Resilienz spielt eine entscheidende Rolle bei der Entwicklung jeder Arbeitsbelastung generative KI Arbeitsbelastungen sind nicht anders. Bei der Entwicklung generativer KI-Workloads unter dem Gesichtspunkt der Belastbarkeit sind besondere Überlegungen anzustellen. Das Verständnis und die Priorisierung der Resilienz ist für generative KI-Workloads von entscheidender Bedeutung, um die Anforderungen an organisatorische Verfügbarkeit und Geschäftskontinuität zu erfüllen. In diesem Beitrag besprechen wir die verschiedenen Stapel einer generativen KI-Arbeitslast und was diese Überlegungen sein sollten.
Generative Full-Stack-KI
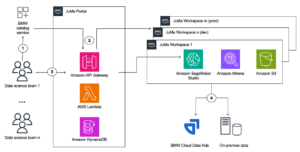
Obwohl sich ein Großteil der Begeisterung für generative KI auf die Modelle konzentriert, sind für eine vollständige Lösung Menschen, Fähigkeiten und Werkzeuge aus mehreren Bereichen erforderlich. Betrachten Sie das folgende Bild, das eine AWS-Ansicht des neuen a16z-Anwendungsstapels für große Sprachmodelle (LLMs) ist.
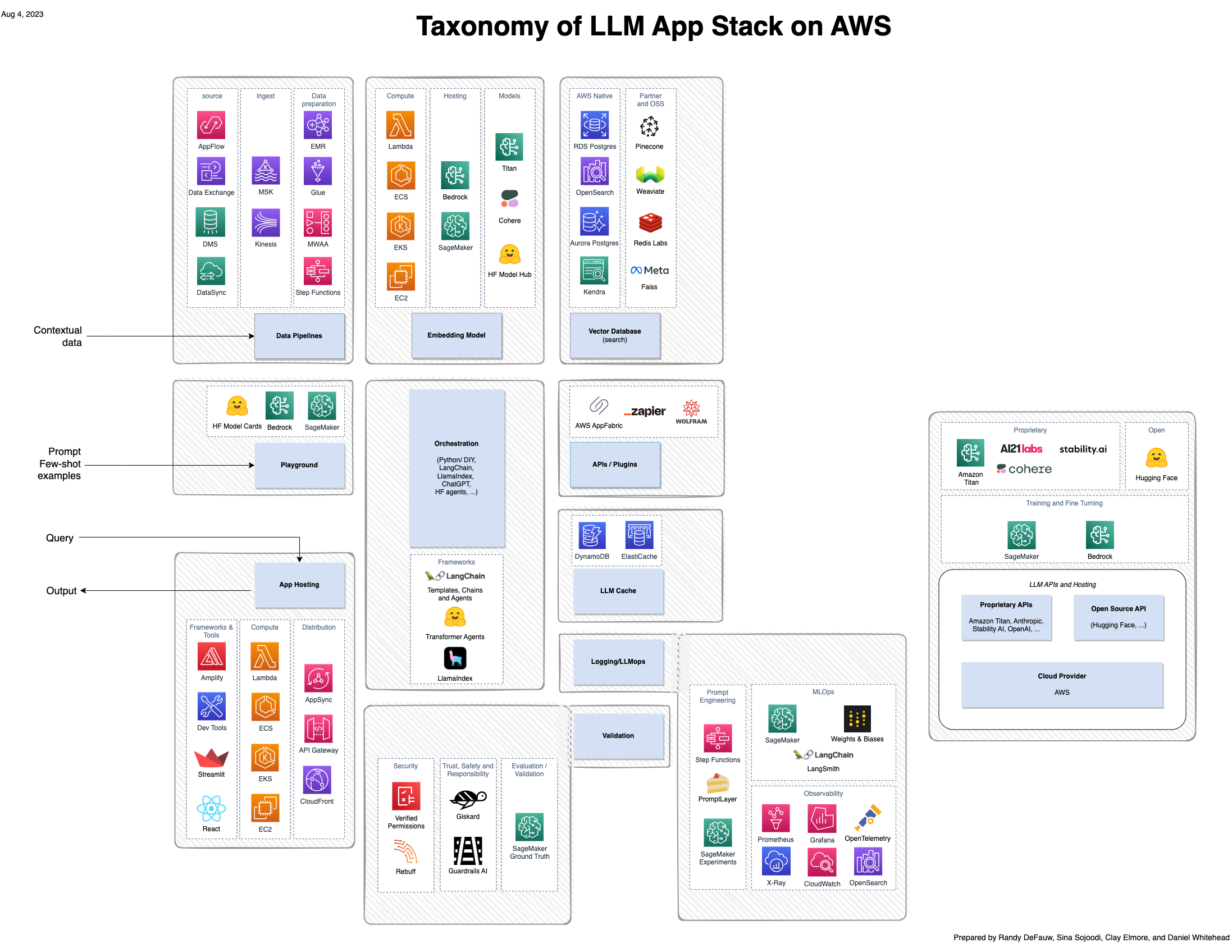
Im Vergleich zu einer traditionelleren Lösung, die auf KI und maschinellem Lernen (ML) basiert, umfasst eine generative KI-Lösung jetzt Folgendes:
- Neue Rollen – Man muss sowohl Modelltuner als auch Modellbauer und Modellintegratoren berücksichtigen
- Neue Werkzeuge – Der herkömmliche MLOps-Stack deckt nicht die Art der Experimentverfolgung oder Beobachtbarkeit ab, die für Prompt Engineering oder Agenten erforderlich ist, die Tools zur Interaktion mit anderen Systemen aufrufen
Argumentation des Agenten
Im Gegensatz zu herkömmlichen KI-Modellen ermöglicht Retrieval Augmented Generation (RAG) genauere und kontextrelevantere Antworten durch die Integration externer Wissensquellen. Im Folgenden sind einige Überlegungen zur Verwendung von RAG aufgeführt:
- Das Festlegen geeigneter Zeitüberschreitungen ist für das Kundenerlebnis wichtig. Nichts sagt mehr über eine schlechte Benutzererfahrung aus, als mitten in einem Chat zu sein und die Verbindung zu verlieren.
- Stellen Sie sicher, dass Sie die Prompt-Eingabedaten und die Prompt-Eingabegröße für die von Ihrem Modell definierten zugewiesenen Zeichengrenzen validieren.
