Зображення автора
Поринаючи у світ науки про дані та машинного навчання, одним із фундаментальних умінь, з якими ви зіткнетеся, є мистецтво читання даних. Якщо ви вже маєте певний досвід роботи з ним, ви, мабуть, знайомі з JSON (JavaScript Object Notation) – популярним форматом для зберігання й обміну даними.
Подумайте про те, як бази даних NoSQL, такі як MongoDB, люблять зберігати дані в JSON, або як REST API часто відповідають у тому самому форматі.
Однак, незважаючи на те, що JSON ідеально підходить для зберігання та обміну, він не зовсім готовий для поглибленого аналізу в необробленому вигляді. Тут ми перетворюємо його на щось більш аналітично дружнє – табличний формат.
Отже, незалежно від того, чи маєте ви справу з одним об’єктом JSON чи чудовим їх масивом, з точки зору Python, ви, по суті, обробляєте dict або список dicts.
Давайте разом дослідимо, як ця трансформація розгортається, роблячи наші дані дозрілими для аналізу????
Сьогодні я поясню магічну команду, яка дозволяє нам легко розібрати будь-який JSON у табличний формат за лічені секунди.
І це… pd.json_normalize()
Отже, давайте подивимося, як це працює з різними типами JSON.
Перший тип JSON, з яким ми можемо працювати, — це однорівневі JSON із кількома ключами та значеннями. Ми визначаємо наші перші прості JSON наступним чином:
Код за автором
Отже, давайте змоделюємо необхідність роботи з цими JSON. Ми всі знаємо, що в їхньому форматі JSON нема чого робити. Нам потрібно перетворити ці JSON у певний читабельний і модифікований формат… що означає Pandas DataFrames!
1.1 Робота з простими структурами JSON
Спочатку нам потрібно імпортувати бібліотеку pandas, а потім ми можемо використати команду pd.json_normalize(), наступним чином:
import pandas as pd
pd.json_normalize(json_string)
Застосовуючи цю команду до JSON з одним записом, ми отримуємо найпростішу таблицю. Однак, коли наші дані трохи складніші та представляють список JSON, ми все ще можемо використовувати ту саму команду без подальших ускладнень, і результат відповідатиме таблиці з кількома записами.

Зображення автора
Легко… так?
Наступне природне питання полягає в тому, що станеться, якщо деякі значення відсутні.
1.2 Робота з нульовими значеннями
Уявіть, що деякі значення не інформовані, як, наприклад, відсутній запис про доходи для Девіда. Під час трансформації нашого JSON у простий фрейм даних pandas відповідне значення відображатиметься як NaN.
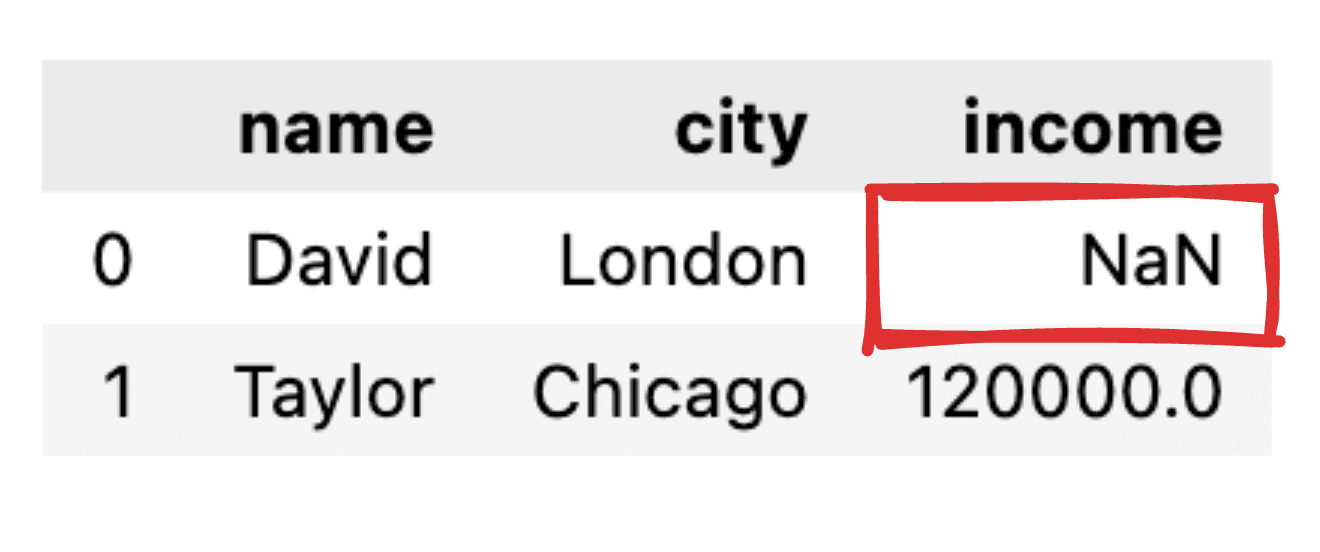
Зображення автора
А що, якщо я хочу отримати лише деякі поля?
