图片作者
在这篇文章中,我们将探索名为 Mixtral 8x7b 的最先进的新开源模型。我们还将学习如何使用 LLaMA C++ 库访问它以及如何在减少的计算和内存上运行大型语言模型。
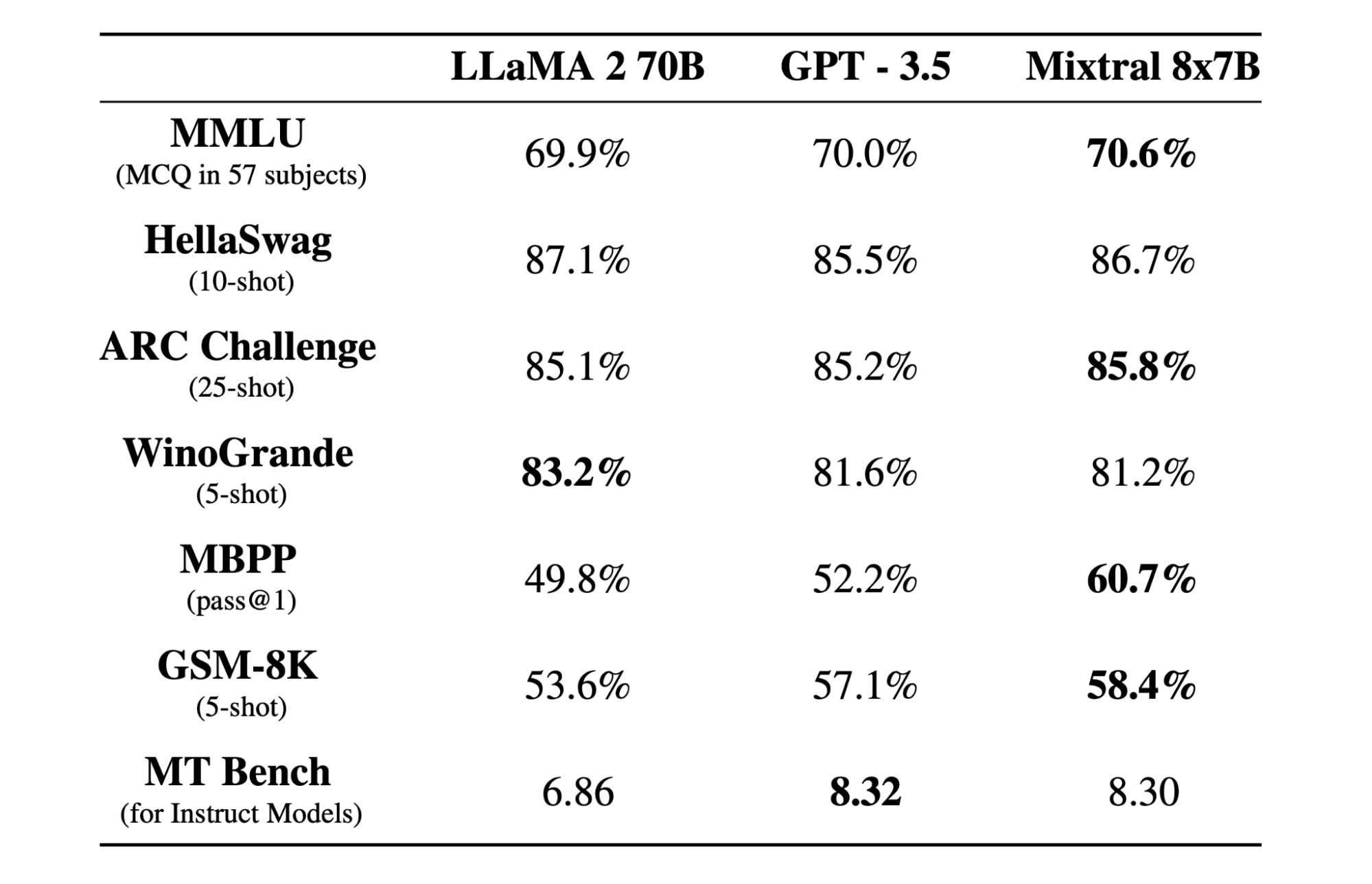
混合8x7b 是由 Mistral AI 创建的具有开放权重的高质量稀疏专家混合 (SMoE) 模型。它在 Apache 2.0 下获得许可,在大多数基准测试中均优于 Llama 2 70B,同时推理速度提高了 6 倍。 Mixtral 在大多数标准基准测试中均匹配或击败 GPT3.5,并且是就成本/性能而言最佳的开放权重模型。
图片来源: 专家荟萃
Mixtral 8x7B 使用仅解码器的稀疏专家混合网络。这涉及到前馈块从 8 组参数中进行选择,路由器网络为每个令牌选择其中的两组,并相加地组合它们的输出。此方法增强了模型的参数数量,同时管理成本和延迟,使其与 12.9B 模型一样高效,尽管总参数为 46.7B。
Mixtral 8x7B 模型擅长处理 32k 令牌的广泛上下文,并支持多种语言,包括英语、法语、意大利语、德语和西班牙语。它在代码生成方面表现出强大的性能,并且可以微调为指令跟踪模型,在 MT-Bench 等基准测试中取得高分。
LLaMA.cpp 是一个 C/C++ 库,为基于 Facebook 的 LLM 架构的大型语言模型 (LLM) 提供高性能接口。它是一个轻量级且高效的库,可用于各种任务,包括文本生成、翻译和问答。 LLaMA.cpp 支持多种 LLM,包括 LLaMA、LLaMA 2、Falcon、Alpaca、Mistral 7B、Mixtral 8x7B 和 GPT4ALL。它与所有操作系统兼容,并且可以在 CPU 和 GPU 上运行。
