SmugMug driver to meget store online fotoplatforme, SmugMug , Flickr, hvilket gør det muligt for mere end 100 millioner kunder sikkert at opbevare, søge, dele og sælge titusinder af billeder. Kunder, der uploadede og søgte gennem årtiers billeder, hjalp med at gøre søgning til kritisk infrastruktur, der voksede støt siden SmugMug første gang blev brugt Amazon CloudSearch i 2012, efterfulgt af Amazon OpenSearch Service siden 2018, efter at have nået milliarder af dokumenter og terabytes søgelager.
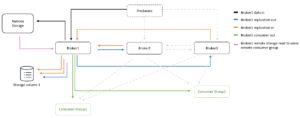
Her deler Lee Shepherd, SmugMug Staff Engineer, SmugMugs søgearkitektur, der bruges til at publicere, udfylde og spejle live trafik til flere klynger. SmugMug bruger disse pipelines til at benchmarke, validere og migrere til nye konfigurationer, herunder Graviton-baserede r6gd.2xlarge-instanser fra i3.2xlarge, sammen med testning Amazon OpenSearch Serverløs. Vi dækker tre pipelines, der bruges til publicering, udfyldning og forespørgsel uden at introducere spidse urealistiske trafikmønstre og uden nogen indvirkning på produktionstjenester.
Der er to vigtigste arkitektoniske stykker, der er afgørende for processen:
- En holdbar kilde til sandhed for indeksdata. Det er bedste praksis og en del af vores backup-strategi for at have en holdbar butik ud over OpenSearch-indekset, og Amazon DynamoDB giver skalerbarhed og integration med AWS Lambda det forenkler meget af processen. Vi bruger DynamoDB til andre ikke-søgetjenester, så dette var en naturlig pasform.
- En Lambda-funktion til at publicere data fra sandhedens kilde i OpenSearch. Ved brug af funktionsaliasser hjælper med at køre flere konfigurationer af den samme Lambda-funktion på samme tid og er nøglen til at holde data synkroniseret.
Publicering
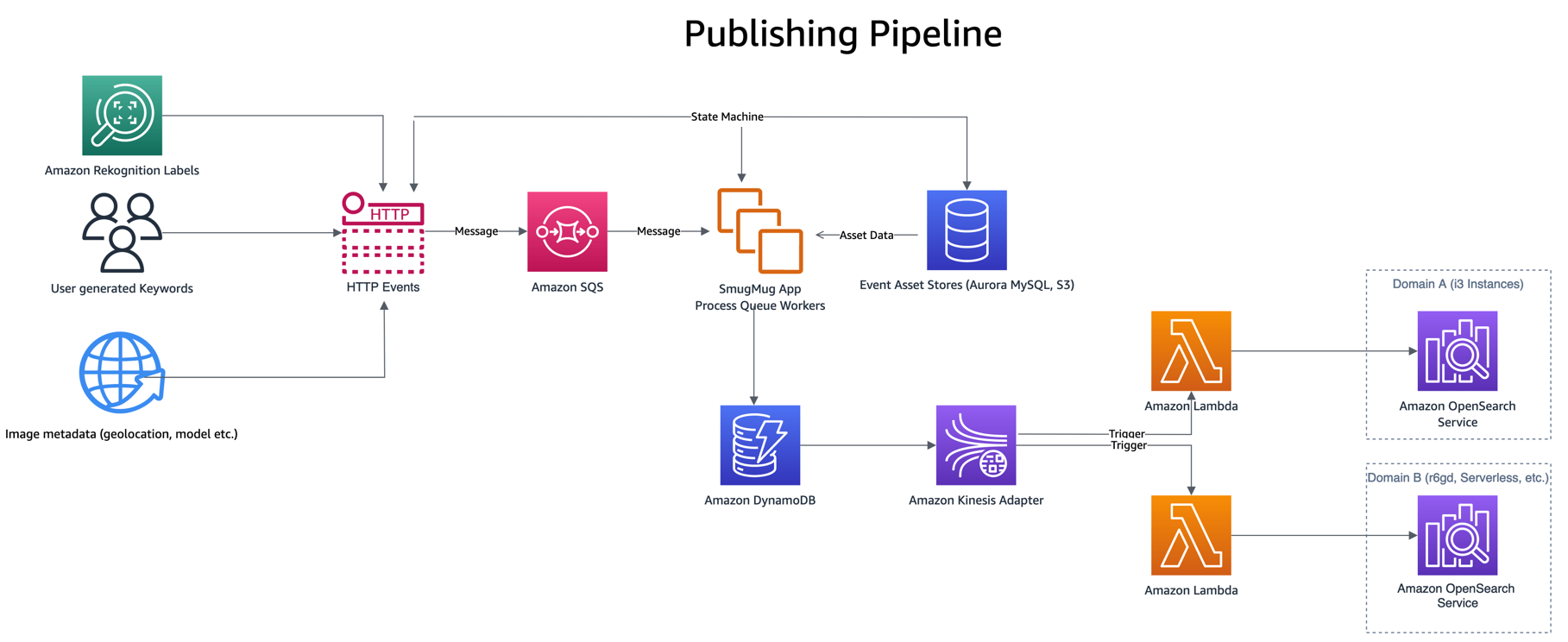