1.3 Вибір лише тих стовпців, які вас цікавлять
Якщо ми просто хочемо перетворити деякі конкретні поля в табличний DataFrame pandas, команда json_normalize() не дозволяє нам вибрати, які поля потрібно трансформувати.
Тому слід виконати невелику попередню обробку JSON, щоб відфільтрувати лише ті стовпці, які цікавлять.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Отже, давайте перейдемо до більш просунутої структури JSON.
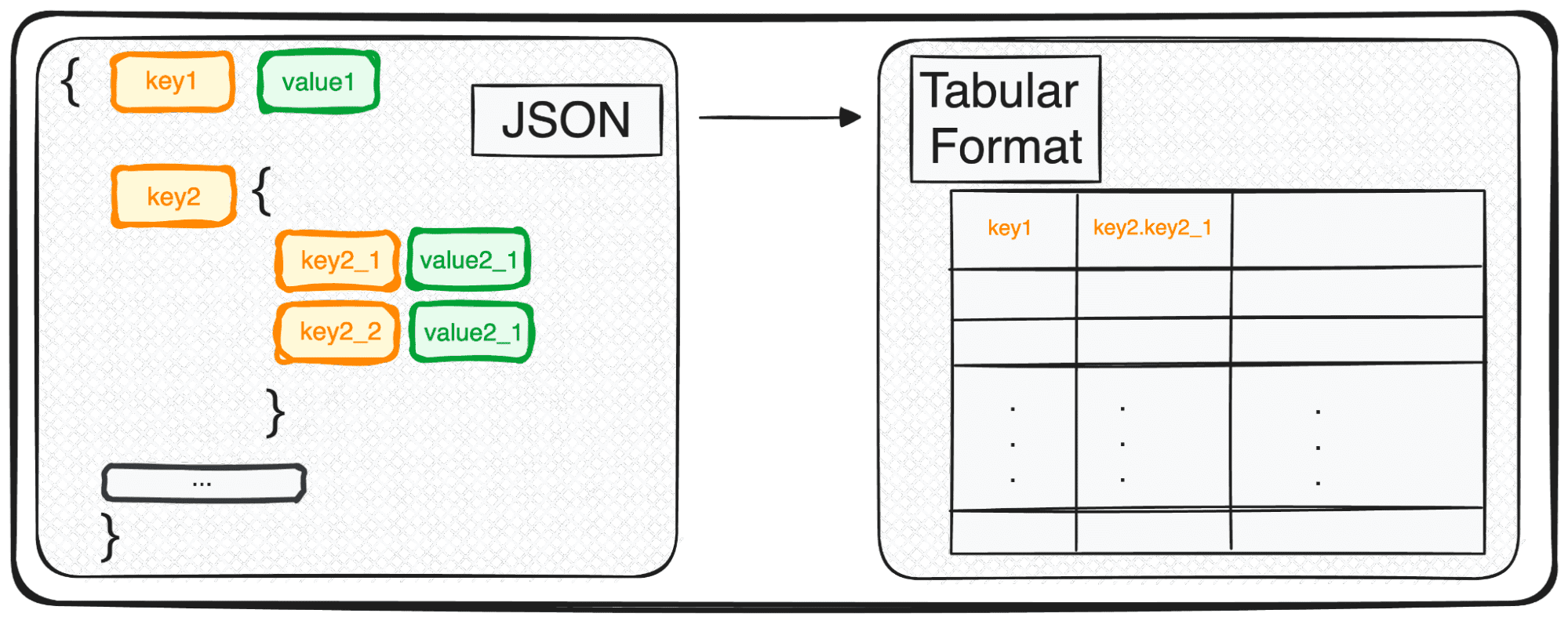
Маючи справу з багаторівневими JSON, ми опиняємося на вкладених JSON на різних рівнях. Процедура така ж, як і раніше, але в цьому випадку ми можемо вибрати, скільки рівнів ми хочемо трансформувати. За замовчуванням команда завжди розгортатиме всі рівні та створюватиме нові стовпці, що містять об’єднані назви всіх вкладених рівнів.
Отже, якщо ми нормалізуємо наступні файли JSON.
