Trotz der scheinbar unaufhaltsamen Einführung von LLMs in allen Branchen sind sie eine Komponente eines umfassenderen Technologie-Ökosystems, das die neue KI-Welle antreibt. Viele Anwendungsfälle für Konversations-KI erfordern LLMs wie Llama 2, Flan T5 und Bloom, um auf Benutzeranfragen zu reagieren. Diese Modelle basieren auf parametrischem Wissen, um Fragen zu beantworten. Das Modell lernt dieses Wissen während des Trainings und kodiert es in die Modellparameter. Um dieses Wissen auf den neuesten Stand zu bringen, müssen wir den LLM umschulen, was viel Zeit und Geld kostet.
Glücklicherweise können wir auch Quellenwissen nutzen, um unsere LLMs zu informieren. Quellenwissen sind Informationen, die über eine Eingabeaufforderung in das LLM eingespeist werden. Ein beliebter Ansatz zur Bereitstellung von Quellenwissen ist Retrieval Augmented Generation (RAG). Mithilfe von RAG rufen wir relevante Informationen aus einer externen Datenquelle ab und speisen diese Informationen in das LLM ein.
In diesem Blogbeitrag untersuchen wir, wie wir LLMs wie Llama-2 mit Amazon Sagemaker JumpStart bereitstellen und unsere LLMs durch Retrieval Augmented Generation (RAG) mithilfe der Pinecone-Vektordatenbank mit relevanten Informationen auf dem neuesten Stand halten, um KI-Halluzinationen zu verhindern .
Retrieval Augmented Generation (RAG) in Amazon SageMaker
Pinecone übernimmt die Abrufkomponente von RAG, Sie benötigen jedoch zwei weitere wichtige Komponenten: einen Ort zum Ausführen der LLM-Inferenz und einen Ort zum Ausführen des Einbettungsmodells.
Amazon SageMaker Studio ist eine integrierte Entwicklungsumgebung (IDE), die eine einzige webbasierte visuelle Schnittstelle bietet, über die Sie auf speziell entwickelte Tools zugreifen können, um die gesamte Entwicklung für maschinelles Lernen (ML) durchzuführen. Es bietet SageMaker JumpStart, einen Modell-Hub, über den Benutzer ein bestimmtes Modell in ihrem eigenen SageMaker-Konto finden, in der Vorschau anzeigen und starten können. Es bietet vorab trainierte, öffentlich verfügbare und proprietäre Modelle für eine Vielzahl von Problemtypen, einschließlich Foundation Models.
Amazon SageMaker Studio bietet die ideale Umgebung für die Entwicklung RAG-fähiger LLM-Pipelines. Gehen Sie zunächst über die AWS-Konsole zu Amazon SageMaker, erstellen Sie eine SageMaker Studio-Domäne und öffnen Sie ein Jupyter Studio-Notebook.
Voraussetzungen:
Führen Sie die folgenden erforderlichen Schritte aus:
- Richten Sie Amazon SageMaker Studio ein.
- Onboarding bei einer Amazon SageMaker-Domäne.
- Melden Sie sich für eine kostenlose Pinecone Vector Database an.
- Erforderliche Bibliotheken: SageMaker Python SDK, Pinecone Client
Lösungsdurchgang
Mit dem SageMaker Studio-Notebook müssen wir zunächst die erforderlichen Bibliotheken installieren:
Bereitstellen eines LLM
In diesem Beitrag diskutieren wir zwei Ansätze zur Bereitstellung eines LLM. Der erste ist durch die HuggingFaceModel Objekt. Sie können dies verwenden, wenn Sie LLMs (und Einbettungsmodelle) direkt über den Hugging Face-Modell-Hub bereitstellen.
Sie können beispielsweise eine bereitstellbare Konfiguration für erstellen google/flan-t5-xl Modell, wie im folgenden Screenshot gezeigt:
Wenn Sie Modelle direkt aus Hugging Face bereitstellen, initialisieren Sie das my_model_configuration mit den folgenden:
- An
envconfig sagt uns, welches Modell wir für welche Aufgabe verwenden möchten. - Unsere SageMaker-Ausführung
rolegibt uns die Berechtigung, unser Modell bereitzustellen. - An
image_uriist eine Image-Konfiguration speziell für die Bereitstellung von LLMs von Hugging Face.
