Mit der Amazon EMR 6.15, wir haben gestartet AWS Lake-Formation basierend auf feinkörnigen Zugriffskontrollen (FGAC) auf Open Table Formats (OTFs), einschließlich Apache Hudi, Apache Iceberg und Delta Lake. Dadurch können Sie Sicherheit und Governance vereinfachen Transaktionsdatenseen indem Sie für Ihre Apache Spark-Jobs Zugriffskontrollen auf Tabellen-, Spalten- und Zeilenebene bereitstellen. Viele große Unternehmen möchten ihren Transaktionsdatensee nutzen, um Erkenntnisse zu gewinnen und die Entscheidungsfindung zu verbessern. Sie können eine Lake-House-Architektur mithilfe von Amazon EMR erstellen, das in Lake Formation für FGAC integriert ist. Mit dieser Kombination von Diensten können Sie Datenanalysen für Ihren Transaktionsdatensee durchführen und gleichzeitig einen sicheren und kontrollierten Zugriff gewährleisten.
Die Amazon EMR-Datensatzserverkomponente unterstützt Datenfilterungsfunktionen auf Tabellen-, Spalten-, Zeilen-, Zellen- und verschachtelter Attributebene. Es erweitert die Unterstützung auf die Formate Hive, Apache Hudi, Apache Iceberg und Delta Lake sowohl für Lese- (einschließlich Zeitreisen und inkrementelle Abfragen) als auch für Schreibvorgänge (auf DML-Anweisungen wie INSERT). Darüber hinaus führt Amazon EMR mit Version 6.15 einen Zugriffskontrollschutz für seine Anwendungs-Webschnittstelle ein, z. B. den Spark History Server auf dem Cluster, den Yarn Timeline Server und die Yarn Resource Manager-Benutzeroberfläche.
In diesem Beitrag zeigen wir, wie man FGAC implementiert Apache Hudi Tabellen mithilfe von Amazon EMR, integriert mit Lake Formation.
Anwendungsfall für den Transaktionsdatensee
Amazon EMR-Kunden nutzen häufig Open Table Formats, um ihre ACID-Transaktions- und Zeitreiseanforderungen in einem Data Lake zu unterstützen. Durch die Beibehaltung historischer Versionen bietet Data Lake Time Travel Vorteile wie Auditing und Compliance, Datenwiederherstellung und Rollback, reproduzierbare Analyse und Datenexploration zu verschiedenen Zeitpunkten.
Ein weiterer beliebter Anwendungsfall für den Transaktionsdatensee ist die inkrementelle Abfrage. Inkrementelle Abfrage bezieht sich auf eine Abfragestrategie, die sich darauf konzentriert, nur die neuen oder aktualisierten Daten in einem Datensee seit der letzten Abfrage zu verarbeiten und zu analysieren. Der Kerngedanke inkrementeller Abfragen besteht darin, mithilfe von Metadaten oder Änderungsverfolgungsmechanismen die neuen oder geänderten Daten seit der letzten Abfrage zu identifizieren. Durch die Identifizierung dieser Änderungen kann die Abfrage-Engine die Abfrage so optimieren, dass nur die relevanten Daten verarbeitet werden, wodurch die Verarbeitungszeit und der Ressourcenbedarf erheblich reduziert werden.
Lösungsüberblick
In diesem Beitrag zeigen wir, wie man FGAC auf Apache Hudi-Tabellen mit Amazon EMR implementiert Amazon Elastic Compute-Cloud (Amazon EC2) integriert mit Lake Formation. Apache Hudi ist ein Open-Source-Transaktions-Data-Lake-Framework, das die inkrementelle Datenverarbeitung und die Entwicklung von Datenpipelines erheblich vereinfacht. Diese neue FGAC-Funktion unterstützt alle OTF. Neben der Demonstration mit Hudi hier werden wir weitere OTF-Tabellen in anderen Blogs veröffentlichen. Wir gebrauchen Laptops in Amazon SageMaker-Studio um Hudi-Daten über verschiedene Benutzerzugriffsberechtigungen über einen EMR-Cluster zu lesen und zu schreiben. Dies spiegelt reale Datenzugriffsszenarien wider – wenn beispielsweise ein technischer Benutzer vollständigen Datenzugriff zur Fehlerbehebung auf einer Datenplattform benötigt, während Datenanalysten möglicherweise nur auf eine Teilmenge dieser Daten zugreifen müssen, die keine personenbezogenen Daten (PII) enthalten ). Integration mit Lake Formation über die Amazon EMR-Laufzeitrolle Darüber hinaus können Sie Ihre Datensicherheit verbessern und die Datenkontrollverwaltung für Amazon EMR-Workloads vereinfachen. Diese Lösung gewährleistet eine sichere und kontrollierte Umgebung für den Datenzugriff und erfüllt die unterschiedlichen Bedürfnisse und Sicherheitsanforderungen verschiedener Benutzer und Rollen in einer Organisation.
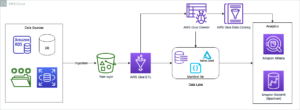
Das folgende Diagramm zeigt die Lösungsarchitektur.
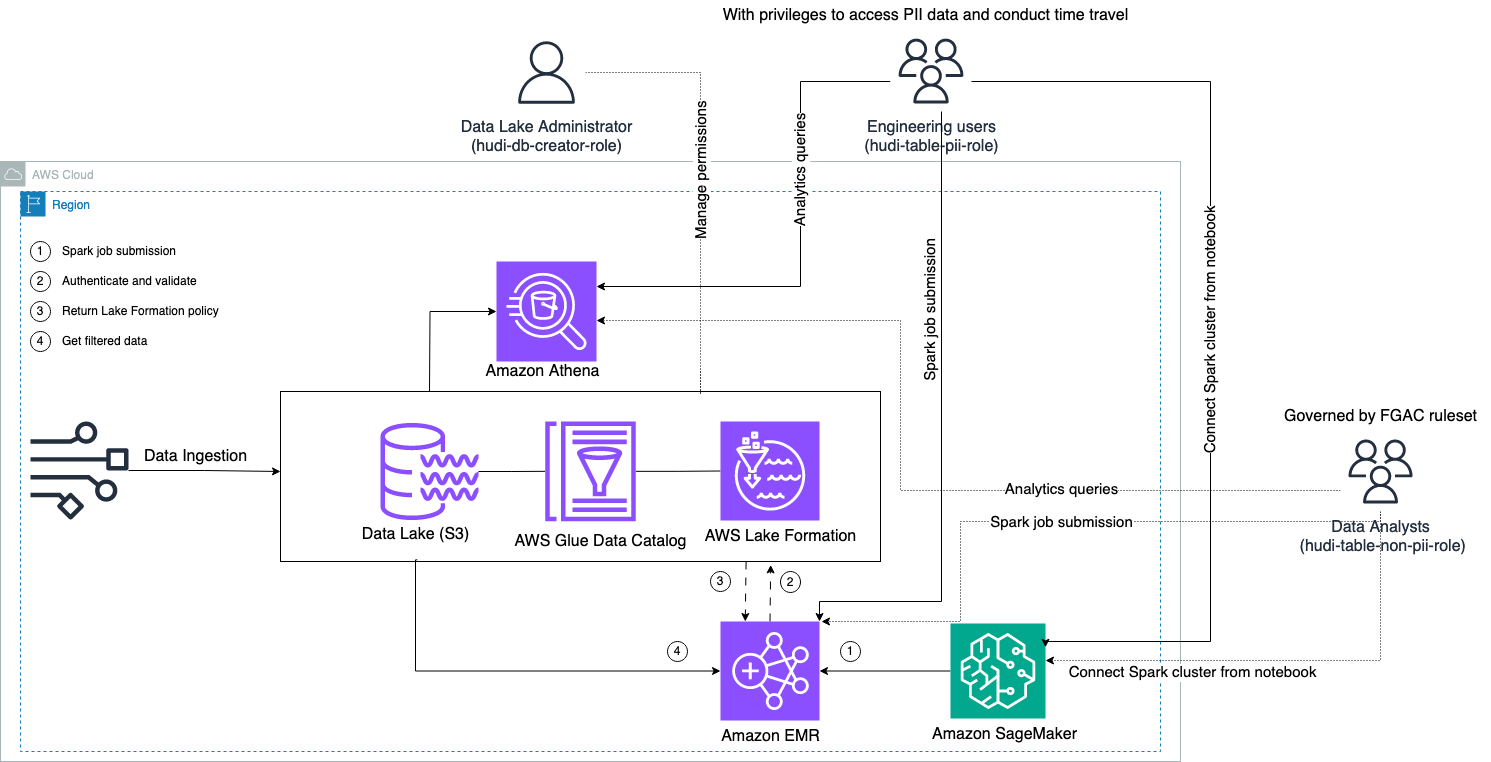
Wir führen einen Datenaufnahmeprozess durch, um einen Hudi-Datensatz in einen hochzuladen (zu aktualisieren und einzufügen). Amazon Simple Storage-Service (Amazon S3)-Bucket und behalten Sie das Tabellenschema im bei oder aktualisieren Sie es AWS-Kleber Datenkatalog. Ohne Datenbewegung können wir die von Lake Formation verwaltete Hudi-Tabelle über verschiedene AWS-Dienste abfragen, z Amazonas Athena, Amazon EMR und Amazon Sage Maker.
Wenn Benutzer einen Spark-Job über einen beliebigen EMR-Cluster-Endpunkt (EMR Steps, Livy, EMR Studio und SageMaker) übermitteln, validiert Lake Formation ihre Berechtigungen und weist den EMR-Cluster an, vertrauliche Daten wie PII-Daten herauszufiltern.
Diese Lösung verfügt über drei verschiedene Benutzertypen mit unterschiedlichen Berechtigungsstufen für den Zugriff auf die Hudi-Daten:
- hudi-db-creator-role – Dies wird vom Data Lake-Administrator verwendet, der über Berechtigungen zum Ausführen von DDL-Vorgängen wie dem Erstellen, Ändern und Löschen von Datenbankobjekten verfügt. Sie können Datenfilterregeln für Lake Formation für die Datenzugriffskontrolle auf Zeilen- und Spaltenebene definieren. Diese FGAC-Regeln stellen sicher, dass der Data Lake gesichert ist und die erforderlichen Datenschutzbestimmungen erfüllt.
- hudi-table-pii-role – Dies wird von technischen Benutzern verwendet. Die technischen Benutzer sind in der Lage, Zeitreisen und inkrementelle Abfragen sowohl für Copy-on-Write (CoW) als auch für Merge-on-Read (MoR) durchzuführen. Sie haben außerdem das Recht, auf PII-Daten basierend auf beliebigen Zeitstempeln zuzugreifen.
