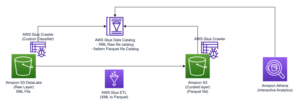
AWS سے چلنے والی ڈیٹا لیکس، کی بے مثال دستیابی کی مدد سے ایمیزون سادہ اسٹوریج سروس (Amazon S3)، مختلف ڈیٹا اور تجزیاتی طریقوں کو یکجا کرنے کے لیے درکار پیمانے، چستی اور لچک کو سنبھال سکتا ہے۔ چونکہ ڈیٹا جھیلیں سائز میں بڑھی ہیں اور استعمال میں پختہ ہو چکی ہیں، اس لیے اعداد و شمار کو کاروباری واقعات کے مطابق رکھنے کے لیے کافی کوششیں کی جا سکتی ہیں۔ اس بات کو یقینی بنانے کے لیے کہ فائلوں کو لین دین کے لحاظ سے مستقل طور پر اپ ڈیٹ کیا جائے، صارفین کی بڑھتی ہوئی تعداد اوپن سورس ٹرانزیکشنل ٹیبل فارمیٹس استعمال کر رہی ہے جیسے اپاچی آئس برگ, اپاچی ہودی، اور لینکس فاؤنڈیشن ڈیلٹا جھیل جو آپ کو اعلی کمپریشن ریٹ کے ساتھ ڈیٹا کو ذخیرہ کرنے میں مدد کرتا ہے، آپ کی ایپلی کیشنز اور فریم ورک کے ساتھ مقامی طور پر انٹرفیس کرتا ہے، اور ایمیزون S3 پر بنی ڈیٹا لیکس میں اضافی ڈیٹا پروسیسنگ کو آسان بناتا ہے۔ یہ فارمیٹس ACID (ایٹمی، مستقل مزاجی، تنہائی، پائیداری) لین دین، اپسرٹس، اور ڈیلیٹس، اور جدید خصوصیات جیسے ٹائم ٹریول اور سنیپ شاٹس کو قابل بناتے ہیں جو پہلے صرف ڈیٹا گوداموں میں دستیاب تھے۔ ہر اسٹوریج فارمیٹ اس فعالیت کو قدرے مختلف طریقوں سے نافذ کرتا ہے۔ موازنہ کے لیے رجوع کریں۔ AWS پر اپنی ٹرانزیکشنل ڈیٹا لیک کے لیے اوپن ٹیبل فارمیٹ کا انتخاب کرنا.
2023 میں AWS نے عام دستیابی کا اعلان کیا۔ اپاچی آئس برگ، اپاچی ہودی، اور لینکس فاؤنڈیشن ڈیلٹا لیک ان کے لیے اپاچی اسپارک کے لیے ایمیزون ایتھینا، جو ایک علیحدہ کنیکٹر یا اس سے وابستہ انحصار کو انسٹال کرنے اور ورژن کا نظم کرنے کی ضرورت کو دور کرتا ہے، اور ان فریم ورک کو استعمال کرنے کے لیے درکار کنفیگریشن کے مراحل کو آسان بناتا ہے۔
اس پوسٹ میں، ہم آپ کو دکھاتے ہیں کہ اسپارک ایس کیو ایل کو کیسے استعمال کیا جائے۔ ایمیزون ایتینا نوٹ بک اور آئس برگ، ہدی، اور ڈیلٹا لیک ٹیبل فارمیٹس کے ساتھ کام کریں۔ ہم عام کاموں کا مظاہرہ کرتے ہیں جیسے ڈیٹا بیس اور ٹیبل بنانا، ٹیبلز میں ڈیٹا داخل کرنا، ڈیٹا سے استفسار کرنا، اور Amazon S3 میں Spark SQL کا استعمال کرتے ہوئے Athena میں ٹیبل کے اسنیپ شاٹس کو دیکھنا۔