Alternativ verfügt SageMaker über eine Reihe von Modellen, die direkt mit einem einfacheren Modell kompatibel sind JumpStartModel Objekt. Viele beliebte LLMs wie Llama 2 werden von diesem Modell unterstützt, das wie im folgenden Screenshot gezeigt initialisiert werden kann:
Für beide Versionen von my_model, stellen Sie sie wie im folgenden Screenshot gezeigt bereit:
Mit unserem initialisierten LLM-Endpunkt können Sie mit der Abfrage beginnen. Das Format unserer Abfragen kann variieren (insbesondere zwischen Konversations- und Nicht-Konversations-LLMs), aber der Prozess ist im Allgemeinen derselbe. Gehen Sie für das Hugging Face-Modell wie folgt vor:
Die Lösung finden Sie im GitHub-Repository.
Die generierte Antwort, die wir hier erhalten, ergibt nicht viel Sinn – es ist eine Halluzination.
Bereitstellung zusätzlichen Kontexts für LLM
Llama 2 versucht, unsere Frage ausschließlich auf der Grundlage interner parametrischer Kenntnisse zu beantworten. Offensichtlich speichern die Modellparameter kein Wissen darüber, welche Instanzen wir mit verwaltetem Spot-Training in SageMaker erreichen können.
Um diese Frage richtig zu beantworten, müssen wir Quellenwissen nutzen. Das heißt, wir geben dem LLM über die Eingabeaufforderung zusätzliche Informationen. Fügen wir diese Informationen direkt als zusätzlichen Kontext für das Modell hinzu.
Wir sehen nun die richtige Antwort auf die Frage; das war einfach! Es ist jedoch unwahrscheinlich, dass ein Benutzer Kontexte in seine Eingabeaufforderungen einfügt, da er die Antwort auf seine Frage bereits kennt.
Anstatt manuell einen einzelnen Kontext einzufügen, identifizieren Sie relevante Informationen automatisch aus einer umfangreicheren Informationsdatenbank. Dafür benötigen Sie Retrieval Augmented Generation.
Augmented Generation abrufen
Mit Retrieval Augmented Generation können Sie eine Informationsdatenbank in einen Vektorraum kodieren, in dem die Nähe zwischen Vektoren ihre Relevanz/semantische Ähnlichkeit darstellt. Mit diesem Vektorraum als Wissensbasis können Sie eine neue Benutzerabfrage konvertieren, sie in denselben Vektorraum kodieren und die relevantesten zuvor indizierten Datensätze abrufen.
Nachdem Sie diese relevanten Datensätze abgerufen haben, wählen Sie einige davon aus und fügen Sie sie als zusätzlichen Kontext in die LLM-Eingabeaufforderung ein, um dem LLM hochrelevantes Quellenwissen bereitzustellen. Dies ist ein zweistufiger Prozess, bei dem:
- Durch die Indizierung wird der Vektorindex mit Informationen aus einem Datensatz gefüllt.
- Der Abruf erfolgt während einer Abfrage und ist der Zeitpunkt, an dem wir relevante Informationen aus dem Vektorindex abrufen.
Für beide Schritte ist ein Einbettungsmodell erforderlich, um unseren für Menschen lesbaren Klartext in einen semantischen Vektorraum zu übersetzen. Verwenden Sie den hocheffizienten MiniLM-Satztransformator von Hugging Face, wie im folgenden Screenshot gezeigt. Dieses Modell ist kein LLM und wird daher nicht auf die gleiche Weise initialisiert wie unser Llama 2-Modell.
Im hub_config, geben Sie die Modell-ID an, wie im Screenshot oben gezeigt, aber verwenden Sie für die Aufgabe die Feature-Extraktion, da wir Vektoreinbettungen und keinen Text wie unser LLM generieren. Anschließend initialisieren Sie die Modellkonfiguration mit HuggingFaceModel wie zuvor, dieses Mal jedoch ohne das LLM-Image und mit einigen Versionsparametern.
