Із запуском функції нейронного пошуку для Служба Amazon OpenSearch у OpenSearch 2.9 тепер легко можна інтегрувати з моделями штучного інтелекту/ML для забезпечення семантичного пошуку та інших випадків використання. Служба OpenSearch підтримує як лексичний, так і векторний пошук із моменту появи функції k-найближчого сусіда (k-NN) у 2020 році; однак налаштування семантичного пошуку вимагало створення структури для інтеграції моделей машинного навчання (ML) для прийому та пошуку. Функція нейронного пошуку полегшує перетворення тексту у вектор під час прийому та пошуку. Коли ви використовуєте нейронний запит під час пошуку, запит перетворюється на векторне вбудовування, а k-NN використовується для повернення найближчих векторних вбудовувань із корпусу.
Щоб використовувати нейронний пошук, необхідно налаштувати модель ML. Ми рекомендуємо налаштувати роз’єми AI/ML для служб AI та ML AWS (наприклад, Amazon SageMaker or Amazon Bedrock) або сторонніх альтернатив. Починаючи з версії 2.9 у службі OpenSearch Service, конектори AI/ML інтегруються з нейронним пошуком, щоб спростити й упровадити переклад вашого корпусу даних і запитів у векторні вбудовування, тим самим усуваючи значну частину складності векторної гідратації та пошуку.
У цій публікації ми демонструємо, як налаштувати конектори AI/ML для зовнішніх моделей через консоль OpenSearch Service.
Огляд рішення
