Створено за допомогою Midjourney
На конференції NeurIPS 2023, яка проходила в жвавому місті Новий Орлеан з 10 по 16 грудня, особливий акцент був зроблений на генеративному ШІ та моделях великих мов (LLM). У світлі останніх революційних досягнень у цій галузі не дивно, що ці теми домінували в дискусіях.
Однією з основних тем цьогорічної конференції був пошук ефективніших систем ШІ. Дослідники та розробники активно шукають способи створення штучного інтелекту, який не тільки навчається швидше, ніж поточні LLM, але й має розширені можливості міркування, споживаючи менше обчислювальних ресурсів. Це прагнення має вирішальне значення в гонці за досягнення загального штучного інтелекту (AGI), мети, яка здається все більш досяжною в осяжному майбутньому.
Запрошені доповіді на NeurIPS 2023 були відображенням цих динамічних інтересів, що швидко розвиваються. Доповідачі з різних сфер досліджень ШІ поділилися своїми останніми досягненнями, запропонувавши вікно в передові розробки ШІ. У цій статті ми заглибимося в ці розмови, вилучивши та обговоривши ключові висновки та знання, які є важливими для розуміння поточних і майбутніх ландшафтів інновацій ШІ.
NextGenAI: омана масштабування та майбутнє генеративного штучного інтелекту
In його розмова, Бьорн Оммер, керівник групи комп’ютерного бачення та навчання Мюнхенського університету імені Людвіга Максиміліана, поділився тим, як його лабораторія прийшла до розробки стабільної дифузії, кількома уроками, які вони винесли з цього процесу, і останніми розробками, зокрема тим, як ми можемо поєднувати моделі дифузії з зіставлення потоків, розширення пошуку та апроксимації LoRA, серед іншого.
Програма вебінару
- В епоху генеративного штучного інтелекту ми перейшли від фокусу на сприйнятті в моделях бачення (тобто розпізнавання об’єктів) до передбачення відсутніх частин (наприклад, створення зображень і відео за допомогою дифузійних моделей).
- Протягом 20 років комп’ютерний зір був зосереджений на еталонних дослідженнях, які допомагали зосередитися на найбільш значущих проблемах. У Generative AI ми не маємо жодних тестів для оптимізації, що відкриває поле для кожного, щоб рухатися у власному напрямку.
- Дифузійні моделі поєднують переваги попередніх генеративних моделей, будучи заснованими на балах зі стабільною процедурою навчання та ефективним редагуванням вибірки, але вони дорогі через довгий ланцюг Маркова.
- Проблема з моделями сильної правдоподібності полягає в тому, що більшість бітів входять у деталі, які важко помітити людське око, тоді як семантика кодування, яка має найбільше значення, займає лише кілька бітів. Лише масштабування не вирішить цю проблему, оскільки попит на обчислювальні ресурси зростає в 9 разів швидше, ніж пропозиція GPU.
- Пропоноване рішення полягає в поєднанні сильних сторін дифузійних моделей і ConvNets, зокрема ефективності згорток для представлення локальних деталей і виразності дифузійних моделей для далекого контексту.
- Бйорн Оммер також пропонує використовувати підхід узгодження потоку, щоб увімкнути синтез зображень високої роздільної здатності з невеликих моделей латентної дифузії.
- Інший підхід до підвищення ефективності синтезу зображень полягає в зосередженні на композиції сцени з використанням доповнення пошуку для заповнення деталей.
- Нарешті, він представив підхід iPoke для контрольованого стохастичного синтезу відео.
Якщо цей поглиблений вміст корисний для вас, підпишіться на наш список розсилки AI щоб отримати попередження, коли ми випускаємо новий матеріал.
Багатогранність відповідального ШІ
In її презентація, Лора Аройо, науковий співробітник Google Research, підкреслила ключове обмеження традиційних підходів до машинного навчання: їхня залежність від двійкової категоризації даних як позитивних чи негативних прикладів. Це надмірне спрощення, стверджувала вона, пропускає складну суб’єктивність, притаманну реальним сценаріям і контенту. За допомогою різних випадків використання Аройо продемонстрував, як неоднозначність вмісту та природні відмінності в людських точках зору часто призводять до неминучих розбіжностей. Вона наголосила на важливості розглядати ці розбіжності як значущі сигнали, а не просто шум.