Sie können das Modell mit erneut bereitstellen deploy, unter Verwendung der kleineren (nur CPU) Instanz von ml.t2.large. Das MiniLM-Modell ist winzig, benötigt also nicht viel Speicher und benötigt keine GPU, da es selbst auf einer CPU schnell Einbettungen erstellen kann. Bei Bedarf können Sie das Modell schneller auf der GPU ausführen.
Um Einbettungen zu erstellen, verwenden Sie die predict Methode und übergeben Sie eine Liste von Kontexten, die über die codiert werden sollen inputs Schlüssel wie abgebildet:
Es werden zwei Eingabekontexte übergeben, die wie gezeigt zwei Kontextvektoreinbettungen zurückgeben:
len(out)
2
Die Einbettungsdimensionalität des MiniLM-Modells ist 384 Das bedeutet, dass jeder Vektor, der MiniLM-Ausgaben einbettet, eine Dimensionalität von haben sollte 384. Wenn Sie sich jedoch die Länge unserer Einbettungen ansehen, werden Sie Folgendes sehen:
len(out[0]), len(out[1])
(8, 8)
Zwei Listen enthalten jeweils acht Elemente. MiniLM verarbeitet zunächst Text in einem Tokenisierungsschritt. Diese Tokenisierung wandelt unseren für Menschen lesbaren Klartext in eine Liste modelllesbarer Token-IDs um. In den Ausgabefunktionen des Modells können Sie die Einbettungen auf Token-Ebene sehen. Eine dieser Einbettungen zeigt die erwartete Dimensionalität von 384 wie gezeigt:
len(out[0][0])
384
Transformieren Sie diese Einbettungen auf Token-Ebene in Einbettungen auf Dokumentebene, indem Sie die Mittelwerte für jede Vektordimension verwenden, wie in der folgenden Abbildung dargestellt.
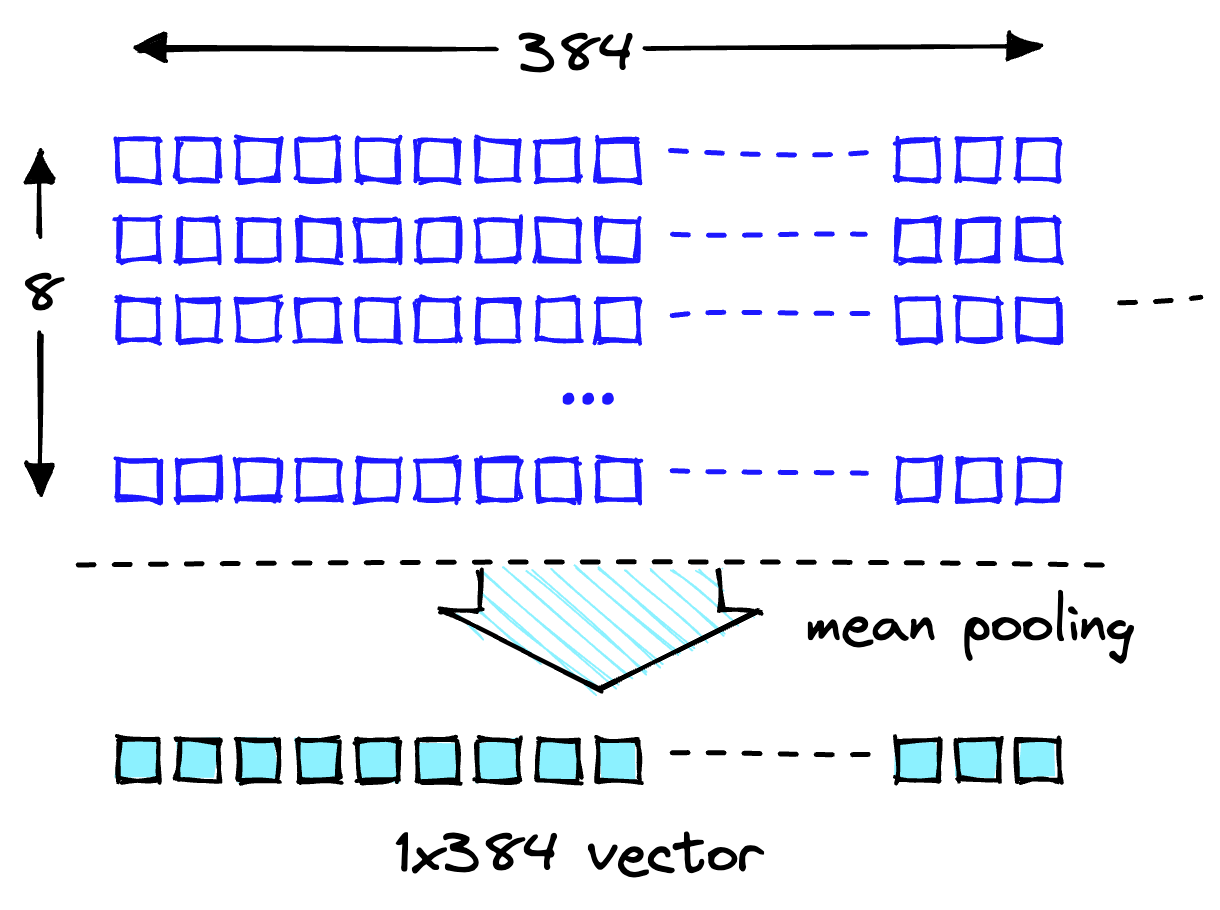
Mittlere Pooling-Operation, um einen einzelnen 384-dimensionalen Vektor zu erhalten.
Mit zwei 384-dimensionalen Vektoreinbettungen, eine für jeden Eingabetext. Um uns das Leben zu erleichtern, packen Sie den Codierungsprozess in eine einzige Funktion ein, wie im folgenden Screenshot gezeigt:
Herunterladen des Datensatzes