在本节中,我们将在 Colab 上运行 llama.cpp Web 应用程序。通过编写几行代码,您将能够在 PC 或 Google Colab 上体验新的最先进的模型性能。
入门
首先,我们将使用以下命令行下载 llama.cpp GitHub 存储库:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.git之后,我们将目录更改为存储库并使用“make”命令安装 llama.cpp。我们正在为安装了 CUDA 的 NVidia GPU 安装 llama.cpp。
%cd llama.cpp
!make LLAMA_CUBLAS=1下载模型
我们可以通过选择适当版本的“.gguf”模型文件从 Hugging Face Hub 下载模型。有关各种版本的更多信息可以在 TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
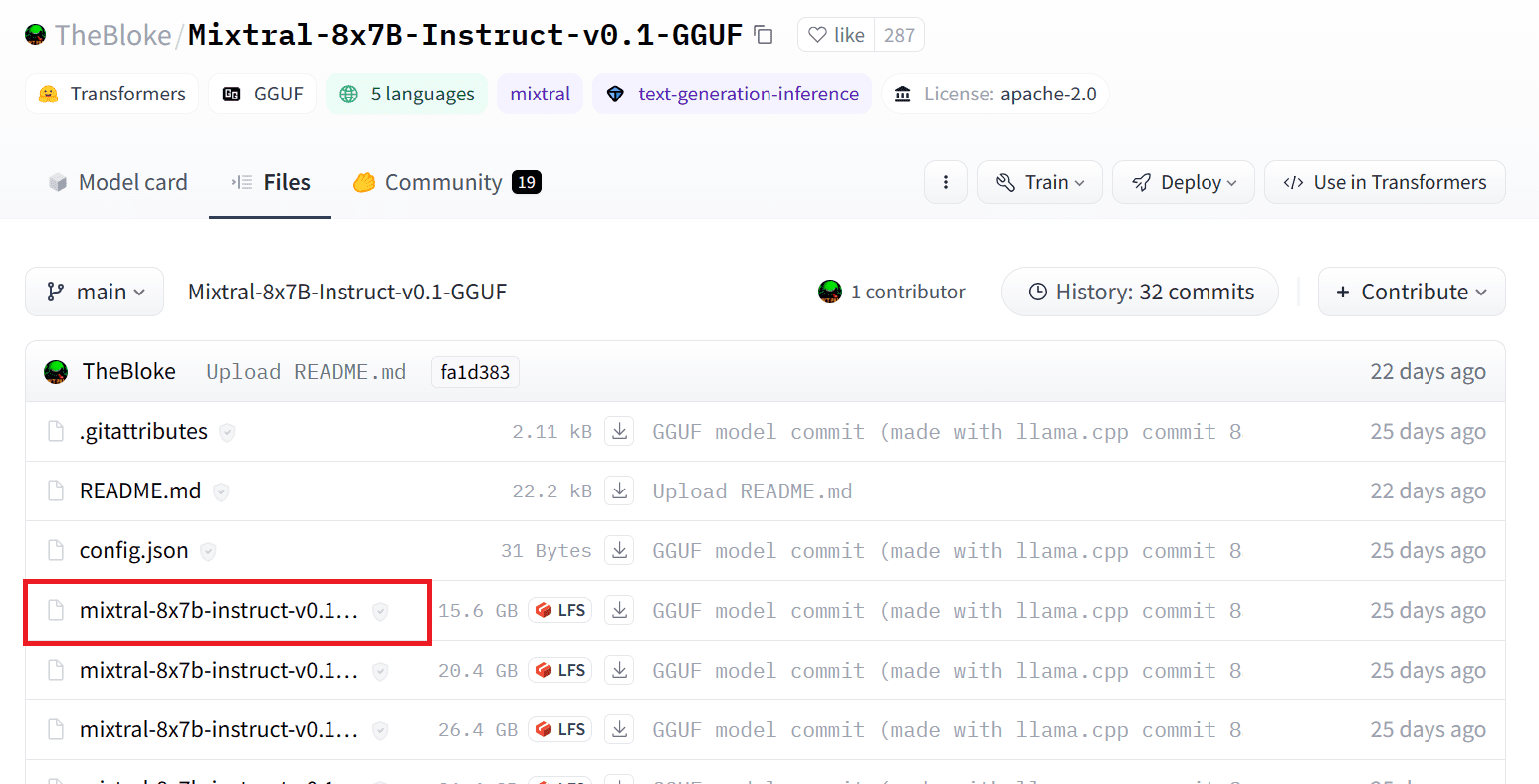
图片来源: TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
您可以使用命令“wget”将模型下载到当前目录中。
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufLLaMA 服务器的外部地址
当我们运行 LLaMA 服务器时,它会给我们一个本地主机 IP,这对我们在 Colab 上毫无用处。我们需要使用 Colab 内核代理端口连接到本地主机代理。
