تصویر کی طرف سے Freepik
بات چیت کے AI سے مراد ورچوئل ایجنٹس اور چیٹ بوٹس ہیں جو انسانی تعاملات کی نقل کرتے ہیں اور انسانوں کو گفتگو میں شامل کر سکتے ہیں۔ مکالماتی AI کا استعمال تیزی سے زندگی کا ایک طریقہ بنتا جا رہا ہے – Alexa سے پوچھنے تکقریب ترین ریستوراں تلاش کریں" سری سے پوچھنا "ایک یاد دہانی بنائیں" ورچوئل اسسٹنٹ اور چیٹ بوٹس کا استعمال اکثر صارفین کے سوالات کے جوابات، شکایات حل کرنے، تحفظات کرنے اور بہت کچھ کرنے کے لیے کیا جاتا ہے۔
ان ورچوئل معاونین کو تیار کرنے کے لیے کافی محنت درکار ہے۔ تاہم، اہم چیلنجوں کو سمجھنے اور ان سے نمٹنے سے ترقی کے عمل کو ہموار کیا جا سکتا ہے۔ میں نے کلیدی چیلنجوں اور ان کے متعلقہ حل کی وضاحت کے لیے ایک ریکروٹمنٹ پلیٹ فارم کے لیے ایک بالغ چیٹ بوٹ بنانے کے لیے اپنے پہلے ہاتھ کے تجربے کا استعمال کیا ہے۔
ایک مکالماتی AI چیٹ بوٹ بنانے کے لیے، ڈویلپرز چیٹ بوٹس بنانے کے لیے RASA، Amazon's Lex، یا Google's Dialogflow جیسے فریم ورک استعمال کر سکتے ہیں۔ زیادہ تر لوگ RASA کو ترجیح دیتے ہیں جب وہ اپنی مرضی کے مطابق تبدیلیوں کی منصوبہ بندی کرتے ہیں یا بوٹ بالغ مرحلے میں ہوتا ہے کیونکہ یہ ایک اوپن سورس فریم ورک ہے۔ دوسرے فریم ورک بھی نقطہ آغاز کے طور پر موزوں ہیں۔
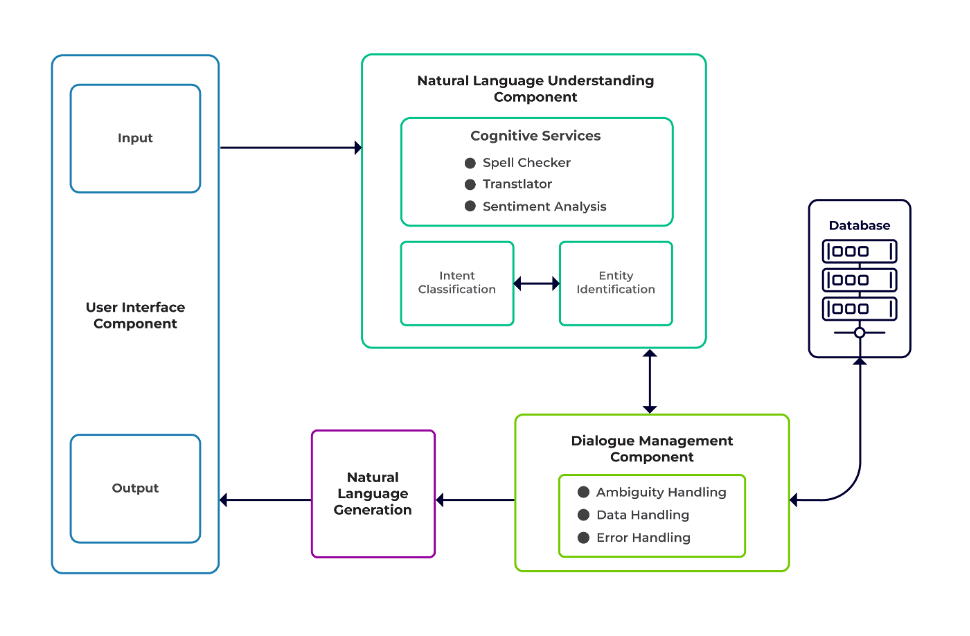
چیلنجز کو چیٹ بوٹ کے تین بڑے اجزاء کے طور پر درجہ بندی کیا جا سکتا ہے۔
قدرتی زبان کی تفہیم (NLU) انسانی مکالمے کو سمجھنے کے لیے بوٹ کی صلاحیت ہے۔ یہ ارادے کی درجہ بندی، ہستی نکالنے، اور ردعمل کی بازیافت کرتا ہے۔
ڈائیلاگ مینیجر صارف کے ان پٹ کے موجودہ اور پچھلے سیٹ کی بنیاد پر کیے جانے والے اعمال کے سیٹ کے لیے ذمہ دار ہے۔ یہ ارادے اور اداروں کو بطور ان پٹ لیتا ہے (پچھلی گفتگو کے حصے کے طور پر) اور اگلے جواب کی نشاندہی کرتا ہے۔
قدرتی زبان کی نسل (NLG) دیئے گئے ڈیٹا سے تحریری یا بولے جانے والے جملوں کو بنانے کا عمل ہے۔ یہ جواب کو فریم کرتا ہے، جو پھر صارف کو پیش کیا جاتا ہے۔