Зокрема, ця публікація допоможе вам підключитися до моделі в SageMaker. Потім ми проведемо вас через використання конектора для налаштування семантичного пошуку в OpenSearch Service як приклад варіанту використання, який підтримується через підключення до моделі ML. Інтеграції Amazon Bedrock і SageMaker наразі підтримуються в інтерфейсі консолі OpenSearch Service, і список інтеграцій першої та сторонньої сторони, підтримуваних інтерфейсом користувача, продовжуватиме зростати.
Для будь-яких моделей, які не підтримуються інтерфейсом користувача, ви можете замість цього налаштувати їх за допомогою доступних API та ML креслення. Для отримання додаткової інформації див Вступ до моделей OpenSearch. Ви можете знайти креслення для кожного роз’єму в Репозиторій ML Commons GitHub.
Передумови
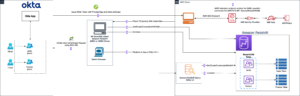
Перед підключенням моделі через консоль OpenSearch Service створіть домен OpenSearch Service. Карта ан Управління ідентифікацією та доступом AWS (IAM) роль за назвою LambdaInvokeOpenSearchMLCommonsRole як серверну роль на ml_full_access роль за допомогою плагіна безпеки на інформаційних панелях OpenSearch, як показано в наступному відео. Робочий процес інтеграції OpenSearch Service попередньо заповнено для використання LambdaInvokeOpenSearchMLCommonsRole Роль IAM за замовчуванням для створення з’єднувача між доменом OpenSearch Service і моделлю, розгорнутою на SageMaker. Якщо ви використовуєте настроювану роль IAM в інтеграції консолі OpenSearch Service, переконайтеся, що настроювана роль зіставлена як роль серверної частини за допомогою ml_full_access дозволи перед розгортанням шаблону.
