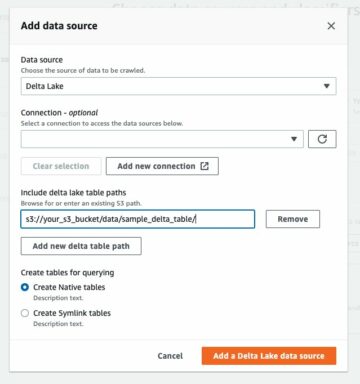
آج کے ڈیجیٹل دور میں، ڈیٹا ہر ادارے کی کامیابی کا مرکز ہے۔ ڈیٹا کے تبادلے کے لیے سب سے زیادہ استعمال ہونے والے فارمیٹس میں سے ایک XML ہے۔ XML فائلوں کا تجزیہ کئی وجوہات کی بناء پر اہم ہے۔ سب سے پہلے، XML فائلیں بہت سی صنعتوں میں استعمال ہوتی ہیں، بشمول فنانس، ہیلتھ کیئر، اور حکومت۔ XML فائلوں کا تجزیہ کرنے سے تنظیموں کو اپنے ڈیٹا میں بصیرت حاصل کرنے میں مدد مل سکتی ہے، جس سے وہ بہتر فیصلے کر سکتے ہیں اور اپنے کام کو بہتر بنا سکتے ہیں۔ XML فائلوں کا تجزیہ کرنے سے ڈیٹا کے انضمام میں بھی مدد مل سکتی ہے، کیونکہ بہت سے ایپلیکیشنز اور سسٹمز XML کو معیاری ڈیٹا فارمیٹ کے طور پر استعمال کرتے ہیں۔ XML فائلوں کا تجزیہ کر کے، تنظیمیں مختلف ذرائع سے ڈیٹا کو آسانی سے ضم کر سکتی ہیں اور اپنے سسٹمز میں مستقل مزاجی کو یقینی بنا سکتی ہیں، تاہم، XML فائلوں میں نیم ساختہ، انتہائی نیسٹڈ ڈیٹا ہوتا ہے، جس سے معلومات تک رسائی اور تجزیہ کرنا مشکل ہو جاتا ہے، خاص طور پر اگر فائل بڑی ہو اور پیچیدہ، انتہائی نیسٹڈ اسکیما۔
XML فائلیں ایپلی کیشنز کے لیے اچھی طرح سے موزوں ہیں، لیکن یہ اینالیٹکس انجن کے لیے بہترین نہیں ہو سکتی ہیں۔ استفسار کی کارکردگی کو بڑھانے اور بہاو تجزیاتی انجنوں میں آسان رسائی کو فعال کرنے کے لیے جیسے ایمیزون ایتیناXML فائلوں کو Parquet جیسے کالمی فارمیٹ میں پہلے سے پروسیس کرنا بہت ضروری ہے۔ یہ تبدیلی تجزیاتی ورک فلو میں بہتر کارکردگی اور استعمال کی اجازت دیتی ہے۔ اس پوسٹ میں، ہم دکھاتے ہیں کہ کس طرح XML ڈیٹا کو استعمال کرتے ہوئے پروسیس کیا جائے۔ AWS گلو اور ایتھینا۔
حل جائزہ
ہم دو الگ الگ تکنیکوں کو دریافت کرتے ہیں جو آپ کے XML فائل پروسیسنگ ورک فلو کو ہموار کر سکتی ہیں:
- تکنیک 1: AWS Glue کرالر اور AWS Glue بصری ایڈیٹر کا استعمال کریں - آپ اپنی XML فائلوں کے لیے ٹیبل کی ساخت کی وضاحت کرنے کے لیے AWS Glue یوزر انٹرفیس کو کرالر کے ساتھ استعمال کر سکتے ہیں۔ یہ نقطہ نظر ایک صارف دوست انٹرفیس فراہم کرتا ہے اور خاص طور پر ان افراد کے لیے موزوں ہے جو اپنے ڈیٹا کو منظم کرنے کے لیے گرافیکل انداز کو ترجیح دیتے ہیں۔
- تکنیک 2: تخمینہ شدہ اور فکسڈ اسکیموں کے ساتھ AWS Glue Dynamic Frames استعمال کریں - جب اس سے بڑی XML فائلوں میں ایک قطار پر کارروائی کرنے کی بات آتی ہے تو کرالر کی ایک حد ہوتی ہے۔ 1 MB. اس پابندی پر قابو پانے کے لیے، ہم AWS Glue کی تعمیر کے لیے AWS Glue نوٹ بک کا استعمال کرتے ہیں۔
DynamicFrames، تخمینہ شدہ اور فکسڈ دونوں اسکیموں کا استعمال کرتے ہوئے یہ طریقہ XML فائلوں کی 1 MB سے زیادہ سائز والی قطاروں کے ساتھ موثر ہینڈلنگ کو یقینی بناتا ہے۔
دونوں طریقوں میں، ہمارا حتمی مقصد XML فائلوں کو Apache Parquet فارمیٹ میں تبدیل کرنا ہے، جس سے وہ ایتھینا کا استعمال کرتے ہوئے استفسار کے لیے آسانی سے دستیاب ہوں۔ ان تکنیکوں کے ساتھ، آپ اپنے XML ڈیٹا کی پروسیسنگ کی رفتار اور رسائی کو بڑھا سکتے ہیں، جس سے آپ آسانی سے قیمتی بصیرت حاصل کر سکتے ہیں۔
شرائط
اس ٹیوٹوریل کو شروع کرنے سے پہلے، درج ذیل شرائط کو مکمل کریں (یہ دونوں تکنیکوں پر لاگو ہوتے ہیں):
- XML فائلیں ڈاؤن لوڈ کریں۔ technology1.xml اور technology2.xml.
- فائلوں کو ایک پر اپ لوڈ کریں۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) بالٹی۔ آپ انہیں ایک ہی S3 بالٹی میں مختلف فولڈرز میں یا مختلف S3 بالٹیوں میں اپ لوڈ کر سکتے ہیں۔
- بنائیں ایک AWS شناخت اور رسائی کا انتظام آپ کی ETL جاب یا نوٹ بک کے لیے (IAM) کا کردار جیسا کہ ہدایت کی گئی ہے۔ AWS Glue Studio کے لیے IAM اجازتیں مرتب کریں۔.