- hudi-table-non-pii-role – Dies wird von Datenanalysten verwendet. Die Datenzugriffsrechte von Datenanalysten werden durch von der FGAC autorisierte Regeln geregelt, die von Data-Lake-Administratoren kontrolliert werden. Spalten mit PII-Daten wie Namen und Adressen sind nicht sichtbar. Darüber hinaus können sie nicht auf Datenzeilen zugreifen, die bestimmte Bedingungen nicht erfüllen. Beispielsweise können die Benutzer nur auf Datenzeilen zugreifen, die zu ihrem Land gehören.
Voraussetzungen:
Sie können die drei in diesem Beitrag verwendeten Notizbücher unter herunterladen GitHub Repo.
Stellen Sie vor der Bereitstellung der Lösung sicher, dass Sie über Folgendes verfügen:
Führen Sie die folgenden Schritte aus, um Ihre Berechtigungen einzurichten:
- Melden Sie sich mit Ihrem IAM-Administratorbenutzer bei Ihrem AWS-Konto an.
Stellen Sie sicher, dass Sie in derus-east-1Region.
- Erstellen Sie einen S3-Bucket im
us-east-1Region (z. B.emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Als nächstes aktivieren wir die Lake-Formation Ändern des Standardberechtigungsmodells.
- Melden Sie sich als Administratorbenutzer bei der Lake Formation-Konsole an.
- Auswählen Datenkatalogeinstellungen für Verwaltung im Navigationsbereich.
- Der Standardberechtigungen für neu erstellte Datenbanken und Tabellen, Abwählen Verwenden Sie für neue Datenbanken nur die IAM-Zugriffssteuerung und Verwenden Sie nur die IAM-Zugriffssteuerung für neue Tabellen in neuen Datenbanken.
- Auswählen Speichern.
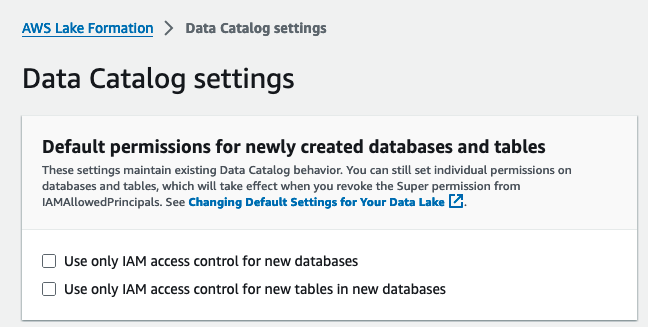
Alternativ müssen Sie IAMAllowedPrincipals für Ressourcen (Datenbanken und Tabellen) widerrufen, die erstellt wurden, wenn Sie Lake Formation mit der Standardoption gestartet haben.
Abschließend erstellen wir ein Schlüsselpaar für Amazon EMR.
- Wählen Sie auf der Amazon EC2-Konsole Schlüsselpaare im Navigationsbereich.
- Auswählen Schlüsselpaar erstellen.
- Aussichten für Name und Vorname, geben Sie einen Namen ein (z. B
emr-fgac-hudi-keypair). - Auswählen Schlüsselpaar erstellen.
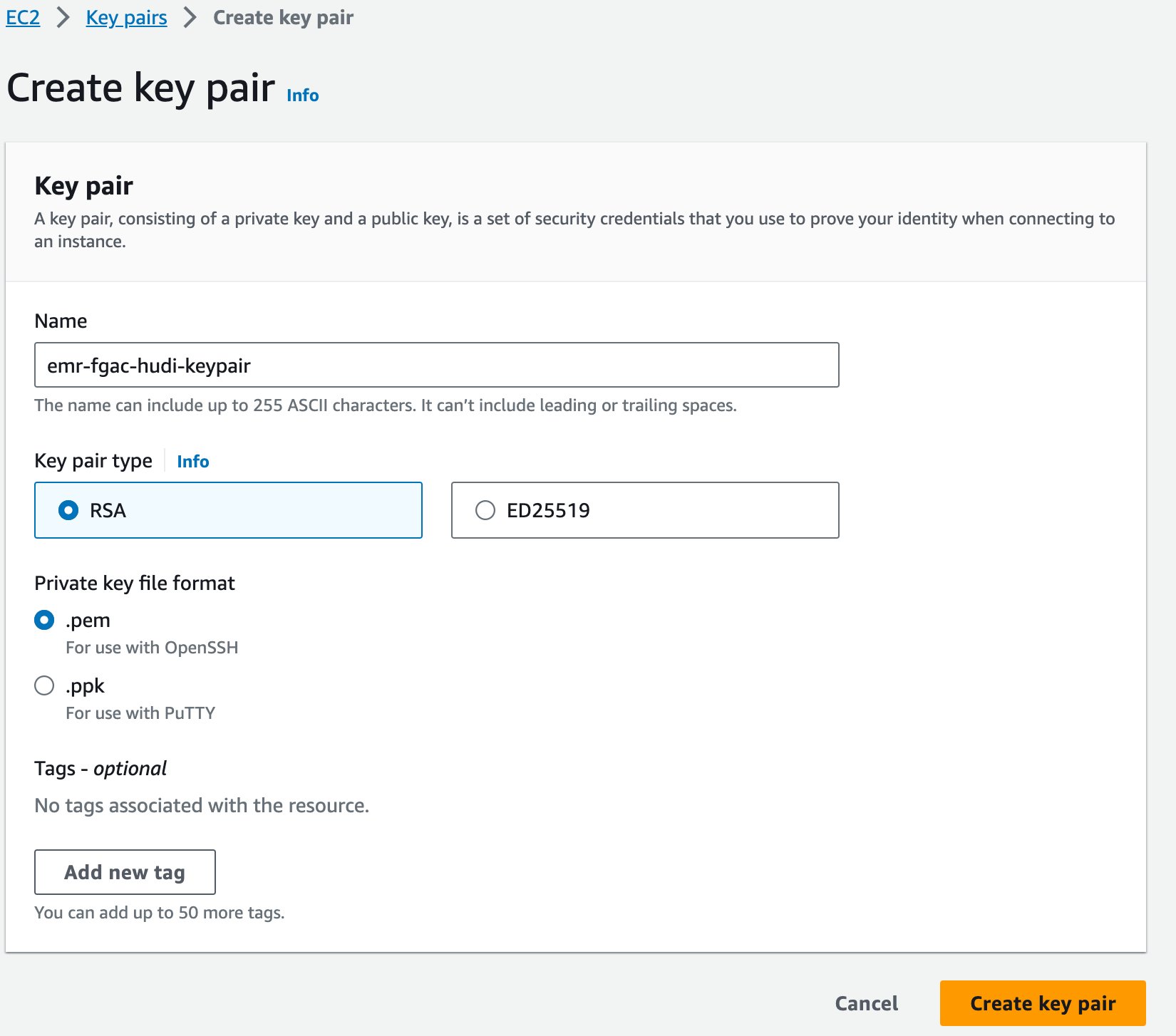
Das generierte Schlüsselpaar (für diesen Beitrag emr-fgac-hudi-keypair.pem) wird auf Ihrem lokalen Computer gespeichert.
Als nächstes erstellen wir ein AWS Cloud9 interaktive Entwicklungsumgebung (IDE).
- Wählen Sie in der AWS Cloud9-Konsole aus Environments im Navigationsbereich.
- Auswählen Umgebung erstellen.
- Aussichten für Name und Vorname¸ Geben Sie einen Namen ein (z. B.
emr-fgac-hudi-env). - Behalten Sie die anderen Einstellungen als Standard bei.
- Auswählen Erstellen.
- Wenn die IDE bereit ist, wählen Sie Offen um es zu öffnen.
- In der AWS Cloud9-IDE auf der Reichen Sie das Menü, wählen Sie Laden Sie lokale Dateien hoch.

- Laden Sie die Schlüsselpaardatei hoch (
emr-fgac-hudi-keypair.pem). - Wählen Sie das Pluszeichen und wählen Sie aus Neues Terminal.
- Geben Sie im Terminal die folgenden Befehlszeilen ein:
Beachten Sie, dass der Beispielcode nur ein Proof of Concept zu Demonstrationszwecken ist. Verwenden Sie für Produktionssysteme eine vertrauenswürdige Zertifizierungsstelle (CA), um Zertifikate auszustellen. Beziehen auf Bereitstellung von Zertifikaten zur Verschlüsselung von Daten während der Übertragung mit Amazon EMR-Verschlüsselung für weitere Einzelheiten.
Stellen Sie die Lösung über AWS CloudFormation bereit
Wir bieten eine AWS CloudFormation Vorlage, die die folgenden Dienste und Komponenten automatisch einrichtet:
- Ein S3-Bucket für den Data Lake. Es enthält den TPC-DS-Beispieldatensatz.
- Ein EMR-Cluster mit aktivierter Sicherheitskonfiguration und öffentlichem DNS.
- EMR-Laufzeit-IAM-Rollen mit differenzierten Lake Formation-Berechtigungen:
- -hudi-db-creator-role – Diese Rolle wird zum Erstellen von Apache Hudi-Datenbanken und -Tabellen verwendet.
- -hudi-table-pii-role – Diese Rolle bietet die Berechtigung zum Abfragen aller Spalten von Hudi-Tabellen, einschließlich Spalten mit PII.
- -hudi-table-non-pii-role – Diese Rolle bietet die Berechtigung zum Abfragen von Hudi-Tabellen, die PII-Spalten von Lake Formation herausgefiltert haben.
- SageMaker Studio-Ausführungsrollen, die es den Benutzern ermöglichen, ihre entsprechenden EMR-Laufzeitrollen zu übernehmen.
- Netzwerkressourcen wie VPC, Subnetze und Sicherheitsgruppen.
Führen Sie die folgenden Schritte aus, um die Ressourcen bereitzustellen:
- Auswählen Schneller Stapel erstellen um den CloudFormation-Stack zu starten.
