OpenAI-Flüstern ist ein fortschrittliches automatisches Spracherkennungsmodell (ASR) mit einer MIT-Lizenz. Die ASR-Technologie findet Anwendung bei Transkriptionsdiensten, Sprachassistenten und der Verbesserung der Zugänglichkeit für Menschen mit Hörbehinderungen. Dieses hochmoderne Modell basiert auf einem umfangreichen und vielfältigen Datensatz mehrsprachiger und multitaskingüberwachter Daten, die aus dem Internet gesammelt werden. Seine hohe Genauigkeit und Anpassungsfähigkeit machen es zu einem wertvollen Hilfsmittel für eine Vielzahl sprachbezogener Aufgaben.
In der sich ständig weiterentwickelnden Landschaft des maschinellen Lernens und der künstlichen Intelligenz Amazon Sage Maker bietet ein umfassendes Ökosystem. SageMaker ermöglicht Datenwissenschaftlern, Entwicklern und Organisationen die Entwicklung, Schulung, Bereitstellung und Verwaltung von Modellen für maschinelles Lernen in großem Maßstab. Es bietet eine breite Palette an Tools und Funktionen und vereinfacht den gesamten maschinellen Lernworkflow, von der Datenvorverarbeitung und Modellentwicklung bis hin zur mühelosen Bereitstellung und Überwachung. Die benutzerfreundliche Oberfläche von SageMaker macht es zu einer zentralen Plattform zur Erschließung des vollen Potenzials der KI und etabliert sie als bahnbrechende Lösung im Bereich der künstlichen Intelligenz.
In diesem Beitrag begeben wir uns auf eine Erkundung der Fähigkeiten von SageMaker und konzentrieren uns dabei insbesondere auf das Hosten von Whisper-Modellen. Wir werden uns dabei eingehend mit zwei Methoden befassen: eine unter Verwendung des Whisper-PyTorch-Modells und die andere unter Verwendung der Hugging-Face-Implementierung des Whisper-Modells. Darüber hinaus werden wir die Inferenzoptionen von SageMaker eingehend untersuchen und sie anhand von Parametern wie Geschwindigkeit, Kosten, Nutzlastgröße und Skalierbarkeit vergleichen. Diese Analyse ermöglicht es Benutzern, fundierte Entscheidungen zu treffen, wenn sie Whisper-Modelle in ihre spezifischen Anwendungsfälle und Systeme integrieren.
Lösungsüberblick
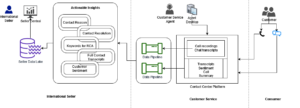
Das folgende Diagramm zeigt die Hauptkomponenten dieser Lösung.
- Um das Modell auf Amazon SageMaker zu hosten, besteht der erste Schritt darin, die Modellartefakte zu speichern. Diese Artefakte beziehen sich auf die wesentlichen Komponenten eines maschinellen Lernmodells, die für verschiedene Anwendungen, einschließlich Bereitstellung und Umschulung, benötigt werden. Sie können Modellparameter, Konfigurationsdateien, Vorverarbeitungskomponenten sowie Metadaten wie Versionsdetails, Urheberschaft und alle Hinweise zur Leistung umfassen. Es ist wichtig zu beachten, dass Whisper-Modelle für PyTorch- und Hugging Face-Implementierungen aus unterschiedlichen Modellartefakten bestehen.
- Als Nächstes erstellen wir benutzerdefinierte Inferenzskripte. Innerhalb dieser Skripte definieren wir, wie das Modell geladen werden soll und legen den Inferenzprozess fest. Hier können wir bei Bedarf auch benutzerdefinierte Parameter integrieren. Darüber hinaus können Sie die erforderlichen Python-Pakete in einem auflisten
requirements.txtDatei. Während der Bereitstellung des Modells werden diese Python-Pakete automatisch in der Initialisierungsphase installiert. - Dann wählen wir entweder die Deep-Learning-Container (DLC) PyTorch oder Hugging Face aus, die von bereitgestellt und verwaltet werden AWS. Bei diesen Containern handelt es sich um vorgefertigte Docker-Images mit Deep-Learning-Frameworks und anderen notwendigen Python-Paketen. Weitere Informationen finden Sie hier Link.
