Wie oft werden maschinelle Lernprojekte erfolgreich eingesetzt? Nicht oft genug. Es gibt reichlich of Energiegewinnung Forschungsprojekte zeigt dass ML-Projekte im Allgemeinen keine Ergebnisse liefern, aber nur wenige haben das Verhältnis von Misserfolg zu Erfolg aus der Sicht von Datenwissenschaftlern beurteilt – den Leuten, die genau die Modelle entwickeln, die diese Projekte einsetzen sollen.
Im Anschluss an eine Umfrage unter Datenwissenschaftlern das ich letztes Jahr mit KDnuggets durchgeführt habe, die diesjährige branchenführende Data Science-Umfrage Die von der ML-Beratungsfirma Rexer Analytics durchgeführte Studie ging auf diese Frage ein – zum Teil, weil Karl Rexer, der Gründer und Präsident des Unternehmens, Sie wirklich einbeziehen ließ und die Einbeziehung von Fragen zum Bereitstellungserfolg vorangetrieben hat (Teil meiner Arbeit während meiner einjährigen Professur für Analytik). an der UVA Darden).
Die Nachrichten sind nicht großartig. Nur 22 % der Datenwissenschaftler geben an, dass ihre „revolutionären“ Initiativen – Modelle, die entwickelt wurden, um einen neuen Prozess oder eine neue Fähigkeit zu ermöglichen – normalerweise umgesetzt werden. 43 % sagen, dass 80 % oder mehr bei der Bereitstellung scheitern.
Über alle Arten von ML-Projekten – einschließlich Aktualisierungsmodellen für bestehende Bereitstellungen – geben nur 32 % an, dass ihre Modelle normalerweise bereitgestellt werden.
Hier sind die detaillierten Ergebnisse dieses Teils der Umfrage, präsentiert von Rexer Analytics, mit einer Aufschlüsselung der Einsatzraten für drei Arten von ML-Initiativen:
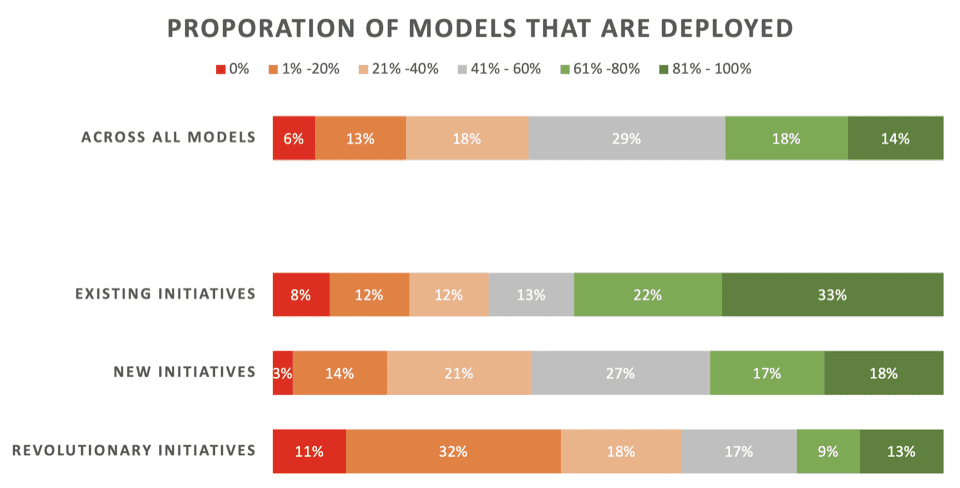
Schlüssel:
- Bestehende Initiativen: Modelle, die entwickelt wurden, um ein vorhandenes Modell zu aktualisieren/aktualisieren, das bereits erfolgreich bereitgestellt wurde
- Neue Initiativen: Modelle, die entwickelt wurden, um einen bestehenden Prozess zu verbessern, für den noch kein Modell bereitgestellt wurde
- Revolutionäre Initiativen: Modelle, die entwickelt wurden, um einen neuen Prozess oder eine neue Fähigkeit zu ermöglichen
Meiner Ansicht nach sind diese Schwierigkeiten bei der Umsetzung vor allem auf zwei Faktoren zurückzuführen: mangelnde Planung und fehlende konkrete Sichtbarkeit der Geschäftsinteressenten. Viele Datenexperten und Unternehmensleiter haben nicht erkannt, dass die beabsichtigte Operationalisierung von ML von Beginn jedes ML-Projekts an sehr detailliert geplant und aggressiv verfolgt werden muss.