شرائط
درج ذیل شرائط کو مکمل کریں:
Amazon S3 سے مثالی نوٹ بک ڈاؤن لوڈ اور درآمد کریں۔
اس کے ساتھ چلنے کے لیے، اس پوسٹ میں زیر بحث نوٹ بکس کو درج ذیل مقامات سے ڈاؤن لوڈ کریں:
نوٹ بک کو ڈاؤن لوڈ کرنے کے بعد، انہیں مندرجہ ذیل کے ذریعے اپنے ایتھینا اسپارک ماحول میں درآمد کریں۔ ایک نوٹ بک درآمد کرنے کے لیے سیکشن میں نوٹ بک فائلوں کا انتظام.
مخصوص اوپن ٹیبل فارمیٹ سیکشن پر جائیں۔
اگر آپ آئس برگ ٹیبل فارمیٹ میں دلچسپی رکھتے ہیں تو تشریف لے جائیں۔ اپاچی آئس برگ ٹیبلز کے ساتھ کام کرنا سیکشن پر ایک اقتصادی کینڈر سکین کر لیں۔
اگر آپ ہدی ٹیبل فارمیٹ میں دلچسپی رکھتے ہیں تو تشریف لے جائیں۔ اپاچی ہودی ٹیبلز کے ساتھ کام کرنا سیکشن پر ایک اقتصادی کینڈر سکین کر لیں۔
اگر آپ ڈیلٹا لیک ٹیبل فارمیٹ میں دلچسپی رکھتے ہیں تو تشریف لے جائیں۔ لینکس فاؤنڈیشن ڈیلٹا لیک ٹیبلز کے ساتھ کام کرنا سیکشن پر ایک اقتصادی کینڈر سکین کر لیں۔
اپاچی آئس برگ ٹیبلز کے ساتھ کام کرنا
ایتھینا میں اسپارک نوٹ بک استعمال کرتے وقت، آپ پی اسپارک کو استعمال کیے بغیر براہ راست ایس کیو ایل کے سوالات چلا سکتے ہیں۔ ہم سیل جادو کا استعمال کرتے ہوئے ایسا کرتے ہیں، جو کہ نوٹ بک سیل میں خاص ہیڈر ہوتے ہیں جو سیل کے رویے کو تبدیل کرتے ہیں۔ ایس کیو ایل کے لیے، ہم شامل کر سکتے ہیں۔ %%sql جادو، جو پورے سیل کے مواد کو ایس کیو ایل اسٹیٹمنٹ کے طور پر بیان کرے گا جسے ایتھینا پر چلایا جائے گا۔
اس سیکشن میں، ہم دکھاتے ہیں کہ آپ Apache Iceberg ٹیبل بنانے، تجزیہ کرنے اور ان کا نظم کرنے کے لیے Apache Spark پر ایس کیو ایل کا استعمال کیسے کر سکتے ہیں۔
ایک نوٹ بک سیشن ترتیب دیں۔
ایتھینا میں اپاچی آئس برگ استعمال کرنے کے لیے، سیشن بناتے یا اس میں ترمیم کرتے وقت، کو منتخب کریں۔ اپاچی آئس برگ کی توسیع کی طرف سے اختیار اپاچی اسپارک کی خصوصیات سیکشن یہ پراپرٹیز کو پہلے سے آباد کرے گا جیسا کہ مندرجہ ذیل اسکرین شاٹ میں دکھایا گیا ہے۔
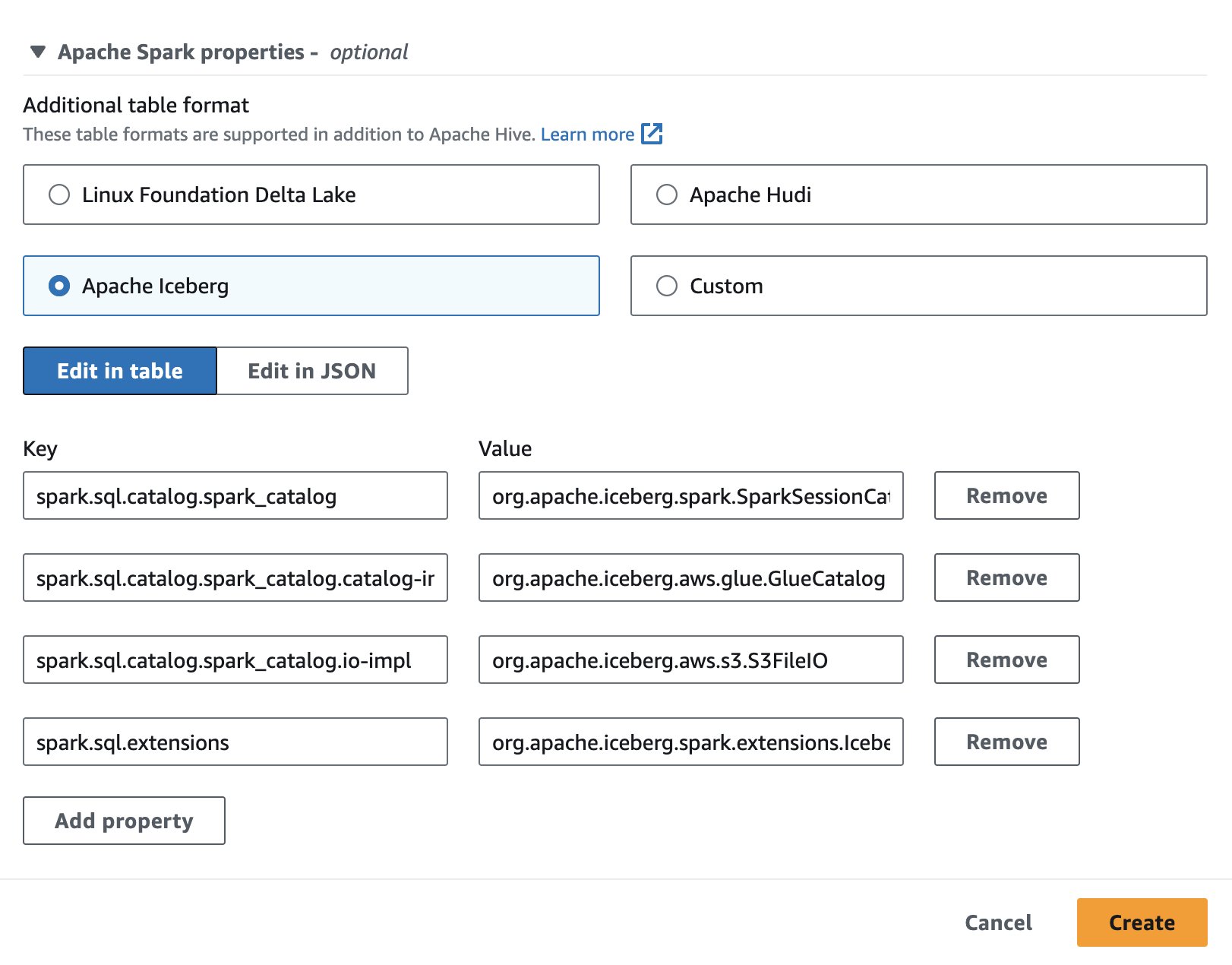
اقدامات کے لیے، دیکھیں سیشن کی تفصیلات میں ترمیم کرنا or اپنی خود کی نوٹ بک بنانا.