- Wenn Sie Prompt Engineering durchführen, sollten Sie Ihre Prompts in einem zuverlässigen Datenspeicher speichern. Dies schützt Ihre Eingabeaufforderungen im Falle eines versehentlichen Verlusts oder als Teil Ihrer gesamten Disaster-Recovery-Strategie.
Datenpipelines
In Fällen, in denen Sie mithilfe des RAG-Musters Kontextdaten für das Basismodell bereitstellen müssen, benötigen Sie eine Datenpipeline, die die Quelldaten aufnehmen, in Einbettungsvektoren konvertieren und die Einbettungsvektoren in einer Vektordatenbank speichern kann. Diese Pipeline könnte eine Batch-Pipeline sein, wenn Sie Kontextdaten im Voraus vorbereiten, oder eine Pipeline mit geringer Latenz, wenn Sie neue Kontextdaten im laufenden Betrieb integrieren. Im Batch-Fall gibt es im Vergleich zu typischen Datenpipelines einige Herausforderungen.
Bei den Datenquellen kann es sich um PDF-Dokumente in einem Dateisystem, Daten aus einem Software-as-a-Service-System (SaaS) wie einem CRM-Tool oder Daten aus einem vorhandenen Wiki oder einer Wissensdatenbank handeln. Die Aufnahme aus diesen Quellen unterscheidet sich von den typischen Datenquellen wie Protokolldaten in einem Amazon Simple Storage-Service (Amazon S3) Bucket oder strukturierte Daten aus einer relationalen Datenbank. Der Grad der Parallelität, den Sie erreichen können, kann durch das Quellsystem begrenzt sein, daher müssen Sie die Drosselung berücksichtigen und Backoff-Techniken verwenden. Einige der Quellsysteme sind möglicherweise anfällig, daher müssen Sie eine Fehlerbehandlungs- und Wiederholungslogik einbauen.
Das Einbettungsmodell könnte einen Leistungsengpass darstellen, unabhängig davon, ob Sie es lokal in der Pipeline ausführen oder ein externes Modell aufrufen. Einbettungsmodelle sind Basismodelle, die auf GPUs laufen und nicht über unbegrenzte Kapazität verfügen. Wenn das Modell lokal ausgeführt wird, müssen Sie die Arbeit basierend auf der GPU-Kapazität zuweisen. Wenn das Modell extern ausgeführt wird, müssen Sie sicherstellen, dass Sie das externe Modell nicht überlasten. In beiden Fällen wird der Grad der Parallelität, den Sie erreichen können, vom Einbettungsmodell bestimmt und nicht davon, wie viel CPU und RAM Ihnen im Stapelverarbeitungssystem zur Verfügung stehen.