Ось ключові висновки з розмови:
- Розбіжності між людьми можуть бути продуктивними. Замість того, щоб розглядати всі відповіді як правильні або неправильні, Лора Аройо запровадила «правду через незгоду», підхід розподілу істинності для оцінки надійності даних шляхом використання розбіжностей оцінювачів.
- Якість даних складна навіть з експертами, тому що експерти не погоджуються так само, як і натовп лаберів. Ці розбіжності можуть бути набагато інформативнішими, ніж відповіді одного експерта.
- У завданнях з оцінки безпеки експерти розходяться в 40% прикладів. Замість того, щоб намагатися вирішити ці розбіжності, нам потрібно зібрати більше таких прикладів і використовувати їх для вдосконалення моделей і показників оцінки.
- Лора Аройо також представила свої Безпека з різноманітністю метод ретельного аналізу даних з точки зору того, що в них і хто їх анотував.
- Цей метод створив порівняльний набір даних із варіативністю оцінок безпеки LLM для різних демографічних груп оцінювачів (загалом 2.5 мільйона оцінок).
- Для 20% розмов було важко визначити, чи була відповідь чат-бота безпечною чи небезпечною, оскільки була приблизно однакова кількість респондентів, які позначили їх як безпечні чи небезпечні.
- Різноманітність оцінювачів і даних відіграє вирішальну роль в оцінюванні моделей. Неможливість визнати широкий діапазон людських точок зору та неоднозначність, присутню в контенті, може перешкодити узгодженню продуктивності машинного навчання з очікуваннями реального світу.
- 80% зусиль щодо безпеки штучного інтелекту вже досить хороші, але решта 20% вимагають подвоєння зусиль для вирішення крайових випадків і всіх варіантів у нескінченному просторі різноманітності.
Статистика узгодженості, власний досвід і чому молоді люди набагато розумніші за сучасний ШІ
In її розмова, Лінда Сміт, видатний професор Університету Індіани в Блумінгтоні, дослідила тему нестачі даних у процесах навчання немовлят і дітей раннього віку. Вона особливо зосередилася на розпізнаванні об’єктів і вивченні імен, заглиблюючись у те, як статистичні дані про досвід, створений немовлятами, пропонують потенційні рішення проблеми нестачі даних.
Програма вебінару
- До трьох років у дітей розвивається здатність самостійно вивчати різні сфери. Менш ніж за 16,000 1,000 годин неспання до свого четвертого дня народження вони встигають вивчити понад XNUMX категорій предметів, освоїти синтаксис своєї рідної мови та ввібрати культурні та соціальні нюанси свого середовища.
- Доктор Лінда Сміт і її команда відкрили три принципи людського навчання, які дозволяють дітям фіксувати так багато з таких рідкісних даних:
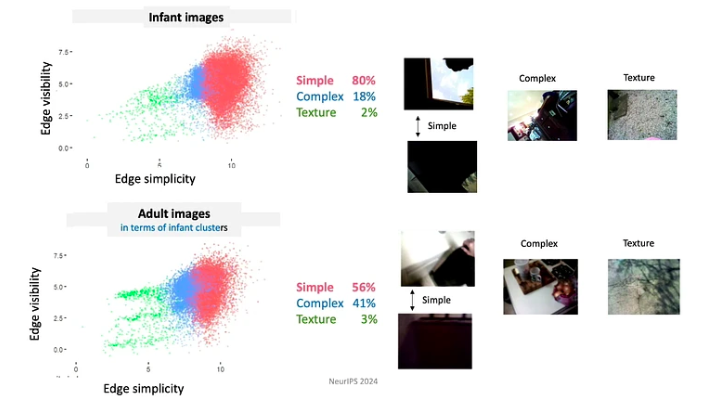
- Учні контролюють вхідні дані, момент за моментом вони формують і структурують вхідні дані. Наприклад, протягом перших кількох місяців свого життя діти схильні більше дивитися на предмети з простими краями.