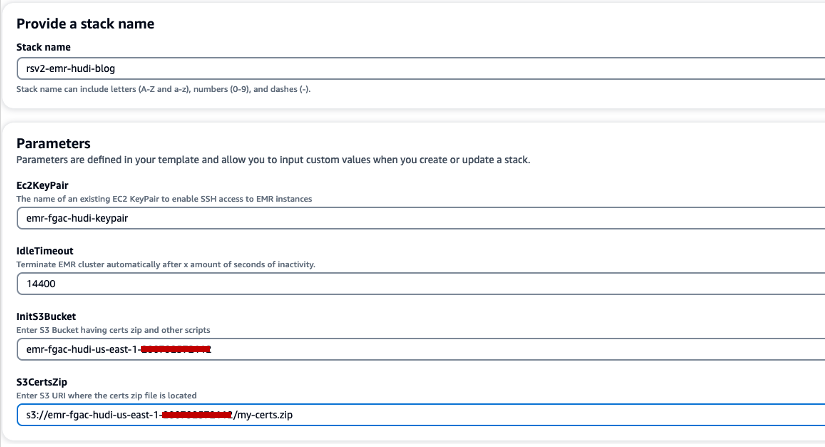
- Aussichten für Stapelname, geben Sie einen Stack-Namen ein (z. B.
rsv2-emr-hudi-blog). - Aussichten für Ec2KeyPairGeben Sie den Namen Ihres Schlüsselpaars ein.
- Aussichten für IdleTimeoutGeben Sie ein Leerlauf-Timeout für den EMR-Cluster ein, um zu vermeiden, dass der Cluster bezahlt wird, wenn er nicht verwendet wird.
- Aussichten für InitS3BucketGeben Sie den S3-Bucket-Namen ein, den Sie erstellt haben, um die ZIP-Datei des Amazon EMR-Verschlüsselungszertifikats zu speichern.
- Aussichten für S3CertsZipGeben Sie den S3-URI der ZIP-Datei des Amazon EMR-Verschlüsselungszertifikats ein.
- Auswählen Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen mit benutzerdefinierten Namen erstellt.
- Auswählen Stapel erstellen.
Die Bereitstellung des CloudFormation-Stacks dauert etwa 10 Minuten.
Richten Sie Lake Formation für die Amazon EMR-Integration ein
Führen Sie die folgenden Schritte aus, um Lake Formation einzurichten:
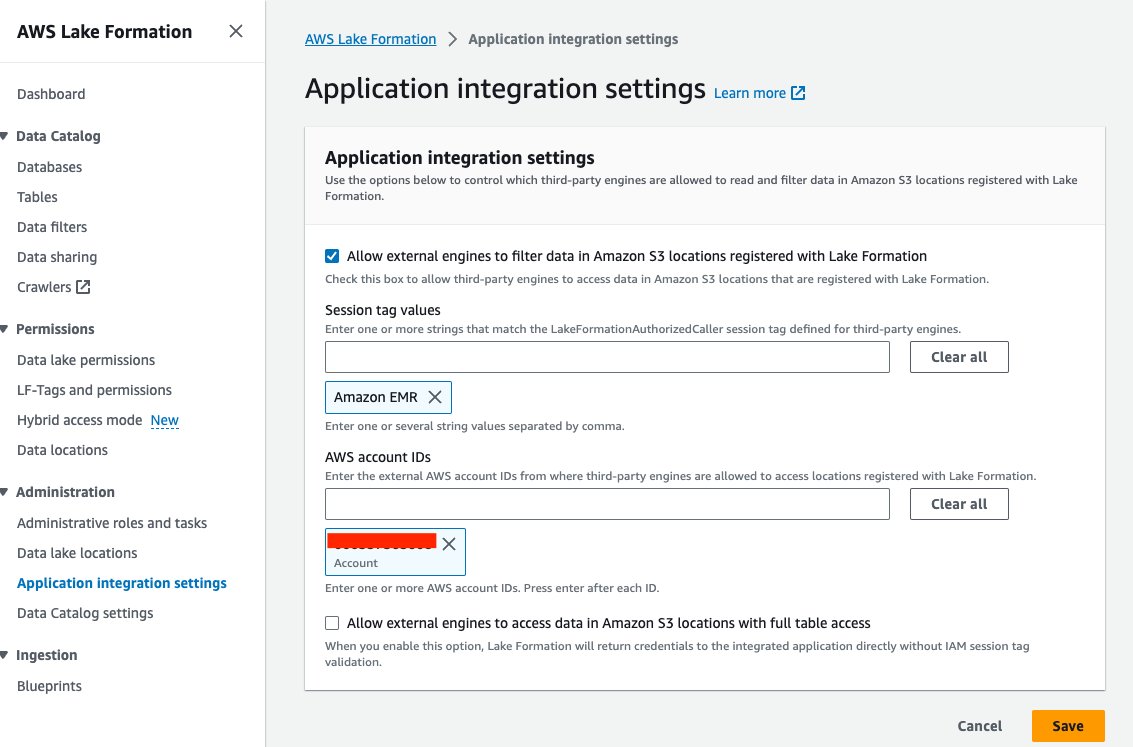
- Wählen Sie in der Lake Formation-Konsole aus Einstellungen zur Anwendungsintegration für Verwaltung im Navigationsbereich.
- Auswählen Erlauben Sie externen Engines, Daten an Amazon S3-Standorten zu filtern, die bei Lake Formation registriert sind.
- Auswählen Amazon EMR für Sitzungs-Tag-Werte.
- Geben Sie Ihre AWS-Konto-ID ein AWS-Konto-IDs.
- Auswählen Speichern.
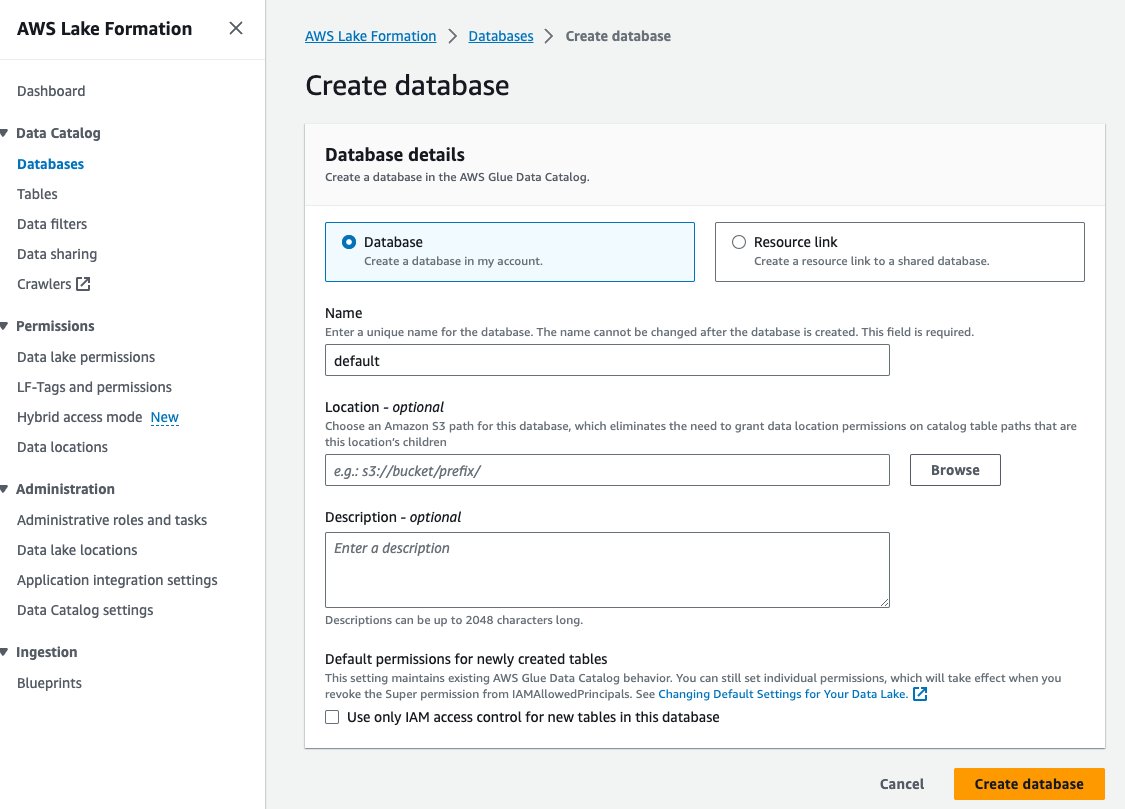
- Auswählen Datenbanken für Datenkatalog im Navigationsbereich.
- Auswählen Datenbank erstellen.
- Aussichten für Name und Vorname, geben Sie den Standardwert ein.
- Auswählen Datenbank erstellen.
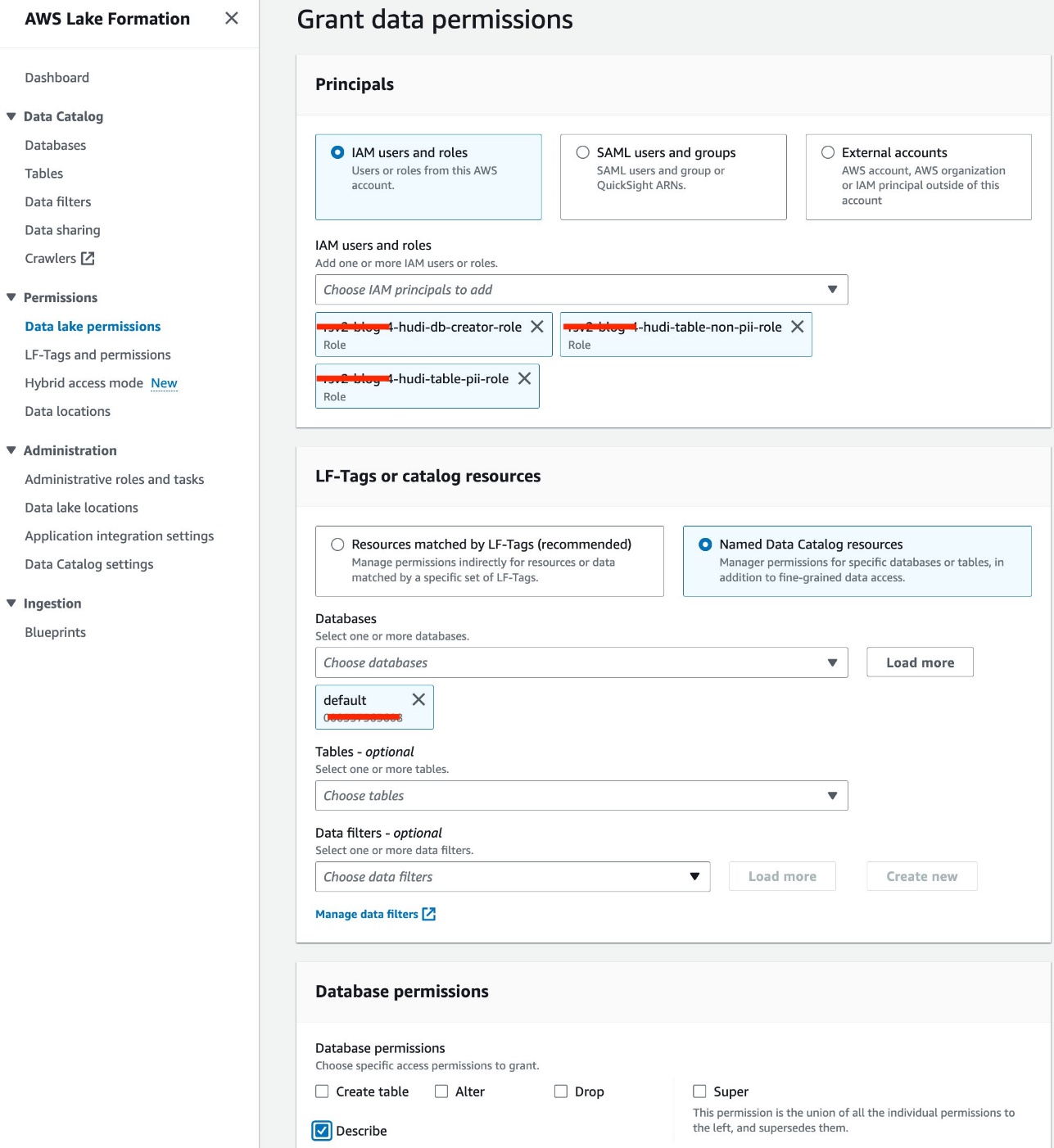
- Auswählen Data Lake-Berechtigungen für Berechtigungen im Navigationsbereich.
