Дані – це рятівний круг усіх онлайн-бізнесів і спосіб, яким ми взаємодіємо.
Кожен день ми приблизно творимо 2.5 квінтильйони байт даних. Це багато. Але що дивує те 90% цих даних є неструктурованим.
Він не має якоїсь особливої структури. Отже, щоб зрозуміти дані, нам дійсно потрібно зрозуміти, як працювати з неструктурованими даними.
Давайте глибоко зануримося в неструктуровані дані без зайвих розмов.
Що таке неструктуровані дані?
Все в цьому цифровому світі складається з даних. Дані можуть мати два формати: вони можуть мати належну структуру або ні.
Будь-яка інформація, яка не впорядкована за будь-якою послідовністю чи схемою чи будь-якою конкретною структурою, яка полегшує її читання для інших, називається неструктурованими даними.
Неструктуровані дані не мають структури чи формату, щоб їх було легко впізнати. Неструктуровані дані значною мірою базуються на тексті, як дані, факти, відкриті відповіді на опитування, але вони також можуть бути нетекстовими, як-от зображення, аудіо чи відео.
Детальніше: Як витягти дані з PDF?
Які приклади неструктурованих даних?
Коли ви думаєте про дані, подумайте про будь-які дані, які не мають повторюваного або розпізнаваного шаблону, і це були б неструктуровані дані. Він може бути текстовим, нетекстуальним, створеним людиною або машиною. Ось кілька прикладів неструктурованих даних:
Текстові дані
Дані, які доступні в електронній або письмовій формі, називаються текстовими даними. Прикладом неструктурованих даних є текстові повідомлення, письмові документи, word, PDF-файли та інші файли.
Мультимедійні повідомлення
Одним із типів неструктурованих даних є мультимедійні повідомлення. Мультимедійні дані містять зображення (JPEG, PNG, GIF), аудіо або відео формат. Мультимедійні повідомлення — це суміш складного коду, який не має подібного шаблону.
Усі зображення, відео чи аудіофайли можуть бути зашифрованими двійковими кодами, які не відповідають шаблону, і тому є неструктурованими даними. Що ви тут бачите?

Ну, насправді це зображення червоного автомобіля.

Зображення та зображення потребують спостереження, щоб зрозуміти, а їхні дані не повністю складені, тому це називається неструктурованими даними.
Вміст веб-сайту
Усі веб-сайти заповнені будь-якою інформацією, яка доступна у вигляді довгих абзаців, розрізнених та неорганізованих форм. Це свого роду дані з цінною інформацією, але вони не гідні, оскільки потрібен належний склад даних.
Дані датчиків - пристрої IoT
Інтернет речей – це фізичний пристрій, який збирає інформацію про оточення та надсилає дані назад у хмару. Пристрої IoT надсилають конфіденційні дані датчиків, які можуть бути неструктурованими. Прикладами пристроїв IoT, які надсилають дані датчиків, можуть бути пристрої моніторингу трафіку, музичні пристрої, такі як Alexa, Google Home тощо.
Електронна адреса
Електронна пошта широко використовується компаніями як один із основних каналів спілкування. Електронні листи можна класифікувати як напівструктуровані та неструктуровані. Існує багато інструментів аналізу, які очищають інформацію електронної пошти, щоб зрозуміти деталі.
Ділові документи
Підприємства мають справу з документами різних типів, як-от PDF-файли, електронні листи, рахунки-фактури, замовлення тощо. Усі документи мають різну структуру. Щоб витягти дані з PDF -файлів, та інші паперові документи, які можуть використовувати підприємства інтелектуальне програмне забезпечення для обробки документів як Нанонець.
Понад 10,000 98 користувачів використовують Nanonets для перетворення неструктурованих даних у структуровані з точністю понад XNUMX%. Спробувати?
Яка різниця між структурованими та неструктурованими даними?