Udgivelsespipelinen er drevet af begivenheder som en bruger, der indtaster søgeord eller billedtekster, nye uploads eller etiketregistrering via Amazon-anerkendelse. Disse hændelser behandles ved at kombinere data fra et par andre aktivbutikker som f.eks Amazon Aurora MySQL-kompatibel udgave , Amazon Simple Storage Service (Amazon S3), før du skriver et enkelt element i DynamoDB.
At skrive til DynamoDB påberåber sig en Lambda-udgivelsesfunktion gennem DynamoDB Streams Kinesis Adapter, der tager en batch af opdaterede elementer fra DynamoDB og indekserer dem i OpenSearch. Der er andre fordele ved at bruge DynamoDB Streams Kinesis Adapter, såsom at reducere antallet af samtidige lambdaer, der kræves.
Den publicerende Lambda-funktion bruger miljøvariabler til at bestemme hvilket OpenSearch-domæne og hvilket indeks, der skal publiceres til. Et produktionsalias er konfigureret til at skrive til produktions-OpenSearch-domænet uden for DynamoDB-tabellen eller Kinesis Stream
Ved test af nye konfigurationer eller migrering konfigureres et migreringsalias til at skrive til det nye OpenSearch-domæne, men bruge samme trigger som produktionsaliaset. Dette muliggør dobbelt indeksering af data til begge OpenSearch Service-domæner samtidigt.
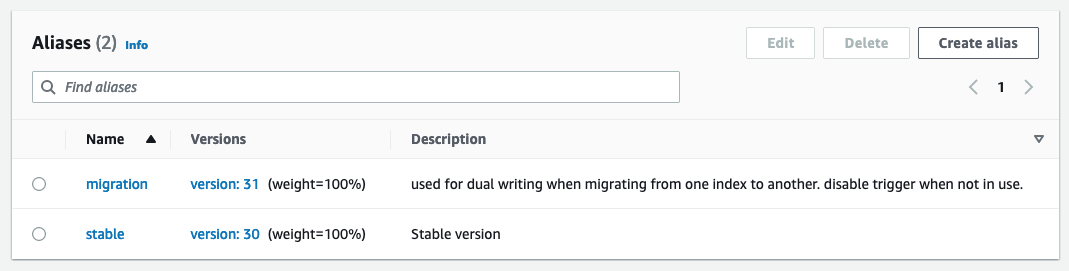
Her er et eksempel på DynamoDB-tabelskemaet:
'LastUpdated'-værdien bruges som dokumentversionen ved indeksering, hvilket gør det muligt for OpenSearch at afvise alle opdateringer, der ikke er i orden.
Genopfyldning
Nu hvor ændringer bliver offentliggjort på begge domæner, skal det nye domæne (indeks) udfyldes med historiske data. For at udfylde et nyoprettet indeks skal en kombination af Amazon Simple Queue Service (Amazon SQS) og DynamoDB bruges. Et script udfylder en SQS-kø med beskeder, der indeholder instruktioner til parallel scanning et segment af DynamoDB-tabellen.