ٹیلنٹکا سافٹ ویئر سے تصویر
ناکافی ڈیٹا
جب ڈیولپرز FAQs یا دیگر سپورٹ سسٹمز کو چیٹ بوٹ سے تبدیل کرتے ہیں، تو انہیں تربیتی ڈیٹا کی معقول مقدار ملتی ہے۔ لیکن ایسا نہیں ہوتا جب وہ شروع سے بوٹ بناتے ہیں۔ ایسے معاملات میں، ڈویلپر تربیتی ڈیٹا مصنوعی طور پر تیار کرتے ہیں۔
کیا کیا جائے؟
ٹیمپلیٹ پر مبنی ڈیٹا جنریٹر تربیت کے لیے صارف کے سوالات کی معقول مقدار پیدا کر سکتا ہے۔ چیٹ بوٹ کے تیار ہونے کے بعد، پراجیکٹ کے مالکان تربیتی ڈیٹا کو بڑھانے اور اسے ایک مدت میں اپ گریڈ کرنے کے لیے اسے محدود تعداد میں صارفین کے سامنے لا سکتے ہیں۔
غیر موزوں ماڈل کا انتخاب
بہترین ارادے اور ہستی نکالنے کے نتائج حاصل کرنے کے لیے مناسب ماڈل کا انتخاب اور تربیتی ڈیٹا بہت ضروری ہے۔ ڈویلپرز عام طور پر چیٹ بوٹس کو ایک مخصوص زبان اور ڈومین میں تربیت دیتے ہیں، اور زیادہ تر دستیاب پہلے سے تربیت یافتہ ماڈلز اکثر ڈومین کے لیے مخصوص ہوتے ہیں اور ایک ہی زبان میں تربیت یافتہ ہوتے ہیں۔
مخلوط زبانوں کے معاملات بھی ہوسکتے ہیں جہاں لوگ کثیر الجہتی ہیں۔ وہ مخلوط زبان میں سوالات درج کر سکتے ہیں۔ مثال کے طور پر، فرانسیسی اکثریتی علاقے میں، لوگ انگریزی کی ایک قسم استعمال کر سکتے ہیں جو فرانسیسی اور انگریزی دونوں کا مرکب ہے۔
کیا کیا جائے؟
متعدد زبانوں میں تربیت یافتہ ماڈلز کا استعمال مسئلہ کو کم کر سکتا ہے۔ پہلے سے تربیت یافتہ ماڈل جیسا کہ LaBSE (Language-agnostic Bert sentence embedding) ایسے معاملات میں مددگار ثابت ہو سکتا ہے۔ LaBSE کو 109 سے زیادہ زبانوں میں جملے کی مماثلت کے کام پر تربیت دی جاتی ہے۔ ماڈل پہلے سے ہی ایک مختلف زبان میں ملتے جلتے الفاظ جانتا ہے۔ ہمارے پروجیکٹ میں، اس نے بہت اچھا کام کیا۔
نامناسب ہستی نکالنا
چیٹ بوٹس کو اداروں کی ضرورت ہوتی ہے کہ وہ شناخت کریں کہ صارف کس قسم کا ڈیٹا تلاش کر رہا ہے۔ ان اداروں میں وقت، جگہ، شخص، شے، تاریخ وغیرہ شامل ہیں۔ تاہم، بوٹس فطری زبان سے کسی ہستی کی شناخت کرنے میں ناکام ہو سکتے ہیں:
ایک ہی سیاق و سباق لیکن مختلف ادارے. مثال کے طور پر، بوٹس کسی جگہ کو ایک ہستی کے طور پر الجھا سکتے ہیں جب کوئی صارف "IIT دہلی کے طلباء کا نام" اور پھر "بنگلور کے طلباء کا نام" ٹائپ کرتا ہے۔
ایسے حالات جہاں اداروں کی کم اعتمادی کے ساتھ غلط پیشین گوئی کی جاتی ہے۔ مثال کے طور پر، ایک بوٹ IIT دہلی کو کم اعتماد والے شہر کے طور پر شناخت کر سکتا ہے۔
مشین لرننگ ماڈل کے ذریعے جزوی ہستی نکالنا۔ اگر کوئی صارف "IIT دہلی کے طلباء" ٹائپ کرتا ہے تو ماڈل "IIT دہلی" کے بجائے صرف "IIT" کو صرف ایک ادارے کے طور پر شناخت کر سکتا ہے۔
کوئی سیاق و سباق نہ ہونے والے ایک لفظی ان پٹ مشین لرننگ ماڈلز کو الجھا سکتے ہیں۔ مثال کے طور پر، "رشیکیش" جیسے لفظ کا مطلب ایک شخص کے ساتھ ساتھ شہر دونوں کا ہو سکتا ہے۔
کیا کیا جائے؟
مزید تربیتی مثالیں شامل کرنا ایک حل ہوسکتا ہے۔ لیکن ایک حد ہے جس کے بعد مزید اضافہ کرنے سے کوئی فائدہ نہیں ہوگا۔ مزید یہ کہ یہ ایک نہ ختم ہونے والا عمل ہے۔ ایک اور حل یہ ہو سکتا ہے کہ پہلے سے طے شدہ الفاظ کا استعمال کرتے ہوئے ریجیکس پیٹرن کی وضاحت کی جائے تاکہ ممکنہ قدروں کے معروف سیٹ، جیسے شہر، ملک وغیرہ کے ساتھ اداروں کو نکالنے میں مدد ملے۔
جب بھی وہ ہستی کی پیشن گوئی کے بارے میں یقین نہیں رکھتے ہیں تو ماڈلز کم اعتماد کا اشتراک کرتے ہیں۔ ڈویلپرز اسے ایک ٹرگر کے طور پر استعمال کر سکتے ہیں کہ وہ اپنی مرضی کے اجزاء کو کال کریں جو کم اعتماد والی ہستی کو درست کر سکے. آئیے اوپر کی مثال پر غور کریں۔ اگر آئی آئی ٹی دہلی کم اعتماد والے شہر کے طور پر پیش گوئی کی جاتی ہے، پھر صارف اسے ہمیشہ ڈیٹا بیس میں تلاش کر سکتا ہے۔ میں پیش گوئی کی گئی ہستی کو تلاش کرنے میں ناکام ہونے کے بعد شہر table، ماڈل دیگر جدولوں پر جائے گا اور آخر کار اسے میں تلاش کرے گا۔ انسٹی ٹیوٹ ٹیبل، ہستی کی اصلاح کے نتیجے میں.