Laden Sie die Amazon SageMaker-FAQs als Wissensdatenbank herunter, um die Daten zu erhalten, die sowohl Frage- als auch Antwortspalten enthalten.

Laden Sie die Amazon SageMaker-FAQs herunter
Suchen Sie bei der Suche nur nach Antworten, sodass Sie die Spalte „Frage“ weglassen können. Einzelheiten finden Sie im Notizbuch.
Unser Datensatz und die Einbettungspipeline sind fertig. Jetzt brauchen wir nur noch einen Ort, an dem wir diese Einbettungen speichern können.
Indizierung
Die Pinecone-Vektordatenbank speichert Vektoreinbettungen und durchsucht sie effizient im großen Maßstab. Um eine Datenbank zu erstellen, benötigen Sie einen kostenlosen API-Schlüssel von Pinecone.
Nachdem Sie eine Verbindung zur Pinecone-Vektordatenbank hergestellt haben, erstellen Sie einen einzelnen Vektorindex (ähnlich einer Tabelle in herkömmlichen DBs). Benennen Sie den Index retrieval-augmentation-aws und richten Sie den Index aus dimension und metric Parameter mit denen, die vom Einbettungsmodell (in diesem Fall MiniLM) benötigt werden.
Führen Sie Folgendes aus, um mit dem Einfügen von Daten zu beginnen:
Sie können mit der Abfrage des Index mit der Frage von früher in diesem Beitrag beginnen.
Die obige Ausgabe zeigt, dass wir relevante Kontexte zurückgeben, die uns bei der Beantwortung unserer Frage helfen. Seit wir top_k = 1, index.query hat das Top-Ergebnis zusammen mit den Metadaten zurückgegeben, die gelesen werden Managed Spot Training can be used with all instances supported in Amazon.
Erweiterung der Eingabeaufforderung
Verwenden Sie die abgerufenen Kontexte, um die Eingabeaufforderung zu erweitern und festzulegen, wie viel Kontext maximal in das LLM eingespeist werden soll. Benutzen Sie die 1000 Begrenzen Sie die Anzahl der Zeichen, um jeden zurückgegebenen Kontext iterativ zur Eingabeaufforderung hinzuzufügen, bis Sie die Inhaltslänge überschreiten.
