У сучасному світі клієнти керують величезними обсягами даних у своїх Служба простого зберігання Amazon (Amazon S3) озера даних, які вимагають заплутаних конвеєрів даних, щоб постійно розуміти зміни в структурі даних і робити їх доступними для споживаючих систем. Клей AWS сканери забезпечують простий спосіб каталогізації даних у каталозі даних AWS Glue, який усуває важку роботу, коли йдеться про керування схемами та класифікацію даних. Роботи AWS Glue витягують схему даних і розділи з Amazon S3, щоб автоматично заповнювати каталог даних, зберігаючи актуальні метадані.
Але оскільки дані експоненціально зростають з часом, кількість розділів у певній таблиці може значно зрости. Оскільки аналітичні служби люблять Амазонка Афіна запитувати таблицю, що містить мільйони розділів, час, необхідний для отримання розділу, збільшується та може призвести до збільшення часу виконання запиту.
Сьогодні підтримку сканера AWS Glue було розширено, щоб автоматично додавати індекси розділів для щойно виявлених таблиць для оптимізації обробки запитів до розділеного набору даних. Тепер, коли сканер створює нову таблицю каталогу даних під час роботи сканера, він також створює індекс розділу за замовчуванням із найбільшою перестановкою всіх стовпців розділу числового та рядкового типу як ключів. Потім каталог даних створює індекс із можливістю пошуку на основі цих ключів, скорочуючи час, необхідний для отримання та фільтрації метаданих розділів у таблицях із мільйонами розділів. Створення індексів розділів приносить користь аналітичним навантаженням, які виконуються на Athena, Amazon EMR, Спектр червоного зсуву Amazonі клей AWS.
У цій публікації ми описуємо, як створювати індекси розділів за допомогою сканера AWS Glue і порівнюємо покращення продуктивності запитів під час доступу до просканованих даних з індексом розділу з Athena та без нього.
Огляд рішення
Ми використовуємо AWS CloudFormation шаблон для створення наших ресурсів рішення. У наступних кроках ми демонструємо, як налаштувати сканер AWS Glue для створення індексу розділу за допомогою консолі AWS Glue або Інтерфейс командного рядка AWS (AWS CLI). Потім ми порівнюємо покращення продуктивності запитів за допомогою Athena.
Передумови
Щоб слідкувати за цією публікацією, ви повинні мати доступ до Управління ідентифікацією та доступом AWS (IAM) роль адміністратора для створення ресурсів за допомогою AWS CloudFormation.
Налаштуйте свої ресурси рішення
Шаблон CloudFormation створює такі ресурси:
- Ролі та політика IAM
- База даних AWS Glue для зберігання схеми
- Кроулер AWS Glue, що вказує на дуже розділений набір даних
- Робоча група Athena та сегмент для зберігання результатів запиту
Виконайте такі кроки, щоб налаштувати ресурси рішення:
- Увійти в Консоль управління AWS як адміністратор IAM.
- Вибирати Запустити стек щоб розгорнути шаблон CloudFormation:

- для Назва бази даних, збережіть значення за замовчуванням
blog_partition_index_crawlerdb.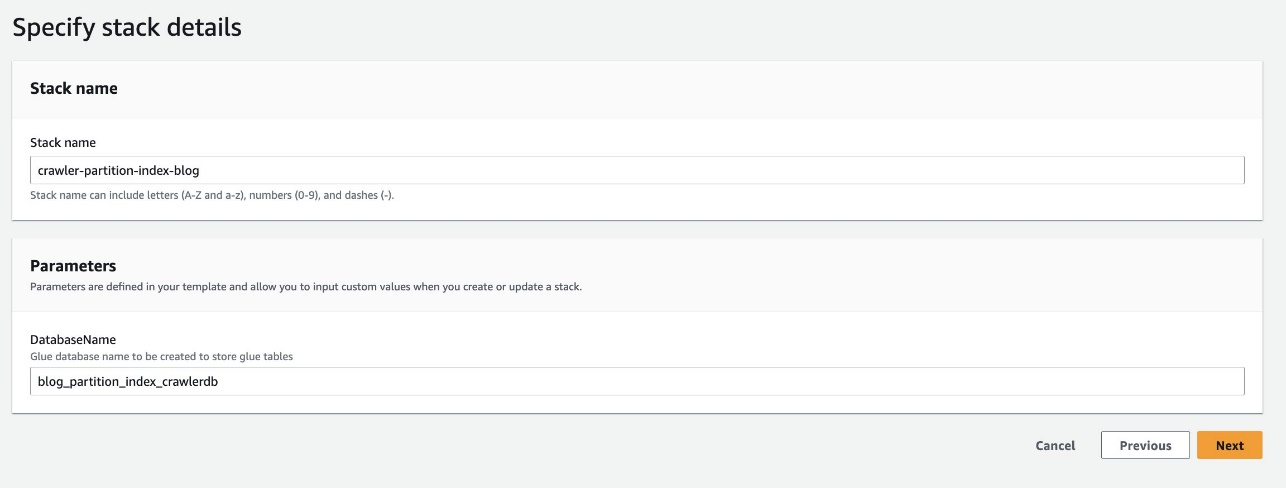
- Вибирати МАЙБУТНІ.