- Mit den Modellartefakten, benutzerdefinierten Inferenzskripten und ausgewählten DLCs erstellen wir Amazon SageMaker-Modelle für PyTorch bzw. Hugging Face.
- Schließlich können die Modelle auf SageMaker bereitgestellt und mit den folgenden Optionen verwendet werden: Echtzeit-Inferenzendpunkte, Batch-Transformationsjobs und asynchrone Inferenzendpunkte. Wir werden später in diesem Beitrag ausführlicher auf diese Optionen eingehen.
Das Beispielnotizbuch und der Code für diese Lösung sind hier verfügbar GitHub-Repository.
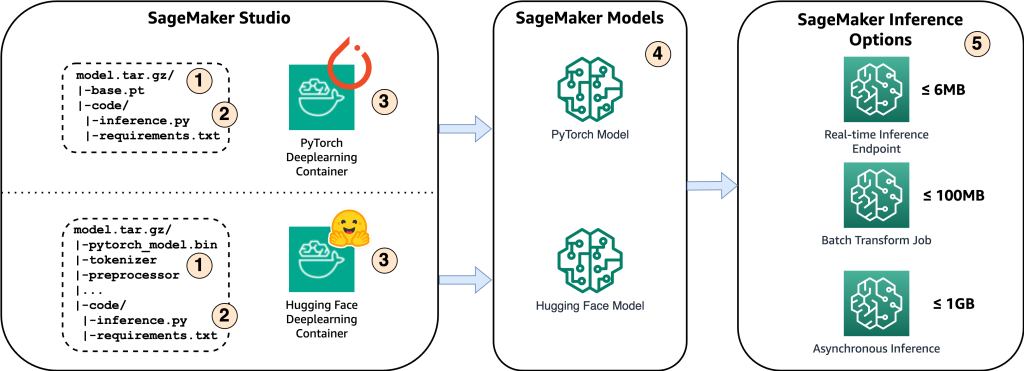
Abbildung 1. Übersicht über die wichtigsten Lösungskomponenten
Lösungsweg
Hosten des Whisper-Modells auf Amazon SageMaker
In diesem Abschnitt erklären wir die Schritte zum Hosten des Whisper-Modells auf Amazon SageMaker unter Verwendung von PyTorch bzw. Hugging Face Frameworks. Um mit dieser Lösung zu experimentieren, benötigen Sie ein AWS-Konto und Zugriff auf den Amazon SageMaker-Dienst.
PyTorch-Framework
- Speichern Sie Modellartefakte
Die erste Option zum Hosten des Modells ist die Verwendung von Offizielles Whisper-Python-Paket, die mit installiert werden kann pip install openai-whisper. Dieses Paket stellt ein PyTorch-Modell bereit. Beim Speichern von Modellartefakten im lokalen Repository besteht der erste Schritt darin, die lernbaren Parameter des Modells, wie z. B. Modellgewichte und Bias jeder Schicht im neuronalen Netzwerk, als „pt“-Datei zu speichern. Sie können aus verschiedenen Modellgrößen wählen, darunter „winzig“, „Basis“, „klein“, „mittel“ und „groß“. Größere Modellgrößen bieten eine höhere Genauigkeitsleistung, gehen jedoch mit einer längeren Inferenzlatenz einher. Darüber hinaus müssen Sie das Modellzustandswörterbuch und das Dimensionswörterbuch speichern, die ein Python-Wörterbuch enthalten, das jede Ebene oder jeden Parameter des PyTorch-Modells zusammen mit anderen Metadaten und benutzerdefinierten Konfigurationen den entsprechenden lernbaren Parametern zuordnet. Der folgende Code zeigt, wie die Whisper PyTorch-Artefakte gespeichert werden.
