Багато організацій, малих і великих, працюють над міграцією та модернізацією своїх аналітичних навантажень на Amazon Web Services (AWS). Існує багато причин для клієнтів переходити на AWS, але одна з головних — це можливість використовувати повністю керовані сервіси, а не витрачати час на підтримку інфраструктури, виправлення, моніторинг, резервне копіювання тощо. Команди керівників і розробників можуть витрачати більше часу на оптимізацію поточних рішень і навіть на експерименти з новими варіантами використання, замість того, щоб підтримувати поточну інфраструктуру.
Маючи можливість швидко рухатися в AWS, ви також повинні відповідально ставитися до даних, які ви отримуєте та обробляєте, продовжуючи масштабувати. Ці обов’язки включають дотримання законів і нормативних актів щодо конфіденційності даних, а також заборону зберігання та розголошення конфіденційних даних, як-от ідентифікаційної інформації (PII) або захищеної інформації про здоров’я (PHI) із попередніх джерел.
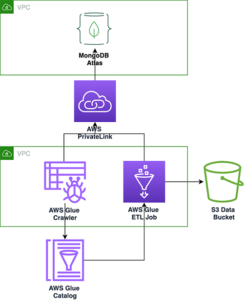
У цій публікації ми ознайомимося з високорівневою архітектурою та конкретним випадком використання, який демонструє, як ви можете продовжувати масштабувати платформу даних вашої організації без необхідності витрачати багато часу на розробку для вирішення проблем конфіденційності даних. Ми використовуємо Клей AWS для виявлення, маскування та редагування ідентифікаційних даних перед їх завантаженням Служба Amazon OpenSearch.
Огляд рішення
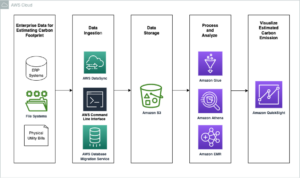
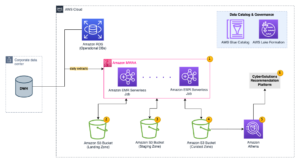
Наступна діаграма ілюструє архітектуру рішення високого рівня. Ми визначили всі шари та компоненти нашого дизайну відповідно до Об’єктив аналізу даних добре архітектурної системи AWS.
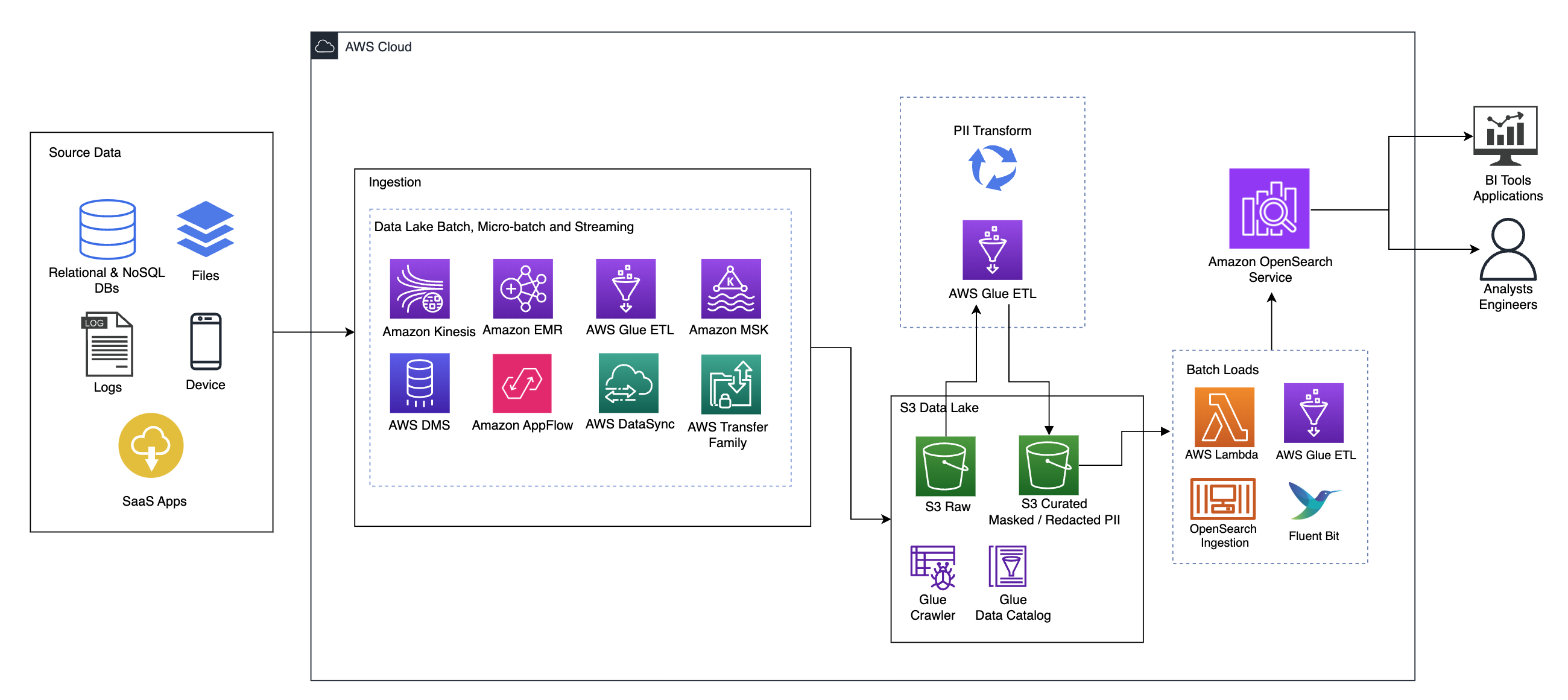
Архітектура складається з кількох компонентів:
Джерела даних
Дані можуть надходити з десятків до сотень джерел, включаючи бази даних, передачу файлів, журнали, програмне забезпечення як послуга (SaaS) тощо. Організації не завжди можуть контролювати, які дані надходять через ці канали до їхніх подальших сховищ і програм.
