Під час розгортання великої мовної моделі (LLM) спеціалісти з машинного навчання (ML) зазвичай дбають про два параметри продуктивності обслуговування моделі: затримку, яка визначається часом, необхідним для створення одного маркера, і пропускну здатність, яка визначається кількістю згенерованих маркерів. в секунду. Хоча пропускна здатність одного запиту до розгорнутої кінцевої точки буде приблизно рівною зворотній затримці моделі, це не обов’язково так, коли кілька одночасних запитів надсилаються до кінцевої точки одночасно. Завдяки технологіям обслуговування моделі, таким як безперервне групування одночасних запитів на стороні клієнта, затримка та пропускна здатність мають складний зв’язок, який суттєво змінюється залежно від архітектури моделі, конфігурацій обслуговування, типу апаратного забезпечення екземпляра, кількості одночасних запитів і варіацій у вхідних даних, таких як як кількість вхідних і вихідних токенів.
У цьому дописі досліджуються ці зв’язки за допомогою комплексного порівняльного аналізу LLM, доступного в Amazon SageMaker JumpStart, включаючи варіанти Llama 2, Falcon і Mistral. Завдяки SageMaker JumpStart фахівці з машинного навчання можуть вибирати серед широкого вибору загальнодоступних базових моделей для розгортання на спеціальному Amazon SageMaker екземпляри в ізольованому мережею середовищі. Ми надаємо теоретичні принципи того, як специфікації прискорювача впливають на бенчмаркінг LLM. Ми також демонструємо вплив розгортання кількох екземплярів за однією кінцевою точкою. Нарешті, ми надаємо практичні рекомендації щодо адаптації процесу розгортання SageMaker JumpStart відповідно до ваших вимог щодо затримки, пропускної спроможності, вартості та обмежень доступних типів екземплярів. Усі результати порівняльного аналізу, а також рекомендації ґрунтуються на універсальності ноутбук які ви можете адаптувати до свого випадку використання.
Розгорнутий бенчмаркінг кінцевої точки
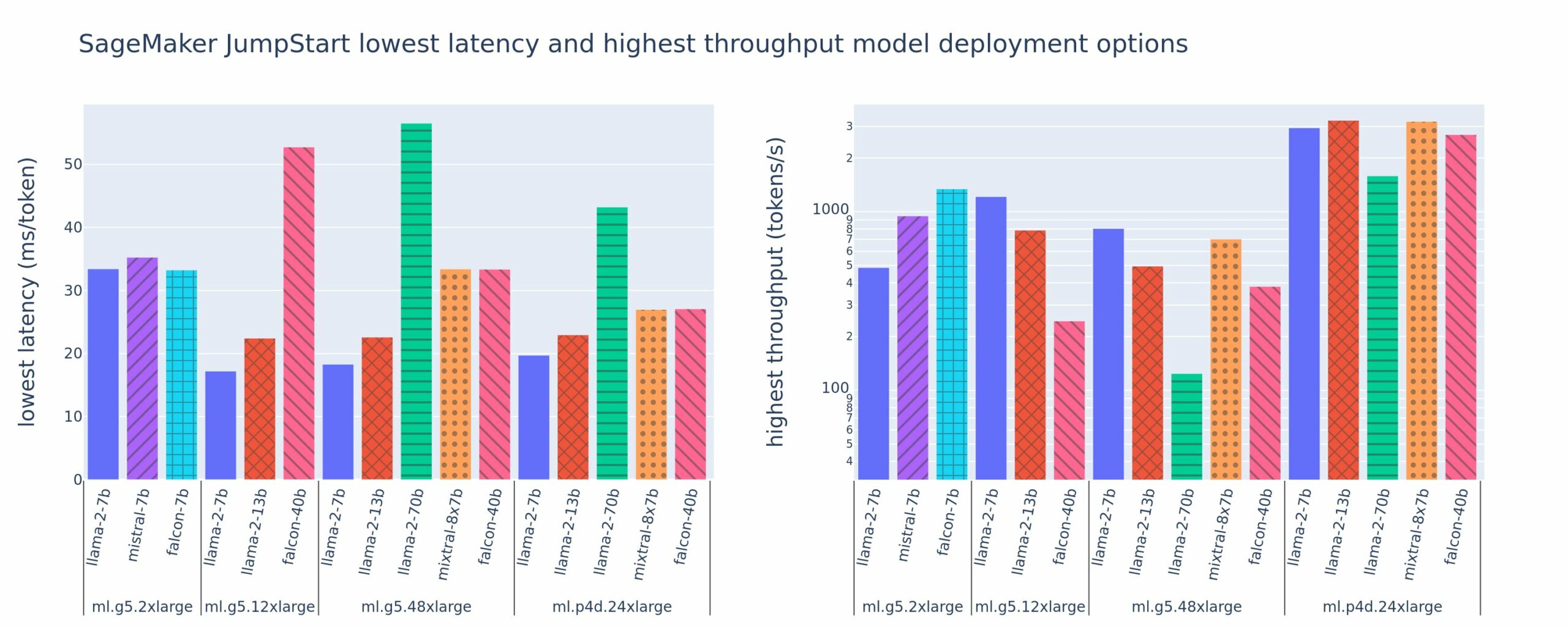
На наступному малюнку показано найнижчі значення затримок (ліворуч) і найвищу пропускну здатність (праворуч) для конфігурацій розгортання для різних типів моделей і типів примірників. Важливо, що кожне з цих розгортань моделі використовує конфігурації за замовчуванням, надані SageMaker JumpStart, враховуючи бажаний ідентифікатор моделі та тип екземпляра для розгортання.
