
Зображення автора
Машинне навчання, безсумнівно, є яскравою зіркою нової ери. Він є основою багатьох основних технологій, які стали невід’ємною частиною нашого повсякденного життя, таких як розпізнавання облич (за підтримки згорткових нейронних мереж або CNN), розпізнавання мовлення (з використанням CNN і періодичних нейронних мереж або RNN), а також дедалі популярніших чат-ботів, як-от ChatGPT (на базі Reinforcement Learning from Human Feedback, RLHF).
Сьогодні доступні численні методи підвищення ефективності моделі машинного навчання. Ці методи можуть надати вашому проекту конкурентну перевагу, забезпечуючи чудову продуктивність.
У цьому обговоренні ми заглибимося в сферу методів вибору функцій. Але перш ніж ми продовжимо, давайте уточнимо: що саме таке вибір функцій?
Вибір функцій — це процес вибору найкращих функцій для вашої моделі. Цей процес може відрізнятися від однієї техніки до іншої, але головна мета — з’ясувати, які функції мають більший вплив на вашу модель.
Тому що іноді занадто багато функцій може зашкодити вашій моделі машинного навчання. як?
Може бути занадто багато різних причин. Наприклад, ці функції можуть бути пов’язані одна з одною, що може спричинити мультиколінеарність і погіршити продуктивність вашої моделі.
Ще одна потенційна проблема пов’язана з обчислювальною потужністю. Наявність занадто великої кількості функцій вимагає більшої обчислювальної потужності для одночасного виконання завдання, що може вимагати більше ресурсів і, як наслідок, збільшення витрат.
Звичайно, можуть бути й інші причини. Але ці приклади повинні дати вам загальне уявлення про потенційні проблеми. Однак є ще один важливий аспект, який слід зрозуміти, перш ніж ми заглибимося далі в цю тему.
Так, це чудове запитання, на яке слід відповісти перед початком проекту. Але непросто дати загальну відповідь.
Вибір моделі вибору функцій залежить від типу даних, які у вас є, і мети вашого проекту.
Наприклад, методи на основі фільтрів, такі як тест хі-квадрат або взаємне отримання інформації, зазвичай використовуються для вибору ознак у категоріальних даних. Для числових даних підходять методи на основі оболонки, такі як вибір вперед або назад.
Тим не менш, добре знати, що багато методів вибору ознак можуть обробляти як категоричні, так і числові дані.
Наприклад, ласо-регресія, дерева рішень і випадковий ліс можуть добре обробляти обидва типи даних.
З точки зору контрольованого та неконтрольованого вибору функцій, контрольовані методи, такі як рекурсивне усунення функцій або дерева рішень, підходять для мічених даних. Неконтрольовані методи, такі як аналіз головних компонентів (PCA) або аналіз незалежних компонентів (ICA), використовуються для немаркованих даних.
Зрештою, вибір методу вибору функцій має ґрунтуватися на конкретних характеристиках ваших даних і цілях вашого проекту.
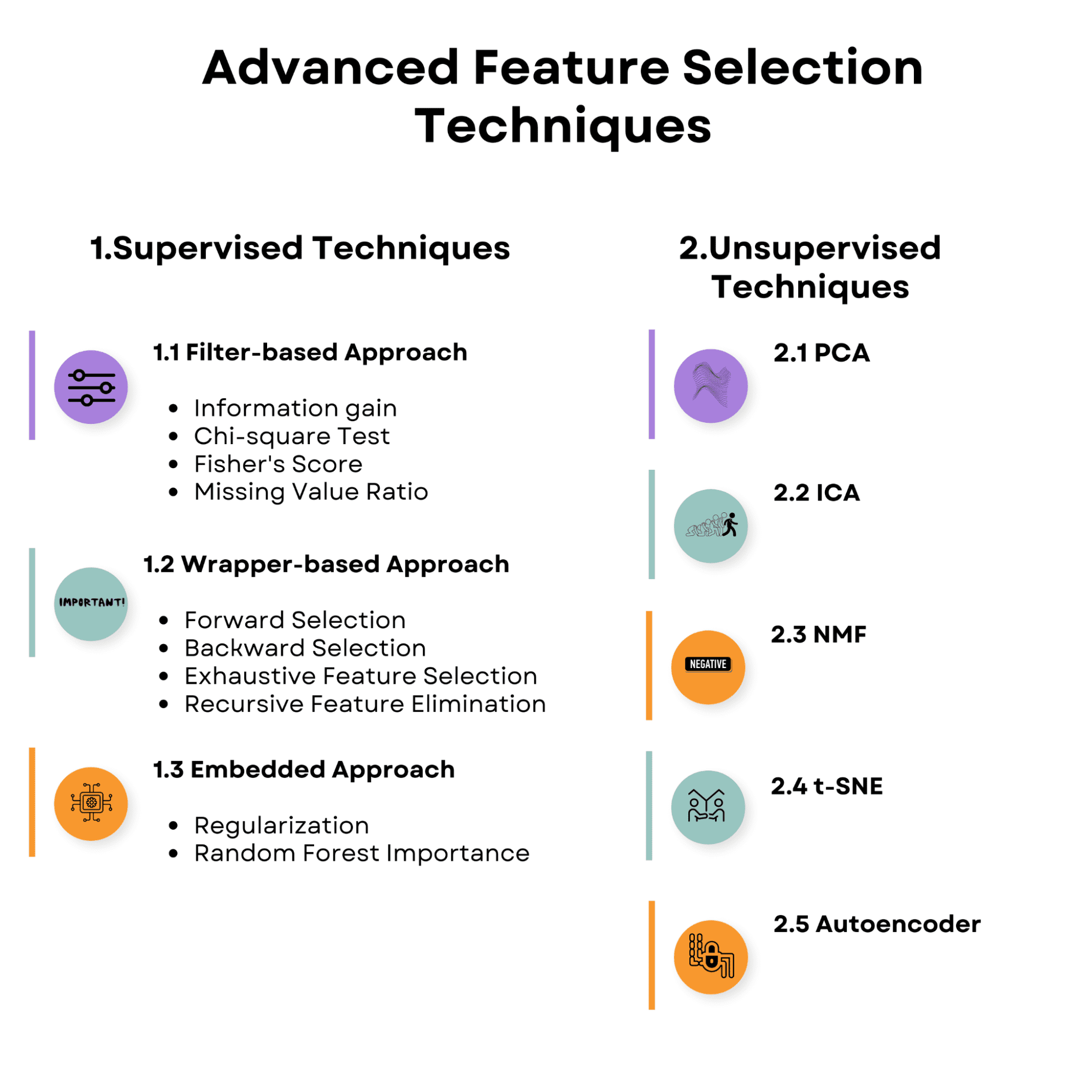
Ознайомтеся з оглядом тем, які ми обговоримо в статті. Ознайомтеся з ним і почнемо з методів вибору контрольованих функцій.
Зображення автора
Стратегії вибору ознак у контрольованому навчанні спрямовані на виявлення найбільш релевантних ознак для прогнозування цільової змінної за допомогою зв’язку між вхідними ознаками та цільовою змінною. Ці стратегії можуть допомогти покращити продуктивність моделі, зменшити переобладнання та знизити обчислювальні витрати на навчання моделі.
Ось огляд методів вибору контрольованих функцій, про які ми поговоримо.