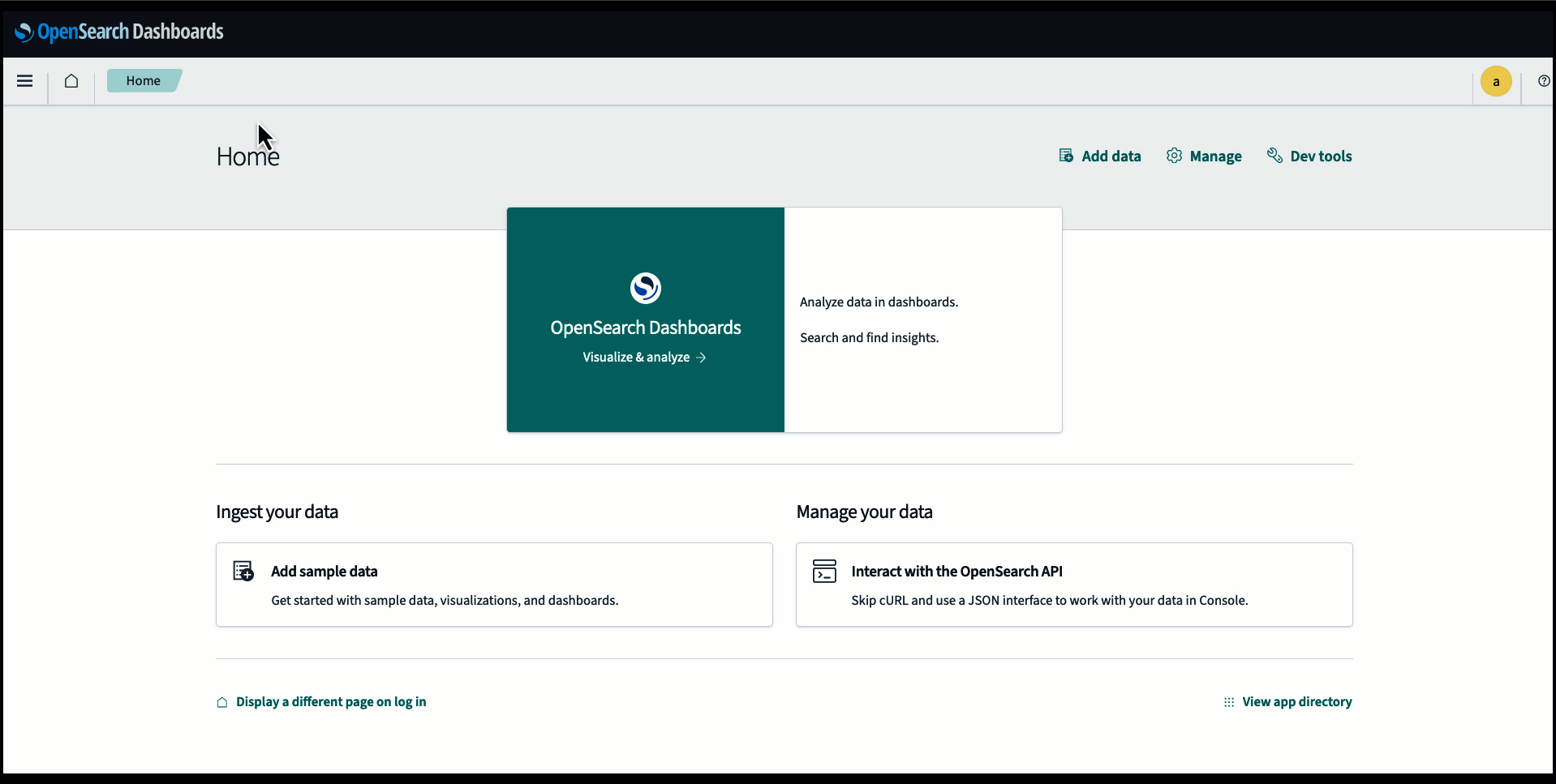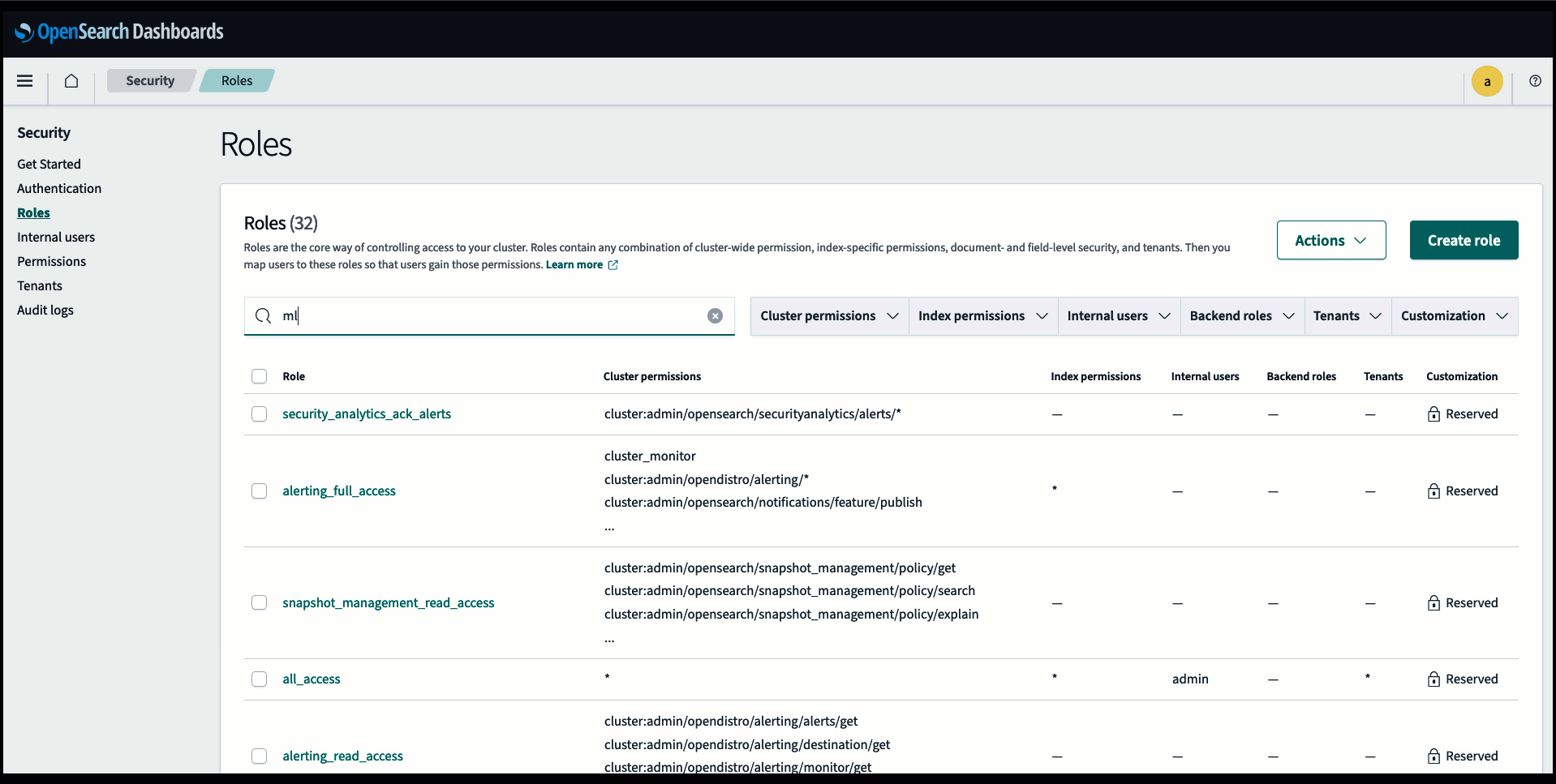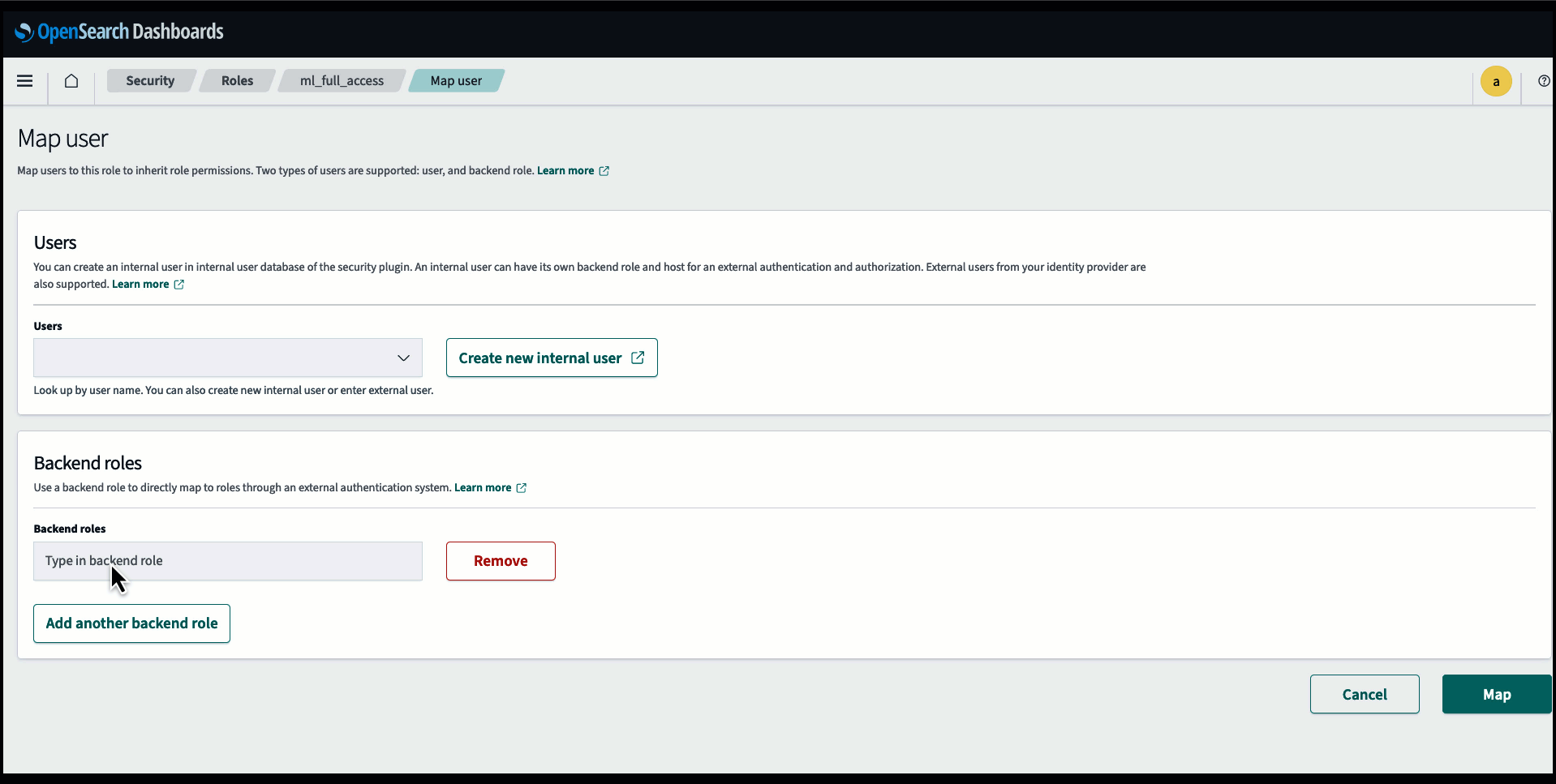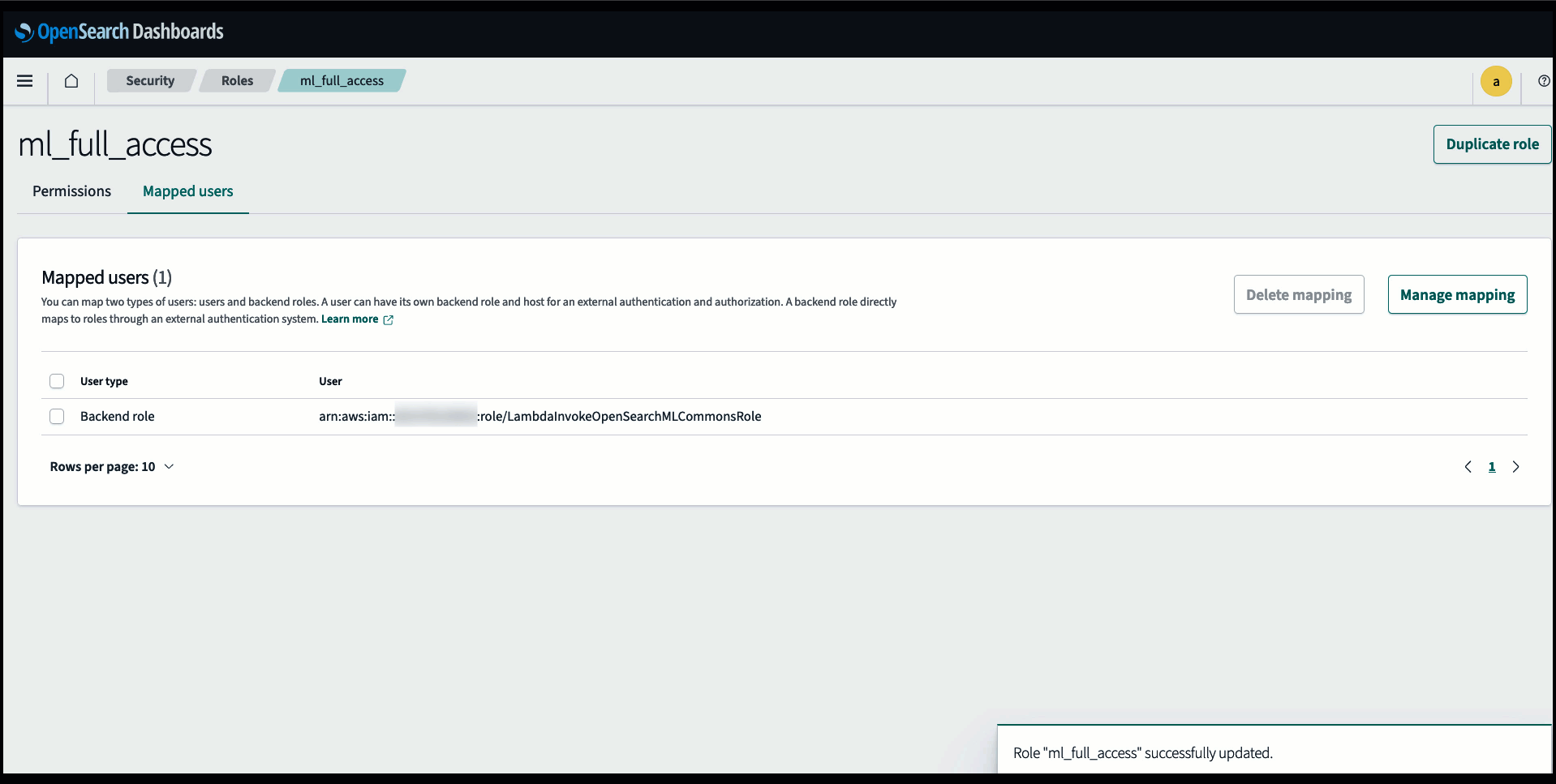
Розгорніть модель за допомогою AWS CloudFormation
У наступному відео демонструються дії за допомогою консолі OpenSearch Service для розгортання моделі за лічені хвилини на Amazon SageMaker і генерації ідентифікатора моделі за допомогою роз’ємів AI. Перший крок – вибрати Інтеграції на панелі навігації на консолі OpenSearch Service AWS, яка спрямовує до списку доступних інтеграцій. Інтеграція налаштована через інтерфейс користувача, який запропонує вам ввести необхідні дані.
Щоб налаштувати інтеграцію, вам потрібно лише надати кінцеву точку домену OpenSearch Service і надати назву моделі для унікальної ідентифікації підключення моделі. За замовчуванням шаблон розгортає модель трансформації речень Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Коли ви обираєте Створити стек, ви перенаправлені на AWS CloudFormation консоль. Шаблон CloudFormation розгортає архітектуру, деталізовану на наступній діаграмі.

Стек CloudFormation створює AWS Lambda програма, яка розгортає модель з Служба простого зберігання Amazon (Amazon S3), створює з’єднувач і генерує ідентифікатор моделі на виході. Потім ви можете використовувати цей ідентифікатор моделі для створення семантичного індексу.