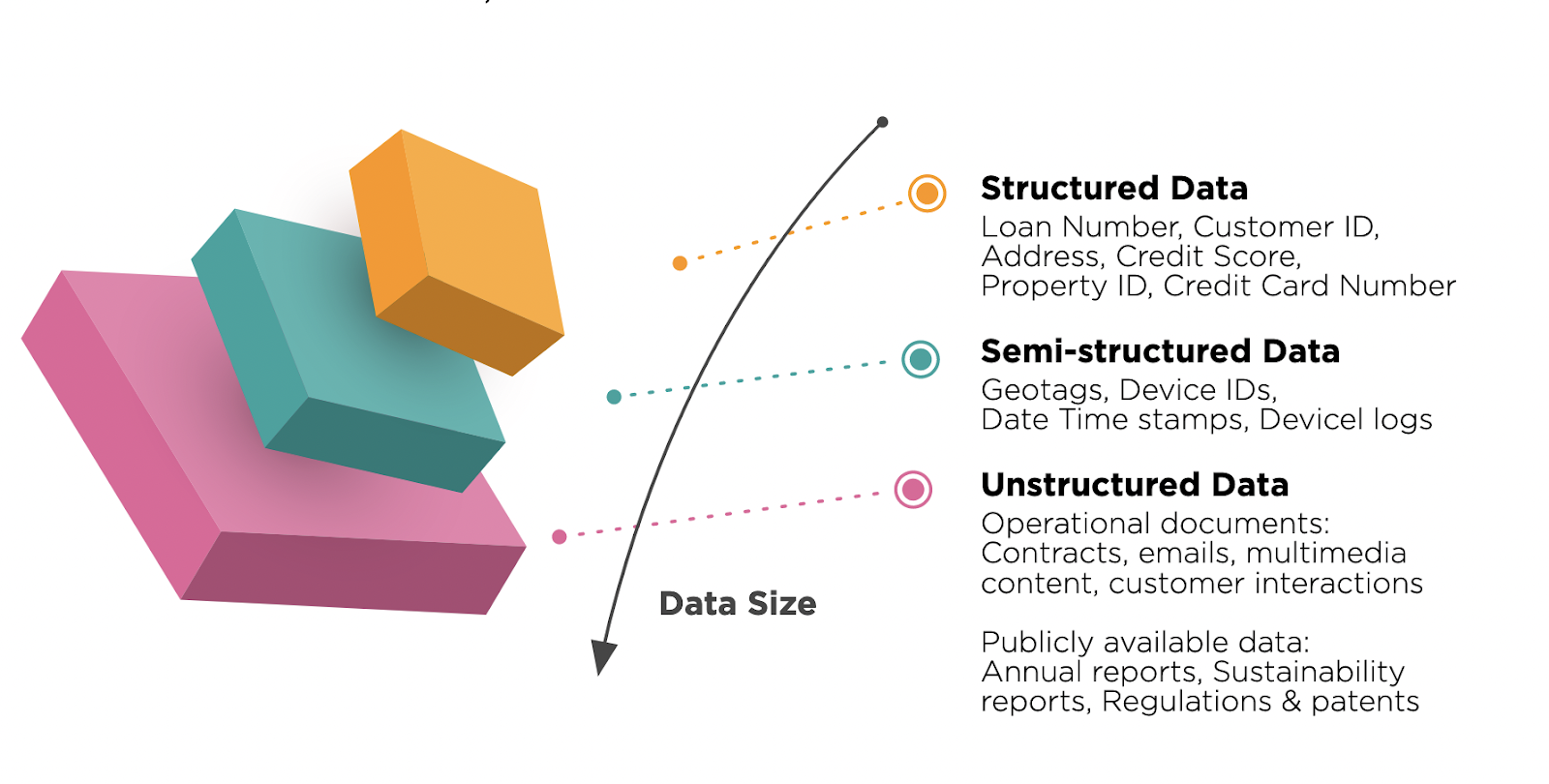
Великі дані включають структуровані, напівструктуровані та неструктуровані дані. Усі ці типи даних можуть запропонувати багато. Давайте детально розглянемо їх відмінності.