Im Fall einer geringen Latenz müssen Sie die Zeit berücksichtigen, die zum Generieren der Einbettungsvektoren benötigt wird. Die aufrufende Anwendung sollte die Pipeline asynchron aufrufen.
Vektordatenbanken
Eine Vektordatenbank hat zwei Funktionen: Einbettungsvektoren speichern und eine Ähnlichkeitssuche durchführen, um den nächstgelegenen zu finden k entspricht einem neuen Vektor. Es gibt drei allgemeine Arten von Vektordatenbanken:
- Dedizierte SaaS-Optionen wie Pinecone.
- In andere Dienste integrierte Vektordatenbankfunktionen. Dazu gehören native AWS-Dienste wie Amazon OpenSearch-Dienst und Amazonas-Aurora.
- In-Memory-Optionen, die für transiente Daten in Szenarien mit geringer Latenz verwendet werden können.
Auf die Ähnlichkeitssuchfunktionen gehen wir in diesem Beitrag nicht im Detail ein. Obwohl sie wichtig sind, stellen sie einen funktionalen Aspekt des Systems dar und haben keinen direkten Einfluss auf die Belastbarkeit. Stattdessen konzentrieren wir uns auf die Resilienzaspekte einer Vektordatenbank als Speichersystem:
- Latency – Kann die Vektordatenbank einer hohen oder unvorhersehbaren Belastung standhalten? Ist dies nicht der Fall, muss die aufrufende Anwendung die Ratenbegrenzung, den Backoff und den erneuten Versuch übernehmen.
- Skalierbarkeit – Wie viele Vektoren kann das System aufnehmen? Wenn Sie die Kapazität der Vektordatenbank überschreiten, müssen Sie sich mit Sharding oder anderen Lösungen befassen.
- Hochverfügbarkeit und Notfallwiederherstellung – Das Einbetten von Vektoren stellt wertvolle Daten dar und ihre Neuerstellung kann teuer sein. Ist Ihre Vektordatenbank in einer einzigen AWS-Region hochverfügbar? Ist es möglich, Daten für Notfallwiederherstellungszwecke in eine andere Region zu replizieren?
Anwendungsebene
Bei der Integration generativer KI-Lösungen gibt es drei einzigartige Überlegungen zur Anwendungsebene:
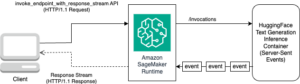
- Möglicherweise hohe Latenz – Foundation-Modelle laufen oft auf großen GPU-Instanzen und verfügen möglicherweise über eine begrenzte Kapazität. Stellen Sie sicher, dass Sie Best Practices für Ratenbegrenzung, Backoff und Wiederholung sowie Lastabwurf anwenden. Verwenden Sie asynchrone Designs, damit die Hauptschnittstelle der Anwendung nicht durch hohe Latenz beeinträchtigt wird.
- Sicherheitslage – Wenn Sie Agenten, Tools, Plugins oder andere Methoden zum Verbinden eines Modells mit anderen Systemen verwenden, achten Sie besonders auf Ihren Sicherheitsstatus. Modelle versuchen möglicherweise, auf unerwartete Weise mit diesen Systemen zu interagieren. Befolgen Sie die übliche Praxis des Zugriffs mit den geringsten Rechten, indem Sie beispielsweise eingehende Eingabeaufforderungen von anderen Systemen einschränken.
- Sich schnell weiterentwickelnde Frameworks – Open-Source-Frameworks wie LangChain entwickeln sich rasant weiter. Verwenden Sie einen Microservices-Ansatz, um andere Komponenten aus diesen weniger ausgereiften Frameworks zu isolieren.
Kapazität
Wir können über Kapazität in zwei Kontexten nachdenken: Inferenz- und Trainingsmodell-Datenpipelines. Die Kapazität ist ein Gesichtspunkt, wenn Unternehmen ihre eigenen Pipelines bauen. CPU- und Speicheranforderungen sind zwei der größten Anforderungen bei der Auswahl von Instanzen zur Ausführung Ihrer Arbeitslasten.
Instanzen, die generative KI-Workloads unterstützen können, können schwieriger zu erhalten sein als Ihr durchschnittlicher Allzweck-Instanztyp. Instanzflexibilität kann bei der Kapazitäts- und Kapazitätsplanung hilfreich sein. Je nachdem, in welcher AWS-Region Sie Ihre Arbeitslast ausführen, stehen verschiedene Instanztypen zur Verfügung.
