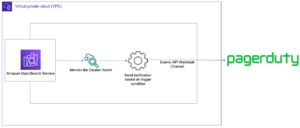
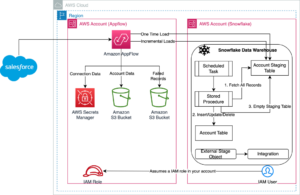
Як практично всі клієнти, ви хочете витрачати якомога менше, отримуючи при цьому найкращу продуктивність. Це означає, що вам потрібно звернути увагу на співвідношення ціни та якості. с Амазонська червона зміна, ти теж можеш отримати свій торт і з’їсти його! Amazon Redshift забезпечує до 4.9 разів нижчу вартість на користувача та до 7.9 разів кращу ціну-продуктивність, ніж інші хмарні сховища даних у реальних робочих навантаженнях, використовуючи передові методи, як-от масштабування паралельного доступу для підтримки сотень одночасних користувачів, покращене кодування рядків для швидшої роботи запитів. , і Amazon Redshift без сервера підвищення продуктивності. Читайте далі, щоб зрозуміти, чому ціна-продуктивність має значення та як Amazon Redshift ціна-продуктивність є мірою того, скільки коштує отримати певний рівень робочого навантаження, а саме продуктивність ROI (повернення інвестицій).
Оскільки і ціна, і продуктивність беруть участь у розрахунку ціна-ефективність, є два способи думати про ціну-ефективність. Перший спосіб — підтримувати ціну незмінною: якщо у вас є 1 долар, який можна витратити, яку продуктивність ви отримаєте від свого сховища даних? База даних із кращим співвідношенням ціна-ефективність забезпечить кращу продуктивність за кожен витрачений 1 долар США. Таким чином, утримуючи ціну незмінною під час порівняння двох сховищ даних, які коштують однаково, база даних із кращою ціною та ефективністю виконуватиме ваші запити швидше. Другий спосіб поглянути на співвідношення ціна-ефективність — підтримувати продуктивність незмінною: якщо вам потрібно, щоб ваше робоче навантаження завершилося за 10 хвилин, скільки це буде коштувати? База даних із кращим співвідношенням ціна-ефективність виконає ваше робоче навантаження за 10 хвилин за нижчої вартості. Таким чином, якщо продуктивність залишається незмінною під час порівняння двох сховищ даних, розмір яких забезпечує однакову продуктивність, база даних із кращим співвідношенням ціна-продуктивність коштуватиме менше та заощадить ваші гроші.
Нарешті, ще один важливий аспект співвідношення ціни та ефективності – передбачуваність. Для планування важливо знати, скільки коштуватиме ваше сховище даних із зростанням кількості користувачів сховища даних. Він має не лише забезпечувати найкраще співвідношення ціна-продуктивність сьогодні, але й передбачувано масштабуватися та забезпечувати найкраще співвідношення ціни та продуктивності, коли додається більше користувачів і робочих навантажень. Ідеальне сховище даних повинно мати лінійний масштаб— масштабування вашого сховища даних для надання вдвічі більшої пропускної здатності запитів в ідеалі має коштувати вдвічі дорожче (або менше).
У цій публікації ми ділимося результатами продуктивності, щоб проілюструвати, як Amazon Redshift забезпечує значно кращі ціни та продуктивність порівняно з провідними альтернативними хмарними сховищами даних. Це означає, що якщо ви витратите на Amazon Redshift таку ж суму, як і на одне з цих інших сховищ даних, ви отримаєте кращу продуктивність із Amazon Redshift. Крім того, якщо ви налаштуєте кластер Redshift, щоб забезпечити таку саму продуктивність, ви побачите нижчі витрати порівняно з цими альтернативами.
Ціна-продуктивність для реальних робочих навантажень
Ви можете використовувати Amazon Redshift для забезпечення найрізноманітніших робочих навантажень, від пакетної обробки складних звітів на основі вилучення, перетворення та завантаження (ETL) і потокової аналітики в реальному часі до інформаційних панелей бізнес-аналітики (BI) з низькою затримкою, які потрібно обслуговувати сотні чи навіть тисячі користувачів одночасно з часом відповіді до секунди, і все між ними. Один із способів постійного покращення співвідношення ціна-ефективність для наших клієнтів — це постійний перегляд телеметрії про продуктивність програмного та апаратного забезпечення від парку Redshift, пошук можливостей і варіантів використання клієнтами, де ми можемо ще більше покращити продуктивність Amazon Redshift.
Кілька останніх прикладів оптимізації продуктивності за допомогою телеметрії парку включають:
- Оптимізація рядкових запитів – Проаналізувавши, як Amazon Redshift обробляє різні типи даних у групі Redshift, ми виявили, що оптимізація запитів із великою кількістю рядків значно покращить робоче навантаження наших клієнтів. (Ми обговоримо це більш детально далі в цій публікації.)