Код за автором
Ми отримаємо наступну таблицю з 3 стовпцями під польовими навичками:
- навички.python
- навички.SQL
- навички.GCP
і 4 колонки під полями ролей
- ролі.менеджер проекту
- roles.data engineer
- roles.data scientist
- roles.data аналітик

Зображення автора
Однак уявіть, що ми просто хочемо змінити свій найвищий рівень. Ми можемо зробити це, спеціально визначивши параметр max_level рівним 0 (max_level, який ми хочемо розширити).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Значення, що очікують на розгляд, зберігатимуться в JSON у нашій pandas DataFrame.
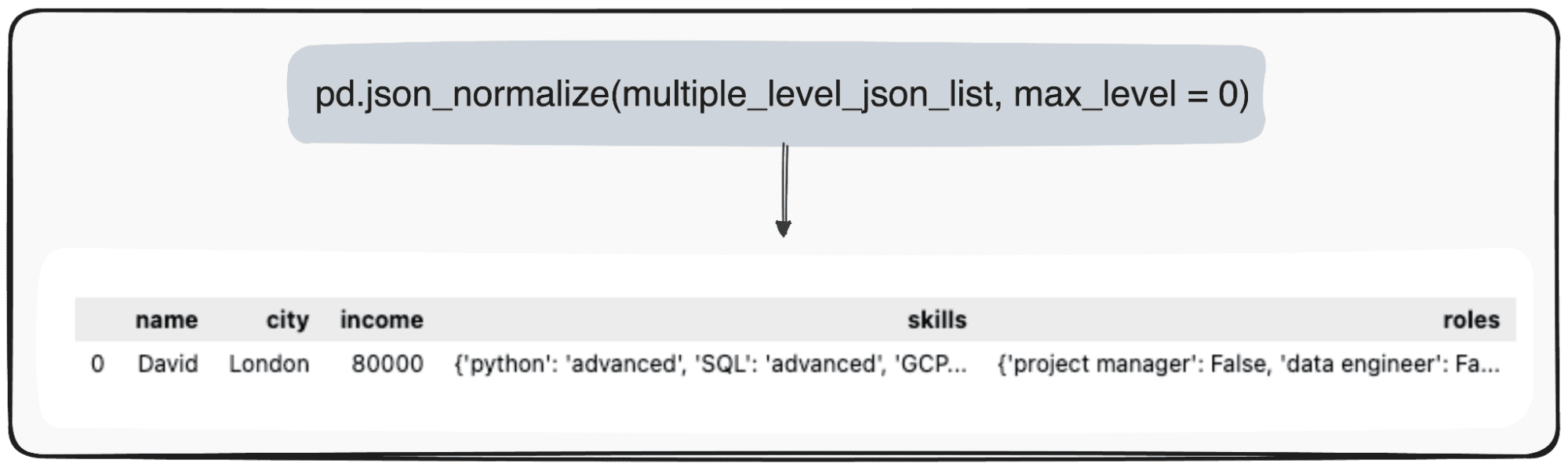
Зображення автора
Останній випадок, який ми можемо знайти, це наявність вкладеного списку в полі JSON. Отже, ми спочатку визначаємо наші JSON для використання.
Код за автором
Ми можемо ефективно керувати цими даними за допомогою Pandas у Python. Функція pd.json_normalize() особливо корисна в цьому контексті. Він може зводити дані JSON, включаючи вкладений список, у структурований формат, придатний для аналізу. Коли цю функцію застосовують до наших даних JSON, вона створює нормалізовану таблицю, яка включає вкладений список як частину своїх полів.
Крім того, Pandas пропонує можливість ще більше вдосконалити цей процес. Використовуючи параметр record_path у pd.json_normalize(), ми можемо наказати функції спеціально нормалізувати вкладений список.
Ця дія призведе до створення спеціальної таблиці для вмісту списку. За замовчуванням цей процес розгорне лише елементи зі списку. Однак, щоб збагатити цю таблицю додатковим контекстом, таким як збереження пов’язаного ідентифікатора для кожного запису, ми можемо використовувати мета-параметр.

Зображення автора
Таким чином, перетворення даних JSON у файли CSV за допомогою бібліотеки Python Pandas є простим і ефективним.
JSON досі залишається найпоширенішим форматом у сучасному сховищі та обміні даними, зокрема в базах даних NoSQL та REST API. Однак це створює деякі важливі аналітичні проблеми при роботі з даними в необробленому форматі.
Ключова роль pd.json_normalize() Pandas постає як чудовий спосіб обробки таких форматів і перетворення наших даних у pandas DataFrame.
Я сподіваюся, що цей посібник був корисним, і наступного разу, коли ви матимете справу з JSON, ви зможете зробити це більш ефективним способом.