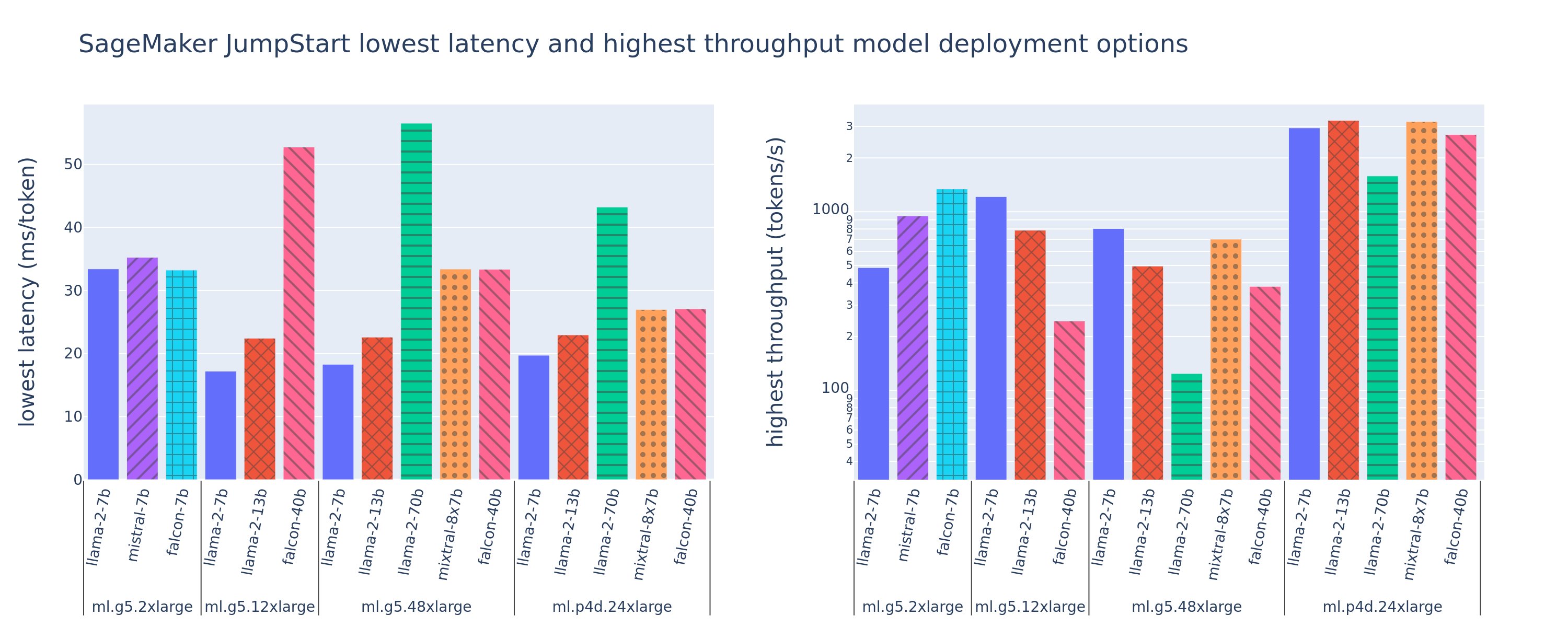
Ці значення затримки та пропускної здатності відповідають корисним навантаженням із 256 вхідними маркерами та 256 вихідними маркерами. Конфігурація найнижчої затримки обмежує обслуговування моделі одним одночасним запитом, а конфігурація найвищої пропускної здатності максимізує можливу кількість одночасних запитів. Як ми бачимо в нашому порівняльному аналізі, збільшення одночасних запитів монотонно збільшує пропускну здатність із зменшенням покращення для великих одночасних запитів. Крім того, моделі повністю шардуються на підтримуваному екземплярі. Наприклад, оскільки екземпляр ml.g5.48xlarge має 8 графічних процесорів, усі моделі SageMaker JumpStart, які використовують цей екземпляр, сегментуються за допомогою тензорного паралелізму на всіх восьми доступних прискорювачах.
Ми можемо відзначити кілька висновків із цієї цифри. По-перше, не всі моделі підтримуються на всіх екземплярах; деякі менші моделі, такі як Falcon 7B, не підтримують сегментування моделі, тоді як більші моделі мають вищі вимоги до обчислювальних ресурсів. По-друге, із збільшенням шардингу продуктивність зазвичай покращується, але не обов’язково покращується для невеликих моделей. Це пов’язано з тим, що малі моделі, такі як 7B і 13B, спричиняють значні накладні витрати на зв’язок, якщо їх розділити на занадто багато прискорювачів. Ми обговоримо це більш детально пізніше. Нарешті, екземпляри ml.p4d.24xlarge, як правило, мають значно кращу пропускну здатність завдяки покращенню пропускної здатності пам’яті A100 порівняно з графічним процесором A10G. Як ми обговоримо пізніше, рішення про використання конкретного типу екземпляра залежить від ваших вимог до розгортання, включаючи затримку, пропускну здатність і обмеження вартості.
Як можна отримати ці найменші значення затримки та найвищу пропускну здатність конфігурації? Давайте почнемо з графіка затримки та пропускної здатності для кінцевої точки Llama 2 7B на екземплярі ml.g5.12xlarge для корисного навантаження з 256 вхідними маркерами та 256 вихідними маркерами, як показано на наступній кривій. Подібна крива існує для кожної розгорнутої кінцевої точки LLM.

Зі збільшенням паралелізму пропускна здатність і затримка також монотонно зростають. Таким чином, найнижча точка затримки виникає при значенні одночасного запиту, що дорівнює 1, і ви можете економічно збільшити пропускну здатність системи, збільшивши кількість одночасних запитів. Існує чітке «коліно» на цій кривій, коли очевидно, що збільшення пропускної здатності, пов’язане з додатковим паралелізмом, не переважує пов’язане збільшення затримки. Точне розташування цього коліна залежить від конкретного випадку використання; деякі практики можуть визначити коліно в точці, де перевищено заздалегідь задану вимогу до затримки (наприклад, 100 мс/токен), тоді як інші можуть використовувати контрольні тести навантаження та методи теорії масового обслуговування, такі як правило половинної затримки, а інші можуть використовувати Теоретичні характеристики прискорювача.