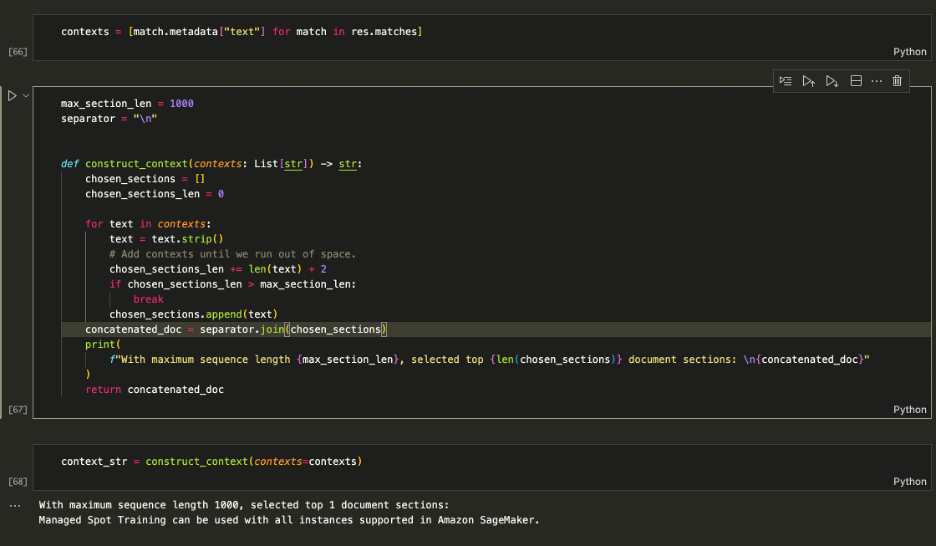
Erweiterung der Eingabeaufforderung
Füttere die context_str in die LLM-Eingabeaufforderung ein, wie im folgenden Screenshot gezeigt:
[Eingabe]: Welche Instanzen kann ich mit Managed Spot Training in SageMaker verwenden? [Ausgabe]: Basierend auf dem bereitgestellten Kontext können Sie Managed Spot Training mit allen in Amazon SageMaker unterstützten Instanzen verwenden. Daher lautet die Antwort: Alle in Amazon SageMaker unterstützten Instanzen.
Die Logik funktioniert, also fassen Sie sie in eine einzige Funktion zusammen, um alles sauber zu halten.
Sie können jetzt Fragen wie die im Folgenden gezeigten stellen:
Aufräumen
Um unerwünschte Gebühren zu vermeiden, löschen Sie das Modell und den Endpunkt.
Zusammenfassung
In diesem Beitrag haben wir Ihnen RAG mit Open-Access-LLMs auf SageMaker vorgestellt. Wir haben auch gezeigt, wie man Amazon SageMaker Jumpstart-Modelle mit Llama 2, Hugging Face LLMs mit Flan T5 und das Einbetten von Modellen mit MiniLM bereitstellt.
Wir haben mithilfe unserer Open-Access-Modelle und eines Pinecone-Vektorindex eine vollständige End-to-End-RAG-Pipeline implementiert. Auf diese Weise haben wir gezeigt, wie wir Halluzinationen minimieren, das LLM-Wissen auf dem neuesten Stand halten und letztendlich das Benutzererlebnis und das Vertrauen in unsere Systeme verbessern können.
Um dieses Beispiel selbst auszuführen, klonen Sie dieses GitHub-Repository und führen Sie die vorherigen Schritte mithilfe von durch Frage-Antwort-Notizbuch auf GitHub.
Über die Autoren
 Vedant Jain ist Senior AI/ML-Spezialist und arbeitet an strategischen generativen KI-Initiativen. Bevor er zu AWS kam, hatte Vedant Positionen im Bereich ML/Data Science Specialty bei verschiedenen Unternehmen inne, darunter Databricks, Hortonworks (jetzt Cloudera) und JP Morgan Chase. Außerhalb seiner Arbeit beschäftigt sich Vedant leidenschaftlich gerne mit Musik, Klettern, der Nutzung der Wissenschaft für ein sinnvolles Leben und der Erkundung von Küchen aus aller Welt.
