这是一个人工智能突破日新月异的时代。 几年前,我们在公共场合并没有很多 AI 生成的东西,但现在每个人都可以使用这项技术。 对于许多想要充分利用该技术来开发可能需要很长时间的复杂事物的个人创作者或公司来说,它是极好的。
改变我们工作方式的最令人难以置信的突破之一是发布了 OpenAI 的 GPT-3.5 模型. GPT-3.5 模型是什么? 如果我让模型自己说话。 在这种情况下,答案是“自然语言处理领域的一个高度先进的人工智能模型,在生成上下文准确和相关的文本方面有了巨大的改进t”。
OpenAI 为 GPT-3.5 模型提供了一个 API,我们可以使用它来开发一个简单的应用程序,例如文本摘要器。 为此,我们可以使用 Python 将模型 API 无缝集成到我们预期的应用程序中。 这个过程是什么样的? 让我们开始吧。
在学习本教程之前有一些先决条件,包括:
– Python 知识,包括使用外部库和 IDE 的知识
– 了解 API 并使用 Python 处理端点
– 可以访问 OpenAI API
要获得 OpenAI API 访问权限,我们必须在 OpenAI 开发者平台 并访问您个人资料中的查看 API 密钥。 在 Web 上,单击“创建新密钥”按钮以获取 API 访问权限(见下图)。 请记住保存密钥,因为之后将不会向他们显示密钥。

图片作者
准备就绪后,让我们尝试了解 OpenAI API 模型的基础知识。
GPT-3.5 家族型号 被指定用于许多语言任务,并且该系列中的每个模型都在某些任务中表现出色。 对于本教程示例,我们将使用 gpt-3.5-turbo 因为在撰写本文时,就其功能和成本效益而言,它是推荐的当前模型。
我们经常使用 text-davinci-003 在 OpenAI 教程中,但我们将在本教程中使用当前模型。 我们会依靠 聊天完成 端点而不是 Completion,因为当前推荐的模型是聊天模型。 即使名称是聊天模型,它也适用于任何语言任务。
让我们尝试了解 API 的工作原理。 首先,我们需要安装当前的 OpenAI 包。
pip install openai
完成安装包后,我们将尝试通过 ChatCompletion 端点连接来使用 API。 但是,我们需要在继续之前设置环境。
在你最喜欢的 IDE(对我来说是 VS Code)中,创建两个名为 .env 和 summarizer_app.py,类似于下图。
图片作者
summarizer_app.py 是我们构建简单的汇总器应用程序的地方,以及 .env 文件是我们存储 API 密钥的地方。 出于安全原因,始终建议将我们的 API 密钥放在另一个文件中,而不是将它们硬编码在 Python 文件中。
在 .env file 输入以下语法并保存文件。 将 your_api_key_here 替换为您的实际 API 密钥。 不要将 API 密钥更改为字符串对象; 让他们保持原样。
OPENAI_API_KEY=your_api_key_here
更好地理解 GPT-3.5 API; 我们将使用以下代码生成单词 summarizer。
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
上面的代码是我们如何与 OpenAI APIs GPT-3.5 模型交互的。 使用 ChatCompletion API,我们创建一个对话,并在通过提示后得到预期的结果。
让我们分解每个部分以更好地理解它们。 在第一行,我们使用 openai.ChatCompletion.create 根据我们将传递给 API 的提示创建响应的代码。
