Озера даних на базі AWS, які підтримуються неперевершеною доступністю Служба простого зберігання Amazon (Amazon S3), може впоратися з масштабом, гнучкістю та гнучкістю, необхідними для поєднання різних даних і підходів до аналітики. Оскільки озера даних зросли в розмірах і зрілих у використанні, значні зусилля можуть бути витрачені на підтримку даних у відповідності з бізнес-подіями. Щоб гарантувати, що файли оновлюються відповідно до транзакцій, все більше клієнтів використовують формати транзакційних таблиць з відкритим кодом, такі як Айсберг Апач, Апач Худі та Linux Foundation Delta Lake які допомагають зберігати дані з високим рівнем стиснення, власно взаємодіють із вашими програмами та фреймворками та спрощують поступову обробку даних у озерах даних, побудованих на Amazon S3. Ці формати забезпечують транзакції ACID (атомарність, послідовність, ізоляція, довговічність), оновлення та видалення, а також розширені функції, такі як подорож у часі та знімки, які раніше були доступні лише в сховищах даних. Кожен формат зберігання реалізує цю функціональність дещо по-різному; для порівняння див Вибір формату відкритої таблиці для вашого озера транзакційних даних на AWS.
У 2023, AWS оголосила про загальну доступність для Apache Iceberg, Apache Hudi та Linux Foundation Delta Lake в Amazon Athena для Apache Spark, що усуває потребу встановлювати окремий з’єднувач або пов’язані залежності та керувати версіями, а також спрощує кроки налаштування, необхідні для використання цих фреймворків.
У цій публікації ми покажемо вам, як використовувати Spark SQL у Амазонка Афіна зошити та працювати з форматами таблиць Iceberg, Hudi та Delta Lake. Ми демонструємо типові операції, такі як створення баз даних і таблиць, вставка даних у таблиці, запит даних і перегляд знімків таблиць в Amazon S3 за допомогою Spark SQL в Athena.
Передумови
Виконайте такі передумови:
Завантажте та імпортуйте приклади блокнотів з Amazon S3
Щоб продовжити, завантажте блокноти, про які йдеться в цій публікації, із таких місць:
Завантаживши блокноти, імпортуйте їх у своє середовище Athena Spark, дотримуючись інструкцій Щоб імпортувати блокнот розділ в Керування файлами блокнота.
Перейдіть до певного розділу «Відкрити формат таблиці».
Якщо вас цікавить формат таблиці Iceberg, перейдіть до Робота з таблицями Apache Iceberg .
Якщо вас цікавить формат таблиці Hudi, перейдіть до Робота з таблицями Apache Hudi .
Якщо вас цікавить формат таблиці Delta Lake, перейдіть до Робота з таблицями Delta Lake основи Linux .
Робота з таблицями Apache Iceberg
Використовуючи блокноти Spark в Athena, ви можете запускати запити SQL безпосередньо без використання PySpark. Ми робимо це за допомогою магії клітинок, тобто спеціальних заголовків у клітинці блокнота, які змінюють поведінку клітинки. Для SQL ми можемо додати %%sql magic, який інтерпретуватиме весь вміст комірки як оператор SQL для виконання на Athena.
У цьому розділі ми покажемо, як ви можете використовувати SQL на Apache Spark для Athena для створення, аналізу та керування таблицями Apache Iceberg.
Налаштуйте сеанс блокнота
Щоб використовувати Apache Iceberg в Athena, під час створення або редагування сеансу виберіть Айсберг Апач варіант шляхом розширення Властивості Apache Spark розділ. Він попередньо заповнить властивості, як показано на наступному знімку екрана.
