Зі зростанням Roblox за останні 16+ років зросли масштаб і складність технічної інфраструктури, яка підтримує мільйони захоплюючих 3D-досвідів. За останні два роки кількість машин, які ми підтримуємо, зросла більш ніж утричі: з приблизно 36,000 30 станом на 2021 червня 145,000 року до майже 1,000 XNUMX сьогодні. Для підтримки цих постійних можливостей для людей у всьому світі потрібно понад XNUMX внутрішніх служб. Щоб допомогти нам контролювати витрати та затримку мережі, ми розгортаємо ці машини та керуємо ними як частину створеної на замовлення гібридної приватної хмарної інфраструктури, яка працює переважно локально.
Наша інфраструктура наразі підтримує понад 70 мільйонів щоденних активних користувачів у всьому світі, включаючи творців, які покладаються на Roblox економіка для своїх підприємств. Усі ці мільйони людей очікують дуже високого рівня надійності. Враховуючи захоплюючий характер нашого досвіду, існує надзвичайно низька толерантність до затримок або затримок, не кажучи вже про збої. Roblox — це платформа для спілкування та спілкування, де люди збираються разом у захоплюючих 3D-досвідах. Коли люди спілкуються як свої аватари в захоплюючому просторі, навіть незначні затримки чи збої помітніші, ніж під час текстового потоку чи конференц-дзвінка.
У жовтні 2021 року ми зіткнулися з системним збоєм. Все почалося з малого, з проблеми в одному компоненті в одному центрі обробки даних. Але це швидко поширилося, оскільки ми проводили розслідування, і зрештою призвело до 73-годинного збою. У той час ми ділилися обома подробиці про те, що сталося і деякі з наших ранніх уроків із цього питання. Відтоді ми вивчаємо ці знання та працюємо над підвищенням стійкості нашої інфраструктури до типів збоїв, які виникають у всіх великих системах через такі чинники, як екстремальні сплески трафіку, погода, збій апаратного забезпечення, помилки програмного забезпечення чи просто люди, що роблять помилки. Коли виникають ці збої, як ми гарантуємо, що проблема в окремому компоненті чи групі компонентів не пошириться на всю систему? Це питання було в центрі нашої уваги протягом останніх двох років, і поки робота триває, те, що ми зробили на даний момент, уже окупається. Наприклад, у першій половині 2023 року ми заощадили 125 мільйонів годин залучення на місяць порівняно з першою половиною 2022 року. Сьогодні ми ділимося тим, що вже зробили, а також своїм довгостроковим баченням розвитку більш стійка система інфраструктури.
Створення зупинки зворотного ходу
У великих інфраструктурних системах невеликі збої трапляються багато разів на день. Якщо одна машина має проблему і її потрібно вивести з експлуатації, це можна вирішити, оскільки більшість компаній підтримують кілька екземплярів своїх серверних служб. Отже, коли один екземпляр виходить з ладу, інші беруть на себе навантаження. Щоб усунути ці часті збої, запити зазвичай налаштовані на автоматичний повтор, якщо вони отримують помилку.
Це стає складним, коли система або особа надто агресивно повторює спроби, що може стати способом поширення цих дрібних збоїв по всій інфраструктурі на інші служби та системи. Якщо мережа або користувач достатньо наполегливо повторює спроби, це зрештою перевантажить кожен екземпляр цієї служби та, можливо, інші системи глобально. Наш збій у 2021 році став результатом чогось, що є досить поширеним у великих системах: збій починається з малого, а потім поширюється системою, стаючи настільки великим, що його важко вирішити, поки все не вийде з ладу.