- کے ساتھ اپنے کردار میں ایک ان لائن پالیسی شامل کریں۔ پہلے سے ہی: پاس رول عمل:
- اپنی S3 بالٹی تک رسائی کے ساتھ کردار میں اجازت کی پالیسی شامل کریں۔
اب جب کہ ہم شرطیں پوری کر چکے ہیں، آئیے پہلی تکنیک کو لاگو کرنے کی طرف بڑھتے ہیں۔
تکنیک 1: AWS Glue کرالر اور بصری ایڈیٹر استعمال کریں۔
درج ذیل خاکہ سادہ فن تعمیر کی وضاحت کرتا ہے جسے آپ حل کو نافذ کرنے کے لیے استعمال کر سکتے ہیں۔
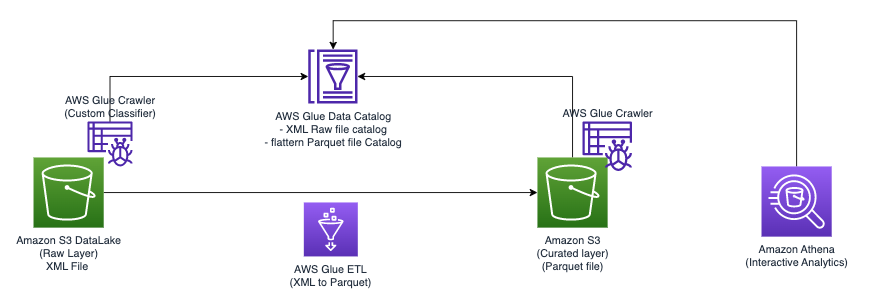
AWS Glue اور Athena کا استعمال کرتے ہوئے Amazon S3 میں ذخیرہ کردہ XML فائلوں کا تجزیہ کرنے کے لیے، ہم درج ذیل اعلیٰ سطحی مراحل کو مکمل کرتے ہیں:
- XML میٹا ڈیٹا نکالنے کے لیے AWS Glue کرالر بنائیں اور AWS Glue ڈیٹا کیٹلاگ میں ایک ٹیبل بنائیں۔
- AWS Glue ایکسٹریکٹ، ٹرانسفارم اور لوڈ (ETL) جاب کا استعمال کرتے ہوئے XML ڈیٹا کو ایک فارمیٹ (جیسے Parquet) میں پروسیس اور تبدیل کریں جو ایتھینا کے لیے موزوں ہے۔
- AWS Glue کنسول یا کے ذریعے AWS Glue جاب ترتیب دیں اور چلائیں۔ AWS کمانڈ لائن انٹرفیس (AWS CLI)۔
- ایس کیو ایل استفسارات کو فعال کرتے ہوئے، پروسیس شدہ ڈیٹا (پارکیٹ فارمیٹ میں) ایتھینا ٹیبلز کے ساتھ استعمال کریں۔
- Amazon S3 میں محفوظ اپنے ڈیٹا پر SQL سوالات کے ساتھ XML ڈیٹا کا تجزیہ کرنے کے لیے Athena میں صارف دوست انٹرفیس استعمال کریں۔
یہ آرکیٹیکچر AWS Glue اور Athena کا استعمال کرتے ہوئے Amazon S3 پر XML ڈیٹا کا تجزیہ کرنے کے لیے ایک قابل توسیع، سرمایہ کاری مؤثر حل ہے۔ آپ پیچیدہ انفراسٹرکچر مینجمنٹ کے بغیر بڑے ڈیٹاسیٹس کا تجزیہ کر سکتے ہیں۔
ہم XML فائل میٹا ڈیٹا نکالنے کے لیے AWS Glue کرالر کا استعمال کرتے ہیں۔ آپ عام مقصد کے XML درجہ بندی کے لیے پہلے سے طے شدہ AWS Glue درجہ بندی کا انتخاب کر سکتے ہیں۔ یہ خود بخود XML ڈیٹا ڈھانچہ اور اسکیما کا پتہ لگاتا ہے، جو عام فارمیٹس کے لیے مفید ہے۔
ہم اس حل میں ایک حسب ضرورت XML درجہ بندی بھی استعمال کرتے ہیں۔ یہ مخصوص XML اسکیموں یا فارمیٹس کے لیے ڈیزائن کیا گیا ہے، جس سے میٹا ڈیٹا کو درست طریقے سے نکالا جا سکتا ہے۔ یہ غیر معیاری XML فارمیٹس کے لیے مثالی ہے یا جب آپ کو درجہ بندی پر تفصیلی کنٹرول کی ضرورت ہو۔ ایک حسب ضرورت درجہ بندی یقینی بناتا ہے کہ صرف ضروری میٹا ڈیٹا نکالا جائے، بہاو پروسیسنگ اور تجزیہ کے کاموں کو آسان بنا کر۔ یہ نقطہ نظر آپ کی XML فائلوں کے استعمال کو بہتر بناتا ہے۔
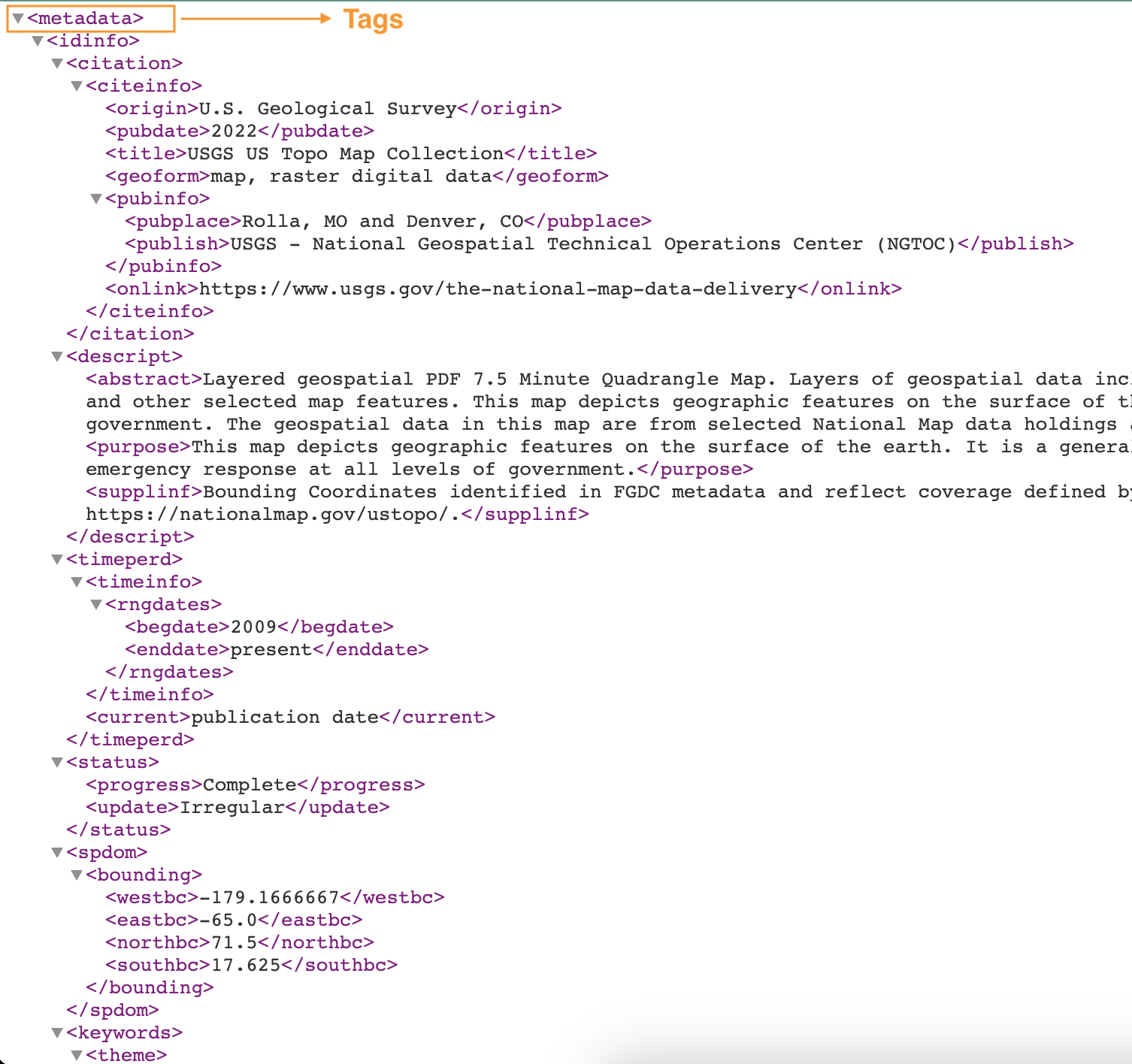
مندرجہ ذیل اسکرین شاٹ ٹیگز کے ساتھ XML فائل کی ایک مثال دکھاتا ہے۔
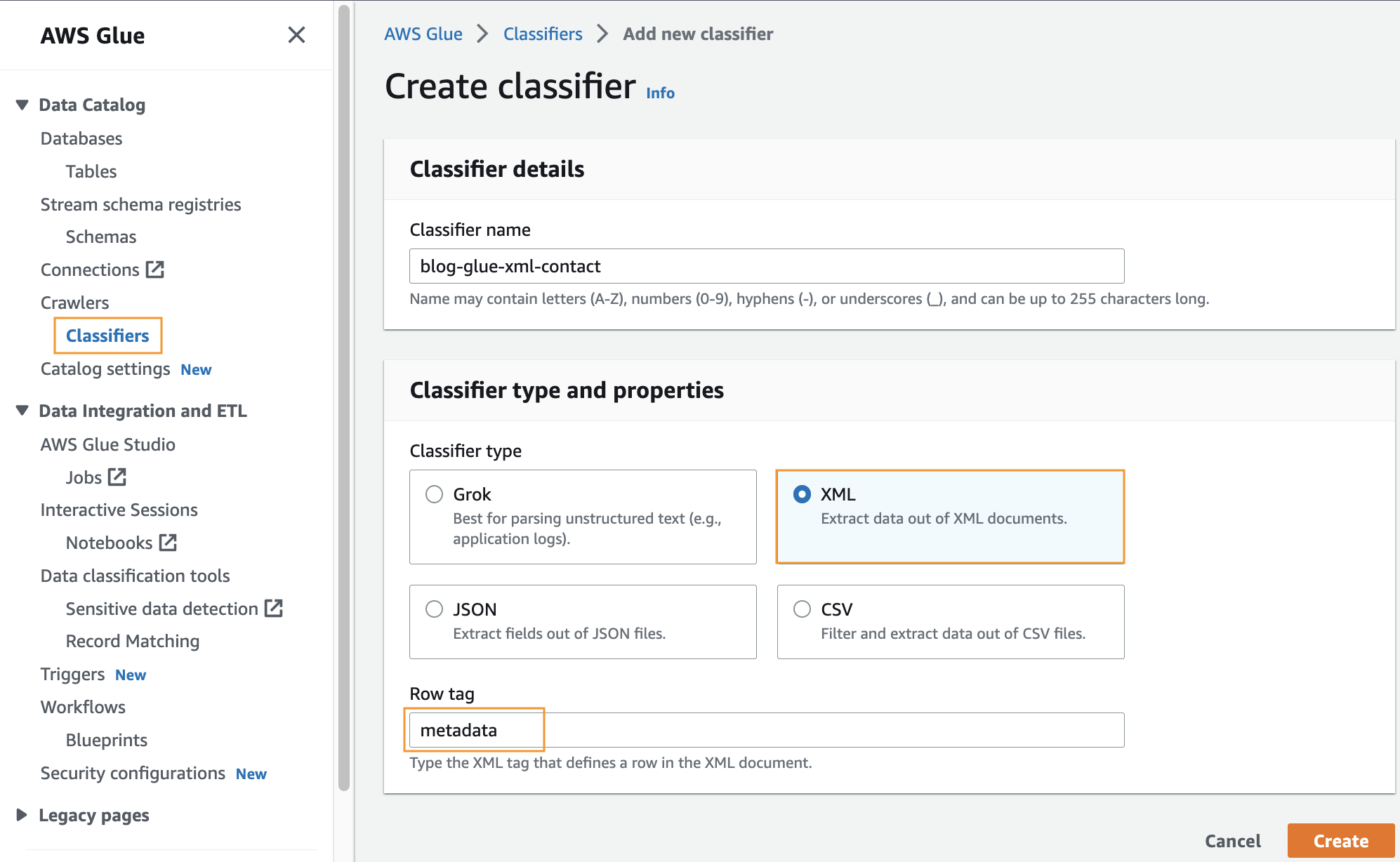
ایک حسب ضرورت درجہ بندی بنائیں
اس مرحلے میں، آپ XML فائل سے میٹا ڈیٹا نکالنے کے لیے ایک حسب ضرورت AWS Glue کلاسیفائر بناتے ہیں۔ درج ذیل مراحل کو مکمل کریں:
- AWS گلو کنسول پر، نیچے کرالر نیویگیشن پین میں، منتخب کریں۔ درجہ بندی کرنے والا.
- میں سے انتخاب کریں درجہ بندی شامل کریں۔.
- منتخب کریں XML درجہ بندی کی قسم کے طور پر۔
- درجہ بندی کرنے والے کے لیے ایک نام درج کریں، جیسے
blog-glue-xml-contact. - کے لئے قطار ٹیگ، روٹ ٹیگ کا نام درج کریں جس میں میٹا ڈیٹا ہے (مثال کے طور پر،
metadata). - میں سے انتخاب کریں تخلیق کریں.
xml فائل کو کرال کرنے کے لیے AWS Glue Crawler بنائیں
اس سیکشن میں، ہم پچھلے مرحلے میں بنائے گئے کسٹمر کلاسیفائر کا استعمال کرتے ہوئے XML فائل سے میٹا ڈیٹا نکالنے کے لیے ایک Glue Crawler بنا رہے ہیں۔
ایک ڈیٹا بیس بنائیں
- دیکھیں AWS گلو کنسولمنتخب کریں ڈیٹا بیس نیوی گیشن پین میں.