Ми також зауважимо, що максимальна кількість одночасних запитів обмежена. На попередньому малюнку лінія трасування закінчується 192 одночасними запитами. Джерелом цього обмеження є ліміт часу очікування виклику SageMaker, де кінцеві точки SageMaker відкладають відповідь на виклик через 60 секунд. Це налаштування залежить від облікового запису та не налаштовується для окремої кінцевої точки. Для LLM генерація великої кількості вихідних токенів може зайняти секунди або навіть хвилини. Таким чином, великі вхідні або вихідні навантаження можуть спричинити помилку запитів на виклик. Крім того, якщо кількість одночасних запитів дуже велика, багато запитів будуть стояти в черзі, що призведе до обмеження часу очікування в 60 секунд. Для цілей цього дослідження ми використовуємо обмеження часу очікування, щоб визначити максимальну пропускну здатність, можливу для розгортання моделі. Важливо, що незважаючи на те, що кінцева точка SageMaker може обробляти велику кількість одночасних запитів без дотримання тайм-ауту відповіді виклику, ви можете визначити максимальну кількість одночасних запитів з огляду на коліно на кривій затримки-пропускної здатності. Ймовірно, це момент, коли ви починаєте розглядати горизонтальне масштабування, коли одна кінцева точка забезпечує кілька екземплярів репліками моделі та розподіляє навантаження між вхідними запитами між репліками, щоб підтримувати більше одночасних запитів.
У наступній таблиці наведено результати порівняльного аналізу для різних конфігурацій моделі Llama 2 7B, включаючи різну кількість вхідних і вихідних маркерів, типи екземплярів і кількість одночасних запитів. Зверніть увагу, що на попередньому малюнку показано лише один рядок цієї таблиці.
| . | Пропускна здатність (токенів/с) | Затримка (мс/токен) | ||||||||||||||||||
| Одночасні запити | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Загальна кількість жетонів: 512, Кількість виведених жетонів: 256 | ||||||||||||||||||||
| мл.g5.2xвеликий | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| мл.g5.12xвеликий | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| мл.g5.48xвеликий | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Загальна кількість жетонів: 4096, Кількість виведених жетонів: 256 | ||||||||||||||||||||
| мл.g5.2xвеликий | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| мл.g5.12xвеликий | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| мл.g5.48xвеликий | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Ми спостерігаємо деякі додаткові закономірності в цих даних. При збільшенні розміру контексту затримка збільшується, а пропускна здатність зменшується. Наприклад, на ml.g5.2xlarge з паралелізмом 1 пропускна здатність становить 30 токенів/с, якщо загальна кількість токенів становить 512, проти 20 токенів/с, якщо загальна кількість токенів становить 4,096. Це пояснюється тим, що обробка більшого вхідного даних займає більше часу. Ми також бачимо, що збільшення можливостей GPU та сегментування впливає на максимальну пропускну здатність і максимальну кількість підтримуваних одночасних запитів. Таблиця показує, що Llama 2 7B має помітно різні максимальні значення пропускної здатності для різних типів примірників, і ці максимальні значення пропускної здатності виникають при різних значеннях одночасних запитів. Ці характеристики змусять спеціаліста з ML виправдати вартість одного екземпляра над іншим. Наприклад, враховуючи вимоги до низької затримки, практикуючий спеціаліст може вибрати екземпляр ml.g5.12xlarge (4 графічні процесори A10G) замість екземпляра ml.g5.2xlarge (1 графічний процесор A10G). Якщо передбачити високу пропускну здатність, використання екземпляра ml.p4d.24xlarge (8 GPU A100) із повним сегментуванням буде виправданим лише за високого паралелізму. Зауважте, однак, що часто корисно замість цього завантажити кілька компонентів висновку моделі 7B в один екземпляр ml.p4d.24xlarge; така підтримка кількох моделей обговорюється далі в цій публікації.
Попередні спостереження були зроблені для моделі Llama 2 7B. Однак подібні закономірності залишаються вірними і для інших моделей. Основний висновок полягає в тому, що показники затримки та продуктивності залежать від корисного навантаження, типу екземпляра та кількості одночасних запитів, тому вам потрібно буде знайти ідеальну конфігурацію для конкретної програми. Щоб згенерувати попередні числа для вашого випадку використання, ви можете запустити пов’язаний ноутбук, де ви можете налаштувати цей аналіз тесту навантаження для вашої моделі, типу екземпляра та корисного навантаження.
Осмислення специфікацій прискорювача
Вибір відповідного апаратного забезпечення для висновків LLM значною мірою залежить від конкретних випадків використання, цілей взаємодії з користувачем і обраного LLM. У цьому розділі зроблено спробу створити розуміння кривої затримки-пропускної здатності щодо принципів високого рівня на основі специфікацій прискорювача. Самих цих принципів недостатньо для прийняття рішення: необхідні реальні орієнтири. Термін пристрій використовується тут для охоплення всіх апаратних прискорювачів ML. Ми стверджуємо, що коліно на кривій затримка-пропускна здатність обумовлено одним із двох факторів:
- Прискорювач вичерпав пам'ять для кешування матриць KV, тому наступні запити ставляться в чергу
- Прискорювач все ще має запасну пам’ять для кешу KV, але використовує досить великий розмір пакета, тому час обробки залежить від затримки обчислювальної операції, а не від пропускної здатності пам’яті.
Зазвичай ми вважаємо за краще обмежуватися другим фактором, оскільки це означає, що ресурси прискорювача насичені. По суті, ви максимізуєте ресурси, за які заплатили. Розглянемо це твердження більш детально.