Зображення автора
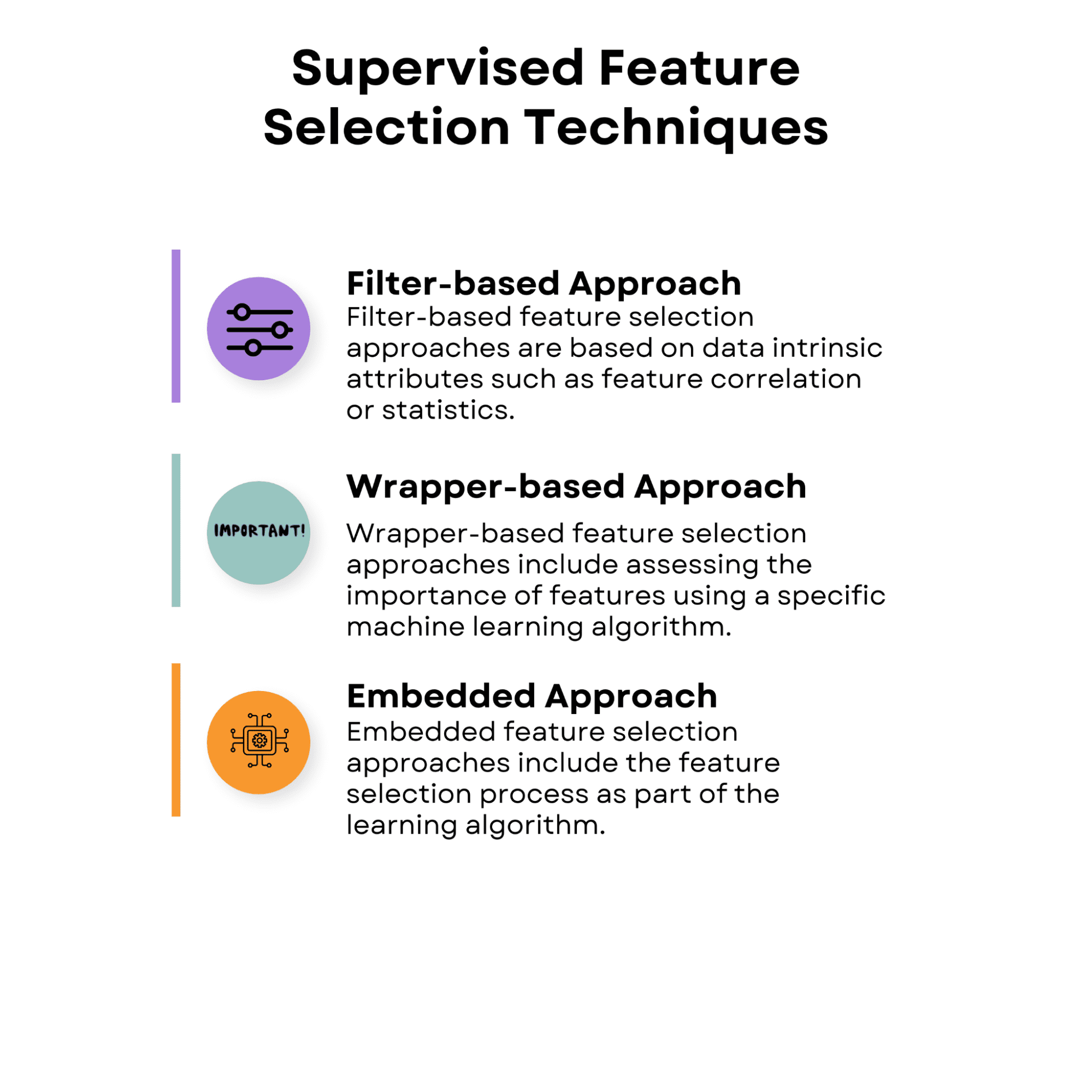
1.1 Підхід на основі фільтрів
Підходи вибору функцій на основі фільтрів базуються на внутрішніх атрибутах даних, таких як кореляція ознак або статистика. Ці підходи оцінюють значення кожної характеристики окремо або в парі без урахування продуктивності певного алгоритму навчання.
Підходи на основі фільтрів ефективні з точки зору обчислень і можуть використовуватися з різними алгоритмами навчання. Однак, оскільки вони не враховують взаємодію між функціями та методом навчання, вони не завжди можуть охопити ідеальну підмножину функцій для певного алгоритму.
Подивіться на огляд підходів на основі фільтрів, а потім ми обговоримо кожен.

Зображення автора
Приріст інформації
Інформаційний приріст – це статистика, яка вимірює зменшення ентропії (невизначеності) для конкретної функції шляхом розподілу даних відповідно до цієї характеристики. Він часто використовується в алгоритмах дерева рішень, а також має корисні функції. Чим вищий інформаційний приріст функції, тим вона корисніша для прийняття рішень.
Тепер давайте застосуємо отримання інформації за допомогою попередньо створеного набору даних про діабет.
Набір даних про діабет містить фізіологічні особливості, пов’язані з прогнозуванням прогресування діабету.
- вік: Вік у роках
- стать: стать (1 = чоловік, 0 = жінка)
- ІМТ: індекс маси тіла, розрахований як вага в кілограмах, поділена на квадрат зростання в метрах
- bp: середній артеріальний тиск (мм рт. ст.)
- s1, s2, s3, s4, s5, s6: вимірювання сироватки крові шести різних хімічних речовин крові (включно з глюкозою),
Наступний код демонструє, як застосувати метод отримання інформації. У цьому коді як приклад використовується набір даних діабету з бібліотеки sklearn.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target
Основна мета цього коду полягає в тому, щоб обчислити показники важливості функцій на основі отримання інформації, що допомагає визначити найбільш релевантні функції для прогнозної моделі. Визначаючи ці оцінки, ви можете приймати обґрунтовані рішення про те, які функції включити або виключити з аналізу, що в кінцевому підсумку призведе до покращення продуктивності моделі, зменшення переобладнання та швидшого часу навчання.
Щоб досягти цього, цей код обчислює показники отримання інформації для кожної функції в наборі даних і зберігає їх у словнику.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target # Apply Information Gain
ig = mutual_info_regression(X, y) # Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)): feature_scores[data.feature_names[i]] = ig[i]
Далі функції сортуються в порядку спадання відповідно до їхніх балів.
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True) # Print the feature importance scores and the sorted features
for feature, score in sorted_features: print('Feature:', feature, 'Score:', score)
Ми візуалізуємо відсортовані показники важливості ознак у вигляді горизонтальної гістограми, що дозволить вам легко порівняти релевантність різних функцій для даного завдання.
Ця візуалізація особливо корисна, коли вирішуєте, які функції зберегти або відкинути під час створення моделі машинного навчання.
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)") # Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]): ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
Давайте подивимося весь код.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target # Apply Information Gain
ig = mutual_info_regression(X, y) # Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)): feature_scores[data.feature_names[i]] = ig[i]
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True) # Print the feature importance scores and the sorted features
for feature, score in sorted_features: print("Feature:", feature, "Score:", score)
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)") # Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]): ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
Ось вихід.
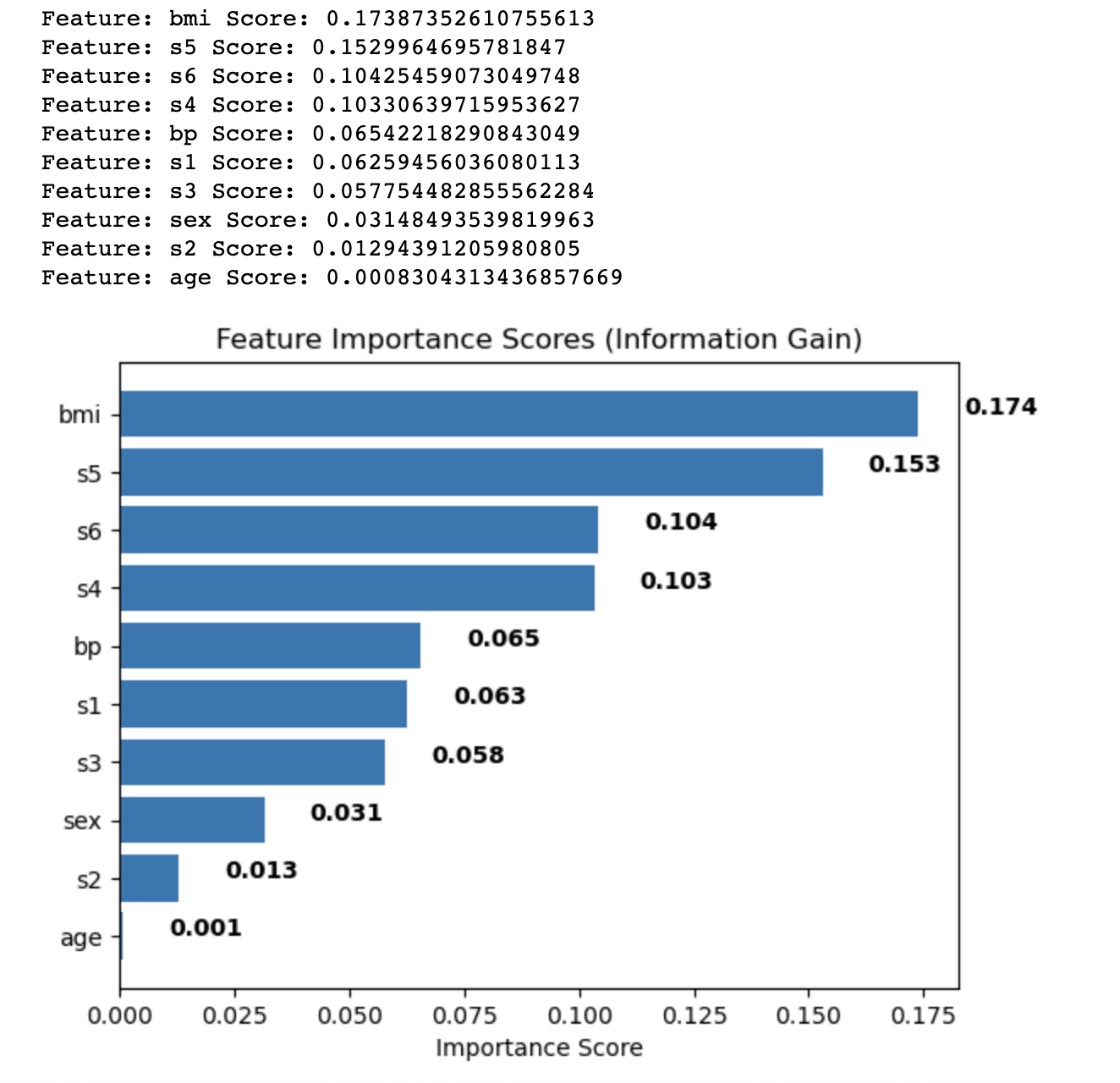
Вихідні дані показують оцінки важливості ознак, розраховані за допомогою методу отримання інформації для кожної функції в наборі даних діабету. Функції відсортовані в порядку спадання на основі їхніх балів, які вказують на їх відносну важливість у прогнозуванні цільової змінної.