- Автоматизовані матеріалізовані перегляди – Ми виявили, що клієнти Amazon Redshift часто виконують багато запитів, які мають загальні шаблони підзапитів. Наприклад, кілька різних запитів можуть об’єднати ті самі три таблиці за допомогою однієї умови з’єднання. Тепер Amazon Redshift може автоматично створювати та підтримувати матеріалізовані подання, а потім прозоро переписувати запити, щоб використовувати матеріалізовані подання за допомогою машинного навчання. автоматизований матеріалізований вигляд функція автономності в Amazon Redshift. Якщо ввімкнено, автоматичні матеріалізовані перегляди можуть прозоро підвищити продуктивність запитів для повторюваних запитів без втручання користувача. (Зверніть увагу, що автоматизовані матеріалізовані перегляди не використовувалися в жодному з результатів порівняльного тесту, які обговорюються в цій публікації).
- Робочі навантаження з високим рівнем паралелізму – Ми бачимо, що все частіше використовують Amazon Redshift для обслуговування робочих навантажень, схожих на інформаційну панель. Ці робочі навантаження характеризуються бажаним часом відповіді на запити, що становить одну цифру секунд або менше, із десятками чи сотнями одночасних користувачів, які одночасно виконують запити з гострою та часто непередбачуваною моделлю використання. Прототиповим прикладом цього є інформаційна панель BI, що підтримується Amazon Redshift, яка має сплеск трафіку в понеділок вранці, коли велика кількість користувачів починає свій тиждень.
Зокрема, робочі навантаження з високим рівнем паралелізму мають дуже широке застосування: більшість робочих навантажень сховищ даних працюють у режимі паралельності, і нерідко сотні чи навіть тисячі користувачів виконують запити в Amazon Redshift одночасно. Amazon Redshift розроблено для забезпечення передбачуваності та швидкості часу відповіді на запити. Redshift Serverless робить це автоматично за вас, додаючи та видаляючи обчислення за потреби, щоб забезпечити швидкий і передбачуваний час відповіді на запити. Це означає, що інформаційна панель із підтримкою Redshift Serverless, яка швидко завантажується, коли до неї звертаються один або два користувачі, продовжуватиме завантажуватися швидко, навіть якщо багато користувачів завантажують її одночасно.