Якщо модель All-MiniLM-L6-v2 за замовчуванням не підходить для вашої мети, ви можете розгорнути будь-яку модель вбудованого тексту за вашим вибором на вибраному хості моделі (SageMaker або Amazon Bedrock), надавши свої артефакти моделі як доступний об’єкт S3. Крім того, ви можете вибрати один із наведених нижче варіантів попередньо підготовлені мовні моделі і розгорніть його в SageMaker. Інструкції щодо налаштування кінцевої точки та моделей див Доступні зображення Amazon SageMaker.
SageMaker — це повністю керована служба, яка об’єднує широкий набір інструментів для забезпечення високопродуктивного та недорогого машинного навчання для будь-яких випадків використання, забезпечуючи ключові переваги, такі як моніторинг моделі, безсерверний хостинг і автоматизація робочого процесу для постійного навчання та розгортання. SageMaker дозволяє розміщувати та керувати життєвим циклом моделей вбудовування тексту, а також використовувати їх для забезпечення семантичних пошукових запитів у OpenSearch Service. Після підключення SageMaker розміщує ваші моделі, а служба OpenSearch використовується для запитів на основі результатів висновків від SageMaker.
Перегляньте розгорнуту модель через інформаційні панелі OpenSearch
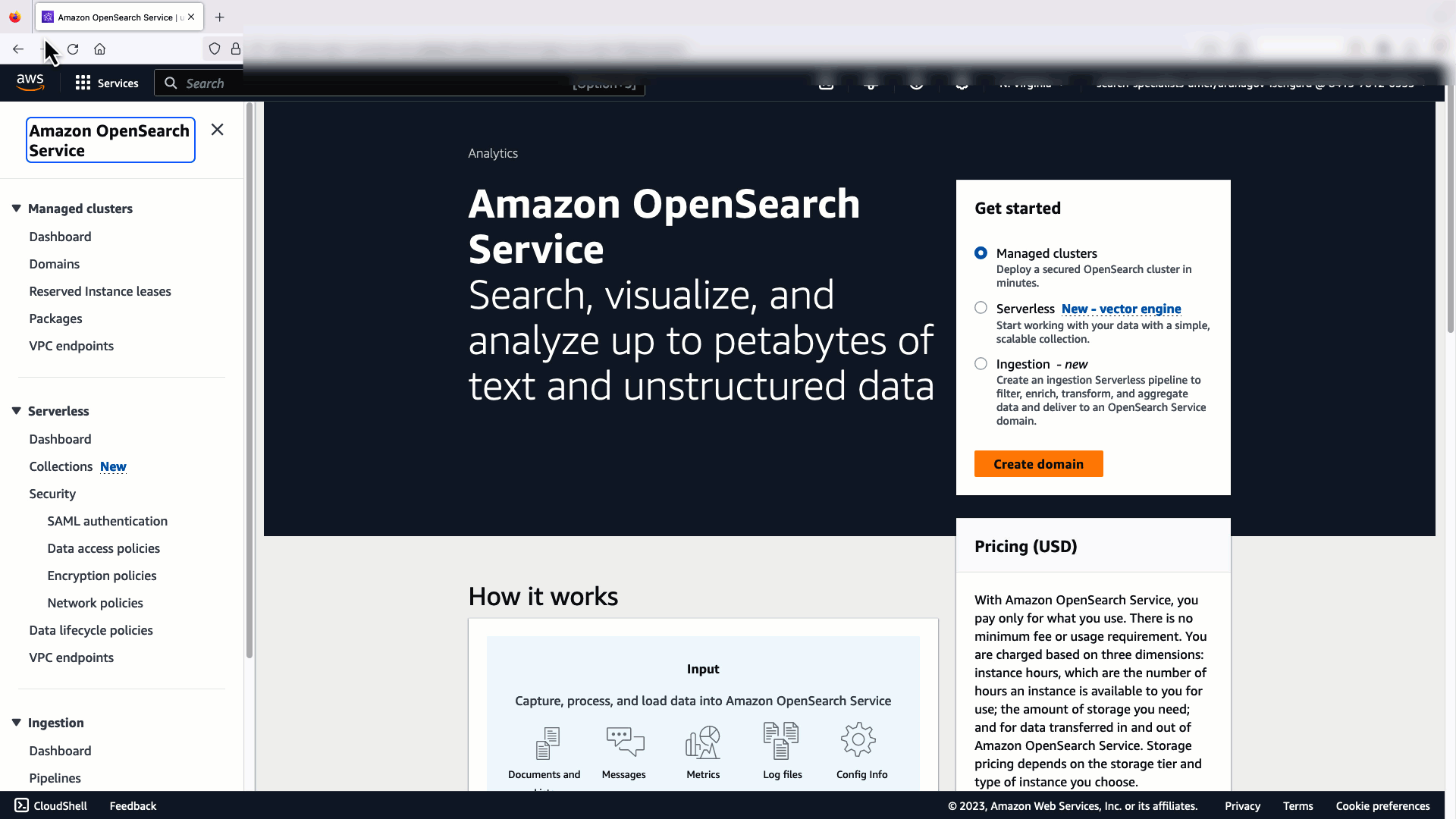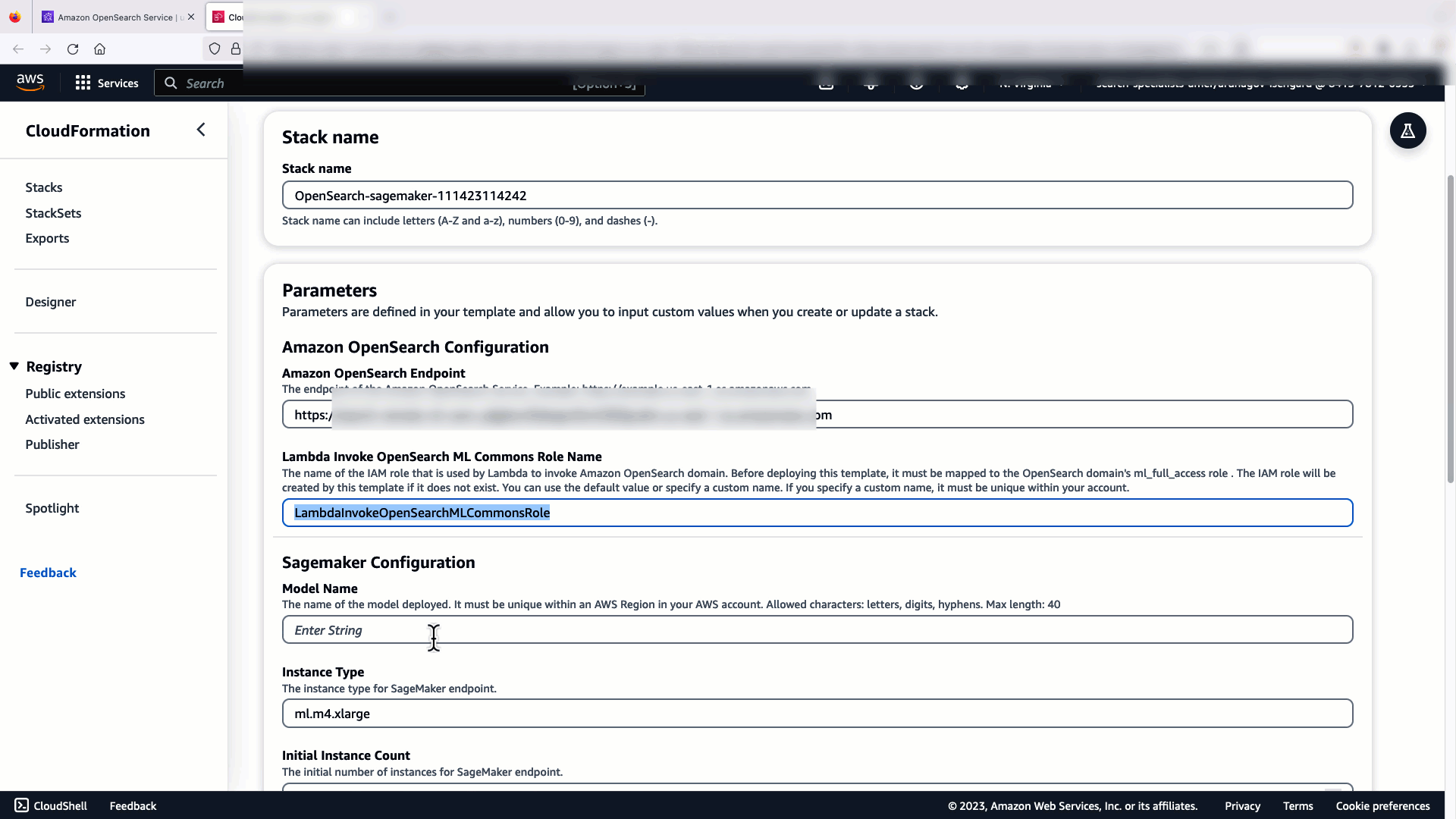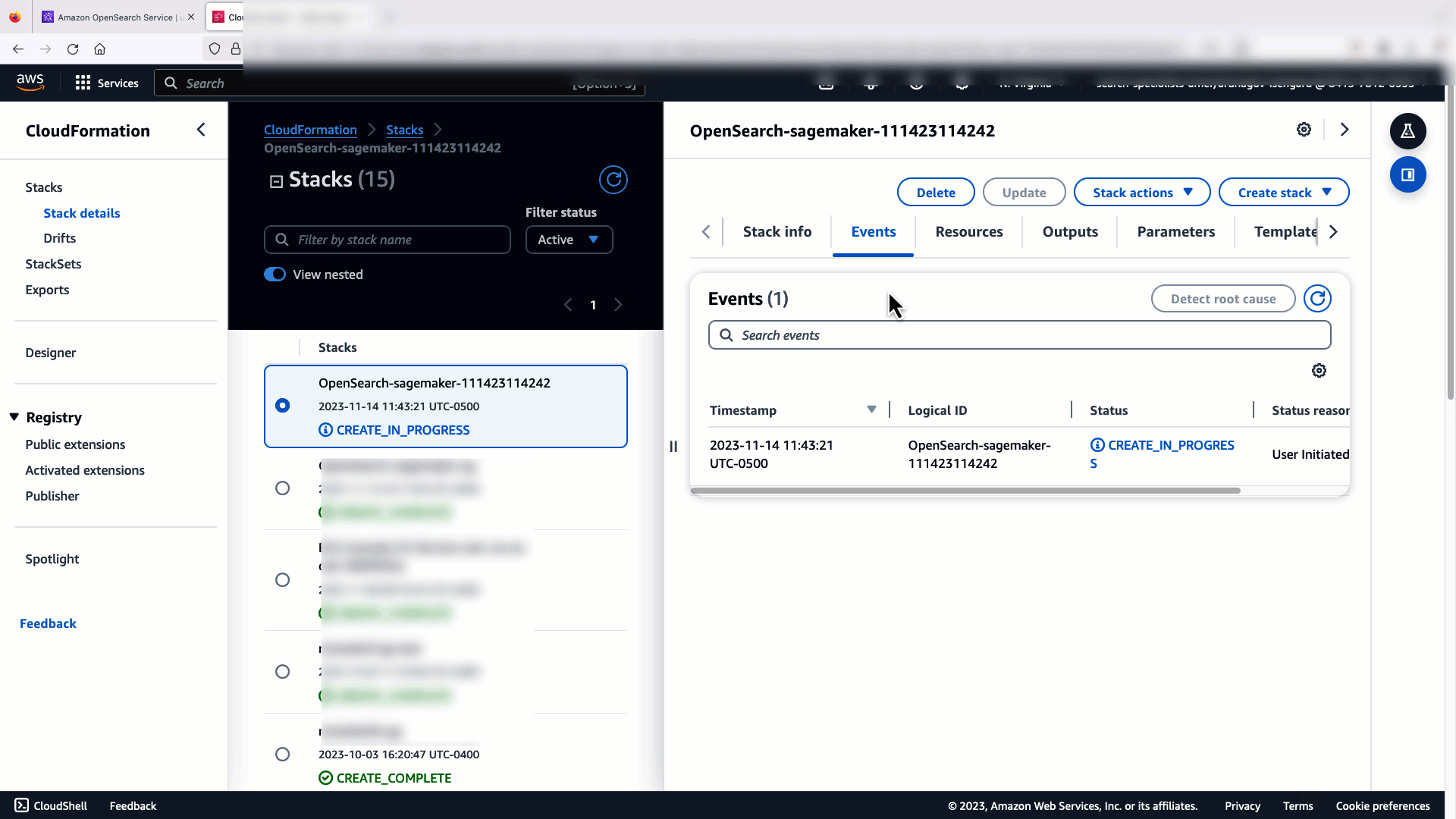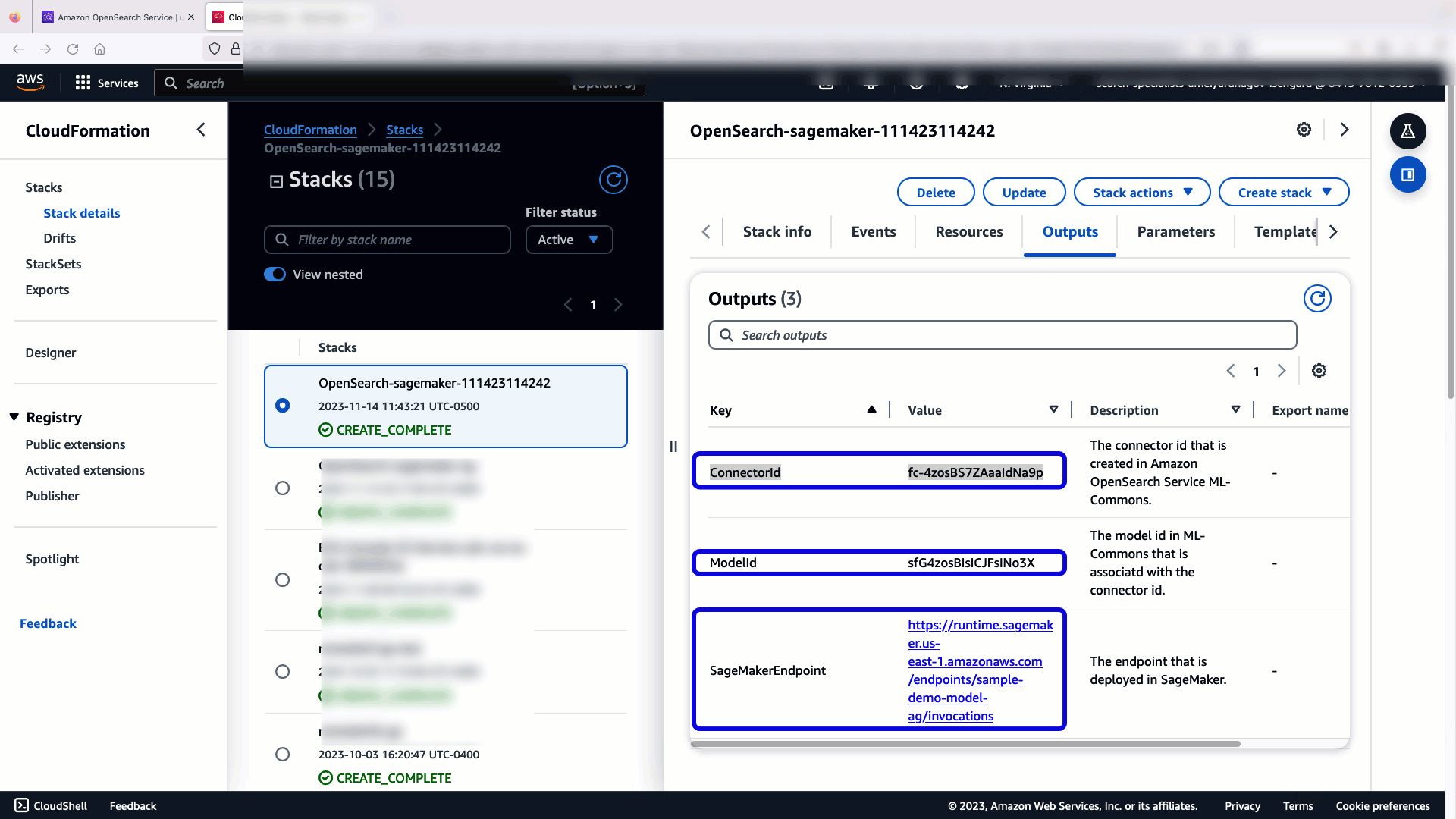