SQS-køen starter en Lambda-funktion, der læser beskedinstruktionerne, henter en batch af elementer fra det tilsvarende segment af DynamoDB-tabellen og skriver dem ind i et OpenSearch-indeks. Nye beskeder skrives til SQS-køen for at holde styr på fremskridt gennem segmentet. Når segmentet er fuldført, skrives der ikke flere beskeder til SQS-køen, og processen stopper af sig selv.
Samtidighed bestemmes af antallet af segmenter, med yderligere kontroller leveret af Lambdas samtidighedsskalering. SmugMug er i stand til at indeksere mere end 1 milliard dokumenter i timen på deres OpenSearch-konfiguration, uden at det har nogen indvirkning på produktionsdomænet.
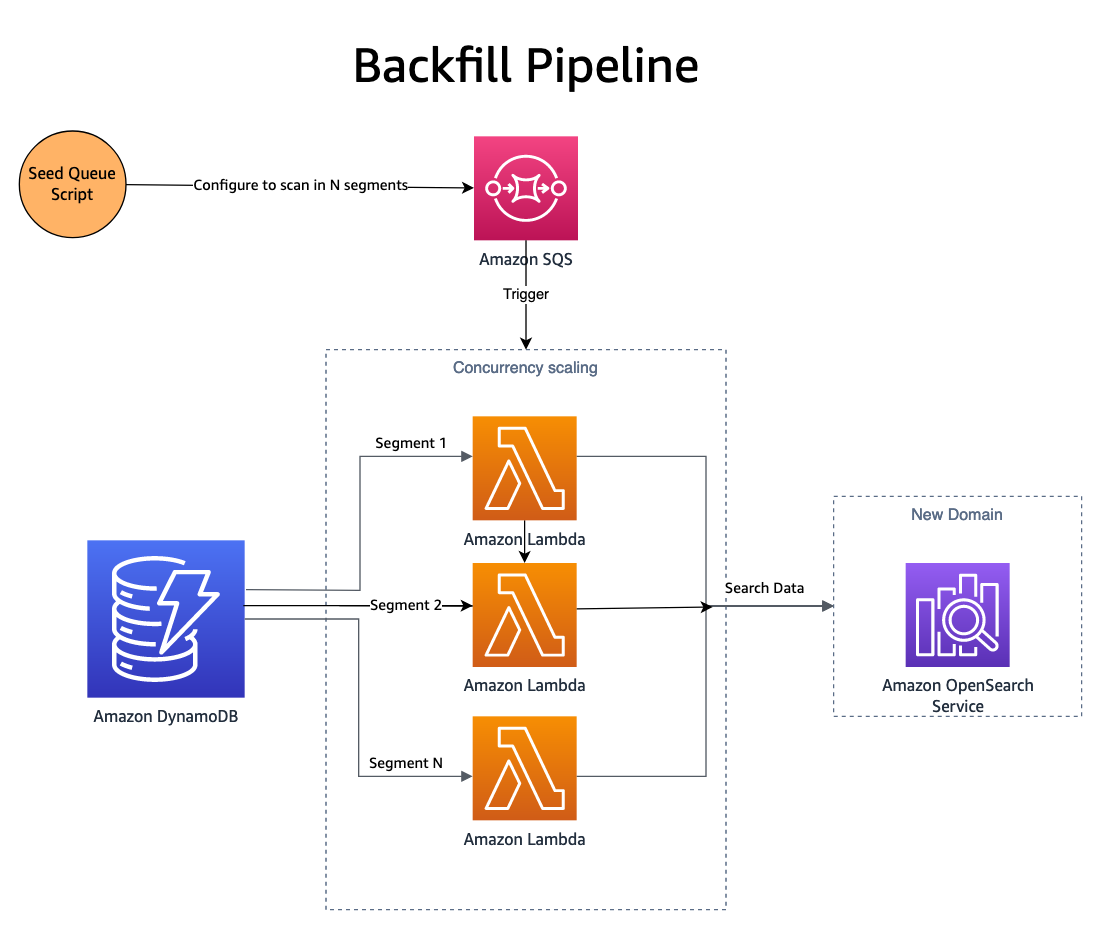