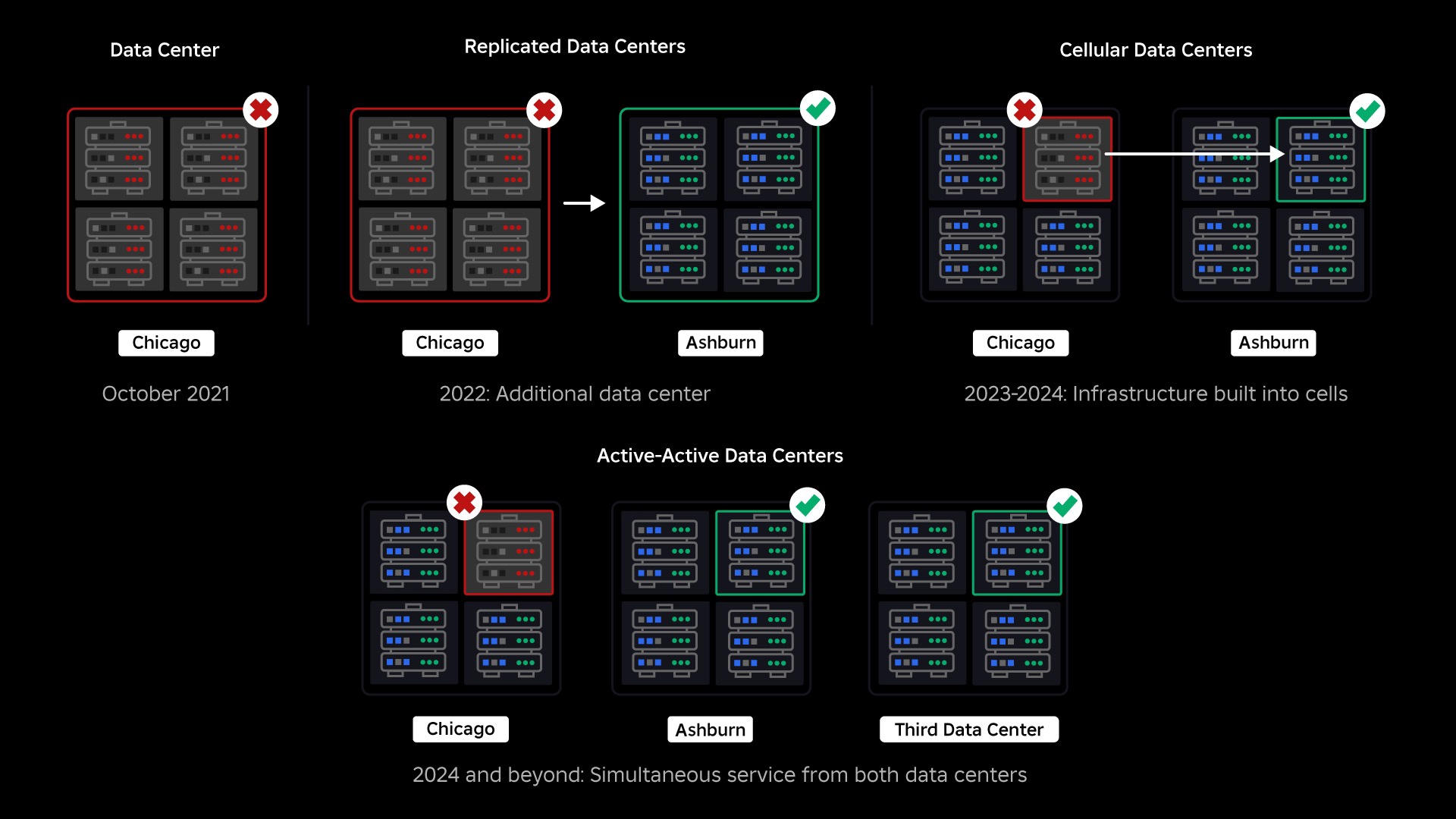
На момент збою у нас був один активний центр обробки даних (з компонентами в ньому, які виступали як резервні). Нам потрібна була можливість вручну переключитися на новий центр обробки даних, коли через проблему вийшов із ладу існуючий. Нашим першочерговим завданням було забезпечення розгортання резервної копії Roblox, тому ми створили цю резервну копію в новому центрі обробки даних, розташованому в іншому географічному регіоні. Це додало захист для найгіршого сценарію: збій поширився на достатню кількість компонентів у центрі обробки даних, щоб він став повністю непрацездатним. Тепер у нас є один центр обробки даних, який обробляє робочі навантаження (активний), і один у режимі очікування, який виконує функцію резервного копіювання (пасивний). Наша довгострокова мета — перейти від цієї активно-пасивної конфігурації до активно-активної конфігурації, у якій обидва центри обробки даних обробляють робочі навантаження, а