Результати такі:
- Індекс маси тіла (ІМТ) має найвищу оцінку важливості (0.174), що вказує на те, що він має найбільший вплив на цільову змінну в наборі даних діабету.
- Вимірювання сироватки 5 (s5) слідує з оцінкою 0.153, що робить його другою за важливістю характеристикою.
- Вимірювання сироватки крові 6 (s6), вимірювання сироватки крові 4 (s4) і артеріальний тиск (BP) мають помірні показники важливості в діапазоні від 0.104 до 0.065.
- Решта характеристик, таких як вимірювання сироватки 1, 2 і 3 (s1, s2, s3), стать і вік, мають відносно нижчі показники важливості, що вказує на те, що вони менш сприяють прогностичній силі моделі.
Аналізуючи ці показники важливості функцій, ви можете вирішити, які функції включити або виключити з аналізу, щоб покращити продуктивність вашої моделі машинного навчання. У цьому випадку ви можете розглянути можливість збереження функцій із вищими оцінками важливості, таких як bmi та s5, водночас потенційно вилучивши або додатково дослідивши функції з нижчими оцінками, такими як вік і s2.
Тест хі-квадрат
Тест хі-квадрат — це статистичний тест, який використовується для оцінки зв’язку між двома категоріальними змінними. Він використовується при виборі ознак для аналізу зв’язку між категоріальною ознакою та цільовою змінною. Вищий показник хі-квадрат показує сильніший зв’язок між ознакою та цільовою ознакою, показуючи, що ознака важливіша для завдання класифікації.
Хоча тест Хі-квадрат є широко використовуваним методом вибору ознак, він зазвичай використовується для категоріальних даних, де ознаки та цільові змінні є дискретними.
Оцінка Фішера
Дискримінантне співвідношення Фішера, широко відоме як оцінка Фішера, — це підхід до вибору ознак, який ранжує ознаки на основі їх здатності диференціювати різні класи в наборі даних. Його можна використовувати для безперервних ознак у задачі класифікації.
Оцінка Фішера розраховується як співвідношення міжкласової та внутрішньокласової дисперсії. Вищий бал Фішера означає, що характеристика є більш дискримінаційною та цінною для класифікації.
Щоб використовувати оцінку Фішера для вибору ознак, обчисліть оцінку для кожної безперервної функції та розташуйте їх відповідно до їхніх балів. Модель вважає важливішими функції з вищим показником Фішера.
Відсутнє співвідношення вартості
Відношення відсутніх значень — це простий метод вибору функції, який приймає рішення на основі кількості відсутніх значень у функції.
Функції, які мають значну частку відсутніх значень, можуть бути неінформативними та можуть погіршити продуктивність моделі. Ви можете відфільтрувати функції із занадто великою кількістю відсутніх значень, вказавши порогове значення для прийнятного співвідношення відсутніх значень.
Щоб використати співвідношення відсутніх значень для вибору функції, виконайте такі дії:
- Обчисліть відношення відсутніх значень для кожної функції, поділивши кількість відсутніх значень на загальну кількість екземплярів у наборі даних.
- Встановіть порогове значення для прийнятного співвідношення відсутніх значень (наприклад, 0.8, що означає, що функція має мати не більше 80% своїх значень, які не враховуються).
- Відфільтруйте функції, для яких відсутнє співвідношення значень перевищує порогове значення.
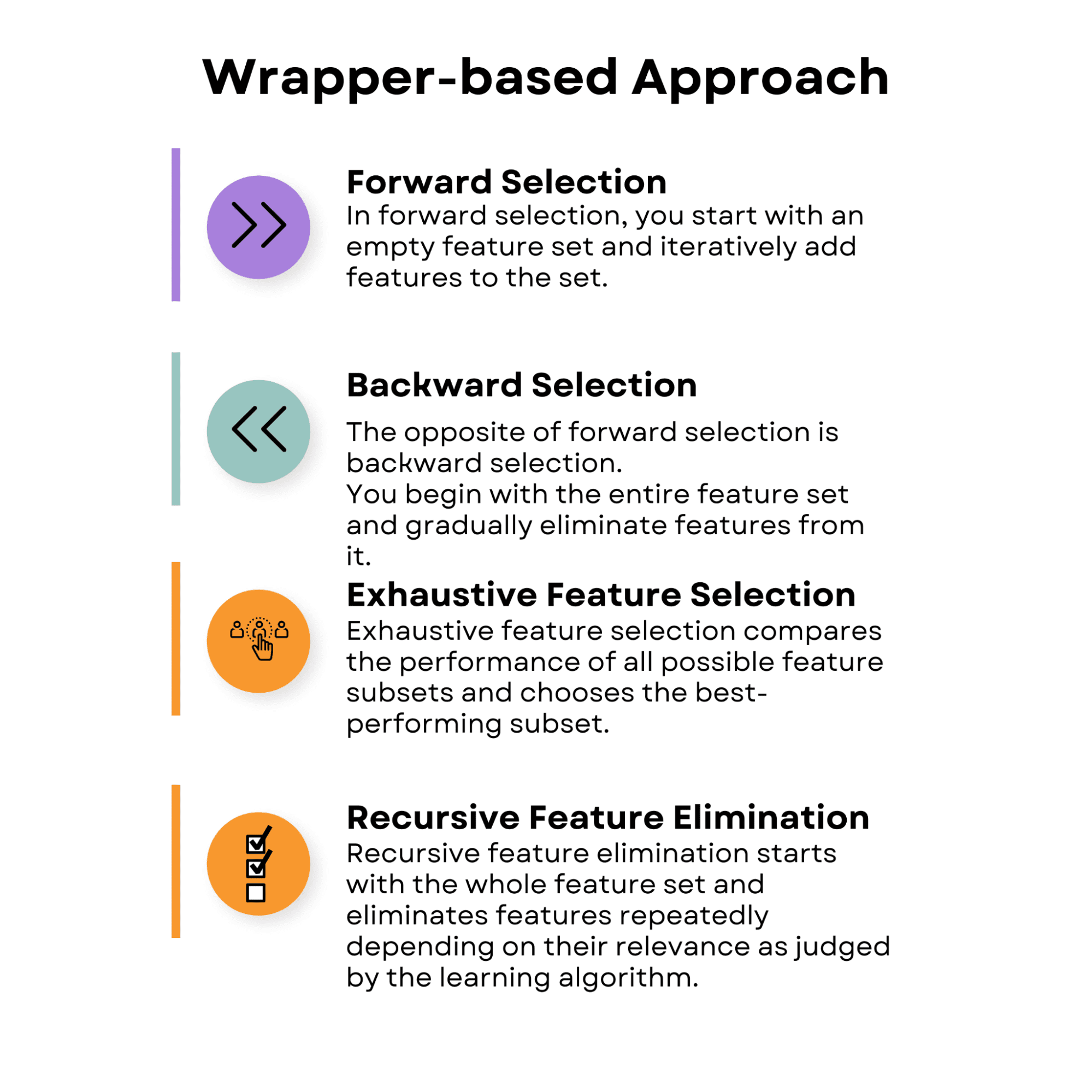
1.2 Підхід на основі оболонки
Підходи вибору функцій на основі оболонки включають оцінку важливості функцій за допомогою певного алгоритму машинного навчання. Вони шукають найкращу підмножину функцій, експериментуючи з різними комбінаціями функцій і оцінюючи їх ефективність за допомогою вибраного методу.
Через величезну кількість доступних підмножин функцій підходи на основі оболонки можуть бути дорогими з точки зору обчислень, особливо при роботі з масивами даних великої розмірності.
Однак вони часто перевершують підходи на основі фільтрів, оскільки враховують зв’язок між функціями та алгоритмом навчання.
Зображення автора
Переслати вибір
У прямому виборі ви починаєте з порожнього набору функцій і послідовно додаєте функції до набору. На кожному кроці ви оцінюєте продуктивність моделі з поточним набором функцій і додатковою функцією. До набору додається функція, яка забезпечує найкраще підвищення продуктивності.
Процес триває до тих пір, поки не буде спостерігатися значне покращення продуктивності або досягнуто попередньо визначеної кількості функцій.
Наступний код демонструє застосування прямого вибору, методу контрольованого вибору функцій на основі оболонки.