Кешування KV і пам'ять пристрою
Стандартні механізми трансформації уваги обчислюють увагу для кожного нового маркера проти всіх попередніх маркерів. Більшість сучасних серверів ML кешують ключі уваги та значення в пам’яті пристрою (DRAM), щоб уникнути повторного обчислення на кожному кроці. Це називається це КВ кеш, і він зростає разом із розміром партії та довжиною послідовності. Він визначає, скільки запитів користувачів можна обслуговувати паралельно, і визначить коліно на кривій затримки-пропускної здатності, якщо обмежений обчислювальний режим у другому сценарії, згаданому раніше, ще не виконано, враховуючи доступну DRAM. Наступна формула є приблизним наближенням максимального розміру кешу KV.

У цій формулі B — розмір партії, а N — кількість прискорювачів. Наприклад, модель Llama 2 7B у FP16 (2 байти/параметр), що обслуговується на GPU A10G (24 ГБ DRAM), споживає приблизно 14 ГБ, залишаючи 10 ГБ для кешу KV. Підключаючи повну довжину контексту моделі (N = 4096) і решту параметрів (n_layers=32, n_kv_attention_heads=32 і d_attention_head=128), цей вираз показує, що ми обмежені паралельним обслуговуванням пакету з чотирьох користувачів через обмеження DRAM . Якщо ви спостерігаєте за відповідними контрольними показниками в попередній таблиці, це є хорошим наближенням для спостережуваного коліна на цій кривій затримка-пропускна здатність. Методи, такі як згрупований запит уваги (GQA) може зменшити розмір кешу KV, у випадку GQA з таким же коефіцієнтом зменшує кількість головок KV.
Арифметична інтенсивність і пропускна здатність пам'яті пристрою
Зростання обчислювальної потужності прискорювачів ML випередило пропускну здатність їхньої пам’яті, тобто вони можуть виконувати набагато більше обчислень з кожним байтом даних за час, необхідний для доступу до цього байту.
Команда арифметична інтенсивність, або відношення обчислювальних операцій до доступу до пам’яті, для операції визначає, чи обмежена вона пропускною спроможністю пам’яті чи обчислювальною потужністю на вибраному обладнанні. Наприклад, графічний процесор A10G (сімейство екземплярів g5) із 70 TFLOPS FP16 і пропускною здатністю 600 ГБ/с може обчислювати приблизно 116 операцій/байт. Графічний процесор A100 (сімейство екземплярів p4d) може обчислювати приблизно 208 операцій/байт. Якщо арифметична інтенсивність для моделі трансформатора нижче цього значення, вона прив’язана до пам’яті; якщо вище, воно пов’язане з обчисленням. Механізм звернення уваги для Llama 2 7B вимагає 62 операції/байт для розміру пакета 1 (пояснення див. Посібник із висновків і продуктивності LLM), що означає, що він прив’язаний до пам’яті. Коли механізм уваги прив’язаний до пам’яті, дорогі FLOPS залишаються невикористаними.
Є два способи краще використовувати прискорювач і збільшити арифметичну інтенсивність: зменшити необхідний доступ до пам’яті для операції (ось що FlashAttention фокусується на) або збільшити розмір партії. Однак ми можемо не в змозі збільшити розмір нашого пакета настільки, щоб досягти режиму, пов’язаного з обчисленнями, якщо наша DRAM занадто мала, щоб утримувати відповідний кеш KV. Приблизне наближення критичного розміру пакета B*, який відокремлює режими, пов’язані з обчисленням, і режими, пов’язані з пам’яттю, для стандартного висновку декодера GPT описується наступним виразом, де A_mb — пропускна здатність пам’яті прискорювача, A_f — FLOPS прискорювача, а N — число прискорювачів. Цей критичний розмір пакету можна отримати, знайшовши, де час доступу до пам’яті дорівнює часу обчислення. Відноситься до це повідомлення у блозі щоб більш детально зрозуміти рівняння 2 та його припущення.

Це те саме співвідношення операцій/байт, яке ми раніше розрахували для A10G, тому критичний розмір пакета на цьому графічному процесорі становить 116. Один із способів наблизитися до цього теоретичного, критичного розміру пакета — збільшити сегментування моделі та розділити кеш між більшою кількістю прискорювачів N. Це ефективно збільшує ємність кеш-пам’яті KV, а також розмір партії, пов’язаної з пам’яттю.
Ще однією перевагою сегментування моделі є розподіл параметрів моделі та завантаження даних між N прискорювачами. Цей тип сегментування є типом паралелізму моделі, який також називають тензорний паралельність. Наївно кажучи, пропускна здатність пам’яті та обчислювальна потужність у сукупності перевищують N разів. Якщо припустити відсутність будь-яких накладних витрат (зв’язок, програмне забезпечення тощо), це зменшить затримку декодування на маркер на N, якщо ми обмежені пам’яттю, оскільки затримка декодування маркера в цьому режимі обмежена часом, який потрібен для завантаження моделі ваги та кеш. Однак у реальному житті збільшення ступеня шардингу призводить до збільшення зв’язку між пристроями для обміну проміжними активаціями на кожному рівні моделі. Ця швидкість зв’язку обмежена пропускною здатністю з’єднання пристрою. Його вплив важко оцінити точно (докладніше див Паралелізм моделі), але згодом це може перестати приносити переваги або погіршити продуктивність — це особливо актуально для менших моделей, оскільки менші обсяги передачі даних призводять до нижчої швидкості передачі.
Щоб порівняти прискорювачі ML на основі їхніх характеристик, ми рекомендуємо наступне. Спочатку обчисліть приблизний критичний розмір пакету для кожного типу прискорювача відповідно до другого рівняння та розмір кешу KV для критичного розміру пакета згідно з першим рівнянням. Потім ви можете використовувати доступну DRAM на прискорювачі, щоб обчислити мінімальну кількість прискорювачів, необхідних для відповідності кешу KV і параметрів моделі. Якщо ви обираєте між кількома прискорювачами, розташуйте прискорювачі в порядку найменшої вартості за ГБ/с пропускної здатності пам’яті. Нарешті, порівняйте ці конфігурації та перевірте, яка вартість/токен є найкращою для вашої верхньої межі бажаної затримки.