Tatsächlich habe ich ein neues Buch darüber geschrieben: Das KI-Playbook: Die seltene Kunst der Bereitstellung maschinellen Lernens meistern. In diesem Buch stelle ich eine auf die Bereitstellung ausgerichtete, sechsstufige Vorgehensweise zur Einführung maschineller Lernprojekte von der Konzeption bis zur Bereitstellung vor, die ich nenne bizML (Bestellen Sie das Hardcover oder E-Book vor und Erhalten Sie ein kostenloses Vorabexemplar der Hörbuchversion sofort).
Der wichtigste Stakeholder eines ML-Projekts – die Person, die für die betriebliche Effektivität verantwortlich ist, die verbessert werden soll, z. B. ein Branchenmanager – benötigt Transparenz darüber, wie genau ML seine Abläufe verbessern wird und welchen Wert die Verbesserung voraussichtlich bringen wird. Sie benötigen dies, um letztendlich grünes Licht für die Bereitstellung eines Modells zu geben und vorher die Ausführung des Projekts in den Phasen vor der Bereitstellung zu beurteilen.
Aber die Leistung von ML wird oft nicht gemessen! Als in der Rexer-Umfrage gefragt wurde: „Wie oft misst Ihr Unternehmen/Ihre Organisation die Leistung von Analyseprojekten?“ Nur 48 % der Datenwissenschaftler sagten „Immer“ oder „Meistens“. Das ist ziemlich wild. Es sollte eher bei 99 % oder 100 % liegen.
Und wenn die Leistung gemessen wird, geschieht dies anhand technischer Kennzahlen, die geheimnisvoll und für Geschäftsbeteiligte größtenteils irrelevant sind. Datenwissenschaftler wissen es besser, halten sich aber im Allgemeinen nicht daran – zum Teil, weil ML-Tools im Allgemeinen nur technische Metriken liefern. Laut der Umfrage zählen Datenwissenschaftler geschäftliche KPIs wie ROI und Umsatz zu den wichtigsten Kennzahlen, technische Kennzahlen wie Steigerung und AUC zählen jedoch zu den am häufigsten gemessenen Kennzahlen.
Technische Leistungsmetriken seien „grundsätzlich nutzlos für Geschäftsinteressenten und nicht mit ihnen verknüpft“, heißt es Harvard Data Science Review. Hier ist der Grund: Sie sagen Ihnen nur das relativ Leistung eines Modells, z. B. wie es mit Schätzungen oder einer anderen Basislinie verglichen wird. Geschäftskennzahlen verraten es Ihnen Absolute Geschäftswert, den das Modell voraussichtlich liefern wird – oder, bei der Bewertung nach der Bereitstellung, dass es sich als nachweislich erwiesen hat. Solche Metriken sind für einsatzorientierte ML-Projekte unerlässlich.
Über den Zugriff auf Geschäftskennzahlen hinaus müssen auch die Geschäftsinteressenten verstärkt werden. Als in der Rexer-Umfrage gefragt wurde: „Verfügen die Manager und Entscheidungsträger in Ihrem Unternehmen, die die Modelleinführung genehmigen müssen, im Allgemeinen über ausreichende Kenntnisse, um solche Entscheidungen gut informiert zu treffen?“ Nur 49 % der Befragten antworteten mit „Meistens“ oder „Immer“.