- Перегляньте деталі на останній сторінці та виберіть Я визнаю, що AWS CloudFormation може створювати ресурси IAM.
- Вибирати Створити стек.
- Коли стек буде завершено, на консолі AWS CloudFormation перейдіть до Виходи вкладка стека.
- Запишіть значення
DatabaseNameтаGlueCrawlerName.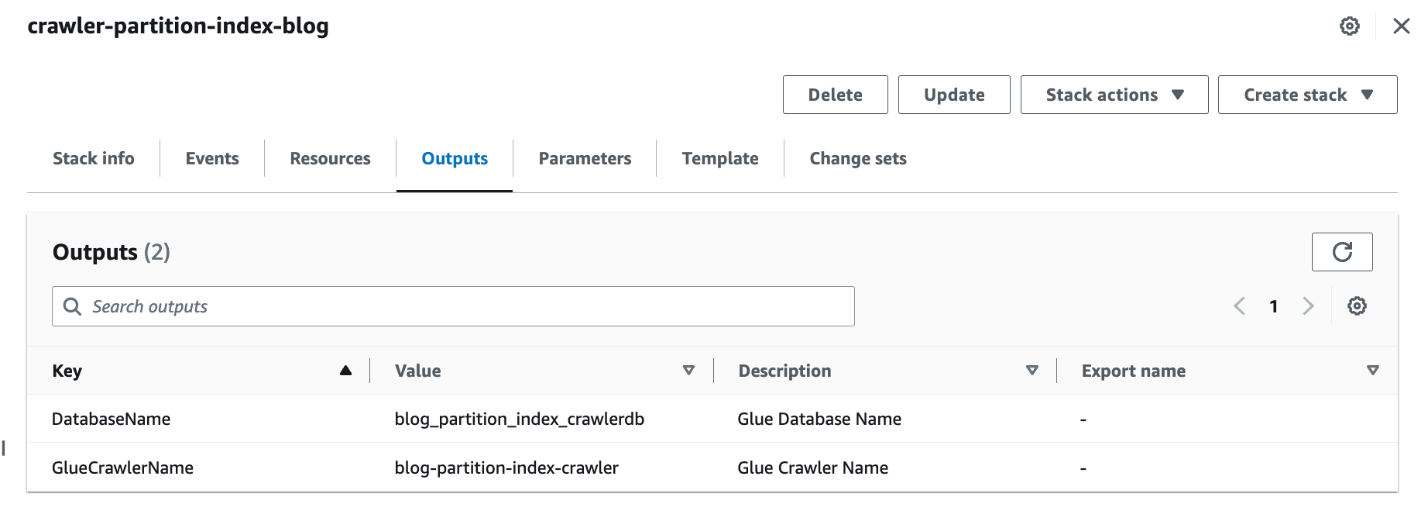
Деякі з ресурсів, які розгортає цей стек, несуть витрати під час використання.
Відредагуйте та запустіть сканер AWS Glue
Щоб налаштувати та запустити сканер AWS Glue, виконайте такі дії:
- На консолі AWS Glue виберіть Гусениці у навігаційній панелі.
- Знайдіть
crawler blog-partition-index-crawlerІ вибирай Редагувати.
- У Налаштуйте вихід і планування розділ під Додаткові параметривиберіть Автоматично створюйте індекси розділів.