- Wählen Sie DLC
Der nächste Schritt besteht darin, daraus den vorgefertigten DLC auszuwählen Link. Seien Sie vorsichtig bei der Auswahl des richtigen Bildes, indem Sie die folgenden Einstellungen berücksichtigen: Framework (PyTorch), Framework-Version, Aufgabe (Inferenz), Python-Version und Hardware (d. h. GPU). Es wird empfohlen, nach Möglichkeit die neuesten Versionen des Frameworks und von Python zu verwenden, da dies zu einer besseren Leistung führt und bekannte Probleme und Fehler aus früheren Versionen behebt.
- Erstellen Sie Amazon SageMaker-Modelle
Als nächstes nutzen wir die SageMaker Python-SDK um PyTorch-Modelle zu erstellen. Es ist wichtig, beim Erstellen eines PyTorch-Modells daran zu denken, Umgebungsvariablen hinzuzufügen. Standardmäßig kann TorchServe nur Dateigrößen bis zu 6 MB verarbeiten, unabhängig vom verwendeten Inferenztyp.
Die folgende Tabelle zeigt die Einstellungen für verschiedene PyTorch-Versionen:
| Unser Ansatz | Umgebungsvariablen |
| PyTorch 1.8 (basierend auf TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (basierend auf MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definieren Sie die Modelllademethode in inference.py
Im Brauch inference.py Skript prüfen wir zunächst die Verfügbarkeit einer CUDA-fähigen GPU. Wenn eine solche GPU verfügbar ist, dann weisen wir diese zu 'cuda' Gerät zum DEVICE Variable; andernfalls weisen wir die zu 'cpu' Gerät. Dieser Schritt stellt sicher, dass das Modell für eine effiziente Berechnung auf der verfügbaren Hardware platziert wird. Wir laden das PyTorch-Modell mit dem Whisper Python-Paket.
Hugging Face-Rahmen
- Speichern Sie Modellartefakte
Die zweite Möglichkeit ist die Verwendung Das Flüstern des Hugging Face Implementierung. Das Modell kann mit geladen werden AutoModelForSpeechSeq2Seq Klasse Transformatoren. Die lernbaren Parameter werden mit dem in einer Binärdatei (bin) gespeichert save_pretrained Methode. Der Tokenizer und der Präprozessor müssen außerdem separat gespeichert werden, um sicherzustellen, dass das Hugging Face-Modell ordnungsgemäß funktioniert. Alternativ können Sie ein Modell direkt über den Hugging Face Hub auf Amazon SageMaker bereitstellen, indem Sie zwei Umgebungsvariablen festlegen: HF_MODEL_ID und HF_TASK. Weitere Informationen finden Sie hier Website.
- Wählen Sie DLC
Ähnlich wie beim PyTorch-Framework können Sie daraus einen vorgefertigten Hugging Face-DLC auswählen Link. Stellen Sie sicher, dass Sie einen DLC auswählen, der die neuesten Hugging Face-Transformatoren unterstützt und GPU-Unterstützung bietet.
- Erstellen Sie Amazon SageMaker-Modelle
Ebenso nutzen wir die SageMaker Python-SDK um Hugging Face-Modelle zu erstellen. Das Hugging Face Whisper-Modell hat eine Standardbeschränkung, bei der es nur Audiosegmente bis zu 30 Sekunden verarbeiten kann. Um diese Einschränkung zu beheben, können Sie Folgendes einschließen chunk_length_s Geben Sie beim Erstellen des Hugging Face-Modells einen Parameter in der Umgebungsvariablen ein und übergeben Sie diesen Parameter später beim Laden des Modells an das benutzerdefinierte Inferenzskript. Legen Sie abschließend die Umgebungsvariablen fest, um die Nutzlastgröße und das Antwort-Timeout für den Hugging Face-Container zu erhöhen.
| Unser Ansatz | Umgebungsvariablen |
|
HuggingFace-Inferenzcontainer (basierend auf MMS) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definieren Sie die Modelllademethode in inference.py
Beim Erstellen eines benutzerdefinierten Inferenzskripts für das Hugging Face-Modell verwenden wir eine Pipeline, die es uns ermöglicht, das zu übergeben chunk_length_s als Parameter. Dieser Parameter ermöglicht es dem Modell, lange Audiodateien während der Inferenz effizient zu verarbeiten.