Виберіть конфігурацію розгортання кінцевої точки
Багато LLM, що розповсюджуються SageMaker JumpStart, використовують текст-генерація-висновок (TGI) Контейнер SageMaker для модельної сервіровки. У наведеній нижче таблиці пояснюється, як налаштувати різноманітні параметри обслуговування моделі, щоб впливати на обслуговування моделі, що впливає на криву затримки та пропускної здатності, або захистити кінцеву точку від запитів, які перевантажать кінцеву точку. Це основні параметри, які можна використовувати для налаштування розгортання кінцевої точки для вашого випадку використання. Якщо не вказано інше, ми використовуємо значення за умовчанням параметри корисного навантаження генерації тексту та Змінні середовища TGI.
| Змінна середовища | Опис | Значення за замовчуванням SageMaker JumpStart |
| Конфігурації обслуговування моделі | . | . |
MAX_BATCH_PREFILL_TOKENS |
Обмежує кількість токенів під час операції попереднього заповнення. Ця операція генерує кеш KV для нової послідовності підказок введення. Це інтенсивне використання пам’яті та обчислень, тому це значення обмежує кількість токенів, дозволених в одній операції попереднього заповнення. Етапи декодування для інших запитів призупиняються під час попереднього заповнення. | 4096 (за замовчуванням TGI) або максимальна підтримувана довжина контексту для конкретної моделі (надається SageMaker JumpStart), залежно від того, що більше. |
MAX_BATCH_TOTAL_TOKENS |
Контролює максимальну кількість токенів для включення в пакет під час декодування або одного прямого проходу через модель. В ідеалі це встановлено для максимального використання всього доступного обладнання. | Не вказано (TGI за замовчуванням). TGI встановить це значення щодо залишкової пам’яті CUDA під час розігріву моделі. |
SM_NUM_GPUS |
Кількість шардів для використання. Тобто кількість графічних процесорів, які використовуються для запуску моделі з використанням тензорного паралелізму. | Залежно від екземпляра (надається SageMaker JumpStart). Для кожного підтримуваного екземпляра для даної моделі SageMaker JumpStart забезпечує найкраще налаштування паралелізму тензорів. |
| Конфігурації для захисту вашої кінцевої точки (налаштуйте їх для свого випадку використання) | . | . |
MAX_TOTAL_TOKENS |
Це обмежує бюджет пам’яті для одного клієнтського запиту, обмежуючи кількість маркерів у вхідній послідовності плюс кількість маркерів у вихідній послідовності ( max_new_tokens параметр корисного навантаження). |
Максимальна підтримувана довжина контексту для конкретної моделі. Наприклад, 4096 для Llama 2. |
MAX_INPUT_LENGTH |
Визначає максимально дозволену кількість маркерів у послідовності введення для одного запиту клієнта. Під час збільшення цього значення слід враховувати наступне: довші послідовності введення вимагають більше пам’яті, що впливає на безперервне пакетування, і багато моделей мають підтримувану довжину контексту, яку не можна перевищувати. | Максимальна підтримувана довжина контексту для конкретної моделі. Наприклад, 4095 для Llama 2. |
MAX_CONCURRENT_REQUESTS |
Максимальна кількість одночасних запитів, дозволена розгорнутою кінцевою точкою. Нові запити, що перевищують це обмеження, негайно викликають помилку перевантаження моделі, щоб запобігти низькій затримці для поточних запитів обробки. | 128 (TGI за замовчуванням). Цей параметр дозволяє отримати високу пропускну здатність для різноманітних випадків використання, але вам слід закріпити відповідне, щоб зменшити помилки тайм-ауту виклику SageMaker. |
Сервер TGI використовує безперервне пакетування, яке динамічно групує одночасні запити разом, щоб спільно використовувати одну модель прямого проходу. Існує два типи прямого пропуску: попереднього заповнення та декодування. Для кожного нового запиту має виконуватися один перехід попереднього заповнення, щоб заповнити кеш KV для маркерів послідовності введення. Після того, як кеш KV заповнюється, перехід вперед декодування виконує єдине передбачення наступного маркера для всіх пакетних запитів, яке ітеративно повторюється для отримання вихідної послідовності. Оскільки нові запити надсилаються на сервер, наступний крок декодування має зачекати, щоб етап попереднього заповнення міг виконуватися для нових запитів. Це має відбутися до того, як ці нові запити будуть включені в наступні етапи безперервного пакетного декодування. Через апаратні обмеження безперервне пакетування, що використовується для декодування, може включати не всі запити. У цей момент запити потрапляють у чергу обробки, і затримка логічного висновку починає значно збільшуватися лише з незначним збільшенням пропускної здатності.
Порівняльний аналіз затримки LLM можна розділити на затримку попереднього заповнення, затримку декодування та затримку черги. Час, який витрачається кожним із цих компонентів, принципово відрізняється за своєю природою: попереднє заповнення — це одноразове обчислення, декодування відбувається один раз для кожного токена у вихідній послідовності, а постановка в чергу включає процеси пакетування сервера. Коли обробляється кілька одночасних запитів, стає важко відокремити затримки від кожного з цих компонентів, оскільки затримка, яку відчуває будь-який запит клієнта, включає затримки в черзі, обумовлені необхідністю попереднього заповнення нових одночасних запитів, а також затримки в черзі, обумовлені включенням запиту в процесах пакетного декодування. З цієї причини ця публікація зосереджена на затримці наскрізної обробки. Коліно на кривій затримка-пропускна здатність виникає в точці насичення, де затримка черги починає значно зростати. Це явище виникає для будь-якого сервера виводу моделі та обумовлюється специфікаціями прискорювача.