Et NodeJS AWS-SDK-baseret script bruges til at seede SQS-køen. Her er et uddrag af SQS-konfigurationsscriptets muligheder:
Sammen med formatet af den resulterende SQS-meddelelse:
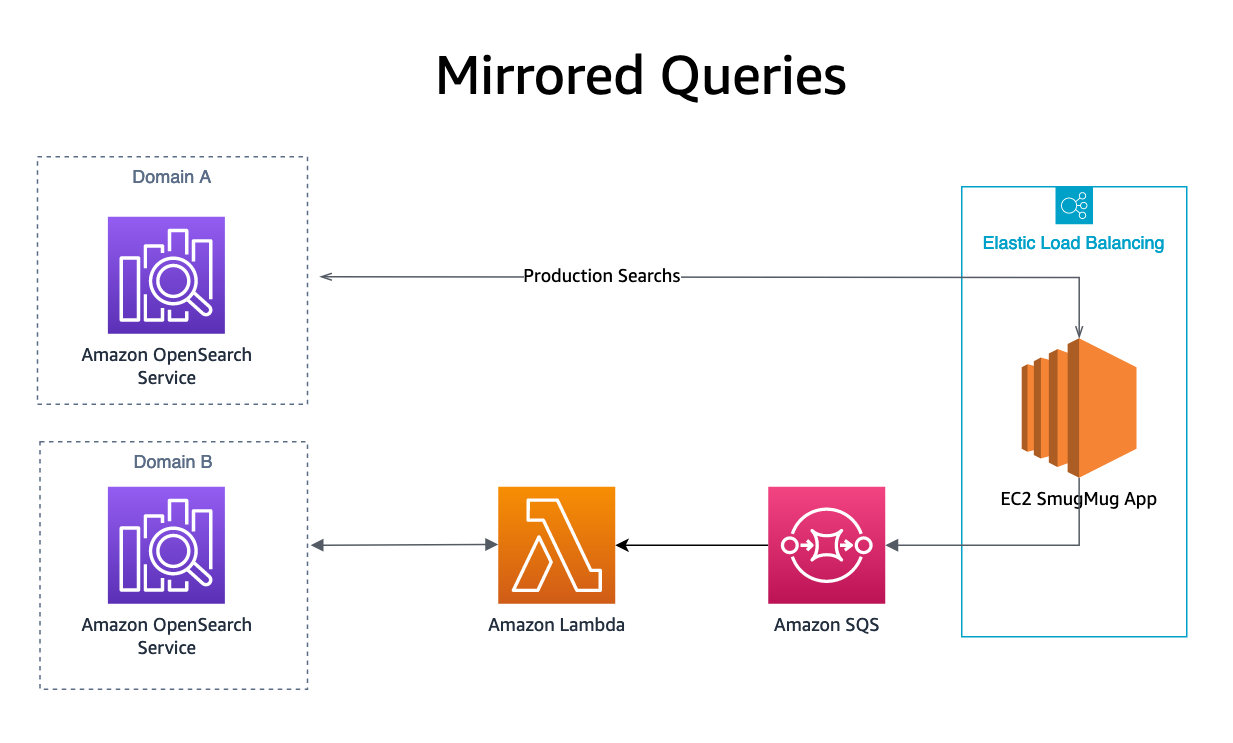
Spejling
Sidst vores spejlet søgeforespørgsel resultater køres ved at sende en OpenSearch-forespørgsel til en SQS-kø ud over vores produktionsdomæne. SQS-køen starter en Lambda-funktion, der afspiller forespørgslen til replikadomænet. Søgeresultaterne fra disse anmodninger sendes ikke til nogen bruger, men tillader replikering af produktionsbelastning på OpenSearch-tjenesten, der testes, uden at det påvirker produktionssystemer eller kunder.