Erkunden verschiedener Inferenzoptionen auf Amazon SageMaker
Die Schritte zum Auswählen von Inferenzoptionen sind für die Modelle PyTorch und Hugging Face gleich, sodass wir im Folgenden nicht zwischen ihnen unterscheiden. Es ist jedoch erwähnenswert, dass zum Zeitpunkt des Verfassens dieses Beitrags die Serverlose Schlussfolgerung Die Option von SageMaker unterstützt keine GPUs und daher schließen wir diese Option für diesen Anwendungsfall aus.
Wir können das Modell als Echtzeit-Endpunkt bereitstellen und Antworten in Millisekunden bereitstellen. Es ist jedoch wichtig zu beachten, dass diese Option auf die Verarbeitung von Eingaben unter 6 MB beschränkt ist. Wir definieren den Serializer als Audio-Serializer, der für die Konvertierung der Eingabedaten in ein geeignetes Format für das bereitgestellte Modell verantwortlich ist. Wir nutzen eine GPU-Instanz zur Inferenz, was eine beschleunigte Verarbeitung von Audiodateien ermöglicht. Die Inferenzeingabe ist eine Audiodatei, die aus dem lokalen Repository stammt.
Die zweite Inferenzoption ist der Batch-Transformationsauftrag, der Eingabenutzlasten von bis zu 100 MB verarbeiten kann. Allerdings kann diese Methode einige Minuten Latenz in Anspruch nehmen. Jede Instanz kann jeweils nur eine Batch-Anfrage verarbeiten, und das Starten und Herunterfahren der Instanz dauert ebenfalls einige Minuten. Die Inferenzergebnisse werden in einem Amazon Simple Storage Service gespeichert (Amazon S3)-Bucket nach Abschluss des Batch-Transformationsauftrags.
Berücksichtigen Sie bei der Konfiguration des Batch-Transformators unbedingt Folgendes max_payload = 100 um größere Nutzlasten effektiv zu bewältigen. Die Inferenzeingabe sollte der Amazon S3-Pfad zu einer Audiodatei oder ein Amazon S3 Bucket-Ordner sein, der eine Liste von Audiodateien mit einer Größe von jeweils weniger als 100 MB enthält.
Batch Transform partitioniert die Amazon S3-Objekte in der Eingabe nach Schlüssel und ordnet Amazon S3-Objekte Instanzen zu. Wenn Sie beispielsweise über mehrere Audiodateien verfügen, verarbeitet eine Instanz möglicherweise „input1.wav“ und eine andere Instanz möglicherweise die Datei „input2.wav“, um die Skalierbarkeit zu verbessern. Mit Batch Transform können Sie konfigurieren max_concurrent_transforms um die Anzahl der HTTP-Anfragen an jeden einzelnen Transformer-Container zu erhöhen. Es ist jedoch wichtig zu beachten, dass der Wert von (max_concurrent_transforms* max_payload) darf 100 MB nicht überschreiten.
Schließlich ist Amazon SageMaker Asynchronous Inference ideal für die gleichzeitige Verarbeitung mehrerer Anfragen, bietet moderate Latenz und unterstützt Eingabenutzlasten von bis zu 1 GB. Diese Option bietet eine hervorragende Skalierbarkeit und ermöglicht die Konfiguration einer Autoscaling-Gruppe für den Endpunkt. Wenn eine Flut von Anfragen auftritt, wird automatisch hochskaliert, um den Datenverkehr zu bewältigen. Sobald alle Anfragen verarbeitet sind, wird der Endpunkt auf 0 herunterskaliert, um Kosten zu sparen.
Mithilfe asynchroner Inferenz werden die Ergebnisse automatisch in einem Amazon S3-Bucket gespeichert. Im AsyncInferenceConfigkönnen Sie Benachrichtigungen für erfolgreiche oder fehlgeschlagene Abschlüsse konfigurieren. Der Eingabepfad zeigt auf einen Amazon S3-Speicherort der Audiodatei. Weitere Einzelheiten finden Sie im Code auf GitHub.