Ви можете перевірити відповідний блокнот Jupyter у після сховища GitHub.
Хосеп Феррер – інженер-аналітик із Барселони. Він закінчив інженер-фізику та зараз працює в галузі Data Science, що стосується людської мобільності. Він неповний робочий день створює контент, який зосереджується на науці даних і технологіях. Ви можете зв'язатися з ним на LinkedIn, Twitter or Medium.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :є
- : ні
- :де
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- МЕНЮ
- дію
- Додатковий
- просунутий
- ВСІ
- дозволяти
- дозволяє
- вже
- завжди
- an
- аналіз
- аналітик
- Аналітичний
- аналітика
- та
- будь-який
- Інтерфейси
- з'являтися
- прикладної
- Застосування
- ЕСТЬ
- масив
- Art
- AS
- асоційований
- Барселона
- основний
- BE
- перед тим
- Біт
- обидва
- але
- by
- CAN
- можливості
- випадок
- проблеми
- перевірка
- Вибирати
- Місто
- Колони
- загальний
- комплекс
- ускладнення
- контакт
- зміст
- зміст
- контекст
- конвертувати
- перетворення
- відповідати
- Відповідний
- творець
- В даний час
- дані
- аналітик даних
- інженер даних
- наука про дані
- вчений даних
- зберігання даних
- базами даних
- Девід
- справу
- присвячених
- дефолт
- визначати
- визначаючи
- чудовий
- DICT
- різний
- прямий
- do
- робить
- кожен
- легко
- легко
- Ефективний
- фактично
- елементи
- виникає
- зіткнення
- інженер
- Машинобудування
- збагачувати
- по суті
- обмін
- обмін
- виключно
- Розширювати
- досвід
- пояснюючи
- дослідити
- знайомий
- кілька
- поле
- Поля
- Файли
- фільтрувати
- знайти
- Перший
- увагу
- після
- слідує
- для
- форма
- формат
- дружній
- від
- функція
- фундаментальний
- далі
- GCP
- породжувати
- отримати
- GitHub
- Go
- великий
- керівництво
- обробляти
- Обробка
- відбувається
- Мати
- має
- he
- його
- надія
- Як
- Однак
- HTTPS
- людина
- i
- Я БУДУ
- ID
- if
- картина
- імпорт
- важливо
- in
- поглиблений
- включати
- У тому числі
- Дохід
- об'єднує
- повідомив
- екземпляр
- інтерес
- в
- isn
- IT
- ЙОГО
- JavaScript
- json
- Jupyter Notebook
- просто
- KDnuggets
- ключ
- ключі
- Знати
- останній
- вивчення
- рівень
- рівні
- бібліотека
- як
- список
- трохи
- ll
- любов
- машина
- навчання за допомогою машини
- магія
- підтримується
- Робить
- управляти
- менеджер
- багато
- засоби
- Meta
- відсутній
- мобільність
- сучасний
- MongoDB
- більше
- найбільш
- рухатися
- багато
- множинний
- ім'я
- Природний
- Необхідність
- вкладений
- Нові
- наступний
- немає
- особливо
- ноутбук
- об'єкт
- отримувати
- of
- Пропозиції
- часто
- on
- ONE
- тільки
- or
- наші
- себе
- вихід
- панди
- параметр
- частина
- особливо
- в очікуванні
- ідеальний
- виконується
- Фізика
- основний
- plato
- Інформація про дані Платона
- PlatoData
- популярний
- подарунки
- ймовірно
- процедура
- процес
- випускає
- проект
- Python
- питання
- досить
- Сировина
- RE
- читання
- готовий
- запис
- облік
- удосконалювати
- Реагувати
- REST
- результати
- утримує
- право
- Роль
- s
- то ж
- наука
- Наука і технології
- вчений
- seconds
- побачити
- вибирає
- Повинен
- простий
- імітувати
- один
- навички
- невеликий
- So
- деякі
- що в сім'ї щось
- конкретний
- конкретно
- SQL
- Як і раніше
- зберігання
- зберігати
- структура
- структурований
- такі
- підходящий
- РЕЗЮМЕ
- T
- таблиця
- Технологія
- terms
- Що
- Команда
- світ
- їх
- Їх
- потім
- Ці
- це
- ті
- час
- до
- разом
- топ
- Перетворення
- Перетворення
- перетворення
- тип
- Типи
- при
- us
- використання
- корисний
- використання
- використовує
- значення
- Цінності
- хотіти
- було
- шлях..
- we
- Що
- коли
- Чи
- який
- в той час як
- волі
- з
- в
- Work
- робочий
- працює
- світ
- б
- ви
- зефірнет