Зображення автора
Існує багато курсів і ресурсів з машинного навчання та науки про дані, але дуже мало з інженерії даних. Це викликає деякі запитання. Це складна сфера? Він пропонує низьку зарплату? Хіба це не вважається таким же захоплюючим, як інші технічні ролі? Однак реальність така, що багато компаній активно шукають талантів у розробці даних і пропонують значні зарплати, іноді понад 200,000 XNUMX доларів США. Інженери з даних відіграють вирішальну роль як архітектори платформ даних, проектуючи та створюючи базові системи, які дозволяють науковцям із обробки даних та експертам з машинного навчання ефективно функціонувати.
Вирішуючи цю галузеву прогалину, DataTalkClub запровадив трансформаційний і безкоштовний навчальний табір, “Data Engineering Zoomcamp“. Цей курс розроблений, щоб розширити можливості початківців або професіоналів, які хочуть змінити кар’єру, з основними навичками та практичним досвідом у розробці даних.
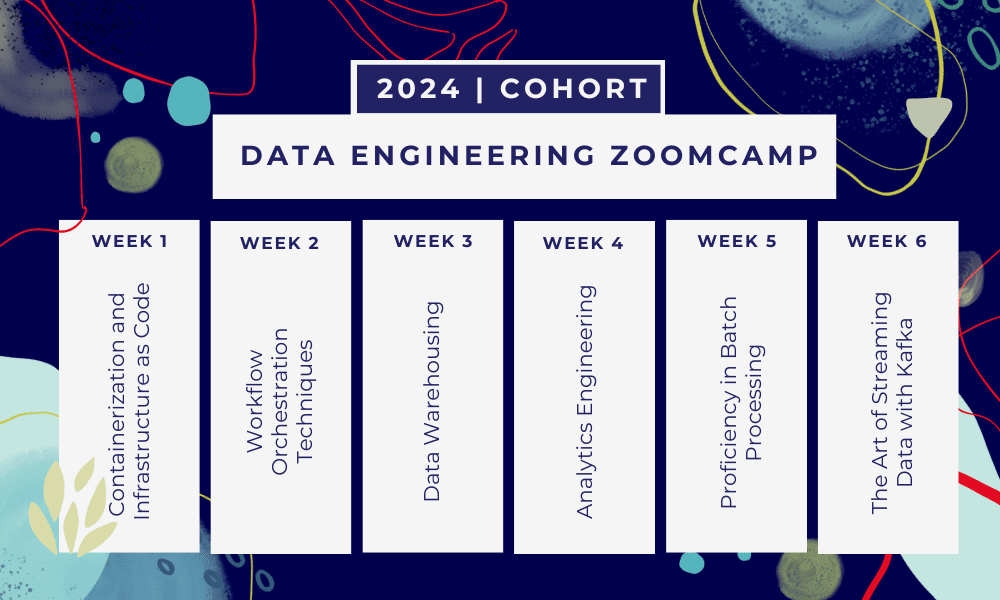
Це 6-тижневий навчальний табір де ви навчатиметеся через численні курси, матеріали для читання, семінари та проекти. Наприкінці кожного модуля ви отримаєте домашнє завдання, щоб відпрацювати те, що ви навчилися.
- Тиждень 1: Вступ до GCP, Docker, Postgres, Terraform і налаштування середовища.
- Тиждень 2: Оркестровка робочого процесу за допомогою Mage.
- Тиждень 3: Сховище даних за допомогою BigQuery та машинне навчання за допомогою BigQuery.
- Тиждень 4: Інженер-аналітик з dbt, Google Data Studio та Metabase.
- Тиждень 5: Пакетна обробка за допомогою Spark.
- Тиждень 6: Стрімінг з Кафкою.