- Auswählen Gewähren.
- Auswählen IAM-Benutzer und -Rollen.
- Wählen Sie Ihre IAM-Rollen.
- Aussichten für Datenbanken, wählen Sie Standard.
- Aussichten für DatenbankberechtigungenWählen Beschreiben.
- Auswählen Gewähren.
Kopieren Sie die Hudi-JAR-Datei in Amazon EMR HDFS
Zu Verwenden Sie Hudi mit Jupyter-Notebooksmüssen Sie die folgenden Schritte für den EMR-Cluster ausführen, einschließlich des Kopierens einer Hudi-JAR-Datei aus dem lokalen Amazon EMR-Verzeichnis in den HDFS-Speicher, damit Sie eine Spark-Sitzung für die Verwendung von Hudi konfigurieren können:
- Autorisieren Sie eingehenden SSH-Verkehr (Port 22).
- Kopieren Sie den Wert für Öffentliches DNS des Primärknotens (z. B. ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) aus dem EMR-Cluster Zusammenfassung .
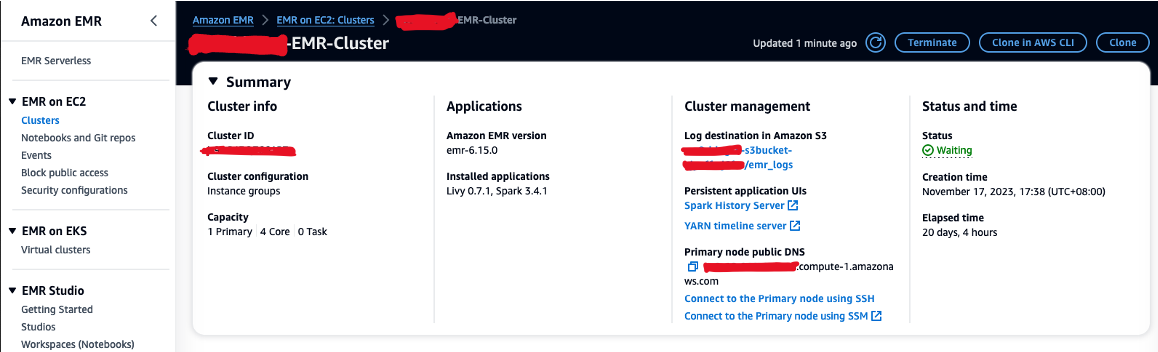
- Kehren Sie zum vorherigen AWS Cloud9-Terminal zurück, das Sie zum Erstellen des EC2-Schlüsselpaars verwendet haben.
- Führen Sie den folgenden Befehl aus, um eine SSH-Verbindung zum EMR-Primärknoten herzustellen. Ersetzen Sie den Platzhalter durch Ihren EMR-DNS-Hostnamen:
- Führen Sie den folgenden Befehl aus, um die Hudi-JAR-Datei nach HDFS zu kopieren:
Erstellen Sie die Hudi-Datenbank und -Tabellen in Lake Formation
Jetzt können wir die Hudi-Datenbank und -Tabellen mit FGAC erstellen, das durch die EMR-Laufzeitrolle aktiviert wird. Der EMR-Laufzeitrolle ist eine IAM-Rolle, die Sie angeben können, wenn Sie einen Job oder eine Abfrage an einen EMR-Cluster senden.
Erteilen Sie die Berechtigung zum Erstellen einer Datenbank
Erteilen wir zunächst dem Ersteller der Lake Formation-Datenbank die Erlaubnis dazu<STACK-NAME>-hudi-db-creator-role:
- Melden Sie sich als Administrator bei Ihrem AWS-Konto an.
- Wählen Sie in der Lake Formation-Konsole aus Administrative Rollen und Aufgaben für Verwaltung im Navigationsbereich.
- Bestätigen Sie, dass Ihr AWS-Anmeldebenutzer als Data Lake-Administrator hinzugefügt wurde.
- Im Datenbankersteller Wählen Sie im Abschnitt Gewähren.
- Aussichten für IAM-Benutzer und -Rollen, wählen
<STACK-NAME>-hudi-db-creator-role. - Aussichten für KatalogberechtigungenWählen Datenbank erstellen.
- Auswählen Gewähren.
Registrieren Sie den Data Lake-Standort
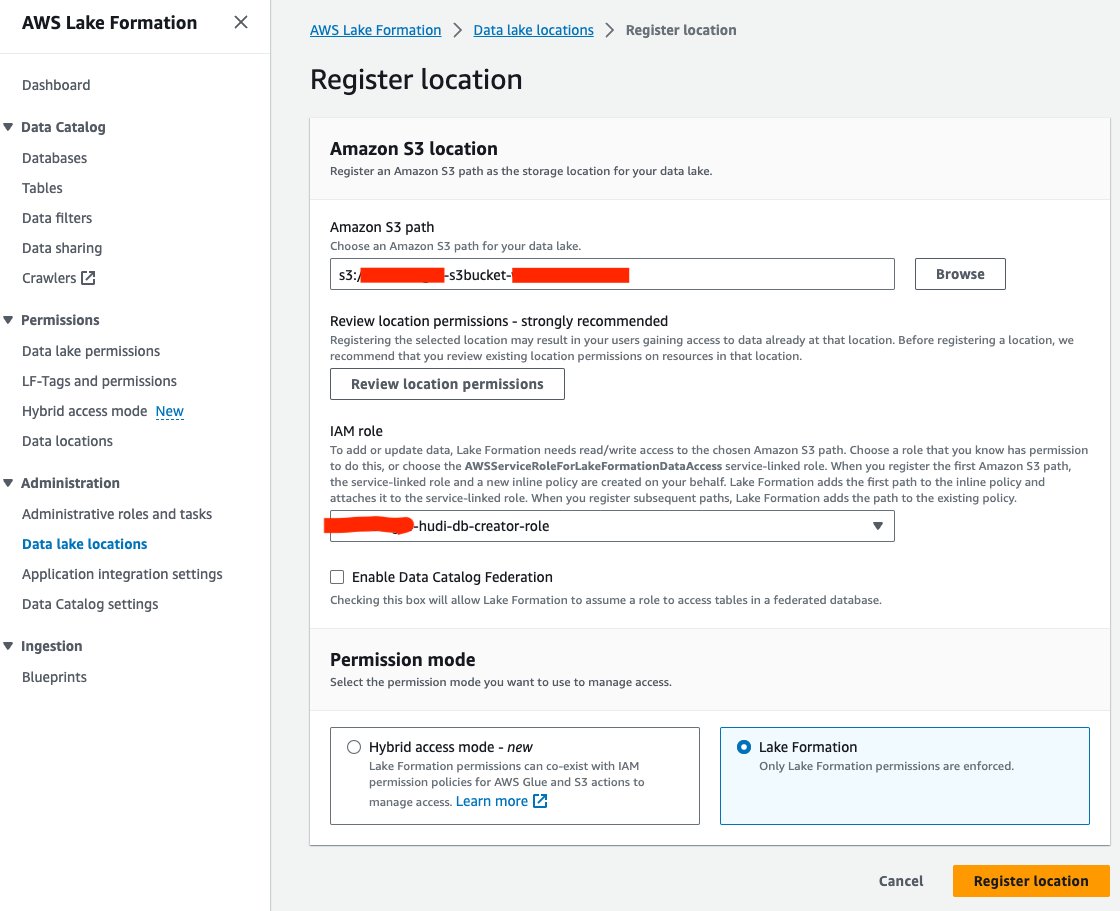
Als nächstes registrieren wir den S3-Data-Lake-Standort in Lake Formation:
- Wählen Sie in der Lake Formation-Konsole aus Datenseestandorte für Verwaltung im Navigationsbereich.
- Auswählen Ort registrieren.
- Aussichten für Amazon S3-PfadWählen Sie Entdecken und wählen Sie den Data Lake S3-Bucket aus. (
<STACK_NAME>s3bucket-XXXXXXX), erstellt aus dem CloudFormation-Stack. - Aussichten für IAM-Rolle, wählen
<STACK-NAME>-hudi-db-creator-role. - Aussichten für BerechtigungsmodusWählen Seebildung.
- Auswählen Ort registrieren.
Erteilen Sie die Berechtigung zum Datenspeichern
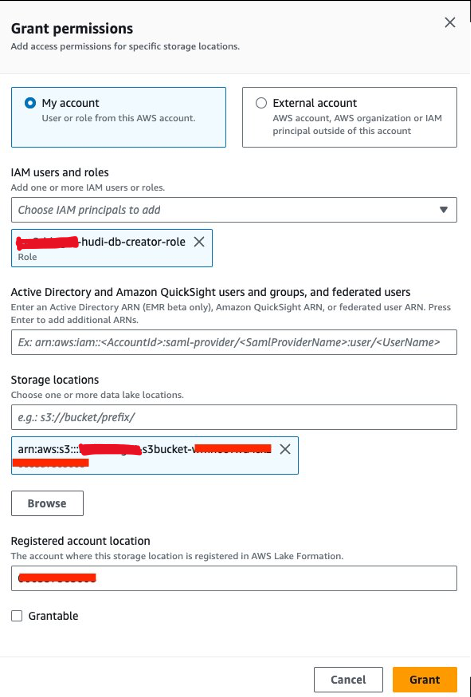
Als nächstes müssen wir gewähren<STACK-NAME>-hudi-db-creator-roledie Datenspeicherungsberechtigung:
- Wählen Sie in der Lake Formation-Konsole aus Datenstandorte für Berechtigungen im Navigationsbereich.