Vedant Jain ist Senior AI/ML-Spezialist und arbeitet an strategischen generativen KI-Initiativen. Bevor er zu AWS kam, hatte Vedant Positionen im Bereich ML/Data Science Specialty bei verschiedenen Unternehmen inne, darunter Databricks, Hortonworks (jetzt Cloudera) und JP Morgan Chase. Außerhalb seiner Arbeit beschäftigt sich Vedant leidenschaftlich gerne mit Musik, Klettern, der Nutzung der Wissenschaft für ein sinnvolles Leben und der Erkundung von Küchen aus aller Welt.
 James Briggs ist Staff Developer Advocate bei Pinecone und auf Vektorsuche und KI/ML spezialisiert. Er unterstützt Entwickler und Unternehmen bei der Entwicklung ihrer eigenen GenAI-Lösungen durch Online-Schulung. Vor seiner Zeit bei Pinecone arbeitete James im Bereich KI für kleine Technologie-Startups bis hin zu etablierten Finanzunternehmen. Außerhalb der Arbeit liebt James das Reisen und neue Abenteuer, von Surfen und Tauchen bis hin zu Muay Thai und BJJ.
James Briggs ist Staff Developer Advocate bei Pinecone und auf Vektorsuche und KI/ML spezialisiert. Er unterstützt Entwickler und Unternehmen bei der Entwicklung ihrer eigenen GenAI-Lösungen durch Online-Schulung. Vor seiner Zeit bei Pinecone arbeitete James im Bereich KI für kleine Technologie-Startups bis hin zu etablierten Finanzunternehmen. Außerhalb der Arbeit liebt James das Reisen und neue Abenteuer, von Surfen und Tauchen bis hin zu Muay Thai und BJJ.
 Xin Huang ist Senior Applied Scientist für Amazon SageMaker JumpStart und die integrierten Algorithmen von Amazon SageMaker. Er konzentriert sich auf die Entwicklung skalierbarer Algorithmen für maschinelles Lernen. Seine Forschungsinteressen liegen im Bereich der Verarbeitung natürlicher Sprache, erklärbares Deep Learning auf tabellarischen Daten und robuste Analyse von nichtparametrischem Raum-Zeit-Clustering. Er hat viele Artikel auf ACL-, ICDM-, KDD-Konferenzen und der Royal Statistical Society: Series A veröffentlicht.
Xin Huang ist Senior Applied Scientist für Amazon SageMaker JumpStart und die integrierten Algorithmen von Amazon SageMaker. Er konzentriert sich auf die Entwicklung skalierbarer Algorithmen für maschinelles Lernen. Seine Forschungsinteressen liegen im Bereich der Verarbeitung natürlicher Sprache, erklärbares Deep Learning auf tabellarischen Daten und robuste Analyse von nichtparametrischem Raum-Zeit-Clustering. Er hat viele Artikel auf ACL-, ICDM-, KDD-Konferenzen und der Royal Statistical Society: Series A veröffentlicht.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/mitigate-hallucinations-through-retrieval-augmented-generation-using-pinecone-vector-database-llama-2-from-amazon-sagemaker-jumpstart/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 16
- 17
- 19
- 23
- 32
- 7
- 8
- 9
- 90
- a
- Über Uns
- oben
- Zugang
- Nach
- Konto
- über
- hinzufügen
- Zusätzliche
- Zusätzliche Angaben
- Adoption
- Abenteuer
- Anwalt
- aufs Neue
- AI
- KI-Anwendungsfälle
- AI / ML
- Algorithmen