- پر کلک کریں ڈیٹا بیس شامل کریں۔
- ایک نام فراہم کریں جیسے
blog_glue_xml - میں سے انتخاب کریں تخلیق کریں ڈیٹا بیس
ایک کرالر بنائیں
اپنا پہلا کرالر بنانے کے لیے درج ذیل مراحل کو مکمل کریں:
- AWS Glue کنسول پر، منتخب کریں۔ کرالر نیوی گیشن پین میں.
- میں سے انتخاب کریں کرالر بنائیں.
- پر کرالر کی خصوصیات سیٹ کریں۔ صفحہ، نئے کرالر کے لیے ایک نام فراہم کریں (جیسے
blog-glue-parquet)، پھر منتخب کریں۔ اگلے. - پر ڈیٹا کے ذرائع اور درجہ بندی کا انتخاب کریں۔ صفحہ ، منتخب کریں ابھی تک نہیں کے تحت ڈیٹا سورس کنفیگریشن.
- میں سے انتخاب کریں ڈیٹا اسٹور شامل کریں۔.
- کے لئے S3 راستہ، پر براؤز کریں۔
s3://${BUCKET_NAME}/input/geologicalsurvey/.
اس بات کو یقینی بنائیں کہ آپ فولڈر کے اندر موجود فائل کے بجائے XML فولڈر منتخب کرتے ہیں۔
- باقی آپشنز کو بطور ڈیفالٹ چھوڑ دیں اور منتخب کریں۔ S3 ڈیٹا ماخذ شامل کریں۔.
- توسیع حسب ضرورت درجہ بندی - اختیاری۔، blog-glue-xml-contact کا انتخاب کریں، پھر منتخب کریں۔ اگلے اور باقی آپشنز کو بطور ڈیفالٹ رکھیں۔
- اپنا IAM کردار منتخب کریں یا منتخب کریں۔ نیا IAM کردار بنائیں، لاحقہ شامل کریں۔
glue-xml-contact(مثال کے طور پر،AWSGlueServiceNotebookRoleBlog)، اور منتخب کریں۔ اگلے. - پر آؤٹ پٹ اور شیڈولنگ سیٹ کریں۔ صفحہ، نیچے آؤٹ پٹ کی تشکیلمنتخب کریں
blog_glue_xmlلیے ٹارگٹ ڈیٹا بیس. - درج
console_جیسا کہ جدولوں میں سابقہ شامل کیا گیا (اختیاری) اور نیچے کرالر کا شیڈول، تعدد کو سیٹ پر رکھیں مطالبے پر. - میں سے انتخاب کریں اگلے.
- تمام پیرامیٹرز کا جائزہ لیں اور منتخب کریں۔ کرالر بنائیں.
کرالر چلائیں۔
کرالر بنانے کے بعد، اسے چلانے کے لیے درج ذیل اقدامات مکمل کریں:
- AWS Glue کنسول پر، منتخب کریں۔ کرالر نیوی گیشن پین میں.
- اپنا بنایا ہوا کرالر کھولیں اور منتخب کریں۔ رن.
کرالر کو مکمل ہونے میں 1-2 منٹ لگیں گے۔
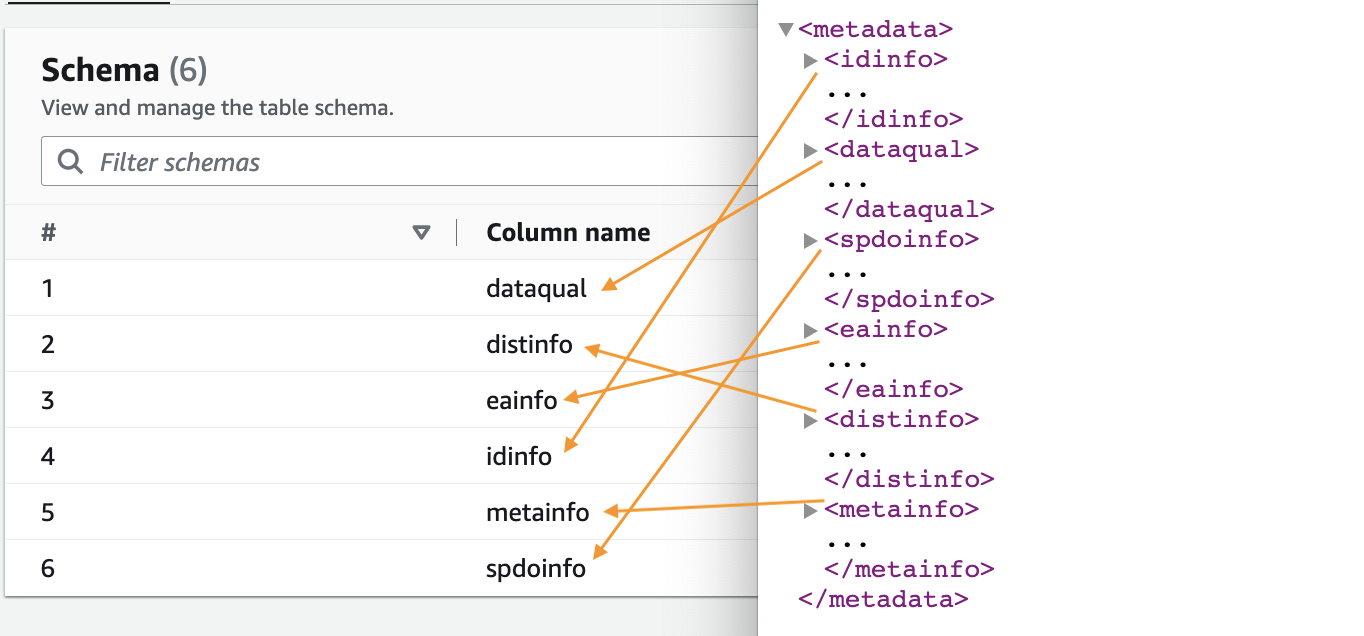
- جب کرالر مکمل ہو جائے، منتخب کریں۔ ڈیٹا بیس نیوی گیشن پین میں.
- آپ نے جو ڈیٹا بیس بنایا ہے اسے منتخب کریں اور کرالر کے ذریعے نکالے گئے اسکیما کو دیکھنے کے لیے ٹیبل کا نام منتخب کریں۔
XML کو Parquet فارمیٹ میں تبدیل کرنے کے لیے AWS Glue جاب بنائیں
اس مرحلے میں، آپ XML فائل کو Parquet فائل میں تبدیل کرنے کے لیے AWS Glue Studio جاب بناتے ہیں۔ درج ذیل مراحل کو مکمل کریں:
- AWS Glue کنسول پر، منتخب کریں۔ نوکریاں نیوی گیشن پین میں.
- کے تحت نوکری پیدا کریں۔منتخب خالی کینوس کے ساتھ بصری.
- میں سے انتخاب کریں تخلیق کریں.
- کام کا نام تبدیل کریں۔
blog_glue_xml_job.
اب آپ کے پاس AWS Glue Studio بصری جاب ایڈیٹر خالی ہے۔ ایڈیٹر کے اوپری حصے میں مختلف آراء کے لیے ٹیبز ہیں۔
- منتخب کیجئیے اسکرپٹ AWS Glue ETL اسکرپٹ کا خالی خول دیکھنے کے لیے ٹیب پر کلک کریں۔
جیسا کہ ہم بصری ایڈیٹر میں نئے مراحل شامل کرتے ہیں، اسکرپٹ خود بخود اپ ڈیٹ ہوجائے گا۔
- منتخب کیجئیے ملازمت کی تفصیلات تمام جاب کنفیگریشنز دیکھنے کے لیے ٹیب۔
- کے لئے IAM کا کردارمنتخب کریں
AWSGlueServiceNotebookRoleBlog. - کے لئے گلو ورژنمنتخب کریں Glue 4.0 - Spark 3.3، Scala 2، Python 3 کو سپورٹ کرتا ہے.
- سیٹ کریں کارکنوں کی تعداد طلب کی۔ 2 پر.
- سیٹ کریں دوبارہ کوششوں کی تعداد 0 پر.
- منتخب کیجئیے بصری بصری ایڈیٹر پر واپس جانے کے لیے ٹیب۔
- پر ماخذ ڈراپ ڈاؤن مینو ، منتخب کریں۔ AWS گلو ڈیٹا کیٹلاگ.
- پر ڈیٹا سورس کی خصوصیات - ڈیٹا کیٹلاگ ٹیب، درج ذیل معلومات فراہم کریں:
- کے لئے ڈیٹا بیسمنتخب کریں
blog_glue_xml. - کے لئے ٹیبل، اس ٹیبل کا انتخاب کریں جو نام console_ سے شروع ہوتا ہے جسے کرالر نے بنایا ہے (مثال کے طور پر،
console_geologicalsurvey).
- کے لئے ڈیٹا بیسمنتخب کریں
- پر نوڈ کی خصوصیات ٹیب، درج ذیل معلومات فراہم کریں:
- تبدیل کریں نام کرنے کے لئے
geologicalsurveyڈیٹاسیٹ - میں سے انتخاب کریں عمل اور تبدیلی سکیما تبدیل کریں (میپنگ کا اطلاق کریں).
- میں سے انتخاب کریں نوڈ کی خصوصیات اور تبدیلی کا نام چینج سکیما (Apply Mapping) سے تبدیل کر دیں۔
ApplyMapping. - پر ہدف مینو، منتخب کریں S3.
- تبدیل کریں نام کرنے کے لئے
- پر ڈیٹا سورس کی خصوصیات - S3 ٹیب، درج ذیل معلومات فراہم کریں:
- کے لئے فارمیٹمنتخب چھڑی.
- کے لئے کمپریشن کی قسممنتخب غیر سنجیدہ.
- کے لئے S3 ذریعہ کی قسممنتخب S3 مقام.
- کے لئے S3 URL، داخل کریں
s3://${BUCKET_NAME}/output/parquet/. - میں سے انتخاب کریں نوڈ پراپرٹیز اور نام تبدیل کر دیں۔
Output.