- Оскільки діти постійно вдосконалюють свої знання та здібності, вони навчаються за дуже обмеженою навчальною програмою. Дані, які їм доступні, організовані дуже важливими способами. Наприклад, немовлята до 4 місяців проводять найбільше часу, дивлячись на обличчя, приблизно 15 хвилин на годину, тоді як діти старше 12 місяців зосереджуються переважно на руках, спостерігаючи за ними приблизно 20 хвилин на годину.
- Епізоди навчання складаються з серії взаємопов’язаних переживань. Просторові та часові кореляції створюють узгодженість, яка, у свою чергу, сприяє формуванню довготривалих спогадів про одноразові події. Наприклад, коли дітям пропонують випадковий асортимент іграшок, вони часто зосереджуються на кількох «улюблених» іграшках. Вони займаються цими іграшками, використовуючи повторювані шаблони, що допомагає швидше вивчати предмети.
- Перехідні (робочі) спогади зберігаються довше, ніж сенсорні дані. Властивості, які покращують процес навчання, включають мультимодальність, асоціації, прогнозні зв’язки та активацію минулих спогадів.
- Для швидкого навчання потрібен альянс між механізмами, які генерують дані, і механізмами, які навчаються.
Створення ескізів: основні інструменти, вдосконалення навчання та адаптивна надійність
Джелані Нельсон, професор електротехніки та комп’ютерних наук Каліфорнійського університету в Берклі, представив концепцію «ескізів» даних – стиснуте в пам’ять представлення набору даних, яке все ще дозволяє відповідати на корисні запити. Хоча розмова була досить технічною, вона дала чудовий огляд деяких фундаментальних інструментів для ескізів, у тому числі останніх досягнень.
Ключові висновки:
- CountSketch, основний інструмент створення ескізів, був вперше представлений у 2002 році для вирішення проблеми «сильних нападів», звітуючи про невеликий список найчастіших елементів із заданого потоку елементів. CountSketch був першим відомим сублінійним алгоритмом, використаним для цієї мети.
- Дві непотокові програми важких нападників включають:
- Метод на основі внутрішніх точок (IPM), який дає асимптотично найшвидший відомий алгоритм для лінійного програмування.
- Метод HyperAttention, який вирішує обчислювальну проблему, спричинену зростаючою складністю довгих контекстів, які використовуються в LLM.
- Значна частина останніх робіт була зосереджена на розробці ескізів, стійких до адаптивної взаємодії. Основна ідея полягає в тому, щоб використовувати інформацію з адаптивного аналізу даних.
Крім панелі масштабування
це чудова панель на великих мовних моделях модерував Олександр Раш, доцент Cornell Tech і дослідник Hugging Face. Серед інших учасників були:
- Аканкша Чоудгері – науковий співробітник Google DeepMind, який цікавиться системами, попередньою підготовкою магістра права та мультимодальністю. Вона була частиною команди, яка розробляла PaLM, Gemini та Pathways.
- Анджела Фан – науковий співробітник Meta Generative AI, яка цікавиться вирівнюванням, центрами обробки даних і багатомовністю. Брала участь у розробці Llama-2 і Meta AI Assistant.
- Персі Лянг – професор Стенфордського університету, який досліджує креаторів, відкритий вихідний код і генеративних агентів. Він є директором Центру дослідження моделей фундаментів (CRFM) у Стенфорді та засновником Together AI.
Обговорення було зосереджено на чотирьох ключових темах: (1) архітектура та інженерія, (2) дані та узгодження, (3) оцінка та прозорість і (4) автори та учасники.
Ось деякі висновки з цієї панелі:
- Навчання сучасних мовних моделей не є складним. Основна проблема під час навчання такої моделі, як Llama-2-7b, полягає у вимогах до інфраструктури та необхідності координації між декількома графічними процесорами, центрами обробки даних тощо. Однак, якщо кількість параметрів достатньо мала, щоб дозволити навчання на одному графічному процесорі, навіть студент може впоратися з цим.
- У той час як моделі авторегресії зазвичай використовуються для створення тексту, а моделі дифузії для створення зображень і відео, були експерименти зі зміною цих підходів. Зокрема, у проекті Gemini авторегресійна модель використовується для створення зображень. Були також дослідження використання дифузійних моделей для генерації тексту, але вони ще не виявилися достатньо ефективними.