Щоб змоделювати цей тип робочого навантаження, ми використали тест, отриманий від TPC-DS із набором даних 100 ГБ. TPC-DS — це галузевий стандартний тест, який включає низку типових запитів до сховищ даних. У цьому відносно невеликому масштабі в 100 ГБ запити в цьому тесті виконуються на Redshift Serverless в середньому за кілька секунд, що відповідає очікуванням користувачів, які завантажують інтерактивну інформаційну панель BI. Ми провели від 1 до 200 одночасних тестів цього тесту, імітуючи від 1 до 200 користувачів, які намагалися завантажити інформаційну панель одночасно. Ми також повторили тест на кількох популярних альтернативних хмарних сховищах даних, які також підтримують автоматичне масштабування (якщо ви знайомі з публікацією Amazon Redshift зберігає лідерство за ціною та ефективністю, ми не включили конкурента А, оскільки він не підтримує автоматичне збільшення). Ми виміряли середній час відповіді на запит, тобто скільки часу користувач чекатиме завершення запитів (або завантаження інформаційної панелі). Результати показані на наступній діаграмі.
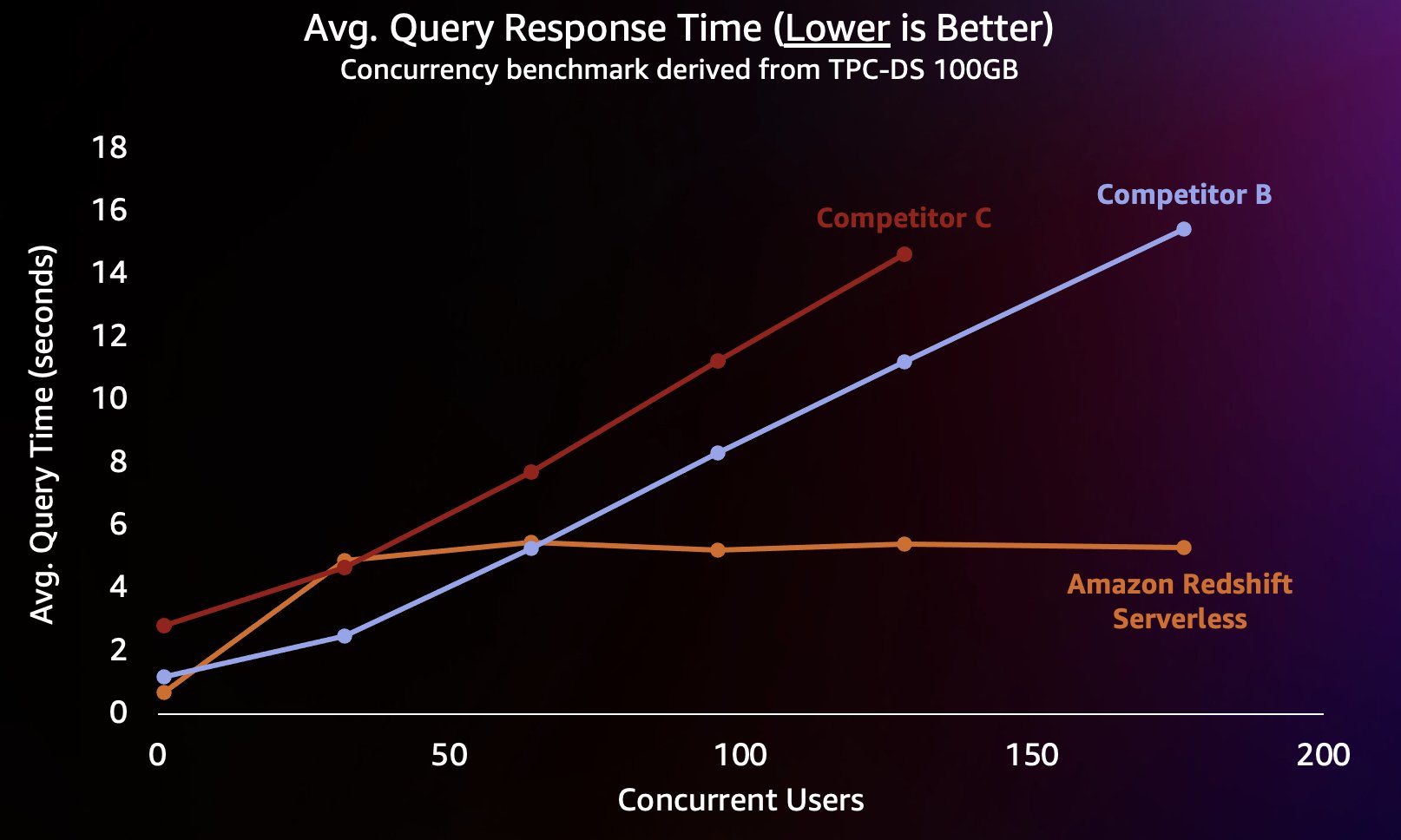
Конкурент B добре масштабується до приблизно 64 одночасних запитів, після чого він не може забезпечити додаткові обчислення, і запити починають стояти в черзі, що призводить до збільшення часу відповіді на запит. Хоча конкурент C може масштабуватися автоматично, він масштабується для нижчої пропускної здатності запитів, ніж Amazon Redshift і конкурент B, і не може підтримувати низький час виконання запитів. Крім того, він не підтримує запити в черзі, коли закінчується обчислювальний ресурс, що не дозволяє масштабувати його понад 128 одночасних користувачів. Надсилання додаткових запитів, крім цього, відхиляється системою.
Тут Redshift Serverless здатний підтримувати відносно постійний час відповіді на запит близько 5 секунд, навіть якщо сотні користувачів виконують запити одночасно. Середній час відповіді на запит для конкурентів B і C стабільно зростає зі збільшенням навантаження на сховища, що призводить до того, що користувачам доводиться чекати довше (до 16 секунд) на повернення своїх запитів, коли сховище даних зайняте. Це означає, що якщо користувач намагається оновити інформаційну панель (яка навіть може надіслати кілька одночасних запитів під час перезавантаження), Amazon Redshift зможе підтримувати час завантаження інформаційної панелі набагато стабільнішим, навіть якщо інформаційну панель завантажують десятки чи сотні інших користувачів одночасно.
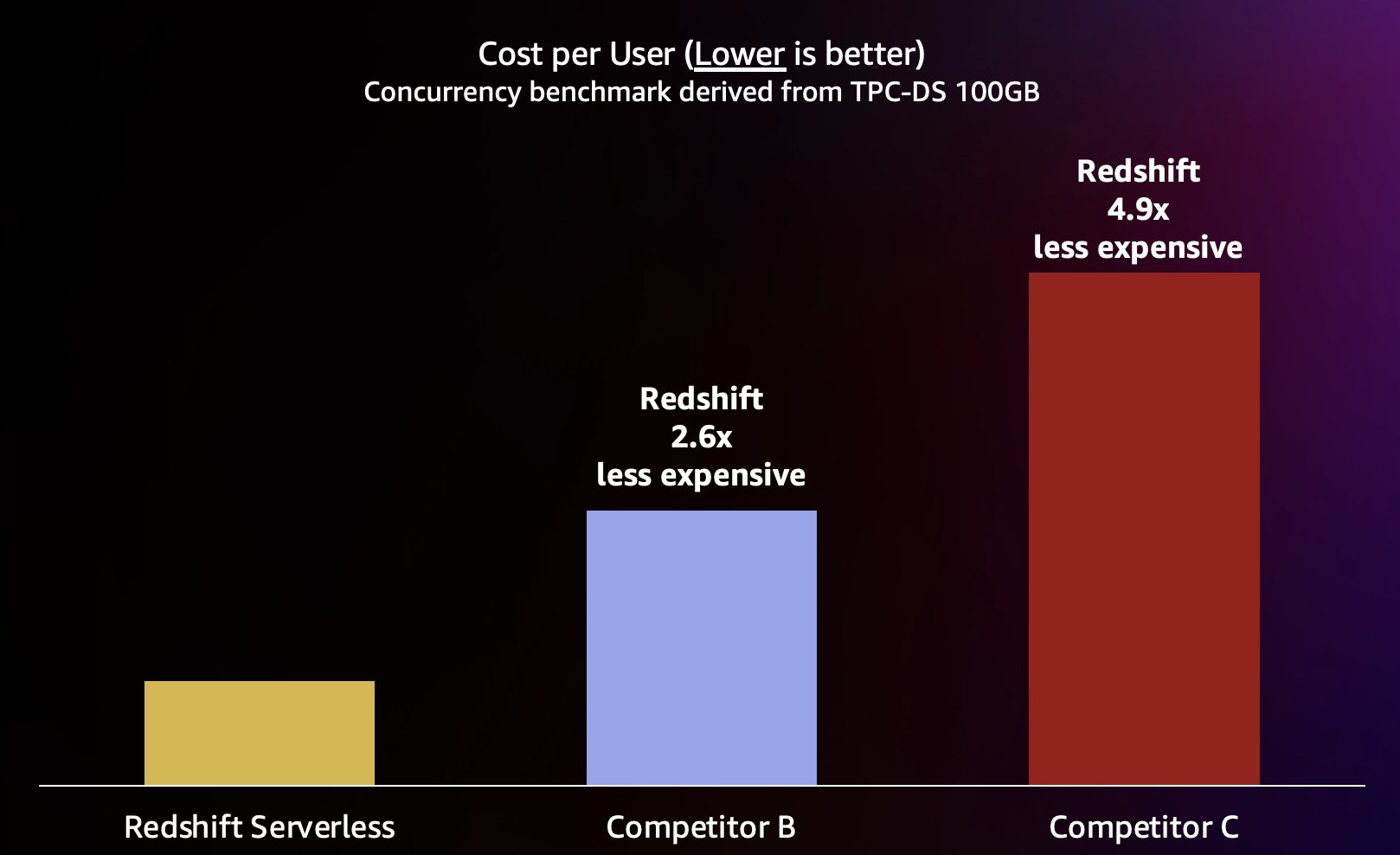