Поглинання: Пакет озера даних, мікропакет і потокове передавання
Багато організацій розміщують свої вихідні дані у своєму озері даних різними способами, включаючи пакетні, мікропакетні та потокові завдання. Наприклад, Amazon EMR, Клей AWS та Служба міграції бази даних AWS (AWS DMS) можна використовувати для виконання пакетних і/або потокових операцій, які надходять до озера даних на Служба простого зберігання Amazon (Amazon S3). Amazon App Flow може використовуватися для передачі даних із різних додатків SaaS до озера даних. AWS DataSync та Сімейство AWS Transfer може допомогти з переміщенням файлів до озера даних і з нього через низку різних протоколів. Амазонський кінезіс і Amazon MSK також мають можливості потокової передачі даних безпосередньо в озеро даних на Amazon S3.
Озеро даних S3
Використання Amazon S3 для вашого озера даних відповідає сучасній стратегії даних. Він забезпечує недороге зберігання без шкоди для продуктивності, надійності чи доступності. Завдяки такому підходу ви можете використовувати обчислення для своїх даних за потреби та платити лише за ємність, необхідну для роботи.
У цій архітектурі необроблені дані можуть надходити з різних джерел (внутрішніх і зовнішніх), які можуть містити конфіденційні дані.
Використовуючи сканери AWS Glue, ми можемо виявити та каталогізувати дані, які створять схеми таблиць для нас, і зрештою спростити використання AWS Glue ETL із перетворенням ідентифікаційної інформації для виявлення та маскування або редагування будь-яких конфіденційних даних, які могли потрапити в озері даних.
Бізнес-контекст і набори даних
Щоб продемонструвати цінність нашого підходу, уявімо, що ви є частиною команди розробки даних організації, що надає фінансові послуги. Ваші вимоги полягають у виявленні та маскуванні конфіденційних даних, коли вони надходять у хмарне середовище вашої організації. Дані будуть використані подальшими аналітичними процесами. У майбутньому ваші користувачі зможуть безпечно шукати історичні платіжні транзакції на основі потоків даних, зібраних із внутрішніх банківських систем. Результати пошуку від операційних груп, клієнтів і додатків інтерфейсу мають бути замасковані в конфіденційних полях.
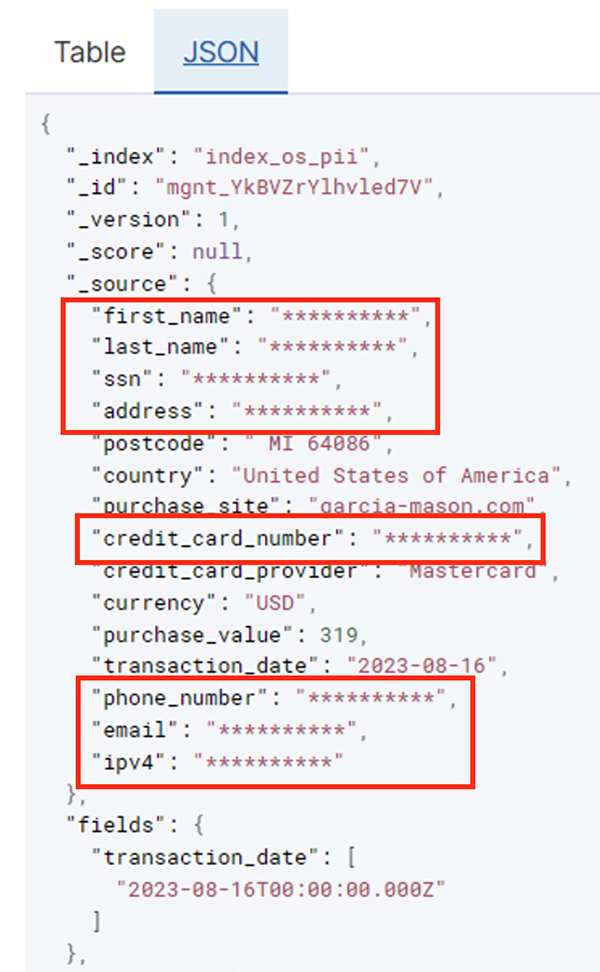
У наведеній нижче таблиці показано структуру даних, яка використовується для рішення. Для ясності ми зіставили необроблені назви стовпців із підібраними. Ви помітите, що кілька полів у цій схемі вважаються конфіденційними даними, як-от ім’я, прізвище, номер соціального страхування (SSN), адреса, номер кредитної картки, номер телефону, електронна адреса та адреса IPv4.
| Необроблена назва стовпця | Підібрана назва колонки | тип |
| c0 | ім'я | рядок |
| c1 | прізвище | рядок |
| c2 | ссн | рядок |
| c3 | адреса | рядок |
| c4 | поштовий індекс | рядок |
| c5 | країна | рядок |
| c6 | сайт покупки | рядок |
| c7 | Номер кредитної карти | рядок |
| c8 | постачальник_кредитної_картки | рядок |
| c9 | валюта | рядок |
| c10 | покупка_вартість | ціле |
| c11 | дата транзакції | дата |
| c12 | телефонний номер | рядок |
| c13 | рядок | |
| c14 | ipv4 | рядок |
Випадок використання: пакетне виявлення ідентифікаційної інформації перед завантаженням у службу OpenSearch
Клієнти, які реалізують наведену нижче архітектуру, створили своє озеро даних на Amazon S3 для запуску різних типів аналітики в масштабі. Це рішення підходить для клієнтів, яким не потрібне надходження даних у службу OpenSearch у режимі реального часу та які планують використовувати інструменти інтеграції даних, які працюють за розкладом або запускаються через події.