- Враховуючи обмежену доступність англомовних даних для навчальних моделей, дослідники досліджують альтернативні підходи. Однією з можливостей є навчання мультимодальних моделей на поєднанні тексту, відео, зображень та аудіо з розрахунком, що навички, отримані з цих альтернативних модальностей, можуть бути перенесені в текст. Інший варіант – використання синтетичних даних. Важливо зазначити, що синтетичні дані часто змішуються з реальними даними, але ця інтеграція не є випадковою. Текст, опублікований в Інтернеті, зазвичай проходить перевірку та редагування людьми, що може додати додаткову цінність для навчання моделі.
- Відкриті фундаментальні моделі часто вважаються корисними для інновацій, але потенційно шкідливими для безпеки ШІ, оскільки їх можуть використовувати зловмисники. Однак доктор Персі Лян стверджує, що відкриті моделі також позитивно сприяють безпеці. Він стверджує, що, будучи доступними, вони надають більшій кількості дослідників можливість проводити дослідження безпеки штучного інтелекту та переглядати моделі на потенційні вразливості.
- Сьогодні анотування даних вимагає значно більше досвіду в області анотацій порівняно з п’ятьма роками тому. Однак, якщо в майбутньому помічники штучного інтелекту працюватимуть так, як очікується, ми отримуватимемо більше цінних даних зворотного зв’язку від користувачів, зменшуючи залежність від обширних даних від анотаторів.
Системи для базових моделей і базові моделі для систем
In ця розмова, Крістофер Ре, доцент кафедри комп’ютерних наук Стенфордського університету, показує, як базові моделі змінили системи, які ми створюємо. Він також досліджує, як ефективно створювати моделі основи, запозичуючи інформацію з досліджень систем баз даних, і обговорює потенційно більш ефективні архітектури для моделей основи, ніж Transformer.
Ось основні висновки з цієї розмови:
- Основні моделі ефективні у вирішенні проблем «смерті від 1000 порізів», коли кожне окреме завдання може бути відносно простим, але сама широта та різноманітність завдань є серйозною проблемою. Хорошим прикладом цього є проблема очищення даних, яку LLM тепер можуть допомогти вирішити набагато ефективніше.
- Оскільки прискорювачі стають швидшими, пам’ять часто стає вузьким місцем. Це проблема, яку дослідники баз даних вирішують десятиліттями, і ми можемо прийняти деякі з їхніх стратегій. Наприклад, підхід Flash Attention мінімізує потоки вводу-виводу через блокування та агресивне злиття: щоразу, коли ми отримуємо доступ до частини інформації, ми виконуємо над нею якомога більше операцій.
- Існує новий клас архітектур, заснований на обробці сигналів, який може бути ефективнішим, ніж модель Transformer, особливо при обробці довгих послідовностей. Обробка сигналу забезпечує стабільність і ефективність, закладаючи основу для інноваційних моделей, таких як S4.
Онлайн-навчання з підкріпленням у цифрових втручаннях у сфері охорони здоров’я
In її розмова, Сьюзен Мерфі, професор статистики та комп’ютерних наук Гарвардського університету, поділилася першими рішеннями деяких проблем, з якими вони стикаються під час розробки онлайн-алгоритмів RL для використання в цифрових втручаннях у сфері охорони здоров’я.
Ось кілька висновків із презентації:
- Доктор Сьюзен Мерфі обговорила два проекти, над якими вона працювала:
- HeartStep, де запропоновано діяльність на основі даних зі смартфонів і носимих трекерів, а також
- Oralytics для навчання здоров’ю ротової порожнини, де втручання ґрунтувалися на даних взаємодії, отриманих від електронної зубної щітки.
- Розробляючи політику поведінки агента штучного інтелекту, дослідники повинні переконатися, що вона є автономною та може бути реально реалізована в ширшій системі охорони здоров’я. Це передбачає забезпечення того, щоб час, необхідний для участі особи, був розумним, а рекомендовані дії були як етично обґрунтованими, так і науково вірогідними.