Загальні вимоги під час розгортання включають мінімально необхідну пропускну здатність, максимальну дозволену затримку, максимальну вартість години та максимальну вартість генерації 1 мільйона токенів. Ви повинні обумовити ці вимоги корисними навантаженнями, які представляють запити кінцевих користувачів. Дизайн, який відповідає цим вимогам, повинен враховувати багато факторів, включаючи конкретну архітектуру моделі, розмір моделі, типи екземплярів і кількість екземплярів (горизонтальне масштабування). У наступних розділах ми зосередимося на розгортанні кінцевих точок для мінімізації затримки, максимальної пропускної здатності та мінімізації витрат. Цей аналіз розглядає 512 загальних токенів і 256 вихідних токенів.
Мінімізуйте затримку
Затримка є важливою вимогою в багатьох випадках використання в реальному часі. У наведеній нижче таблиці ми розглядаємо мінімальну затримку для кожної моделі та кожного типу екземпляра. Ви можете досягти мінімальної затримки, налаштувавши MAX_CONCURRENT_REQUESTS = 1.
| Мінімальна затримка (мс/токен) | |||||
| Ідентифікатор моделі | мл.g5.2xвеликий | мл.g5.12xвеликий | мл.g5.48xвеликий | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Лама 2 7B | 33 | 17 | 18 | 20 | - |
| Лама 2 7B Чат | 33 | 17 | 18 | 20 | - |
| Лама 2 13B | - | 22 | 23 | 23 | - |
| Лама 2 13B Чат | - | 23 | 23 | 23 | - |
| Лама 2 70B | - | - | 57 | 43 | - |
| Лама 2 70B Чат | - | - | 57 | 45 | - |
| Містраль 7Б | 35 | - | - | - | - |
| Містраль 7B Інструкт | 35 | - | - | - | - |
| Мікстраль 8x7B | - | - | 33 | 27 | - |
| Falcon 7B | 33 | - | - | - | - |
| Falcon 7B Instruct | 33 | - | - | - | - |
| Falcon 40B | - | 53 | 33 | 27 | - |
| Falcon 40B Instruct | - | 53 | 33 | 28 | - |
| Falcon 180B | - | - | - | - | 42 |
| Falcon 180B Чат | - | - | - | - | 42 |
Щоб досягти мінімальної затримки для моделі, ви можете використовувати наступний код, замінюючи потрібний ідентифікатор моделі та тип екземпляра:
Зверніть увагу, що значення затримки змінюються залежно від кількості вхідних і вихідних маркерів. Однак процес розгортання залишається незмінним, за винятком змінних середовища MAX_INPUT_TOKENS та MAX_TOTAL_TOKENS. Тут ці змінні середовища встановлюються, щоб гарантувати вимоги до затримки кінцевої точки, оскільки більші послідовності введення можуть порушити вимогу до затримки. Зауважте, що SageMaker JumpStart уже надає інші оптимальні змінні середовища під час вибору типу екземпляра; наприклад, використання ml.g5.12xlarge встановить SM_NUM_GPUS до 4 у середовищі моделі.
Збільште пропускну здатність
У цьому розділі ми максимізуємо кількість згенерованих токенів за секунду. Зазвичай це досягається при максимальній кількості дійсних одночасних запитів для моделі та типу екземпляра. У наведеній нижче таблиці ми повідомляємо про пропускну здатність, досягнуту за найбільшого значення одночасного запиту, досягнутого до того, як буде виявлено час очікування виклику SageMaker для будь-якого запиту.
| Максимальна пропускна здатність (токени/сек), одночасні запити | |||||
| Ідентифікатор моделі | мл.g5.2xвеликий | мл.g5.12xвеликий | мл.g5.48xвеликий | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Лама 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Лама 2 7B Чат | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Лама 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Лама 2 13B Чат | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Лама 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Лама 2 70B Чат | - | - | 114 (16) | 1546 (256) | - |
| Містраль 7Б | 947 (64) | - | - | - | - |
| Містраль 7B Інструкт | 986 (128) | - | - | - | - |
| Мікстраль 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcon 7B | 1340 (128) | - | - | - | - |
| Falcon 7B Instruct | 1313 (128) | - | - | - | - |
| Falcon 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B Instruct | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcon 180B | - | - | - | - | 1100 (128) |
| Falcon 180B Чат | - | - | - | - | 1081 (128) |
Щоб досягти максимальної пропускної здатності для моделі, ви можете використовувати такий код:
Зауважте, що максимальна кількість одночасних запитів залежить від типу моделі, типу екземпляра, максимальної кількості вхідних маркерів і максимальної кількості вихідних маркерів. Тому вам слід встановити ці параметри перед налаштуванням MAX_CONCURRENT_REQUESTS.
Також зауважте, що користувач, зацікавлений у мінімізації затримки, часто суперечить користувачеві, зацікавленому в максимізації пропускної здатності. Перший зацікавлений у відповідях у реальному часі, тоді як другий зацікавлений у пакетній обробці, щоб черга кінцевих точок завжди була насичена, таким чином мінімізуючи час простою обробки. Користувачі, які хочуть максимізувати пропускну здатність залежно від вимог до затримки, часто зацікавлені в роботі на коліні кривої затримка-пропускна здатність.
Мінімізуйте витрати
Перший варіант мінімізації витрат передбачає мінімізацію вартості години. Завдяки цьому ви можете розгорнути вибрану модель на екземплярі SageMaker з найнижчою ціною за годину. Щоб отримати інформацію про ціни екземплярів SageMaker у реальному часі, див Ціни Amazon SageMaker. Загалом тип екземпляра за замовчуванням для SageMaker JumpStart LLM є найдешевшим варіантом розгортання.