在下一行中,我们有用于改进文本任务的超参数。 以下是每个超参数函数的摘要:
model:我们要使用的模型系列。 在本教程中,我们使用当前推荐的模型(gpt-3.5-turbo).max_tokens:模型生成单词的上限。 它有助于限制生成的文本的长度。temperature:模型输出的随机性,温度越高,意味着更多样化和创造性的结果。 值范围在 0 到无穷大之间,尽管大于 2 的值并不常见。top_p: Top P or top-k sampling or nucleus sampling 是一个从输出分布上控制采样池的参数。 例如,值 0.1 表示模型仅对分布的前 10% 的输出进行采样。 取值范围在0到1之间; 更高的值意味着更多样化的结果。frequency_penalty:输出中重复标记的惩罚。 值范围在 -2 到 2 之间,其中正值会抑制模型重复标记,而负值会鼓励模型使用更多重复词。 0 表示没有惩罚。messages:我们传递要与模型一起处理的文本提示的参数。 我们传递了一个字典列表,其中键是帮助模型理解上下文和结构的角色对象(“系统”、“用户”或“助手”),而值是上下文。- 角色“系统”是为模型“助手”行为设定的准则,
- “用户”角色代表与模型交互的人的提示,
- “助手”角色是对“用户”提示的响应
解释完上面的参数,我们可以看到 messages 上面的参数有两个字典对象。 第一个字典是我们如何将模型设置为文本摘要器。 第二个是我们传递文本并获得摘要输出的地方。
在第二本词典中,您还会看到变量 person_type 和 prompt。 该 person_type 是我用来控制汇总样式的变量,我将在教程中展示。 虽然 prompt 是我们将传递要总结的文本的地方。
继续本教程,将以下代码放在 summarizer_app.py 文件,我们将尝试运行下面的函数是如何工作的。
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
上面的代码是我们创建一个 Python 函数的地方,该函数将接受我们之前讨论过的各种参数并返回文本摘要输出。
使用您的参数尝试上面的函数并查看输出。 然后让我们继续本教程,使用 streamlit 包创建一个简单的应用程序。
流光 是一个开源 Python 包,旨在创建机器学习和数据科学 Web 应用程序。 它易于使用且直观,因此推荐给许多初学者。
在继续本教程之前,让我们先安装 streamlit 包。
pip install streamlit
安装完成后,将以下代码放入 summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
尝试在命令提示符下运行以下代码以启动应用程序。
streamlit run summarizer_app.py
如果一切正常,您将在默认浏览器中看到以下应用程序。
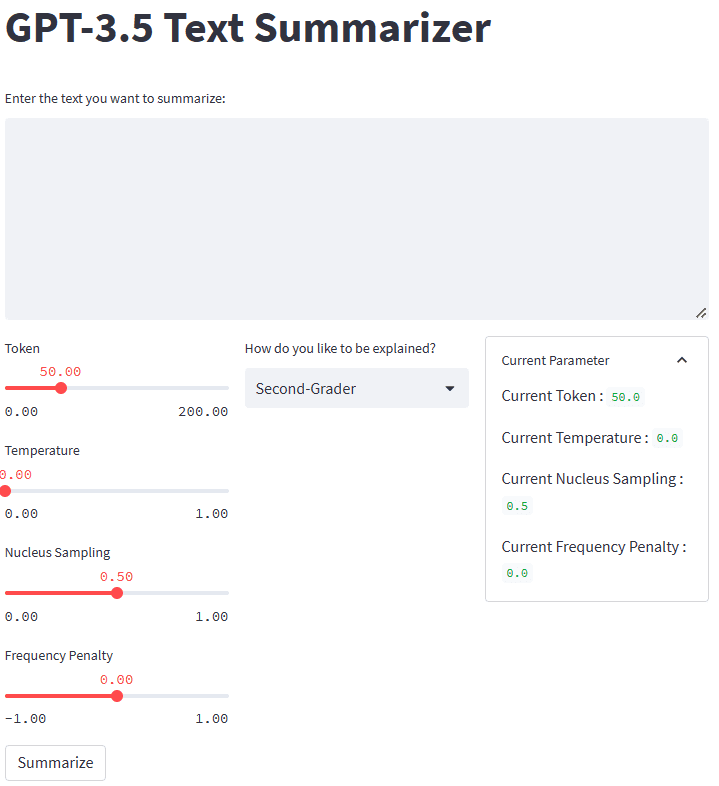
图片作者
那么,上面的代码发生了什么? 让我简要解释一下我们使用的每个功能:
.st.title:提供网络应用程序的标题文本。.st.write:将参数写入应用程序; 它可以是任何东西,但主要是字符串文本。.st.text_area: 提供一个文本输入区域,可以存储在变量中,用于我们的文本摘要器的提示.st.columns:对象容器以提供并排交互。.st.slider:提供一个滑块小部件,其中包含用户可以与之交互的设置值。 该值存储在用作模型参数的变量中。.st.selectbox:提供一个选择小部件,供用户选择他们想要的摘要样式。 在上面的示例中,我们使用了五种不同的样式。.st.expander:提供一个容器,用户可以展开并容纳多个对象。.st.button:提供一个按钮,当用户按下它时运行预期的功能。