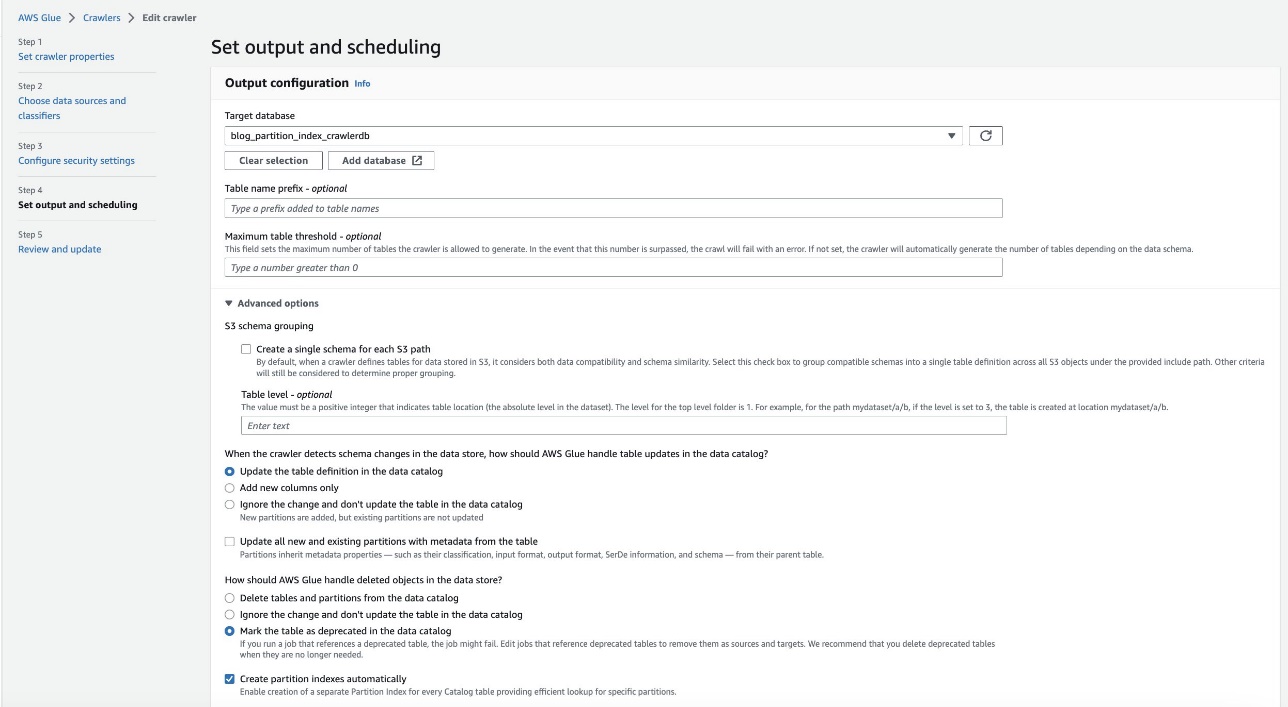
- Перегляньте та оновіть налаштування сканера.
Крім того, ви можете налаштувати сканер за допомогою AWS CLI (вкажіть свою роль IAM і регіон):
- Тепер запустіть сканер і переконайтеся, що запуск сканера завершено.
Це дуже розділений набір даних, і його завершення займе приблизно 90 хвилин.
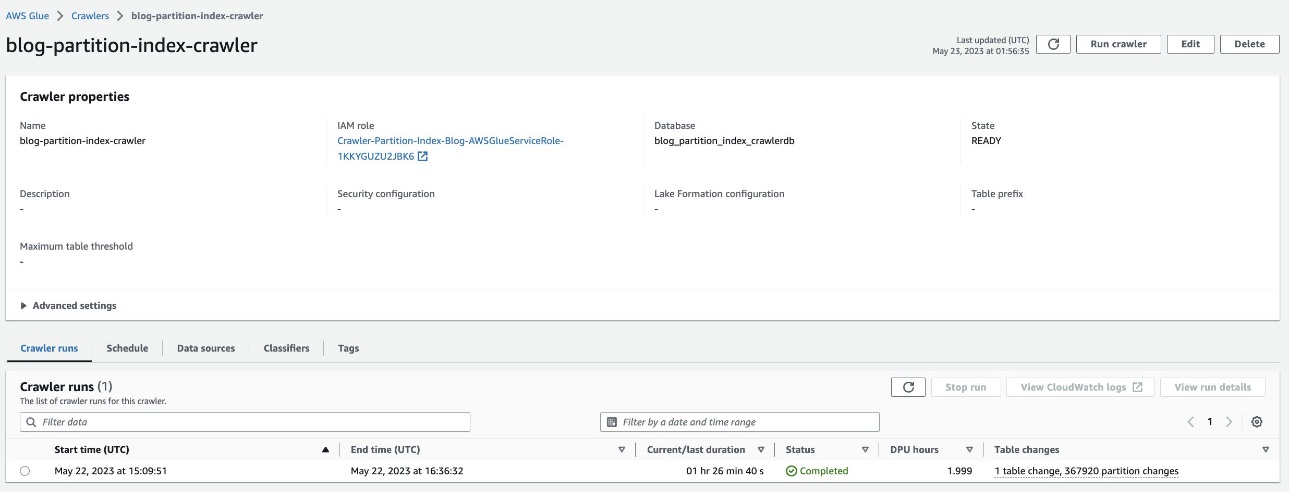
Перевірте розділену таблицю
У базі даних AWS Glue blog_partition_index_crawlerdb, переконайтеся, що табл highly_partitioned_table створюється.