У прикладі використовується набір даних про рак молочної залози з бібліотеки sklearn. Набір даних про рак молочної залози, також відомий як набір даних Вісконсінського діагностичного раку молочної залози (WDBC), — це стандартний набір даних, який зазвичай використовується для класифікації. І тут головною метою є створення прогностичних моделей для діагностики раку молочної залози як злоякісного (ракового) або доброякісного (неракового).
Для нашої моделі ми виберемо іншу кількість функцій, щоб побачити, як відповідно змінюється продуктивність, але спочатку давайте завантажимо бібліотеки, набір даних і змінні.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target
Метою коду є ідентифікація оптимальної підмножини ознак для моделі логістичної регресії за допомогою прямого вибору. Ця методика починається з порожнього набору функцій і ітеративно додає функції, які покращують продуктивність моделі на основі визначеного показника оцінки. У цьому випадку використовується показник точності.
Наступна частина коду використовує SequentialFeatureSelector з бібліотеки mlxtend для прямого вибору. Він налаштований за допомогою моделі логістичної регресії, бажаної кількості функцій і 5-кратної перехресної перевірки. Об’єкт прямого вибору підбирається до навчальних даних, а вибрані функції друкуються.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target # Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Define the logistic regression model
model = LogisticRegression() # Define the forward selection object
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring='accuracy', cv=5) # Perform forward selection on the training set
sfs.fit(X_train, y_train)
Крім того, нам потрібно оцінити продуктивність вибраних функцій на наборі для тестування та візуалізувати продуктивність моделі з різними піднаборами функцій на лінійній діаграмі.
Діаграма показує точність перехресної перевірки як функцію кількості функцій, надаючи уявлення про компроміс між складністю моделі та прогнозованою ефективністю.
Аналізуючи вихідні дані та діаграму, ви можете визначити оптимальну кількість функцій, які слід включити у свою модель, що зрештою покращить її продуктивність і зменшить переобладнання.
# Print the selected features
print('Selected Features:', sfs.k_feature_names_) # Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print('Accuracy:', accuracy) # Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df['avg_score'] = sfs_df['avg_score'].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind='line', y='avg_score', ax=ax)
ax.set_xlabel('Number of Features')
ax.set_ylabel('Accuracy')
ax.set_title('Forward Selection Performance')
plt.show()
Ось весь код.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target # Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Define the logistic regression model
model = LogisticRegression() # Define the forward selection object
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring="accuracy", cv=5) # Perform forward selection on the training set
sfs.fit(X_train, y_train) # Print the selected features
print("Selected Features:", sfs.k_feature_names_) # Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print("Accuracy:", accuracy) # Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df["avg_score"] = sfs_df["avg_score"].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind="line", y="avg_score", ax=ax)
ax.set_xlabel("Number of Features")
ax.set_ylabel("Accuracy")
ax.set_title("Forward Selection Performance")
plt.show()
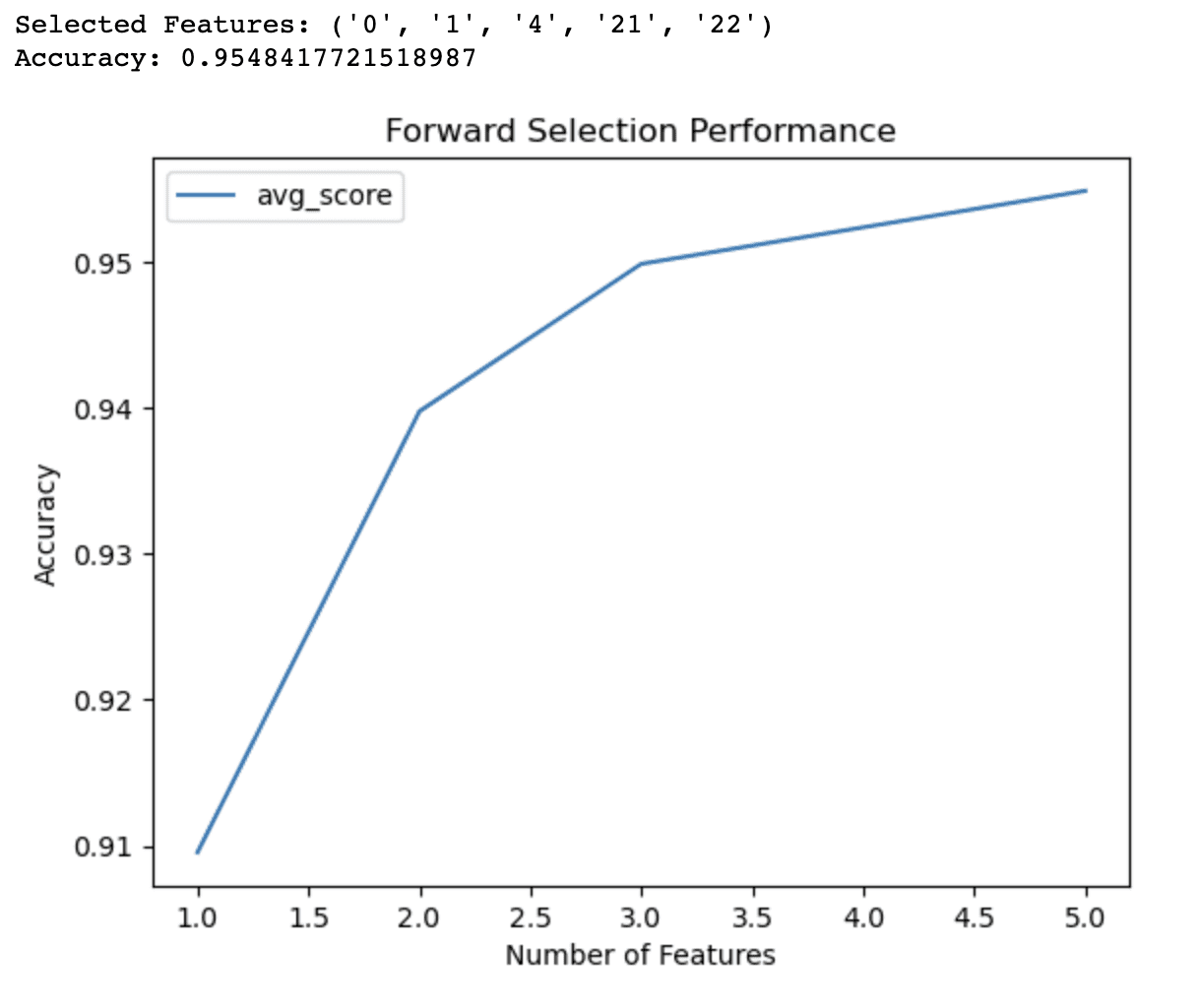
Вихід коду прямого вибору демонструє, що алгоритм визначив підмножину з 5 ознак, які дають найкращу точність (0.9548) для моделі логістичної регресії на наборі даних раку молочної залози. Ці вибрані функції ідентифікуються своїми індексами: 0, 1, 4, 21 і 22.
Лінійний графік надає додаткову інформацію про продуктивність моделі з різною кількістю функцій. Це показує, що:
- Маючи лише одну функцію, модель досягає точності близько 1%.
- Додавання другої функції підвищує точність до 94%.
- Завдяки 3 функціям точність ще більше підвищується до 95%.
- 4 функції підвищують точність трохи вище 95%.
Окрім 4 функцій, покращення точності стають менш значними. Ця інформація може допомогти вам прийняти обґрунтовані рішення щодо компромісів між складністю моделі та прогнозованою ефективністю. На основі цих результатів ви можете вирішити використовувати лише 3 або 4 функції у своїй моделі, щоб збалансувати точність і простоту.
Зворотний вибір
Протилежністю вибору вперед є вибір назад. Ви починаєте з усього набору функцій і поступово виключаєте з нього функції.
На кожному етапі вимірюєте продуктивність моделі з поточним набором функцій мінус функцію, яку потрібно видалити.
Функція, яка спричиняє найменше зниження продуктивності, виключається з набору.
Процедура повторюється до тих пір, поки не буде суттєвого збільшення продуктивності або досягнуто заданої кількості функцій.
Виділення назад і вперед класифікуються як послідовний вибір функцій; ви можете дізнатися більше тут.
Вичерпний вибір функцій
Вичерпний вибір функцій порівнює продуктивність усіх можливих підмножин функцій і вибирає найефективнішу підмножину. Цей підхід вимагає обчислень, особливо для великих наборів даних, але він забезпечує найкращу підмножину функцій.
Рекурсивне усунення ознак
Рекурсивне видалення функцій починається з усього набору функцій і усуває функції неодноразово залежно від їх відповідності, оціненої алгоритмом навчання. Найменш важлива функція видаляється на кожному кроці, а модель перенавчається. Метод повторюється до тих пір, поки не буде досягнуто задану кількість ознак.
1.3 Вбудований підхід
Підходи до вибору вбудованих функцій включають процес вибору функцій як частину алгоритму навчання.