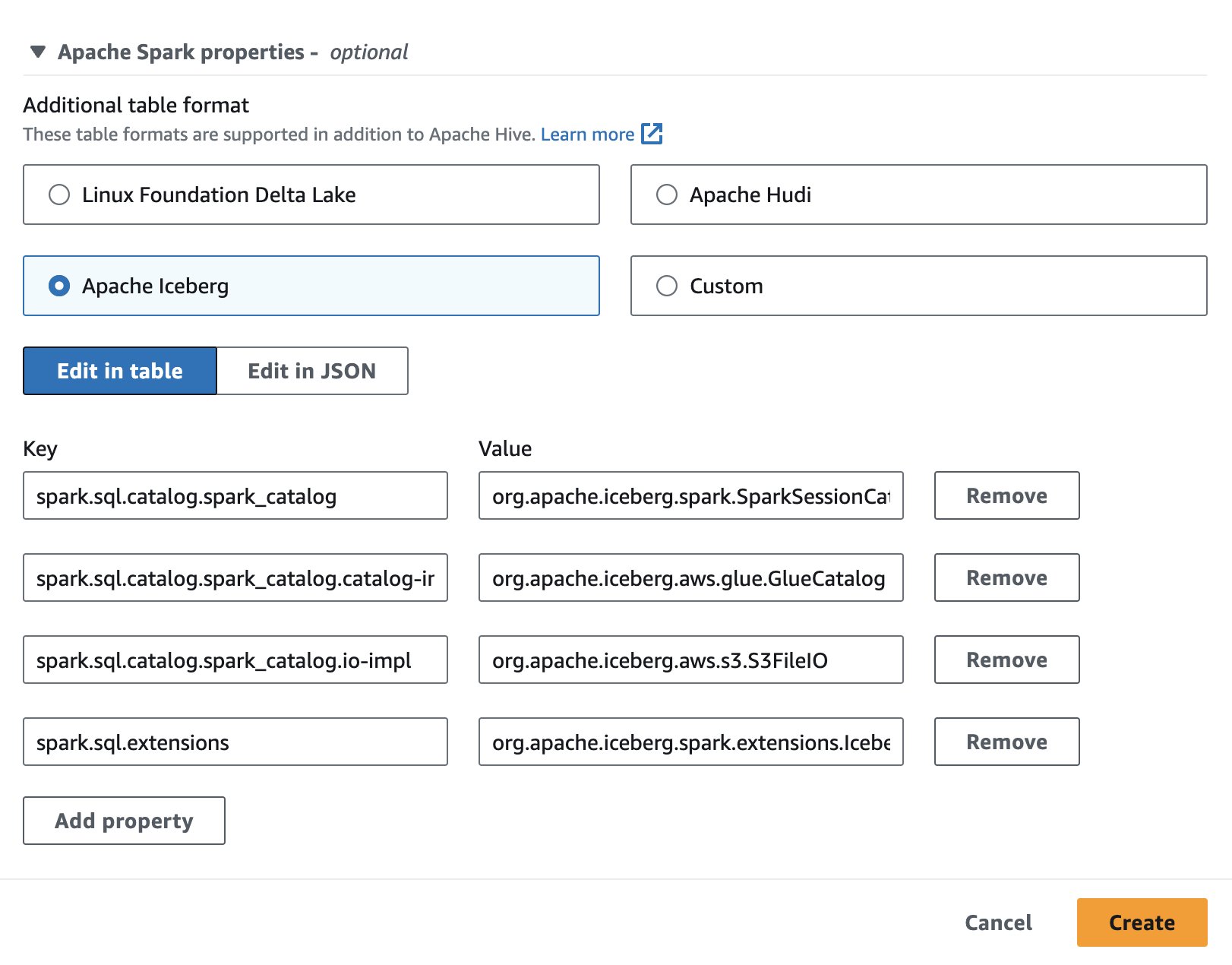
Для кроків див Редагування деталей сеансу or Створення власного блокнота.
Код, використаний у цьому розділі, доступний у SparkSQL_iceberg.ipynb файл, щоб слідувати.
Створіть базу даних і таблицю Iceberg
Спочатку ми створюємо базу даних у каталозі даних AWS Glue. За допомогою наступного SQL ми можемо створити базу даних під назвою icebergdb:
Далі в базі даних icebergdb, ми створюємо таблицю Iceberg під назвою noaa_iceberg вказуючи на місце в Amazon S3, куди ми будемо завантажувати дані. Виконайте наступний оператор і замініть розташування s3://<your-S3-bucket>/<prefix>/ з вашим відром S3 і префіксом:
Вставте дані в таблицю
Щоб заселити noaa_iceberg Таблиця Айсберг, вставляємо дані з таблиці Паркет sparkblogdb.noaa_pq який було створено як частину передумов. Ви можете зробити це за допомогою INSERT INTO заява в Spark:
Крім того, ви можете використовувати СТВОРИТИ ТАБЛИЦЮ ЯК ВИБІР з пропозицією USING iceberg, щоб створити таблицю Iceberg і вставити дані з вихідної таблиці за один крок:
Зробіть запит до таблиці Iceberg
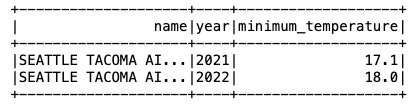
Тепер, коли дані вставлено в таблицю Iceberg, ми можемо почати їх аналізувати. Давайте запустимо Spark SQL, щоб знайти мінімальну зареєстровану температуру за роками для 'SEATTLE TACOMA AIRPORT, WA US' Розташування:
Отримуємо наступний вихід.