Щоб переконатися, що шаблон CloudFormation успішно розгорнув модель у домені OpenSearch Service, і отримати ідентифікатор моделі, ви можете скористатися ML Commons REST GET API через інструменти розробника OpenSearch Dashboards.
GET _plugins REST API тепер надає додаткові API для перегляду стану моделі. Наступна команда дозволяє побачити статус віддаленої моделі:
Як показано на наступному знімку екрана, a DEPLOYED Статус у відповіді вказує на те, що модель успішно розгорнуто в кластері OpenSearch Service.

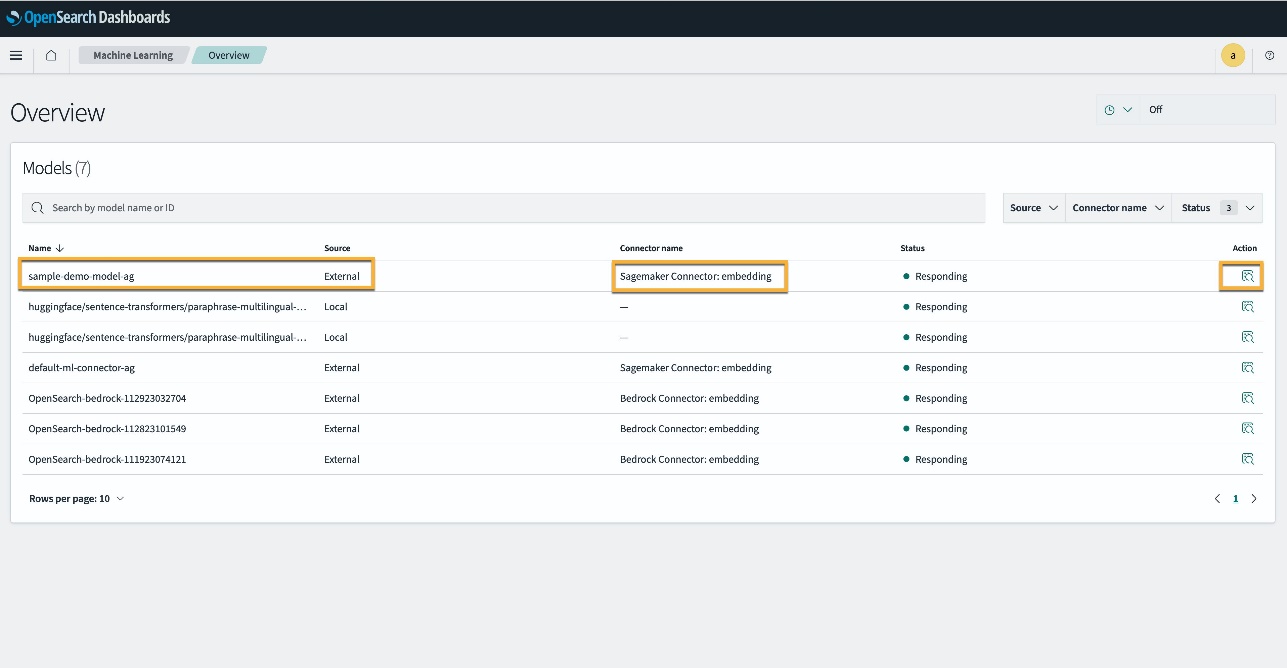
Крім того, ви можете переглянути модель, розгорнуту у вашому домені OpenSearch Service, за допомогою машинне навчання сторінки інструментальних панелей OpenSearch.

На цій сторінці наведено інформацію про моделі та статуси всіх розгорнутих моделей.