اس سیکشن میں استعمال شدہ کوڈ میں دستیاب ہے۔ SparkSQL_iceberg.ipynb فالو کرنے کے لیے فائل۔
ایک ڈیٹا بیس اور آئس برگ ٹیبل بنائیں
سب سے پہلے، ہم AWS Glue Data Catalog میں ایک ڈیٹا بیس بناتے ہیں۔ درج ذیل ایس کیو ایل کے ساتھ، ہم ایک ڈیٹا بیس بنا سکتے ہیں جسے کہتے ہیں۔ icebergdb:
اگلا، ڈیٹا بیس میں icebergdbہم ایک آئس برگ ٹیبل بناتے ہیں جسے کہتے ہیں۔ noaa_iceberg ایمیزون S3 میں ایک مقام کی طرف اشارہ کرتے ہوئے جہاں ہم ڈیٹا لوڈ کریں گے۔ درج ذیل بیان کو چلائیں اور مقام کو تبدیل کریں۔ s3://<your-S3-bucket>/<prefix>/ اپنی S3 بالٹی اور سابقہ کے ساتھ:
ٹیبل میں ڈیٹا داخل کریں۔
کو آباد کرنے کے لیے noaa_iceberg آئس برگ ٹیبل، ہم پارکیٹ ٹیبل سے ڈیٹا داخل کرتے ہیں۔ sparkblogdb.noaa_pq جو کہ شرائط کے حصے کے طور پر بنایا گیا تھا۔ آپ یہ ایک کا استعمال کرکے کر سکتے ہیں۔ داخل کریں اسپارک میں بیان:
متبادل طور پر، آپ استعمال کرسکتے ہیں منتخب کے طور پر ٹیبل بنائیں آئس برگ ٹیبل بنانے اور ایک قدم میں سورس ٹیبل سے ڈیٹا داخل کرنے کے لیے آئس برگ کی شق کے ساتھ:
آئس برگ ٹیبل سے استفسار کریں۔
اب جب کہ ڈیٹا کو آئس برگ ٹیبل میں داخل کیا گیا ہے، ہم اس کا تجزیہ شروع کر سکتے ہیں۔ آئیے اسپارک ایس کیو ایل کو چلائیں تاکہ سال کے لحاظ سے کم از کم ریکارڈ شدہ درجہ حرارت معلوم کیا جا سکے۔ 'SEATTLE TACOMA AIRPORT, WA US' مقام:
ہمیں مندرجہ ذیل آؤٹ پٹ ملتا ہے۔
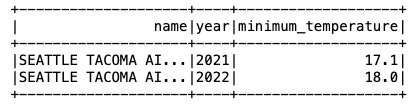
آئس برگ ٹیبل میں ڈیٹا کو اپ ڈیٹ کریں۔
آئیے اپنے ٹیبل میں ڈیٹا کو اپ ڈیٹ کرنے کا طریقہ دیکھتے ہیں۔ ہم اسٹیشن کا نام اپ ڈیٹ کرنا چاہتے ہیں۔ 'SEATTLE TACOMA AIRPORT, WA US' کرنے کے لئے 'Sea-Tac'. اسپارک ایس کیو ایل کا استعمال کرتے ہوئے، ہم ایک چلا سکتے ہیں۔ اپ ڈیٹ آئس برگ ٹیبل کے خلاف بیان:
اس کے بعد ہم کم از کم ریکارڈ شدہ درجہ حرارت تلاش کرنے کے لیے پچھلی SELECT استفسار چلا سکتے ہیں۔ 'Sea-Tac' مقام:
ہمیں درج ذیل آؤٹ پٹ ملتا ہے۔

کومپیکٹ ڈیٹا فائلیں۔
اوپن ٹیبل فارمیٹس جیسے آئس برگ فائل اسٹوریج میں ڈیلٹا تبدیلیاں کرکے اور مینی فیسٹ فائلوں کے ذریعے قطاروں کے ورژن کو ٹریک کرکے کام کرتے ہیں۔ زیادہ ڈیٹا فائلز مینی فیسٹ فائلوں میں زیادہ میٹا ڈیٹا ذخیرہ کرنے کا باعث بنتی ہیں، اور چھوٹی ڈیٹا فائلیں اکثر غیر ضروری مقدار میں میٹا ڈیٹا کا باعث بنتی ہیں، جس کے نتیجے میں کم موثر سوالات اور ایمیزون S3 تک رسائی کے زیادہ اخراجات ہوتے ہیں۔ چل رہا ہے Iceberg's rewrite_data_files ایتھینا کے لیے اسپارک میں طریقہ کار ڈیٹا فائلوں کو کمپیکٹ کرے گا، بہت سی چھوٹی ڈیلٹا تبدیلی فائلوں کو پڑھنے کے لیے آپٹمائزڈ پارکویٹ فائلوں کے ایک چھوٹے سیٹ میں ملا کر۔ جب استفسار کیا جائے تو فائلوں کو کمپیکٹ کرنا پڑھنے کے عمل کو تیز کرتا ہے۔ ہمارے ٹیبل پر کمپیکشن چلانے کے لیے درج ذیل اسپارک ایس کیو ایل کو چلائیں:
rewrite_data_files اختیارات پیش کرتا ہے۔ اپنی ترتیب کی حکمت عملی کی وضاحت کرنے کے لیے، جس سے ڈیٹا کو دوبارہ ترتیب دینے اور کمپیکٹ کرنے میں مدد مل سکتی ہے۔
ٹیبل اسنیپ شاٹس کی فہرست بنائیں
آئس برگ ٹیبل پر ہر تحریر، اپ ڈیٹ، ڈیلیٹ، اپسرٹ، اور کمپیکشن آپریشن اسنیپ شاٹ آئسولیشن اور ٹائم ٹریول کے لیے پرانے ڈیٹا اور میٹا ڈیٹا کو ساتھ رکھتے ہوئے ٹیبل کا ایک نیا سنیپ شاٹ بناتا ہے۔ آئس برگ ٹیبل کے سنیپ شاٹس کی فہرست بنانے کے لیے درج ذیل اسپارک ایس کیو ایل اسٹیٹمنٹ کو چلائیں:
پرانے سنیپ شاٹس کی میعاد ختم