由于 streamlit 会自动按照给定的代码从上到下设计 UI,我们可以更专注于交互。
准备好所有部分后,让我们用一个文本示例来尝试我们的摘要应用程序。 对于我们的示例,我将使用 相对论维基百科页面 要总结的文字。 使用默认参数和二年级学生风格,我们获得以下结果。
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
您可能会获得与上述结果不同的结果。 让我们尝试家庭主妇风格并稍微调整参数(令牌 100,温度 0.5,核采样 0.5,频率惩罚 0.3)。
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
正如我们所看到的,我们提供的相同文本在风格上有所不同。 通过更改提示和参数,我们的应用程序可以更加实用。
我们的文本摘要应用程序的整体外观如下图所示。
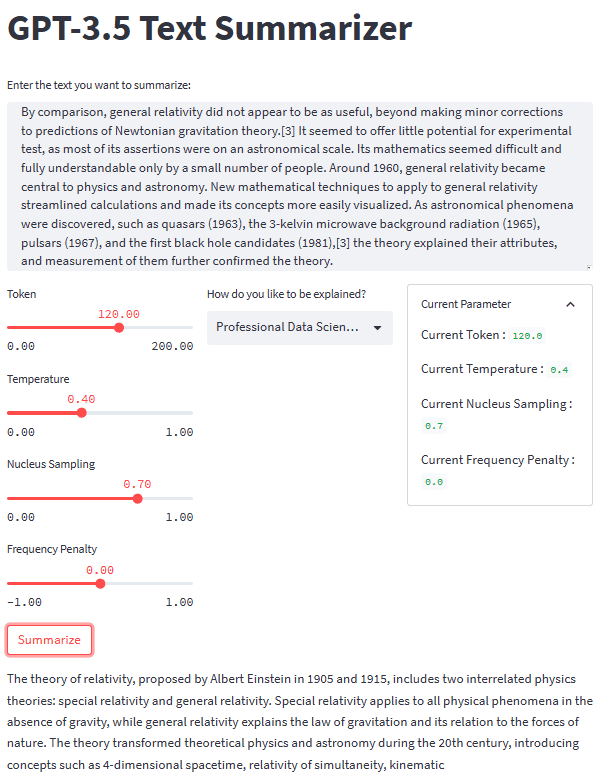
图片作者
那就是使用 GPT-3.5 创建文本摘要应用程序开发的教程。 您可以进一步调整应用程序并部署该应用程序。
生成式人工智能正在兴起,我们应该通过创建出色的应用程序来利用这个机会。 在本教程中,我们将了解 GPT-3.5 OpenAI API 的工作原理,以及如何使用它们在 Python 和 streamlit 包的帮助下创建文本摘要应用程序。
科尼利厄斯·尤达·维贾亚 是一名数据科学助理经理和数据作家。 在 Allianz Indonesia 全职工作期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :是
- ][p
- $UP
- 1
- 100
- 28
- 7
- a
- 关于
- 以上
- 接受
- ACCESS
- 无障碍
- 精准的
- 获得
- 高级
- 优点
- 后
- AI
- 所有类型
- 安联
- 尽管
- 时刻
- 和
- 另一个
- 回答
- API
- API访问
- APIs
- 应用
- 应用领域
- 应用程序开发
- 应用
- 保健
- 国家 / 地区
- 论点
- 刊文
- AS
- 助理
- 天文学
- At
- 自动
- 基本包
- BE
- 因为
- before
- 初学者
- 如下。
- 更好
- 之间
- 位
- 黑色
- 黑洞
- 半身裙/裤
- 盒子
- 午休
- 突破
- 突破
- 简要地
- 浏览器
- 建立
- 按键
- by
- 被称为
- CAN
- 案件
- 世纪
- 更改
- 选择
- 点击
- 码
- 列
- 未来
- 相当常见
- 公司
- 完成
- 复杂
- 概念
- 连接
- 容器
- 集装箱
- 内容
- 上下文
- 继续
- 控制
- 谈话
- 可以
- 创建信息图
- 创造
- 创意奖学金
- 创作者
- 电流
- 每天
- data
- 数据科学
- 数据科学家
- 默认
- 部署
- 设计
- 设计
- 开发
- 开发商
- 研发支持
- 差异
- 不同
- 通过各种方式找到
- 讨论
- 分配
- 不同
- 别
- 向下
- 每
- 或
- 鼓励
- 端点
- 输入
- 环境
- 时代
- 醚(ETH)
- 甚至
- 每个人
- 一切
- 例子
- 优秀
- 执行
- 扩大
- 说明
- 解释
- 介绍
- 外部
- 家庭