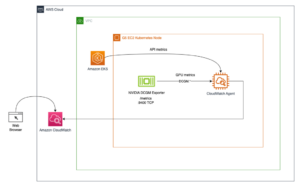
Optional: Wie bereits erwähnt, haben wir die Möglichkeit, eine Autoscaling-Gruppe für den asynchronen Inferenzendpunkt zu konfigurieren, die es ihm ermöglicht, einen plötzlichen Anstieg der Inferenzanforderungen zu bewältigen. Ein Codebeispiel finden Sie hier GitHub-Repository. Im folgenden Diagramm sehen Sie ein Liniendiagramm, das zwei Metriken von anzeigt Amazon CloudWatch: ApproximateBacklogSize und ApproximateBacklogSizePerInstance. Als 1000 Anfragen ausgelöst wurden, stand zunächst nur eine Instanz zur Verarbeitung der Inferenz zur Verfügung. Drei Minuten lang überschritt die Rückstandsgröße durchweg drei (bitte beachten Sie, dass diese Zahlen konfiguriert werden können), und die Autoscaling-Gruppe reagierte, indem sie zusätzliche Instanzen hochfuhr, um den Rückstand effizient zu beseitigen. Dies führte zu einem deutlichen Rückgang der ApproximateBacklogSizePerInstanceDadurch können Backlog-Anfragen viel schneller als in der Anfangsphase verarbeitet werden.

Abbildung 2. Liniendiagramm, das die zeitlichen Änderungen der Amazon CloudWatch-Metriken veranschaulicht
Vergleichende Analyse für die Inferenzoptionen
Die Vergleiche für verschiedene Inferenzoptionen basieren auf gängigen Anwendungsfällen der Audioverarbeitung. Echtzeit-Inferenz bietet die schnellste Inferenzgeschwindigkeit, beschränkt die Nutzlastgröße jedoch auf 6 MB. Dieser Inferenztyp eignet sich für Audiobefehlssysteme, bei denen Benutzer Geräte oder Software mithilfe von Sprachbefehlen oder gesprochenen Anweisungen steuern oder mit ihnen interagieren. Sprachbefehle sind in der Regel klein und eine geringe Inferenzlatenz ist entscheidend, um sicherzustellen, dass transkribierte Befehle sofort Folgeaktionen auslösen können. Batch Transform ist ideal für geplante Offline-Aufgaben, wenn die Größe jeder Audiodatei weniger als 100 MB beträgt und keine besonderen Anforderungen an schnelle Inferenzreaktionszeiten bestehen. Asynchrone Inferenz ermöglicht Uploads von bis zu 1 GB und bietet eine moderate Inferenzlatenz. Dieser Inferenztyp eignet sich gut zum Transkribieren von Filmen, Fernsehserien und aufgezeichneten Konferenzen, bei denen größere Audiodateien verarbeitet werden müssen.
Sowohl Echtzeit- als auch asynchrone Inferenzoptionen bieten Funktionen zur automatischen Skalierung, sodass die Endpunktinstanzen je nach Anforderungsvolumen automatisch nach oben oder unten skaliert werden können. In Fällen ohne Anfragen entfernt die automatische Skalierung unnötige Instanzen und hilft Ihnen, Kosten zu vermeiden, die mit bereitgestellten Instanzen verbunden sind, die nicht aktiv genutzt werden. Für Echtzeit-Inferenz muss jedoch mindestens eine persistente Instanz beibehalten werden, was bei kontinuierlichem Betrieb des Endpunkts zu höheren Kosten führen kann. Im Gegensatz dazu ermöglicht die asynchrone Inferenz die Reduzierung des Instanzvolumens auf 0, wenn es nicht verwendet wird. Beim Konfigurieren eines Batch-Transformationsauftrags ist es möglich, mehrere Instanzen zur Verarbeitung des Auftrags zu verwenden und max_concurrent_transforms so anzupassen, dass eine Instanz mehrere Anforderungen verarbeiten kann. Daher bieten alle drei Inferenzoptionen eine große Skalierbarkeit.