ان ڈیٹا فائلوں کو حذف کرنے کے لیے جن کی مزید ضرورت نہیں ہے، اور ٹیبل میٹا ڈیٹا کا سائز چھوٹا رکھنے کے لیے باقاعدگی سے اسنیپ شاٹس کی میعاد ختم ہونے کی سفارش کی جاتی ہے۔ یہ کبھی بھی ان فائلوں کو نہیں ہٹائے گا جن کی اب بھی غیر میعاد ختم ہونے والے سنیپ شاٹ کی ضرورت ہے۔ اسپارک فار ایتھینا میں، ٹیبل کے سنیپ شاٹس کی میعاد ختم کرنے کے لیے درج ذیل ایس کیو ایل کو چلائیں۔ icebergdb.noaa_iceberg جو ایک مخصوص ٹائم اسٹیمپ سے پرانے ہیں:
نوٹ کریں کہ ٹائم اسٹیمپ ویلیو فارمیٹ میں سٹرنگ کے طور پر بیان کی گئی ہے۔ yyyy-MM-dd HH:mm:ss.fff. آؤٹ پٹ حذف شدہ ڈیٹا اور میٹا ڈیٹا فائلوں کی تعداد کا حساب دے گا۔
ٹیبل اور ڈیٹا بیس کو گرا دیں۔
آپ اس مشق سے Amazon S3 میں آئس برگ ٹیبلز اور متعلقہ ڈیٹا کو صاف کرنے کے لیے درج ذیل Spark SQL چلا سکتے ہیں۔
ڈیٹا بیس icebergdb کو ہٹانے کے لیے درج ذیل Spark SQL چلائیں:
ان تمام آپریشنز کے بارے میں مزید جاننے کے لیے جو آپ اسپارک فار ایتھینا کا استعمال کرتے ہوئے آئس برگ ٹیبلز پر انجام دے سکتے ہیں، دیکھیں۔ چنگاری کے سوالات اور چنگاری کے طریقہ کار آئس برگ دستاویزات میں۔
اپاچی ہودی ٹیبلز کے ساتھ کام کرنا
اگلا، ہم دکھاتے ہیں کہ آپ کس طرح Apache Hudi ٹیبل بنانے، تجزیہ کرنے اور ان کا نظم کرنے کے لیے Spark on Athena کا استعمال کر سکتے ہیں۔
ایک نوٹ بک سیشن ترتیب دیں۔
ایتھینا میں اپاچی ہودی کو استعمال کرنے کے لیے، سیشن بناتے یا اس میں ترمیم کرتے وقت، کو منتخب کریں۔ اپاچی ہودی کی توسیع کی طرف سے اختیار اپاچی اسپارک کی خصوصیات سیکشن پر ایک اقتصادی کینڈر سکین کر لیں۔
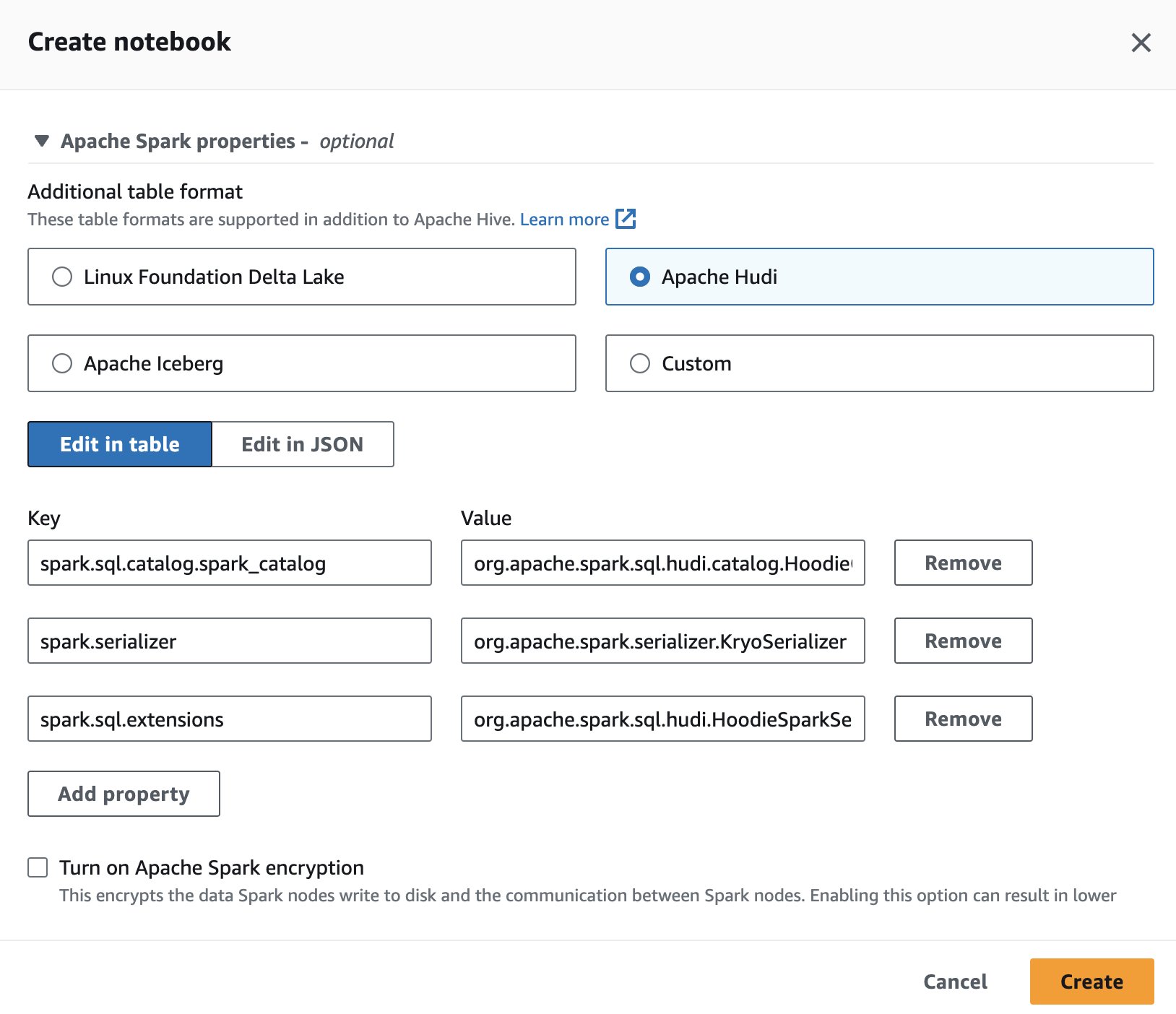
اقدامات کے لیے، دیکھیں سیشن کی تفصیلات میں ترمیم کرنا or اپنی خود کی نوٹ بک بنانا.
اس سیکشن میں استعمال شدہ کوڈ میں دستیاب ہونا چاہیے۔ SparkSQL_hudi.ipynb فالو کرنے کے لیے فائل۔
ایک ڈیٹا بیس اور ہدی ٹیبل بنائیں
سب سے پہلے، ہم کہتے ہیں ایک ڈیٹا بیس بناتے ہیں hudidb جسے AWS Glue Data Catalog میں ذخیرہ کیا جائے گا جس کے بعد Hudi ٹیبل کی تخلیق:
ہم ایمیزون S3 میں ایک مقام کی طرف اشارہ کرتے ہوئے ایک ہدی ٹیبل بناتے ہیں جہاں ہم ڈیٹا لوڈ کریں گے۔ نوٹ کریں کہ ٹیبل کا ہے۔ کاپی آن لکھیں قسم اس کی تعریف کی گئی ہے۔ type= 'cow' ٹیبل ڈی ڈی ایل میں۔ ہم نے اسٹیشن اور تاریخ کو ایک سے زیادہ بنیادی کلیدوں کے طور پر اور preCombinedField کو سال کے طور پر بیان کیا ہے۔ اس کے علاوہ، میز کو سال پر تقسیم کیا جاتا ہے. درج ذیل بیان کو چلائیں اور مقام کو تبدیل کریں۔ s3://<your-S3-bucket>/<prefix>/ اپنی S3 بالٹی اور سابقہ کے ساتھ:
ٹیبل میں ڈیٹا داخل کریں۔
آئس برگ کی طرح، ہم استعمال کرتے ہیں۔ داخل کریں سے ڈیٹا پڑھ کر ٹیبل کو آباد کرنے کا بیان sparkblogdb.noaa_pq پچھلی پوسٹ میں بنائی گئی جدول:
ہودی ٹیبل سے استفسار کریں۔
اب جب کہ ٹیبل بن گیا ہے، آئیے زیادہ سے زیادہ ریکارڈ شدہ درجہ حرارت تلاش کرنے کے لیے ایک سوال چلائیں۔ 'SEATTLE TACOMA AIRPORT, WA US' مقام:
ہدی ٹیبل میں ڈیٹا کو اپ ڈیٹ کریں۔
چلو سٹیشن کا نام بدلتے ہیں۔ 'SEATTLE TACOMA AIRPORT, WA US' کرنے کے لئے 'Sea–Tac'. ہم اسپارک فار ایتھینا ٹو پر اپ ڈیٹ اسٹیٹمنٹ چلا سکتے ہیں۔ اپ ڈیٹ کے ریکارڈ noaa_hudi ٹیبل:
کے لیے زیادہ سے زیادہ ریکارڈ شدہ درجہ حرارت تلاش کرنے کے لیے ہم پچھلی SELECT استفسار چلاتے ہیں۔ 'Sea-Tac' مقام:
ٹائم ٹریول کے سوالات چلائیں۔
ہم ماضی کے ڈیٹا سنیپ شاٹس کا تجزیہ کرنے کے لیے ایس کیو ایل آن ایتھینا میں ٹائم ٹریول کے سوالات استعمال کر سکتے ہیں۔ مثال کے طور پر:
یہ استفسار ماضی میں مخصوص وقت کے مطابق سیٹل ہوائی اڈے کے درجہ حرارت کا ڈیٹا چیک کرتا ہے۔ ٹائم اسٹیمپ کی شق ہمیں موجودہ ڈیٹا کو تبدیل کیے بغیر واپس سفر کرنے دیتی ہے۔ نوٹ کریں کہ ٹائم اسٹیمپ ویلیو فارمیٹ میں سٹرنگ کے طور پر بیان کی گئی ہے۔ yyyy-MM-dd HH:mm:ss.fff.