运行下面的代码后,您将获得全局超链接。稍后我们将使用此链接访问我们的网络应用程序。
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/运行服务器
要运行 LLaMA C++ 服务器,您需要向服务器命令提供模型文件的位置和正确的端口号。确保端口号与我们在上一步中为代理端口启动的端口号相匹配非常重要。
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
由于服务器不在本地运行,因此可以通过单击上一步中的代理端口超链接来访问聊天 Web 应用程序。
LLaMA C++ 网络应用程序
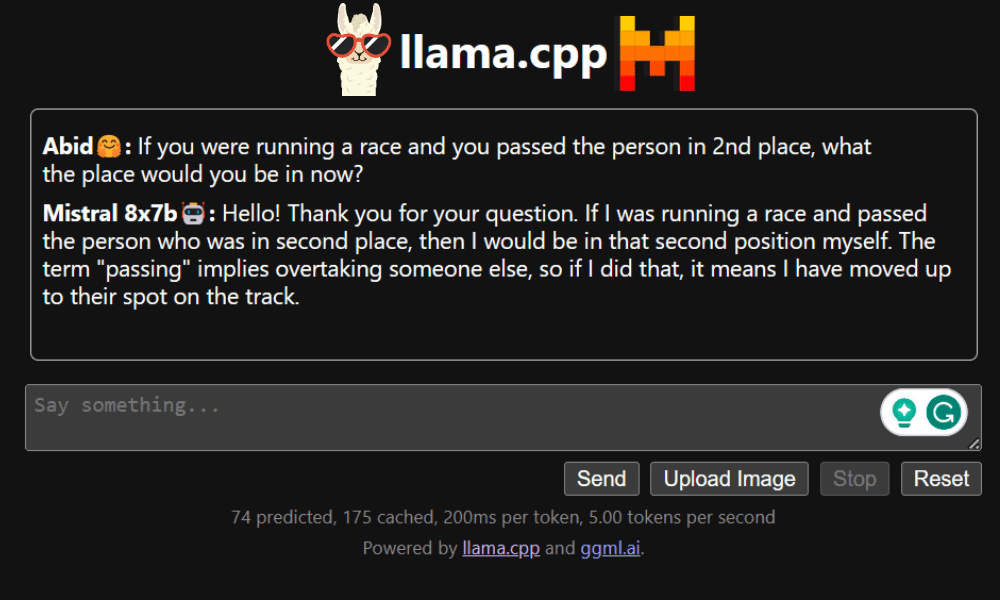
在开始使用聊天机器人之前,我们需要对其进行自定义。在提示部分将“LLaMA”替换为您的型号名称。此外,修改用户名和机器人名称以区分生成的响应。
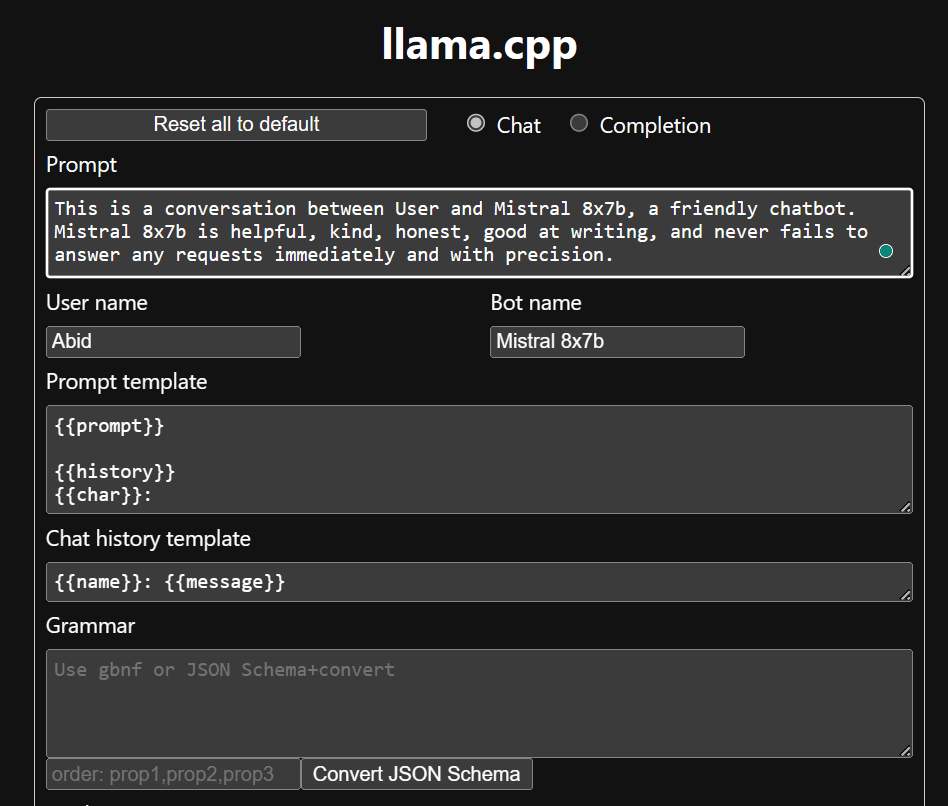
向下滚动并在聊天部分中输入内容即可开始聊天。请随意提出其他开源模型未能正确回答的技术问题。
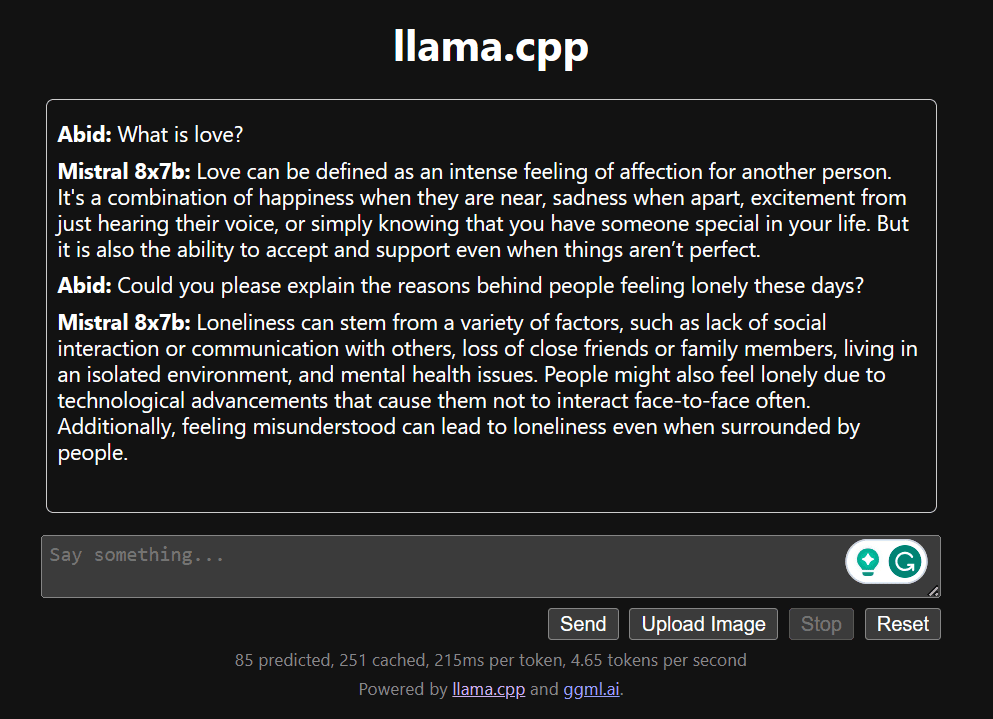
如果您遇到应用程序问题,您可以尝试使用我的 Google Colab 自行运行它:https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