За замовчуванням сканер визначає індекс на основі найбільшої перестановки стовпців розділу дійсних типів стовпців у тому самому порядку стовпців розділу, які є числовими або рядковими. Для таблиці, створеної сканером (highly_partitioned_table), маємо розділові колони year (рядок), month (рядок), day (рядок), і hour (рядок).
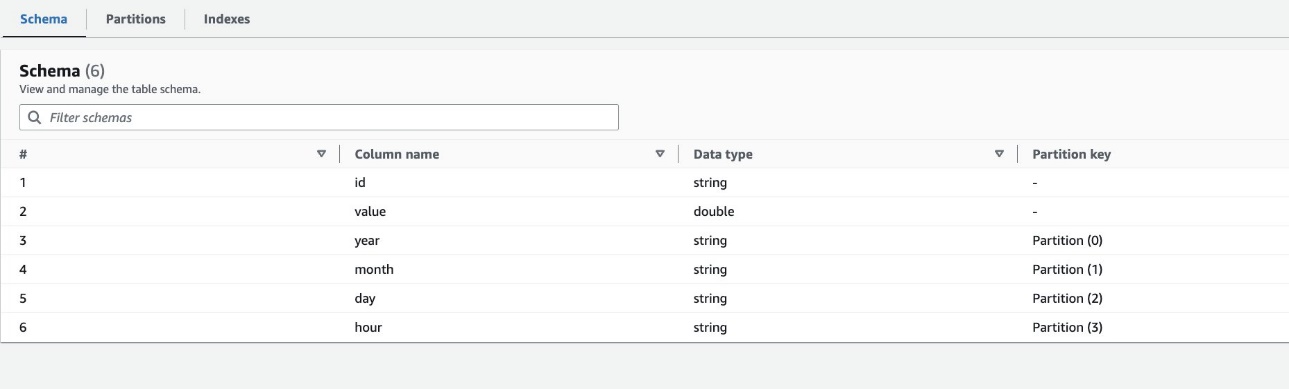
На основі цього визначення сканер створив індекс на основі перестановки року, місяця, дня та години. Пошуковий робот створив індекси з префіксом crawler_ на будь-якому індексі розділу, створеному за замовчуванням.
Перевірте те саме, перейшовши до таблиці highly_partitioned_table на консолі AWS Glue і вибравши Індекси Вкладка.