- Auswählen Gewähren.
- Aussichten für IAM-Benutzer und -Rollen, wählen
<STACK-NAME>-hudi-db-creator-role. - Aussichten für Speicherorte, geben Sie den S3-Bucket ein (
<STACK_NAME>-s3bucket-XXXXXXX). - Auswählen Gewähren.
Stellen Sie eine Verbindung zum EMR-Cluster her
Lassen Sie uns nun ein Jupyter-Notebook in SageMaker Studio verwenden, um eine Verbindung zum EMR-Cluster mit der EMR-Laufzeitrolle des Datenbankerstellers herzustellen:
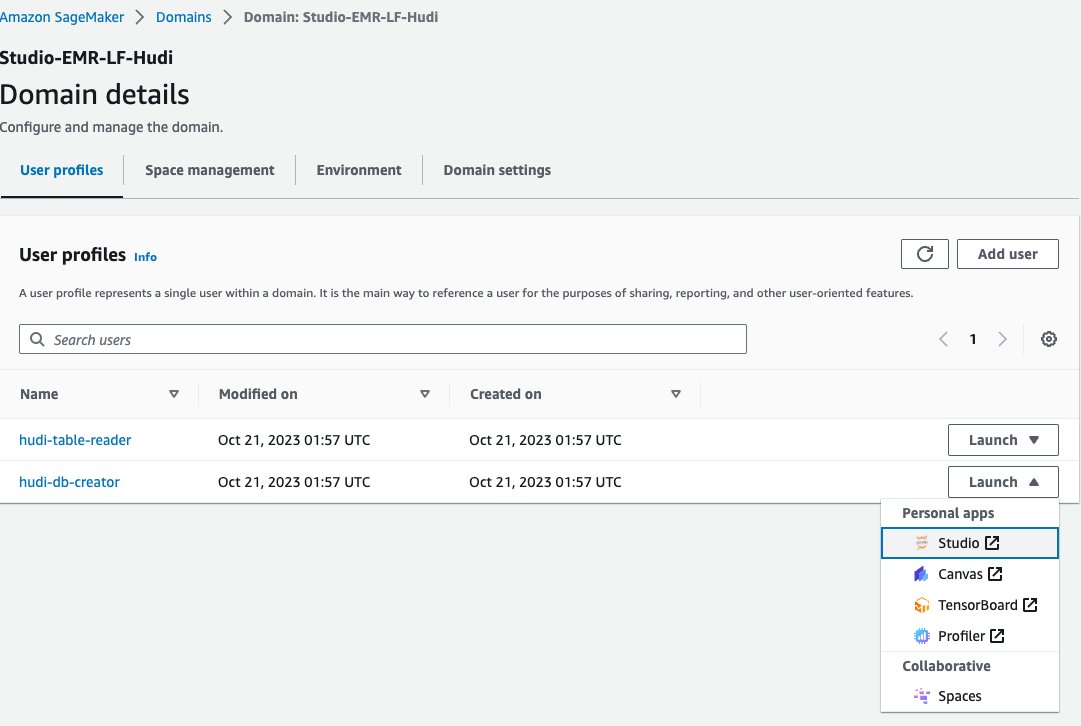
- Wählen Sie in der SageMaker-Konsole Domains im Navigationsbereich.
- Wählen Sie die Domäne
<STACK-NAME>-Studio-EMR-LF-Hudi. - Auf dem Einführung Menü neben dem Benutzerprofil
<STACK-NAME>-hudi-db-creator, wählen Studio.
- Laden Sie das Notizbuch herunter rsv2-hudi-db-creator-notebook.
- Wählen Sie das Upload-Symbol.
- Wählen Sie das heruntergeladene Jupyter-Notizbuch aus und wählen Sie Offen.
- Öffnen Sie das hochgeladene Notizbuch.
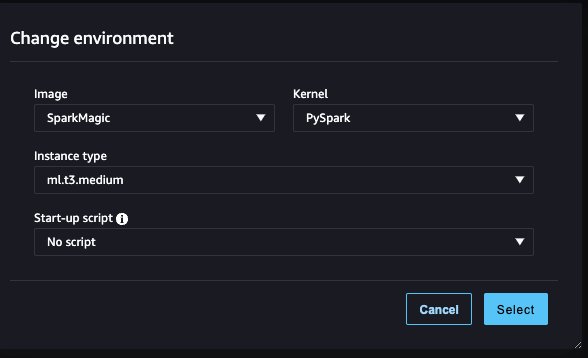
- Aussichten für Bild, wählen FunkenMagie.
- Aussichten für Kernel, wählen PySpark.
- Belassen Sie die anderen Konfigurationen als Standard und wählen Sie Auswählen.
- Auswählen Cluster um eine Verbindung zum EMR-Cluster herzustellen.

- Wählen Sie den EMR-on-EC2-Cluster (
<STACK-NAME>-EMR-Cluster), erstellt mit dem CloudFormation-Stack. - Auswählen Vernetz Dich.
- Aussichten für EMR-Ausführungsrolle, wählen
<STACK-NAME>-hudi-db-creator-role. - Auswählen Vernetz Dich.
Erstellen Sie Datenbanken und Tabellen
Jetzt können Sie den Schritten im Notebook folgen, um die Hudi-Datenbank und -Tabellen zu erstellen. Die wichtigsten Schritte sind wie folgt:
- Wenn Sie das Notebook starten, konfigurieren Sie es
“spark.sql.catalog.spark_catalog.lf.managed":"true"um Spark darüber zu informieren, dass spark_catalog durch Lake Formation geschützt ist. - Erstellen Sie Hudi-Tabellen mit dem folgenden Spark SQL.
- Fügen Sie Daten aus der Quelltabelle in die Hudi-Tabellen ein.
- Fügen Sie die Daten erneut in die Hudi-Tabellen ein.
Fragen Sie die Hudi-Tabellen über Lake Formation mit FGAC ab
Nachdem Sie die Hudi-Datenbank und -Tabellen erstellt haben, können Sie die Tabellen mithilfe einer fein abgestimmten Zugriffskontrolle mit Lake Formation abfragen. Wir haben zwei Arten von Hudi-Tabellen erstellt: Copy-On-Write (COW) und Merge-On-Read (MOR). Die COW-Tabelle speichert Daten in einem Spaltenformat (Parquet) und jede Aktualisierung erstellt während eines Schreibvorgangs eine neue Version der Dateien. Das bedeutet, dass Hudi bei jedem Update die gesamte Datei neu schreibt, was ressourcenintensiver sein kann, aber eine schnellere Leseleistung bietet. MOR hingegen wird für Fälle eingeführt, in denen COW möglicherweise nicht optimal ist, insbesondere für schreib- oder änderungsintensive Arbeitslasten. In einer MOR-Tabelle schreibt Hudi bei jeder Aktualisierung nur die Zeile für den geänderten Datensatz, was die Kosten senkt und Schreibvorgänge mit geringer Latenz ermöglicht. Allerdings ist die Leseleistung im Vergleich zu COW-Tabellen möglicherweise langsamer.
Erteilen Sie die Zugriffsberechtigung für die Tabelle
Wir nutzen die IAM-Rolle<STACK-NAME>-hudi-table-pii-roleum Hudi COW und MOR abzufragen, die PII-Spalten enthalten. Wir erteilen zunächst die Tabellenzugriffsberechtigung über Lake Formation:
- Wählen Sie in der Lake Formation-Konsole aus Data Lake-Berechtigungen für Berechtigungen im Navigationsbereich.
- Auswählen Gewähren.
- Auswählen
<STACK-NAME>-hudi-table-pii-rolefür IAM-Benutzer und -Rollen. - Wähle die
rsv2_blog_hudi_db_1Datenbank für Datenbanken. - Aussichten für Tische, wählen Sie die vier Hudi-Tabellen aus, die Sie im Jupyter-Notizbuch erstellt haben.