- 奇妙
- 喜爱
- 少数
- 部分
- 文件
- 档
- 姓氏:
- 专注焦点
- 以下
- 针对
- 部队
- 频率
- 止
- 功能
- 实用
- 进一步
- 其他咨询
- 生成
- 产生
- 发电
- 得到
- 特定
- 引力
- 引力波
- 重力
- 方针
- 处理
- 发生
- 有
- 有
- 帮助
- 帮助
- 有帮助
- 帮助
- 此处
- 更高
- 高度
- 举行
- 孔
- 创新中心
- How To
- 合作方式
- 但是
- HTTPS
- i
- 思路
- 图片
- 进口
- 重要
- 改善
- 改善
- in
- 包括
- 包含
- 难以置信
- 个人
- 印度尼西亚
- 无限
- 开始
- 输入
- 安装
- 安装
- 代替
- 整合
- 相互作用
- 互动
- 相互作用
- 介绍
- 直观的
- IT
- 它的
- JPG
- 掘金队
- 键
- 键
- 知识
- 语言
- 法律
- 学习用品
- 学习
- 长度
- 库
- 喜欢
- 极限
- Line
- 清单
- 长
- 长时间
- 看
- 看起来像
- 机
- 机器学习
- 经理
- 许多
- 手段
- 媒体
- 的话
- 可能
- 模型
- 更多
- 最先进的
- 移动
- 多
- 姓名
- 自然
- 自然语言
- 自然语言处理
- 自然
- 需求
- 负
- 全新
- 下页
- 对象
- 对象
- 获得
- of
- on
- 一
- 开放源码
- OpenAI
- ZAP优势
- 附加选项
- OS
- 其他名称
- 产量
- 最划算
- 包
- 包
- 参数
- 参数
- 部分
- 通过
- 人
- 的
- 物理
- 件
- 地方
- 行星
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 池
- 积极
- 预测
- 先决条件
- 先前
- 过程
- 处理
- 所以专业
- 本人简介
- 建议
- 提供
- 提供
- 国家
- 放
- 蟒蛇
- 随机性
- 范围
- 宁
- 准备
- 原因
- 建议
- 寄存器
- 关系
- 释放
- 相应
- 纪念
- 重复的
- 更换
- 代表
- 响应
- 导致
- 回报
- 上升
- 角色
- 运行
- 同
- 保存
- 科学
- 科学家
- 无缝
- 其次
- 秘密
- 部分
- 保安
- 选择
- 分开
- 集
- Share
- 应该
- 显示
- 如图
- 显著
- 类似
- 简易
- 滑块
- 智能
- So
- 社会
- 社会化媒体
- 一些
- 东西
- 太空
- 特别
- 指定
- 明星
- 商店
- 存储
- 串
- 结构体
- 学生
- 样式
- 风格
- 这样
- 总结
- 概要
- 句法
- 系统
- 采取
- 谈论
- 会谈
- 任务
- 任务
- 专业技术
- 这
- 法律
- 世界
- 他们
- 他们自己
- 理论
- 博曼
- 事
- 三
- 通过
- 次
- 秘诀
- 标题
- 至
- 象征
- 最佳
- 转化
- 教程
- ui
- 理解
- 理解
- 大学
- us
- 使用
- 用户
- 用户
- 利用
- 折扣值
- 价值观
- 各个
- 广阔
- 通过
- 查看
- 参观
- vs
- VS代码
- 波浪
- 卷筒纸
- Web应用程序
- 井
- 什么是
- 什么是
- 这
- 而
- WHO
- 维基百科上的数据
- 将
- 中
- 也完全不需要
- Word
- 话
- 工作
- 加工
- 合作
- 世界
- 将
- 作家
- 写作
- 书面
- 年
- 您一站式解决方案
- 和风网