Структуровані дані – це ще один тип даних, які відповідають певному шаблону і легко розпізнати. Ця форма даних доступна в СУБД і має багато застосувань. Існує коротка таблиця описів як структурованих, так і неструктурованих даних:
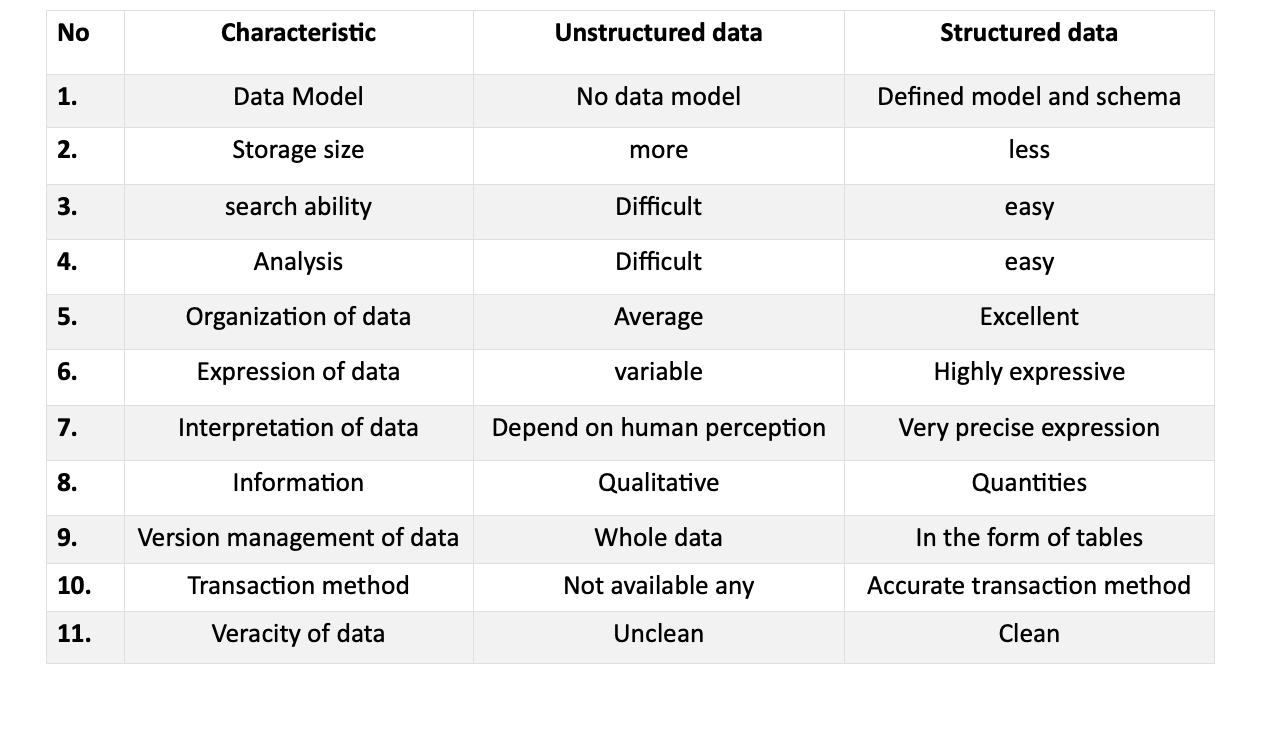
Модель даних
- Неструктуровані дані часто надходять у формі великих PDF-файлів, текстових або мультимедійних файлів, тоді як структуровані дані є точними та впорядкованими.
- Визначена модель структурованих даних робить їх легкими та надійними для вивчення та доступу.
- Великі файли потребують значного обсягу пам’яті, що робить структуровані дані більш бажаними завдяки регульованому розміру файлу, часто у табличному форматі.
Аналіз даних
- Аналіз визначає релевантність і точність даних.
- Неструктуровані дані можуть містити недостовірні або неоднозначні знання, на відміну від структурованих даних, які організовані та скориговані.
- Структуровані дані є кращими через легкість аналізу порівняно з неструктурованими даними.
можливості пошуку
- Вилучення неструктурованих даних може бути хаотичним, що робить пошук основних точок трудомістким.
- Структуровані дані легко доступні для пошуку завдяки їх організації.
- Неструктуровані дані можуть бути складними для розуміння та пошуку через їх розмір і формат.
Візіонерський аналіз
- Цілеспрямований аналіз неструктурованих даних може виявити цінну інформацію.
- Дані в короткому, актуальному форматі привертають більше інтересу, ніж довгі абзаци.
- Структуровані дані дозволяють швидше автентифікувати інформацію, заощаджуючи час користувачів.
Які труднощі виникають під час роботи з неструктурованими даними?
Неструктуровані дані надходять у дуже довгому вигляді, тому вилучення неструктурованих даних необхідне. Під час роботи з неструктурованими даними робочий персонал стикається з багатьма проблемами. Перш за все, цей тип даних доступний у вигляді масового тексту будь-якої іншої форми, тому для цих даних потрібно занадто багато часу. По-друге, якщо дані доступні у великих файлах, як, швидше за все, представлені неструктуровані дані, вони займають занадто багато місця. Якість структурованих даних полягає в тому, що вони представлені в дуже точних та табличних формах, тому вилучення даних дуже легко.
Компрометована релевантність
Видно, що неструктуровані дані містять багато інформації, яка не є цінною, дуже неточною та нерелевантною. Точність даних повинна підтримуватися якнайкраще, тому найбільша проблема, з якою стикається вилучення неструктурованих даних, полягає в тому, щоб зберегти якість релевантних і точних даних незмінною.
зберігання
З часів цифровізації світу в 20 столітті успіх даних забезпечується тим, що вони займають менше місця і більше інформації. У минулому дані зберігалися у багатьох великих файлах, неструктуровані дані займали занадто багато місця, що тепер стало проблемою впоратися з усіма цими змінами.