- Основні проблеми при розробці агента RL для цифрових втручань у здоров’я включають роботу з високим рівнем шуму, оскільки люди живуть своїм життям і не завжди можуть відповідати на повідомлення, навіть якщо вони цього бажають, а також керування сильними, відстроченими негативними ефектами .
Як бачите, NeurIPS 2023 дає яскравий погляд на майбутнє ШІ. Запрошені доповіді підкреслили тенденцію до більш ефективних, ресурсозберігаючих моделей і дослідження нових архітектур поза традиційними парадигмами.
Вам подобається ця стаття? Підпишіться на отримання нових оновлень щодо досліджень ШІ.
Ми повідомимо вас, коли випустимо більше таких підсумкових статей, як ця.
споріднений
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.topbots.com/neurips-2023-invited-talks/
- : має
- :є
- : ні
- :де
- $UP
- 000
- 1
- 10
- 10th
- 11
- 110
- 12
- 12 місяців
- 125
- 13
- 14
- 15%
- 154
- 16
- 16th
- 17
- 20
- 20 роки
- 2023
- 32
- 35%
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- здатність
- Здатний
- МЕНЮ
- прискорювачі
- доступ
- доступною
- Досягнення
- досягнення
- визнавати
- через
- дії
- Активація
- активно
- діяльності
- актори
- адаптивний
- додавати
- Додатковий
- адреса
- адреси
- адресація
- прийняти
- досягнення
- Переваги
- вік
- Агент
- агенти
- агресивний
- AGI
- назад
- AI
- AI помічник
- ai дослідження
- Системи ШІ
- посібник
- Олександр
- алгоритм
- алгоритми
- вирівнювання
- ВСІ
- Альянс
- дозволяти
- тільки
- вже
- Також
- альтернатива
- хоча
- завжди
- Неоднозначність
- серед
- an
- аналіз
- та
- Інший
- будь-який
- застосування
- підхід
- підходи
- приблизно
- ЕСТЬ
- сперечався
- Аргументує
- стаття
- статті
- штучний
- штучний загальний інтелект
- AS
- Оцінювання
- Помічник
- помічники
- Юрист
- асоціаціях
- асортимент
- At
- Досяжний
- увагу
- аудіо
- автономний
- наявність
- заснований
- BE
- оскільки
- ставати
- було
- поведінка
- буття
- еталонний тест
- тести
- корисний
- Берклі
- між
- За
- Blend
- суміші
- блокування
- Запозичення
- обидва
- широта
- ширше
- будувати
- але
- by
- прийшов
- CAN
- можливості
- захоплення
- випадків
- категорії
- Центр
- Центри
- ланцюг
- виклик
- проблеми
- змінилися
- Chatbot
- діти
- Крістофер
- Місто
- клас
- Очищення
- тренування
- збирати
- поєднання
- об'єднувати
- порівняний
- комплекс
- складність
- склад
- обчислювальна
- комп'ютер
- Інформатика
- Комп'ютерне бачення
- обчислення
- концепція
- Проводити
- конференція
- будувати
- зміст
- контекст
- контексти
- безперестанку
- сприяти
- Автори
- контроль
- контроль
- розмови
- координувати
- Core
- Корнелл
- виправити
- кореляції
- може
- створювати
- Творці
- натовп
- вирішальне значення
- культурний
- курація
- Поточний
- Програма
- передовий
- дані
- аналіз даних
- центрів обробки даних
- Database
- справу
- десятиліття
- Грудень
- вирішувати
- Deepmind
- Затримується
- заглиблюватися
- Попит
- запити
- демографічний
- продемонстрований
- відділ
- проектування
- деталь
- деталі
- розвивати
- розвиненою
- розробників
- розвивається
- розробка
- події
- важкий
- радіомовлення
- цифровий
- Цифрове здоров'я
- напрям
- Директор
- відкритий
- обговорювалися
- обговорення
- обговорення
- обговорення
- Видатний
- різноманітність
- домен
- домени
- домінують
- Не знаю
- подвоєння
- dr
- два
- під час
- динамічний
- e
- кожен
- край
- редагування
- Ефективний
- ефекти
- ефективність
- ефективний
- продуктивно
- зусилля
- зусилля
- або
- електротехніка
- Electronic
- виникає
- акцент
- підкреслив
- включіть
- дозволяє
- кодування
- займатися
- зачеплення
- Машинобудування
- підвищувати
- підвищена
- досить
- забезпечувати
- забезпечення
- Навколишнє середовище
- Епізоди
- рівним
- особливо
- істотний
- і т.д.