Оскільки Amazon Redshift може забезпечувати дуже високу пропускну здатність для коротких запитів (як ми писали в Amazon Redshift зберігає лідерство за ціною та ефективністю), він також здатний обробляти ці вищі паралелізми під час масштабування ефективніше, а отже, за значно менших витрат. Щоб оцінити це кількісно, ми дивимося на співвідношення ціна-продуктивність, використовуючи опубліковані ціноутворення за запитом для кожного зі складів у попередньому тесті, показано на наступній діаграмі. Варто відзначити, що використання Зарезервовані екземпляри (RI), особливо 3-річні RI, придбані з можливістю передоплати, мають найнижчу вартість запуску Amazon Redshift на забезпечених кластерах, що забезпечує найкраще відносне співвідношення ціни та ефективності порівняно з варіантами RI на вимогу або іншими.

Таким чином, Amazon Redshift не тільки може забезпечити кращу продуктивність за вищих паралелізмів, але й за значно менших витрат. Кожна точка даних на діаграмі ціна-ефективність еквівалентна вартості запуску еталонного тесту в указаному паралельному режимі. Оскільки ціна-продуктивність є лінійною, ми можемо розділити витрати на виконання порівняльного тесту з будь-якою паралельністю на паралельність (кількість одночасних користувачів у цій діаграмі), щоб сказати нам, скільки коштує додавання кожного нового користувача для цього конкретного порівняльного тесту.
Попередні результати легко відтворити. Усі запити, використані в тесті, доступні в нашому GitHub сховище і продуктивність вимірюється шляхом запуску сховища даних, увімкнення масштабування одночасного використання на Amazon Redshift (або відповідної функції автоматичного масштабування в інших сховищах), завантаження даних із коробки (без ручного налаштування чи індивідуального налаштування бази даних), а потім запуску одночасний потік запитів із одночасністю від 1 до 200 із кроком 32 для кожного сховища даних. Те саме сховище GitHub посилається на попередньо згенеровані (і немодифіковані) дані TPC-DS Служба простого зберігання Amazon (Amazon S3) у різних масштабах за допомогою офіційного набору для генерації даних TPC-DS.
Оптимізація навантажень із високим вмістом рядків
Як згадувалося раніше, команда Amazon Redshift постійно шукає нові можливості для забезпечення ще кращого співвідношення ціна-ефективність для наших клієнтів. Одне вдосконалення, яке ми нещодавно запустили, яке значно покращило продуктивність, це оптимізація, яка прискорює продуктивність запитів до рядкових даних. Наприклад, ви можете знайти загальний дохід від роздрібних магазинів, розташованих у Нью-Йорку, за запитом на зразок SELECT sum(price) FROM sales WHERE city = ‘New York’. Цей запит застосовує предикат до рядкових даних (city = ‘New York’). Як ви можете собі уявити, обробка рядкових даних повсюдна в додатках сховищ даних.