балансувальник навантаження розподіляє запити між ними на основі затримки, ємності та справності. Щойно це буде запроваджено, ми очікуємо ще більшої надійності для всього Roblox і зможемо виходити з ладу майже миттєво, а не протягом кількох годин. 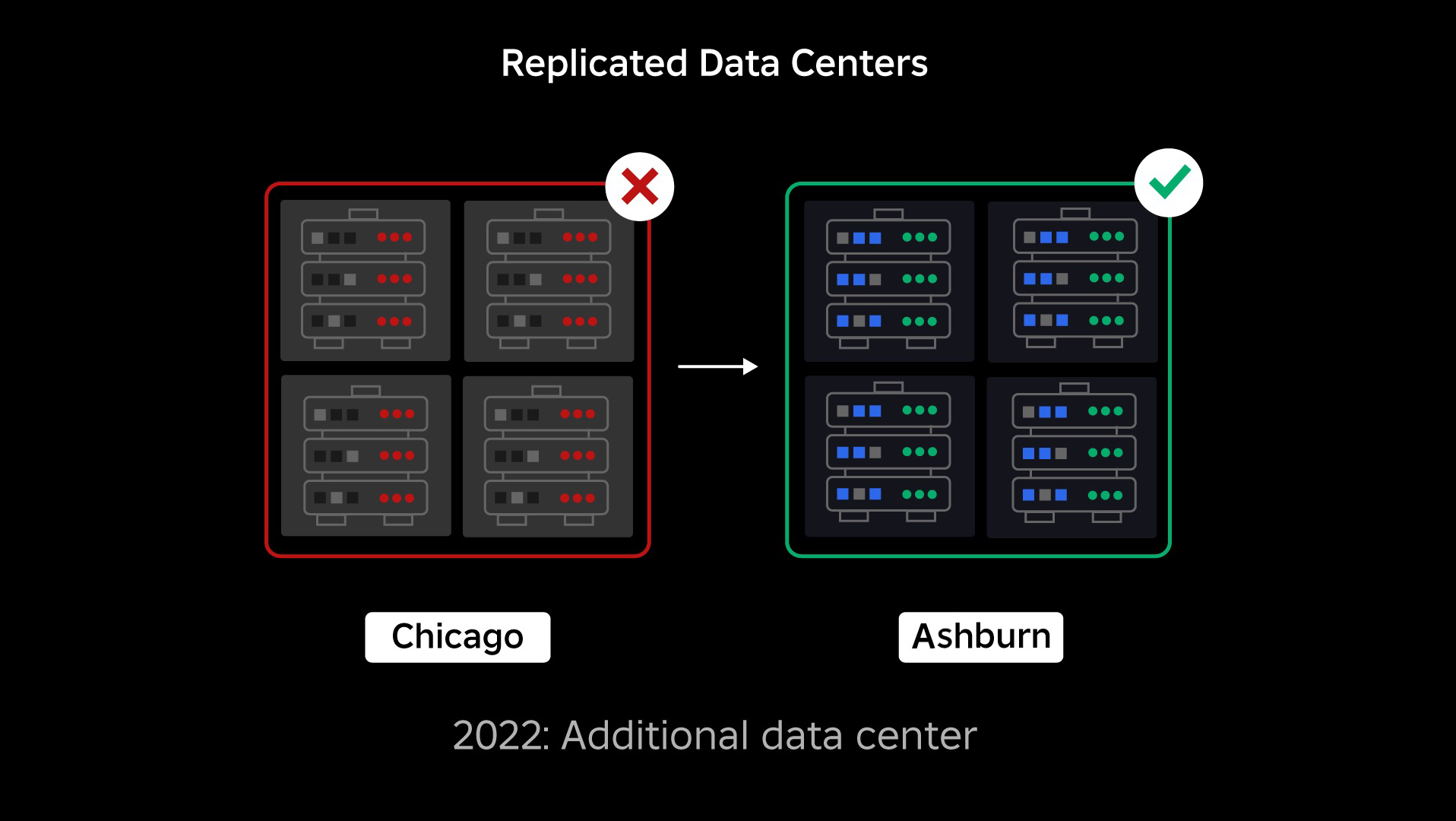
Перехід до стільникової інфраструктури
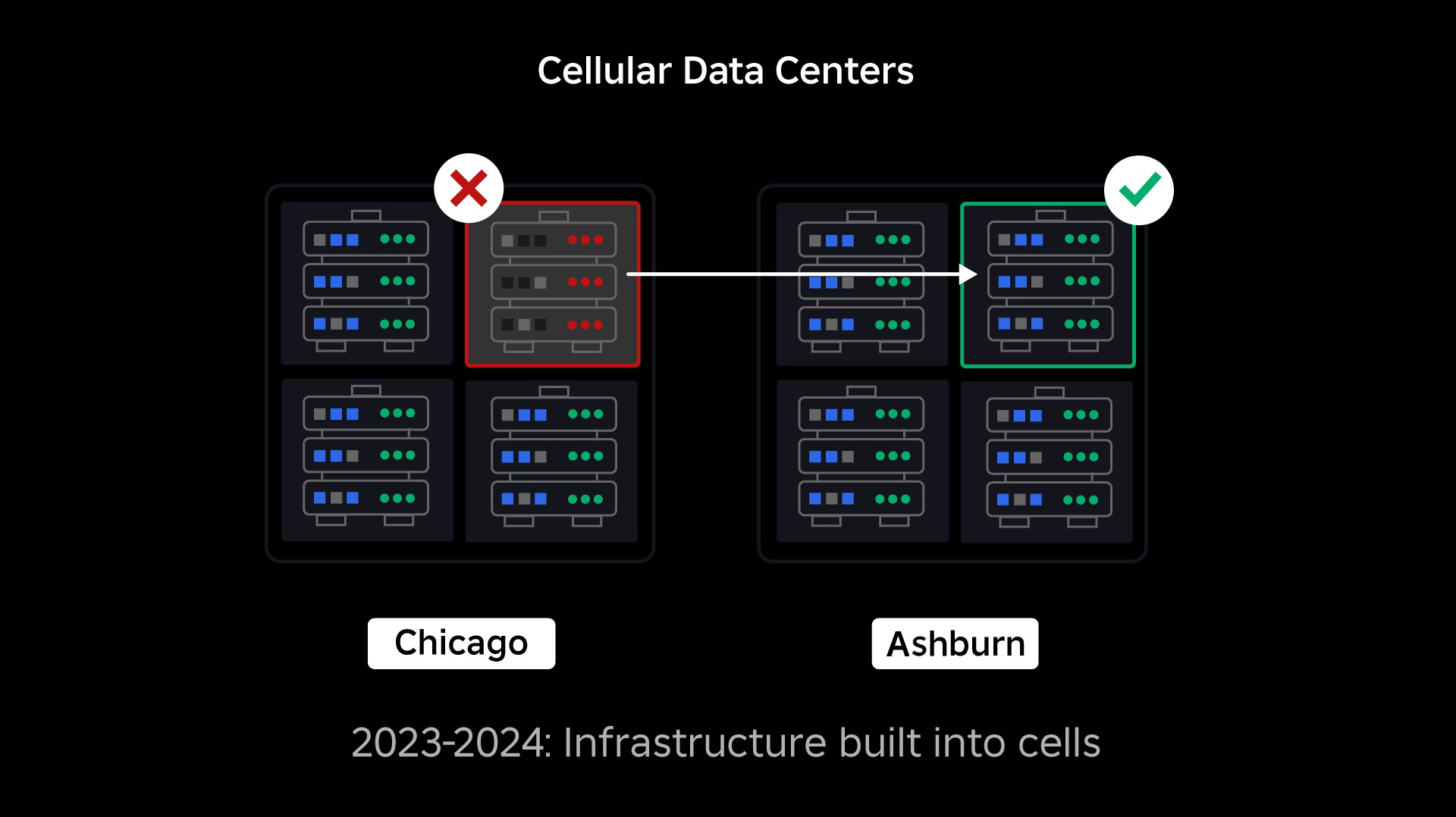
Наш наступний пріоритет полягав у створенні міцних вибухових стін у кожному центрі обробки даних, щоб зменшити ймовірність виходу з ладу всього центру обробки даних. Клітини (деякі компанії називають їх кластерами) — це, по суті, набір машин, і ми створюємо ці стіни. Ми копіюємо послуги як всередині, так і між осередками для додаткової надлишковості. Зрештою, ми хочемо, щоб усі служби в Roblox працювали в осередках, щоб вони могли отримати вигоду як від потужних захистів, так і від резервування. Якщо клітинка більше не працює, її можна безпечно дезактивувати. Реплікація між осередками дозволяє службі продовжувати працювати, поки осередок відновлюється. У деяких випадках відновлення клітини може означати повне відновлення клітини. У промисловості стирання та повторна ініціалізація окремого комп’ютера або невеликого набору машин є досить поширеним явищем, але робити це для цілого осередку, який містить приблизно 1,400 машин, не так.
Щоб це працювало, ці комірки мають бути в основному однорідними, щоб ми могли швидко й ефективно переміщувати навантаження з однієї комірки в іншу. Ми встановили певні вимоги, яким мають відповідати служби, перш ніж працювати в клітинці. Наприклад, служби повинні бути контейнерними, що робить їх набагато більш портативними та не дозволяє будь-кому вносити зміни в конфігурацію на рівні ОС. Ми прийняли філософію інфраструктури як коду для комірок: у нашому репозиторії вихідного коду ми включаємо визначення всього, що є в комірці, щоб ми могли швидко перебудувати її з нуля за допомогою автоматизованих інструментів.