Für die kritischen Benutzerreisen sollten Unternehmen die Reservierung oder Vorabbereitstellung von Instanztypen in Betracht ziehen, um die Verfügbarkeit bei Bedarf sicherzustellen. Mit diesem Muster wird eine statisch stabile Architektur erreicht, was eine bewährte Methode für Ausfallsicherheit darstellt. Weitere Informationen zur statischen Stabilität in der Zuverlässigkeitssäule des AWS Well-Architected Framework finden Sie unter Nutzen Sie statische Stabilität, um bimodales Verhalten zu verhindern.
Beobachtbarkeit
Neben den Ressourcenmetriken, die Sie normalerweise sammeln, wie CPU- und RAM-Auslastung, müssen Sie die GPU-Auslastung genau überwachen, wenn Sie ein Modell darauf hosten Amazon Sage Maker or Amazon Elastic Compute-Cloud (Amazon EC2). Die GPU-Auslastung kann sich unerwartet ändern, wenn sich das Basismodell oder die Eingabedaten ändern, und ein Mangel an GPU-Speicher kann das System in einen instabilen Zustand versetzen.
Weiter oben im Stapel möchten Sie auch den Anruffluss durch das System verfolgen und die Interaktionen zwischen Agenten und Tools erfassen. Da die Schnittstelle zwischen Agenten und Tools weniger formal definiert ist als ein API-Vertrag, sollten Sie diese Traces nicht nur auf Leistung überwachen, sondern auch, um neue Fehlerszenarien zu erfassen. Um das Modell oder den Agenten auf Sicherheitsrisiken und Bedrohungen zu überwachen, können Sie Tools wie verwenden Amazon-Wachdienst.
Sie sollten auch Basislinien für Einbettungsvektoren, Eingabeaufforderungen, Kontext und Ausgabe sowie die Interaktionen zwischen diesen erfassen. Wenn sich diese im Laufe der Zeit ändern, kann dies darauf hindeuten, dass Benutzer das System auf neue Weise nutzen, dass die Referenzdaten den Frageraum nicht auf die gleiche Weise abdecken oder dass die Ausgabe des Modells plötzlich anders ist.
Katastrophale Erholung
Ein Business-Continuity-Plan mit einer Disaster-Recovery-Strategie ist für jede Arbeitslast ein Muss. Generative KI-Workloads sind nicht anders. Das Verständnis der Fehlermodi, die für Ihre Arbeitslast gelten, wird Ihnen bei Ihrer Strategie helfen. Wenn Sie AWS-verwaltete Dienste für Ihre Arbeitslast verwenden, z Amazonas Grundgestein und SageMaker stellen Sie sicher, dass der Dienst in Ihrer AWS-Wiederherstellungsregion verfügbar ist. Zum jetzigen Zeitpunkt unterstützen diese AWS-Services die Replikation von Daten über AWS-Regionen hinweg nicht nativ. Daher müssen Sie über Ihre Datenverwaltungsstrategien für die Notfallwiederherstellung nachdenken und möglicherweise auch eine Feinabstimmung in mehreren AWS-Regionen vornehmen.
Zusammenfassung
In diesem Beitrag wurde beschrieben, wie Resilienz beim Aufbau generativer KI-Lösungen berücksichtigt werden kann. Obwohl generative KI-Anwendungen einige interessante Nuancen aufweisen, gelten die bestehenden Resilienzmuster und Best Practices weiterhin. Es geht lediglich darum, jeden Teil einer generativen KI-Anwendung zu bewerten und die relevanten Best Practices anzuwenden.
Weitere Informationen zur generativen KI und ihrer Verwendung mit AWS-Services finden Sie in den folgenden Ressourcen:
Über die Autoren
 Jennifer Moran ist ein AWS Senior Resiliency Specialist Solutions Architect mit Sitz in New York City. Sie verfügt über einen vielfältigen Hintergrund, hat in vielen technischen Disziplinen gearbeitet, darunter Softwareentwicklung, agile Führung und DevOps, und setzt sich für Frauen in der Technologiebranche ein. Es macht ihr Spaß, Kunden bei der Entwicklung resilienter Lösungen zur Verbesserung der Resilienzhaltung zu unterstützen und spricht öffentlich über alle Themen im Zusammenhang mit Resilienz.