- میں سے انتخاب کریں محفوظ کریں کام کو بچانے کے لئے.
- میں سے انتخاب کریں رن کام کو چلانے کے لیے۔
مندرجہ ذیل اسکرین شاٹ بصری ایڈیٹر میں کام کو ظاہر کرتا ہے۔
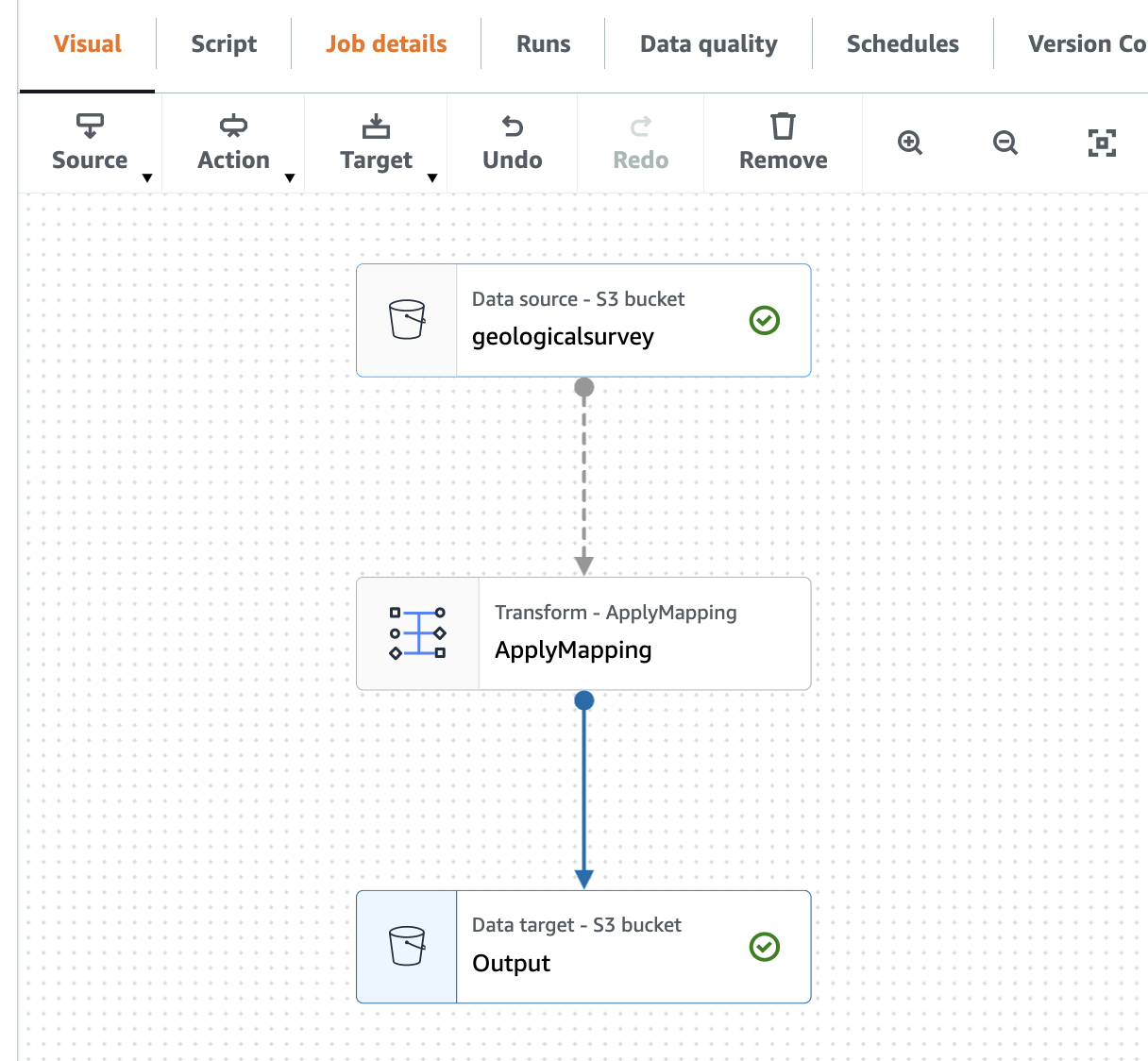
پارکیٹ فائل کو کرال کرنے کے لیے AWS Gue Crawler بنائیں
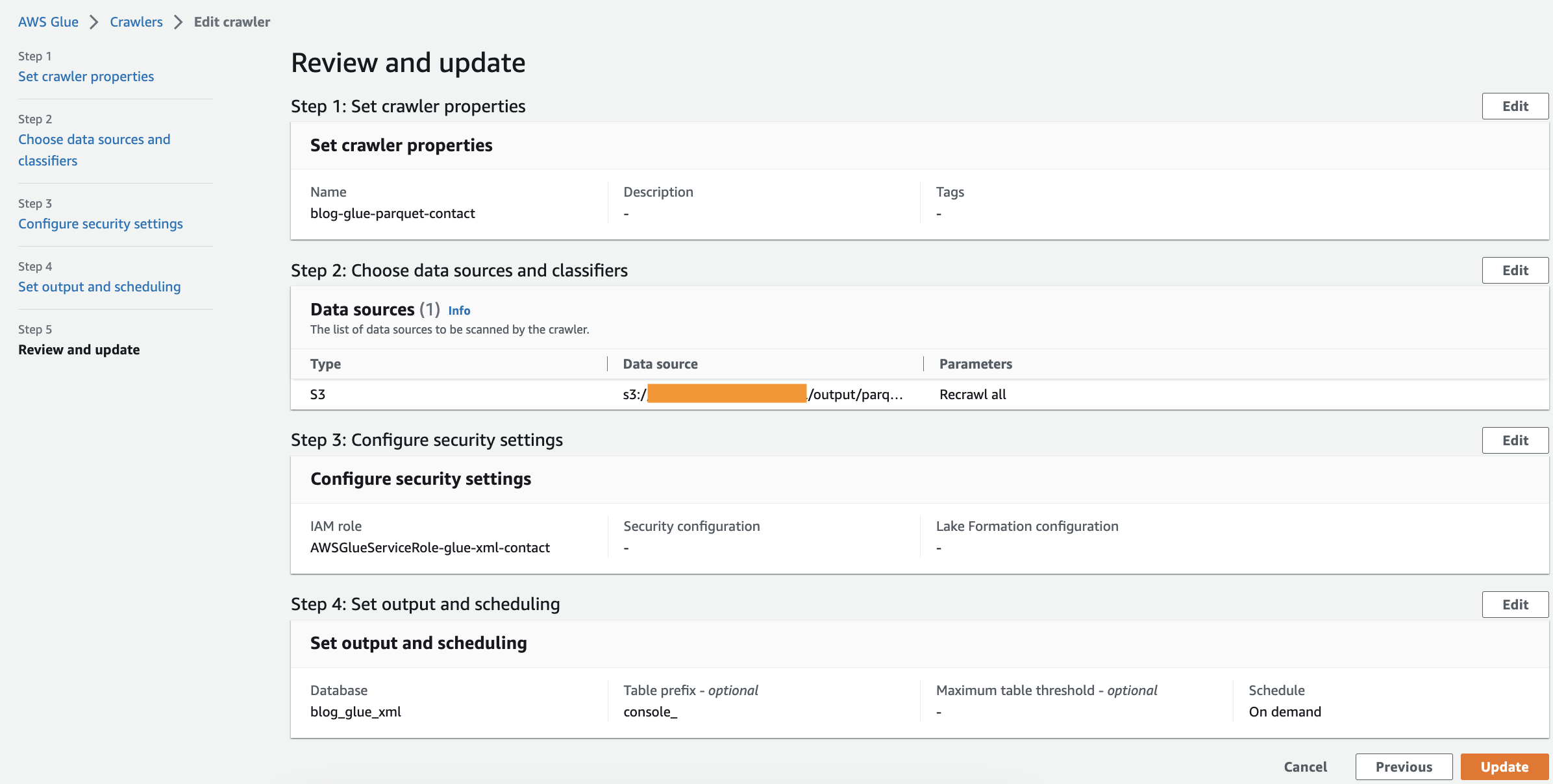
اس مرحلے میں، آپ AWS Glue کرالر بناتے ہیں تاکہ آپ نے AWS Glue Studio جاب کا استعمال کرتے ہوئے بنائی ہوئی Parquet فائل سے میٹا ڈیٹا نکالا جائے۔ اس بار، آپ ڈیفالٹ درجہ بندی استعمال کرتے ہیں۔ درج ذیل مراحل کو مکمل کریں:
- AWS Glue کنسول پر، منتخب کریں۔ کرالر نیوی گیشن پین میں.
- میں سے انتخاب کریں کرالر بنائیں.
- پر کرالر کی خصوصیات سیٹ کریں۔ صفحہ، نئے کرالر کے لیے ایک نام فراہم کریں، جیسے blog-glue-parquet-contact، پھر منتخب کریں اگلے.
- پر ڈیٹا کے ذرائع اور درجہ بندی کا انتخاب کریں۔ صفحہ ، منتخب کریں ابھی تک نہیں لیے ڈیٹا سورس کنفیگریشن.
- میں سے انتخاب کریں ڈیٹا اسٹور شامل کریں۔.
- کے لئے S3 راستہ، پر براؤز کریں۔
s3://${BUCKET_NAME}/output/parquet/.
یقینی بنائیں کہ آپ منتخب کرتے ہیں۔ parquet فولڈر کے اندر فائل کے بجائے فولڈر۔
- پیشگی سیکشن کے دوران تخلیق کردہ اپنا IAM کردار منتخب کریں یا منتخب کریں۔ نیا IAM کردار بنائیں (مثال کے طور پر،
AWSGlueServiceNotebookRoleBlog)، اور منتخب کریں۔ اگلے. - پر آؤٹ پٹ اور شیڈولنگ سیٹ کریں۔ صفحہ، نیچے آؤٹ پٹ کی تشکیلمنتخب کریں
blog_glue_xmlلیے ڈیٹا بیس. - درج
parquet_جیسا کہ جدولوں میں سابقہ شامل کیا گیا (اختیاری) اور نیچے کرالر کا شیڈول، تعدد کو سیٹ پر رکھیں مطالبے پر. - میں سے انتخاب کریں اگلے.