- ausrichten
- Alle
- entlang
- bereits
- ebenfalls
- Amazon
- Amazon Sage Maker
- Amazon SageMaker-JumpStart
- Amazon SageMaker-Studio
- Amazon Web Services
- Betrag
- an
- Analyse
- und
- beantworten
- Antworten
- jedem
- Bienen
- App
- angewandt
- Ansatz
- Ansätze
- SIND
- Bereich
- um
- AS
- fragen
- At
- Versuche
- vermehren
- Augmented
- Auto
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- AWS
- Base
- basierend
- BE
- weil
- Bevor
- beginnen
- zwischen
- Blog
- Blühen
- beide
- breiteres
- bauen
- eingebaut
- Unternehmen
- aber
- by
- CAN
- Erfassung
- Häuser
- Fälle
- Zeichen
- Gebühren
- Verfolgungsjagd
- reinigen
- Klettern
- Cloudera
- Clustering
- Kolonne
- Spalten
- Unternehmen
- kompatibel
- abschließen
- Komponente
- Komponenten
- Kongressbegleitung
- Sie
- Konsul (Console)
- enthalten
- enthält
- Inhalt
- Kontext
- Kontexte
- Konversations
- Konversations-KI
- verkaufen
- Konzerne
- und beseitigen Muskelschwäche
- korrekt
- CPU
- erstellen
- kritischem
- Zur Zeit
- technische Daten
- Datenbase
- Databricks
- Datum
- DBS
- entscheidet
- tief
- tiefe Lernen
- einsetzen
- Bereitstellen
- Entwickler:in / Unternehmen
- Entwickler
- Entwicklung
- Entwicklung
- Abmessungen
- Direkt
- diskutieren
- do
- die
- doesn
- Tut nicht
- Domain
- Don
- Drop
- im
- jeder
- Früher
- einfacher
- Ökosystem
- Bildungswesen
- effizient
- effizient
- Einbettung
- umarmen
- Codierung
- Ende
- End-to-End
- Endpunkt
- zu steigern,
- Arbeitsumfeld
- etablierten
- Äther (ETH)
- Sogar
- Beispiel
- überschreiten
- Ausführung
- erwartet
- ERFAHRUNGEN
- ERKUNDEN
- Möglichkeiten sondieren
- umfangreiche
- extern
- Extrakt
- Gesicht
- beschleunigt
- Eigenschaften
- Fed
- wenige
- Finanzen
- Finden Sie
- Fertig
- Vorname
- Schwimmer
- konzentriert
- Folgende
- Aussichten für
- Format
- Foundation
- Frei
- für
- Funktion
- allgemein
- erzeugt
- Erzeugung
- Generation
- generativ
- Generative KI
- bekommen
- GitHub
- ABSICHT
- gegeben
- gibt
- Go
- Goes
- GPU
- Anleitungen
- Griff
- das passiert
- Haben
- he
- Statt
- Hilfe
- hier
- hoch
- seine
- Ultraschall
- Hilfe
- aber
- HTTPS
- Huang
- Nabe
- Umarmendes Gesicht
- für Menschen lesbar
- i
- IAM
- ID
- ideal
- identifizieren
- ids
- if
- Image
- umgesetzt
- importieren
- in
- das
- Einschließlich
- Erhöhung
- Index
- indiziert
- Branchen
- informieren
- Information
- Initiativen
- Varianten des Eingangssignals:
- Eingänge
- installieren
- Instanz
- Instanzen
- integriert
- Interessen
- Schnittstelle
- intern
- in
- eingeführt
- IT
- Artikel
- Jakob
- Beitritt
- JP Morgan
- JP Morgan Chase
- jpg
- Behalten
- Wesentliche
- Wissen
- Wissen
- Sprache
- grosse
- größer
- starten
- führen
- lernen
- Länge
- Bibliotheken
- Lebensdauer
- Gefällt mir
- LIMIT
- Liste
- Listen
- Leben
- Lama
- Logik
- aussehen
- suchen
- Los
- Maschine
- Maschinelles Lernen
- um
- Making
- verwaltet
- manuell
- viele
- Spiel
- Streichhölzer
- maximal
- Höchstbetrag
- Kann..