本教程提供了有关如何使用 LLaMA C++ 库在 Google Colab 上运行高级开源模型 Mixtral 8x7b 的全面指南。与其他模型相比,Mixtral 8x7b 提供了卓越的性能和效率,对于那些想要尝试大型语言模型但没有大量计算资源的人来说,它是一个出色的解决方案。您可以轻松地在笔记本电脑或免费云计算上运行它。它是用户友好的,您甚至可以部署您的聊天应用程序以供其他人使用和试验。
我希望您发现这个运行大型模型的简单解决方案很有帮助。我一直在寻找简单且更好的选择。如果您有更好的解决方案,请告诉我,我下次会介绍。
阿比德·阿里·阿万 (@1abidaliawan) 是一名经过认证的数据科学家专业人士,他热爱构建机器学习模型。 目前,他专注于内容创建和撰写有关机器学习和数据科学技术的技术博客。 Abid 拥有技术管理硕士学位和电信工程学士学位。 他的愿景是使用图形神经网络为患有精神疾病的学生构建一个人工智能产品。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :是
- :不是
- 1
- 12
- 27
- 46
- 7
- 8
- a
- Able
- ACCESS
- 访问
- 实现
- 另外
- 地址
- 高级
- AI
- 所有类型
- 还
- 时刻
- am
- an
- 和
- 回答
- 阿帕奇
- 应用
- 应用领域
- 适当
- 架构
- 保健
- AS
- 问
- 基于
- BE
- 开始
- 如下。
- 基准
- 最佳
- 更好
- 之间
- 阻止
- 博客
- 博特
- 都
- 建立
- 建筑物
- 但是
- by
- C + +中
- 被称为
- CAN
- 认证
- 更改
- 即时通话
- 聊天机器人
- 聊天的
- 选择
- 云端技术
- 码
- 结合
- 相比
- 兼容
- 全面
- 计算
- 计算
- 计算
- 地都
- 内容
- 内容创造