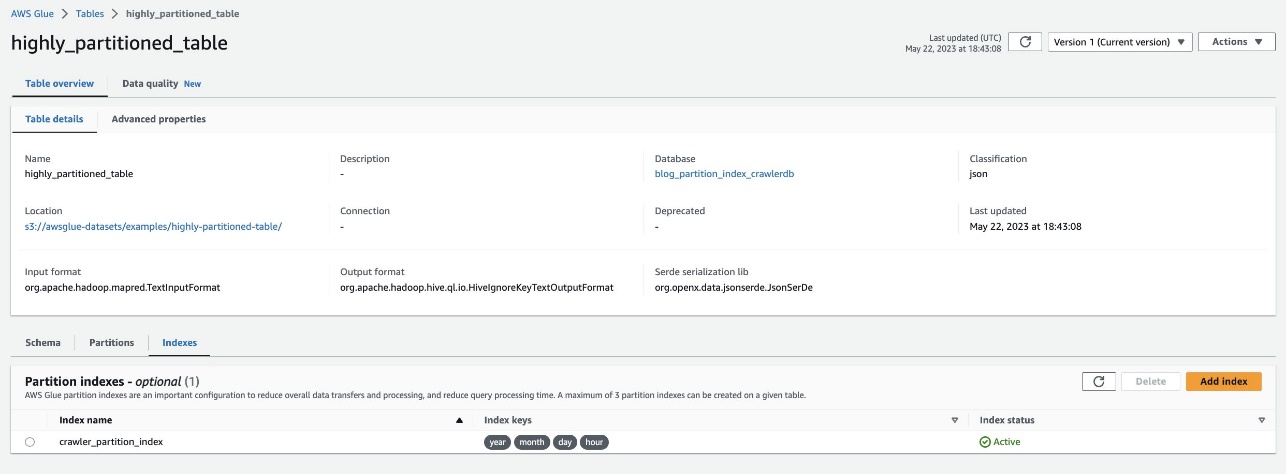
Веб-сканер зміг просканувати джерело даних S3 і успішно заповнити індекси розділів для таблиці.
Порівняйте покращення продуктивності запитів за допомогою Athena
По-перше, ми запитуємо таблицю в Athena без використання індексу розділу. Щоб перевірити таблиці за допомогою Athena, виконайте такі дії:
- На консолі Athena виберіть
crawler-primary-workgroupяк робоча група Athena та виберіть Признай.
- Виконайте наступний запит:
На наступному знімку екрана показано, що запит тривав приблизно 32 секунди без увімкнення фільтрації за допомогою індексу розділу.
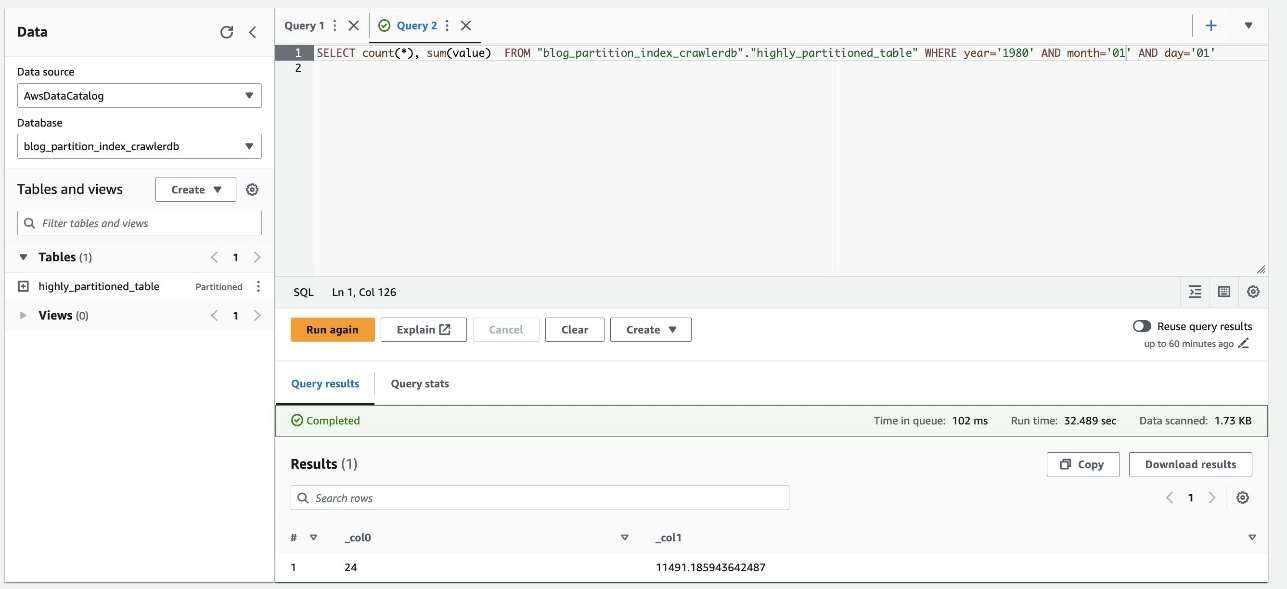
- Тепер ми вмикаємо індекс розділу для запиту Athena:
- Виконайте наступний запит ще раз і запам’ятайте час виконання:
На наступному знімку екрана показано, що запит зайняв лише 700 мілісекунд, що набагато швидше, якщо фільтрування ввімкнено за допомогою індексу розділу.