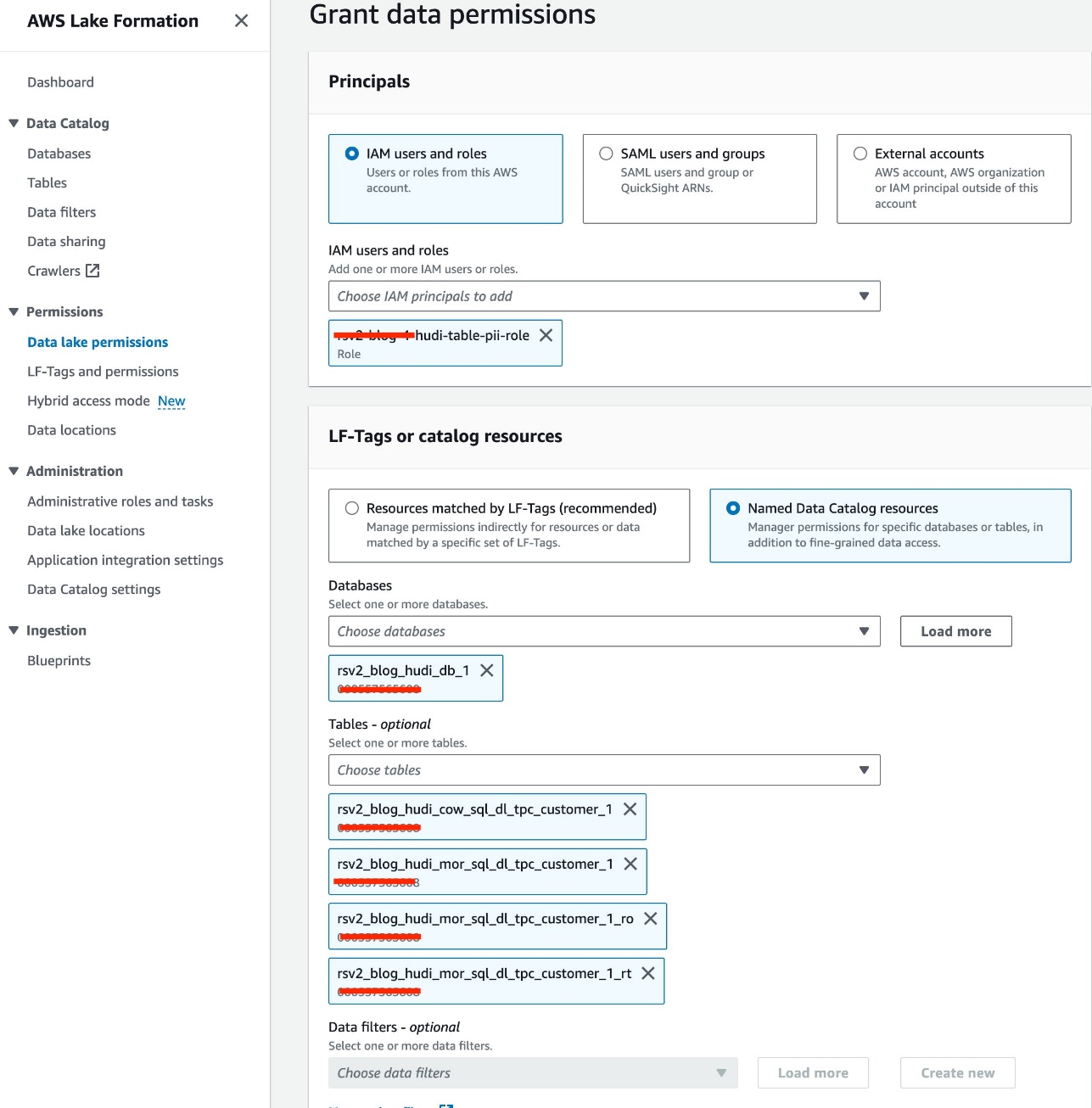
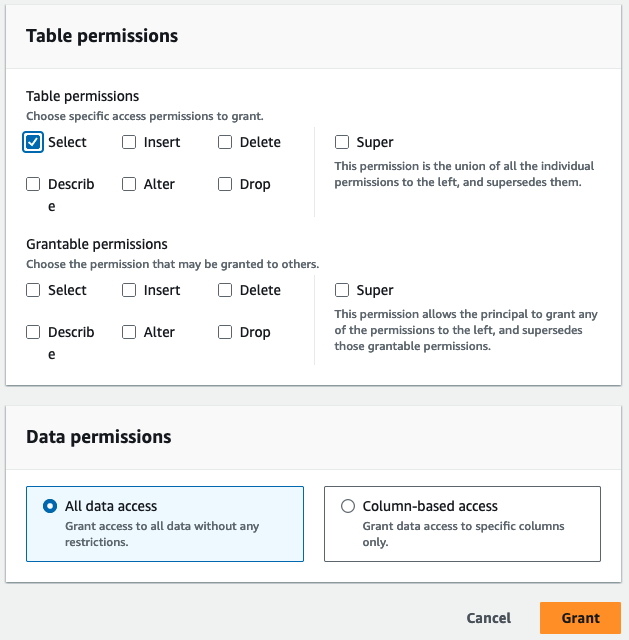
- Aussichten für TabellenberechtigungenWählen Auswählen.
- Auswählen Gewähren.
PII-Spalten abfragen
Jetzt können Sie das Notebook ausführen, um die Hudi-Tabellen abzufragen. Führen wir ähnliche Schritte wie im vorherigen Abschnitt aus, um das Notebook in SageMaker Studio auszuführen:
- Navigieren Sie in der SageMaker-Konsole zu der
<STACK-NAME>-Studio-EMR-LF-HudiDomäne. - Auf dem Einführung Menü neben dem
<STACK-NAME>-hudi-table-readerBenutzerprofil, wählen Sie Studio. - Laden Sie das heruntergeladene Notizbuch hoch rsv2-hudi-table-pii-reader-notebook.
- Öffnen Sie das hochgeladene Notizbuch.
- Wiederholen Sie die Schritte zum Einrichten des Notebooks und stellen Sie eine Verbindung zum gleichen EMR-Cluster her, verwenden Sie jedoch die Rolle
<STACK-NAME>-hudi-table-pii-role.
In der aktuellen Phase muss der FGAC-fähige EMR-Cluster die Commit-Zeitspalte von Hudi abfragen, um inkrementelle Abfragen und Zeitreisen durchzuführen. Die Spark-Syntax „Zeitstempel ab“ wird nicht unterstützt Spark.read(). Wir arbeiten aktiv daran, die Unterstützung für beide Aktionen in zukünftige Amazon EMR-Versionen mit aktiviertem FGAC zu integrieren.
Sie können nun den Schritten im Notizbuch folgen. Im Folgenden sind einige hervorgehobene Schritte aufgeführt:
- Führen Sie eine Snapshot-Abfrage aus.
- Führen Sie eine inkrementelle Abfrage aus.
- Führen Sie eine Zeitreiseabfrage aus.
- Führen Sie MOR-leseoptimierte Tabellenabfragen in Echtzeit aus.
Fragen Sie die Hudi-Tabellen mit Datenfiltern auf Spalten- und Zeilenebene ab
Wir nutzen die IAM-Rolle<STACK-NAME>-hudi-table-non-pii-roleum Hudi-Tabellen abzufragen. Diese Rolle darf keine Spalten abfragen, die personenbezogene Daten enthalten. Wir verwenden die Lake Formation-Datenfilter auf Spalten- und Zeilenebene, um eine differenzierte Zugriffskontrolle zu implementieren:
- Wählen Sie in der Lake Formation-Konsole aus Datenfilter für Datenkatalog im Navigationsbereich.
- Auswählen Neuen Filter erstellen.
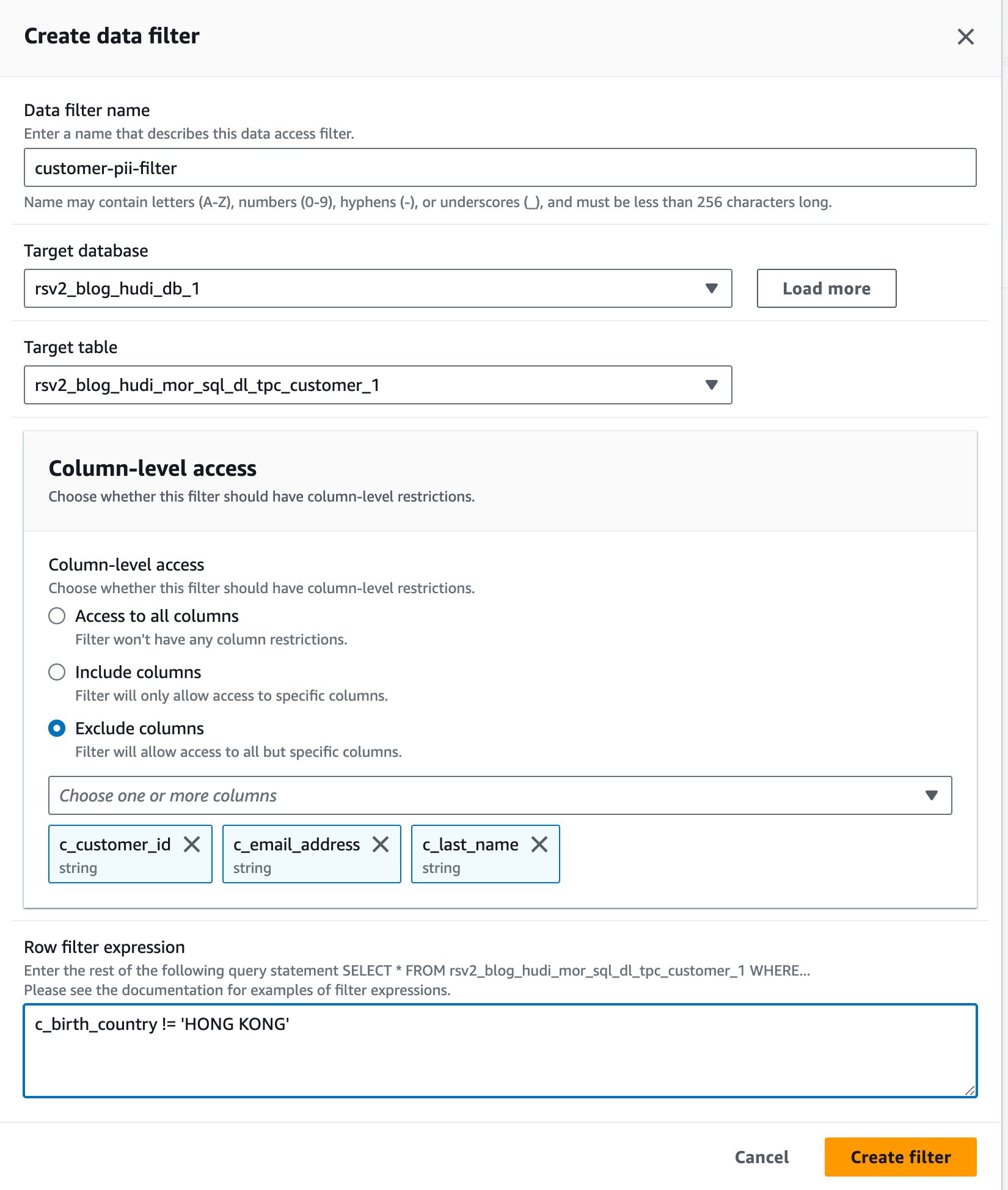
- Aussichten für Name des Datenfilters, eingeben
customer-pii-filter. - Auswählen
rsv2_blog_hudi_db_1für Zieldatenbank. - Auswählen
rsv2_blog_hudi_mor_sql_dl_customer_1für Zieltabelle. - Auswählen Spalten ausschließen und wähle das
c_customer_id,c_email_addressundc_last_nameSäulen. - Enter
c_birth_country != 'HONG KONG'für Zeilenfilterausdruck. - Auswählen Filter erstellen.
- Auswählen Data Lake-Berechtigungen für Berechtigungen im Navigationsbereich.