Оновити дані в таблиці Iceberg
Давайте розглянемо, як оновити дані в нашій таблиці. Ми хочемо оновити назву станції 'SEATTLE TACOMA AIRPORT, WA US' до 'Sea-Tac'. Використовуючи Spark SQL, ми можемо запустити ОНОВЛЕННЯ заява проти таблиці Iceberg:
Потім ми можемо виконати попередній запит SELECT, щоб знайти мінімальну зафіксовану температуру для 'Sea-Tac' Розташування:
Отримуємо наступний висновок.

Компактні файли даних
Відкриті формати таблиць, такі як Iceberg, працюють шляхом створення дельта-змін у сховищі файлів і відстеження версій рядків за допомогою файлів маніфесту. Більше файлів даних призводить до того, що у файлах маніфесту зберігається більше метаданих, а невеликі файли даних часто спричиняють непотрібну кількість метаданих, що призводить до менш ефективних запитів і вищих витрат на доступ до Amazon S3. Біг айсберга rewrite_data_files процедура в Spark для Athena стисне файли даних, об’єднавши багато малих файлів дельта-змін у менший набір файлів Parquet, оптимізованих для читання. Стиснення файлів прискорює операцію читання за запитом. Щоб запустити стиснення нашої таблиці, запустіть такий Spark SQL:
rewrite_data_files пропонує варіанти щоб визначити стратегію сортування, яка може допомогти реорганізувати та стиснути дані.
Перелік знімків таблиці
Кожна операція запису, оновлення, видалення, зміни та стиснення таблиці Iceberg створює новий знімок таблиці, зберігаючи старі дані та метадані для ізоляції знімка та подорожі в часі. Щоб отримати список знімків таблиці Iceberg, запустіть такий оператор Spark SQL:
Закінчився термін дії старих знімків
Миттєві знімки, термін дії яких регулярно закінчується, рекомендовано для видалення файлів даних, які більше не потрібні, і для збереження невеликого розміру метаданих таблиці. Він ніколи не видалить файли, які все ще потрібні для знімка, термін дії якого минув. У Spark для Athena запустіть наступний SQL, щоб завершити термін дії знімків для таблиці icebergdb.noaa_iceberg які старші за певну позначку часу:
Зауважте, що значення мітки часу вказано як рядок у форматі yyyy-MM-dd HH:mm:ss.fff. Результат дасть підрахунок кількості видалених файлів даних і метаданих.
Викиньте таблицю та базу даних
Ви можете запустити наступний Spark SQL, щоб очистити таблиці Iceberg і пов’язані дані в Amazon S3 з цієї вправи:
Запустіть такий Spark SQL, щоб видалити базу даних icebergdb:
Щоб дізнатися більше про всі операції, які можна виконувати на столах Iceberg за допомогою Spark для Athena, див Запити Spark та Іскрові процедури в документації Iceberg.
Робота з таблицями Apache Hudi
Далі ми покажемо, як можна використовувати SQL у Spark для Athena для створення, аналізу та керування таблицями Apache Hudi.
Налаштуйте сеанс блокнота
Щоб використовувати Apache Hudi в Athena, під час створення або редагування сеансу виберіть Апач Худі варіант шляхом розширення Властивості Apache Spark .