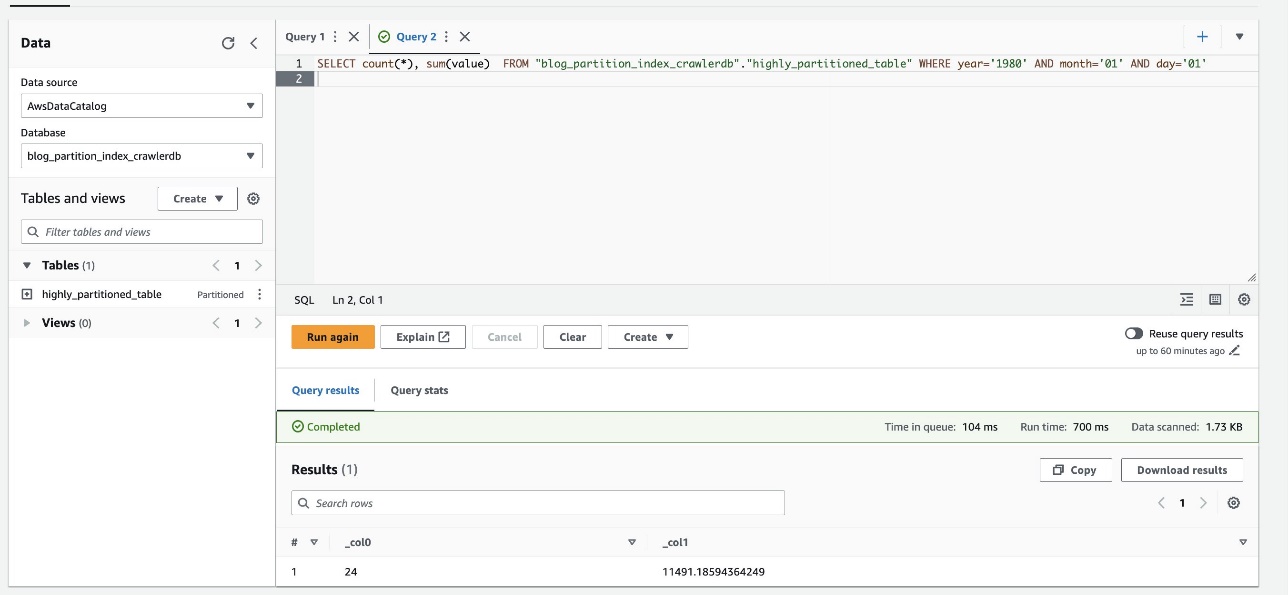
Прибирати
Щоб уникнути небажаних стягнень з вашого облікового запису AWS, ви можете видалити ресурси AWS:
- Увійдіть у консоль CloudFormation як адміністратор IAM, який використовується для створення стеку CloudFormation.
- Видаліть створений стек CloudFormation.
Висновок
У цій публікації ми пояснили, як налаштувати сканер AWS для створення індексів розділів, і порівняли продуктивність запитів під час доступу до даних за допомогою індексів з Athena.
Якщо в таблиці немає індексів розділів, AWS Glue завантажує всі розділи таблиці, а потім фільтрує завантажені розділи, що призводить до неефективного отримання метаданих. Такі аналітичні служби, як Redshift Spectrum, Amazon EMR і AWS Glue ETL Spark DataFrames, тепер можуть використовувати індекси для отримання розділів, що забезпечує значну продуктивність запитів.
Додаткову інформацію про індекси розділів і продуктивність запитів у різних аналітичних механізмах див Покращте продуктивність запитів Amazon Athena за допомогою індексів розділів AWS Glue Data Catalog та Покращте продуктивність запитів за допомогою індексів розділів AWS Glue.
Особлива подяка всім, хто зробив внесок у запуск цієї функції сканера: Юханг Чен, Кайл Дуонг і Міта Гаваде.
Про авторів
 Шрівідья Партхасараті є старшим архітектором великих даних у команді AWS Lake Formation. Їй подобається створювати рішення для сітки даних і ділитися ними зі спільнотою.
Шрівідья Партхасараті є старшим архітектором великих даних у команді AWS Lake Formation. Їй подобається створювати рішення для сітки даних і ділитися ними зі спільнотою.