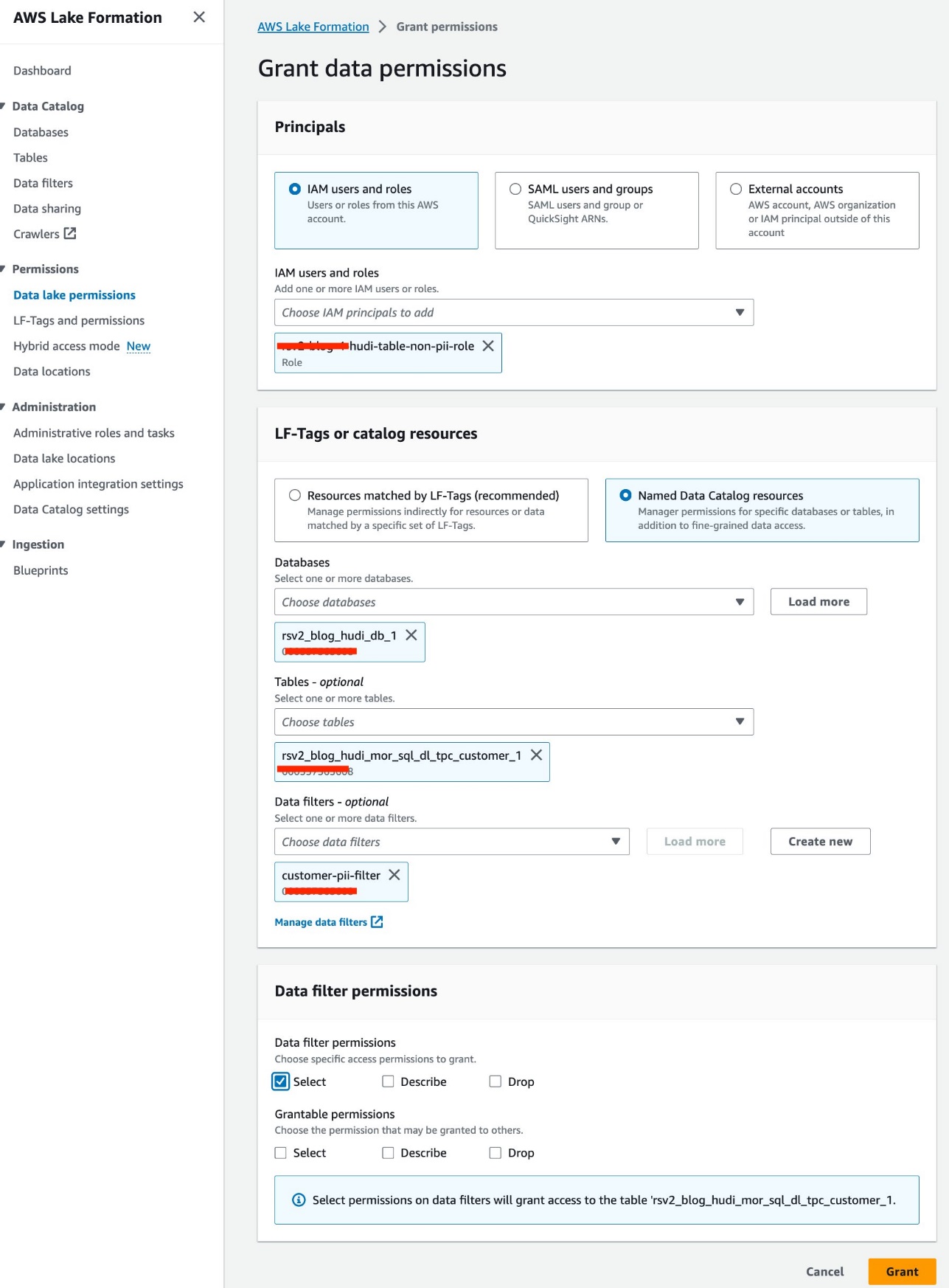
- Auswählen Gewähren.
- Auswählen
<STACK-NAME>-hudi-table-non-pii-rolefür IAM-Benutzer und -Rollen. - Auswählen
rsv2_blog_hudi_db_1für Datenbanken. - Auswählen
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1für Tische. - Auswählen
customer-pii-filterfür Datenfilter. - Aussichten für Berechtigungen für DatenfilterWählen Auswählen.
- Auswählen Gewähren.
Führen wir ähnliche Schritte aus, um das Notebook in SageMaker Studio auszuführen:
- Navigieren Sie in der SageMaker-Konsole zur Domäne
Studio-EMR-LF-Hudi. - Auf dem Einführung Menü für die
hudi-table-readerBenutzerprofil, wählen Sie Studio. - Laden Sie das heruntergeladene Notizbuch hoch rsv2-hudi-table-non-pii-reader-notebook und wählen Sie Offen.
- Wiederholen Sie die Schritte zum Einrichten des Notebooks und stellen Sie eine Verbindung zum gleichen EMR-Cluster her, wählen Sie jedoch die Rolle aus
<STACK-NAME>-hudi-table-non-pii-role.
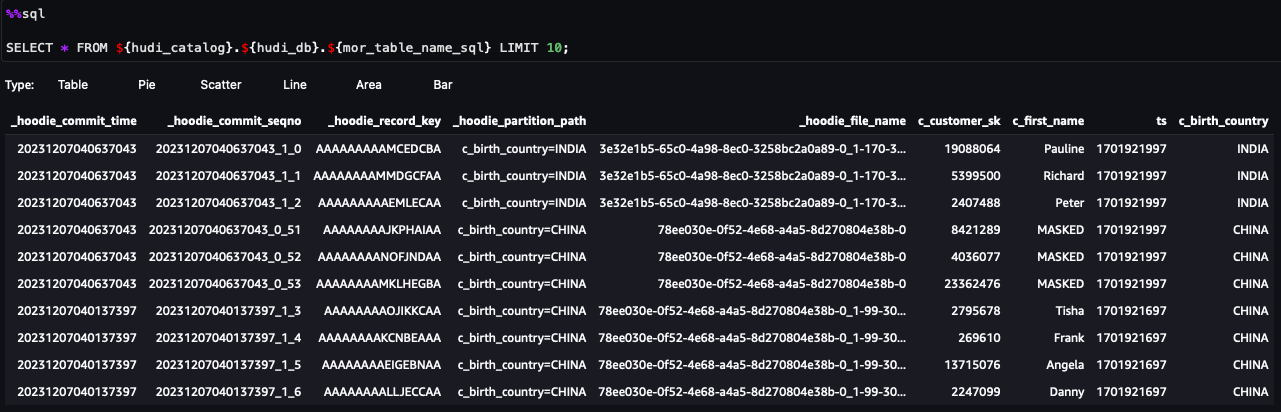
Sie können nun den Schritten im Notizbuch folgen. Anhand der Abfrageergebnisse können Sie erkennen, dass FGAC über den Datenfilter „Lake Formation“ angewendet wurde. Die Rolle kann die PII-Spalten nicht sehenc_customer_id,c_last_name undc_email_address. Auch die Zeilen vonHONG KONGwurden gefiltert.
Aufräumen
Nachdem Sie mit dem Experimentieren mit der Lösung fertig sind, empfehlen wir, die Ressourcen mit den folgenden Schritten zu bereinigen, um unerwartete Kosten zu vermeiden:
- Beenden Sie die SageMaker Studio-Apps für die Benutzerprofile.
Der EMR-Cluster wird nach Ablauf des Leerlaufzeitlimits automatisch gelöscht.
- Löschen Sie die Amazon Elastic File System (Amazon EFS)-Volume, das für die Domäne erstellt wurde.
- Leeren Sie die S3-Eimer erstellt vom CloudFormation-Stack.
- Löschen Sie den Stack auf der AWS CloudFormation-Konsole.
Zusammenfassung
In diesem Beitrag haben wir Apachi Hudi, einen Typ von OTF-Tabellen, verwendet, um diese neue Funktion zur Durchsetzung einer differenzierten Zugriffskontrolle auf Amazon EMR zu demonstrieren. Sie können in Lake Formation granulare Berechtigungen für OTF-Tabellen definieren und diese über Spark SQL-Abfragen auf EMR-Cluster anwenden. Sie können auch transaktionale Data Lake-Funktionen wie das Ausführen von Snapshot-Abfragen, inkrementellen Abfragen, Zeitreisen und DML-Abfragen verwenden. Bitte beachten Sie, dass diese neue Funktion alle OTF-Tabellen abdeckt.
Diese Funktion wird insgesamt ab Amazon EMR-Version 6.15 eingeführt Regionen wo Amazon EMR verfügbar ist. Mit der Amazon EMR-Integration mit Lake Formation können Sie große Datenmengen sicher verwalten und verarbeiten, Erkenntnisse gewinnen und fundierte Entscheidungen erleichtern und gleichzeitig Datensicherheit und Governance wahren.
Weitere Informationen finden Sie unter Aktivieren Sie Lake Formation mit Amazon EMR und wenden Sie sich gerne an Ihre AWS-Lösungsarchitekten, die Ihnen bei Ihrer Datenreise behilflich sein können.
Über den Autor
 Raymond Lai ist ein Senior Solutions Architect, der sich auf die Bedürfnisse großer Unternehmenskunden spezialisiert hat. Seine Expertise liegt in der Unterstützung von Kunden bei der Migration komplexer Unternehmenssysteme und Datenbanken zu AWS sowie beim Aufbau von Enterprise Data Warehousing- und Data Lake-Plattformen. Raymond zeichnet sich durch die Identifizierung und Gestaltung von Lösungen für KI/ML-Anwendungsfälle aus und legt einen besonderen Schwerpunkt auf serverlose AWS-Lösungen und ereignisgesteuertes Architekturdesign.
Raymond Lai ist ein Senior Solutions Architect, der sich auf die Bedürfnisse großer Unternehmenskunden spezialisiert hat. Seine Expertise liegt in der Unterstützung von Kunden bei der Migration komplexer Unternehmenssysteme und Datenbanken zu AWS sowie beim Aufbau von Enterprise Data Warehousing- und Data Lake-Plattformen. Raymond zeichnet sich durch die Identifizierung und Gestaltung von Lösungen für KI/ML-Anwendungsfälle aus und legt einen besonderen Schwerpunkt auf serverlose AWS-Lösungen und ereignisgesteuertes Architekturdesign.
 Bin Wang, PhD, ist Senior Analytic Specialist Solutions Architect bei AWS und verfügt über mehr als 12 Jahre Erfahrung in der ML-Branche mit besonderem Schwerpunkt auf Werbung. Er verfügt über Fachkenntnisse in der Verarbeitung natürlicher Sprache (NLP), Empfehlungssystemen, verschiedenen ML-Algorithmen und ML-Operationen. Er hat eine große Leidenschaft für die Anwendung von ML/DL und Big-Data-Techniken zur Lösung realer Probleme.
Bin Wang, PhD, ist Senior Analytic Specialist Solutions Architect bei AWS und verfügt über mehr als 12 Jahre Erfahrung in der ML-Branche mit besonderem Schwerpunkt auf Werbung. Er verfügt über Fachkenntnisse in der Verarbeitung natürlicher Sprache (NLP), Empfehlungssystemen, verschiedenen ML-Algorithmen und ML-Operationen. Er hat eine große Leidenschaft für die Anwendung von ML/DL und Big-Data-Techniken zur Lösung realer Probleme.
 Aditya Schah ist Softwareentwicklungsingenieur bei AWS. Er interessiert sich für Datenbanken und Data-Warehouse-Engines und hat an Leistungsoptimierungen, Sicherheits-Compliance und ACID-Compliance für Engines wie Apache Hive und Apache Spark gearbeitet.