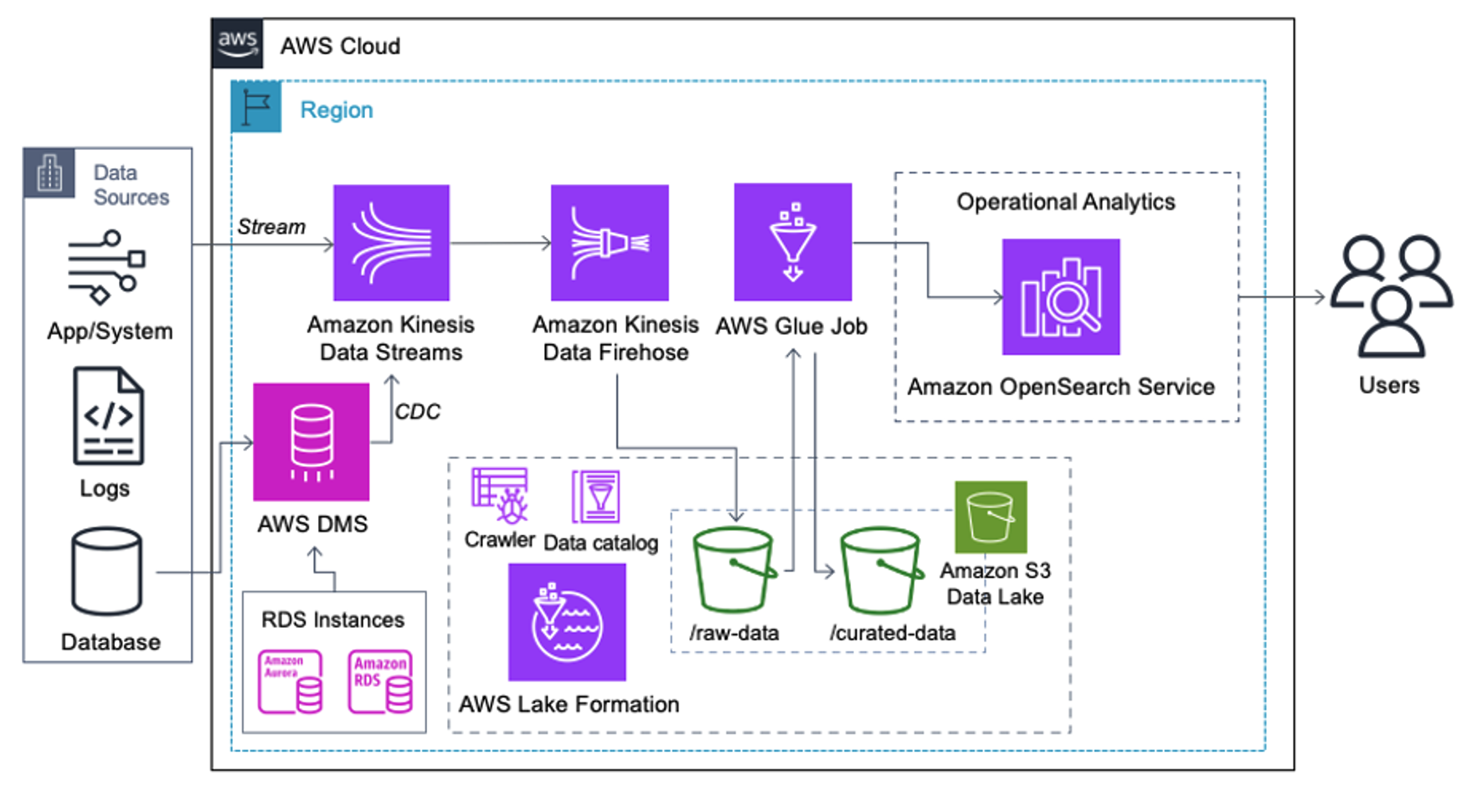
Перш ніж записи даних потраплять на Amazon S3, ми впроваджуємо рівень прийому, щоб надійно та безпечно передавати всі потоки даних до озера даних. Kinesis Data Streams розгорнуто як рівень прийому для прискореного прийому структурованих і напівструктурованих потоків даних. Прикладами цього є зміни реляційної бази даних, програми, системні журнали або потоки кліків. Для випадків використання збору змінених даних (CDC) ви можете використовувати Kinesis Data Streams як ціль для AWS DMS. Програми або системи, що генерують потоки, що містять конфіденційні дані, надсилаються в потік даних Kinesis за допомогою одного з трьох підтримуваних методів: Amazon Kinesis Agent, AWS SDK для Java або Kinesis Producer Library. Як останній крок, Amazon Kinesis Data Firehose допомагає нам надійно завантажувати пакети даних майже в реальному часі в наше місце призначення озера даних S3.
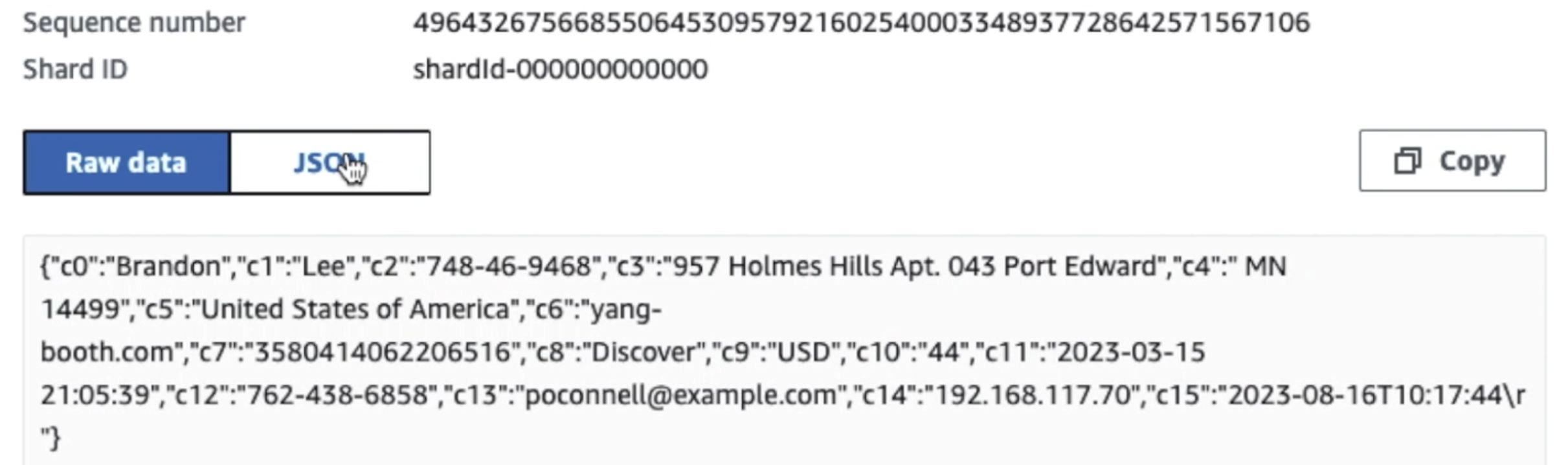
На наступному знімку екрана показано, як дані проходять через Kinesis Data Streams через Переглядач даних і отримує зразки даних, які потрапляють на необроблений префікс S3. Для цієї архітектури ми дотримувалися життєвого циклу даних для префіксів S3, як рекомендовано в Основа озера даних.