- تمام پیرامیٹرز کا جائزہ لیں اور منتخب کریں۔ کرالر بنائیں.
اب آپ کرالر چلا سکتے ہیں، جسے مکمل ہونے میں 1-2 منٹ لگتے ہیں۔

آپ AWS Glue Data Catalog میں Parquet فائل کے لیے نئے بنائے گئے اسکیما کا جائزہ لے سکتے ہیں، جو XML فائل کے اسکیما سے ملتا جلتا ہے۔
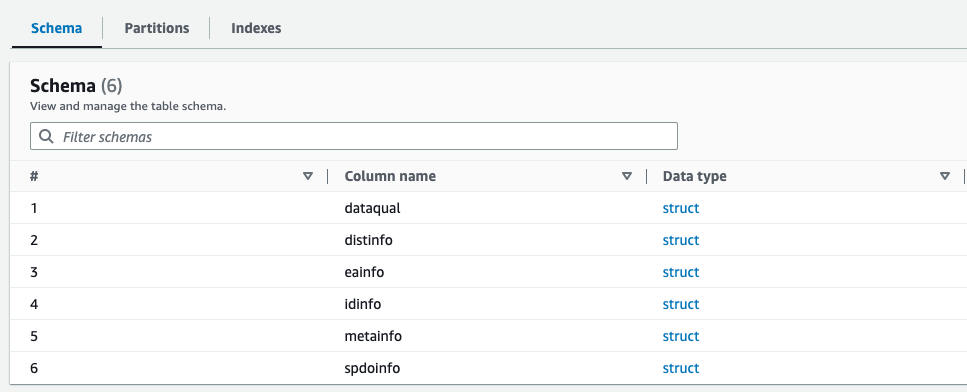
اب ہمارے پاس ڈیٹا ہے جو ایتھینا کے ساتھ استعمال کے لیے موزوں ہے۔ اگلے حصے میں، ہم ایتھینا کا استعمال کرتے ہوئے ڈیٹا کے سوالات کرتے ہیں۔
ایتھینا کا استعمال کرتے ہوئے پارکیٹ فائل سے استفسار کریں۔
ایتھینا استفسار کرنے کی حمایت نہیں کرتی ہے۔ XML فائل کی شکل، یہی وجہ ہے کہ آپ نے زیادہ موثر ڈیٹا استفسار اور استعمال کے لیے XML فائل کو Parquet میں تبدیل کیا ڈاٹ نوٹیشن پیچیدہ اقسام اور نیسٹڈ ڈھانچے سے استفسار کرنے کے لیے۔
درج ذیل مثال کا کوڈ نیسٹڈ ڈیٹا سے استفسار کرنے کے لیے ڈاٹ اشارے کا استعمال کرتا ہے۔
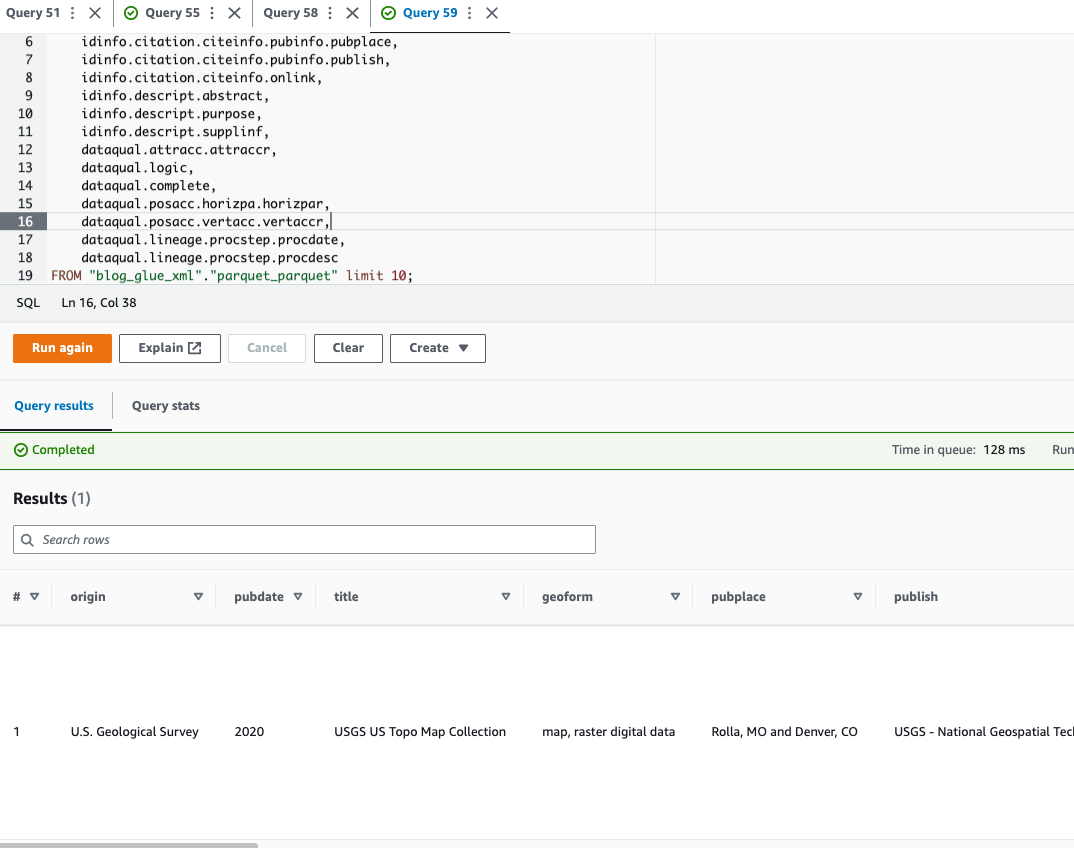
اب جب کہ ہم نے تکنیک 1 مکمل کر لی ہے، آئیے تکنیک 2 کے بارے میں جاننے کے لیے آگے بڑھتے ہیں۔
تکنیک 2: تخمینہ شدہ اور فکسڈ اسکیموں کے ساتھ AWS Glue Dynamic Frames استعمال کریں
پچھلے حصے میں، ہم نے ٹیبل بنانے کے لیے AWS Glue کرالر کا استعمال کرتے ہوئے ایک چھوٹی XML فائل کو ہینڈل کرنے کے عمل کا احاطہ کیا، فائل کو Parquet فارمیٹ میں تبدیل کرنے کے لیے AWS Glue جاب، اور Parquet ڈیٹا تک رسائی کے لیے Athena۔ تاہم، کرالر کو حدود کا سامنا کرنا پڑتا ہے جب یہ XML فائلوں پر کارروائی کرنے کی بات آتی ہے جو حد سے زیادہ ہیں۔ 1 MB سائز میں. اس حصے میں، ہم بڑی XML فائلوں کے بیچ پروسیسنگ کے موضوع پر غور کرتے ہیں، انفرادی واقعات کو نکالنے اور ایتھینا کا استعمال کرتے ہوئے تجزیہ کرنے کے لیے اضافی تجزیہ کی ضرورت ہوتی ہے۔
ہمارے نقطہ نظر میں AWS Glue کے ذریعے XML فائلوں کو پڑھنا شامل ہے۔ ڈائنامک فریمز, قیاس شدہ اور فکسڈ دونوں اسکیموں کا استعمال۔ پھر ہم انفرادی واقعات کو Parquet فارمیٹ میں استعمال کرتے ہوئے نکالتے ہیں۔ رشتہ دار بنانا تبدیلی، ہمیں ایتھینا کا استعمال کرتے ہوئے بغیر کسی رکاوٹ کے سوال کرنے اور ان کا تجزیہ کرنے کے قابل بناتا ہے۔
اس حل کو نافذ کرنے کے لیے، آپ درج ذیل اعلیٰ سطحی مراحل کو مکمل کرتے ہیں:
- XML فائل کو پڑھنے اور تجزیہ کرنے کے لیے AWS Glue نوٹ بک بنائیں۔
- استعمال
DynamicFramesساتھInferSchemaXML فائل کو پڑھنے کے لیے۔ - کسی بھی صفوں کو ہٹانے کے لیے ریلیشنلائز فنکشن کا استعمال کریں۔
- ڈیٹا کو پارکیٹ فارمیٹ میں تبدیل کریں۔
- ایتھینا کا استعمال کرتے ہوئے پارکیٹ ڈیٹا سے استفسار کریں۔
- پچھلے مراحل کو دہرائیں، لیکن اس بار اسکیما کو پاس کریں۔
DynamicFramesاستعمال کرنے کے بجائےInferSchema.
الیکٹرک گاڑیوں کی آبادی کا ڈیٹا XML فائل میں a ہے۔ response اس کی جڑ کی سطح پر ٹیگ کریں۔ اس ٹیگ میں کی ایک صف شامل ہے۔ row tags، جو اس کے اندر اندر بنے ہوئے ہیں۔ قطار ٹیگ ایک صف ہے جس میں دوسرے قطار کے ٹیگز کا ایک سیٹ ہوتا ہے، جو گاڑی کے بارے میں معلومات فراہم کرتا ہے، بشمول اس کا میک، ماڈل اور دیگر متعلقہ تفصیلات۔ مندرجہ ذیل اسکرین شاٹ ایک مثال دکھاتا ہے۔

AWS گلو نوٹ بک بنائیں
AWS Glue نوٹ بک بنانے کے لیے، درج ذیل مراحل کو مکمل کریں:
- کھولو AWS گلو اسٹوڈیو کنسول، منتخب کریں نوکریاں نیوی گیشن پین میں.
- منتخب کریں Jupyter نوٹ بک اور منتخب کریں تخلیق کریں.
- اپنی AWS Glue جاب کے لیے ایک نام درج کریں، جیسے
blog_glue_xml_job_Jupyter. - وہ کردار منتخب کریں جو آپ نے پیشگی شرائط میں بنایا ہے (
AWSGlueServiceNotebookRoleBlog).