Створіть нейронний конвеєр, використовуючи ідентифікатор моделі
Коли статус моделі відображається як або DEPLOYED в Dev Tools або зелений і Відповідаючи на інформаційних панелях OpenSearch ви можете використовувати ідентифікатор моделі, щоб створити свій нейронний конвеєр. У інструментах розробника OpenSearch Dashboards у вашому домені запускається наступний конвеєр. Переконайтеся, що ви замінили ідентифікатор моделі на унікальний ідентифікатор, створений для моделі, розгорнутої у вашому домені.

Створіть індекс семантичного пошуку, використовуючи нейронний конвеєр як конвеєр за замовчуванням
Тепер ви можете визначити своє відображення індексу за допомогою конвеєра за замовчуванням, налаштованого на використання нового нейронного конвеєра, який ви створили на попередньому кроці. Переконайтеся, що векторні поля оголошено як knn_vector і розміри відповідають моделі, яка розгортається на SageMaker. Якщо ви зберегли конфігурацію за замовчуванням для розгортання моделі All-MiniLM-L6-v2 на SageMaker, збережіть наведені нижче налаштування як є та запустіть команду в Dev Tools.

Завантажте зразки документів для створення векторів
Для цієї демонстрації ви можете отримати зразок роздрібного каталогу продукції demostore до нового semantic_demostore індекс. Замініть ім’я користувача, пароль і кінцеву точку домену інформацією про свій домен і передайте необроблені дані в OpenSearch Service:

Перевірте новий індекс semantic_demostore
Тепер, коли ви ввели свій набір даних у домен OpenSearch Service, перевірте, чи згенеровано необхідні вектори за допомогою простого пошуку для отримання всіх полів. Перевірте, чи поля визначені як knn_vectors мають потрібні вектори.

Порівняйте лексичний і семантичний пошук за допомогою нейронного пошуку за допомогою інструмента порівняння результатів пошуку
Команда Інструмент порівняння результатів пошуку на інформаційних панелях OpenSearch доступний для виробничих робочих навантажень. Ви можете перейти до Порівняти результати пошуку і порівняйте результати запиту між лексичним і нейронним пошуком, налаштованим на використання ідентифікатора моделі, згенерованого раніше.

Прибирати
Ви можете видалити ресурси, які ви створили, дотримуючись інструкцій у цій публікації, видаливши стек CloudFormation. Це призведе до видалення ресурсів Lambda та сегмента S3, які містять модель, розгорнуту в SageMaker. Виконайте наступні дії:
- На консолі AWS CloudFormation перейдіть на сторінку деталей стека.
- Вибирати видаляти.

- Вибирати видаляти підтвердити.

Ви можете відстежувати хід видалення стеку на консолі AWS CloudFormation.
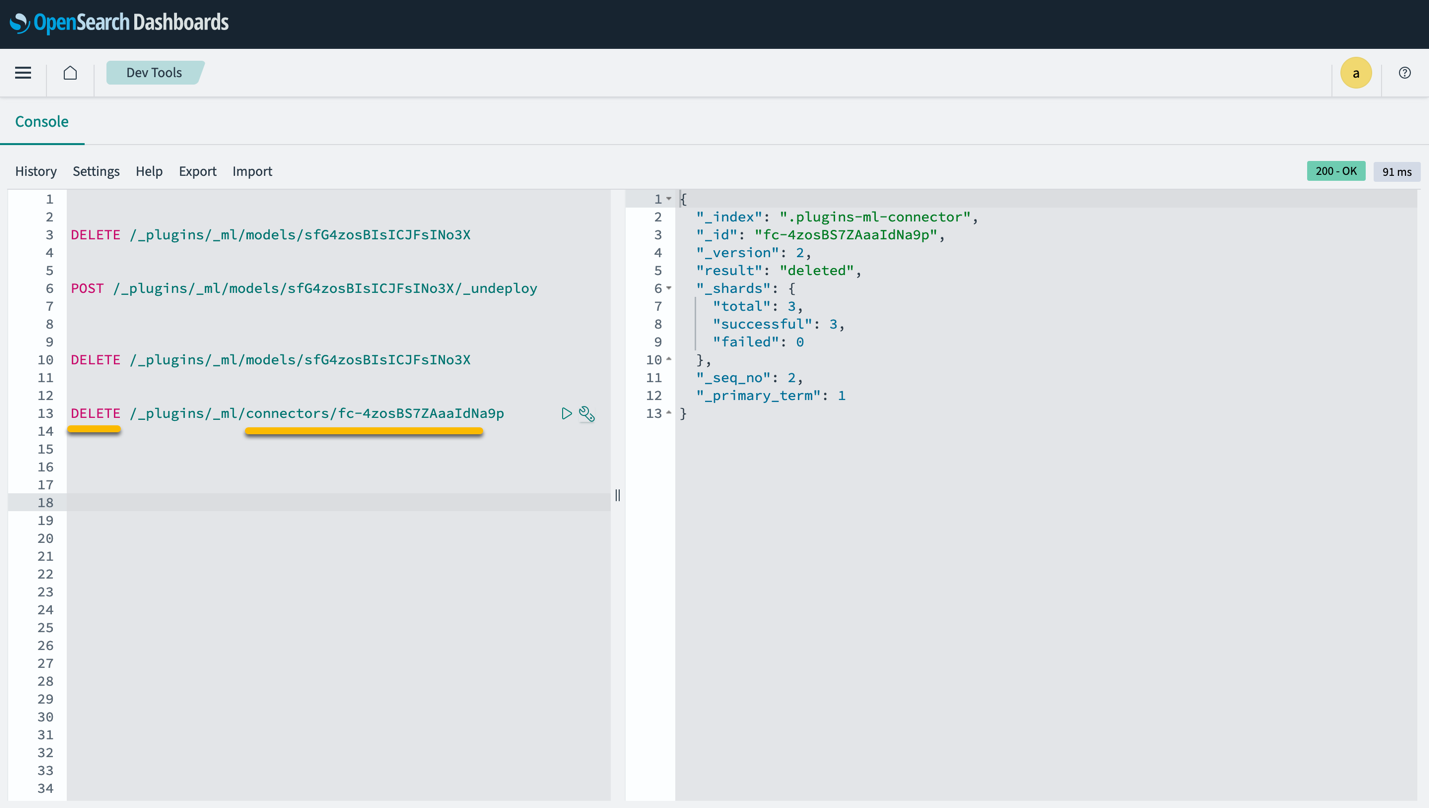
Зауважте, що видалення стека CloudFormation не видаляє модель, розгорнуту в домені SageMaker, і створений конектор AI/ML. Це пояснюється тим, що ці моделі та з’єднувач можуть бути пов’язані з кількома індексами в межах домену. Щоб конкретно видалити модель і пов’язаний з нею з’єднувач, використовуйте API моделі, як показано на наступних знімках екрана.