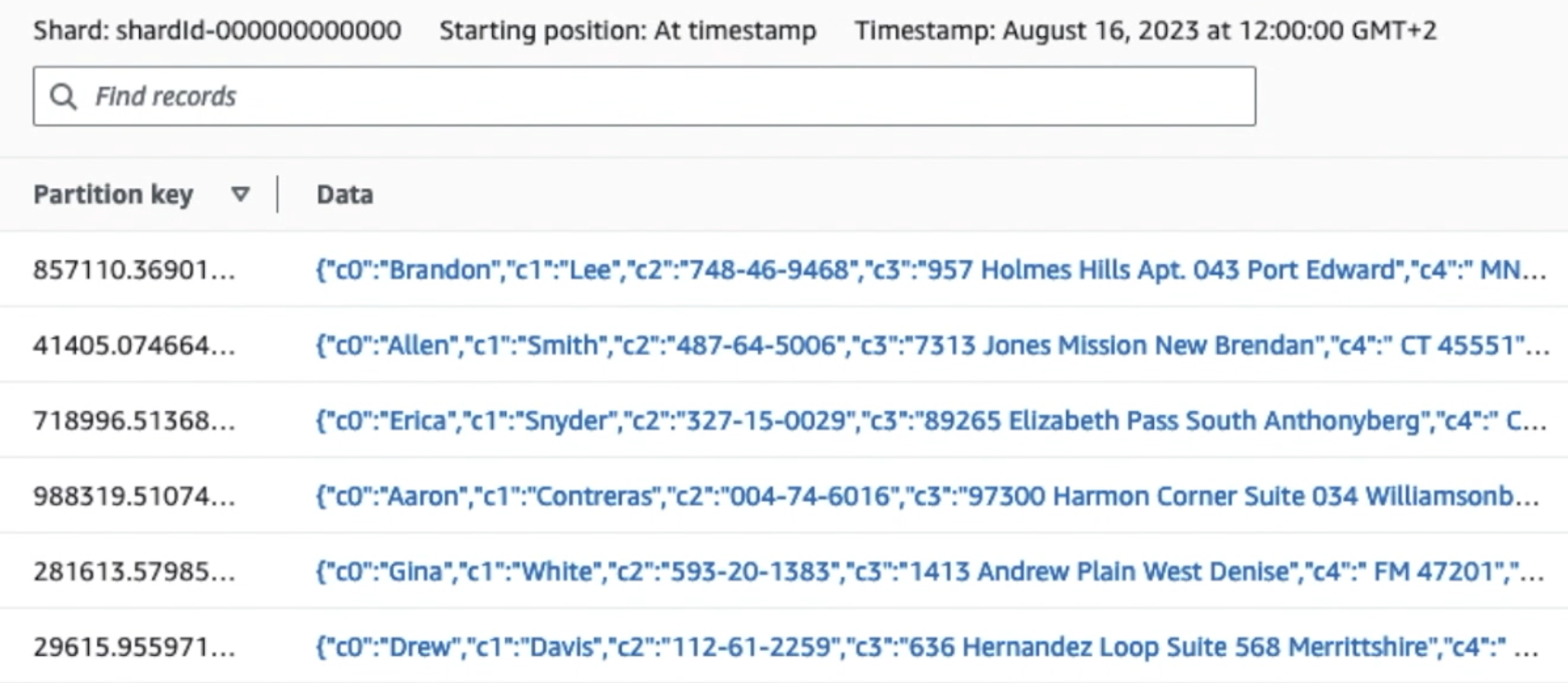
Як видно з деталей першого запису на наступному знімку екрана, корисне навантаження JSON відповідає тій же схемі, що й у попередньому розділі. Ви можете побачити невідредаговані дані, що надходять у потік даних Kinesis, який буде замасковано пізніше на наступних етапах.
Після того, як дані збираються та надходять у потоки даних Kinesis і доставляються до сегмента S3 за допомогою Kinesis Data Firehose, рівень обробки архітектури бере на себе роботу. Ми використовуємо перетворення AWS Glue PII для автоматизації виявлення та маскування конфіденційних даних у нашому конвеєрі. Як показано на наведеній нижче схемі робочого процесу, ми використали підхід без використання коду, візуальний ETL, щоб реалізувати наше завдання трансформації в AWS Glue Studio.
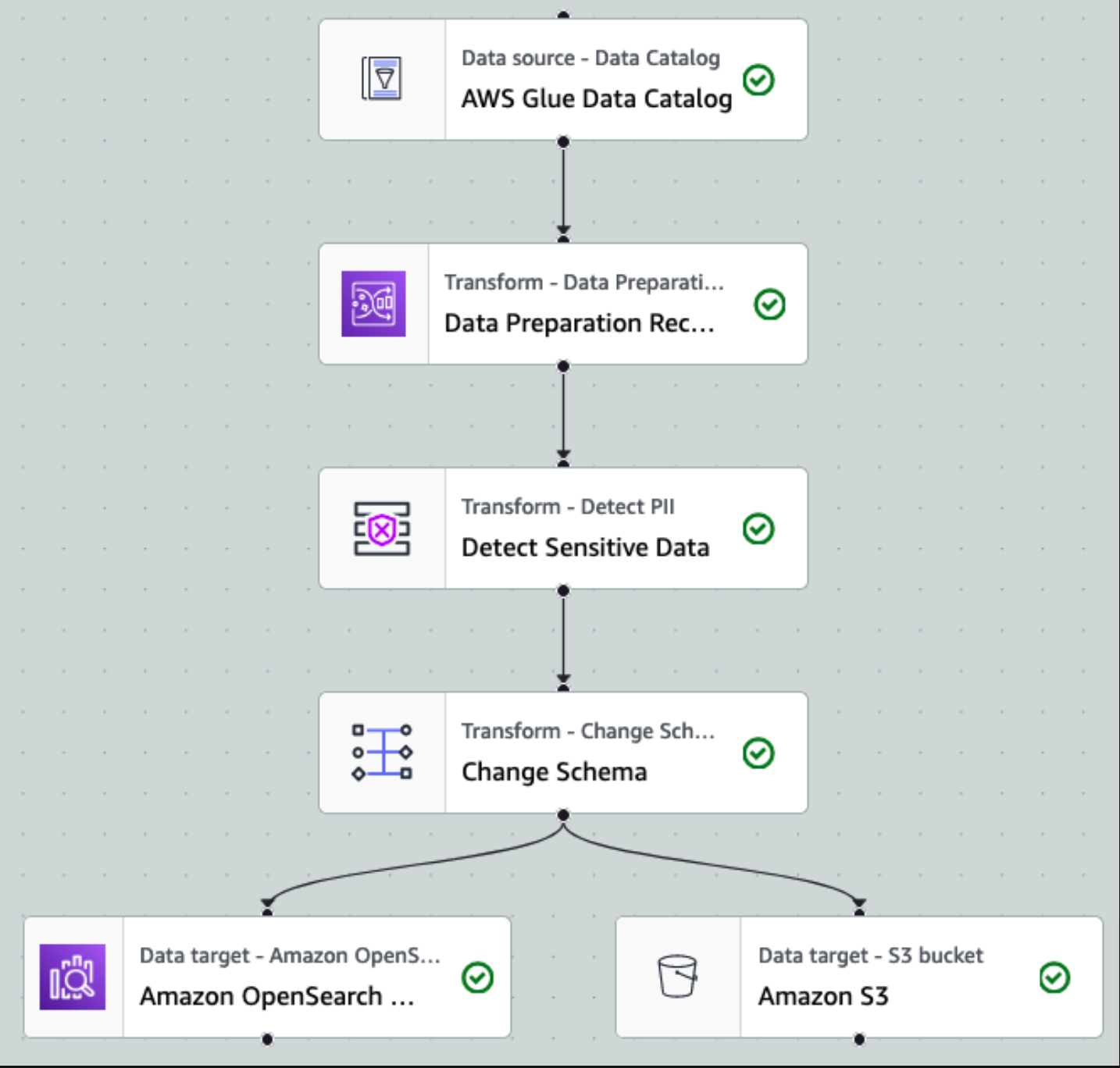
По-перше, ми отримуємо доступ до вихідної таблиці каталогу даних у необробленому вигляді з pii_data_db бази даних. Таблиця має структуру схеми, представлену в попередньому розділі. Щоб відстежувати необроблені оброблені дані, ми використовували закладки для роботи.