Щоб кількісно визначити, як часто робочі навантаження клієнтів отримують доступ до рядків, ми провели детальний аналіз використання типів даних рядків за допомогою телеметрії парку десятків тисяч кластерів клієнтів, якими керує Amazon Redshift. Наш аналіз показує, що в 90% кластерів рядкові стовпці складають принаймні 30% усіх стовпців, а в 50% кластерів рядкові стовпці складають принаймні 50% усіх стовпців. Крім того, більшість усіх запитів, які виконуються на платформі хмарного сховища даних Amazon Redshift, мають доступ принаймні до одного рядкового стовпця. Іншим важливим фактором є те, що рядкові дані дуже часто мають низьку потужність, тобто стовпці містять відносно невеликий набір унікальних значень. Наприклад, хоча ан orders Таблиця, що представляє дані про продажі, може містити мільярди рядків, ан order_status стовпець у цій таблиці може містити лише кілька унікальних значень у цих мільярдах рядків, наприклад pending, in process та completed.
На момент написання цієї статті більшість рядкових стовпців в Amazon Redshift стискаються ЛЗО or ZSTD алгоритми. Це хороші алгоритми стиснення загального призначення, але вони не призначені для використання переваг рядкових даних із низькою потужністю. Зокрема, вони вимагають, щоб дані були розпаковані перед операцією, і менш ефективні у використанні пропускної здатності апаратної пам’яті. Для даних з низькою потужністю існує інший тип кодування, який може бути більш оптимальним: BYTEDICT. У цьому кодуванні використовується схема кодування словника, яка дозволяє механізму бази даних працювати безпосередньо над стиснутими даними без необхідності їх попереднього розпакування.
Щоб ще більше підвищити співвідношення ціна-продуктивність для рядкових навантажень, Amazon Redshift тепер запроваджує додаткові покращення продуктивності, які пришвидшують сканування та оцінки предикатів порівняно з рядковими стовпцями з низькою кардинальністю, які кодуються як BYTEDICT, у 5–63 рази швидше (див. результати в наступний розділ) порівняно з альтернативними кодуваннями стиснення, такими як LZO або ZSTD. Amazon Redshift досягає цього підвищення продуктивності шляхом векторизації сканувань над легкими, ефективними ЦП, закодованими BYTEDICT стовпцями рядків з низькою кардинальністю. Ці оптимізації обробки рядків дозволяють ефективно використовувати пропускну здатність пам’яті, надану сучасним апаратним забезпеченням, уможливлюючи аналітику даних у режимі реального часу. Ці нещодавно представлені можливості продуктивності є оптимальними для рядкових стовпців з низькою кардинальністю (до кількох сотень унікальних рядкових значень).
Увімкнувши це нове високоефективне покращення рядка, ви можете автоматично отримати переваги автоматична оптимізація таблиці у вашому сховищі даних Amazon Redshift. Якщо у вас не ввімкнено автоматичну оптимізацію таблиць, ви можете отримувати рекомендації від Радник по червоному зсуву Amazon у консолі Amazon Redshift щодо придатності рядкового стовпця для кодування BYTEDICT. Ви також можете визначити нові таблиці, які мають рядкові стовпці з низькою кардинальністю з кодуванням BYTEDICT. Покращення рядків у Amazon Redshift тепер доступні в усіх регіонах AWS Amazon Redshift доступний.
Результати роботи
Щоб оцінити вплив наших удосконалень рядків на продуктивність, ми створили набір даних розміром 10 ТБ (терабайт), який складався з даних рядків низької потужності. Ми створили три версії даних, використовуючи короткі, середні та довгі рядки, що відповідають 25-му, 50-му та 75-му процентилю довжини рядків із телеметрії флоту Amazon Redshift. Ми двічі завантажили ці дані в Amazon Redshift, закодувавши їх в одному випадку за допомогою стиснення LZO, а в іншому – за допомогою стиснення BYTEDICT. Нарешті, ми виміряли продуктивність інтенсивних запитів, які повертають багато рядків (90% таблиці), середню кількість рядків (50% таблиці) і кілька рядків (1% таблиці) понад ці низькі набори даних рядків потужності. Результати ефективності підсумовані в наступній діаграмі.

Запити з предикатами, які збігаються з високим відсотком рядків, отримали покращення в 5–30 разів за допомогою нового векторизованого кодування BYTEDICT порівняно з LZO, тоді як запити з предикатами, які збігаються з низьким відсотком рядків, показали покращення в 10–63 рази в цьому внутрішньому тесті.