غلط ارادے کی درجہ بندی
ہر صارف کے پیغام کا اس سے کوئی نہ کوئی مقصد وابستہ ہوتا ہے۔ چونکہ ارادے بوٹ کی کارروائیوں کا اگلا طریقہ اخذ کرتے ہیں، اس لیے صارف کے سوالات کو ارادے کے ساتھ درست طریقے سے درجہ بندی کرنا بہت ضروری ہے۔ تاہم، ڈویلپرز کو ارادوں میں کم سے کم الجھن کے ساتھ ارادوں کی شناخت کرنی چاہیے۔ بصورت دیگر، الجھن کی وجہ سے معاملات بگڑ سکتے ہیں۔ مثال کے طور پر، "مجھے کھلی جگہیں دکھائیں" بمقابلہمجھے کھلی پوزیشن کے امیدوار دکھائیں"۔
کیا کیا جائے؟
مبہم سوالات میں فرق کرنے کے دو طریقے ہیں۔ سب سے پہلے، ایک ڈویلپر ذیلی ارادے کو متعارف کرا سکتا ہے۔ دوم، ماڈل شناخت شدہ اداروں کی بنیاد پر سوالات کو سنبھال سکتے ہیں۔
ایک ڈومین کے لیے مخصوص چیٹ بوٹ ایک بند نظام ہونا چاہیے جہاں اسے واضح طور پر شناخت کرنا چاہیے کہ یہ کیا قابل ہے اور کیا نہیں۔ ڈویلپرز کو ڈومین کے لیے مخصوص چیٹ بوٹس کی منصوبہ بندی کے دوران ترقی کو مراحل میں کرنا چاہیے۔ ہر مرحلے میں، وہ چیٹ بوٹ کی غیر تعاون یافتہ خصوصیات (غیر تعاون یافتہ ارادے کے ذریعے) کی شناخت کر سکتے ہیں۔
وہ یہ بھی شناخت کر سکتے ہیں کہ چیٹ بوٹ "دائرہ کار سے باہر" کے ارادے میں کیا نہیں سنبھال سکتا۔ لیکن ایسے معاملات ہوسکتے ہیں جہاں بوٹ غیر تعاون یافتہ اور دائرہ کار سے باہر کے ارادے سے الجھا ہوا ہو۔ اس طرح کے منظرناموں کے لیے، ایک فال بیک میکانزم موجود ہونا چاہیے جہاں، اگر ارادے کا اعتماد ایک حد سے نیچے ہے، تو ماڈل کنفیوژن کیسز کو سنبھالنے کے لیے فال بیک کے ارادے کے ساتھ احسن طریقے سے کام کر سکتا ہے۔
ایک بار جب بوٹ صارف کے پیغام کے ارادے کی شناخت کر لیتا ہے، تو اسے جواب واپس بھیجنا چاہیے۔ بوٹ جواب کا فیصلہ طے شدہ اصولوں اور کہانیوں کے ایک مخصوص سیٹ کی بنیاد پر کرتا ہے۔ مثال کے طور پر، ایک اصول اتنا ہی آسان ہو سکتا ہے جتنا کہ بولنا "صبح بخیر" جب صارف سلام کرتا ہے۔ "ہیلو"۔ تاہم، اکثر، چیٹ بوٹس کے ساتھ بات چیت میں فالو اپ تعامل ہوتا ہے، اور ان کے جوابات گفتگو کے مجموعی تناظر پر منحصر ہوتے ہیں۔
کیا کیا جائے؟
اس کو سنبھالنے کے لیے، چیٹ بوٹس کو حقیقی گفتگو کی مثالیں فراہم کی جاتی ہیں جنہیں کہانیاں کہتے ہیں۔ تاہم، صارفین ہمیشہ ارادے کے مطابق تعامل نہیں کرتے ہیں۔ ایک بالغ چیٹ بوٹ کو ایسے تمام انحرافات کو احسن طریقے سے سنبھالنا چاہیے۔ ڈیزائنرز اور ڈویلپرز اس بات کی ضمانت دے سکتے ہیں اگر وہ کہانیاں لکھتے وقت صرف خوش راہ پر توجہ نہ دیں بلکہ ناخوش راہوں پر بھی کام کریں۔
چیٹ بوٹس کے ساتھ صارف کی مصروفیت چیٹ بوٹ کے جوابات پر بہت زیادہ انحصار کرتی ہے۔ اگر جوابات بہت زیادہ روبوٹک یا بہت واقف ہیں تو صارفین دلچسپی کھو سکتے ہیں۔ مثال کے طور پر، ایک صارف کو غلط ان پٹ کے لیے "آپ نے غلط سوال ٹائپ کیا ہے" جیسا جواب پسند نہیں کیا حالانکہ جواب درست ہے۔ یہاں کا جواب اسسٹنٹ کی شخصیت سے میل نہیں کھاتا۔