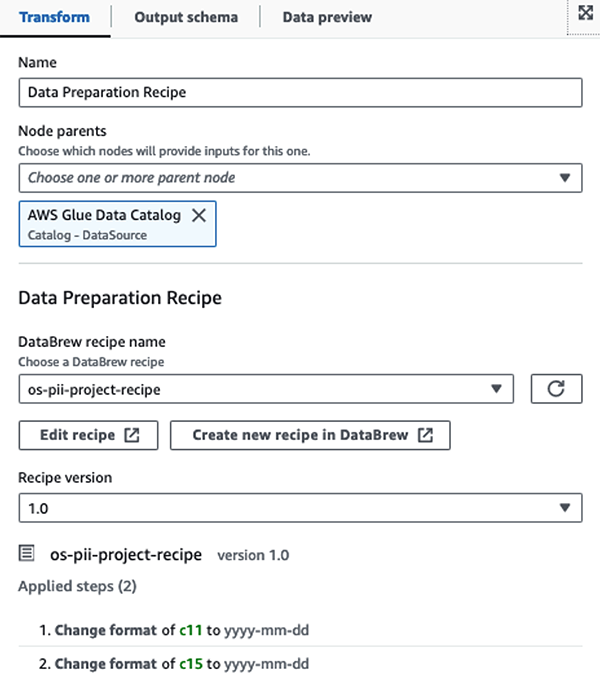
Ми використовуємо Рецепти AWS Glue DataBrew у візуальному ETL-завданні AWS Glue Studio щоб трансформувати два атрибути дати, щоб вони були сумісні з очікуваним OpenSearch Формати. Це дозволяє нам мати повний досвід без використання коду.
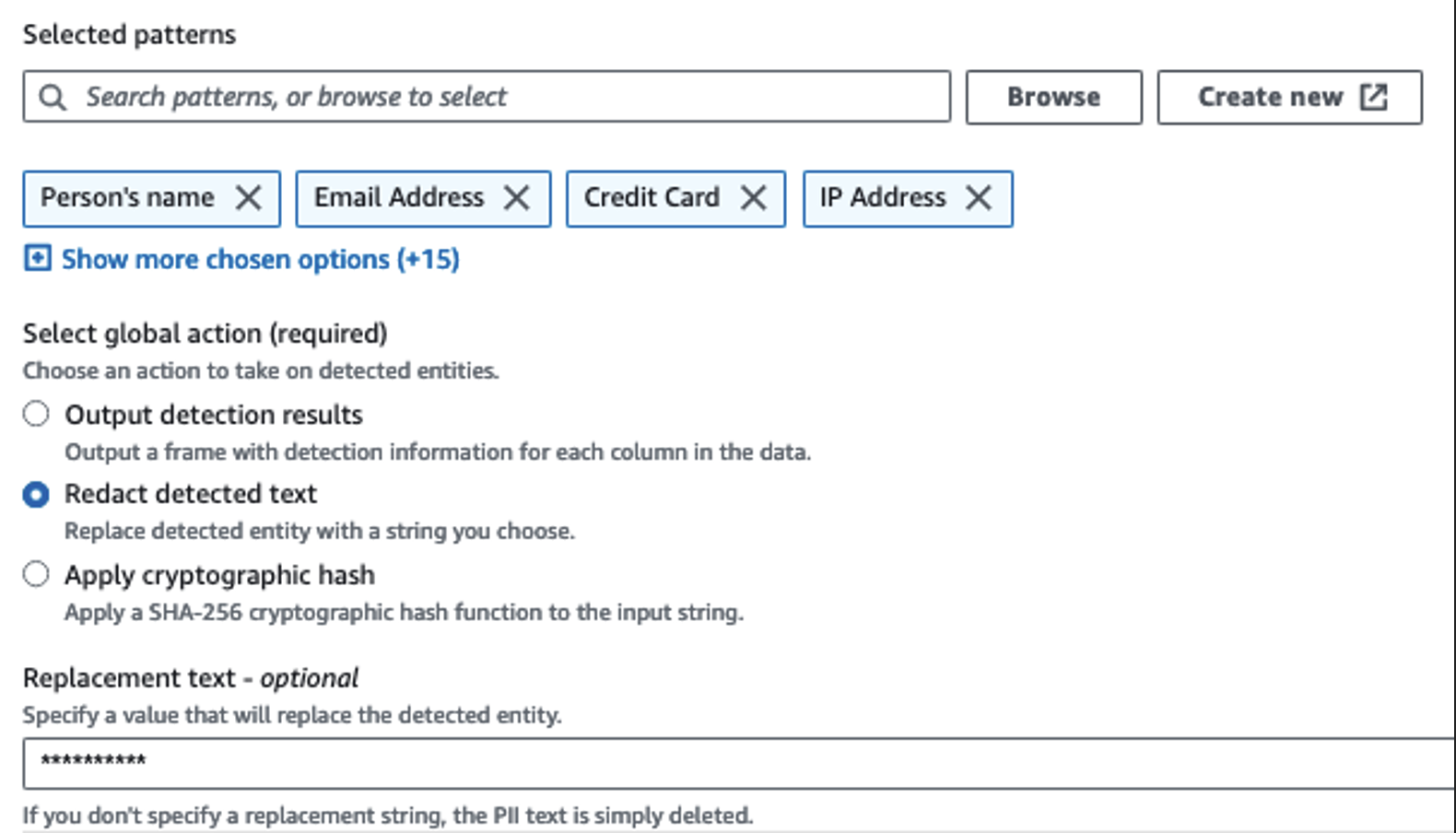
Ми використовуємо дію «Виявлення ідентифікаційної інформації», щоб ідентифікувати конфіденційні стовпці. Ми дозволяємо AWS Glue визначити це на основі вибраних шаблонів, порогу виявлення та зразкової частини рядків із набору даних. У нашому прикладі ми використали шаблони, які застосовуються саме до Сполучених Штатів (наприклад, номери соціального страхування) і можуть не виявляти конфіденційні дані з інших країн. Ви можете шукати доступні категорії та місця, застосовні до вашого випадку використання, або використовувати регулярні вирази (регулярні вирази) в AWS Glue для створення об’єктів виявлення для конфіденційних даних з інших країн.