Робота з неструктурованими даними займає багато часу. Коли справа доходить до терміновості даних, вилучення інформації з неструктурованих даних зайняло занадто багато часу. Тому дані зайняли занадто багато часу і в терміновому порядку, дуже важко витягти всі знання з даних.
З початку оцифрування з’явилося багато інструментів для вирішення проблем вилучення неструктурованих даних. Щоб заощадити час, вилучення неструктурованих даних за допомогою штучного інтелекту засоби вилучення даних Подібно до Nanonets, він дуже надійний, тому що надає повну та цілком релевантну інформацію для даних. Релевантність даних дуже важлива, оскільки це важливий інструмент економії часу для робочого персоналу та аналітиків. За допомогою цих стратегій даних можна легко інтерпретувати цінну інформацію з даних.
Як ви можете використовувати Nanonets для перетворення неструктурованих даних на статистичні дані?
Nanonets — це платформа, яка використовує методи AI, ML і NLP, щоб допомогти користувачам отримувати ідеї з неструктурованих даних. Ось спрощена покрокова інструкція щодо того, як цього досягти:
- Збір даних: Зберіть свої неструктуровані дані. Це можуть бути зображення, текстові файли, PDF-файли, відео чи аудіофайли.
- Завантажити в Nanonets: завантажте свої неструктуровані дані на платформу Nanonets за допомогою свого облікового запису. Ти можеш створіть свій тут. Це можна зробити безпосередньо або через API, присутні в додатку.
- Виберіть або навчіть модель: Тепер на основі документа, який ви завантажуєте, виберіть модель OCR. Nanonets надає попередньо підготовлені моделі для багатьох типів документів. . Виберіть модель, яка відповідає вашому типу даних і меті. Якщо жодна з попередньо навчених моделей не відповідає вашим потребам, ви можете навчити спеціальну модель OCR, використовуючи свої дані.
- Застосувати модель до даних: Коли ваша модель буде готова, застосуйте її до своїх документів. Модель витягне дані з ваших документів і перетворить їх у структурований формат, як-от таблиця, excel, csv, який легше читати.
- Перегляньте та відрегулюйте: перевірити результати аналізу моделі. Якщо вони недостатньо точні, ви можете налаштувати модель за допомогою платформи перетягування Nanonets, доки результати не відповідатимуть вашим потребам.
- Отримайте статистику: Нарешті, використовуйте структуровані дані, щоб отримати розуміння. Ви можете експортувати дані та виконувати аналітику даних, щоб отримати статистику.
Пам’ятайте, що конкретні кроки можуть відрізнятися залежно від конкретного типу неструктурованих даних і аналітичних даних, які ви хочете отримати. Nanonets може автоматизувати процес за допомогою автоматизованих робочих процесів, потужного програмного забезпечення OCR та інтерфейсу користувача без коду.
Ми живемо в трансформаційну епоху, коли цифровізація спрощує розвиток бізнесу та прийняття рішень. Вилучення неструктурованих даних оптимізувало різні процеси завдяки економії часу та швидкості роботи.
Неструктуровані дані, по суті сирі матеріали, обробляються для вилучення цінної інформації для зручного зберігання. Його таблична форма покращує доступність. Запити даних організовані в зручні, добре структуровані форми, позбавлені двозначності, що робить їх легкими для читання. Серед різноманітних доступних інструментів вилучення даних кожен сприяє ефективності системи та покращенню середовища.
Вилучення неструктурованих даних має вирішальне значення для підтримки автентичності даних у всіх галузях. Наприклад, банківський сектор використовує ці інструменти для розвитку бізнесу.
У наукових дослідженнях інструменти вилучення неструктурованих даних зводять дані до більш точної форми, незалежно від того, згенеровані вони людиною чи машиною, надаючи цінну інформацію.
Підприємства в різних галузях використовують методи вилучення неструктурованих даних, щоб зрозуміти свої бізнес-документи та додати додатковий рівень інтелекту до своєї аналітики. На малюнку нижче показано появу використання неструктурованих даних у різних галузях.