- Ефір (ETH)
- оцінки
- оцінка
- Навіть
- Події
- все
- еволюціонувати
- еволюціонує
- приклад
- Приклади
- відмінно
- очікування
- очікування
- очікуваний
- дорогий
- досвід
- Досліди
- Експерименти
- експерт
- експертиза
- experts
- експлуатований
- дослідження
- Розвіданий
- досліджує
- Дослідження
- піддаватися
- обширний
- очей
- Face
- особи
- полегшує
- відсутності
- вентилятор
- швидше
- швидкий
- зворотний зв'язок
- кілька
- менше
- поле
- заповнювати
- Перший
- п'ять
- спалах
- потік
- Потоки
- Сфокусувати
- увагу
- стежити
- для
- передбачуваний
- освіта
- фонд
- засновник
- чотири
- Четвертий
- частий
- часто
- від
- фундаментальний
- злиття
- майбутнє
- Майбутнє ШІ
- Близнюки
- Загальне
- загальний інтелект
- породжувати
- породжує
- покоління
- генеративний
- Генеративний ШІ
- даний
- дає
- Проблиск
- Go
- мета
- добре
- GPU
- Графічні процесори
- новаторський
- Group
- Групи
- Зростання
- було
- Обробка
- Руки
- шкідливий
- Запрягання
- Гарвард
- Гарвардський університет
- Мати
- he
- голова
- здоров'я
- охорона здоров'я
- важкий
- Герой
- допомога
- допоміг
- її
- Високий
- висока роздільна здатність
- Виділено
- дуже
- перешкода
- його
- годину
- ГОДИННИК
- Як
- How To
- Однак
- HTTP
- HTTPS
- людина
- Людей
- i
- ідея
- if
- освітлюючи
- зображення
- генерація зображень
- зображень
- реалізовані
- значення
- важливо
- удосконалювати
- in
- поглиблений
- включати
- включені
- У тому числі
- зростаючий
- все більше і більше
- Індіана
- індивідуальний
- неминучий
- інформація
- інформативний
- Інфраструктура
- притаманне
- за своєю суттю
- інновація
- інноваційний
- вхід
- розуміння
- екземпляр
- замість
- інтеграція
- Інтелект
- взаємодія
- взаємопов'язані
- інтереси
- втручання
- в
- введені
- запрошений
- IT
- пунктів
- JPG
- судження
- ключ
- Знати
- знання
- відомий
- lab
- маркування
- мова
- великий
- міцний
- останній
- укладка
- вести
- провідний
- УЧИТЬСЯ
- вчений
- учнів
- вивчення
- Legacy
- менше
- Уроки
- дозволяти
- рівні
- лежить
- світло
- як
- ймовірність
- обмеження
- обмеженою
- Лінда
- список
- Місце проживання
- місцевий
- Довго
- довше
- подивитися
- шукати
- машина
- навчання за допомогою машини
- розсилки
- головний
- управляти
- управління
- багато
- майстер
- узгодження
- матеріал
- Питання
- макс-ширина
- Може..