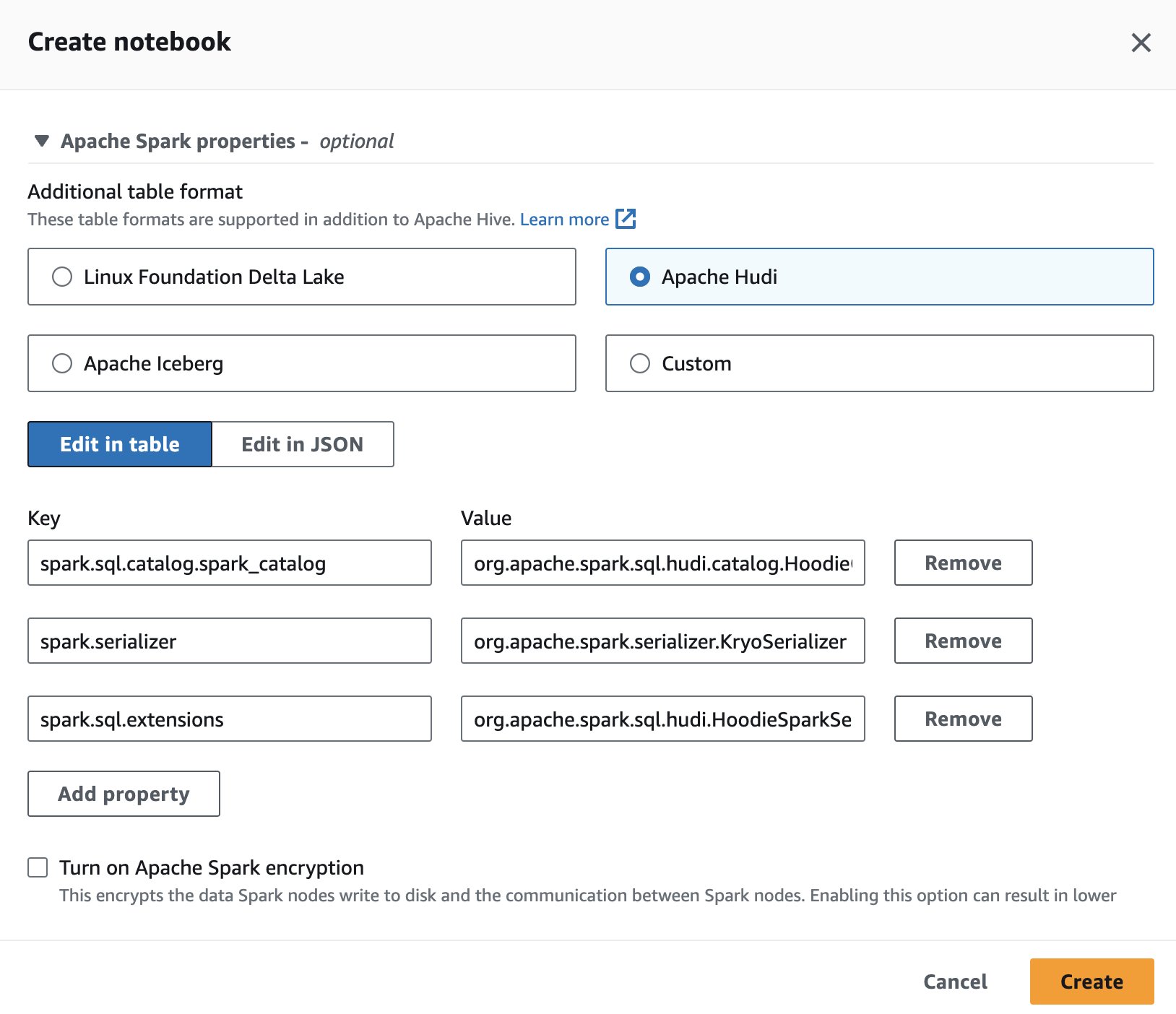
Для кроків див Редагування деталей сеансу or Створення власного блокнота.
Код, використаний у цьому розділі, має бути доступним у SparkSQL_hudi.ipynb файл, щоб слідувати.
Створіть базу даних і таблицю Hudi
Спочатку ми створюємо базу даних під назвою hudidb які зберігатимуться в каталозі даних AWS Glue з подальшим створенням таблиці Hudi:
Ми створюємо таблицю Hudi, яка вказує на місце в Amazon S3, куди ми будемо завантажувати дані. Зверніть увагу, що таблиця складається з копіювати на запис типу. Це визначається type= 'cow' в таблиці DDL. Ми визначили станцію та дату як декілька первинних ключів, а preCombinedField як рік. Крім того, таблиця розділена по роках. Виконайте наступний оператор і замініть розташування s3://<your-S3-bucket>/<prefix>/ з вашим відром S3 і префіксом:
Вставте дані в таблицю
Як і з Iceberg, ми використовуємо INSERT INTO оператор для заповнення таблиці шляхом читання даних з sparkblogdb.noaa_pq таблиця створена в попередній публікації:
Зробіть запит до таблиці Hudi
Тепер, коли таблицю створено, давайте запустимо запит, щоб знайти максимальну зафіксовану температуру для 'SEATTLE TACOMA AIRPORT, WA US' Розташування:
Оновити дані в таблиці Hudi
Давайте змінимо назву станції 'SEATTLE TACOMA AIRPORT, WA US' до 'Sea–Tac'. Ми можемо виконати оператор UPDATE на Spark для Athena оновлення записи noaa_hudi стіл:
Ми виконуємо попередній запит SELECT, щоб знайти максимальну зафіксовану температуру для 'Sea-Tac' Розташування:
Виконуйте запити про подорожі в часі
Ми можемо використовувати запити про подорожі в часі в SQL на Athena для аналізу минулих знімків даних. Наприклад:
Цей запит перевіряє дані про температуру в аеропорту Сіетла за певний час у минулому. Речення timestamp дозволяє нам повернутися назад без зміни поточних даних. Зауважте, що значення мітки часу вказано як рядок у форматі yyyy-MM-dd HH:mm:ss.fff.