Aufräumen
Sobald Sie die Lösung vollständig genutzt haben, entfernen Sie unbedingt die SageMaker-Endpunkte, um zusätzliche Kosten zu vermeiden. Mit dem bereitgestellten Code können Sie Echtzeit- bzw. asynchrone Inferenzendpunkte löschen.
Zusammenfassung
In diesem Beitrag haben wir Ihnen gezeigt, wie der Einsatz maschineller Lernmodelle für die Audioverarbeitung in verschiedenen Branchen immer wichtiger wird. Am Beispiel des Whisper-Modells haben wir gezeigt, wie man Open-Source-ASR-Modelle auf Amazon SageMaker mit PyTorch- oder Hugging-Face-Ansätzen hostet. Die Untersuchung umfasste verschiedene Inferenzoptionen auf Amazon SageMaker und bot Einblicke in den effizienten Umgang mit Audiodaten, das Erstellen von Vorhersagen und das effektive Kostenmanagement. Dieser Beitrag soll Wissen für Forscher, Entwickler und Datenwissenschaftler vermitteln, die daran interessiert sind, das Whisper-Modell für audiobezogene Aufgaben zu nutzen und fundierte Entscheidungen über Inferenzstrategien zu treffen.
Ausführlichere Informationen zum Bereitstellen von Modellen auf SageMaker finden Sie hier Entwicklerhandbuch. Darüber hinaus kann das Whisper-Modell mit SageMaker JumpStart bereitgestellt werden. Weitere Einzelheiten finden Sie hier Flüstermodelle für die automatische Spracherkennung sind jetzt in Amazon SageMaker JumpStart verfügbar Post.
Schauen Sie sich gerne das Notizbuch und den Code für dieses Projekt an GitHub und teilen Sie uns Ihren Kommentar mit.
Über den Autor
 Ying Hou, PhD, ist ein Prototyping-Architekt für maschinelles Lernen bei AWS. Ihre Hauptinteressengebiete umfassen Deep Learning mit einem Schwerpunkt auf GenAI, Computer Vision, NLP und Zeitreihendatenvorhersage. In ihrer Freizeit verbringt sie gerne schöne Momente mit ihrer Familie, vertieft sich in Romane und wandert in den Nationalparks Großbritanniens.
Ying Hou, PhD, ist ein Prototyping-Architekt für maschinelles Lernen bei AWS. Ihre Hauptinteressengebiete umfassen Deep Learning mit einem Schwerpunkt auf GenAI, Computer Vision, NLP und Zeitreihendatenvorhersage. In ihrer Freizeit verbringt sie gerne schöne Momente mit ihrer Familie, vertieft sich in Romane und wandert in den Nationalparks Großbritanniens.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- beschleunigt
- Zugang
- Zugänglichkeit
- Konto
- Genauigkeit
- über
- Aktionen
- aktiv
- hinzufügen
- Zusätzliche
- zusätzlich
- Adresse
- einstellen
- advanced
- AI
- Ziel
- Alle
- Zulassen
- erlaubt
- entlang
- ebenfalls
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- Analyse
- und
- Ein anderer
- jedem
- Anwendungen
- Ansätze
- SIND
- Bereiche
- Feld
- künstlich
- künstliche Intelligenz
- AS
- Vermögenswert
- Assistenten
- damit verbundenen
- At
- Audio-
- Urheberschaft
- automatische
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Verfügbarkeit
- verfügbar
- vermeiden
- AWS
- Base
- basierend
- BE
- werden
- unten
- Besser
- zwischen
- Vorurteile
- BIN
- beide
- Bugs