Наразі не всі служби відповідають цим вимогам, тому ми працювали над тим, щоб допомогти власникам послуг відповідати їм, де це було можливо, і створили нові інструменти, щоб полегшити перенесення послуг у клітинки, коли вони будуть готові. Наприклад, наш новий інструмент розгортання автоматично «смугує» розгортання служби між осередками, тому власникам послуг не потрібно думати про стратегію реплікації. Цей рівень суворості робить процес міграції набагато складнішим і трудомістким, але довгостроковим результатом буде система, де:
- Набагато легше стримати збій і запобігти його поширенню на інші клітини;
- Наші інженери інфраструктури можуть бути більш ефективними та рухатися швидше; і
- Інженерам, які створюють сервіси на рівні продукту, які в кінцевому підсумку розгортаються в клітинках, не потрібно знати або турбуватися про те, в яких клітинках працюють їхні служби.
Вирішення більших проблем
Подібно до того, як протипожежні двері використовуються для стримування полум’я, комірки діють як міцні вибухові стіни в нашій інфраструктурі, щоб допомогти стримати будь-яку проблему, яка викликає збій в одній комірці. Зрештою, усі служби, які складають Roblox, будуть надлишково розгорнуті всередині та між осередками. Після завершення цієї роботи проблеми все ще можуть поширюватися досить широко, щоб зробити всю клітинку непрацездатною, але проблемі буде надзвичайно важко поширюватися за межі цієї клітинки. І якщо нам вдасться зробити клітини взаємозамінними, відновлення буде значно швидшим тому що ми зможемо переключитися на іншу комірку й уберегти проблему від впливу на кінцевих користувачів.
Де це стає складно, так це розділити ці клітини настільки, щоб зменшити можливість поширення помилок, зберігаючи при цьому продуктивність і функціональність. У складній інфраструктурній системі службам потрібно спілкуватися одна з одною, щоб обмінюватися запитами, інформацією, робочими навантаженнями тощо. Коли ми копіюватимемо ці служби в осередки, нам потрібно продумати, як ми керуємо перехресним зв’язком. В ідеальному світі ми перенаправляємо трафік від однієї нездорової клітини до інших здорових клітин. Але як ми впораємось із «запитом про смерть» — таким викликаючи клітина бути нездоровою? Якщо ми перенаправимо цей запит до іншої клітинки, це може призвести до того, що ця клітинка стане несправною саме так, як ми намагаємося уникнути. Нам потрібно знайти механізми переміщення «хорошого» трафіку з нездорових клітин, одночасно виявляючи та придушуючи трафік, який спричиняє нездоровість клітин.
У короткостроковій перспективі ми розгорнули копії обчислювальних служб для кожної обчислювальної комірки, щоб більшість запитів до центру обробки даних могла обслуговуватися однією коміркою. Ми також розподіляємо трафік між осередками. Дивлячись далі, ми розпочали розробку процесу виявлення сервісів наступного покоління, який буде використовуватися мережевою мережею сервісів, яку ми сподіваємося завершити у 2024 році. Це дозволить нам запроваджувати складні політики, які дозволятимуть міжстільниковий зв’язок лише тоді, коли це не матиме негативного впливу на осередки відновлення після відмови. Також у 2024 році з’явиться метод для спрямування залежних запитів до версії служби в одній комірці, що мінімізує міжстійковий трафік і тим самим зменшить ризик поширення збоїв між осередками.
На піку понад 70 відсотків трафіку наших внутрішніх служб обслуговується з осередків, і ми багато дізналися про те, як створювати осередки, але ми очікуємо додаткових досліджень і тестувань, оскільки ми продовжуватимемо переносити наші служби до 2024 року та поза межами. По мірі просування ці вибухові стіни ставатимуть дедалі міцнішими.
Перенесення постійної інфраструктури
Roblox — це глобальна платформа, яка підтримує користувачів у всьому світі, тому ми не можемо переміщувати служби під час непікової навантаженості чи простою, що ще більше ускладнює процес міграції всіх наших машин у клітинки та роботу наших служб у цих клітинках. . У нас є мільйони постійних інтерфейсів, які потребують підтримки, навіть коли ми переміщуємо машини, на яких вони працюють, і служби, які їх підтримують. Коли ми розпочинали цей процес, у нас не було десятків тисяч машин, які просто стояли без використання та були доступні для перенесення цих робочих навантажень.