Оптимізуйте швидкість запитів за допомогою кластеризації
Щоб покращити продуктивність запиту, ви можете виконати Кластеризація у таблицях Hudi за допомогою SQL у Spark для Athena:
Компактні столи
Compaction — це служба таблиць, яка використовується Hudi спеціально для таблиць Merge On Read (MOR) для періодичного об’єднання оновлень із файлів журналу на основі рядків у відповідний базовий файл на основі стовпців для створення нової версії базового файлу. Ущільнення не застосовується до таблиць Copy On Write (COW) і застосовується лише до таблиць MOR. Ви можете виконати такий запит у Spark для Athena, щоб виконати стиснення таблиць MOR:
Викиньте таблицю та базу даних
Запустіть такий Spark SQL, щоб видалити створену вами таблицю Hudi та пов’язані дані з розташування Amazon S3:
Запустіть наступний Spark SQL, щоб видалити базу даних hudidb:
Щоб дізнатися про всі операції, які можна виконувати над таблицями Hudi за допомогою Spark для Athena, див SQL DDL та Процедури в документації Hudi.
Робота з таблицями Delta Lake основи Linux
Далі ми покажемо, як ви можете використовувати SQL на Spark для Athena для створення, аналізу та керування таблицями Delta Lake.
Налаштуйте сеанс блокнота
Щоб використовувати Delta Lake у Spark для Athena під час створення або редагування сеансу, виберіть Linux Foundation Delta Lake шляхом розширення Властивості Apache Spark .
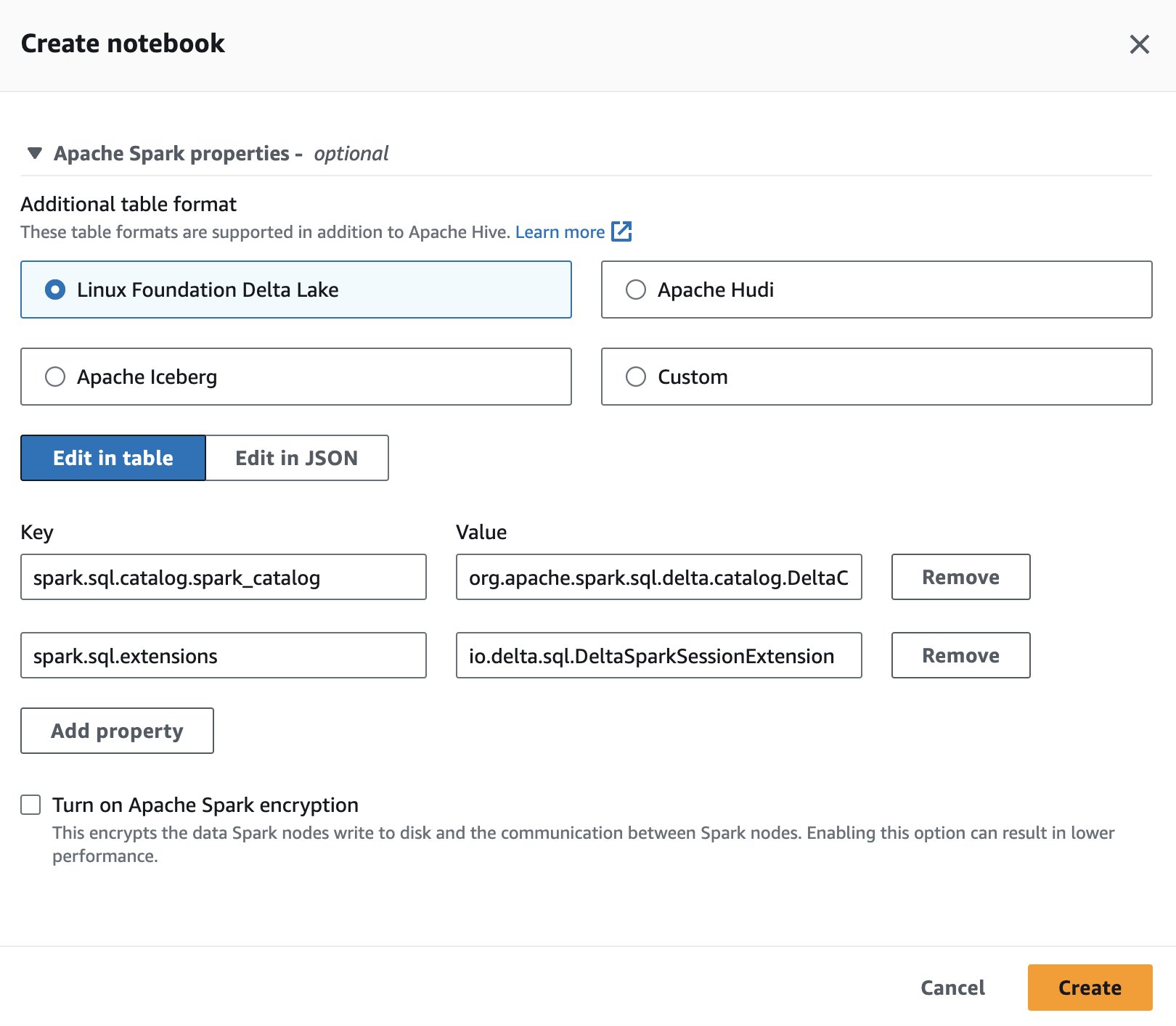
Для кроків див Редагування деталей сеансу or Створення власного блокнота.
Код, використаний у цьому розділі, має бути доступним у SparkSQL_delta.ipynb файл, щоб слідувати.
Створіть базу даних і таблицю Delta Lake