Це означає, що протягом фази навчання алгоритм навчання не тільки оптимізує параметри моделі, але й вибирає найважливіші характеристики. Вбудовані методи можуть бути більш ефективними, ніж методи-огортки, оскільки вони не вимагають зовнішньої процедури вибору функцій.
Зображення автора
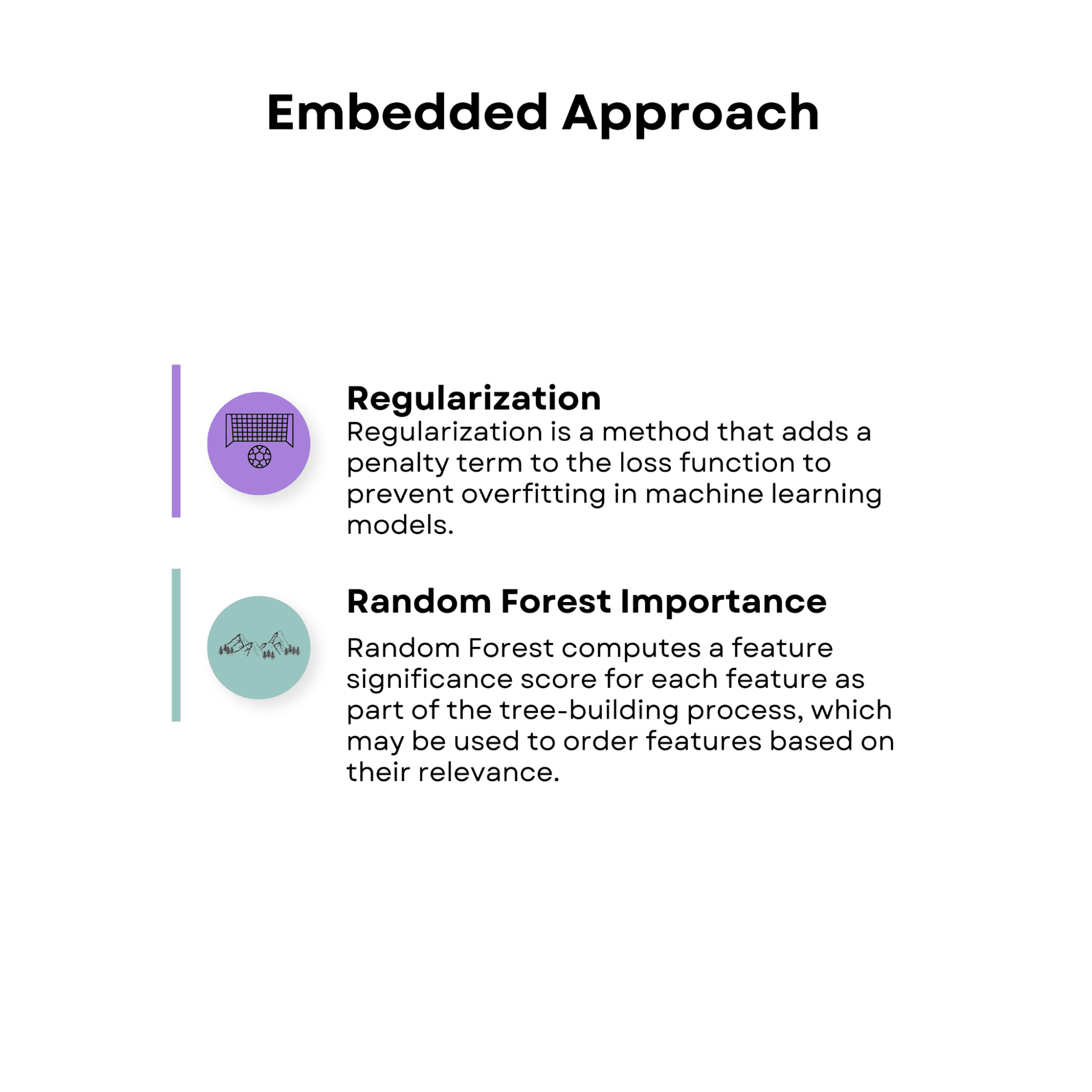
Регуляризація
Регулярізація — це метод, який додає штрафний термін до функції втрат, щоб запобігти переобладнанню в моделях машинного навчання.
Методи регулярізації, такі як ласо (регуляризація L1) і гребінь (регулярізація L2), можна використовувати разом із вибором ознак, щоб зменшити коефіцієнти менш значущих ознак до нуля, таким чином вибираючи підмножину найбільш відповідних характеристик.
Важливість випадкового лісу
Випадковий ліс — це підхід до ансамблевого навчання, який поєднує передбачення кількох дерев рішень. Випадковий ліс обчислює оцінку значущості функції для кожної функції в рамках процесу побудови дерева, який можна використовувати для впорядкування функцій на основі їх релевантності. Модель вважає ознаки з вищим рейтингом значущості більш значущими.
Якщо ви хочете дізнатися більше про випадковий ліс, ось стаття “Дерево рішень і алгоритм випадкового лісу», що також пояснює алгоритм дерева рішень.
У наступному прикладі використовується набір даних Covertype, який містить інформацію про різні типи лісового покриву.
Метою набору даних Covertype є прогнозування типу лісового покриву (домінуючих видів дерев) у Національному лісі Рузвельта Північного Колорадо.
Основною метою наведеного нижче коду є визначення важливості ознак за допомогою класифікатора випадкового лісу. Оцінюючи внесок кожної ознаки в загальну ефективність класифікації, цей метод допомагає визначити найбільш відповідні ознаки для побудови прогнозної моделі.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # Load the Covertype dataset
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None) # Assign column names
cols = ["Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways", "Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm", "Horizontal_Distance_To_Fire_Points"] + ["Wilderness_Area_"+str(i) for i in range(1,5)] + ["Soil_Type_"+str(i) for i in range(1,41)] + ["Cover_Type"] data.columns = cols
Потім ми створюємо об’єкт RandomForestClassifier і підганяємо його до навчальних даних. Потім він витягує важливість функцій із навченої моделі та сортує їх у порядку спадання. 10 найкращих функцій вибираються на основі оцінки їх важливості та відображаються в рейтингу.
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42) # Fit the model to the training data
rfc.fit(X_train, y_train) # Get feature importances from the trained model
importances = rfc.feature_importances_ # Sort the feature importances in descending order
indices = np.argsort(importances)[::-1] # Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices] # Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10 print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
Крім того, код візуалізує 10 найважливіших функцій за допомогою горизонтальної гістограми.
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align='center')
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
Ця візуалізація дозволяє легко порівнювати показники важливості та допомагає приймати обґрунтовані рішення про те, які функції включити або виключити з аналізу.
Вивчаючи вихідні дані та діаграму, ви можете вибрати найбільш релевантні функції для вашої прогнозної моделі, що може допомогти покращити її продуктивність, зменшити переобладнання та прискорити час навчання.
Ось весь код.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # Load the Covertype dataset
data = pd.read_csv( "https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None,
) # Assign column names
cols = ( [ "Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways", "Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm", "Horizontal_Distance_To_Fire_Points", ] + ["Wilderness_Area_" + str(i) for i in range(1, 5)] + ["Soil_Type_" + str(i) for i in range(1, 41)] + ["Cover_Type"]
) data.columns = cols # Split the dataset into features and target
X = data.iloc[:, :-1]
y = data.iloc[:, -1] # Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42
) # Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42) # Fit the model to the training data
rfc.fit(X_train, y_train) # Get feature importances from the trained model
importances = rfc.feature_importances_ # Sort the feature importances in descending order
indices = np.argsort(importances)[::-1] # Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices] # Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10 print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align="center")
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
Ось вихід.