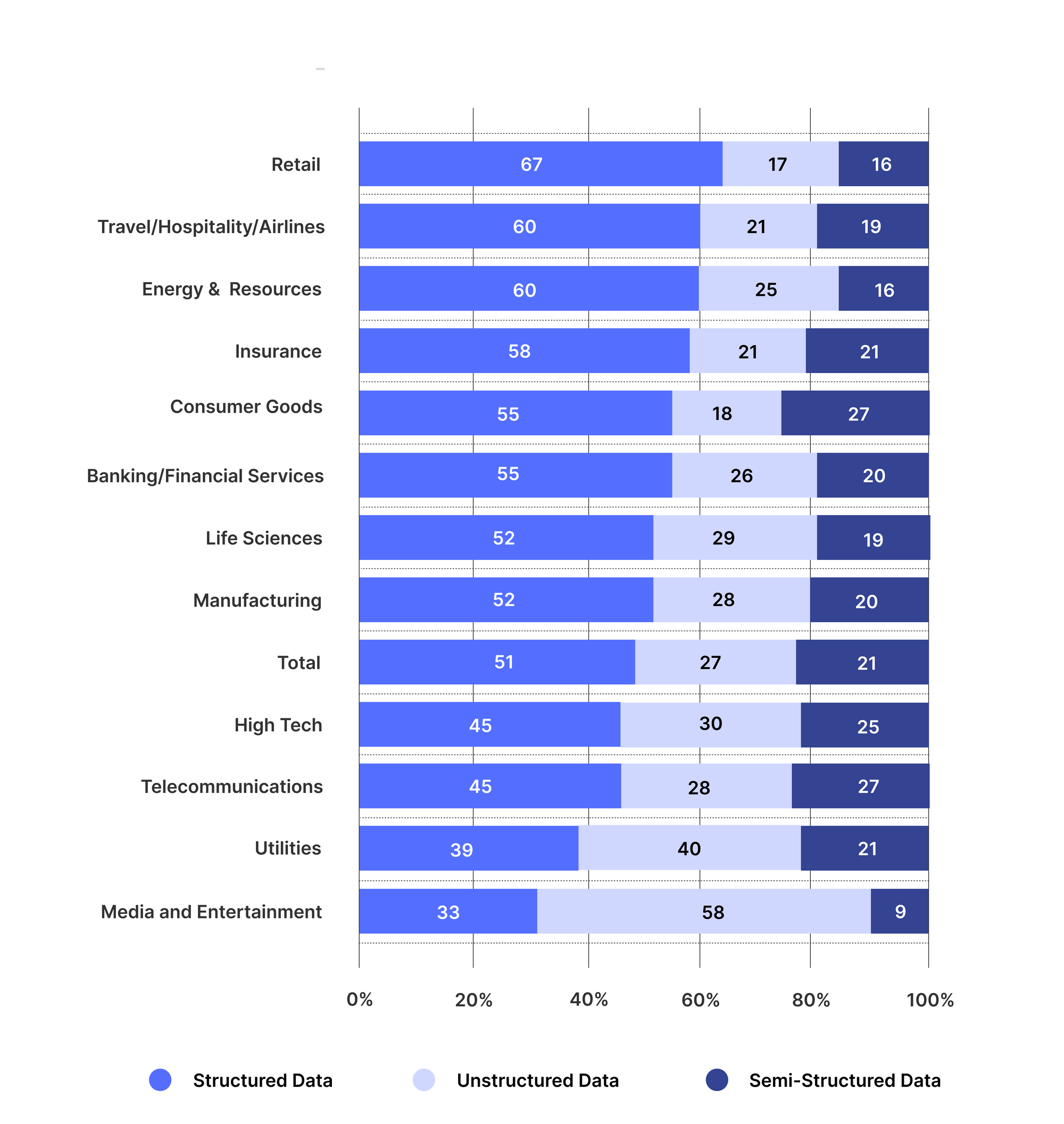
[Джерело: Дослідження TCS]
Ось кілька прикладів того, як різні галузі використовують інтелектуальні платформи обробки документів, такі як Nanonets, для вилучення неструктурованих даних і підвищення їх продуктивності.
Банки
Банки використовують Платформи IDP щоб отримати інформацію з неструктурованих джерел даних, таких як претензії, форми клієнтів, документи KYC, записи дзвінків, фінансові звіти тощо.
Детальніше: RPA в банківській справі та Автоматизація банківської справи
Страхування
Страхування – це жорстко регульована галузь. Він повинен виконувати перевірку документів і перевірку особи на кожному етапі процесів страхових випадків. Страхові компанії використовують автоматизовані платформи обробки документів для автоматизації процесів подання претензій, управління ризиками та інших функцій, які ґрунтуються на правилах. Процес страхових відшкодувань містить багато неструктурованих даних. Вилучення неструктурованих даних Завдяки використанню платформ зі штучним інтелектом, як-от Nanonets, процес страхових претензій спрощується, оскільки дозволяє вибірково витягувати дані із зображень, PDF-файлів, відео, аудіо тощо.
Детальніше: Автоматизація страхування, Страхування OCR та RPA в страхуванні
здоров'я
Забезпечення виняткового досвіду для пацієнтів полягає в забезпеченні кращого обслуговування, скороченні часу очікування пацієнтів і гарантії того, що персонал не перевантажується. Використання Платформа IDP отримання інформації з неструктурованих джерел даних, як-от голос даних клієнтів, опитування пацієнтів, EHR, скарги клієнтів, веб-сайти нормативних документів та огляд літератури, допомагає Healthcare забезпечити кращу роботу пацієнтів.