Ich glaube, dass Folgendes passiert. Der „Kunde“ des Datenwissenschaftlers, der geschäftliche Stakeholder, bekommt oft kalte Füße, wenn es um die Genehmigung der Bereitstellung geht, da dies eine erhebliche betriebliche Änderung an den Hauptabläufen des Unternehmens, den größten Prozessen, bedeuten würde. Ihnen fehlt der kontextuelle Rahmen. Sie fragen sich zum Beispiel: „Wie soll ich verstehen, wie sehr dieses Modell, dessen Leistung weit hinter der Perfektion einer Kristallkugel zurückbleibt, tatsächlich helfen wird?“ Damit stirbt das Projekt. Wenn man dann den „gewonnenen Erkenntnissen“ kreativ eine positive Wendung gibt, kann man das Scheitern sauber unter den Teppich kehren. Der KI-Hype bleibt bestehen, auch wenn der potenzielle Wert, der Zweck des Projekts verloren geht.
Zu diesem Thema – Stakeholder-Aktivierung – werde ich mein neues Buch veröffentlichen: Das KI-Playbook, nur noch einmal. Das Buch deckt nicht nur die bizML-Praxis ab, sondern schult auch Geschäftsleute weiter, indem es eine wichtige, aber dennoch freundliche Portion halbtechnischen Hintergrundwissens vermittelt, das alle Beteiligten benötigen, um durchgängig maschinelle Lernprojekte zu leiten oder daran teilzunehmen. Dies bringt Geschäfts- und Datenexperten auf den gleichen Stand, sodass sie intensiv zusammenarbeiten und gemeinsam präzise Lösungen finden können was maschinelles Lernen vorhersagen soll, wie gut es vorhersagt und wie auf seine Vorhersagen reagiert wird, um den Betrieb zu verbessern. Diese Grundvoraussetzungen entscheiden über den Erfolg oder Misserfolg jeder Initiative – wenn man sie richtig macht, ebnet man den Weg für den wertorientierten Einsatz von maschinellem Lernen.
Man kann mit Sicherheit sagen, dass die Lage da draußen schwierig ist, insbesondere bei neuen, ersten ML-Initiativen. Da die schiere Kraft des KI-Hypes seine Fähigkeit verliert, dies immer wieder aufzuholen
Wenn der realisierte Wert geringer ist als versprochen, wird der Druck, den operativen Wert von ML nachzuweisen, immer größer.? Deshalb sage ich: Machen Sie jetzt einen Schritt voraus – beginnen Sie mit der Einführung einer effektiveren Kultur der unternehmensübergreifenden Zusammenarbeit und einer einsatzorientierten Projektführung!
Für detailliertere Ergebnisse aus der 2023 Rexer Analytics Data Science-Umfrage, klicken hier. Dies ist die größte Umfrage unter Datenwissenschafts- und Analyseexperten in der Branche. Es besteht aus etwa 35 Multiple-Choice- und offenen Fragen, die viel mehr als nur Erfolgsquoten bei der Bereitstellung abdecken – sieben allgemeine Bereiche der Data-Mining-Wissenschaft und -Praxis: (1) Feld und Ziele, (2) Algorithmen, (3) Modelle, ( 4) Tools (verwendete Softwarepakete), (5) Technologie, (6) Herausforderungen und (7) Zukunft. Es wird als Service (ohne Unternehmenssponsoring) für die Data-Science-Community durchgeführt und die Ergebnisse werden in der Regel unter bekannt gegeben die Konferenz der Machine Learning Week und über frei verfügbare zusammenfassende Berichte geteilt.
Dieser Artikel ist ein Produkt der Arbeit des Autors, während er ein Jahr lang eine Stelle als Bodily Bicentennial Professor für Analytik an der UVA Darden School of Business innehatte, die schließlich mit der Veröffentlichung von gipfelte Das KI-Playbook: Die seltene Kunst der Bereitstellung maschinellen Lernens meistern (kostenloses Hörbuchangebot).