- aber
- by
- CAN
- Fähigkeiten
- fähig
- vorsichtig
- Fälle
- Änderungen
- Chart
- aus der Ferne überprüfen
- Auswählen
- Auswahl
- Klasse
- klar
- Code
- wie die
- Kommentar
- gemeinsam
- Vergleich
- Vergleiche
- Abgeschlossene Verkäufe
- Abschluss
- Komponenten
- umfassend
- Berechnung
- Computer
- Computer Vision
- Leiten
- Kongressbegleitung
- Konfiguration
- konfiguriert
- konfigurieren
- Berücksichtigung
- konsequent
- enthalten
- Container
- Behälter
- ständig
- Kontrast
- Smartgeräte App
- Umwandlung
- und beseitigen Muskelschwäche
- Dazugehörigen
- Kosten
- Kosten
- könnte
- CPU
- erstellen
- Erstellen
- wichtig
- Original
- technische Daten
- Entscheidungen
- verringern
- tief
- tiefe Lernen
- Standard
- definieren
- Synergie
- einsetzen
- Einsatz
- Bereitstellen
- Einsatz
- Detail
- detailliert
- Details
- entwickeln
- Entwickler
- Entwicklung
- Gerät
- Geräte
- anders
- unterscheiden
- Abmessungen
- Direkt
- Anzeige
- tauchen
- verschieden
- Docker
- Tut nicht
- Dabei
- nach unten
- im
- e
- jeder
- Früher
- Ökosystem
- effektiv
- effizient
- effizient
- mühelos
- entweder
- sonst
- einsteigen
- befähigt
- ermöglichen
- ermöglicht
- ermöglichen
- umfassen
- Endpunkt
- Endpunkte
- zu steigern,
- Eine Verbesserung der
- gewährleisten
- sorgt
- Ganz
- Arbeitsumfeld
- essential
- Festlegung
- Äther (ETH)
- Untersuchung
- Beispiel
- überschreiten
- überschritten
- Ausgezeichnet
- Experiment
- Erklären
- Exploration
- Möglichkeiten sondieren
- Gesicht
- Gescheitert
- falsch
- Familie
- FAST
- beschleunigt
- schnellsten
- wenige
- Reichen Sie das
- Mappen
- findet
- Vorname
- Setzen Sie mit Achtsamkeit
- Fokussierung
- Folgende
- Aussichten für
- Format
- Unser Ansatz
- Gerüste
- Frei
- für
- voller
- GPU
- GPUs
- groß
- Gruppe an
- Griff
- Handling
- Hardware
- Haben
- Hörtests
- Unternehmen
- hier (auf dänisch)
- GUTE
- höher
- Wandern
- Gastgeber
- Hosting
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- Nabe
- Umarmendes Gesicht
- i
- ideal
- if
- illustrieren
- Image
- Bilder
- Implementierung
- Realisierungen
- importieren
- wichtig
- in
- eingehende
- das
- Dazu gehören
- Einschließlich
- integrieren
- Erhöhung
- zunehmend
- Krankengymnastik
- Einzelpersonen
- Branchen
- Information
- informiert
- Anfangs-
- anfänglich
- Einleitung
- Varianten des Eingangssignals:
- Eingänge
- Einblicke
- installieren
- Instanz
- Instanzen
- Anleitung
- Integration
- Intelligenz
- interagieren
- Interesse
- interessiert
- Schnittstelle
- in
- Probleme
- IT
- SEINE
- Job
- Jobs
- jpg
- Wesentliche
- Wissen
- bekannt
- Landschaft
- größer
- zuletzt
- Latency
- später
- neueste
- Schicht
- führen
- lernen
- am wenigsten
- Nutzung
- Lizenz
- Einschränkung
- Limitiert
- Line
- Liste
- Belastung
- Laden
- aus einer regionalen
- Standorte
- Lang
- länger
- Sneaker
- Maschine
- Maschinelles Lernen
- gemacht
- Main
- um
- MACHT
- Making
- verwalten
- flächendeckende Gesundheitsprogramme
- Landkarten
- Kann..