Redshift Serverless ціна-продуктивність
На додаток до результатів високої ефективності паралелізму, наведених у цій публікації, ми також використали порівняльний тест Cloud Data Warehouse, отриманий від TPC-DS, щоб порівняти співвідношення ціна-продуктивність Redshift Serverless з іншими сховищами даних, використовуючи більший набір даних 3 ТБ. Ми вибрали сховища даних із аналогічними цінами, у цьому випадку в межах 10% від 32 доларів США за годину, використовуючи загальнодоступні ціни за запитом. Ці результати показують, що, як і екземпляри Amazon Redshift RA3, Redshift Serverless забезпечує кращі ціни та продуктивність порівняно з іншими провідними хмарними сховищами даних. Як завжди, ці результати можна відтворити за допомогою наших сценаріїв SQL у нашому GitHub сховище.

Ми радимо вам спробувати Amazon Redshift за допомогою власного доказ концепції робочі навантаження як найкращий спосіб побачити, як Amazon Redshift може задовольнити ваші потреби в аналізі даних.
Знайдіть найкраще співвідношення ціни та продуктивності для ваших робочих навантажень
Еталонні показники, які використовуються в цій публікації, походять від стандартного тесту TPC-DS і мають такі характеристики:
- Схема та дані використовуються без змін із TPC-DS.
- Запити генеруються за допомогою офіційного набору TPC-DS із параметрами запиту, згенерованими з використанням випадкового початкового числа за замовчуванням набору TPC-DS. Схвалені TPC варіанти запитів використовуються для сховища, якщо сховище не підтримує діалект SQL запиту TPC-DS за замовчуванням.
- Тест включає 99 запитів TPC-DS SELECT. Він не включає етапи обслуговування та пропускної здатності.
- Для єдиного тесту паралелізму об’ємом 3 ТБ було виконано три запуски потужності, і для кожного сховища даних вибрано найкращий запуск.
- Співвідношення «ціна-продуктивність» для запитів TPC-DS розраховується як ціна за годину (USD), помножена на час виконання тесту в годинах, що еквівалентно вартості запуску тесту. Остання опублікована ціна на вимогу використовується для всіх сховищ даних, а не ціна зарезервованого екземпляра, як зазначалося раніше.
Ми називаємо це порівняльним тестом Cloud Data Warehouse, і ви можете легко відтворити попередні результати порівняльного тестування за допомогою сценаріїв, запитів і даних, доступних у нашому GitHub сховище. Він отриманий на основі тестів TPC-DS, як описано в цій публікації, і як такий не порівнюється з опублікованими результатами TPC-DS, оскільки результати наших тестів не відповідають офіційній специфікації.
Висновок
Amazon Redshift прагне забезпечити найкраще в галузі співвідношення ціни та продуктивності для найрізноманітніших робочих навантажень. Redshift Serverless лінійно масштабується з найкращою (найнижчою) ціною-продуктивністю, підтримуючи сотні одночасних користувачів, зберігаючи постійний час відповіді на запити. Згідно з результатами тестування, розглянутими в цій публікації, Amazon Redshift має в 2.6 рази кращі показники ціни та ефективності за того самого рівня паралельності порівняно з найближчим конкурентом (конкурент B). Як згадувалося раніше, використання зарезервованих екземплярів із 3-річною опцією авансової оплати дає вам найнижчу вартість для запуску Amazon Redshift, що призводить до навіть кращого відносного співвідношення ціни та ефективності порівняно з ціноутворенням інстанцій на вимогу, яке ми використовували в цій публікації. Наш підхід до безперервного покращення продуктивності включає в себе унікальне поєднання одержимості клієнтів, щоб зрозуміти випадки використання клієнтами та пов’язані з ними вузькі місця масштабованості в поєднанні з безперервним аналізом даних парку для виявлення можливостей значної оптимізації продуктивності.
Кожне навантаження має унікальні характеристики, тому, якщо ви тільки починаєте, a доказ концепції це найкращий спосіб зрозуміти, як Amazon Redshift може знизити ваші витрати, забезпечуючи кращу продуктивність. Виконуючи власне підтвердження концепції, важливо зосередитися на правильних показниках — пропускна здатність запитів (кількість запитів на годину), час відповіді та ціна-ефективність. Ви можете прийняти рішення на основі даних, запустивши перевірку концепції самостійно або за допомогою від AWS або a партнер з системної інтеграції та консалтингу.
Щоб бути в курсі останніх подій в Amazon Redshift, дотримуйтесь Що нового в Amazon Redshift годувати.
Про авторів
 Стефан Громолл є старшим інженером з продуктивності команди Amazon Redshift, де він відповідає за вимірювання та покращення продуктивності Redshift. У вільний час він любить готувати, гратися зі своїми трьома хлопцями та рубати дрова.
Стефан Громолл є старшим інженером з продуктивності команди Amazon Redshift, де він відповідає за вимірювання та покращення продуктивності Redshift. У вільний час він любить готувати, гратися зі своїми трьома хлопцями та рубати дрова.
 Раві Анімі є старшим керівником відділу управління продуктами в команді Amazon Redshift і керує декількома функціональними напрямками служби хмарного сховища даних Amazon Redshift, зокрема продуктивністю, просторовою аналітикою, потоковим прийомом і стратегіями міграції. Він має досвід роботи з реляційними базами даних, багатовимірними базами даних, технологіями Інтернету речей, службами зберігання та обчислювальної інфраструктури, а нещодавно як засновник стартапу, використовуючи AI/глибоке навчання, комп’ютерне бачення та робототехніку.