Eric Siegel, Ph.D., ist ein führender Berater und ehemaliger Professor der Columbia University, der maschinelles Lernen verständlich und fesselnd macht. Er ist der Gründer der Predictive Analytics-Welt und für Deep Learning Welt Konferenzreihe, die seit 17,000 mehr als 2009 Teilnehmern geholfen hat, der Dozent des renommierten Kurses Führung und Praxis des maschinellen Lernens – End-to-End-Meisterschaft, ein beliebter Redner, für den beauftragt wurde Über 100 Keynote-Vorträgeund Executive Editor von Die Zeiten des maschinellen Lernens. Er hat den Bestseller geschrieben Predictive Analytics: Die Fähigkeit, vorherzusagen, wer klicken, kaufen, lügen oder sterben wird, der in Kursen an mehr als 35 Universitäten verwendet wurde, und er gewann Lehrpreise, als er Professor an der Columbia University war, wo er sang pädagogische Lieder an seine Schüler. Eric veröffentlicht auch Kommentare zu Analytik und sozialer Gerechtigkeit. Folgen Sie ihm an @predictanalytic.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 1
- 17
- 35%
- 7
- a
- Fähigkeit
- Über uns
- Zugang
- gefeiert
- Nach
- über
- berührt das Schneidwerkzeug
- angesprochen
- advanced
- Nach der
- aggressiv
- voraus
- AI
- Algorithmen
- Alle
- erlaubt
- bereits
- ebenfalls
- immer
- am
- an
- Analytisch
- Analytik
- und
- angekündigt
- Ein anderer
- genehmigen
- ca.
- Arcane
- SIND
- Bereiche
- Kunst
- Artikel
- AS
- At
- Teilnehmer
- keiner
- verfassten
- verfügbar
- Auszeichnungen
- ein Weg
- Hintergrund
- Baseline
- BE
- weil
- war
- Bevor
- Glauben
- Bestsellerautor
- Besser
- buchen
- Brot
- Break
- Bruch
- Geschäft
- Geschäftsführer
- aber
- Kaufe
- by
- rufen Sie uns an!
- namens
- CAN
- capability
- bestechend
- Herausforderungen
- Übernehmen
- berechnen
- Wahl
- klicken Sie auf
- Auftraggeber
- Kälte
- zusammenarbeiten
- Zusammenarbeit
- Columbia
- COM
- wie die
- kommt
- häufig
- community
- Unternehmen
- Unternehmen
- conception
- Beton
- durchgeführt
- Konferenz
- besteht
- Beratung
- Berater
- kontextuelle
- ständig
- Beitrag
- Unternehmen
- Kurs
- Kurse
- Abdeckung
- Abdeckung
- Kreativ
- cs
- KULTUR
- technische Daten
- Data Mining
- Datenwissenschaft
- Datenwissenschaftler
- Entscheidungsträger
- Entscheidungen
- tief
- Übergeben
- liefern
- einsetzen
- Einsatz
- Einsatz
- Implementierungen
- Detail
- detailliert
- entwickeln
- entwickelt
- getrennt
- do
- die
- Don
- Nicht
- empfohlen
- nach unten
- Fahren
- im
- jeder
- Herausgeber
- Effektiv
- Wirksamkeit
- ermöglichen
- Ende
- End-to-End
- endemisch
- zu steigern,
- genug
- eric
- insbesondere
- essential
- Wesentliche
- Festlegung
- Äther (ETH)
- Auswerten
- Sogar
- Jedes
- Beispiel
- Ausführung
- Exekutive
- vorhandenen
- erwartet
- Tatsache
- Faktoren
- FAIL
- Scheitern
- weit
- Feet
- wenige
- Feld
- folgen
- Aussichten für
- Zwingen
- Früher
- Gründer
- Unser Ansatz
- Frei
- frei
- freundlich
- für
- Zukunft
- gewonnen