Jennifer Moran ist ein AWS Senior Resiliency Specialist Solutions Architect mit Sitz in New York City. Sie verfügt über einen vielfältigen Hintergrund, hat in vielen technischen Disziplinen gearbeitet, darunter Softwareentwicklung, agile Führung und DevOps, und setzt sich für Frauen in der Technologiebranche ein. Es macht ihr Spaß, Kunden bei der Entwicklung resilienter Lösungen zur Verbesserung der Resilienzhaltung zu unterstützen und spricht öffentlich über alle Themen im Zusammenhang mit Resilienz.
 Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Er ist 2013 in den Big-Data-Bereich eingestiegen und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Er ist 2013 in den Big-Data-Bereich eingestiegen und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 100
- 2013
- 90
- a
- a16z
- Fähigkeit
- Über uns
- Zugang
- zufällig
- Konto
- genau
- Erreichen
- Erreicht
- über
- aktiv
- vorantreiben
- Anwalt
- beeinflussen
- gegen
- Makler
- Agenten
- agil
- AI
- KI-Modelle
- Alle
- zugeordnet
- erlaubt
- ebenfalls
- Obwohl
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- und
- Ein anderer
- jedem
- Bienen
- App
- anwendbar
- Anwendung
- Anwendungen
- Jetzt bewerben
- Anwendung
- Ansatz
- angemessen
- Architektur
- SIND
- Bereich
- um
- AS
- Aussehen
- Aspekte
- At
- Aufmerksamkeit
- Augmented
- Autonom
- autonome Fahrzeuge
- Verfügbarkeit
- verfügbar
- durchschnittlich
- AWS
- Hintergrund
- Badewanne
- Base
- basierend
- BE
- weil
- Sein
- BESTE
- Best Practices
- zwischen
- Big
- Big Data
- Größte
- Engpass
- bauen
- Bauherren
- Building
- erbaut
- Geschäft
- Geschäftskontinuität
- aber
- by
- rufen Sie uns an!
- Aufruf
- Aufrufe
- CAN
- Fähigkeiten
- Kapazität
- Erfassung
- Capturing
- Häuser
- Fälle
- Herausforderungen
- Übernehmen
- Änderungen
- Charakter
- Chat
- Auswahl
- Stadt
- eng
- sammeln
- Colorados
- verglichen
- abschließen
- Komponenten
- Berechnen
- Computer
- Computer Vision
- Kongressbegleitung
- Sich zusammenschliessen
- Geht davon
- Berücksichtigung
- Überlegungen
- Kontext
- Kontexte
- kontextuelle
- weiter
- Kontinuität
- Vertrag
- verkaufen
- könnte
- Paar
- Abdeckung
- Abdeckung
- CPU
- kritischem
- CRM
- wichtig
- Kunde
- Customer Experience
- Kunden
- technische Daten
- Datenmanagement
- Datenbase
- Datenbanken
- definiert
- Abhängig
- beschrieben
- Design
- Entwerfen
- Designs
- Detail
- Entwicklung
- DevOps
- diktiert
- anders
- schwer
- Direkt
- Katastrophe
- Disziplinen
- getrennt
- diskutieren
- verschieden
- do
- Unterlagen
- die
- Tut nicht
- Domains
- Nicht
- jeder
- entweder
- Einbettung
- aufstrebenden
- Entwicklung
- gewährleisten
- eingegeben
- Fehler
- Äther (ETH)
- Auswerten
- sich entwickelnden
- Beispiel
- überschreiten
- Aufregung
- vorhandenen
- teuer
- ERFAHRUNGEN
- Experiment
- ERKUNDEN
- erweitern
- extern
- äußerlich
- extra
- Scheitern
- Eigenschaften
- Reichen Sie das
- Finden Sie
- Flexibilität
- Fluss
- Setzen Sie mit Achtsamkeit
- konzentriert
- folgen
- Folgende
- Aussichten für
- Formal
- Foundation
- Unser Ansatz
- Gerüste
- für
- funktional
- Funktionen
- Allgemeines
- allgemeiner Zweck
- erzeugen
- Generation
- generativ
- Generative KI
- bekommen
- GPU
- GPUs
- Guide
- Griff
- Handling
- Haben
- mit
- he
- Statt
- Hilfe
- Unternehmen
- GUTE
- hoch
- hält
- Gastgeber
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- if
- wichtig
- zu unterstützen,
- in
- Dazu gehören
- Einschließlich
- Eingehende
- einarbeiten
- zeigen
- Information
- Varianten des Eingangssignals:
- Instanz
- Instanzen
- beantragen müssen
- Integration
- interagieren
- Interaktionen
- interessant
- Schnittstelle
- einmischen
- in
- beinhaltet
- IT
- Reisen
- nur
- Wissen
- Sprache
- grosse
- Latency
- Leadership
- LERNEN
- lernen
- Lens
- weniger
- Niveau
- Gefällt mir
- Limitiert
- Begrenzung
- Grenzen
- llm
- Belastung
- örtlich
- Log
- Logik
- aussehen
- Verlust
- Los
- Maschine
- Maschinelles Lernen
- Main
- um
- verwaltet
- Management
- viele
- Streichhölzer
- Materie
- reifen
- Kann..