کیا کیا جائے؟
چیٹ بوٹ ایک معاون کے طور پر کام کرتا ہے اور اس میں ایک مخصوص شخصیت اور آواز کی آواز ہونی چاہیے۔ انہیں خوش آئند اور شائستہ ہونا چاہیے، اور ڈویلپرز کو اس کے مطابق گفتگو اور بیانات کو ڈیزائن کرنا چاہیے۔ جوابات روبوٹک یا مکینیکل نہیں لگنے چاہئیں۔ مثال کے طور پر، بوٹ کہہ سکتا ہے، "معذرت، ایسا لگتا ہے کہ میرے پاس کوئی تفصیلات نہیں ہیں۔ کیا آپ اپنا استفسار دوبارہ ٹائپ کر سکتے ہیں؟" غلط ان پٹ کو حل کرنے کے لیے۔
LLM (Large Language Model) پر مبنی چیٹ بوٹس جیسے ChatGPT اور Bard گیم کو تبدیل کرنے والی اختراعات ہیں اور انہوں نے بات چیت کے AIs کی صلاحیتوں کو بہتر بنایا ہے۔ وہ نہ صرف کھلے عام انسانوں جیسی گفتگو کرنے میں اچھے ہیں بلکہ متن کا خلاصہ، پیراگراف لکھنا وغیرہ جیسے مختلف کام انجام دے سکتے ہیں، جو پہلے صرف مخصوص ماڈلز کے ذریعے حاصل کیے جا سکتے تھے۔
روایتی چیٹ بوٹ سسٹم کے ساتھ چیلنجوں میں سے ایک ہر جملے کو ارادوں میں درجہ بندی کرنا اور اس کے مطابق جواب کا فیصلہ کرنا ہے۔ یہ نقطہ نظر عملی نہیں ہے۔ "معذرت، میں آپ کو نہیں مل سکا" جیسے جوابات اکثر پریشان کن ہوتے ہیں۔ بغیر ارادے کے چیٹ بوٹ سسٹم آگے بڑھنے کا راستہ ہیں، اور LLMs اسے حقیقت بنا سکتے ہیں۔
LLMs عام طور پر مخصوص ڈومین مخصوص ہستی کی شناخت کو چھوڑ کر عام نام کی ہستی کی شناخت میں جدید ترین نتائج حاصل کر سکتے ہیں۔ کسی بھی چیٹ بوٹ فریم ورک کے ساتھ LLMs کو استعمال کرنے کا ایک ملا جلا طریقہ ایک زیادہ پختہ اور مضبوط چیٹ بوٹ سسٹم کو متاثر کر سکتا ہے۔
بات چیت کے AI میں تازہ ترین پیشرفت اور مسلسل تحقیق کے ساتھ، چیٹ بوٹس ہر روز بہتر ہو رہے ہیں۔ پیچیدہ کاموں کو ایک سے زیادہ ارادوں کے ساتھ سنبھالنے جیسے شعبے، جیسے کہ "ممبئی کے لیے فلائٹ بک کرو اور دادر تک ٹیکسی کا بندوبست کرو،" بہت زیادہ توجہ حاصل کر رہے ہیں۔
صارف کو مصروف رکھنے کے لیے صارف کی خصوصیات کی بنیاد پر جلد ہی ذاتی نوعیت کی گفتگو کی جائے گی۔ مثال کے طور پر، اگر کوئی بوٹ صارف کو ناخوش پاتا ہے، تو یہ بات چیت کو ایک حقیقی ایجنٹ کے پاس بھیج دیتا ہے۔ مزید برآں، مسلسل بڑھتے ہوئے چیٹ بوٹ ڈیٹا کے ساتھ، گہری سیکھنے کی تکنیک جیسے ChatGPT علم کی بنیاد کا استعمال کرتے ہوئے سوالات کے جوابات خود بخود پیدا کر سکتی ہے۔
سمن سورو سافٹ ویئر پروڈکٹ ڈیولپمنٹ کمپنی ٹیلنٹکا سافٹ ویئر میں ڈیٹا سائنٹسٹ ہے۔ وہ NIT اگرتلہ کے سابق طالب علم ہیں جن کے پاس NLP، Conversational AI، اور جنریٹیو AI کا استعمال کرتے ہوئے انقلابی AI حلوں کو ڈیزائن اور نافذ کرنے کا 8 سال سے زیادہ کا تجربہ ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- : ہے
- : ہے
- : نہیں
- :کہاں
- 8
- a
- کی صلاحیت
- ہمارے بارے میں
- اوپر
- اس کے مطابق
- حاصل
- حاصل کیا
- کے پار
- اعمال