Зображення з DataTalksClub/data-engineering-zoomcamp
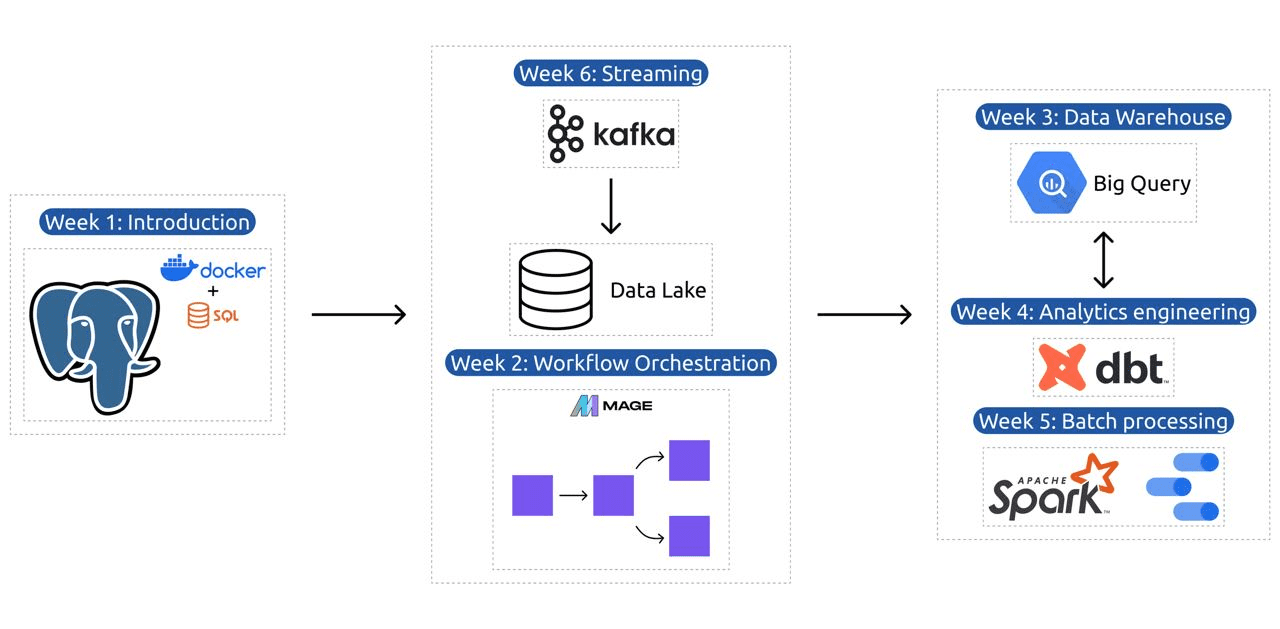
Програма містить 6 модулів, 2 семінари та проект, який охоплює все необхідне для того, щоб стати професійним інженером даних.
Модуль 1: Освоєння контейнеризації та інфраструктури як коду
У цьому модулі ви дізнаєтеся про Docker і Postgres, починаючи з основ і переходячи до детальних посібників зі створення конвеєрів даних, запуску Postgres з Docker тощо.
Модуль також охоплює основні інструменти, як-от pgAdmin, Docker-compose та теми для оновлення SQL, із додатковим вмістом про мережу Docker і спеціальними інструкціями для користувачів підсистеми Windows Linux. Зрештою, курс знайомить вас із GCP і Terraform, надаючи цілісне розуміння контейнеризації та інфраструктури як коду, необхідного для сучасних хмарних середовищ.
Модуль 2: Методи оркестровки робочого процесу
Модуль пропонує поглиблене вивчення Mage, інноваційної гібридної системи з відкритим вихідним кодом для перетворення та інтеграції даних. Цей модуль починається з основ оркестровки робочого процесу, переходить до практичних вправ із Mage, включаючи його налаштування через Docker і створення конвеєрів ETL від API до Postgres і Google Cloud Storage (GCS), а потім до BigQuery.
Поєднання відео, ресурсів і практичних завдань у модулі забезпечує комплексний досвід навчання, озброюючи учнів навичками керування складними робочими процесами даних за допомогою Mage.
Семінар 1: Стратегії прийому даних
На першому семінарі ви навчитеся створювати ефективні конвеєри прийому даних. Семінар зосереджений на основних навичках, таких як вилучення даних з API і файлів, нормалізація та завантаження даних, а також методи інкрементального завантаження. Після завершення цього семінару ви зможете створювати ефективні конвеєри даних, як старший інженер даних.
Модуль 3: Сховища даних
Модуль є поглибленим дослідженням зберігання та аналізу даних, зосередженим на сховищах даних за допомогою BigQuery. Він охоплює ключові поняття, такі як розділення та кластеризація, а також занурюється в найкращі практики BigQuery. Модуль переходить до розширених тем, зокрема інтеграції машинного навчання (ML) із BigQuery, висвітлюючи використання SQL для ML і надаючи ресурси щодо налаштування гіперпараметрів, попередньої обробки функцій і розгортання моделі.
Модуль 4: Аналітична техніка
Інженерний модуль аналітики зосереджений на створенні проекту за допомогою dbt (Data Build Tool) із наявним сховищем даних, BigQuery або PostgreSQL.
Модуль охоплює налаштування dbt як у хмарному, так і в локальному середовищах, представлення концепцій аналітичної інженерії, ETL проти ELT та моделювання даних. Він також охоплює розширені функції dbt, такі як інкрементні моделі, теги, хуки та знімки.