- значущим
- механізми
- пам'яті
- пам'ять
- меров
- повідомлення
- Meta
- метод
- Метрика
- може бути
- мільйона
- мінімізує
- протокол
- відсутній
- модальності
- модель
- Моделі
- момент
- місяців
- більше
- більш ефективний
- найбільш
- переїхав
- багато
- множинний
- Мюнхен
- повинен
- ім'я
- рідний
- Природний
- Необхідність
- негативний
- NeurIPS
- Нові
- Новий Орлеан
- немає
- шум
- ніхто
- увагу
- роман
- зараз
- нюанси
- номер
- об'єкт
- об'єкти
- of
- пропонувати
- пропонує
- Пропозиції
- часто
- старший
- on
- ONE
- онлайн
- тільки
- відкрити
- з відкритим вихідним кодом
- відкритий
- операції
- Можливості
- Оптимізувати
- варіант
- or
- усний
- Оральне здоров'я
- Організований
- Орлеан
- Інше
- Інші учасники
- інші
- наші
- над
- огляд
- власний
- долоню
- панель
- парадигми
- параметри
- частина
- Учасники
- участь
- приватність
- особливо
- частини
- Минуле
- шляхів
- моделі
- Люди
- для
- сприйняття
- виконувати
- продуктивність
- перспективи
- частина
- plato
- Інформація про дані Платона
- PlatoData
- правдоподібний
- відіграє
- політика
- поставлений
- позитивний
- позитивно
- володіє
- можливість
- це можливо
- потенціал
- потенційно
- прогнозування
- інтелектуального
- представити
- Presentation
- представлений
- попередній
- в першу чергу
- первинний
- Принципи
- Проблема
- проблеми
- процедура
- процес
- процеси
- обробка
- Вироблений
- продуктивний
- Професор
- глибоко
- Програмування
- проект
- проектів
- видатний
- властивості
- доведений
- забезпечувати
- за умови
- опублікований
- мета
- переслідування
- якість
- запити
- пошук
- досить
- Гонки
- випадковий
- діапазон
- швидко
- швидко
- швидше
- рейтинги
- реальний
- Реальний світ
- розумний
- отримати
- отримано
- останній
- визнання
- рекомендований
- зниження
- відображення
- навчання
- відносини
- щодо
- звільнити
- надійність
- опора
- решті
- повторювані
- Звітність
- подання
- представляє
- вимагати
- вимагається
- Вимога
- дослідження
- дослідник
- Дослідники
- рішення
- ресурси
- Реагувати
- респонденти
- відповідь
- відповіді
- відповідальний
- огляд
- міцний
- Роль
- Коріння
- грубо
- порив
- сейф
- Безпека
- Масштабування
- сценарії
- сцена
- наука
- НАУКИ
- вчений
- побачити
- пошук
- Здається,
- бачив
- семантика
- Серія
- формуючи
- загальні
- вона
- Шоу
- підпис
- Сигнал
- сигнали
- значний
- істотно
- простий
- один
- навички
- невеликий
- розумнішими
- смартфонів
- коваль
- So
- соціальна
- рішення
- Рішення
- ВИРІШИТИ
- деякі
- Звучати
- Source
- Простір
- просторовий
- конкретно
- витрачати
- Стабільність
- стабільний
- Станфорд
- Стенфордський університет
- статистика
- Як і раніше
- стратегії
- потік
- сильні сторони
- сильний
- структурування
- такі
- Запропонує
- РЕЗЮМЕ
- поставка
- сюрприз
- Сьюзен
- синтаксис
- синтез
- синтетичний
- синтетичні дані
- система
- Systems
- Takeaways
- приймає
- балаканина
- Переговори
- Завдання
- завдання
- команда
- технології
- технічний
- як правило,
- terms
- текст
- генерація тексту
- ніж
- Що
- Команда
- Майбутнє
- їх
- Їх
- Теми
- Там.
- Ці
- вони
- це
- ті
- три
- через
- час
- до
- разом
- інструмент
- інструменти
- ТОПБОТИ
- тема
- теми
- Усього:
- до
- трекери
- традиційний
- Навчання
- переклад
- трансформатор
- прозорість
- лікування
- Trend
- Правда
- намагається
- ПЕРЕГЛЯД
- два
- типово
- при
- зазнає
- розуміння
- університет
- Updates
- використання
- використовуваний
- користувачі
- використання
- зазвичай
- використовувати
- Цінний
- значення
- різноманітність
- різний
- вібруючий
- Відео
- Відео
- точки зору
- бачення
- Уразливості
- W3
- було
- способи
- we
- придатний для носіння
- ДОБРЕ
- були
- Що
- коли
- коли б ні
- в той час як
- Чи
- який
- в той час як
- ВООЗ
- чому
- широкий
- Широкий діапазон
- волі
- вікно
- з
- Work
- робочий
- Неправильно
- років
- ще
- ви
- молодий
- зефірнет