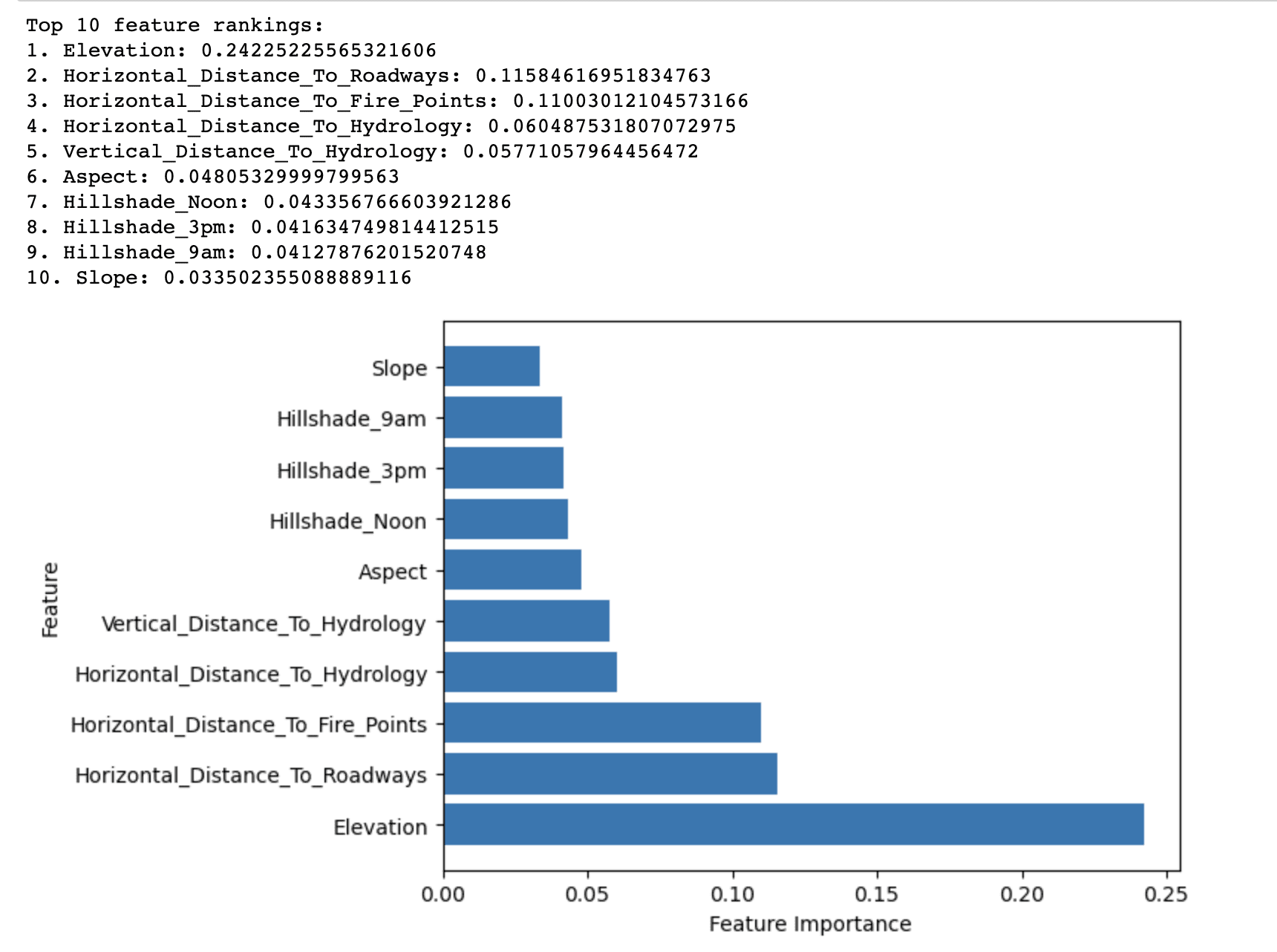
Вихідні дані методу Random Forest Importance відображають 10 найкращих ознак, упорядкованих за їхньою важливістю для прогнозування типу лісового покриву в наборі даних Covertype.
Це показує, що висота має найвищу оцінку важливості (0.2423) серед усіх ознак для прогнозування типу лісового покриву. Це свідчить про те, що висота над рівнем моря відіграє вирішальну роль у визначенні домінуючих видів дерев у Національному лісі Рузвельта.
Інші функції з відносно високою оцінкою важливості включають Horizontal_Distance_To_Roadways (0.1158) і Horizontal_Distance_To_Fire_Points (0.1100). Це свідчить про те, що близькість до доріг і осередків займання також значно впливає на тип лісового покриву.
Решта функцій у списку 10 найкращих мають відносно нижчі оцінки важливості, але вони все ще роблять внесок у загальну ефективність прогнозування моделі. Ці характеристики в основному стосуються гідрологічних факторів, індексів нахилу, висот та відтінку.
Підсумовуючи, результати підкреслюють найважливіші фактори, що впливають на розподіл типів лісового покриву в національному лісі Рузвельта, які можуть бути використані для побудови більш ефективної та дієвої прогнозної моделі для класифікації типів лісового покриву.
Якщо цільова змінна відсутня, можна використовувати підходи до неконтрольованого вибору функцій, щоб зменшити розмірність набору даних, зберігаючи його базову структуру. Ці методи часто включають зміну початкового простору ознак на новий простір нижчих розмірів, у якому змінені ознаки охоплюють більшість варіацій у даних.

Зображення автора
2.1 Аналіз основних компонентів (PCA)
PCA — це метод зменшення лінійної розмірності, який перетворює вихідний простір ознак у новий ортогональний простір, визначений головними компонентами. Ці компоненти являють собою лінійні комбінації оригінальних ознак, вибраних для фіксації найвищого рівня дисперсії в даних.
PCA можна використовувати для вибору основних k основних компонентів, що представляють більшу частину варіації, таким чином зменшуючи розмірність набору даних.
Щоб показати вам, як це працює на практиці, ми попрацюємо з набором даних Wine. Це широко використовуваний набір даних для завдань класифікації та вибору ознак у машинному навчанні. Він складається зі 178 зразків, кожен з яких представляє різні вина, що походять із трьох різних сортів в одному регіоні Італії.
Метою роботи з набором даних Wine зазвичай є створення прогнозної моделі, яка може точно класифікувати зразок вина на один із трьох сортів на основі його хімічних властивостей.
Наведений нижче код демонструє застосування аналізу основних компонентів (PCA), методу неконтрольованого вибору функцій, до набору даних Wine.
Ці компоненти (основні компоненти) фіксують найбільшу кількість відхилень у даних, мінімізуючи втрату інформації.
Код починається із завантаження набору даних Wine, який складається з 13 ознак, що описують хімічні властивості різних зразків вина.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler # Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
Потім ці функції стандартизуються за допомогою StandardScaler, щоб гарантувати, що на PCA не впливають різні масштаби вхідних функцій.
# Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
Далі PCA виконується на стандартизованих даних за допомогою класу PCA з модуля sklearn.decomposition.
# Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
Розраховується коефіцієнт поясненої дисперсії для кожного головного компонента, що вказує на частку загальної дисперсії в даних, які пояснює кожен компонент.
# Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_
Нарешті, генеруються два графіки для візуалізації відношення поясненої дисперсії та кумулятивної поясненої дисперсії за основними компонентами.
Перший графік показує відношення поясненої дисперсії для кожного окремого головного компонента, тоді як другий графік ілюструє, як кумулятивна пояснена дисперсія збільшується, коли включається більше основних компонентів.
Ці графіки допомагають визначити оптимальну кількість основних компонентів для використання в моделі, врівноважуючи компроміс між зменшенням розмірності та збереженням інформації.
# Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8)) # Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel('Principal Component')
ax1.set_ylabel('Explained Variance Ratio')
ax1.set_title('Explained Variance Ratio by Principal Component') # Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio) # Plot the cumulative explained variance in the second subplot
ax2.plot(range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker='o')
ax2.set_xlabel('Number of Principal Components')
ax2.set_ylabel('Cumulative Explained Variance')
ax2.set_title('Cumulative Explained Variance by Principal Components') # Display the figure
plt.tight_layout()
plt.show()
Давайте подивимося весь код.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler # Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names # Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled) # Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_ # Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8)) # Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel("Principal Component")
ax1.set_ylabel("Explained Variance Ratio")
ax1.set_title("Explained Variance Ratio by Principal Component") # Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio) # Plot the cumulative explained variance in the second subplot
ax2.plot( range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker="o",
)
ax2.set_xlabel("Number of Principal Components")
ax2.set_ylabel("Cumulative Explained Variance")
ax2.set_title("Cumulative Explained Variance by Principal Components") # Display the figure
plt.tight_layout()
plt.show()
Ось вихід.