Aditya Schah ist Softwareentwicklungsingenieur bei AWS. Er interessiert sich für Datenbanken und Data-Warehouse-Engines und hat an Leistungsoptimierungen, Sicherheits-Compliance und ACID-Compliance für Engines wie Apache Hive und Apache Spark gearbeitet.
 Melodie Yang ist Senior Big Data Solution Architect für Amazon EMR bei AWS. Sie ist eine erfahrene Analyseleiterin, die mit AWS-Kunden zusammenarbeitet, um Best-Practice-Anleitung und technische Beratung bereitzustellen, um deren Erfolg bei der Datentransformation zu unterstützen. Ihre Interessensgebiete sind Open Source Frameworks und Automatisierung, Data Engineering und DataOps.
Melodie Yang ist Senior Big Data Solution Architect für Amazon EMR bei AWS. Sie ist eine erfahrene Analyseleiterin, die mit AWS-Kunden zusammenarbeitet, um Best-Practice-Anleitung und technische Beratung bereitzustellen, um deren Erfolg bei der Datentransformation zu unterstützen. Ihre Interessensgebiete sind Open Source Frameworks und Automatisierung, Data Engineering und DataOps.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Über uns
- Zugang
- Konto
- anerkennen
- Aktionen
- aktiv
- hinzugefügt
- zusätzlich
- Adressen
- Administrator
- Administratoren
- Marketings
- Beratung
- Nach der
- aufs Neue
- AI / ML
- Algorithmen
- Alle
- erlauben
- erlaubt
- erlaubt
- neben
- ebenfalls
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- Analyse
- Business Analysten
- Analytisch
- Analytik
- Analyse
- und
- jedem
- Apache
- Apache Funken
- Anwendung
- angewandt
- Jetzt bewerben
- Anwendung
- Architekten
- Architektur
- SIND
- Bereiche
- um
- AS
- helfen
- Hilfe
- Unterstützung
- annehmen
- At
- Wirtschaftsprüfung
- Autorität
- zugelassen
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Automation
- verfügbar
- vermeiden
- AWS
- AWS Cloud9
- AWS CloudFormation
- AWS Lake-Formation
- Zurück
- basierend
- BE
- war
- hinter
- Sein
- Vorteile
- neben
- BESTE
- Big
- Big Data
- Blogs
- Prahlerei
- beide
- bauen
- aber
- by
- CA
- CAN
- fähig
- tragen
- Tragen
- Häuser
- Fälle
- Katalog
- Catering
- sicher
- Bescheinigung
- Zertifikate
- Zertifizierung
- Übernehmen
- geändert
- Änderungen
- China
- Auswählen
- Reinigung
- Cloud9
- Cluster
- Code
- Kolonne
- Spalten
- COM
- Kombination
- verpflichten
- Unternehmen
- verglichen
- abschließen
- Compliance
- Komponente
- Komponenten
- Berechnen
- Computer
- konzept
- Bedingungen
- Leiten
- zuversichtlich
- Konfiguration
- Vernetz Dich
- Konsul (Console)
- Bau
- Kontakt
- enthalten
- enthält
- Smartgeräte App
- gesteuert
- Steuerung
- Kopieren
- Dazugehörigen
- Kosten
- Kosten
- Land
- deckt
- erstellen
- erstellt
- schafft
- Erstellen
- Schöpfer
- Strom
- Original
- Kunden
- technische Daten
- Datenzugriff
- Datenanalyse
- Datensee
- Datenplattform
- Datenschutz
- Datenverarbeitung
- Datensicherheit
- Data Warehouse
- Datenbase
- Datenbanken
- Decision Making
- tief
- Standard
- definieren
- Delta
- zeigen
- demonstrieren
- einsetzen
- Einsatz
- Design
- Entwerfen
- Details
- Entwicklung
- anders
- deutlich
- verschieden
- dns
- do
- die
- Tut nicht
- Domain
- erledigt
- Nicht
- nach unten
- herunterladen
- angetrieben
- im
- jeder
- sonst
- ermöglichen
- freigegeben
- ermöglicht
- Verschlüsselung
- Ende
- Endpunkte
- erzwingen
- Motor
- Ingenieur
- Entwicklung
- Motor (en)
- gewährleisten
- sorgt
- Gewährleistung
- Enter
- Unternehmen
- Unternehmenskunden
- Ganz
- Arbeitsumfeld
- Äther (ETH)
- Event
- Jedes
- Beispiel
- Ausführung
- existiert
- ERFAHRUNGEN
- erfahrensten
- Expertise
- Exploration
- erweitert
- extern
- erleichtern
- beschleunigt
- Merkmal
- Eigenschaften
- fühlen
- Reichen Sie das
- Mappen
- Filter
- Filterung
- Filter
- Vorname
- Setzen Sie mit Achtsamkeit
- konzentriert
- folgen
- Folgende
- folgt
- Aussichten für
- Format
- Ausbildung
- vier
- Unser Ansatz
- Gerüste
- Frei
- für
- Erfüllen
- voller
- Funktionalität
- weiter
- Zukunft
- Gewinnen
- erzeugt
- Governance
- geregelt
- gewähren
- sehr
- Gruppe an
- Gruppen
- die Vermittlung von Kompetenzen,
- Pflege
- Haben
- he
- hier (auf dänisch)
- hier
- Besondere
- seine
- historisch
- Geschichte
- Bienenstock
- Hong
- Hongkong
- Häuser
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Idee
- identifizieren
- Identifizierung
- Leerlauf
- if
- zeigt
- implementieren
- zu unterstützen,
- in
- Dazu gehören
- Einschließlich
- einarbeiten
- inkremental
- Indien
- Energiegewinnung
- informieren
- Information
- informiert
- Varianten des Eingangssignals:
- Einblicke
- integriert
- Integration
- Integration
- interaktive
- interessiert
- Interessen
- Schnittstelle
- intern
- in
- kompliziert
- eingeführt
- Stellt vor
- Problem
- IT
- SEINE
- Job
- Jobs
- Reise
- jpg
- Jupyter Notizbuch
- Wesentliche
- Kong
- See
- Sprache
- grosse
- Nachname
- starten
- ins Leben gerufen
- Führer
- LERNEN
- Cholesterinspiegel
- liegt
- Gefällt mir
- LIMIT
- Linien
- aus einer regionalen
- Standorte
- Standorte
- login
- Dur
- um
- verwalten
- verwaltet
- Management
- Manager
- viele
- Kann..
- Mittel
- Mechanismen
- Treffen
- MENÜ
- Metadaten
- könnte
- Migration
- Minuten
- ML
- ML-Algorithmen
- geändert
- mehr
- Bewegung
- Name
- Namen
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Navigieren
- Navigation
- Need
- Bedürfnisse
- Neu
- neue Funktion
- neu
- weiter
- Nlp
- Knoten
- beachten
- Notizbuch
- Laptops
- jetzt an
- Objekte
- of
- vorgenommen,
- on
- EINEM
- einzige
- XNUMXh geöffnet
- Open-Source-
- openssl
- Einkauf & Prozesse
- optimal
- Optimieren
- Option
- Optionen
- or
- Auftrag
- Organisation
- Andere
- übrig
- Paar
- Brot
- besondere
- besonders
- leidenschaftlich
- zahlen
- Leistung
- Durchführung
- Erlaubnis
- Berechtigungen
- Persönlich
- phd
- pii
- Platzhalter
- Plattform
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- erfahren
- Punkte
- Beliebt
- besitzt
- Post
- Praxis
- Erhaltung
- früher
- primär
- Datenschutz
- Privileg
- Privilegien
- Probleme
- Prozessdefinierung
- Verarbeitung
- Produktion
- Profil
- Profil
- Beweis
- Proof of Concept
- geschützt
- Sicherheit
- die
- bietet
- Bereitstellung
- Öffentlichkeit
- Zwecke
- Abfragen
- Lesen Sie mehr
- Lesebrillen
- bereit
- realen Welt
- Echtzeit
- empfehlen
- Rekord
- Erholung
- reduziert
- Reduzierung
- siehe
- bezieht sich
- spiegelt
- Region
- Registrieren
- eingetragen
- Vorschriften
- Release
- Mitteilungen
- relevant
- ersetzen
- falls angefordert
- Voraussetzungen:
- Ressourcen
- ressourcenintensiv
- Downloads
- Folge
- Die Ergebnisse
- Rechte
- Rollen
- Rollen
- REIHE
- rsa
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Führen Sie
- Laufen
- sagemaker
- gleich
- Speichern
- Abschnitt
- Verbindung
- Gesicherte
- Sicherheitdienst
- sehen
- Suchen
- wählen
- Senior
- empfindlich
- Server
- Serverlos
- Dienstleistungen
- Sitzung
- kompensieren
- Sets
- Einstellungen
- Setup
- sie
- Schild
- bedeutend
- ähnlich
- Einfacher
- Vereinfacht
- vereinfachen
- da
- Schnappschuss
- So
- Software
- Software-Entwicklung
- Lösung
- Lösungen
- LÖSEN
- einige
- Quelle
- Spark
- Spezialist
- spezialisiert
- SQL
- Stapel
- Stufe
- Anfang
- begonnen
- Beginnen Sie
- Aussagen
- Shritte
- Lagerung
- Läden
- Strategie
- Schnur
- Studio Adressen
- abschicken
- Subnetze
- Erfolg
- so
- ZUSAMMENFASSUNG
- Support
- Unterstützt
- sicher
- Syntax
- Systeme und Techniken
- Tabelle
- TAG
- nimmt
- Technische
- Techniken
- Vorlage
- Terminal
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- ihr
- Sie
- dann
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- nach drei
- Durch
- Zeit
- Zeitreise
- Timeline
- zu
- Tracking
- Transaktion
- Transaktion
- Transformation
- Transit
- reisen
- was immer dies auch sein sollte.
- vertraut
- Ts
- XNUMX
- tippe
- Typen
- ui
- für
- Unerwartet
- unbekannt
- Entriegelung
- Aktualisierung
- aktualisiert
- Aufrechterhaltung
- hochgeladen
- URI
- -
- Anwendungsfall
- benutzt
- Mitglied
- Nutzer
- Verwendung von
- validiert
- Wert
- verschiedene
- Version
- Sichtbarkeit
- Volumen
- Warehouse
- Lagerung
- we
- Netz
- Web-Services
- wann
- während
- welche
- während
- WHO
- werden wir
- mit
- .
- gearbeitet
- arbeiten,
- schreiben
- Jahr
- U
- Ihr
- Zephyrnet
- Null
- PLZ