Однак у нас була невелика кількість додаткових машин, які були придбані в очікуванні майбутнього зростання. Для початку ми створили нові осередки за допомогою цих машин, а потім перенесли на них робочі навантаження. Ми цінуємо ефективність і надійність, тому замість того, щоб купувати більше машин, коли у нас закінчилися «запасні» машини, ми створили більше клітинок, видаливши та повторно налаштувавши машини, з яких ми перейшли. Потім ми перенесли робочі навантаження на ці повторно створені машини та почали процес заново. Цей процес є складним — оскільки машини замінюються та звільняються, щоб бути вбудованими в клітини, вони не звільняються ідеальним, упорядкованим способом. Вони фізично фрагментовані між залами даних, що змушує нас надавати їх по частинах, що вимагає процесу дефрагментації на апаратному рівні, щоб підтримувати розташування апаратного забезпечення у відповідності з доменами великих фізичних збоїв.
Частина нашої команди розробників інфраструктури зосереджена на перенесенні існуючих робочих навантажень із нашого застарілого середовища або середовища «до осередку» в осередки. Ця робота триватиме, доки ми не перемістимо тисячі різних інфраструктурних служб і тисячі серверних служб у нові клітини. Ми очікуємо, що це займе весь наступний рік і, можливо, до 2025 року через деякі ускладнюючі фактори. По-перше, ця робота вимагає створення надійного інструменту. Наприклад, нам потрібні інструменти для автоматичного перебалансування великої кількості служб, коли ми розгортаємо нову комірку, не впливаючи на наших користувачів. Ми також бачили сервіси, створені з припущеннями щодо нашої інфраструктури. Нам потрібно переглянути ці послуги, щоб вони не залежали від речей, які можуть змінитися в майбутньому, коли ми перейдемо до камер. Ми також запровадили як спосіб пошуку відомих шаблонів проектування, які не працюватимуть добре з стільниковою архітектурою, так і процес методичного тестування для кожної служби, яку перенесено. Ці процеси допомагають нам уникати будь-яких проблем, які виникають у користувачів через несумісність служби з осередками.
Сьогодні близько 30,000 99.99 машин управляються осередками. Це лише частина нашого загального парку, але наразі це був дуже плавний перехід без негативного впливу на гравців. Наша кінцева мета полягає в тому, щоб наші системи досягали 0.01 відсотка безвідмовної роботи користувачів щомісяця, тобто ми будемо порушувати не більше XNUMX відсотка годин залучення. У всій галузі простої неможливо повністю усунути, але наша мета полягає в тому, щоб скоротити будь-які простої Roblox до такого ступеня, щоб вони були майже непомітними.
Майбутнє під час масштабування
Хоча наші перші спроби виявилися успішними, наша робота над клітинами далека від завершення. Оскільки Roblox продовжує масштабуватися, ми продовжуватимемо працювати над підвищенням ефективності та відмовостійкості наших систем за допомогою цієї та інших технологій. З часом платформа ставатиме все більш стійкою до проблем, і будь-які проблеми, які виникають, мають ставати менш помітними та руйнівними для людей на нашій платформі.
Підсумовуючи, на сьогодні ми маємо:
- Побудував другий центр обробки даних і успішно досяг активного/пасивного статусу.
- Створено комірки в наших активних і пасивних центрах обробки даних і успішно переміщено понад 70 відсотків трафіку наших внутрішніх служб у ці комірки.
- Встановіть вимоги та найкращі практики, яких нам потрібно буде дотримуватися, щоб підтримувати однаковість усіх осередків під час перенесення решти нашої інфраструктури.
- Розпочав безперервний процес побудови міцніших «вибухових стін» між клітинами.
Оскільки ці комірки стають більш взаємозамінними, перехресних перешкод між комірками буде менше. Це відкриває для нас дуже цікаві можливості з точки зору підвищення автоматизації моніторингу, усунення несправностей і навіть автоматичного перенесення робочого навантаження.
У вересні ми також почали проводити активні/активні експерименти в наших центрах обробки даних. Це ще один механізм, який ми тестуємо, щоб підвищити надійність і мінімізувати час відновлення після відмови. Ці експерименти допомогли визначити низку шаблонів проектування системи, здебільшого пов’язаних із доступом до даних, які нам потрібно переробити, коли ми прагнемо стати повністю активними-активними. Загалом експеримент був достатньо успішним, щоб залишити його запущеним для трафіку від обмеженої кількості наших користувачів.