- erwähnt
- Metadaten
- Methode
- Methoden
- Metrik
- könnte
- Millisekunden
- Minuten
- MIT
- ML
- Modell
- für
- moderieren
- Moments
- Überwachung
- mehr
- Filme
- viel
- mehrere
- sollen
- Namens
- National
- Nationalparks
- notwendig,
- Need
- erforderlich
- Netzwerk
- Neural
- neuronale Netzwerk
- weiter
- Nlp
- nicht
- beachten
- Notizbuch
- Notizen
- Benachrichtigung
- Benachrichtigungen
- Bemerkens
- jetzt an
- Anzahl
- Zahlen
- Objekt
- Objekte
- beobachten
- of
- bieten
- bieten
- Angebote
- offiziell
- Offline-Bereich.
- on
- einmal
- EINEM
- einzige
- Open-Source-
- arbeitet
- Option
- Optionen
- or
- Auftrag
- Organisationen
- OS
- Andere
- Andernfalls
- Überblick
- Paket
- Pakete
- Parameter
- Parameter
- Parks
- passieren
- Weg
- ausführen
- Leistung
- Phase
- Pipeline
- zentrale
- platziert
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- Punkte
- möglich
- Post
- Potenzial
- Prognose
- Prognosen
- verhindern
- früher
- primär
- Prozessdefinierung
- verarbeitet
- Verarbeitung
- Prozessor
- Projekt
- richtig
- Prototyping
- die
- vorausgesetzt
- bietet
- Bereitstellung
- Python
- Pytorch
- Qualität
- Angebot
- Echtzeit
- Reich
- Anerkennung
- empfohlen
- aufgezeichnet
- Reduziert
- siehe
- Ungeachtet
- bezogene
- Mitteilungen
- merken
- entfernen
- entfernt
- Quelle
- Anforderung
- Zugriffe
- erfordern
- falls angefordert
- Anforderung
- Forscher
- beziehungsweise
- Antwort
- Antworten
- für ihren Verlust verantwortlich.
- Folge
- Folge
- Die Ergebnisse
- behielt
- Umschulung
- Rückkehr
- sagemaker
- gleich
- Speichern
- Gerettet
- Einsparung
- Skalierbarkeit
- Skalieren
- Waage
- vorgesehen
- Wissenschaftler
- Skript
- Skripte
- Zweite
- Sekunden
- Abschnitt
- Segmente
- wählen
- ausgewählt
- Auswahl
- Modellreihe
- Lösungen
- kompensieren
- Einstellung
- Einstellungen
- Teilen
- sie
- sollte
- zeigte
- Konzerte
- Schließung
- signifikant
- Einfacher
- Vereinfacht
- Größe
- Größen
- klein
- kleinere
- So
- Software
- Lösung
- spezifisch
- speziell
- angegeben
- Rede
- Spracherkennung
- Geschwindigkeit
- Ausgabe
- gesprochen
- Anfang
- Bundesstaat
- State-of-the-art
- Schritt
- Shritte
- Lagerung
- Strategien
- Folge
- erfolgreich
- so
- plötzlich
- geeignet
- Support
- Unterstützung
- Unterstützt
- sicher
- Schwall
- Systeme und Techniken
- Tabelle
- Nehmen
- Einnahme
- Aufgabe
- und Aufgaben
- Technologie
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Großbritannien
- ihr
- Sie
- dann
- Dort.
- deswegen
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- nach drei
- Zeit
- Zeitfolgen
- mal
- zu
- Werkzeuge
- Fackel
- der Verkehr
- Training
- trainiert
- Transformieren
- Transformator
- Transformer
- auslösen
- ausgelöst
- tv
- TV-Serie
- XNUMX
- tippe
- typisch
- Uk
- für
- Entriegelung
- auf
- us
- -
- benutzt
- benutzerfreundlich
- Nutzer
- Verwendung von
- Nutzen
- Nutzen
- Verwendung
- wertvoll
- Wert
- Variable
- verschiedene
- riesig
- Version
- Seh-
- Stimme
- Sprachbefehle
- Volumen
- warten
- wollen
- wurde
- we
- Netz
- Web-Services
- GUT
- waren
- wann
- sobald
- welche
- Flüstern
- breit
- Große Auswahl
- mit
- .
- Arbeitsablauf.
- Werk
- wert
- Schreiben
- U
- Ihr
- Zephyrnet