کلسٹرنگ کے ساتھ استفسار کی رفتار کو بہتر بنائیں
استفسار کی کارکردگی کو بہتر بنانے کے لیے، آپ انجام دے سکتے ہیں۔ clustering کے Athena کے لیے Spark میں SQL کا استعمال کرتے ہوئے Hudi ٹیبلز پر:
کومپیکٹ میزیں۔
کومپیکشن ایک ٹیبل سروس ہے جو ہدی کے ذریعہ خاص طور پر مرج آن ریڈ (MOR) ٹیبلز میں استعمال کی جاتی ہے تاکہ قطار پر مبنی لاگ فائلوں سے متعلقہ کالم پر مبنی بیس فائل میں اپ ڈیٹس کو وقتاً فوقتاً بیس فائل کا نیا ورژن تیار کرنے کے لیے ضم کیا جاسکے۔ کومپیکشن کاپی آن رائٹ (COW) ٹیبلز پر لاگو نہیں ہوتا ہے اور صرف MOR ٹیبلز پر لاگو ہوتا ہے۔ ایم او آر ٹیبلز پر کمپیکشن کرنے کے لیے آپ اسپارک فار ایتھینا میں درج ذیل استفسار چلا سکتے ہیں۔
ٹیبل اور ڈیٹا بیس کو گرا دیں۔
ایمیزون S3 مقام سے آپ نے جو ہدی ٹیبل بنایا ہے اور اس سے وابستہ ڈیٹا کو ہٹانے کے لیے درج ذیل اسپارک ایس کیو ایل کو چلائیں:
ڈیٹا بیس کو ہٹانے کے لیے درج ذیل Spark SQL چلائیں۔ hudidb:
ان تمام آپریشنز کے بارے میں جاننے کے لیے جو آپ Spark for Athena کا استعمال کرتے ہوئے ہدی ٹیبلز پر انجام دے سکتے ہیں، ملاحظہ کریں۔ ایس کیو ایل ڈی ڈی ایل اور طریقہ کار ہودی دستاویزات میں۔
لینکس فاؤنڈیشن ڈیلٹا لیک ٹیبلز کے ساتھ کام کرنا
اگلا، ہم دکھاتے ہیں کہ آپ کس طرح ڈیلٹا لیک ٹیبل بنانے، تجزیہ کرنے اور ان کا نظم کرنے کے لیے ایس کیو ایل آن اسپارک فار ایتھینا کا استعمال کر سکتے ہیں۔
ایک نوٹ بک سیشن ترتیب دیں۔
اسپارک میں ڈیلٹا لیک کو ایتھینا کے لیے استعمال کرنے کے لیے، سیشن بناتے یا اس میں ترمیم کرتے وقت، منتخب کریں۔ لینکس فاؤنڈیشن ڈیلٹا جھیل کو بڑھا کر اپاچی اسپارک کی خصوصیات سیکشن پر ایک اقتصادی کینڈر سکین کر لیں۔
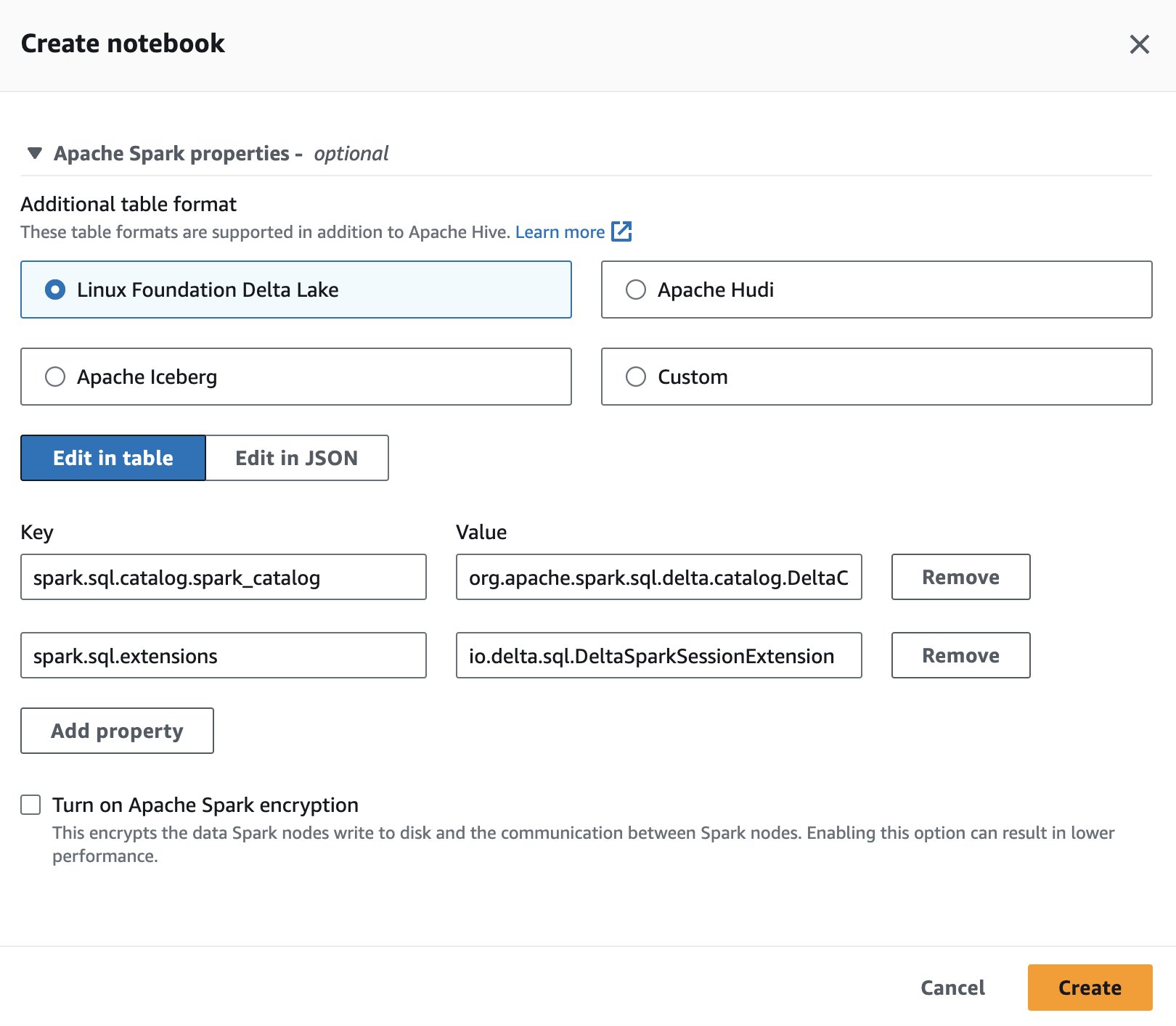
اقدامات کے لیے، دیکھیں سیشن کی تفصیلات میں ترمیم کرنا or اپنی خود کی نوٹ بک بنانا.
اس سیکشن میں استعمال شدہ کوڈ میں دستیاب ہونا چاہیے۔ SparkSQL_delta.ipynb فالو کرنے کے لیے فائل۔
ایک ڈیٹا بیس اور ڈیلٹا لیک ٹیبل بنائیں
اس حصے میں، ہم AWS Glue Data Catalog میں ایک ڈیٹا بیس بناتے ہیں۔ درج ذیل ایس کیو ایل کا استعمال کرتے ہوئے، ہم ایک ڈیٹا بیس بنا سکتے ہیں۔ deltalakedb:
اگلا، ڈیٹا بیس میں deltalakedb، ہم ایک ڈیلٹا لیک ٹیبل بناتے ہیں جسے کہتے ہیں۔ noaa_delta ایمیزون S3 میں ایک مقام کی طرف اشارہ کرتے ہوئے جہاں ہم ڈیٹا لوڈ کریں گے۔ درج ذیل بیان کو چلائیں اور مقام کو تبدیل کریں۔ s3://<your-S3-bucket>/<prefix>/ اپنی S3 بالٹی اور سابقہ کے ساتھ:
ٹیبل میں ڈیٹا داخل کریں۔
ہم ایک استعمال کرتے ہیں داخل کریں سے ڈیٹا پڑھ کر ٹیبل کو آباد کرنے کا بیان sparkblogdb.noaa_pq پچھلی پوسٹ میں بنائی گئی جدول:
آپ ڈیلٹا لیک ٹیبل بنانے اور ایک سوال میں سورس ٹیبل سے ڈیٹا داخل کرنے کے لیے CREATE TABLE AS SELECT کا استعمال بھی کر سکتے ہیں۔
ڈیلٹا لیک ٹیبل سے استفسار کریں۔
اب جبکہ ڈیٹا ڈیلٹا لیک ٹیبل میں داخل ہو چکا ہے، ہم اس کا تجزیہ شروع کر سکتے ہیں۔ آئیے اسپارک ایس کیو ایل کو چلاتے ہیں تاکہ کم از کم ریکارڈ شدہ درجہ حرارت معلوم کریں۔ 'SEATTLE TACOMA AIRPORT, WA US' مقام:
ڈیلٹا جھیل ٹیبل میں ڈیٹا کو اپ ڈیٹ کریں۔
چلو سٹیشن کا نام بدلتے ہیں۔ 'SEATTLE TACOMA AIRPORT, WA US' کرنے کے لئے 'Sea–Tac'. ہم ایک چلا سکتے ہیں اپ ڈیٹ اسپارک فار ایتھینا کے ریکارڈ کو اپ ڈیٹ کرنے کے لیے بیان noaa_delta ٹیبل:
کم از کم ریکارڈ شدہ درجہ حرارت معلوم کرنے کے لیے ہم پچھلی SELECT استفسار چلا سکتے ہیں۔ 'Sea-Tac' مقام، اور نتیجہ پہلے جیسا ہی ہونا چاہئے:
کومپیکٹ ڈیٹا فائلیں۔
اسپارک فار ایتھینا میں، آپ ڈیلٹا لیک ٹیبل پر اوپٹمائز چلا سکتے ہیں، جو چھوٹی فائلوں کو بڑی فائلوں میں کمپیکٹ کرے گا، اس لیے سوالات پر چھوٹی فائل اوور ہیڈ کا بوجھ نہیں پڑے گا۔ کمپیکشن آپریشن کرنے کے لیے، درج ذیل استفسار کو چلائیں:
کا حوالہ دیتے ہیں اصلاحات OPTIMIZE کو چلانے کے دوران دستیاب مختلف اختیارات کے لیے ڈیلٹا لیک دستاویزات میں۔
ڈیلٹا لیک ٹیبل کی طرف سے مزید حوالہ نہ دینے والی فائلوں کو ہٹا دیں۔
آپ ایمیزون S3 میں ذخیرہ شدہ فائلوں کو ہٹا سکتے ہیں جن کا اب ڈیلٹا لیک ٹیبل کے ذریعہ حوالہ نہیں دیا گیا ہے اور وہ اسپارک فار ایتھینا کا استعمال کرتے ہوئے ٹیبل پر VACCUM کمانڈ چلا کر برقرار رکھنے کی حد سے زیادہ پرانی ہیں:
کا حوالہ دیتے ہیں ڈیلٹا ٹیبل کی طرف سے مزید حوالہ نہ دینے والی فائلوں کو ہٹا دیں۔ VACUUM کے ساتھ دستیاب اختیارات کے لیے ڈیلٹا لیک دستاویزات میں۔
ٹیبل اور ڈیٹا بیس کو گرا دیں۔
آپ نے جو ڈیلٹا لیک ٹیبل بنایا ہے اسے ہٹانے کے لیے درج ذیل Spark SQL چلائیں:
ڈیٹا بیس کو ہٹانے کے لیے درج ذیل Spark SQL چلائیں۔ deltalakedb:
ڈیلٹا لیک ٹیبل اور ڈیٹا بیس پر DROP TABLE DDL چلانے سے ان اشیاء کا میٹا ڈیٹا حذف ہو جاتا ہے، لیکن Amazon S3 میں موجود ڈیٹا فائلوں کو خود بخود حذف نہیں کرتا ہے۔ آپ S3 مقام سے ڈیٹا کو حذف کرنے کے لیے نوٹ بک کے سیل میں درج ذیل Python کوڈ چلا سکتے ہیں۔
ایس کیو ایل کے بیانات کے بارے میں مزید جاننے کے لیے جنہیں آپ اسپارک فار ایتھینا کا استعمال کرتے ہوئے ڈیلٹا لیک ٹیبل پر چلا سکتے ہیں، دیکھیں Quickstart کے ڈیلٹا لیک دستاویزات میں۔
نتیجہ
اس پوسٹ نے دکھایا ہے کہ ڈیٹا بیس اور ٹیبلز بنانے، ڈیٹا داخل کرنے اور استفسار کرنے، اور ہدی، ڈیلٹا لیک، اور آئس برگ ٹیبلز پر اپ ڈیٹس، کمپیکشنز، اور ٹائم ٹریول جیسے عام آپریشنز کو انجام دینے کے لیے ایتھینا نوٹ بک میں اسپارک ایس کیو ایل کا استعمال کیسے کیا جائے۔ اوپن ٹیبل فارمیٹس ACID ٹرانزیکشنز، اپسرٹس، اور ڈیلیٹس ڈیٹا لیکس میں شامل کرتے ہیں، خام آبجیکٹ اسٹوریج کی حدود پر قابو پاتے ہیں۔ علیحدہ کنیکٹرز کو انسٹال کرنے کی ضرورت کو دور کرتے ہوئے، Athena کے بلٹ ان انٹیگریشن پر Spark Amazon S3 پر قابل اعتماد ڈیٹا لیکس بنانے کے لیے ان مقبول فریم ورکس کا استعمال کرتے وقت کنفیگریشن کے مراحل اور مینجمنٹ اوور ہیڈ کو کم کرتا ہے۔ اپنے ڈیٹا لیک ورک بوجھ کے لیے اوپن ٹیبل فارمیٹ کو منتخب کرنے کے بارے میں مزید جاننے کے لیے، دیکھیں AWS پر اپنی ٹرانزیکشنل ڈیٹا لیک کے لیے اوپن ٹیبل فارمیٹ کا انتخاب کرنا.