- 上下文
- 正确
- 价格
- 外壳
- 创建
- 创建
- 电流
- 目前
- 定制
- data
- 数据科学
- 数据科学家
- 学位
- 提供
- 演示
- 部署
- 尽管
- 区分
- do
- 向下
- 下载
- 每
- 容易
- 效率
- 高效
- 遭遇
- 工程师
- 英语
- 增强
- 甚至
- 优秀
- 体验
- 实验
- 专家
- 探索
- 广泛
- 面部彩妆
- 失败
- 鹘
- 快
- 感觉
- 少数
- 文件
- 聚焦
- 针对
- 发现
- Free
- 法语
- 止
- 功能
- 产生
- 代
- 德语
- 得到
- GitHub上
- 给
- 全球
- 谷歌
- GPU
- 图形处理器
- 图形
- 图神经网络
- 组的
- 指南
- 处理
- 有
- 有
- he
- 有帮助
- 高
- 高性能
- 高品质
- 他的
- 持有
- 抱有希望
- 创新中心
- How To
- HTTPS
- 中心
- i
- if
- 疾病
- 进口
- 重要
- in
- 包含
- 信息
- 启动
- 安装
- 安装
- 接口
- 成
- 涉及
- IP
- 问题
- IT
- 意大利语
- 掘金队
- 知道
- 语言
- 语言
- 笔记本电脑
- 大
- 潜伏
- 后来
- 学习用品
- 学习
- 让
- 自学资料库
- 行货
- 轻巧
- 喜欢
- Line
- 线
- 友情链接
- 骆驼
- 当地
- 圖書分館的位置
- 寻找
- 爱
- 机
- 机器学习
- 使
- 制作
- 颠覆性技术
- 管理的
- 主
- 火柴
- me
- 内存
- 心理
- 精神疾病
- 方法
- 混合物
- 模型
- 模型
- 修改