Раві Анімі є старшим керівником відділу управління продуктами в команді Amazon Redshift і керує декількома функціональними напрямками служби хмарного сховища даних Amazon Redshift, зокрема продуктивністю, просторовою аналітикою, потоковим прийомом і стратегіями міграції. Він має досвід роботи з реляційними базами даних, багатовимірними базами даних, технологіями Інтернету речей, службами зберігання та обчислювальної інфраструктури, а нещодавно як засновник стартапу, використовуючи AI/глибоке навчання, комп’ютерне бачення та робототехніку.
 Аамер Шах є старшим інженером у команді Amazon Redshift Service.
Аамер Шах є старшим інженером у команді Amazon Redshift Service.
 Санкет Хасе є менеджером з розробки програмного забезпечення в команді Amazon Redshift Service.
Санкет Хасе є менеджером з розробки програмного забезпечення в команді Amazon Redshift Service.
 Орестіс Поліхроніу є головним інженером у команді Amazon Redshift Service.
Орестіс Поліхроніу є головним інженером у команді Amazon Redshift Service.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- : має
- :є
- : ні
- :де
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Здатний
- МЕНЮ
- прискорюється
- доступ
- доступний
- Досягає
- через
- доданий
- додати
- доповнення
- Додатковий
- просунутий
- Перевага
- доступний
- проти
- алгоритми
- ВСІ
- дозволяє
- Також
- альтернатива
- альтернативи
- хоча
- завжди
- Amazon
- Amazon Web Services
- кількість
- an
- аналіз
- аналітика
- Аналізуючи
- та
- Інший
- будь-який
- застосування
- Застосування
- підхід
- ЕСТЬ
- області
- навколо
- AS
- зовнішній вигляд
- асоційований
- At
- увагу
- автоматичний
- Автоматизований
- автоматичний
- автоматично
- доступний
- середній
- AWS
- b
- ширина смуги
- заснований
- BE
- оскільки
- перед тим
- починати
- буття
- еталонний тест
- тести
- користь
- КРАЩЕ
- Краще
- між
- За
- мільярди
- обидва
- вузькі місця
- Box
- приносити
- широкий
- бізнес
- бізнес-аналітика
- зайнятий
- але
- by
- CAKE
- розрахований
- розрахунок
- call
- CAN
- можливості
- випадок
- випадків
- характеристика
- характеризується
- Графік
- рубаючи
- вибрав
- Місто
- хмара
- кластер
- Колонка
- Колони
- поєднання
- вчинено
- загальний
- порівнянний
- порівняти
- порівняний
- порівняння
- конкурент
- конкурентів
- комплекс
- дотримуватися
- обчислення
- комп'ютер
- Комп'ютерне бачення
- концепція
- одночасно
- стан
- проводиться
- послідовний
- Консоль
- постійна
- постійно
- складати
- консалтинг
- містити
- безперестанку
- продовжувати
- триває
- безперервний
- постійно
- приготування
- Відповідний
- Коштувати
- витрати
- з'єднаний
- створювати
- вирішальне значення
- клієнт
- Клієнти
- приладова панель
- інформаційні панелі
- дані
- аналіз даних
- Analytics даних
- обробка даних
- набір даних
- сховище даних
- сховища даних
- керовані даними
- Database
- базами даних
- набори даних
- Дата
- рішення
- дефолт
- визначати
- доставляти
- надання
- постачає
- Отриманий
- описаний
- призначений
- бажаний
- деталь
- докладно
- розробка
- події
- різний
- безпосередньо
- обговорювати
- обговорювалися
- різноманітність
- ділити
- do
- робить
- Ні
- Не знаю
- керований
- кожен
- Раніше
- легко
- є
- Ефективний
- ефективний
- продуктивно
- включений
- дозволяє
- заохочувати
- двигун
- інженер
- підвищена
- Посилення
- Удосконалення
- Що натомість? Створіть віртуальну версію себе у
- Еквівалент
- особливо
- Ефір (ETH)
- оцінки
- Навіть
- все
- приклад
- Приклади
- очікувати
- досвід
- витяг
- фактор
- знайомий
- далеко
- ШВИДКО
- швидше
- особливість
- кілька
- в кінці кінців
- знайти
- закінчення
- Перший
- ФЛЕТ
- Сфокусувати
- стежити
- після
- для
- знайдений
- засновник
- від
- функціональний
- далі
- Головна мета
- генерується
- покоління
- отримати
- отримання
- GitHub
- дає
- буде
- добре
- Зростання
- Зростає
- обробляти
- апаратні засоби
- Мати
- має
- he
- Високий
- вище
- його
- тримати
- проведення
- годину
- ГОДИННИК
- Як
- HTML
- HTTP
- HTTPS
- сто
- Сотні
- ідеальний
- в ідеалі
- ідентифікувати
- if
- ілюструвати
- картина
- Impact
- важливо
- важливий аспект
- удосконалювати
- поліпшений
- поліпшення
- поліпшення
- поліпшення
- in
- включати
- includes
- У тому числі
- Augmenter
- збільшений
- Збільшує
- вказує
- промисловості
- Інфраструктура
- екземпляр
- випадки
- інтеграція
- Інтелект
- інтерактивний
- внутрішній
- втручання
- в
- введені
- введення
- інвестиції
- включає в себе
- КАТО
- IT
- ЙОГО
- приєднатися
- JPG
- просто
- тримати
- комплект
- Знання
- великий
- більше
- пізніше
- останній
- останні розробки
- запущений
- запуск
- лідер
- провідний
- вивчення
- найменш
- менше
- рівень
- легкий
- як
- трохи
- загрузка
- погрузка
- вантажі
- розташований
- Довго
- довше
- подивитися
- шукати
- низький
- знизити
- найнижчий
- підтримувати
- збереження
- обслуговування
- Більшість
- зробити
- вдалося
- управління
- менеджер
- управляє
- керівництво
- багато
- матч
- Питання
- Може..