 Сандіп Адванкар є старшим менеджером із технічних продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
Сандіп Адванкар є старшим менеджером із технічних продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- EVM Фінанси. Уніфікований інтерфейс для децентралізованих фінансів. Доступ тут.
- Quantum Media Group. ІЧ/ПР посилений. Доступ тут.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- : має
- :є
- :де
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Здатний
- доступ
- доступ до
- рахунки
- визнавати
- через
- додавати
- адмін
- знову
- ВСІ
- по
- Також
- Amazon
- Амазонка Афіна
- Amazon EMR
- Amazon Web Services
- суми
- an
- Аналітичний
- аналітика
- та
- будь-який
- приблизно
- ЕСТЬ
- ПЛОЩА
- навколо
- AS
- At
- автоматично
- доступний
- уникнути
- AWS
- AWS CloudFormation
- Клей AWS
- Формування озера AWS
- заснований
- затока
- оскільки
- було
- Переваги
- Великий
- Великий даних
- Створюємо
- бізнес
- by
- Каліфорнія
- CAN
- каталог
- Викликати
- Зміни
- вантажі
- Чень
- Вибирати
- Вибираючи
- класифікація
- Колонка
- Колони
- приходить
- співтовариство
- порівняти
- порівняний
- повний
- Консоль
- постійно
- внесок
- витрати
- гусеничний
- створювати
- створений
- створює
- створення
- створення
- Поточний
- Клієнти
- дані
- доступ до даних
- Озеро даних
- Database
- день
- дефолт
- демонструвати
- розгортання
- розгортає
- описувати
- деталі
- визначає
- відкритий
- вниз
- під час
- продуктивно
- або
- включіть
- включений
- Двигуни
- Ефір (ETH)
- все
- розширений
- пояснені
- експоненціально
- витяг
- витяг даних
- швидше
- особливість
- фільтрувати
- фільтрація
- Фільтри
- остаточний
- стежити
- після
- для
- освіта
- від
- генерує
- даний
- земну кулю
- Рости
- Зростання
- Мати
- he
- важкий
- важкий підйом
- дуже
- тримати
- годину
- Як
- How To
- HTML
- HTTP
- HTTPS
- IAM
- Особистість
- удосконалювати
- поліпшення
- поліпшення
- in
- Augmenter
- Збільшує
- індекс
- покажчики
- неефективний
- інформація
- в
- IT
- JPG
- тримати
- зберігання
- ключі
- озеро
- найбільших
- запуск
- макет
- підйомний
- як
- Лінія
- вантажі
- зробити
- управляти
- управління
- менеджер
- сітці
- метадані
- може бути
- мільйони
- протокол
- місяць
- більше
- багато
- повинен
- Переміщення
- навігація
- навігація
- необхідний
- Нові
- нещодавно
- немає
- зараз
- номер
- of
- on
- тільки
- Оптимізувати
- or
- порядок
- наші
- вихід
- над
- сторінка
- pane
- шлях
- продуктивність
- plato
- Інформація про дані Платона
- PlatoData
- пошта
- представити
- обробка
- Product
- менеджер по продукції
- Продукти
- забезпечувати
- зниження
- регіон
- вимагається
- Вимога
- Вимагається
- ресурси
- в результаті
- результати
- Роль
- ролі
- прогін
- біг
- то ж
- seconds
- розділ
- безпечний
- старший
- Послуги
- комплект
- налаштування
- поділ
- вона
- Шоу
- значний
- істотно
- простий
- рішення
- Рішення
- Source
- Іскритися
- спектр
- стек
- заходи
- зберігання
- зберігати
- просто
- рядок
- Успішно
- підтримка
- Systems
- таблиця
- Приймати
- команда
- технічний
- шаблон
- Дякую
- Що
- Команда
- їх
- Їх
- потім
- Ці
- вони
- це
- час
- до
- сьогоднішній
- прийняли
- переводити
- правда
- тип
- Типи
- при
- розуміти
- небажаний
- Оновити
- використання
- використовуваний
- використання
- використовувати
- значення
- Цінності
- різний
- величезний
- перевірити
- версія
- було
- шлях..
- we
- Web
- веб-сервіси
- коли
- який
- ВООЗ
- волі
- з
- без
- Робоча група
- працює
- світ
- ямл
- рік
- ви
- вашу
- зефірнет