Зрештою, модуль знайомить із технікою візуалізації трансформованих даних за допомогою таких інструментів, як Google Data Studio та Metabase, а також надає ресурси для усунення несправностей та ефективного завантаження даних.
Модуль 5: Вміння пакетної обробки
Цей модуль охоплює пакетну обробку за допомогою Apache Spark, починаючи зі знайомства з пакетною обробкою та Spark, а також інструкцій із встановлення для Windows, Linux і MacOS.
Він включає вивчення Spark SQL і DataFrames, підготовку даних, виконання операцій SQL і розуміння внутрішніх функцій Spark. Нарешті, він завершується запуском Spark у хмарі та інтеграцією Spark із BigQuery.
Модуль 6: Мистецтво потокової передачі даних за допомогою Kafka
Модуль починається зі вступу до концепцій потокової обробки, після чого йде поглиблене вивчення Kafka, включаючи її основи, інтеграцію з Confluent Cloud і практичні програми, що включають виробників і споживачів.
Модуль також охоплює конфігурацію та потоки Kafka, розглядаючи такі теми, як об’єднання потоків, тестування, вікна та використання Kafka ksqldb & Connect. Крім того, він зосереджується на середовищах Python і JVM, включаючи Faust для потокової обробки Python, Pyspark – Structured Streaming і приклади Scala для Kafka Streams.
Семінар 2: Потокова обробка за допомогою SQL
Ви навчитеся обробляти потокові дані та керувати ними за допомогою RisingWave, який надає економічно ефективне рішення з досвідом у стилі PostgreSQL для розширення можливостей ваших програм обробки потоків.
Проект: Програма реальної обробки даних
Метою цього проекту є реалізація всіх концепцій, які ми вивчали в цьому курсі, для створення наскрізного конвеєра даних. Ви створите інформаційну панель, що складається з двох плиток, вибравши набір даних, побудувавши конвеєр для обробки даних і зберігаючи їх в озері даних, побудувавши конвеєр для передачі оброблених даних із озера даних у сховище даних, перетворивши дані в сховищі даних і підготовка їх для інформаційної панелі, і, нарешті, створення інформаційної панелі для візуального представлення даних.
Деталі когорти 2024 року
- Реєстрація: Зареєструйтесь зараз
- Дата початку: 15 січня 2024 року, 17:00 CET
- Самостійне навчання з підтримкою
- Папка Когорта з домашніми завданнями та дедлайнами
- інтерактивний Спільнота Slack для навчання рівних
Передумови
- Базові навички програмування та командного рядка
- Основа в SQL
- Python: корисно, але не обов’язково
Досвідчені інструктори ведуть вашу подорож
- Анкуш Ханна
- Вікторія Перес Мола
- Олексій Григорєв
- Метт Палмер
- Луїс Олівейра
- Майкл Шумейкер
Приєднуйтесь до нашої когорти 2024 року та почніть навчатися з чудовою спільнотою розробників даних. Завдяки навчанню під керівництвом експертів, практичному досвіду та навчальній програмі, адаптованій до потреб галузі, цей навчальний табір не лише озброїть вас необхідними навичками, але й позиціонує вас на передньому краї прибуткової та затребуваної кар’єри. Зареєструйтесь сьогодні та втіліть свої мрії в реальність!