- сенс
- засоби
- вимір
- виміряний
- вимір
- середа
- Зустрічатися
- пам'ять
- згаданий
- може бути
- міграція
- протокол
- сучасний
- понеділок
- гроші
- більше
- Більше того
- найбільш
- багато
- а саме
- Необхідність
- необхідний
- потреби
- Нові
- Нью-Йорк
- Нью-Йорк
- нещодавно
- наступний
- немає
- увагу
- зазначив,
- відзначивши,
- зараз
- номер
- of
- офіційний
- часто
- on
- On-Demand
- ONE
- тільки
- працювати
- працювати
- Можливості
- оптимальний
- оптимізація
- оптимізуючий
- варіант
- Опції
- or
- Інше
- наші
- з
- над
- власний
- параметри
- приватність
- Викрійки
- моделі
- Платити
- оплата
- для
- відсоток
- продуктивність
- планування
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- точка
- популярний
- це можливо
- пошта
- влада
- Передбачуваний
- представлений
- запобігає
- price
- ціни без прихованих комісій
- Головний
- оброблена
- обробка
- Product
- Управління продуктом
- доказ
- доказ концепції
- забезпечувати
- публічно
- опублікований
- придбано
- запити
- швидко
- випадковий
- Читати
- Реальний світ
- реального часу
- отримати
- останній
- нещодавно
- рекомендації
- посилання
- райони
- Відхилено..
- відносний
- щодо
- видалення
- повторний
- повторювані
- тиражувати
- Звіти
- представник
- представляє
- вимагати
- захищені
- відповідь
- відповідальний
- в результаті
- результати
- роздрібна торгівля
- повертати
- revenue
- огляд
- право
- робототехніка
- ROI
- прогін
- біг
- пробіжки
- продажів
- то ж
- зберегти
- бачив
- масштабованість
- шкала
- ваги
- Масштабування
- сканування
- схема
- scripts
- другий
- seconds
- розділ
- побачити
- насіння
- старший
- служити
- Без сервера
- обслуговування
- Послуги
- комплект
- установка
- кілька
- Поділитись
- Короткий
- Повинен
- Показувати
- показаний
- значний
- істотно
- Аналогічно
- простий
- одночасно
- один
- Розмір
- розміром
- невеликий
- So
- Софтвер
- розробка програмного забезпечення
- просторовий
- специфікація
- зазначений
- швидкість
- витрачати
- відпрацьований
- шип
- SQL
- старт
- почалася
- введення в експлуатацію
- залишатися
- неухильно
- заходи
- зберігання
- магазинів
- просто
- стратегії
- потік
- потоковий
- рядок
- представляти
- такі
- придатність
- підтримка
- Підтримуючий
- система
- таблиця
- Приймати
- прийняті
- команда
- методи
- Технології
- сказати
- тензор
- тест
- Тести
- ніж
- Що
- Команда
- їх
- потім
- Там.
- отже
- Ці
- вони
- думати
- це
- ті
- тисячі
- три
- пропускна здатність
- час
- times
- до
- сьогодні
- Усього:
- трафік
- Перетворення
- прозоро
- намагатися
- намагається
- Двічі
- два
- тип
- Типи
- типовий
- повсюдний
- не в змозі
- Uncommon
- розуміти
- створеного
- непередбачуваний
- до
- us
- Використання
- USD
- використання
- використання випадку
- використовуваний
- користувач
- користувачі
- використовує
- використання
- Цінності
- різноманітність
- різний
- дуже
- думки
- фактично
- бачення
- чекати
- хотіти
- Склад
- було
- шлях..
- способи
- we
- Web
- веб-сервіси
- week
- ДОБРЕ
- були
- Що
- коли
- в той час як
- який
- в той час як
- чому
- широкий
- волі
- з
- в
- без
- вартість
- б
- лист
- пише
- йорк
- ви
- вашу
- зефірнет