По-перше, undeploy модель із пам’яті домену OpenSearch Service:

Потім ви можете видалити модель з індексу моделей:

Нарешті, видаліть конектор з індексу конектора:
Висновок
У цій публікації ви дізналися, як розгорнути модель у SageMaker, створити конектор AI/ML за допомогою консолі OpenSearch Service і побудувати індекс нейронного пошуку. Можливість налаштовувати конектори AI/ML у OpenSearch Service спрощує процес гідратації вектора, роблячи інтеграцію із зовнішніми моделями рідною. Ви можете створити індекс нейронного пошуку за лічені хвилини, використовуючи конвеєр нейронного введення та нейронний пошук, які використовують ідентифікатор моделі для генерації вбудовування вектора на льоту під час введення та пошуку.
Щоб дізнатися більше про ці роз’єми AI/ML, див Конектори Amazon OpenSearch Service AI для сервісів AWS, Інтеграція шаблону AWS CloudFormation для семантичного пошуку та Створення конекторів для сторонніх платформ ML.
Про авторів
 Аруна Говіндараджу є спеціалістом з розробки рішень Amazon OpenSearch і працював із багатьма комерційними пошуковими системами та пошуковими системами з відкритим кодом. Вона захоплена пошуком, релевантністю та користувальницьким досвідом. Її досвід у співвіднесенні сигналів кінцевого користувача з поведінкою пошукової системи допоміг багатьом клієнтам покращити пошук.
Аруна Говіндараджу є спеціалістом з розробки рішень Amazon OpenSearch і працював із багатьма комерційними пошуковими системами та пошуковими системами з відкритим кодом. Вона захоплена пошуком, релевантністю та користувальницьким досвідом. Її досвід у співвіднесенні сигналів кінцевого користувача з поведінкою пошукової системи допоміг багатьом клієнтам покращити пошук.
 Дагні Браун є головним менеджером із продуктів в AWS, який займається OpenSearch.
Дагні Браун є головним менеджером із продуктів в AWS, який займається OpenSearch.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- : має
- :є
- : ні
- $UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- здатність
- МЕНЮ
- доступ
- доступною
- Додатковий
- AI
- AI / ML
- ВСІ
- дозволяє
- Також
- альтернативи
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- та
- будь-який
- API
- Інтерфейси
- додаток
- відповідний
- архітектура
- ЕСТЬ
- AS
- асоційований
- At
- Автоматизація
- доступний
- AWS
- AWS CloudFormation
- Backend
- заснований
- BE
- оскільки
- поведінка
- Переваги
- між
- обидва
- Приносить
- широкий
- будувати
- Створюємо
- by
- CAN
- випадок
- випадків
- каталог
- вибір
- Вибирати
- вибраний
- кластер
- комерційний
- Commons
- порівняти
- повний
- складність
- конфігурація
- налаштувати
- конфігурування
- підтвердити
- підключений
- З'єднувальний
- зв'язку
- Консоль
- містити
- продовжувати
- безперервний
- корелюючі
- створювати
- створений
- створює
- В даний час
- виготовлений на замовлення
- Клієнти
- інформаційні панелі
- дані
- дефолт
- визначати
- певний
- надання
- Демонстрація
- демонструвати
- демонструє
- розгортання
- розгорнути
- розгортання
- розгортання
- розгортає
- description
- докладно
- деталі
- DEV
- Розмір
- розміри
- документація
- Ні
- домен
- під час
- кожен
- Раніше
- без зусиль
- або
- вбудовування
- включіть
- Кінцева точка
- двигун
- Двигуни
- забезпечувати
- Ефір (ETH)
- приклад
- досвід
- експертиза
- зовнішній
- Face
- полегшує
- особливість
- Поля
- знайти
- Перший
- увагу
- після
- для
- Рамки
- від
- повністю
- породжувати
- генерується
- генерує
- отримати
- GIF
- GitHub
- зелений
- Рости
- керівництво
- Мати
- допоміг
- її
- висока продуктивність
- господар
- хостинг
- хостів
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- HuggingFace
- гідратація
- IAM
- ID
- ідентифікувати
- Особистість
- if
- удосконалювати
- in
- індекс
- покажчики
- вказує
- інформація
- витрати
- замість
- інструкції
- інтегрувати
- інтеграція
- інтеграцій
- в
- Вступ
- IT
- ЙОГО
- JPG
- json
- тримати
- ключ
- мова
- запуск
- УЧИТЬСЯ
- вчений
- вивчення
- Життєвий цикл
- список
- списки
- недорогий
- машина
- навчання за допомогою машини
- зробити
- Робить
- управляти
- вдалося
- менеджер
- багато
- карта
- відображення
- пам'ять
- метод
- протокол
- ML
- модель
- Моделі
- монітор
- моніторинг
- більше
- багато
- множинний
- повинен
- ім'я
- рідний
- Переміщення
- навігація
- необхідно
- Необхідність
- Нейронний
- Нові
- зараз
- об'єкт
- of
- on
- ONE
- тільки
- відкрити
- з відкритим вихідним кодом
- or
- Інше
- вихід
- сторінка
- pane
- пристрасний
- Пароль
- Дозволи
- трубопровід
- plato
- Інформація про дані Платона
- PlatoData
- підключати
- пошта
- влада
- Харчування
- попередній
- Головний
- попередній
- процес
- процесори
- Product
- менеджер по продукції
- Production
- прогрес
- властивості
- забезпечувати
- забезпечує
- забезпечення
- мета
- запити
- Сировина
- необроблені дані
- рекомендувати
- послатися
- віддалений
- видалення
- замінювати
- вимагається
- ресурси
- відповідь
- REST
- результати
- роздрібна торгівля
- зберігся
- повертати
- Роль
- маршрути
- прогін
- мудрець
- скріншоти
- Пошук
- Пошукова система
- Пошукові системи
- безпеку
- побачити
- вибрати
- служити
- Без сервера
- обслуговування
- Послуги
- комплект
- налаштування
- вона
- показаний
- Шоу
- сигнали
- простий
- спрощує
- спростити
- з
- Рішення
- Source
- спеціаліст
- конкретно
- стек
- Починаючи
- Статус
- Крок
- заходи
- зберігання
- Успішно
- такі
- Підтриманий
- Переконайтеся
- шаблон
- текст
- Що
- Команда
- їх
- Їх
- потім
- тим самим
- Ці
- третя сторона
- це
- через
- до
- разом
- інструменти
- Навчання
- Перетворення
- Переклад
- правда
- тип
- ui
- створеного
- однозначно
- використання
- використання випадку
- використовуваний
- користувач
- User Experience
- використання
- ПЕРЕВІР
- перевірити
- версія
- через
- Відео
- вид
- прогулянки
- було
- we
- Web
- веб-сервіси
- коли
- який
- волі
- з
- в
- працював
- робочий
- автоматизація робочого процесу
- ви
- вашу
- зефірнет