AWS Glue نوٹ بک ایک پہلے سے موجود مثال کے ساتھ آتی ہے جو یہ ظاہر کرتی ہے کہ ڈیٹا بیس سے استفسار کرنے اور آؤٹ پٹ کو Amazon S3 پر کیسے لکھنا ہے۔
- ٹائم آؤٹ کو ایڈجسٹ کریں (منٹ میں) جیسا کہ مندرجہ ذیل اسکرین شاٹ میں دکھایا گیا ہے اور AWS Glue انٹرایکٹو سیشن بنانے کے لیے سیل کو چلائیں۔
بنیادی متغیرات بنائیں
انٹرایکٹو سیشن بنانے کے بعد، نوٹ بک کے آخر میں، درج ذیل متغیرات کے ساتھ ایک نیا سیل بنائیں (اپنی اپنی بالٹی کا نام فراہم کریں):
اسکیما کا اندازہ لگانے والی XML فائل کو پڑھیں
اگر آپ اسکیما کو پاس نہیں کرتے ہیں۔ DynamicFrame، یہ فائلوں کے اسکیما کا اندازہ لگائے گا۔ متحرک فریم کا استعمال کرتے ہوئے ڈیٹا کو پڑھنے کے لیے، آپ درج ذیل کمانڈ استعمال کر سکتے ہیں:
ڈائنامک فریم اسکیما پرنٹ کریں۔
درج ذیل کوڈ کے ساتھ اسکیما پرنٹ کریں:
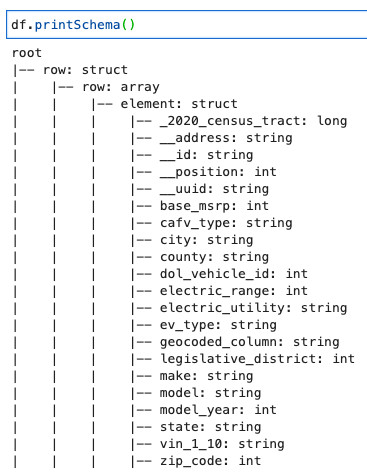
اسکیما a کے ساتھ ایک نیسٹڈ ڈھانچہ دکھاتا ہے۔ row ایک سے زیادہ عناصر پر مشتمل صف۔ اس ڈھانچے کو لائنوں میں اتارنے کے لیے، آپ AWS Glue استعمال کر سکتے ہیں۔ رشتہ دار بنانا تبدیلی:
ہم صرف قطار کی صف میں موجود معلومات میں دلچسپی رکھتے ہیں، اور ہم درج ذیل کمانڈ کا استعمال کرکے اسکیما کو دیکھ سکتے ہیں:
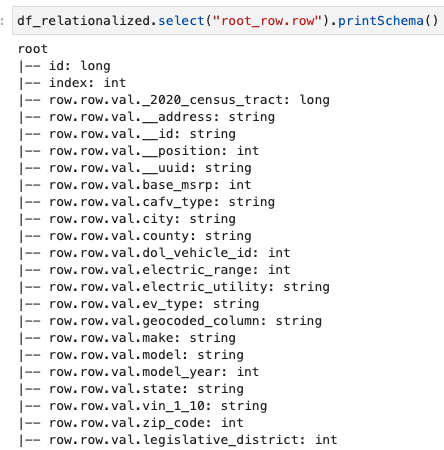
کالم کے ناموں پر مشتمل ہے۔ row.row، جو ڈیٹاسیٹ میں صف کے ڈھانچے اور سرنی کالم سے مماثل ہے۔ ہم اس پوسٹ میں کالموں کا نام تبدیل نہیں کرتے ہیں۔ ایسا کرنے کے لیے ہدایات کے لیے رجوع کریں۔ AWS Glue کا استعمال کرتے ہوئے ڈیٹا فائلوں میں کالم کے ناموں کی ڈائنامک میپنگ اور نام تبدیل کریں: حصہ 1. پھر آپ ڈیٹا کو Parquet فارمیٹ میں تبدیل کر سکتے ہیں اور درج ذیل کمانڈ کا استعمال کرتے ہوئے AWS Glue ٹیبل بنا سکتے ہیں۔
AWS گلو DynamicFrame وہ خصوصیات فراہم کرتا ہے جو آپ ڈیٹا کیٹلاگ میں اسکیما بنانے اور اپ ڈیٹ کرنے کے لیے اپنے ETL اسکرپٹ میں استعمال کر سکتے ہیں۔ ہم استعمال کرتے ہیں updateBehavior پیرامیٹر براہ راست ڈیٹا کیٹلاگ میں ٹیبل بنانے کے لیے۔ اس نقطہ نظر کے ساتھ، ہمیں AWS Glue جاب مکمل ہونے کے بعد AWS Glue کرالر چلانے کی ضرورت نہیں ہے۔

اسکیما ترتیب دے کر XML فائل پڑھیں
فائل کو پڑھنے کا ایک متبادل طریقہ اسکیما کی پہلے سے وضاحت کرنا ہے۔ ایسا کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- AWS Glue ڈیٹا کی اقسام درآمد کریں:
- XML فائل کے لیے ایک سکیما بنائیں:
- XML فائل کو پڑھتے وقت اسکیما کو پاس کریں:
- ڈیٹاسیٹ کو پہلے کی طرح ان نیسٹ کریں:
- ڈیٹاسیٹ کو Parquet میں تبدیل کریں اور AWS Glue ٹیبل بنائیں:
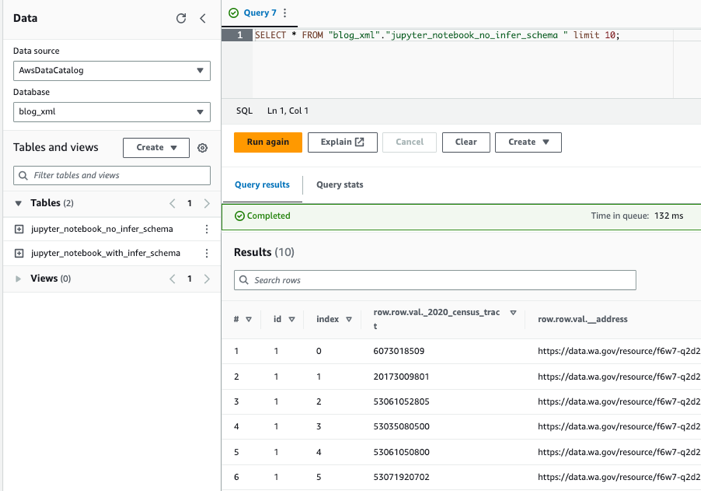
ایتھینا کا استعمال کرتے ہوئے میزوں سے استفسار کریں۔
اب جب کہ ہم نے دونوں میزیں بنا لی ہیں، ہم ایتھینا کا استعمال کرتے ہوئے میزوں سے استفسار کر سکتے ہیں۔ مثال کے طور پر، ہم درج ذیل استفسار استعمال کر سکتے ہیں:
صاف کرو
اس پوسٹ میں، ہم نے AWS Glue Data Catalog میں ایک IAM رول، AWS Glue Jupyter نوٹ بک، اور دو میزیں بنائی ہیں۔ ہم نے S3 بالٹی میں کچھ فائلیں بھی اپ لوڈ کیں۔ ان اشیاء کو صاف کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- IAM کنسول پر، اپنے بنائے ہوئے کردار کو حذف کریں۔
- AWS Glue Studio کنسول پر، حسب ضرورت کلاسیفائر، کرالر، ETL جابز، اور Jupyter نوٹ بک کو حذف کریں۔
- AWS Glue Data Catalog پر جائیں اور اپنی بنائی ہوئی میزیں حذف کریں۔
- Amazon S3 کنسول پر، اپنی بنائی ہوئی بالٹی پر جائیں اور نام کے فولڈرز کو حذف کریں۔
temp,infer_schema، اورno_infer_schema.
