
- jetzt an
- Anzahl
- of
- offiziell
- vorgenommen,
- on
- On-Demand
- EINEM
- einzige
- betreiben
- betrieben
- Entwicklungsmöglichkeiten
- optimal
- Optimierung
- Optimierung
- Option
- Optionen
- or
- Andere
- UNSERE
- übrig
- besitzen
- Parameter
- besondere
- Schnittmuster
- Muster
- AUFMERKSAMKEIT
- Zahlung
- für
- Prozentsatz
- Leistung
- Planung
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Points
- Beliebt
- möglich
- Post
- Werkzeuge
- Vorhersagbar
- vorgeführt
- verhindert
- Preis
- gebühr
- Principal
- verarbeitet
- Verarbeitung
- Produkt
- Produktmanagement
- Beweis
- Proof of Concept
- die
- öffentlich
- veröffentlicht
- gekauft
- Abfragen
- schnell
- zufällig
- Lesen Sie mehr
- realen Welt
- Echtzeit
- erhalten
- kürzlich
- kürzlich
- Empfehlungen
- Referenzen
- Regionen
- Abgelehnt..
- relativ
- verhältnismäßig
- Entfernen
- wiederholt
- repetitiv
- repliziert
- Meldungen
- Vertreter
- Darstellen
- erfordern
- reserviert
- Antwort
- für ihren Verlust verantwortlich.
- was zu
- Die Ergebnisse
- Einzelhandel
- Rückkehr
- Einnahmen
- Überprüfen
- Recht
- Robotik
- ROI
- Führen Sie
- Laufen
- läuft
- Vertrieb
- gleich
- Speichern
- sah
- Skalierbarkeit
- Skalieren
- Waage
- Skalierung
- scannt
- Schema
- Skripte
- Zweite
- Sekunden
- Abschnitt
- sehen
- Samen
- Senior
- brauchen
- Serverlos
- Lösungen
- kompensieren
- Setup
- mehrere
- Teilen
- Short
- sollte
- erklären
- gezeigt
- signifikant
- bedeutend
- Ähnlich
- Einfacher
- gleichzeitig
- Single
- Größe
- Größe
- klein
- So
- Software
- Software-Entwicklung
- räumlich
- Spezifikation
- angegeben
- Geschwindigkeit
- verbringen
- verbrachte
- Spitze
- SQL
- Anfang
- begonnen
- Anfang
- bleiben
- ständig
- Shritte
- Lagerung
- Läden
- einfach
- Strategien
- Strom
- Streaming
- Schnur
- abschicken
- so
- Eignung
- Support
- Unterstützung
- System
- Tabelle
- Nehmen
- gemacht
- Team
- Techniken
- Technologies
- erzählen
- Zehn
- Test
- Tests
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- dann
- Dort.
- deswegen
- Diese
- vom Nutzer definierten
- think
- fehlen uns die Worte.
- diejenigen
- Tausende
- nach drei
- Durchsatz
- Zeit
- mal
- zu
- heute
- Gesamt
- der Verkehr
- Transformieren
- transparent
- versuchen
- Versuch
- Twice
- XNUMX
- tippe
- Typen
- typisch
- allgegenwärtig
- nicht fähig
- Ungewöhnlich
- verstehen
- einzigartiges
- unberechenbar
- bis
- us
- Anwendungsbereich
- USD
- -
- Anwendungsfall
- benutzt
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- Werte
- Vielfalt
- verschiedene
- sehr
- Ansichten
- praktisch
- Seh-
- warten
- wollen
- Warehouse
- wurde
- Weg..
- Wege
- we
- Netz
- Web-Services
- Woche
- GUT
- waren
- Was
- wann
- während
- welche
- während
- warum
- breit
- werden wir
- mit
- .
- ohne
- wert
- würde
- Schreiben
- schrieb
- York
- U
- Ihr
- Zephyrnet