У цьому розділі ми створюємо базу даних у каталозі даних AWS Glue. Використовуючи наступний SQL, ми можемо створити базу даних під назвою deltalakedb:
Далі в базі даних deltalakedb, ми створюємо таблицю Delta Lake під назвою noaa_delta вказуючи на місце в Amazon S3, куди ми будемо завантажувати дані. Виконайте наступний оператор і замініть розташування s3://<your-S3-bucket>/<prefix>/ з вашим відром S3 і префіксом:
Вставте дані в таблицю
Ми використовуємо INSERT INTO оператор для заповнення таблиці шляхом читання даних з sparkblogdb.noaa_pq таблиця створена в попередній публікації:
Ви також можете використовувати CREATE TABLE AS SELECT, щоб створити таблицю Delta Lake і вставити дані з вихідної таблиці в один запит.
Запит таблиці Delta Lake
Тепер, коли дані вставлено в таблицю Delta Lake, ми можемо почати їх аналізувати. Давайте запустимо Spark SQL, щоб знайти мінімальну зафіксовану температуру для 'SEATTLE TACOMA AIRPORT, WA US' Розташування:
Оновити дані в таблиці Delta Lake
Давайте змінимо назву станції 'SEATTLE TACOMA AIRPORT, WA US' до 'Sea–Tac'. Ми можемо запустити ОНОВЛЕННЯ заява на Spark for Athena для оновлення записів noaa_delta стіл:
Ми можемо виконати попередній запит SELECT, щоб знайти мінімальну зафіксовану температуру для 'Sea-Tac' розташування, а результат має бути таким же, як і раніше:
Компактні файли даних
У Spark для Athena ви можете запустити OPTIMIZE у таблиці Delta Lake, яка стисне малі файли у більші, щоб запити не обтяжувалися невеликими файлами. Щоб виконати операцію стиснення, запустіть такий запит:
Відноситься до Оптимізації у документації Delta Lake для різних параметрів, доступних під час запуску OPTIMIZE.