Другий варіант мінімізації витрат передбачає мінімізацію витрат на створення 1 мільйона токенів. Це проста трансформація таблиці, яку ми обговорювали раніше, щоб максимізувати пропускну здатність, де ви можете спочатку обчислити час у годинах, який потрібен для створення 1 мільйона токенів (1e6 / пропускна здатність / 3600). Потім ви можете помножити цей час, щоб створити 1 мільйон токенів із ціною за годину вказаного екземпляра SageMaker.
Зауважте, що екземпляри з найнижчою ціною за годину – це не те саме, що екземпляри з найнижчою ціною для створення 1 мільйона токенів. Наприклад, якщо запити на виклик є спорадичними, екземпляр із найнижчою ціною за годину може бути оптимальним, тоді як у сценаріях дроселювання найнижча вартість генерації мільйона токенів може бути більш прийнятною.
Компроміс між тензорним паралельним і мультимодельним
У всіх попередніх аналізах ми розглядали розгортання однієї копії моделі зі тензорним паралельним ступенем, що дорівнює кількості графічних процесорів у типі інстанції розгортання. Це стандартна поведінка SageMaker JumpStart. Однак, як зазначалося раніше, сегментування моделі може покращити затримку моделі та пропускну здатність лише до певної межі, за якою вимоги до зв’язку між пристроями домінують над часом обчислення. Це означає, що часто вигідно розгортати декілька моделей із нижчим тензорним ступенем паралельності в одному екземплярі, а не одну модель із вищим тензорним ступенем паралельності.
Тут ми розгортаємо кінцеві точки Llama 2 7B і 13B на примірниках ml.p4d.24xlarge зі ступенями тензорної паралелі (TP) 1, 2, 4 і 8. Для ясності поведінки моделі кожна з цих кінцевих точок завантажує лише одну модель.
| . | Пропускна здатність (токенів/с) | Затримка (мс/токен) | ||||||||||||||||||
| Одночасні запити | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Ступінь TP | Лама 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Лама 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Наші попередні аналізи вже показали значні переваги пропускної здатності на примірниках ml.p4d.24xlarge, що часто призводить до кращої продуктивності з точки зору вартості генерації 1 мільйона токенів у порівнянні з сімейством примірників g5 за умов високого навантаження одночасних запитів. Цей аналіз чітко демонструє, що вам слід розглянути компроміс між шардингом моделі та реплікацією моделі в одному екземплярі; тобто повністю сегментована модель зазвичай не є найкращим використанням обчислювальних ресурсів ml.p4d.24xlarge для сімейств моделей 7B і 13B. Фактично, для сімейства моделей 7B ви отримуєте найкращу пропускну здатність для однієї репліки моделі зі тензорним паралельним ступенем 4 замість 8.
Звідси ви можете екстраполювати, що конфігурація найвищої пропускної здатності для моделі 7B включає ступінь паралелі тензора 1 із вісьмома копіями моделі, а конфігурація найвищої пропускної здатності для моделі 13B, ймовірно, є степенем паралелі тензора 2 із чотирма репліками моделі. Щоб дізнатися більше про те, як це зробити, див Зменшіть витрати на розгортання моделі в середньому на 50%, використовуючи новітні функції Amazon SageMaker, який демонструє використання кінцевих точок на основі компонентів висновку. Через методи балансування навантаження, маршрутизацію сервера та спільне використання ресурсів центрального процесора ви можете не досягти повного покращення пропускної здатності, що дорівнює кількості реплік, помноженій на пропускну здатність однієї репліки.
Горизонтальне масштабування
Як зазначалося раніше, кожне розгортання кінцевої точки має обмеження на кількість одночасних запитів залежно від кількості вхідних і вихідних маркерів, а також типу екземпляра. Якщо це не відповідає вимогам щодо пропускної здатності або одночасних запитів, ви можете збільшити масштаб, щоб використовувати більше одного екземпляра за розгорнутою кінцевою точкою. SageMaker автоматично виконує балансування навантаження запитів між примірниками. Наприклад, наступний код розгортає кінцеву точку, яка підтримується трьома примірниками:
У наведеній нижче таблиці показано збільшення пропускної здатності як фактор кількості екземплярів для моделі Llama 2 7B.
| . | . | Пропускна здатність (токенів/с) | Затримка (мс/токен) | ||||||||||||||
| . | Одночасні запити | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Кількість екземплярів | Тип екземпляра | Загальна кількість жетонів: 512, Кількість виведених жетонів: 256 | |||||||||||||||
| 1 | мл.g5.2xвеликий | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | мл.g5.2xвеликий | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | мл.g5.2xвеликий | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Примітно, що коліно на кривій затримки-пропускної здатності зміщується вправо, оскільки більша кількість екземплярів може обробляти більшу кількість одночасних запитів у кінцевій точці з кількома екземплярами. Для цієї таблиці значення одночасного запиту стосується всієї кінцевої точки, а не кількості одночасних запитів, які отримує кожен окремий екземпляр.
Ви також можете використовувати автомасштабування, функцію для моніторингу робочих навантажень і динамічного коригування потужності для підтримки стабільної та передбачуваної продуктивності за можливо найнижчих витрат. Це виходить за рамки цієї публікації. Щоб дізнатися більше про автомасштабування, див Налаштування кінцевих точок висновку автомасштабування в Amazon SageMaker.
Викликати кінцеву точку з одночасними запитами
Припустімо, у вас є велика група запитів, які ви хотіли б використати для генерації відповідей із розгорнутої моделі в умовах високої пропускної здатності. Наприклад, у наступному блоці коду ми складаємо список із 1,000 корисних навантажень, причому кожне корисне навантаження вимагає створення 100 токенів. Загалом ми просимо створити 100,000 XNUMX токенів.