مصنفین کے بارے میں
![]() پتھک شاہ ایمیزون ایتھینا پر ایک سینئر اینالیٹکس آرکیٹیکٹ ہے۔ اس نے 2015 میں AWS میں شمولیت اختیار کی اور تب سے بڑے ڈیٹا اینالیٹکس کی جگہ پر توجہ مرکوز کر رہا ہے، جس سے صارفین کو AWS تجزیاتی خدمات کا استعمال کرتے ہوئے قابل توسیع اور مضبوط حل تیار کرنے میں مدد مل رہی ہے۔
پتھک شاہ ایمیزون ایتھینا پر ایک سینئر اینالیٹکس آرکیٹیکٹ ہے۔ اس نے 2015 میں AWS میں شمولیت اختیار کی اور تب سے بڑے ڈیٹا اینالیٹکس کی جگہ پر توجہ مرکوز کر رہا ہے، جس سے صارفین کو AWS تجزیاتی خدمات کا استعمال کرتے ہوئے قابل توسیع اور مضبوط حل تیار کرنے میں مدد مل رہی ہے۔
![]() راج دیو ناتھ Amazon Athena پر AWS میں پروڈکٹ مینیجر ہے۔ وہ صارفین کی پسند کی مصنوعات بنانے اور صارفین کو ان کے ڈیٹا سے قیمت نکالنے میں مدد کرنے کے بارے میں پرجوش ہے۔ اس کا پس منظر متعدد اختتامی منڈیوں کے لیے حل فراہم کرنے میں ہے، جیسے فنانس، ریٹیل، سمارٹ بلڈنگز، ہوم آٹومیشن، اور ڈیٹا کمیونیکیشن سسٹم۔
راج دیو ناتھ Amazon Athena پر AWS میں پروڈکٹ مینیجر ہے۔ وہ صارفین کی پسند کی مصنوعات بنانے اور صارفین کو ان کے ڈیٹا سے قیمت نکالنے میں مدد کرنے کے بارے میں پرجوش ہے۔ اس کا پس منظر متعدد اختتامی منڈیوں کے لیے حل فراہم کرنے میں ہے، جیسے فنانس، ریٹیل، سمارٹ بلڈنگز، ہوم آٹومیشن، اور ڈیٹا کمیونیکیشن سسٹم۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- ہمارے بارے میں
- تک رسائی حاصل
- شامل کریں
- اعلی درجے کی
- کے خلاف
- ہوائی اڈے
- تمام
- ساتھ
- بھی
- ایمیزون
- ایمیزون ایتینا
- ایمیزون ویب سروسز
- رقم
- an
- تجزیاتی
- تجزیے
- تجزیہ
- اور
- کا اعلان کیا ہے
- اپاچی
- اپاچی چمک
- قابل اطلاق
- ایپلی کیشنز
- لاگو ہوتا ہے
- نقطہ نظر
- کیا
- ارد گرد
- AS
- منسلک
- At
- خود کار طریقے سے
- میشن
- دستیابی
- دستیاب
- AWS
- AWS گلو
- واپس
- پس منظر
- بیس
- BE
- رہا
- رویے
- بگ
- بگ ڈیٹا
- تعمیر
- عمارت
- تعمیر
- تعمیر میں
- کاروبار
- لیکن
- by
- فون
- کہا جاتا ہے
- کر سکتے ہیں
- کیٹلوگ
- کیونکہ
- سیل
- تبدیل
- تبدیلیاں
- چیک
- صاف
- کوڈ
- جمع
- امتزاج
- کامن
- مواصلات
- مواصلات کے نظام
- کمپیکٹ
- موازنہ
- ترتیب
- متواتر
- مندرجات
- اسی کے مطابق
- اخراجات
- شمار
- تخلیق
- بنائی
- پیدا
- تخلیق
- مخلوق
- موجودہ
- گاہکوں
- اعداد و شمار
- ڈیٹا تجزیات
- ڈیٹا لیک
- ڈیٹا پروسیسنگ
- ڈیٹا گودام
- ڈیٹا بیس
- ڈیٹا بیس
- تاریخ
- کی وضاحت
- ترسیل
- ڈیلٹا
- مظاہرہ
- demonstrated,en
- انحصار
- مختلف
- براہ راست
- بات چیت
- do
- دستاویزات
- نہیں کرتا
- ڈاؤن لوڈ، اتارنا
- چھوڑ
- استحکام
- ہر ایک
- اس سے قبل
- ترمیم
- ہنر
- کوشش
- ملازم
- کو چالو کرنے کے
- آخر
- کو یقینی بنانے کے
- پوری
- ماحولیات
- Ether (ETH)
- واقعات
- مثال کے طور پر
- ورزش
- توسیع
- نکالنے
- خصوصیات
- فائل
- فائلوں
- کی مالی اعانت
- مل