Видаліть файли, на які більше не посилається таблиця Delta Lake
Ви можете видалити файли, що зберігаються в Amazon S3, на які більше не посилається таблиця Delta Lake і старіші за порогове значення, запустивши команду VACCUM у таблиці за допомогою Spark для Athena:
Відноситься до Видаліть файли, на які більше не посилається дельта-таблиця у документації Delta Lake для опцій, доступних з VACUUM.
Викиньте таблицю та базу даних
Запустіть такий Spark SQL, щоб видалити створену таблицю Delta Lake:
Запустіть наступний Spark SQL, щоб видалити базу даних deltalakedb:
Запуск DROP TABLE DDL у таблиці та базі даних Delta Lake видаляє метадані для цих об’єктів, але не видаляє автоматично файли даних в Amazon S3. Ви можете запустити такий код Python у комірці блокнота, щоб видалити дані з розташування S3:
Щоб дізнатися більше про оператори SQL, які можна виконати в таблиці Delta Lake за допомогою Spark для Athena, див. Швидкий старт в документації Delta Lake.
Висновок
У цьому дописі продемонстровано, як використовувати Spark SQL у ноутбуках Athena для створення баз даних і таблиць, вставлення та запиту даних, а також виконання типових операцій, таких як оновлення, ущільнення та подорожі в часі в таблицях Hudi, Delta Lake і Iceberg. Формати відкритих таблиць додають транзакції ACID, зміни та видалення до озер даних, долаючи обмеження зберігання необроблених об’єктів. Усунувши потребу встановлювати окремі роз’єми, вбудована інтеграція Spark on Athena зменшує етапи конфігурації та витрати на керування під час використання цих популярних інфраструктур для створення надійних озер даних на Amazon S3. Щоб дізнатися більше про вибір формату відкритої таблиці для робочих навантажень озера даних, див Вибір формату відкритої таблиці для вашого озера транзакційних даних на AWS.
Про авторів
![]() Патік Шах є старшим архітектором аналітики в Amazon Athena. Він приєднався до AWS у 2015 році і з того часу зосереджується на аналітиці великих даних, допомагаючи клієнтам створювати масштабовані та надійні рішення за допомогою аналітичних служб AWS.
Патік Шах є старшим архітектором аналітики в Amazon Athena. Він приєднався до AWS у 2015 році і з того часу зосереджується на аналітиці великих даних, допомагаючи клієнтам створювати масштабовані та надійні рішення за допомогою аналітичних служб AWS.
![]() Радж Девнатх є менеджером із продуктів в AWS на Amazon Athena. Він захоплено створює продукти, які люблять клієнти, і допомагає клієнтам отримувати цінність із їхніх даних. Його досвід роботи в наданні рішень для багатьох кінцевих ринків, таких як фінанси, роздрібна торгівля, розумні будівлі, домашня автоматизація та системи передачі даних.
Радж Девнатх є менеджером із продуктів в AWS на Amazon Athena. Він захоплено створює продукти, які люблять клієнти, і допомагає клієнтам отримувати цінність із їхніх даних. Його досвід роботи в наданні рішень для багатьох кінцевих ринків, таких як фінанси, роздрібна торгівля, розумні будівлі, домашня автоматизація та системи передачі даних.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- : має
- :є
- : ні
- :де
- $UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- МЕНЮ
- доступ
- додавати
- просунутий
- проти
- аеропорт
- ВСІ
- по
- Також
- Amazon
- Амазонка Афіна
- Amazon Web Services
- кількість
- an
- аналітика
- аналізувати
- Аналізуючи
- та
- оголошений
- Apache
- Apache Spark
- застосовно
- застосування
- застосовується
- підходи
- ЕСТЬ
- навколо
- AS
- асоційований
- At
- автоматично
- Автоматизація
- наявність
- доступний
- AWS
- Клей AWS
- назад
- фон
- база
- BE
- було
- поведінка
- Великий
- Великий даних
- будувати
- Створюємо
- побудований
- вбудований
- бізнес
- але
- by
- call
- званий
- CAN
- каталог
- Викликати
- осередок
- зміна
- Зміни
- Перевірки