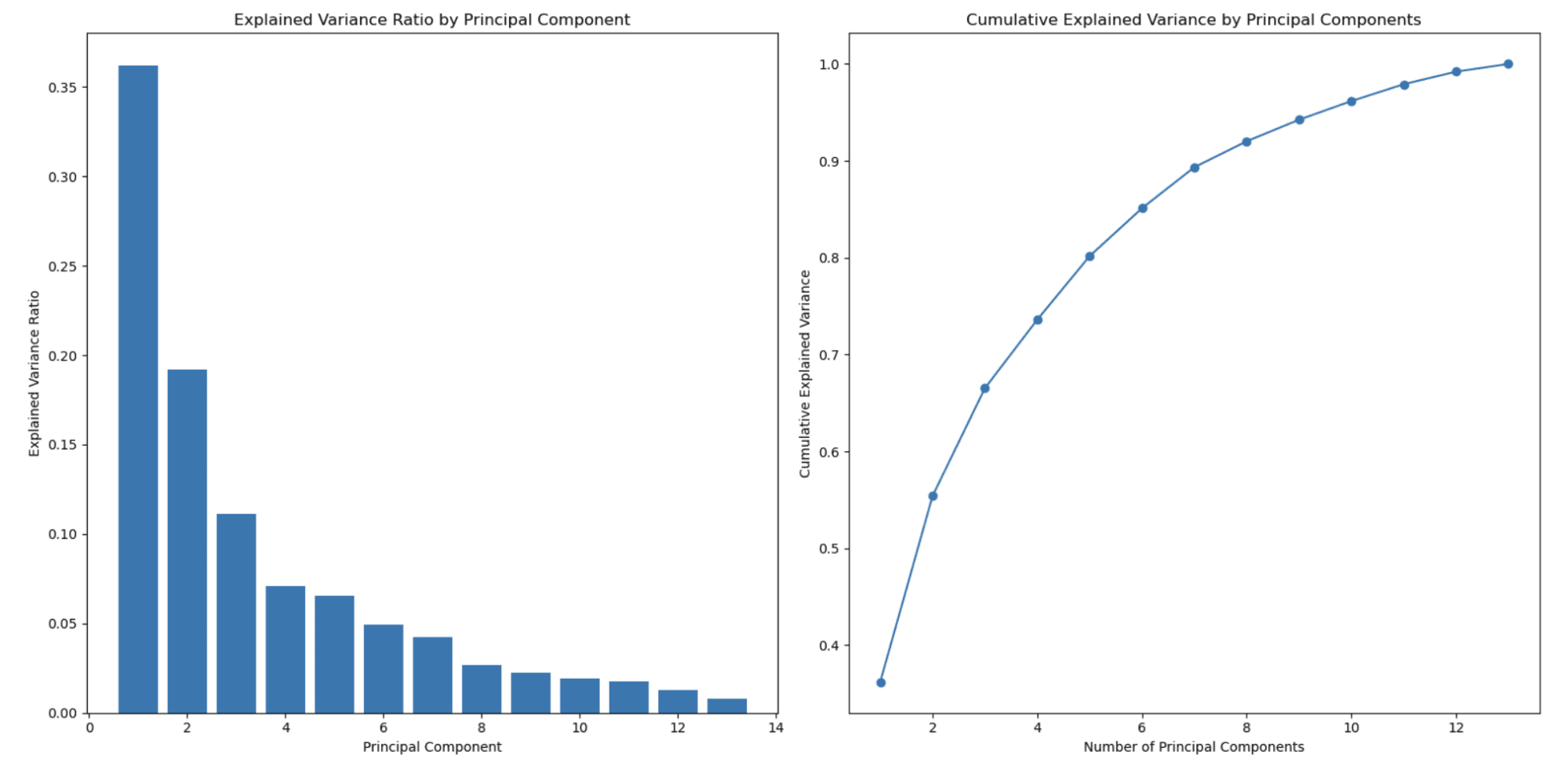
Графік ліворуч показує, що пояснений коефіцієнт дисперсії зменшується зі збільшенням кількості головних компонентів. Це типова поведінка, яка спостерігається в PCA, оскільки головні компоненти впорядковані за кількістю дисперсії, яку вони пояснюють.
Перший головний компонент (ознака) фіксує найбільшу дисперсію, другий головний компонент фіксує другу за величиною величину і так далі. У результаті пояснений коефіцієнт дисперсії зменшується з кожним наступним головним компонентом.
Це одна з основних причин використання PCA для зменшення розмірності.
Другий графік праворуч показує кумулятивну пояснену дисперсію та допомагає визначити, скільки основних компонентів (функцій) вибрати, щоб представити відсоток ваших даних. Вісь абсцис – кількість головних компонентів, а вісь у – кумулятивну пояснену дисперсію. Коли ви рухаєтеся вздовж осі х, ви можете бачити, яка частина загальної дисперсії зберігається, коли ви включаєте стільки основних компонентів.
У цьому прикладі ви бачите, що вибір приблизно 3 або 4 головних компонентів уже охоплює понад 80% загальної дисперсії, а близько 8 головних компонентів охоплює понад 90% загальної дисперсії.
Ви можете вибрати кількість головних компонентів на основі бажаного компромісу між зменшенням розмірності та дисперсією, яку ви хочете зберегти.
У цьому прикладі ми використовували Sci-kit, щоб навчитися застосовувати PCA, і тут ви можете знайти офіційний документ.
2.2 Незалежний аналіз компонентів (ICA)
ICA — це метод поділу багатовимірного сигналу на компоненти.
У контексті вибору ознак ICA можна використовувати для перетворення оригінального простору ознак у новий простір, що характеризується статистично незалежними компонентами. Ви можете зменшити розмірність набору даних, зберігаючи базову структуру, вибравши K верхніх незалежних компонентів.
2.3 Факторизація невід’ємної матриці (NMF)
Коефіцієнт невід’ємної матриці (NMF) — це підхід зменшення розмірності, який апроксимує матрицю невід’ємних даних як добуток двох невід’ємних матриць меншої розмірності.
NMF можна використовувати в контексті вибору ознак для вилучення нового набору базових ознак, які фіксують важливу структуру вихідних даних. Ви можете мінімізувати розмірність набору даних, зберігаючи при цьому обмеження на невід’ємність, вибравши перші k основних ознак.
2.4 t-розподілене стохастичне вбудовування сусідів (t-SNE)
t-SNE — це нелінійний метод зменшення розмірності, який намагається зберегти структуру набору даних шляхом зменшення різниці між попарними розподілами ймовірностей у місцях високої та низької розмірності.
t-SNE може бути застосований у виборі ознак, щоб спроектувати оригінальний простір ознак у простір нижчих розмірів, який зберігає структуру даних, дозволяючи розширену візуалізацію та оцінку.
Ви можете знайти більше інформації про неконтрольовані алгоритми та t-SNE тут "Алгоритми неконтрольованого навчання".
2.5 Автокодер
Автокодер, свого роду штучна нейронна мережа, вчиться кодувати вхідні дані в представлення нижчої розмірності, а потім декодувати їх назад до вихідної версії. Маловимірне представлення автокодувальника можна використовувати для створення іншого набору функцій, які фіксують базову структуру вихідних даних.
Підсумовуючи, вибір функцій є життєво важливим у машинному навчанні. Це допомагає зменшити розмірність даних, мінімізувати ризик переобладнання та покращити загальну продуктивність моделі. Вибір правильного методу вибору функції залежить від конкретної проблеми, набору даних і вимог до моделювання.
Ця стаття охоплює широкий спектр методів вибору функцій, включаючи контрольовані та неконтрольовані методи.
Контрольовані методи, такі як підходи на основі фільтрів, на основі оболонки та вбудовані, використовують зв’язок між функціями та цільовою змінною для визначення найважливіших функцій.
Техніки без контролю, такі як PCA, ICA, NMF, t-SNE та автокодери, зосереджуються на внутрішній структурі даних, щоб зменшити розмірність без урахування цільової змінної.
Вибираючи відповідний метод вибору функцій для вашої моделі, важливо враховувати характеристики ваших даних, основні припущення кожного методу та складність обчислень.
Ретельно вибираючи та застосовуючи правильну техніку вибору функцій, ви можете значно підвищити ефективність, сприяючи кращому розумінню та прийняттю рішень.
Нейт Розіді є фахівцем із даних та стратегією продукту. Він також є ад’юнкт-професором, який викладає аналітику, і є засновником StrataScratch, платформа, яка допомагає науковцям з даних готуватися до інтерв’ю з реальними запитаннями для інтерв’ю від провідних компаній. Зв'яжіться з ним Twitter: StrataScratch or LinkedIn.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- EVM Фінанси. Уніфікований інтерфейс для децентралізованих фінансів. Доступ тут.