- انہوں نے مزید کہا
- اس کے علاوہ
- پتہ
- خطاب کرتے ہوئے
- ترقی
- کے بعد
- ایجنٹ
- ایجنٹ
- AI
- اے آئی چیٹ بوٹ
- Alexaکی بنیاد پر IQ Option ، بائنومو سے اوپری پوزیشن پر ہے۔
- تمام
- پہلے ہی
- بھی
- سابق طالب علم
- ہمیشہ
- رقم
- an
- اور
- ایک اور
- جواب
- کوئی بھی
- نقطہ نظر
- کیا
- علاقوں
- AS
- سے پوچھ
- اسسٹنٹ
- اسسٹنٹ
- منسلک
- At
- توجہ
- خود کار طریقے سے
- دستیاب
- سے اجتناب
- واپس
- بیس
- کی بنیاد پر
- BE
- بننے
- مخلوق
- نیچے
- BEST
- بہتر
- بوٹ
- دونوں
- خودکار صارف دکھا ئیں
- تعمیر
- لیکن
- by
- فون
- کہا جاتا ہے
- کر سکتے ہیں
- نہیں کر سکتے ہیں
- صلاحیتوں
- صلاحیت رکھتا
- مقدمات
- درجہ بندی
- کچھ
- چیلنجوں
- تبدیلیاں
- خصوصیات
- چیٹ بٹ
- چیٹ بٹس
- چیٹ جی پی ٹی
- شہر
- درجہ بندی
- درجہ بندی
- واضح طور پر
- بند
- کمپنی کے
- شکایات
- پیچیدہ
- جزو
- اجزاء
- سمجھو
- آپکا اعتماد
- الجھن میں
- مبہم
- الجھن
- غور کریں
- سیاق و سباق
- مسلسل
- بات چیت
- سنوادی
- بات چیت AI
- مکالمات
- درست
- صحیح طریقے سے
- اسی کے مطابق
- سکتا ہے
- ملک
- کورس
- تخلیق
- تخلیق
- اہم
- موجودہ
- اپنی مرضی کے
- اعداد و شمار
- ڈیٹا سائنسدان
- ڈیٹا بیس
- تاریخ
- دن
- مہذب
- فیصلہ کرنا
- گہری
- گہری سیکھنے
- وضاحت
- کی وضاحت
- دلی
- انحصار
- اخذ کردہ
- ڈیزائن
- ڈیزائنرز
- ڈیزائننگ
- تفصیلات
- ڈیولپر
- ڈویلپرز
- ترقی
- ڈائیلاگ فلو
- مکالمے کے
- مختلف
- فرق کرنا
- do
- نہیں کرتا
- ڈومین
- نہیں
- ہر ایک
- اس سے قبل
- آسانی سے
- کوشش
- سرایت کرنا
- لامتناہی
- مشغول
- مصروف
- مصروفیت
- انگریزی
- بڑھانے کے
- درج
- اداروں
- ہستی
- وغیرہ
- بھی
- آخر میں
- مسلسل بڑھتی ہوئی
- ہر کوئی
- ہر روز
- مثال کے طور پر
- مثال کے طور پر
- تجربہ
- وضاحت
- نکالنے
- نکالنے
- FAIL
- ناکامی
- واقف
- فاسٹ
- خصوصیات
- فیڈ
- مل
- پتہ ہے
- پرواز
- توجہ مرکوز
- کے لئے
- آگے
- فریم ورک
- فریم ورک
- فرانسیسی
- سے
- جنرل
- پیدا
- پیدا کرنے والے
- نسل
- پیداواری
- پیداواری AI۔
- جنریٹر
- حاصل
- حاصل کرنے
- دی
- اچھا
- گوگل
- اس بات کی ضمانت
- ہینڈل
- ہینڈلنگ
- ہو
- خوش
- ہے
- ہونے
- he
- بھاری
- مدد
- مدد گار
- یہاں
- کس طرح
- کیسے
- تاہم
- HTTPS
- انسانی
- شائستہ
- i
- کی نشاندہی
- شناخت
- شناخت
- if
- پر عمل درآمد
- بہتر
- in
- شامل
- بدعت
- ان پٹ
- آدانوں
- حوصلہ افزائی
- مثال کے طور پر
- کے بجائے
- ارادہ
- ارادے
- بات چیت
- بات چیت
- بات چیت
- دلچسپی
- میں
- متعارف کرانے
- IT
- فوٹو
- صرف
- KDnuggets
- رکھیں
- کلیدی
- بچے
- علم
- جانا جاتا ہے
- جانتا ہے
- زبان
- زبانیں
- بڑے
- تازہ ترین
- سیکھنے
- زندگی
- کی طرح
- LIMIT
- لمیٹڈ
- لنکڈ
- کھو
- لو
- کم
- مشین
- مشین لرننگ
- اہم
- بنا
- بنانا
- میچ
- عقلمند و سمجھدار ہو
- مئی..