Детальніше: Автоматизація охорони здоров'я та ШІ в охороні здоров'я
Нерухомість
Компанії з нерухомості мають справу з кількома людьми одночасно, такими як клієнти, будівельники, орендарі, продавці, конкуренти та власники нерухомості. Використання програмного забезпечення для автоматизованої обробки документів може допомогти установам нерухомості створити багаті профілі згаданих зацікавлених сторін і спростити вилучення даних з неструктурованих джерел даних, таких як орендна плата, контракти, документи про оцінку майна тощо.
Висновок
Дані – це нова нафта. Підприємство, що володіє вилученням неструктурованих даних, може розкрити весь потенціал корпоративних даних. Nanonets дозволяють підприємствам автоматизувати обробку документів і можуть розумно витягувати дані з будь-якого типу документів.
Нанонети онлайн OCR та OCR API є багато цікавого випадки використання tкапелюх може оптимізувати ефективність вашого бізнесу, заощадити витрати та стимулювати зростання. Дізнайся як варіанти використання Nanonets можуть застосовуватися до вашого продукту.
FAQ
Які переваги використання неструктурованих даних?
Неструктуровані дані важко зрозуміти, інтерпретувати та використовувати безпосередньо, але це не єдине. Існує багато переваг використання неструктурованих даних, як зазначено нижче:
Немає фіксованого формату
Неструктуровані дані підтримують дані всіх форматів і розмірів. Будь-які дані, які не мають належної послідовності, можна класифікувати як неструктуровані дані. Може бути корисним для розширення горизонту типів даних.
Немає схеми
Як обговорювалося вище, неструктуровані дані не мають фіксованої послідовності, а також не мають фіксованої схеми. Саме це ускладнює вилучення неструктурованих даних для більшості частин.
Гнучкість
Оскільки неструктуровані дані не мають структури, вони можуть мати будь-який формат. Це робить його текучим з точки зору структури.
Портативний і масштабований
Неструктуровані дані є більш портативними та масштабованими в порівнянні з напівструктурованими та структурованими даними.
Багато бізнес-додатків
Враховуючи, що 80% даних підприємства неструктуровані, додатків для цих даних дуже багато. Неструктуровані дані підприємства використовуються для різних випадків використання бізнес-аналітики. Наприклад, презентації, відео компанії, розуміння профілів клієнтів тощо.
Як перетворити неструктуровані дані в структуровані?
Робота з великими та об’ємними даними може бути важким завданням. Щоб заощадити час і зберегти оригінальність і точність даних, їх слід скоротити до такої міри, щоб залишилася лише необхідна інформація. Вилучення неструктурованих даних має різні методи, і його значення дуже показує вся наведена вище інформація. Різниця між структурованим і неструктурованим дає важливі підказки щодо даних. Щоб перетворити неструктуровані дані в структуровані, можна скористатися наведеними нижче кроками.
Крок 1. Поставте перед собою чітку мету
Жоден проект ніколи не повинен розпочинатися без набору вимірних цілей. Маючи чітке уявлення про кінцеву мету, яку інформацію ви хочете отримати, стає легше завершити наступні кроки.
Крок 2: Завершіть роботу над джерелами даних
Дані всюди. Але, щоб почати перетворення, вам потрібно визначити джерела даних для створення ваших неструктурованих даних. Стратегії вилучення даних будуть різними для різних джерел даних. Наномережі дозволяють користувачам збирати дані з кількох джерел, таких як Gmail, Dropbox, Outlook, робочий стіл тощо.
Дані можна отримати з великих PDF-файлів, зображень та інших текстових форм.
Крок 3: Стандартизація даних
Третій крок — знати, що робити з вилученням неструктурованих даних. Аналітик повинен мати уявлення про кінцевий результат неструктурованих даних.
Якщо ви вибрали дані, наступним кроком є остаточне оформлення результатів даних. Якщо дані мають будь-яку змінну форму, аналітик повинен стандартизувати їх, перш ніж проводити будь-який аналіз. Цей конкретний крок передбачає очищення та стандартизацію форматів даних для наступних кроків.
Крок 4. Вибір технології вилучення даних:
Після розуміння джерел даних і методу стандартизації даних важливо завершити програмне забезпечення, яке ви хочете використовувати для реалізації цих кроків. Платформи IDP, такі як Nanonets, допомагають організаціям підключатися, витягувати дані та стандартизувати їх для подальшого аналізу.