- Quantum Media Group. ІЧ/ПР посилений. Доступ тут.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- джерело: https://www.kdnuggets.com/2023/06/advanced-feature-selection-techniques-machine-learning-models.html?utm_source=rss&utm_medium=rss&utm_campaign=advanced-feature-selection-techniques-for-machine-learning-models
- : має
- :є
- : ні
- :де
- 1
- 10
- 11
- 12
- 13
- 15%
- 16
- 20
- 22
- 27
- 7
- 8
- 9
- 95%
- a
- здатність
- МЕНЮ
- вище
- прискорювати
- прийнятний
- За
- відповідно
- рахунки
- точність
- точно
- Achieve
- досягнутий
- Досягає
- додавати
- доданий
- Додатковий
- Додає
- просунутий
- зачіпає
- вік
- посібник
- мета
- алгоритм
- алгоритми
- ВСІ
- Дозволити
- дозволяє
- тільки
- по
- вже
- Також
- завжди
- серед
- кількість
- an
- аналіз
- аналітика
- аналізувати
- Аналізуючи
- та
- Інший
- відповідь
- додаток
- прикладної
- Застосовувати
- Застосування
- підхід
- підходи
- відповідний
- ЕСТЬ
- навколо
- стаття
- штучний
- AS
- зовнішній вигляд
- оцінити
- Оцінювання
- припущення
- At
- Атрибути
- доступний
- середній
- назад
- Хребет
- Balance
- Балансування
- бар
- заснований
- основний
- основа
- BE
- оскільки
- ставати
- перед тим
- починати
- початок
- нижче
- КРАЩЕ
- Краще
- між
- Black
- кров
- Кров'яний тиск
- bmi
- тіло
- сміливий
- обидва
- BP
- Рак молочної залози
- будувати
- Створюємо
- але
- by
- обчислювати
- розрахований
- обчислює
- CAN
- рак
- захоплення
- захвати
- обережно
- випадок
- Викликати
- Причини
- Центр
- певний
- змінилися
- Зміни
- заміна
- характеристика
- характеристика
- характеризується
- Графік
- chatbots
- ChatGPT
- хімічний
- хімікалії
- вибір
- Вибирати
- Вибираючи
- вибраний
- клас
- класів
- класифікація
- Класифікувати
- CNN
- код
- Колорадо
- Колонка
- Колони
- COM
- комбінації
- комбінати
- зазвичай
- Компанії
- порівняти
- порівняння
- конкурентоспроможний
- складність
- компонент
- Компоненти
- обчислювальна потужність
- обчислення
- висновок
- зв'язок
- З'єднуватися
- Отже
- Вважати
- вважається
- беручи до уваги
- вважає
- складається
- містить
- контекст
- триває
- безперервний
- сприяти
- внесок
- конвертувати
- Кореляція
- Коштувати
- дорого
- витрати
- може
- обкладинка
- покритий
- створювати
- критичний
- Поточний
- щодня
- дані
- вчений даних
- набори даних
- вирішувати
- Вирішивши
- рішення
- Прийняття рішень
- дерево рішень
- рішення
- зменшити
- зменшується
- певний
- надання
- вимогливий
- демонструє
- Залежно
- залежить
- бажаний
- Визначати
- визначення
- Діабет
- DID
- відрізняються
- різниця
- різний
- диференціювати
- відкрити
- обговорювати
- обговорення
- дисплей
- дисплеїв
- розподіл
- Розподілу
- розділений
- do
- документ
- домінуючий
- e
- кожен
- легко
- легко
- край
- Ефективний
- ефективний
- або
- усунутий
- усувається
- Усуває
- вбудований
- вбудовування
- працює
- підвищувати
- підвищена
- забезпечувати
- гарантує
- Весь
- Епоха
- особливо
- Ефір (ETH)
- оцінювати
- оцінки
- оцінка
- точно
- Вивчення
- приклад
- Приклади
- виконувати
- Пояснювати
- пояснені
- Пояснює
- зовнішній
- витяг
- Виписки
- лицьової
- розпізнавання осіб
- фактор
- фактори
- знайомий
- швидше
- особливість
- риси
- зворотний зв'язок
- жінка
- Фіга
- Рисунок
- фільтрувати
- знайти
- Пожежа
- Перший
- відповідати
- Поплавок
- Сфокусувати
- стежити
- після
- слідує
- для
- ліс
- форми
- Вперед
- засновник
- від
- функція
- далі
- Отримувати
- Стать
- Загальне
- генерується
- отримати
- Давати
- даний
- мета
- Цілі
- добре
- поступово
- графік
- великий
- великий
- сітка
- обробляти
- шкодити
- Мати
- має
- he
- висота
- допомога
- корисний
- допомогу
- допомагає
- тут
- Високий
- вище
- найвищий
- Виділіть
- його
- Горизонтальний
- Як
- How To
- Однак
- HTTPS
- величезний
- людина
- i
- ICS
- ідея
- ідеальний
- ідентифікований
- ідентифікувати
- Запалювання
- ілюструє
- Impact
- Вплив
- імпорт
- значення
- важливо
- важливий аспект
- удосконалювати
- поліпшений
- поліпшення
- поліпшення
- поліпшується
- поліпшення
- in
- включати
- включені
- includes
- У тому числі
- Augmenter
- збільшений
- Збільшує
- все більше і більше
- незалежний
- індекс
- вказувати
- вказуючи
- індекси
- індивідуальний
- вплив
- інформація
- повідомив
- початковий
- вхід
- розуміння
- замість
- інтегральний
- взаємодія
- інтерв'ю
- питання інтерв'ю
- інтерв'ю
- в
- сутнісний
- залучений
- питання
- IT
- Італія
- ЙОГО
- робота
- судити
- просто
- KDnuggets
- зберігання
- Дитина
- Знати
- відомий
- l2
- етикетки
- великий
- провідний
- УЧИТЬСЯ
- вивчення
- найменш
- залишити
- менше
- рівень
- використання
- libraries
- бібліотека
- як
- обмеження
- Лінія
- LINK
- список
- Місце проживання
- ll
- загрузка
- погрузка
- місць
- подивитися
- від
- знизити
- зниження
- машина
- навчання за допомогою машини
- головний
- головним чином
- збереження
- підтримує
- основний
- Більшість
- зробити
- РОБОТИ
- Робить
- багато
- Маса
- matplotlib
- Матриця
- Може..
- сенс
- вимір
- вимір
- вимірювання
- заходи
- метод
- методика
- метрика
- може бути
- мінімізація
- відсутній
- модель
- моделювання
- Моделі
- поміркованому
- Модулі
- більше
- найбільш
- рухатися
- багато
- взаємний
- Імена
- National
- Необхідність
- мережу
- мереж
- Нейронний
- нейронної мережі
- нейронні мережі
- Нові
- наступний
- немає
- номер
- номера
- нумпі
- об'єкт
- мета
- спостерігається
- of
- офіційний
- часто
- on
- ONE
- тільки
- протилежний
- оптимальний
- Оптимізує
- or
- порядок
- оригінал
- походження
- Інше
- наші
- з
- Вищі результати
- вихід
- над
- загальний
- огляд
- пар
- панди
- параметри
- частина
- приватність
- особливо
- відсоток
- виконувати
- продуктивність
- виконується
- фаза
- вибирати
- Вибори
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- відіграє
- точок
- популярний
- це можливо
- потенціал
- потенційно
- влада
- Харчування
- практика
- передбачати
- прогнозування
- Прогнози
- Готувати
- наявність
- тиск
- запобігати
- первинний
- Головний
- друк
- ймовірність
- Проблема
- проблеми
- процес
- виробляти
- Product
- Професор
- прогресія
- проект
- Проект A
- властивості
- частка
- забезпечує
- забезпечення
- питання
- питань
- випадковий
- діапазон
- ранжування
- ранг
- Ранжування
- ряди
- рейтинги
- співвідношення
- досяг
- Читати
- реальний
- царство
- Причини
- визнання
- Рекурсивний
- зменшити
- Знижений
- зниження
- скорочення
- регіон
- регресія
- навчання
- пов'язаний
- відносини
- відносний
- щодо
- актуальність
- доречний
- решті
- Вилучено
- видалення
- повторний
- ПОВТОРНО
- представляти
- подання
- представляє
- представляє
- вимагати
- Вимога
- ресурси
- результат
- результати
- зберігати
- утримує
- утримання
- Виявляє
- право
- Risk
- Роль
- s
- користь
- то ж
- ваги
- вчений
- Вчені
- рахунок
- безліч
- другий
- побачити
- Шукати
- обраний
- вибирає
- вибір
- сироватка
- комплект
- набори
- кілька
- секс
- Повинен
- Показувати
- показ
- Шоу
- Сигнал
- значення
- значний
- істотно
- простота
- з
- SIX
- Схил
- So
- Простір
- конкретний
- зазначений
- мова
- Розпізнавання мови
- розкол
- площа
- Star
- старт
- починається
- статистичний
- статистично
- статистика
- Крок
- заходи
- Як і раніше
- магазинів
- просто
- стратегії
- Стратегія
- більш сильний
- структура
- наступні
- істотний
- такі
- Запропонує
- підходящий
- РЕЗЮМЕ
- чудовий
- контрольоване навчання
- Підтриманий
- взяття
- балаканина
- Мета
- Завдання
- завдання
- Навчання
- методи
- Технології
- термін
- terms
- тест
- Тестування
- ніж
- Що
- Команда
- інформація
- їх
- Їх
- потім
- Там.
- тим самим
- Ці
- вони
- це
- три
- поріг
- по всьому
- times
- до
- сьогодні
- занадто
- топ
- Кращі 10
- тема
- теми
- Усього:
- до
- поїзд
- навчений
- Навчання
- дерево
- Дерева
- два
- тип
- Типи
- типовий
- типово
- Зрештою
- Невизначеність
- що лежить в основі
- розуміти
- до
- використання
- використовуваний
- використовує
- використання
- зазвичай
- Цінний
- значення
- Цінності
- різноманітність
- різний
- версія
- візуалізації
- життєво важливий
- хотіти
- we
- вага
- ДОБРЕ
- Що
- коли
- який
- в той час як
- всі
- широкий
- Широкий діапазон
- широко
- волі
- ВИНО
- Вісконсін
- з
- в
- без
- Work
- робочий
- працює
- X
- років
- ще
- вихід
- ви
- вашу
- себе
- зефірнет
- нуль