کلیدی لے لو
AWS Glue میں، ایک خصوصیت ہے جسے کہا جاتا ہے۔ InferSchema AWS گلو میں DynamicFrames. یہ اس میں موجود ڈیٹا کی بنیاد پر ڈیٹا فریم کی ساخت کا خود بخود پتہ لگاتا ہے۔ اس کے برعکس، اسکیما کی وضاحت کا مطلب یہ ہے کہ ڈیٹا کو لوڈ کرنے سے پہلے ڈیٹا فریم کا ڈھانچہ کیسا ہونا چاہیے۔
XML، ٹیکسٹ پر مبنی فارمیٹ ہونے کی وجہ سے، اپنے کالموں کے ڈیٹا کی قسموں کو محدود نہیں کرتا ہے۔ اس سے InferSchema فنکشن میں مسائل پیدا ہو سکتے ہیں۔ مثال کے طور پر، پہلی دوڑ میں، کالم A کے ساتھ ایک فائل جس کی قیمت 2 ہوتی ہے، Parquet فائل میں کالم A کے ساتھ بطور عدد۔ دوسری دوڑ میں، ایک نئی فائل میں C ویلیو کے ساتھ کالم A ہے، جس کی وجہ سے ایک پارکیٹ فائل کالم A کے ساتھ بطور سٹرنگ ہے۔ اب S3 پر دو فائلیں ہیں، ہر ایک کالم A کے ساتھ مختلف ڈیٹا کی قسمیں، جو نیچے کی طرف سے مسائل پیدا کر سکتی ہیں۔
پیچیدہ ڈیٹا کی اقسام جیسے نیسٹڈ ڈھانچے یا صفوں کے ساتھ بھی ایسا ہی ہوتا ہے۔ مثال کے طور پر، اگر کسی فائل میں ایک ٹیگ انٹری کو کہا جاتا ہے۔ transaction، یہ ایک ساخت کے طور پر اندازہ لگایا گیا ہے۔ لیکن اگر کسی اور فائل میں ایک ہی ٹیگ ہے، تو اس کا اندازہ ایک صف کے طور پر کیا جاتا ہے۔
ڈیٹا کی قسم کے ان مسائل کے باوجود، InferSchema مفید ہے جب آپ اسکیما کو نہیں جانتے یا دستی طور پر اس کی وضاحت کرنا ناقابل عمل ہے۔ تاہم، یہ بڑے یا مسلسل تبدیل ہونے والے ڈیٹاسیٹس کے لیے مثالی نہیں ہے۔ اسکیما کی وضاحت کرنا زیادہ درست ہے، خاص طور پر پیچیدہ ڈیٹا کی اقسام کے ساتھ، لیکن اس کے اپنے مسائل ہیں، جیسے کہ دستی کوشش کی ضرورت ہوتی ہے اور ڈیٹا کی تبدیلیوں کے لیے لچکدار ہونا۔
InferSchema اس کی حدود ہیں، جیسے ڈیٹا کی قسم کا غلط اندازہ اور null اقدار کو سنبھالنے کے مسائل۔ اسکیما کی وضاحت میں بھی حدود ہوتی ہیں، جیسے دستی کوشش اور ممکنہ غلطیاں۔
اسکیما کا اندازہ لگانے اور اس کی وضاحت کرنے کے درمیان انتخاب کا انحصار پروجیکٹ کی ضروریات پر ہوتا ہے۔ InferSchema چھوٹے ڈیٹاسیٹس کی فوری تلاش کے لیے بہت اچھا ہے، جبکہ اسکیما کی وضاحت بڑے، پیچیدہ ڈیٹاسیٹس کے لیے بہتر ہے جس میں درستگی اور مستقل مزاجی کی ضرورت ہوتی ہے۔ آپ کے پراجیکٹ کے لیے سب سے موزوں چیز کو منتخب کرنے کے لیے ہر طریقہ کی تجارت اور رکاوٹوں پر غور کریں۔
نتیجہ
اس پوسٹ میں، ہم نے AWS Glue کا استعمال کرتے ہوئے XML ڈیٹا کو منظم کرنے کے لیے دو تکنیکوں کی کھوج کی، ہر ایک مخصوص ضروریات اور آپ کو درپیش چیلنجوں سے نمٹنے کے لیے تیار کی گئی ہے۔
تکنیک 1 ان لوگوں کے لیے ایک صارف دوست راستہ پیش کرتی ہے جو گرافیکل انٹرفیس کو ترجیح دیتے ہیں۔ آپ آسانی سے اپنی XML فائلوں کے لیے ٹیبل کی ساخت کی وضاحت کرنے کے لیے AWS Glue کرالر اور بصری ایڈیٹر کا استعمال کر سکتے ہیں۔ یہ نقطہ نظر ڈیٹا مینجمنٹ کے عمل کو آسان بناتا ہے اور خاص طور پر ان لوگوں کے لیے اپیل کرتا ہے جو اپنے ڈیٹا کو ہینڈل کرنے کے لیے ایک سیدھا راستہ تلاش کر رہے ہیں۔
تاہم، ہم تسلیم کرتے ہیں کہ کرالر کی اپنی حدود ہیں، خاص طور پر جب XML فائلوں کی قطاریں 1 MB سے بڑی ہیں۔ یہ وہ جگہ ہے جہاں تکنیک 2 بچاؤ کے لئے آتی ہے۔ AWS گلو کو استعمال کرکے DynamicFrames تخمینہ شدہ اور فکسڈ دونوں اسکیموں کے ساتھ، اور AWS Glue نوٹ بک کا استعمال کرتے ہوئے، آپ کسی بھی سائز کی XML فائلوں کو مؤثر طریقے سے ہینڈل کر سکتے ہیں۔ یہ طریقہ ایک مضبوط حل فراہم کرتا ہے جو 1 MB کی رکاوٹ سے زیادہ قطاروں والی XML فائلوں کے لیے بھی بغیر کسی رکاوٹ کے پروسیسنگ کو یقینی بناتا ہے۔
جیسا کہ آپ ڈیٹا مینجمنٹ کی دنیا میں تشریف لے جاتے ہیں، آپ کی ٹول کٹ میں ان تکنیکوں کا ہونا آپ کو اپنے پروجیکٹ کی مخصوص ضروریات کی بنیاد پر باخبر فیصلے کرنے کا اختیار دیتا ہے۔ چاہے آپ تکنیک 1 کی سادگی کو ترجیح دیں یا تکنیک 2 کی توسیع پذیری، AWS Glue وہ لچک فراہم کرتا ہے جس کی آپ کو XML ڈیٹا کو مؤثر طریقے سے ہینڈل کرنے کی ضرورت ہے۔
مصنفین کے بارے میں
 نونت شکلاتجزیات پر توجہ کے ساتھ AWS ماہر حل آرکیٹیکٹ کے طور پر کام کرتا ہے۔ اس کے پاس گاہکوں کو ان کے ڈیٹا سے قیمتی بصیرتیں دریافت کرنے میں مدد کرنے کا زبردست جوش ہے۔ اپنی مہارت کے ذریعے، وہ ایسے اختراعی حل تیار کرتا ہے جو کاروباروں کو باخبر، ڈیٹا پر مبنی انتخاب تک پہنچنے کے لیے بااختیار بناتا ہے۔ خاص طور پر، نونیت شکلا "AWS پر ڈیٹا رینگلنگ" نامی کتاب کے ماہر مصنف ہیں۔
نونت شکلاتجزیات پر توجہ کے ساتھ AWS ماہر حل آرکیٹیکٹ کے طور پر کام کرتا ہے۔ اس کے پاس گاہکوں کو ان کے ڈیٹا سے قیمتی بصیرتیں دریافت کرنے میں مدد کرنے کا زبردست جوش ہے۔ اپنی مہارت کے ذریعے، وہ ایسے اختراعی حل تیار کرتا ہے جو کاروباروں کو باخبر، ڈیٹا پر مبنی انتخاب تک پہنچنے کے لیے بااختیار بناتا ہے۔ خاص طور پر، نونیت شکلا "AWS پر ڈیٹا رینگلنگ" نامی کتاب کے ماہر مصنف ہیں۔
 پیٹرک مولر AWS میں سینئر ڈیٹا لیب آرکیٹیکٹ کے طور پر کام کرتا ہے۔ اس کی بنیادی ذمہ داری صارفین کے خیالات کو پیداوار کے لیے تیار ڈیٹا پروڈکٹ میں تبدیل کرنے میں مدد کرنا ہے۔ اپنے فارغ وقت میں، پیٹرک کو فٹ بال کھیلنا، فلمیں دیکھنا، اور سفر کرنا پسند ہے۔
پیٹرک مولر AWS میں سینئر ڈیٹا لیب آرکیٹیکٹ کے طور پر کام کرتا ہے۔ اس کی بنیادی ذمہ داری صارفین کے خیالات کو پیداوار کے لیے تیار ڈیٹا پروڈکٹ میں تبدیل کرنے میں مدد کرنا ہے۔ اپنے فارغ وقت میں، پیٹرک کو فٹ بال کھیلنا، فلمیں دیکھنا، اور سفر کرنا پسند ہے۔
 اموگھ گائیکواڑ ایمیزون ویب سروسز میں ایک سینئر حل ڈیولپر ہے۔ وہ عالمی صارفین کو AWS پر AI/ML سلوشنز بنانے اور تعینات کرنے میں مدد کرتا ہے۔ اس کا کام بنیادی طور پر کمپیوٹر ویژن، اور قدرتی زبان کی پروسیسنگ پر مرکوز ہے اور صارفین کو پائیداری کے لیے ان کے AI/ML ورک بوجھ کو بہتر بنانے میں مدد کرتا ہے۔ اموگ نے مشین لرننگ میں مہارت کے ساتھ کمپیوٹر سائنس میں ماسٹرز حاصل کیا ہے۔
اموگھ گائیکواڑ ایمیزون ویب سروسز میں ایک سینئر حل ڈیولپر ہے۔ وہ عالمی صارفین کو AWS پر AI/ML سلوشنز بنانے اور تعینات کرنے میں مدد کرتا ہے۔ اس کا کام بنیادی طور پر کمپیوٹر ویژن، اور قدرتی زبان کی پروسیسنگ پر مرکوز ہے اور صارفین کو پائیداری کے لیے ان کے AI/ML ورک بوجھ کو بہتر بنانے میں مدد کرتا ہے۔ اموگ نے مشین لرننگ میں مہارت کے ساتھ کمپیوٹر سائنس میں ماسٹرز حاصل کیا ہے۔
 شیلا سونون AWS میں ایک سینئر رہائشی آرکیٹیکٹ ہیں۔ وہ AWS صارفین کو ان کے ڈیٹا، تجزیات، اور AI/ML ورک بوجھ اور عمل درآمد کو تیز کرنے کے بارے میں باخبر انتخاب اور تجارت کرنے میں مدد کرتی ہے۔ اپنے فارغ وقت میں، وہ اپنے خاندان کے ساتھ - عام طور پر ٹینس کورٹس پر وقت گزارنے سے لطف اندوز ہوتی ہے۔
شیلا سونون AWS میں ایک سینئر رہائشی آرکیٹیکٹ ہیں۔ وہ AWS صارفین کو ان کے ڈیٹا، تجزیات، اور AI/ML ورک بوجھ اور عمل درآمد کو تیز کرنے کے بارے میں باخبر انتخاب اور تجارت کرنے میں مدد کرتی ہے۔ اپنے فارغ وقت میں، وہ اپنے خاندان کے ساتھ - عام طور پر ٹینس کورٹس پر وقت گزارنے سے لطف اندوز ہوتی ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- ہمارے بارے میں