Абід Алі Аван (@1abidaliawan) є сертифікованим фахівцем із дослідження даних, який любить створювати моделі машинного навчання. Зараз він зосереджується на створенні контенту та написанні технічних блогів про технології машинного навчання та науки про дані. Абід має ступінь магістра з управління технологіями та ступінь бакалавра в галузі телекомунікаційної інженерії. Його бачення полягає в тому, щоб створити продукт AI з використанням нейронної мережі графа для студентів, які борються з психічними захворюваннями.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- : має
- :є
- : ні
- :де
- $UP
- 000
- 1
- 15%
- 17
- 2024
- a
- Здатний
- МЕНЮ
- активно
- Додатково
- адресація
- просунутий
- просування
- після
- AI
- ВСІ
- по
- Також
- дивовижний
- an
- аналіз
- Аналітичний
- аналітика
- та
- та інфраструктури
- Apache
- Apache Spark
- API
- Інтерфейси
- застосування
- архітектори
- ЕСТЬ
- Art
- AS
- At
- доступний
- Основи
- BE
- ставати
- становлення
- початківці
- корисний
- КРАЩЕ
- передового досвіду
- великий запит
- Blend
- блоги
- обидва
- будувати
- Створюємо
- але
- by
- кар'єра
- кар'єра
- Сертифікований
- хмара
- Cloud Storage
- Кластеризація
- код
- Кодування
- Когорта
- співтовариство
- Компанії
- завершення
- всеосяжний
- поняття
- робить висновок
- конфігурація
- Перехід
- З'єднуватися
- вважається
- Складається
- будувати
- Споживачі
- містить
- зміст
- контент-створення
- курс
- курси
- охоплює
- створювати
- створення
- створення
- вирішальне значення
- В даний час
- Програма
- приладова панель
- дані
- інженер даних
- Озеро даних
- наука про дані
- вчений даних
- зберігання даних
- сховище даних
- Дата
- Ступінь
- розгортання
- призначений
- проектування
- докладно
- важкий
- Docker
- кожен
- фактично
- ефективний
- або
- уповноважувати
- включіть
- кінець
- кінець в кінець
- інженер
- Машинобудування
- Інженери
- зараховувати
- гарантує
- Навколишнє середовище
- середовищах
- істотний
- Ефір (ETH)
- все
- Приклади
- захоплюючий
- існуючий
- досвід
- experts
- дослідження
- Дослідження
- продовжується
- особливість
- риси
- Показуючи
- кілька
- поле
- Файли
- в кінці кінців
- Перший
- Сфокусувати
- фокусується
- фокусування
- потім
- для
- передній край
- Основоположний
- Рамки
- Безкоштовна
- від
- функція
- Основи
- розрив
- GCP
- даний
- Google Cloud
- графік
- Графік нейронної мережі
- керуватися
- практичний
- Мати
- he
- виділивши
- його
- тримає
- цілісний
- домашнє завдання
- гачки
- Однак
- HTTPS
- гібрид
- Налаштування гіперпараметрів
- хвороба
- здійснювати
- in
- поглиблений
- includes
- У тому числі
- зростаючий
- промисловість
- Інфраструктура
- інноваційний
- установка
- інструкції
- Інтеграція
- інтеграція
- в
- введені
- Вводить
- введення
- Вступ
- введення
- за участю
- IT
- ЙОГО
- січня
- з'єднання
- кафка
- KDnuggets
- ключ
- озеро
- провідний
- УЧИТЬСЯ
- вчений
- учнів
- вивчення
- як
- Лінія
- Linux
- погрузка
- місцевий
- шукати
- любить
- низький
- прибутковий
- машина
- навчання за допомогою машини
- MacOS
- управляти
- управління
- обов'язковий
- багато
- майстер
- Освоєння
- Матеріали
- психічний
- Психічні розлади
- ML
- модель
- моделювання
- Моделі
- сучасний
- Модулі
- Модулі
- більше
- множинний
- необхідно
- Необхідність
- необхідний
- потреби
- мережу
- мережа
- Нейронний
- нейронної мережі
- мета
- of
- пропонує
- Пропозиції
- on
- тільки
- з відкритим вихідним кодом
- операції
- or
- оркестровка
- Інше
- наші
- Паломник
- особливо
- шлях
- Платити
- однолітка
- виконанні
- трубопровід
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- Play
- позиції
- postgresql
- Практичний
- практичне застосування
- практика
- практики
- підготовка
- представити
- процес
- оброблена
- обробка
- Виробники
- Product
- професійний
- професіонали
- прогресує
- проект
- проектів
- забезпечує
- забезпечення
- Python
- питань
- піднімається
- читання
- Реальний світ
- Реальність
- ресурси
- Роль
- ролі
- біг
- s
- зарплати
- масштаб
- наука
- вчений
- Вчені
- пошук
- вибирає
- старший
- установка
- установка
- навички
- слабкий
- рішення
- деякі
- іноді
- складний
- Іскритися
- спеціальний
- SQL
- старт
- Починаючи
- зберігання
- потік
- потоковий
- потоки
- структурований
- Бореться
- Студентам
- студія
- істотний
- такі
- підтримка
- перемикач
- Systems
- з урахуванням
- талант
- завдання
- технології
- технічний
- методи
- Технології
- Технологія
- телекомунікації
- Terraform
- Тестування
- Що
- Команда
- Основи
- потім
- це
- через
- до
- сьогодні
- інструмент
- інструменти
- теми
- Навчання
- Передача
- Перетворення
- Перетворення
- перетворювальний
- перетворений
- перетворення
- навчальні посібники
- два
- розуміння
- USD
- використання
- користувачі
- використання
- Ve
- дуже
- через
- Відео
- бачення
- візуально
- vs
- Склад
- Складування
- we
- Що
- який
- ВООЗ
- волі
- windows
- з
- робочий
- Робочі процеси
- майстерня
- Семінари
- лист
- ви
- вашу
- зефірнет