- me
- مطلب
- میکانی
- میکانزم
- پیغام
- شاید
- کم سے کم
- اختلاط
- مخلوط
- ماڈل
- ماڈل
- زیادہ
- اس کے علاوہ
- سب سے زیادہ
- بہت
- ایک سے زیادہ
- ممبئی
- ضروری
- my
- نام
- نامزد
- قدرتی
- قدرتی زبان
- اگلے
- این ایل جی
- ویزا
- nlu
- نہیں
- تعداد
- of
- اکثر
- on
- ایک بار
- صرف
- کھول
- اوپن سورس
- or
- دیگر
- دوسری صورت میں
- ہمارے
- پر
- مجموعی طور پر
- مالکان
- حصہ
- راستہ
- راستے
- پیٹرن
- لوگ
- انجام دینے کے
- کارکردگی
- کارکردگی کا مظاہرہ
- مدت
- انسان
- نجیکرت
- مرحلہ
- مراحل
- مقام
- منصوبہ
- منصوبہ بندی
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مہربانی کرکے
- پوائنٹ
- پوزیشن
- قبضہ کرو
- ممکن
- عملی
- پیش گوئی
- کی پیشن گوئی
- کو ترجیح دیتے ہیں
- پیش
- پچھلا
- مسئلہ
- آگے بڑھو
- عمل
- مصنوعات
- مصنوعات کی ترقی
- منصوبے
- سوالات
- سوالات
- R
- رس
- تیار
- اصلی
- حقیقت
- واقعی
- تسلیم
- بھرتی
- کو کم
- حوالہ
- مراد
- خطے
- انحصار کرو
- یاد دہانی
- کی جگہ
- کی ضرورت
- کی ضرورت ہے
- تحقیق
- حل
- جواب
- جوابات
- ذمہ دار
- نتیجے
- نتائج کی نمائش
- انقلابی
- مضبوط
- حکمرانی
- قوانین
- اسی
- کا کہنا ہے کہ
- منظرنامے
- سائنسدان
- فیرنا
- تلاش کریں
- تلاش
- لگتا ہے
- انتخاب
- بھیجنے
- سزا
- کام کرتا ہے
- مقرر
- سیکنڈ اور
- ہونا چاہئے
- اسی طرح
- سادہ
- بعد
- ایک
- شامیوں
- سافٹ ویئر کی
- حل
- حل
- کچھ
- آواز
- مخصوص
- بات
- اسٹیج
- شروع
- ریاستی آرٹ
- خبریں
- کارگر
- طلباء
- کافی
- اس طرح
- موزوں
- حمایت
- سپورٹ سسٹمز
- اس بات کا یقین
- مصنوعی طور پر
- کے نظام
- سسٹمز
- T
- ٹیبل
- لے لو
- لیتا ہے
- ٹاسک
- کاموں
- تکنیک
- متن
- سے
- کہ
- ۔
- ان
- ان
- تو
- وہاں.
- یہ
- وہ
- اس
- اگرچہ؟
- تین
- حد
- وقت
- کرنے کے لئے
- سر
- آواز کی سر
- بھی
- روایتی
- ٹرین
- تربیت یافتہ
- ٹریننگ
- ٹرگر
- دو
- قسم
- اقسام
- افہام و تفہیم
- اپ گریڈ
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- رکن کا
- صارفین
- کا استعمال کرتے ہوئے
- عام طور پر
- اقدار
- کی طرف سے
- مجازی
- وائس
- vs
- W
- راستہ..
- طریقوں
- کا خیر مقدم
- اچھا ہے
- کیا
- جب
- جب بھی
- جس
- جبکہ
- گے
- ساتھ
- لفظ
- الفاظ
- کام
- کام کیا
- گا
- تحریری طور پر
- لکھا
- غلط
- سال
- آپ
- اور
- زیفیرنیٹ