Ми раді продовжувати роботу над підвищенням ефективності та стійкості платформи. Ця робота над осередками та активно-активною інфраструктурою, разом з іншими нашими зусиллями, дозволить нам перетворитися на надійну, високоефективну комунальну компанію для мільйонів людей і продовжити масштабування, оскільки ми працюємо над реальним підключенням мільярда людей час.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- : має
- :є
- : ні
- :де
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- здатність
- Здатний
- МЕНЮ
- доступ
- Achieve
- досягнутий
- через
- Діяти
- діючий
- активний
- доданий
- Додатковий
- адреса
- прийнята
- знову
- агресивно
- вирівняні
- ВСІ
- дозволяти
- тільки
- по
- вже
- Також
- an
- та
- Інший
- передбачити
- очікування
- будь-який
- будь
- приблизно
- архітектура
- ЕСТЬ
- навколо
- AS
- припущення
- At
- Автоматизований
- автоматично
- Автоматизація
- доступний
- аватари
- уникнути
- Back-end
- резервна копія
- свінг
- Балансування
- заснований
- BE
- оскільки
- ставати
- стає
- становлення
- було
- перед тим
- почався
- буття
- користь
- КРАЩЕ
- передового досвіду
- між
- За
- Великий
- більший
- Мільярд
- Блог
- обидва
- приносити
- приніс
- помилки
- будувати
- Створюємо
- побудований
- підприємства
- але
- Купівля
- by
- call
- CAN
- не може
- потужність
- випадків
- Викликати
- викликаний
- викликаючи
- осередок
- Клітини
- стільниковий
- Центр
- Центри
- певний
- складні
- зміна
- Зміни
- близько
- хмара
- інфраструктура хмари
- код
- Приходити
- майбутній
- загальний
- спілкуватися
- спілкування
- Комунікація
- Компанії
- порівняний
- повний
- повністю
- комплекс
- складність
- компонент
- Компоненти
- обчислення
- обчислення
- конференція
- конфігурація
- З'єднуватися
- зв'язку
- містити
- містить
- продовжувати
- триває
- безперервний
- контроль
- copies
- витрати
- може
- створювати
- створення
- Творці
- В даний час
- Побудований на замовлення
- щодня
- дані
- доступ до даних
- Центр обробки даних
- центрів обробки даних
- Дата
- день
- визначення
- Ступінь
- затримки
- залежати
- залежний
- розгортання
- розгорнути
- розгортання
- дизайн
- шаблони дизайну
- DID
- різний
- важкий
- керівництво
- відкриття
- Зривати
- руйнівний
- розповсюдження
- do
- робить
- справи
- домени
- зроблений
- Не знаю
- Двері
- вниз
- час простою
- водіння
- два
- під час
- кожен
- Рано
- легше
- легко
- ефективність
- ефективний
- продуктивно
- зусилля
- усувається
- дозволяє
- кінець
- зачеплення
- Машинобудування
- Інженери
- досить
- забезпечувати
- Весь
- повністю
- Навколишнє середовище
- помилка
- помилки
- по суті
- і т.д.
- Навіть
- врешті-решт
- Кожен
- все
- приклад
- збуджений
- існуючий
- очікувати
- досвідчений
- Досліди
- експеримент
- Експерименти
- екстремальний
- надзвичайно
- фактори
- FAIL
- відсутності
- зазнає невдачі
- Провал
- збої
- достатньо
- далеко
- мода
- швидше
- знайти
- Пожежа
- Перший
- ФЛЕТ
- Сфокусувати
- увагу
- стежити
- для
- Вперед
- фракція
- фрагментарно
- Безкоштовна
- частий
- від
- Повний
- повністю
- функціональний
- далі
- майбутнє
- майбутнє зростання
- в цілому
- географічний
- отримати
- отримання
- даний
- Глобальний
- Глобально
- Go
- мета
- йде
- буде
- великий
- Group
- Рости
- вирощений
- Зростання
- було
- Половина
- обробляти
- Обробка
- траплятися
- Жорсткий
- апаратні засоби
- Мати
- голова
- здоров'я
- здоровий
- допомога
- допоміг
- Високий
- вище
- надія
- ГОДИННИК
- Як
- How To
- Однак
- HTTPS
- Людей
- гібрид
- ідеальний
- ідентифікувати
- if
- занурення
- Impact
- впливає
- здійснювати
- реалізовані
- удосконалювати
- in
- включати
- У тому числі
- несумісні
- Augmenter
- зростаючий