- پہلا
- لچک
- توجہ مرکوز
- پر عمل کریں
- پیچھے پیچھے
- کے بعد
- کے لئے
- فارمیٹ
- فاؤنڈیشن
- فریم ورک
- سے
- فعالیت
- جنرل
- حاصل
- دے دو
- گروپ
- بڑھتے ہوئے
- اضافہ ہوا
- ہینڈل
- ہے
- ہونے
- he
- ہیڈر
- مدد
- مدد
- hh
- ہائی
- اعلی
- ان
- ہوم پیج (-)
- ہوم میشن۔
- کس طرح
- کیسے
- HTML
- HTTP
- HTTPS
- تصویر
- عمل
- درآمد
- کو بہتر بنانے کے
- in
- اضافہ
- انسٹال
- انضمام
- دلچسپی
- انٹرفیس
- میں
- تنہائی
- IT
- شامل ہو گئے
- فوٹو
- رکھیں
- رکھتے ہوئے
- چابیاں
- جھیل
- جھیلوں
- بڑے
- طول بلد
- لیڈز
- جانیں
- کم
- آو ہم
- کی طرح
- حدود
- لینکس
- لینکس فاؤنڈیشن
- لسٹ
- لوڈ
- محل وقوع
- مقامات
- لاگ ان کریں
- اب
- دیکھو
- تلاش
- محبت
- ماجک
- انتظام
- انتظام
- مینیجر
- انداز
- بہت سے
- Markets
- میکس
- زیادہ سے زیادہ
- ضم کریں
- میٹا ڈیٹا
- منٹ
- کم سے کم
- زیادہ
- ایک سے زیادہ
- نام
- natively
- تشریف لے جائیں
- ضرورت ہے
- ضرورت
- کبھی نہیں
- نئی
- نہیں
- براہ مہربانی نوٹ کریں
- نوٹ بک
- نوٹ بک
- تعداد
- اعتراض
- آبجیکٹ اسٹوریج
- اشیاء
- of
- تجویز
- اکثر
- پرانا
- بڑی عمر کے
- on
- ایک
- صرف
- OP
- کھول
- اوپن سورس
- آپریشن
- آپریشنز
- کی اصلاح کریں
- اختیار
- آپشنز کے بھی
- or
- حکم
- ہمارے
- پیداوار
- پر قابو پانے
- خود
- حصہ
- جذباتی
- گزشتہ
- انجام دینے کے
- کارکردگی
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مقبول
- پوسٹ
- ضروریات
- پچھلا
- پہلے
- پرائمری
- طریقہ کار
- پروسیسنگ
- پیدا
- مصنوعات
- پروڈکٹ مینیجر
- حاصل
- خصوصیات
- ازگر
- سوالات
- قیمتیں
- خام
- پڑھیں
- پڑھنا
- سفارش کی
- درج
- ریکارڈ
- کم
- کا حوالہ دیتے ہیں
- حوالہ دیا
- قابل اعتماد
- ہٹا
- ہٹاتا ہے
- کو ہٹانے کے
- کی جگہ
- ضرورت
- نتیجہ
- نتیجے
- خوردہ
- برقراری
- مضبوط
- رن
- چل رہا ہے
- اسی
- توسیع پذیر
- پیمانے
- سیٹل
- دوسری
- سیکشن
- دیکھنا
- منتخب
- منتخب
- علیحدہ
- سروس
- سروسز
- اجلاس
- مقرر
- ہونا چاہئے
- دکھائیں
- دکھایا گیا
- شوز
- اہم
- سادہ
- آسان بناتا ہے۔
- آسان بنانے
- بعد
- سائز
- تھوڑا سا مختلف
- SLP
- چھوٹے
- چھوٹے
- ہوشیار
- سنیپشاٹ
- So
- حل
- ماخذ
- خلا
- چنگاری
- خصوصی
- مخصوص
- خاص طور پر
- مخصوص
- تیزی
- رفتار
- خرچ
- SQL
- شروع کریں
- بیان
- بیانات
- سٹیشن
- مرحلہ
- مراحل
- ابھی تک
- ذخیرہ
- ذخیرہ
- ذخیرہ
- حکمت عملی
- سلک
- اس طرح
- تائید
- کے نظام
- سسٹمز
- ٹیبل
- Tacoma
- سے
- کہ
- ۔
- ان
- ان
- تو
- یہ
- اس
- حد
- کے ذریعے
- وقت
- وقت سفر
- ٹائمسٹیمپ
- کرنے کے لئے
- ٹریکنگ
- لین دین
- معاملات
- سفر
- قسم
- بے مثال
- اپ ڈیٹ کریں
- اپ ڈیٹ
- تازہ ترین معلومات
- us
- استعمال
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- کا استعمال کرتے ہوئے
- ویکیوم
- قیمت
- ورژن
- ورژن
- چاہتے ہیں
- تھا
- طریقوں
- we
- ویب
- ویب خدمات
- تھے
- جب
- جس
- جبکہ
- گے
- ساتھ
- بغیر
- کام
- لکھنا
- سال
- آپ
- اور
- زیفیرنیٹ