Konklusion
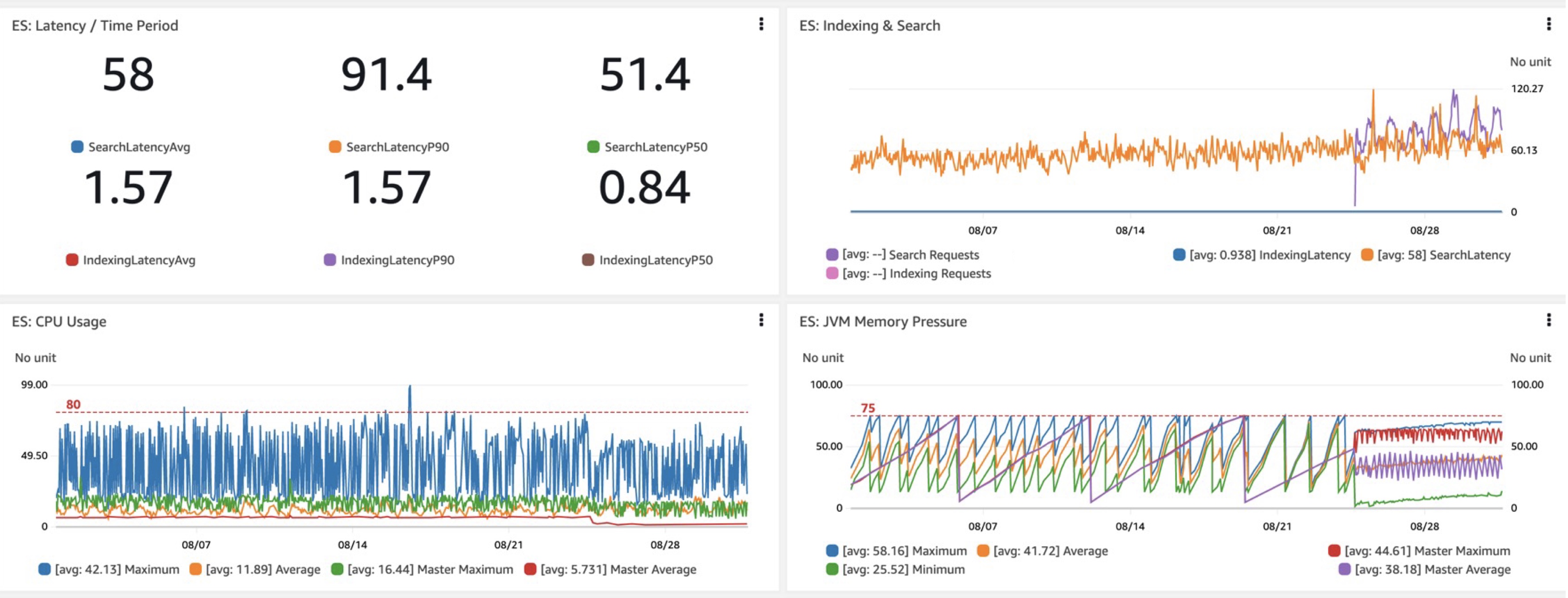
Når vi evaluerer et nyt OpenSearch-domæne eller en ny konfiguration, er de vigtigste målinger, vi er interesserede i, forespørgselsforsinkelsesydelse, nemlig de tog latenser (latenser pr. gang), og vigtigst af alt, latenser for søgning. I vores skift til Graviton R6gd så vi omkring 40 procent lavere P50-P99 latenser, sammen med lignende gevinster i CPU-brug sammenlignet med i3'er (ignorerer Gravitons lavere omkostninger). En anden velkommen fordel var det mere forudsigelige og overvågelige JVM-hukommelsestryk med ændringerne af affaldsindsamlingen fra tilføjelsen af G1GC på R6gd og andre nye forekomster.
Ved at bruge denne pipeline tester vi også OpenSearch Serverless og finder dets bedste use-cases. Vi er begejstrede for den service og agter fuldt ud at have en fuldstændig serverløs arkitektur med tiden. Følg med for resultater.