Важливо вибрати правильний метод відбору проб, який пропонує AWS Glue. У цьому прикладі відомо, що дані, які надходять із потоку, містять конфіденційні дані в кожному рядку, тому немає необхідності відбирати 100% рядків у наборі даних. Якщо у вас є вимога, згідно з якою конфіденційні дані не можуть надходити до вихідних джерел, подумайте про вибірку 100% даних для вибраних вами шаблонів або відскануйте весь набір даних і виконайте дії з кожною окремою клітинкою, щоб переконатися, що всі конфіденційні дані виявлено. Перевагою, яку ви отримуєте від вибірки, є зниження витрат, оскільки вам не потрібно сканувати стільки даних.

Дія «Виявлення ідентифікаційної інформації» дозволяє вибрати рядок за умовчанням під час маскування конфіденційних даних. У нашому прикладі ми використовуємо рядок **********.
Ми використовуємо операцію застосування відображення, щоб перейменувати та видалити непотрібні стовпці, наприклад ingestion_year, ingestion_month та ingestion_day. Цей крок також дозволяє нам змінити тип даних одного зі стовпців (purchase_value) від рядка до цілого.

З цього моменту завдання розділяється на два вихідних місця призначення: OpenSearch Service і Amazon S3.
Наш наданий кластер OpenSearch Service підключено через Вбудований конектор OpenSearch для Glue. Ми вказуємо індекс OpenSearch, у який ми хочемо писати, а конектор обробляє облікові дані, домен і порт. На знімку екрана нижче ми записуємо вказаний індекс index_os_pii.
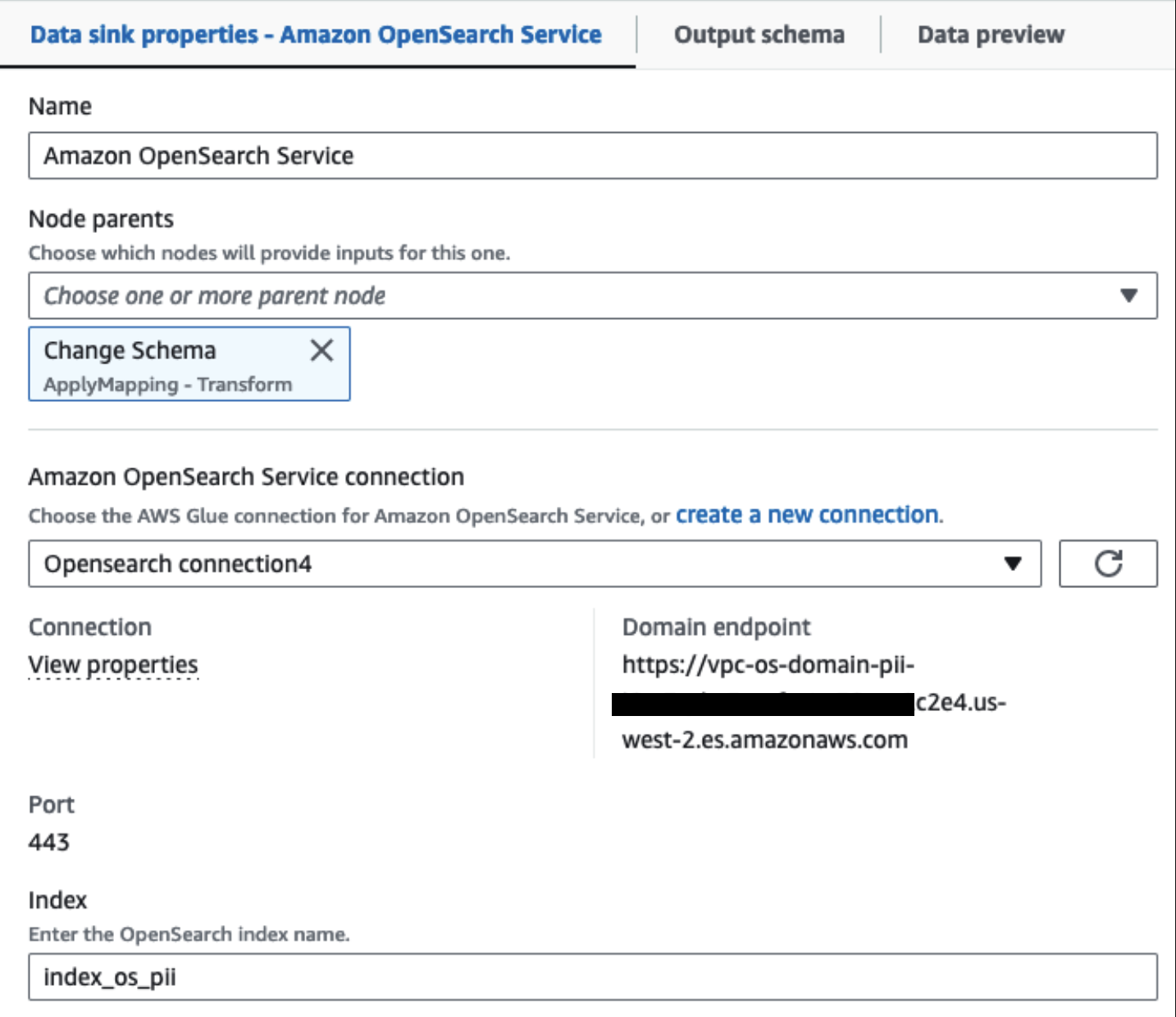
Ми зберігаємо замаскований набір даних у спеціальному префіксі S3. Там ми маємо дані, нормалізовані для конкретного випадку використання та безпечного використання спеціалістами з обробки даних або для спеціальних потреб звітності.