Дані будуть братися іншим програмним забезпеченням, наступним кроком є пошук технології, за допомогою якої дані будуть передані в програмне забезпечення. Для цього використовується раціональна система управління базами даних (СУБД). Це програмне забезпечення та технологія допомагають легко використовувати технологію.
Крок 5: Вибір системи зберігання даних
Система зберігання даних вибирається залежно від типу технології, яку ви шукаєте, вона повинна мати високу доступність, високу швидкість та інші функції. Усі ці функції разом із ємністю зберігання в реальному часі роблять систему зберігання високого рівня.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- Карбування майбутнього з Адріенн Ешлі. Доступ тут.
- Купуйте та продавайте акції компаній, які вийшли на IPO, за допомогою PREIPO®. Доступ тут.
- джерело: https://nanonets.com/blog/unstructured-data-extraction/
- : має
- :є
- : ні
- :де
- 1
- 12
- 24
- 50
- 7
- a
- МЕНЮ
- про це
- вище
- доступ
- доступність
- рахунки
- точність
- точний
- Achieve
- через
- насправді
- додавати
- регульований
- Відрегульований
- Переваги
- прихід
- AI
- Alexa
- ВСІ
- дозволяти
- дозволяє
- по
- Також
- взагалі
- Неоднозначність
- серед
- an
- аналіз
- аналітик
- аналітики
- аналітика
- та
- Інший
- будь-який
- Інтерфейси
- додаток
- застосування
- Застосовувати
- ЕСТЬ
- навколо
- влаштований
- AS
- At
- Приваблює
- аудіо
- Authentication
- справжність
- автоматизувати
- Автоматизований
- наявність
- доступний
- назад
- Banking
- банківський сектор
- Банки
- заснований
- BE
- оскільки
- ставати
- стає
- перед тим
- буття
- нижче
- КРАЩЕ
- Краще
- між
- Великий
- найбільший
- підвищення
- обидва
- Box
- будівельники
- бізнес
- результати діяльності
- підприємства
- але
- by
- call
- званий
- CAN
- потужність
- автомобіль
- випадків
- Століття
- виклик
- проблеми
- Зміни
- канали
- перевірка
- Вибирати
- претензій
- класифікований
- Очищення
- ясно
- близько
- хмара
- код
- збирати
- збирає
- COM
- Приходити
- приходить
- спілкуватися
- Компанії
- компанія
- порівняний
- конкурентів
- скарги
- повністю
- комплекс
- складається
- включає
- висновок
- З'єднуватися
- містить
- контрактів
- Перетворення
- конвертувати
- витрати
- може
- створювати
- вирішальне значення
- виготовлений на замовлення
- клієнт
- дані про клієнтів
- Клієнти
- дані
- Analytics даних
- зберігання даних
- Database
- день
- угода
- Прийняття рішень
- глибокий
- глибоке занурення
- певний
- робочий стіл
- деталь
- деталі
- визначає
- пристрій
- прилади
- різниця
- Відмінності
- різний
- важкий
- цифровий
- цифровий світ
- цифровізація
- безпосередньо
- обговорювалися
- do
- документ
- документація
- робить
- зроблений
- малювати
- Падіння
- два
- кожен
- простота
- легше
- легко
- легко
- ефективність
- або
- повідомлення електронної пошти
- працює
- зашифрованих
- кінець
- Підсилює
- підвищення
- досить
- забезпечувати
- забезпечення
- підприємство
- підприємств
- навколишній
- Епоха
- по суті
- майно
- і т.д.