Om forfatterne
Lee Shepherd er en SmugMug Staff Software Engineer
Aydn Bekirov er en Amazon Web Services Principal Technical Account Manager
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :er
- :ikke
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- I stand
- Om
- Konto
- tilføjet
- Desuden
- Yderligere
- Efter
- tillade
- tillade
- sammen
- også
- Amazon
- Amazon Web Services
- an
- ,
- En anden
- enhver
- arkitektonisk
- arkitektur
- ER
- AS
- aktiv
- At
- Aurora
- AWS
- backup
- baseret
- BE
- før
- være
- benchmark
- gavner det dig
- fordele
- BEDSTE
- Beyond
- Billion
- milliarder
- både
- men
- by
- billedtekster
- Ændringer
- samling
- kombination
- kombinerer
- sammenlignet
- kompatibel
- Fuldender
- konkurrent
- Konfiguration
- konfigureret
- indeholder
- kontrol
- Tilsvarende
- Omkostninger
- dæksel
- CPU
- oprettet
- kritisk
- Kritisk infrastruktur
- Kunder
- data
- årtier
- Detektion
- Bestem
- bestemmes
- dokumentet
- dokumenter
- domæne
- Domæner
- drevet
- hver
- muliggør
- muliggør
- Endpoint
- ingeniør
- indtastning
- helt
- Miljø
- Ether (ETH)
- evaluere
- begivenheder
- eksempel
- ophidset
- få
- Fields
- finde
- Fornavn
- passer
- efterfulgt
- Til
- format
- fra
- fuldt ud
- funktion
- gevinster
- Dyrkning
- Have
- højde
- hjulpet
- hjælper
- historisk
- time
- HTML
- http
- HTTPS
- i
- i3
- ID
- KIMOs Succeshistorier
- vigtigere
- in
- Herunder
- indeks
- indekser
- Infrastruktur
- forekomster
- anvisninger
- integration
- hensigt
- interesseret
- ind
- indføre
- påberåber sig
- Varer
- iteration
- ITS
- selv
- jpg
- Holde
- holde
- Nøgle
- søgeord
- etiket
- stor
- Latency
- lanceringer
- Lee
- ligesom
- leve
- belastning
- Lot
- lavere
- Main
- Hukommelse
- besked
- beskeder
- Metrics
- migrere
- migrere
- migration
- million
- millioner kunder
- spejl
- mere
- mest
- bevæge sig
- flere
- MySQL
- navn
- nemlig
- Natural
- behov
- Ny
- nyligt
- næste
- ingen
- nummer
- of
- off
- on
- online
- opererer
- Indstillinger
- vælger
- or
- Andet
- vores
- Parallel
- del
- mønstre
- per
- procent
- ydeevne
- foto
- pics
- stykker
- pipeline
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Forudsigelig
- tryk
- tidligere
- Main
- behandle
- bearbejdet
- produktion
- Progress
- forudsat
- giver
- offentliggøre
- offentliggjort
- Publicering
- nå
- reducere
- svar
- anmodninger
- påkrævet
- resulterer
- Resultater
- Kør
- sikkert
- samme
- så
- Skalerbarhed
- skalering
- script
- Søg
- søgning
- frø
- segment
- segmenter
- sælger
- afsendelse
- sendt
- Serverless
- tjeneste
- Tjenester
- Del
- Aktier
- lignende
- Simpelt
- samtidigt
- siden
- enkelt
- uddrag
- So
- Software
- Kilde
- Personale
- forblive
- støt
- stopper
- opbevaring
- butik
- forhandler
- Strategi
- vandløb
- sådan
- Systemer
- bord
- tager
- Teknisk
- tiere
- prøve
- Test
- end
- at
- The Source
- deres
- Them
- Der.
- Disse
- denne
- tre
- Gennem
- tid
- til
- tog
- spor
- Trafik
- udløse
- Sandheden
- TUR
- to
- under
- opdateret
- opdateringer
- Uploading
- URL
- Brug
- brug
- brugssager
- anvendte
- Bruger
- bruger
- ved brug af
- VALIDATE
- værdi
- udgave
- meget
- var
- we
- web
- webservices
- velkommen
- Hvad
- hvornår
- mens
- med
- uden
- skriver
- skrivning
- skriftlig
- zephyrnet
- nul