- خلاصہ
- تیز
- تک رسائی حاصل
- رسائی پذیری
- کامیاب
- درستگی
- کے پار
- عمل
- شامل کریں
- شامل کیا
- ایڈیشنل
- پتہ
- کے بعد
- عمر
- AI / ML
- تمام
- کی اجازت
- اجازت دے رہا ہے
- کی اجازت دیتا ہے
- بھی
- متبادل
- ایمیزون
- ایمیزون ایتینا
- ایمیزون ویب سروسز
- an
- تجزیہ
- تجزیاتی
- تجزیے
- تجزیہ
- اور
- ایک اور
- کوئی بھی
- اپاچی
- اپیل
- ایپلی کیشنز
- کا اطلاق کریں
- نقطہ نظر
- نقطہ نظر
- فن تعمیر
- کیا
- لڑی
- AS
- مدد
- مدد
- At
- مصنف
- خود کار طریقے سے
- دستیاب
- AWS
- AWS گلو
- واپس
- کی بنیاد پر
- بنیادی
- BE
- کیونکہ
- اس سے پہلے
- شروع کریں
- کیا جا رہا ہے
- BEST
- بہتر
- کے درمیان
- خالی
- کتاب
- دونوں
- تعمیر
- کاروبار
- لیکن
- by
- کہا جاتا ہے
- کر سکتے ہیں
- کیٹلوگ
- کیونکہ
- سیل
- چیلنجوں
- تبدیل
- تبدیلیاں
- تبدیل کرنے
- انتخاب
- میں سے انتخاب کریں
- شہر
- درجہ بندی
- کلائنٹس
- کوڈ
- کالم
- کالم
- COM
- آتا ہے
- کامن
- عام طور پر
- مکمل
- مکمل
- پیچیدہ
- کمپیوٹر
- کمپیوٹر سائنس
- کمپیوٹر ویژن
- شرط
- سلوک
- مجموعہ
- غور کریں
- کنسول
- مسلسل
- رکاوٹوں
- تعمیر
- پر مشتمل ہے
- پر مشتمل ہے
- پر مشتمل ہے
- اس کے برعکس
- کنٹرول
- تبدیل
- تبدیل
- سرمایہ کاری مؤثر
- سرمایہ کاری مؤثر حل
- کاؤنٹی
- عدالتیں
- احاطہ کرتا ہے
- کرالر
- تخلیق
- بنائی
- تخلیق
- اہم
- اپنی مرضی کے
- گاہک
- گاہکوں
- اعداد و شمار
- ڈیٹا انضمام
- ڈیٹا مینجمنٹ
- اعداد و شمار پر مبنی ہے
- ڈیٹا بیس
- ڈیٹاسیٹس
- معاملہ
- فیصلے
- پہلے سے طے شدہ
- وضاحت
- وضاحت
- ڈیلے
- ثبوت
- انحصار کرتا ہے
- تعیناتی
- ڈیزائن
- تفصیلی
- تفصیلات
- ڈیولپر
- مختلف
- مشکل
- ڈیجیٹل
- ڈیجیٹل دور
- براہ راست
- دریافت
- مختلف
- do
- نہیں کرتا
- کیا
- نہیں
- ڈاٹ
- کے دوران
- متحرک
- ہر ایک
- کو کم
- آسانی سے
- آسان
- ایڈیٹر
- اثر
- مؤثر طریقے
- کارکردگی
- ہنر
- مؤثر طریقے سے
- کوشش
- محنت سے
- الیکٹرک
- برقی گاڑی
- عناصر
- ملازم
- بااختیار
- بااختیار بنانا
- خالی
- کو چالو کرنے کے
- کو فعال کرنا
- تصادم
- آخر
- انجن
- بڑھانے کے
- کو یقینی بنانے کے
- یقینی بناتا ہے
- درج
- حوصلہ افزائی
- اندراج
- نقائص
- خاص طور پر
- Ether (ETH)
- بھی
- واقعات
- ہر کوئی
- مثال کے طور پر
- حد سے تجاوز
- تبادلہ
- مہارت
- کی تلاش
- تلاش
- وضاحت کی
- نکالنے
- نکالنے
- خاندان
- نمایاں کریں
- خصوصیات
- اعداد و شمار
- فائل
- فائلوں
- کی مالی اعانت
- پہلا
- مقرر
- لچک
- توجہ مرکوز
- توجہ مرکوز
- کے بعد
- کے لئے
- فارمیٹ
- فریم
- مفت
- فرکوےنسی
- سے
- تقریب
- حاصل کرنا
- عام مقصد
- پیدا
- گلوبل
- Go
- مقصد
- حکومت
- عظیم
- ہینڈل
- ہینڈلنگ
- ہوتا ہے
- استعمال کرنا
- ہے
- ہونے
- he
- صحت کی دیکھ بھال
- ہارٹ
- مدد
- مدد
- مدد کرتا ہے
- اس کی
- اعلی سطحی
- انتہائی
- ان
- کس طرح
- کیسے
- تاہم
- HTML
- HTTP
- HTTPS
- IAM
- مثالی
- خیالات
- شناختی
- if
- وضاحت کرتا ہے
- پر عملدرآمد
- عمل درآمد
- پر عمل درآمد
- درآمد
- کو بہتر بنانے کے
- بہتر
- in
- سمیت
- انفرادی
- افراد
- صنعتوں
- معلومات
- مطلع
- انفراسٹرکچر
- جدید
- کے اندر
- بصیرت
- کے بجائے
- ہدایات
- ضم
- انضمام
- انٹرایکٹو
- دلچسپی
- انٹرفیس
- میں
- شامل ہے
- مسائل
- IT
- میں
- ایوب
- نوکریاں
- فوٹو
- JSON
- Jupyter نوٹ بک
- رکھیں
- جان
- لیب
- زبان
- بڑے
- بڑے
- معروف
- جانیں
- سیکھنے
- سطح
- کی طرح
- LIMIT
- حد کے
- حدود
- لائن
- لائنوں
- لوڈ
- لوڈ کر رہا ہے
- منطق
- تلاش
- مشین
- مشین لرننگ
- مین
- بنیادی طور پر
- بنا
- بنانا
- انتظام
- مینیجنگ
- دستی
- دستی طور پر
- بہت سے
- تعریفیں
- ماسٹر کی
- مئی..
- کا مطلب ہے کہ
- مینو
- میٹا ڈیٹا
- طریقہ
- منٹ
- ماڈل
- زیادہ
- زیادہ موثر
- سب سے زیادہ
- منتقل
- فلم
- ایک سے زیادہ
- نام
- نامزد
- نام
- قدرتی
- قدرتی زبان
- قدرتی زبان عملیات
- تشریف لے جائیں
- سمت شناسی
- ضروری
- ضرورت ہے
- ضروریات
- نئی
- نیا
- اگلے
- خاص طور پر
- نوٹ بک
- اب
- تعداد
- اشیاء
- of
- تجویز
- on
- ایک
- صرف
- آپریشنز
- زیادہ سے زیادہ
- کی اصلاح کریں
- اصلاح کرتا ہے
- آپشنز کے بھی
- or
- حکم
- تنظیمیں
- نکالنے
- دیگر
- ہمارے
- باہر
- پیداوار
- پر
- پر قابو پانے
- خود
- صفحہ
- پین
- پیرامیٹر
- پیرامیٹرز
- حصہ
- خاص طور پر
- منظور
- راستہ
- پیٹرک
- انجام دینے کے
- کارکردگی
- اجازتیں
- لینے
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیل
- پالیسی
- آبادی
- قبضہ کرو
- پوسٹ
- ممکنہ
- عین مطابق
- کو ترجیح دیتے ہیں
- ضروریات
- پیش نظارہ
- پچھلا
- مسائل
- عمل
- عملدرآمد
- پروسیسنگ
- مصنوعات
- منصوبے
- منصوبوں
- خصوصیات
- فراہم
- فراہم کرتا ہے
- شائع
- مقصد
- ازگر
- سوالات
- فوری
- بلکہ
- پڑھیں
- آسانی سے
- پڑھنا
- وجوہات
- موصول
- تسلیم
- کا حوالہ دیتے ہیں
- متعلقہ
- ضروریات
- بچانے
- وسائل
- جواب
- ذمہ داری
- باقی
- محدود
- پابندی
- نتائج کی نمائش
- مضبوط
- کردار
- جڑ
- ROW
- رن
- اسی
- محفوظ کریں
- بڑے پیمانے پر
- اسکیل ایبلٹی
- توسیع پذیر
- سائنس
- اسکرپٹ
- ہموار
- بغیر کسی رکاوٹ کے
- دوسری
- سیکشن
- دیکھنا
- سینئر
- سروسز
- اجلاس
- مقرر
- قائم کرنے
- کئی
- وہ
- شیل
- ہونا چاہئے
- دکھائیں
- دکھایا گیا
- شوز
- اسی طرح
- سادہ
- سادگی
- آسان بنانا
- ایک
- سائز
- چھوٹے
- So
- فٹ بال
- حل
- حل
- کچھ
- ماخذ
- ذرائع
- چنگاری
- ماہر
- مہارت
- مخصوص
- خاص طور پر
- تیزی
- خرچ کرنا۔
- SQL
- معیار
- شروع ہوتا ہے
- حالت
- بیان
- جس میں لکھا
- مرحلہ
- مراحل
- ذخیرہ
- ذخیرہ
- براہ راست
- کارگر
- سلک
- مضبوط
- ساخت
- ڈھانچوں
- سٹوڈیو
- کامیابی
- اس طرح
- موزوں
- حمایت
- اس بات کا یقین
- پائیداری
- سسٹمز
- ٹیبل
- TAG
- موزوں
- لے لو
- لیتا ہے
- کاموں
- تکنیک
- ٹینس
- سے
- کہ
- ۔
- کے بارے میں معلومات
- دنیا
- ان
- ان
- تو
- وہاں.
- یہ
- وہ
- اس
- ان
- کے ذریعے
- وقت
- عنوان
- عنوان
- کرنے کے لئے
- آج کا
- ٹول کٹ
- سب سے اوپر
- موضوع
- تبدیل
- تبدیلی
- سفر
- ٹرننگ
- سبق
- دو
- قسم
- اقسام
- حتمی
- کے تحت
- اپ ڈیٹ کریں
- اپ ڈیٹ
- اپ لوڈ کردہ
- us
- استعمالی
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- رکن کا
- صارف مواجہ
- صارف دوست
- استعمال
- کا استعمال کرتے ہوئے
- عام طور پر
- استعمال کرنا۔
- قیمتی
- قیمت
- اقدار
- گاڑی
- ورژن
- کی طرف سے
- لنک
- خیالات
- نقطہ نظر
- دیکھ
- راستہ..
- we
- ویب
- ویب خدمات
- کیا
- جب
- جبکہ
- چاہے
- جس
- ڈبلیو
- کیوں
- گے
- ساتھ
- کے اندر
- بغیر
- کام
- کام کا بہاؤ
- کام کے بہاؤ
- کام کرتا ہے
- دنیا
- لکھنا
- XML
- آپ
- اور
- زیفیرنیٹ