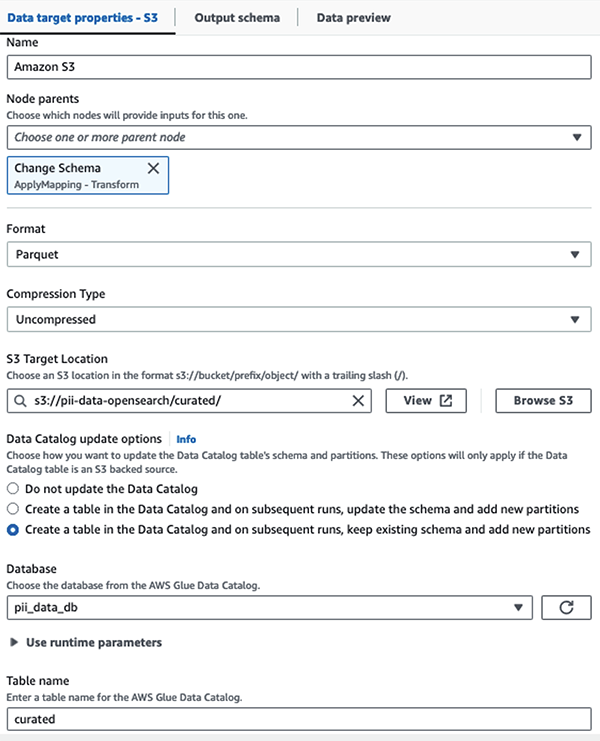
Для уніфікованого управління, контролю доступу та журналів аудиту всіх наборів даних і таблиць каталогу даних можна використовувати Формування озера AWS. Це допоможе вам обмежити доступ до таблиць AWS Glue Data Catalog і базових даних лише тим користувачам і ролям, яким надано необхідні для цього дозволи.
Після успішного виконання пакетного завдання ви можете використовувати службу OpenSearch для запуску пошукових запитів або звітів. Як показано на наступному знімку екрана, конвеєр автоматично маскує конфіденційні поля без жодних зусиль щодо розробки коду.

Ви можете визначити тенденції за оперативними даними, як-от кількість транзакцій за день, відфільтрованих постачальником кредитної картки, як показано на попередньому знімку екрана. Ви також можете визначити місця та домени, де користувачі роблять покупки. The transaction_date допомагає нам побачити ці тенденції з часом. На наступному знімку екрана показано запис із усією інформацією про транзакцію, відредагованою належним чином.
Альтернативні методи завантаження даних в Amazon OpenSearch див Завантаження потокових даних у Amazon OpenSearch Service.
Крім того, конфіденційні дані також можна виявити та замаскувати за допомогою інших рішень AWS. Наприклад, ви можете використовувати Амазонка Мейсі щоб виявити конфіденційні дані всередині сегмента S3, а потім використовувати «Амазонка» редагувати конфіденційні дані, які були виявлені. Для отримання додаткової інформації див Загальні методи виявлення даних PHI та PII за допомогою служб AWS.
Висновок
У цьому дописі обговорювалося важливість обробки конфіденційних даних у вашому середовищі та різних методів і архітектур, щоб залишатися сумісними, а також дозволяти вашій організації швидко масштабуватися. Тепер ви повинні добре розуміти, як виявляти, маскувати або редагувати та завантажувати ваші дані в Amazon OpenSearch Service.
Про авторів
 Майкл Гамільтон є старшим архітектором аналітичних рішень, який зосереджується на допомозі корпоративним клієнтам модернізувати та спростити свої аналітичні навантаження на AWS. Він любить кататися на гірських велосипедах і проводити час з дружиною та трьома дітьми, коли не працює.
Майкл Гамільтон є старшим архітектором аналітичних рішень, який зосереджується на допомозі корпоративним клієнтам модернізувати та спростити свої аналітичні навантаження на AWS. Він любить кататися на гірських велосипедах і проводити час з дружиною та трьома дітьми, коли не працює.
 Даніель Розо є старшим архітектором рішень у AWS, який підтримує клієнтів у Нідерландах. Його пристрасть — розробляти прості рішення для обробки даних і аналітики та допомагати клієнтам переходити на сучасні архітектури даних. Поза роботою він любить грати в теніс і їздити на велосипеді.