- Allgemeines
- allgemein
- bekommen
- bekommen
- Ziele
- groß
- Los
- Haben
- he
- Statt
- Hilfe
- ihm
- seine
- Ultraschall
- HTML
- http
- HTTPS
- Hype
- i
- IBM
- wichtig
- zu unterstützen,
- Verbesserung
- in
- Anfang
- Einschließlich
- Aufnahme
- Energiegewinnung
- branchenführend
- Initiative
- Initiativen
- Einblicke
- beabsichtigt
- in
- einführen
- isn
- IT
- SEINE
- nur
- nur einer
- Karl
- KDnuggets
- Wesentliche
- Keynote
- Art
- Wissen
- Wissen
- fehlt
- höchste
- Nachname
- Letztes Jahr
- führen
- Führung
- Leadership
- führenden
- lernen
- Lüge
- Gefällt mir
- Liste
- ll
- Verliert
- verloren
- Maschine
- Maschinelles Lernen
- Main
- um
- MACHT
- Making
- Manager
- Manager
- Weise
- viele
- Mastering
- bedeuten
- gemeint
- messen
- gemessen
- Metrik
- Bergbau
- MIT
- ML
- Modell
- für
- mehr
- vor allem warme
- meist
- viel
- mehrere
- sollen
- my
- Need
- Bedürfnisse
- Neu
- News
- nicht
- jetzt an
- of
- vorgenommen,
- on
- EINEM
- Einsen
- einzige
- Betriebs-
- Einkauf & Prozesse
- or
- Auftrag
- Organisation
- Pakete
- Seite
- Teil
- teilnehmen
- Wracks
- Perfektion
- Leistung
- führt
- person
- Perspektive
- geplant
- Plato
- Datenintelligenz von Plato
- PlatoData
- Stecker
- Beliebt
- Position
- positiv
- Potenzial
- Werkzeuge
- Praxis
- bestellen
- Kostbar
- genau
- vorhersagen
- Prognosen
- sagt voraus,
- vorgeführt
- Präsident
- Druck
- ziemlich
- Prozessdefinierung
- anpassen
- Produkt
- Profis
- Professor
- Projekt
- Projekte
- versprochen
- Belegen
- zuverlässig
- Publikationen
- Veröffentlicht
- Zweck
- Versetzt
- Putting
- Frage
- Fragen
- Rampe
- Rampe
- Rang
- RARE
- Honorar
- Verhältnis
- erreichen
- realisiert
- erkennen
- bleibt bestehen
- Meldungen
- Befragte
- Die Ergebnisse
- Rückgabe
- Einnahmen
- Revolutionär
- Recht
- steinig
- ROI
- regelmäßig
- Führen Sie
- s
- Safe
- Said
- gleich
- Skalieren
- Schule
- Wissenschaft
- Wissenschaftler
- Wissenschaftler
- Modellreihe
- brauchen
- serviert
- dient
- sieben
- von Locals geführtes
- signifikant
- da
- So
- Social Media
- Software
- einige
- Speaker
- Wirbelsäule ... zu unterstützen.
- Patenschaftsprogramme
- Stufen
- Stakeholder
- Stakeholder
- Anfang
- stammt
- Immer noch
- Kämpfen
- Die Kursteilnehmer
- Erfolg
- erfolgreich
- Erfolgreich
- so
- ZUSAMMENFASSUNG
- Umfrage
- Sweep
- T
- gezielt
- Einführungen
- Technische
- Technologie
- erzählen
- AGB
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- nach drei
- während
- So
- Zeit
- zu
- Werkzeuge
- Thema
- wirklich
- XNUMX
- Letztlich
- für
- verstehen
- verständlich
- Universitäten
- Universität
- auf
- benutzt
- einleiten
- gewöhnlich
- Wert
- Ve
- sehr
- Anzeigen
- Sichtbarkeit
- lebenswichtig
- wurde
- Weg..
- Woche
- wiegen
- GUT
- Was
- wann
- welche
- während
- WHO
- warum
- Wild
- werden wir
- mit
- ohne
- Gewonnen
- Wunder
- Arbeiten
- würde
- geschrieben
- Jahr
- noch
- U
- Ihr
- Zephyrnet