- bedeuten
- sinnvoll
- Mittel
- Memory
- Metadaten
- Methode
- minimieren
- Mildern
- ML
- Modell
- für
- Geld
- mehr
- Morgan
- vor allem warme
- viel
- mehrere
- Musik
- sollen
- Name
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Need
- Bedürfnisse
- Neu
- weiter
- Nlp
- Notizbuch
- jetzt an
- numpig
- Objekt
- of
- on
- EINEM
- Online
- Online-Bildung
- einzige
- XNUMXh geöffnet
- Betrieb
- or
- Auftrag
- OS
- Andernfalls
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- Ausgänge
- aussen
- besitzen
- Papiere
- Parameter
- besondere
- besonders
- passieren
- Bestanden
- Leidenschaft & KREATIVITÄT
- leidenschaftlich
- ausführen
- Durchführung
- Berechtigungen
- ein Bild
- Pipeline
- Ebene
- Plato
- Datenintelligenz von Plato
- PlatoData
- Beliebt
- für einige Positionen
- Post
- Powering
- Prognose
- Prognosen
- Predictor
- bevorzugt
- verhindern
- Vorspann
- früher
- vorher
- Vor
- Aufgabenstellung:
- Prozessdefinierung
- anpassen
- Verarbeitung
- Profil
- Eingabeaufforderungen
- Eigentums-
- vorausgesetzt
- bietet
- Bereitstellung
- öffentlich
- veröffentlicht
- Python
- Pytorch
- Abfragen
- Frage
- Fragen
- schnell
- Angebot
- Bereich
- bereit
- Empfang
- Aufzeichnungen
- Regionen
- relevant
- verlassen
- Quelle
- representiert
- erfordern
- falls angefordert
- Forschungsprojekte
- Reagieren
- Folge
- Die Ergebnisse
- Rückkehr
- Rückkehr
- robust
- Rock
- Rollen
- königlich
- Führen Sie
- läuft
- sagemaker
- gleich
- skalierbaren
- Skalieren
- Wissenschaft
- Wissenschaftler
- Ergebnis
- Bildschirm
- Sdk
- Suche
- Suchbegriffe
- sehen
- wählen
- Senior
- Sinn
- Satz
- Modellreihe
- Serie A
- Lösungen
- kompensieren
- sollte
- erklären
- zeigte
- gezeigt
- Konzerte
- Seite
- ähnlich
- da
- Single
- Größe
- klein
- kleinere
- So
- Gesellschaft
- allein
- Lösung
- Lösungen
- einige
- irgendwo
- Quelle
- Raumfahrt
- Spezialist
- spezialisieren
- Spezialprodukte
- speziell
- Spot
- Unser Team
- Startups
- statistisch
- Schritt
- Shritte
- Stoppen
- speichern
- Läden
- Strategisch
- Schnur
- Studio Adressen
- so
- Support
- Unterstützte
- Unterstützt
- System
- Systeme und Techniken
- T
- Tabelle
- nimmt
- Aufgabe
- Tech
- Tech-Start-ups
- Technologie
- erzählt
- Text
- thailändisch
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Gegend
- die Welt
- ihr
- Sie
- deswegen
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- Durch
- Zeit
- zu
- Zeichen
- Tokenisierung
- auch
- Werkzeuge
- Top
- traditionell
- Ausbildung
- Transformator
- Transformer
- Transformationen
- Übersetzen
- Reise
- Vertrauen
- XNUMX
- Typen
- Letztlich
- unwahrscheinlich
- nicht zu stoppen.
- bis
- unerwünscht
- Aktualisierung
- URI
- us
- -
- benutzt
- Mitglied
- Benutzererfahrung
- Nutzer
- Verwendung von
- Werte
- verschiedene
- Version
- visuell
- warten
- Walkthrough
- wollen
- wurde
- Wave
- Weg..
- we
- Netz
- Web-Services
- Webbasiert
- Was
- wann
- welche
- während
- breit
- Große Auswahl
- werden wir
- mit
- ohne
- Arbeiten
- gearbeitet
- arbeiten,
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- würde
- wickeln
- X
- ja
- U
- Ihr
- Zephyrnet