- Ефір (ETH)
- НІКОЛИ
- Кожен
- приклад
- Приклади
- перевершувати
- винятковий
- Розширювати
- досвід
- експорт
- додатково
- витяг
- видобуток
- стикаються
- Факти
- ШВИДКО
- риси
- Рисунок
- філе
- Файли
- заповнений
- остаточний
- завершити
- в кінці кінців
- фінансовий
- знайти
- фірми
- Перший
- фіксованою
- рідина
- увагу
- стежити
- після
- слідує
- для
- Forbes
- форма
- формат
- форми
- від
- Повний
- Функції
- далі
- збирати
- породжувати
- отримати
- GIF
- Давати
- Gmail
- мета
- Цілі
- Домашня сторінка Google
- Зростання
- керівництво
- Жорсткий
- Мати
- має
- здоров'я
- охорона здоров'я
- сильно
- допомога
- допомагає
- тут
- Високий
- дуже
- Головна
- горизонт
- Як
- How To
- HTTP
- HTTPS
- людина
- ідея
- ідентифікувати
- Особистість
- ідентичність Перевірка
- if
- зображення
- зображень
- реалізації
- важливо
- поліпшення
- in
- неточні
- промисловості
- промисловість
- інформація
- розуміння
- екземпляр
- установи
- страхування
- Інтелект
- Розумний
- Інтелектуальна обробка документів
- взаємодіяти
- інтерес
- цікавий
- інтерфейс
- інтернет
- Інтернет речей
- в
- КАТО
- прилади іоту
- незалежно
- IT
- ЙОГО
- Дитина
- Знати
- знання
- ЗСК
- великий
- шар
- залишити
- менше
- як
- літератури
- життя
- Довго
- подивитися
- шукати
- серія
- підтримувати
- основний
- зробити
- РОБОТИ
- Робить
- управління
- система управління
- багато
- матеріал
- Зустрічатися
- згаданий
- повідомлення
- метод
- методика
- може бути
- ML
- модель
- Моделі
- моніторинг
- більше
- найбільш
- багато
- мультимедіа
- множинний
- музика
- необхідно
- Необхідність
- потреби
- Нові
- наступний
- nlp
- немає
- зараз
- мета
- отримувати
- OCR
- Програмне забезпечення OCR
- of
- пропонувати
- часто
- Нафта
- on
- один раз
- ONE
- онлайн
- Інтернет-бізнес
- тільки
- операція
- Оптимізувати
- or
- порядок
- замовлень
- організація
- організації
- Організований
- оригінальність
- Інше
- інші
- Результат
- прогноз
- Власники
- на паперовій основі
- документи
- приватність
- частини
- Минуле
- пацієнт
- Викрійки
- Люди
- виконувати
- продуктивність
- фізичний
- фотографії
- платформа
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- точок
- це можливо
- потенціал
- потужний
- необхідність
- переважним
- представити
- Presentations
- подарунки
- первинний
- ймовірно
- процес
- процеси
- обробка
- Product
- продуктивність
- Профілі
- проект
- правильний
- власність
- за умови
- забезпечує
- забезпечення
- мета
- якість
- запити
- швидше
- Квінтільйон
- Раціональний
- Сировина
- RE
- Читати
- готовий
- реальний
- нерухомість
- реального часу
- насправді
- визнавати
- облік
- червоний
- зниження
- регулярний
- регулюється
- регуляторні
- актуальність
- доречний
- надійний
- залишається
- оренда
- Звіти
- вимагати
- вимагається
- дослідження
- відповіді
- результат
- результати
- показувати
- огляд
- Багаті
- Risk
- управління ризиками
- грубо
- s
- то ж
- зберегти
- економія
- масштабовані
- розсіяний
- схема
- Наукове дослідження
- Пошук
- другий
- сектор
- побачити
- бачив
- обраний
- вибирає
- селективний
- послати
- відправка
- посилає
- сенс
- чутливий
- Послідовність
- обслуговування
- комплект
- Короткий
- укорочений
- Повинен
- показаний
- Шоу
- значення
- значний
- аналогічний
- спрощений
- Розмір
- розміри
- So
- Софтвер
- деякі
- Source
- Джерела
- конкретний
- Персонал
- зацікавлених сторін
- стандартизації
- старт
- Крок
- заходи
- Як і раніше
- зберігання
- просто
- стратегії
- раціоналізувати
- обтічний
- структура
- структурований
- структуровані та неструктуровані дані
- Вивчення
- успіх
- такі
- костюм
- Опори
- дивно
- Навколо
- Огляд
- система
- таблиця
- Приймати
- приймає
- взяття
- Завдання
- методи
- Технологія
- terms
- ніж
- Що
- Команда
- інформація
- світ
- їх
- Їх
- Там.
- отже
- Ці
- вони
- річ
- речі
- думати
- третій
- це
- по всьому
- час
- трудомісткий
- times
- до
- занадто
- прийняли
- інструмент
- інструменти
- трафік
- поїзд
- передані
- перетворювальний
- намагатися
- два
- тип
- Типи
- розуміти
- розуміння
- на відміну від
- відімкнути
- до
- відповідний сучасним вимогам
- Завантаження
- терміновість
- використання
- використовуваний
- користувач
- Інтерфейс користувача
- зручно
- користувачі
- використання
- використовує
- Цінний
- Цінна інформація
- Оцінка
- різноманітність
- різний
- постачальники
- перевірка
- дуже
- через
- Відео
- Відео
- Голос
- чекати
- хотіти
- було
- шлях..
- we
- веб-сайти
- Що
- Що таке
- коли
- Чи
- який
- в той час як
- чому
- широко
- волі
- з
- без
- слово
- Робочі процеси
- робочий
- світ
- б
- письмовий
- ви
- вашу
- зефірнет