- все більше і більше
- індивідуальний
- промисловість
- інформація
- Інфраструктура
- всередині
- екземпляр
- випадки
- миттєво
- цікавий
- внутрішній
- в
- питання
- питання
- IT
- червень
- просто
- тримати
- зберігання
- Знати
- відомий
- великий
- масштабний
- в значній мірі
- Затримка
- вчений
- Залишати
- догляд
- Legacy
- менше
- дозволяти
- рівень
- левередж
- як
- обмеженою
- загрузка
- розташований
- місць
- довгостроковий
- довше
- шукати
- серія
- низький
- машина
- Машинки для перманенту
- підтримувати
- зробити
- РОБОТИ
- Робить
- управляти
- вдалося
- вручну
- багато
- макс-ширина
- значити
- сенс
- механізм
- механізми
- Зустрічатися
- сітці
- метод
- методичний
- може бути
- мігрувати
- мігрували
- мігруючи
- міграція
- мільйона
- мільйони
- мінімізувати
- незначний
- помилки
- моніторинг
- місяць
- більше
- більш ефективний
- найбільш
- рухатися
- багато
- множинний
- повинен
- природа
- майже
- Необхідність
- необхідний
- негативний
- негативно
- мережу
- Нові
- нещодавно
- наступний
- наступне покоління
- немає
- зараз
- номер
- номера
- відбуваються
- жовтень
- of
- від
- on
- один раз
- ONE
- постійний
- тільки
- Можливості
- Можливість
- or
- OS
- Інше
- інші
- наші
- з
- відключення
- Недоліки
- над
- загальний
- Власники
- частина
- пасивний
- Минуле
- моделі
- платіж
- Peak
- Люди
- для
- відсотків
- виконанні
- наполегливо
- людина
- філософія
- фізичний
- Фізично
- вибирати
- місце
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- гравець
- Політика
- портативний
- частина
- можливість
- це можливо
- можливо
- потенційно
- практики
- запобігати
- запобігає
- в першу чергу
- пріоритет
- приватний
- процес
- процеси
- прогрес
- поступово
- поширення
- захист
- доведення
- забезпечення
- придбано
- Штовхати
- запити
- питання
- швидко
- швидше
- готовий
- реальний
- реального часу
- ребаланс
- відновлення
- переадресовувати
- зменшити
- регіон
- надійність
- надійний
- покладатися
- ремонт
- замінити
- копіювання
- Сховище
- запитів
- Вимога
- Вимагається
- дослідження
- пружність
- пружний
- рішення
- REST
- результат
- призвело до
- переглядати
- Risk
- Roblox
- міцний
- прогін
- біг
- пробіжки
- безпечно
- то ж
- зберігаються
- шкала
- сценарій
- подряпати
- Пошук
- другий
- бачив
- розділення
- Вересень
- служив
- обслуговування
- Послуги
- виступаючої
- комплект
- кілька
- Поділитись
- загальні
- поділ
- зсув
- ПЕРЕМІЩЕННЯ
- Короткий
- Повинен
- істотно
- з
- один
- Сидячий
- невеликий
- згладити
- So
- так далеко
- Софтвер
- деякі
- що в сім'ї щось
- складний
- Source
- вихідні
- Простір
- шипи
- поширення
- Поширення
- старт
- почалася
- починається
- Статус
- Як і раніше
- Стратегія
- сильний
- більш сильний
- вивчення
- процвітати
- успішний
- Успішно
- РЕЗЮМЕ
- підтримка
- Підтриманий
- Підтримуючий
- Опори
- система
- Systems
- Приймати
- прийняті
- команда
- технічний
- Технології
- тензор
- термін
- terms
- Тестування
- текст
- ніж
- Що
- Команда
- Майбутнє
- світ
- їх
- Їх
- потім
- Там.
- тим самим
- Ці
- вони
- речі
- думати
- це
- ті
- тисячі
- через
- по всьому
- час
- times
- до
- сьогодні
- разом
- терпимість
- занадто
- інструмент
- інструменти
- Усього:
- до
- трафік
- перехід
- спрацьовування
- намагається
- два
- Типи
- кінцевий
- Зрештою
- розблокує
- до
- невикористаний
- на
- час безвідмовної роботи
- us
- використовуваний
- користувач
- користувачі
- використання
- утиліта
- значення
- версія
- дуже
- видимий
- бачення
- хотіти
- було
- шлях..
- we
- погода
- ДОБРЕ
- були
- Що
- будь
- коли
- який
- в той час як
- ВООЗ
- широкий
- волі
- витирання
- з
- в
- Work
- працював
- робочий
- світ
- турбуватися
- б
- рік
- років
- зефірнет