- очистити
- код
- об'єднувати
- об'єднання
- загальний
- Комунікація
- системи зв’язку
- компактний
- порівняння
- конфігурація
- послідовний
- зміст
- Відповідний
- витрати
- вважати
- створювати
- створений
- створює
- створення
- створення
- Поточний
- Клієнти
- дані
- Analytics даних
- Озеро даних
- обробка даних
- сховища даних
- Database
- базами даних
- Дата
- певний
- надання
- Дельта
- демонструвати
- продемонстрований
- залежно
- різний
- безпосередньо
- обговорювалися
- do
- документація
- Ні
- скачати
- Падіння
- довговічність
- кожен
- Раніше
- редагування
- ефективний
- зусилля
- працевлаштований
- включіть
- кінець
- забезпечувати
- Весь
- Навколишнє середовище
- Ефір (ETH)
- Події
- приклад
- Здійснювати
- розширюється
- витяг
- риси
- філе
- Файли
- фінансування
- знайти
- Перший
- Гнучкість
- фокусування
- стежити
- потім
- після
- для
- формат
- фонд
- каркаси
- від
- функціональність
- Загальне
- отримати
- Давати
- Group
- Зростання
- вирощений
- обробляти
- Мати
- має
- he
- Заголовки
- допомога
- допомогу
- hh
- Високий
- вище
- його
- Головна
- Головна Автоматизація
- Як
- How To
- HTML
- HTTP
- HTTPS
- зображення
- implements
- імпорт
- удосконалювати
- in
- зростаючий
- встановлювати
- інтеграція
- зацікавлений
- інтерфейс
- в
- ізоляція
- IT
- приєднався
- JPG
- тримати
- зберігання
- ключі
- озеро
- озера
- більше
- широта
- Веде за собою
- УЧИТЬСЯ
- менше
- дозволяє
- як
- недоліки
- Linux
- основи linux
- список
- загрузка
- розташування
- місць
- журнал
- довше
- подивитися
- шукати
- любов
- магія
- управляти
- управління
- менеджер
- манера
- багато
- ринки
- Макс
- максимальний
- Злиття
- метадані
- хвилин
- мінімальний
- більше
- множинний
- ім'я
- спочатку
- Переміщення
- Необхідність
- необхідний
- ніколи
- Нові
- немає
- увагу
- ноутбук
- ноутбуки
- номер
- об'єкт
- Об'єкт зберігання
- об'єкти
- of
- Пропозиції
- часто
- Старий
- старший
- on
- ONE
- тільки
- OP
- відкрити
- з відкритим вихідним кодом
- операція
- операції
- Оптимізувати
- варіант
- Опції
- or
- порядок
- наші
- вихід
- подолання
- власний
- частина
- пристрасний
- Минуле
- виконувати
- продуктивність
- plato
- Інформація про дані Платона
- PlatoData
- популярний
- пошта
- передумови
- попередній
- раніше
- первинний
- процедура
- обробка
- виробляти
- Product
- менеджер по продукції
- Продукти
- властивості
- Python
- запити
- ставки
- Сировина
- Читати
- читання
- рекомендований
- записаний
- облік
- знижує
- послатися
- посилання на
- надійний
- видаляти
- видаляє
- видалення
- замінювати
- вимагається
- результат
- в результаті
- роздрібна торгівля
- утримання
- міцний
- прогін
- біг
- то ж
- масштабовані
- шкала
- Сіетл
- другий
- розділ
- побачити
- вибрати
- вибирає
- окремий
- обслуговування
- Послуги
- Сесія
- комплект
- Повинен
- Показувати
- показаний
- Шоу
- значний
- простий
- спрощує
- спростити
- з
- Розмір
- трохи відрізняється
- SLP
- невеликий
- менше
- розумний
- Знімок
- So
- Рішення
- Source
- Простір
- Іскритися
- спеціальний
- конкретний
- конкретно
- зазначений
- швидкість
- швидкість
- відпрацьований
- SQL
- старт
- Заява
- заяви
- станція
- Крок
- заходи
- Як і раніше
- зберігання
- зберігати
- зберігати
- Стратегія
- рядок
- такі
- Підтриманий
- система
- Systems
- таблиця
- Tacoma
- ніж
- Що
- Команда
- їх
- Їх
- потім
- Ці
- це
- поріг
- через
- час
- подорож у часі
- відмітка часу
- до
- Відстеження
- транзакційний
- Transactions
- подорожувати
- тип
- неперевершений
- Оновити
- оновлений
- Updates
- us
- Використання
- використання
- використовуваний
- використання
- Вакуум
- значення
- версія
- версії
- хотіти
- було
- способи
- we
- Web
- веб-сервіси
- були
- коли
- який
- в той час як
- волі
- з
- без
- Work
- запис
- рік
- ви
- вашу
- зефірнет