- MBA
- Triff
- Memory
- Methoden
- Metrik
- Michigan
- Microservices
- Mitte
- ML
- MLOps
- Modell
- für
- Modi
- Überwachen
- mehr
- viel
- mehrere
- sollen
- nativen
- nativ
- notwendig,
- Need
- erforderlich
- Bedürfnisse
- Neu
- New York
- New York City
- nicht
- normal
- nichts
- jetzt an
- Abschattung
- und viele
- erhalten
- of
- vorgenommen,
- on
- einzige
- XNUMXh geöffnet
- Open-Source-
- Optionen
- or
- organisatorisch
- Organisationen
- Andere
- Möglichkeiten für das Ausgangssignal:
- übrig
- Gesamt-
- besitzen
- Teil
- Schnittmuster
- Muster
- AUFMERKSAMKEIT
- Personen
- ausführen
- Leistung
- Durchführung
- ein Bild
- Säule
- Pipeline
- zentrale
- Plan
- Planung
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielt
- Plugins
- für einige Positionen
- Post
- Praxis
- Praktiken
- Danach
- vorgeführt
- verhindern
- Principal
- Priorisierung
- Verarbeitung
- Produkt
- Produktmanagement
- Projekte
- Eingabeaufforderungen
- die
- öffentlich
- Zwecke
- setzen
- Frage
- Lappen
- RAM
- Bereich
- schnell
- Bewerten
- lieber
- Erholung
- siehe
- Referenz
- Ungeachtet
- Region
- Regionen
- bezogene
- relevant
- Zuverlässigkeit
- zuverlässig
- Replikation
- Voraussetzungen:
- Elastizität
- federnde
- Ressourcen
- Downloads
- Antworten
- einschränkend
- Abruf
- Risiken
- Rollen
- Führen Sie
- Laufen
- läuft
- SaaS
- sagemaker
- gleich
- sagt
- Szenarien
- Suche
- Suche
- Sicherheitdienst
- Sicherheitsrisiken
- Senior
- Dienstleistungen
- mehrere
- sharding
- sie
- vergießen
- sollte
- Einfacher
- Single
- Größe
- Fähigkeiten
- So
- Software
- Software als Service
- Software-Entwicklung
- Softwareentwicklung
- Lösung
- Lösungen
- einige
- Quelle
- Quellen
- Raumfahrt
- spricht
- Spezialist
- Stabilität
- stabil
- Stapel
- Stacks
- Bundesstaat
- Immer noch
- Lagerung
- speichern
- Strategien
- Strategie
- strukturierte
- so
- Support
- sicher
- System
- Systeme und Techniken
- Nehmen
- nimmt
- Taxonomie
- Tech
- Technische
- Techniken
- Technologie
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- ihr
- Sie
- Dort.
- Diese
- vom Nutzer definierten
- think
- fehlen uns die Worte.
- diejenigen
- Bedrohungen
- nach drei
- Durch
- Tier
- Zeit
- zu
- Werkzeug
- Werkzeuge
- Themen
- Spur
- Tracking
- traditionell
- Ausbildung
- versuchen
- XNUMX
- tippe
- Typen
- typisch
- typisch
- Verständnis
- Unerwartet
- einzigartiges
- Universität
- University of Michigan
- unbegrenzt
- unberechenbar
- -
- benutzt
- Mitglied
- Benutzererfahrung
- Nutzer
- Verwendung von
- BESTÄTIGEN
- wertvoll
- Vielfalt
- Fahrzeuge
- Anzeigen
- Seh-
- wollen
- Weg..
- Wege
- we
- Netz
- Web-Services
- GUT
- Was
- wann
- ob
- welche
- werden wir
- mit
- Damen
- Frauen in Tech
- Arbeiten
- gearbeitet
- arbeiten,
- Schreiben
- York
- U
- Ihr
- Zephyrnet