Даніель Розо є старшим архітектором рішень у AWS, який підтримує клієнтів у Нідерландах. Його пристрасть — розробляти прості рішення для обробки даних і аналітики та допомагати клієнтам переходити на сучасні архітектури даних. Поза роботою він любить грати в теніс і їздити на велосипеді.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- : має
- :є
- : ні
- :де
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- здатність
- Здатний
- прискорений
- доступ
- Діяти
- дію
- Ad
- адреса
- Агент
- ВСІ
- дозволено
- Дозволити
- дозволяє
- Також
- завжди
- Amazon
- Амазонський кінезіс
- Amazon Web Services
- Веб-служби Amazon (AWS)
- кількість
- суми
- an
- Аналітичний
- аналітика
- та
- будь-який
- застосовно
- застосування
- Застосовувати
- підхід
- відповідним чином
- архітектура
- ЕСТЬ
- AS
- At
- Атрибути
- аудит
- автоматизувати
- автоматично
- наявність
- доступний
- AWS
- Клей AWS
- резервне копіювання
- Banking
- Банківські системи
- заснований
- BE
- оскільки
- було
- перед тим
- буття
- нижче
- користь
- приносити
- будувати
- побудований
- вбудований
- але
- by
- CAN
- можливості
- потужність
- захоплення
- карта
- випадок
- випадків
- каталог
- категорії
- CDC
- осередок
- зміна
- Зміни
- канали
- діти
- вибрав
- ясність
- хмара
- кластер
- код
- Колонка
- Колони
- Приходити
- приходить
- майбутній
- сумісний
- поступливий
- Компоненти
- У складі
- обчислення
- Турбота
- підключений
- Вважати
- вважається
- спожитий
- споживання
- містити
- контекст
- продовжувати
- контроль
- виправити
- витрати
- може
- країни
- створювати
- Повноваження
- кредит
- кредитна картка
- Куратор
- Поточний
- Клієнти
- дані
- Analytics даних
- інтеграція даних
- Озеро даних
- Платформа даних
- конфіденційність даних
- стратегія даних
- Database
- базами даних
- набори даних
- Дата
- день
- дефолт
- певний
- поставляється
- демонструвати
- демонструє
- розгорнути
- дизайн
- призначення
- напрямки
- деталі
- виявляти
- виявлено
- Виявлення
- Визначати
- розробка
- команди розробників
- різний
- безпосередньо
- відкрити
- відкритий
- обговорювалися
- do
- домен
- домени
- Не знаю
- кожен
- зусилля
- Машинобудування
- забезпечувати
- підприємство
- корпоративні клієнти
- Весь
- юридичні особи
- Навколишнє середовище
- Ефір (ETH)
- Навіть
- Події
- Кожен
- приклад
- Приклади
- очікуваний
- досвід
- вирази
- зовнішній
- ШВИДКО
- Поля
- філе
- Файли
- фінансовий
- фінансові послуги
- Перший
- Тече
- Потоки
- фокусування
- потім
- після
- слідує
- для
- Рамки
- від
- Повний
- повністю
- майбутнє
- породжує
- отримати
- добре
- управління
- надається
- Ручки
- Обробка
- Мати
- he
- здоров'я
- інформація про стан здоров'я
- допомога
- допомогу
- допомагає
- на вищому рівні
- його
- історичний
- Як
- How To
- HTML
- HTTP
- HTTPS
- Сотні
- ідентифікувати
- if
- ілюструє
- картина
- здійснювати
- значення
- важливо
- in
- включати
- У тому числі
- індекс
- індивідуальний
- інформація
- Інфраструктура
- всередині
- інтеграція
- внутрішній
- в
- IT
- Java
- робота
- Джобс
- JPG
- json
- тримати
- Kinesis Data Firehose
- Потоки даних Kinesis
- відомий
- озеро
- земля
- Землі
- великий
- останній
- пізніше
- Законодавство
- Закони та правила
- шар
- шарів
- Керівництво
- дозволяти
- бібліотека
- Життєвий цикл
- як
- Лінія
- загрузка
- погрузка
- місць
- подивитися
- недорогий
- головний
- збереження
- зробити
- вдалося
- багато
- відображення
- маска
- Може..
- метод
- методика
- мігрувати
- міграція
- сучасний
- модернізувати
- моніторинг
- більше
- Гора
- рухатися
- переміщення
- багато
- множинний
- повинен
- ім'я
- Імена
- необхідно
- Необхідність
- необхідний
- нужденних
- потреби
- Нідерланди
- Нові
- немає
- вузли
- Зверніть увагу..
- зараз
- номер
- of
- Пропозиції
- on
- ONE
- тільки
- операція
- оперативний
- операції
- оптимізуючий
- Опції
- or
- організація
- організації
- Інше
- наші
- вихід
- поза
- над
- частина
- пристрасть
- Виправлення
- моделі
- Платити
- оплата
- для
- виконувати
- продуктивність
- Дозволи
- Особисто
- телефон
- пій
- трубопровід
- план
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- точка
- частина
- пошта
- попередній
- представлений
- попередній
- недоторканність приватного життя
- закони про конфіденційність
- оброблена
- процеси
- обробка
- виробник
- захищений
- протоколи
- Постачальник
- забезпечує
- Купівля
- запити
- швидко
- швидше
- Сировина
- необроблені дані
- реального часу
- Причини
- отримання
- Рецепти
- рекомендований
- запис
- облік
- Знижений
- послатися
- регулярний
- правила
- надійність
- залишатися
- видаляти
- Звітність
- Звіти
- вимагати
- вимога
- Вимога
- обов'язки
- відповідальний
- обмежити
- результати
- ролі
- ROW
- прогін
- пробіжки
- SaaS
- жертвуючи
- сейф
- безпечно
- то ж
- шкала
- сканування
- розклад
- Вчені
- Екран
- Sdk
- Пошук
- розділ
- безпечно
- безпеку
- побачити
- вибрати
- обраний
- старший
- чутливий
- посланий
- обслуговування
- Послуги
- постріл
- Повинен
- показаний
- Шоу
- простий
- спростити
- невеликий
- So
- соціальна
- Софтвер
- програмне забезпечення як послуга
- рішення
- Рішення
- Source
- Джерела
- конкретний
- конкретно
- зазначений
- витрачати
- Витрати
- Розколи
- етапи
- Штати
- Крок
- зберігання
- зберігати
- просто
- Стратегія
- потік
- потоковий
- потоки
- рядок
- структура
- структурований
- студія
- наступні
- Успішно
- такі
- підходящий
- Підтриманий
- Підтримуючий
- система
- Systems
- таблиця
- приймає
- Мета
- команда
- команди
- методи
- теніс
- тензор
- ніж
- Що
- Команда
- Майбутнє
- Нідерланди
- Джерело
- їх
- потім
- Там.
- Ці
- це
- ті
- три
- поріг
- через
- час
- до
- прийняли
- інструменти
- трек
- Transactions
- переклад
- переклади
- Перетворення
- Перетворення
- Тенденції
- спрацьовує
- два
- тип
- Типи
- Зрештою
- що лежить в основі
- розуміння
- єдиний
- United
- Сполучені Штати
- us
- використання
- використання випадку
- використовуваний
- користувачі
- використання
- значення
- різноманітність
- різний
- через
- візуальний
- ходити
- було
- способи
- we
- Web
- веб-сервіси
- Що
- коли
- який
- в той час як
- ВООЗ
- дружина
- волі
- з
- в
- без
- Work
- робочий
- робочий
- запис
- ви
- вашу
- зефірнет