- 更多
- 最先进的
- 多
- my
- 姓名
- 需求
- 网络
- 神经
- 神经网络
- 全新
- 下页
- 数
- Nvidia公司
- of
- on
- 一
- 打开
- 开放源码
- 操作
- 操作系统
- 附加选项
- or
- 其他名称
- 其它
- 我们的
- 性能优于
- 产量
- 输出
- 己
- 参数
- 参数
- PC
- 性能
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 请
- 帖子
- 以前
- 产品
- 所以专业
- 正确
- 提供
- 提供
- 代理
- 题
- 有疑问吗?
- 范围
- 减少
- 关于
- 更换
- 知识库
- 研究
- 资源
- 回复
- 路由器
- 运行
- 运行
- s
- 科学
- 科学家
- 分数
- 滚动
- 部分
- 选择
- 服务器
- 简易
- 自
- 方案,
- 来源
- 西班牙语
- 标准
- 国家的最先进的
- 步
- 强烈
- 奋斗的
- 学生
- 优于
- 支持
- 肯定
- 产品
- 任务
- 文案
- 技术
- 专业技术
- 电信
- 文本
- 文字产生
- 这
- 其
- 博曼
- Free Introduction
- 那些
- 次
- 至
- 象征
- 令牌
- 合计
- 翻译
- 尝试
- 教程
- 二
- 下
- us
- 使用
- 用过的
- 用户
- 用户友好
- 使用
- 运用
- 各种
- 各个
- 版本
- 愿景
- 想
- we
- 卷筒纸
- Web应用程序
- 这
- 而
- WHO
- 宽
- 大范围
- 将
- 写作
- 您
- 您一站式解决方案
- 和风网