Під час надсилання великої кількості запитів до API середовища виконання SageMaker можуть виникати помилки придушення. Щоб пом’якшити це, ви можете створити спеціальний клієнт середовища виконання SageMaker, який збільшує кількість повторних спроб. Ви можете надати отриманий об’єкт сеансу SageMaker будь-якому з JumpStartModel конструктор або sagemaker.predictor.retrieve_default якщо ви хочете приєднати новий предиктор до вже розгорнутої кінцевої точки. У наступному коді ми використовуємо цей об’єкт сеансу під час розгортання моделі Llama 2 із стандартними конфігураціями SageMaker JumpStart:
Ця розгорнута кінцева точка має MAX_CONCURRENT_REQUESTS = 128 за замовчуванням. У наступному блоці ми використовуємо бібліотеку одночасних ф’ючерсів для повторного виклику кінцевої точки для всіх корисних даних із 128 робочими потоками. Щонайбільше кінцева точка обробить 128 одночасних запитів, і щоразу, коли запит повертає відповідь, виконавець негайно надсилає новий запит до кінцевої точки.
Це призводить до генерації 100,000 1255 токенів із пропускною здатністю 5.2 токенів/с на одному екземплярі ml.g80xlarge. Це займає приблизно XNUMX секунд.
Зауважте, що це значення пропускної здатності значно відрізняється від максимальної пропускної здатності для Llama 2 7B на ml.g5.2xlarge у попередніх таблицях цієї публікації (486 токенів/с при 64 одночасних запитах). Це пояснюється тим, що вхідне корисне навантаження використовує 8 маркерів замість 256, кількість вихідних маркерів становить 100 замість 256, а менша кількість маркерів дозволяє виконувати 128 одночасних запитів. Це останнє нагадування, що всі значення затримки та пропускної здатності залежать від корисного навантаження! Зміна кількості маркерів корисного навантаження вплине на процеси пакетування під час обслуговування моделі, що, у свою чергу, вплине на час попереднього заповнення, декодування та черги для вашої програми.
Висновок
У цій публікації ми представили порівняльний аналіз LLM SageMaker JumpStart, зокрема Llama 2, Mistral і Falcon. Ми також представили посібник із оптимізації затримки, пропускної здатності та вартості для конфігурації розгортання кінцевої точки. Ви можете почати, запустивши пов'язаний блокнот щоб порівняти свій варіант використання.
Про авторів
 Доктор Кайл Ульріх є прикладним науковцем у команді Amazon SageMaker JumpStart. Його дослідницькі інтереси включають масштабовані алгоритми машинного навчання, комп’ютерне бачення, часові ряди, байєсівські непараметричні процеси та процеси Гаусса. Його доктор філософії отримав в Університеті Дьюка, і він опублікував статті в NeurIPS, Cell і Neuron.
Доктор Кайл Ульріх є прикладним науковцем у команді Amazon SageMaker JumpStart. Його дослідницькі інтереси включають масштабовані алгоритми машинного навчання, комп’ютерне бачення, часові ряди, байєсівські непараметричні процеси та процеси Гаусса. Його доктор філософії отримав в Університеті Дьюка, і він опублікував статті в NeurIPS, Cell і Neuron.
 Dr. Вівек Мадан є прикладним науковцем у команді Amazon SageMaker JumpStart. Він отримав ступінь доктора філософії в Університеті Іллінойсу в Урбана-Шампейн і був науковим співробітником у технічному університеті Джорджії. Він є активним дослідником машинного навчання та розробки алгоритмів і публікував статті на конференціях EMNLP, ICLR, COLT, FOCS і SODA.
Dr. Вівек Мадан є прикладним науковцем у команді Amazon SageMaker JumpStart. Він отримав ступінь доктора філософії в Університеті Іллінойсу в Урбана-Шампейн і був науковим співробітником у технічному університеті Джорджії. Він є активним дослідником машинного навчання та розробки алгоритмів і публікував статті на конференціях EMNLP, ICLR, COLT, FOCS і SODA.
 Доктор Ашиш Хетан є старшим прикладним науковим співробітником Amazon SageMaker JumpStart і допомагає розробляти алгоритми машинного навчання. Він отримав ступінь доктора філософії в Іллінойському університеті Урбана-Шампейн. Він активно досліджує машинне навчання та статистичні висновки та опублікував багато статей на конференціях NeurIPS, ICML, ICLR, JMLR, ACL та EMNLP.
Доктор Ашиш Хетан є старшим прикладним науковим співробітником Amazon SageMaker JumpStart і допомагає розробляти алгоритми машинного навчання. Він отримав ступінь доктора філософії в Іллінойському університеті Урбана-Шампейн. Він активно досліджує машинне навчання та статистичні висновки та опублікував багато статей на конференціях NeurIPS, ICML, ICLR, JMLR, ACL та EMNLP.
 Жоао Моура є старшим архітектором рішень зі штучного інтелекту/ML в AWS. Жоао допомагає клієнтам AWS – від невеликих стартапів до великих підприємств – навчати та ефективно розгортати великі моделі, а також ширше створювати платформи машинного навчання на AWS.
Жоао Моура є старшим архітектором рішень зі штучного інтелекту/ML в AWS. Жоао допомагає клієнтам AWS – від невеликих стартапів до великих підприємств – навчати та ефективно розгортати великі моделі, а також ширше створювати платформи машинного навчання на AWS.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/
- : має
- :є
- : ні
- :де
- $UP
- 000
- 1
- 10
- 100
- 11
- 116
- 12
- 14
- 150
- 16
- 17
- 20
- 24
- 28
- 30
- 32
- 60
- 600
- 70
- 8
- 80
- a
- A100
- Здатний
- МЕНЮ
- вище
- прискорювач
- прискорювачі
- прийняття
- доступ
- виконувати
- За
- Achieve
- досягнутий
- через
- активації
- активний
- пристосовувати
- Додатковий
- Додатково
- регулювати
- Переваги
- впливати
- після
- проти
- сукупність
- AI / ML
- алгоритм
- алгоритми
- вирівнювати
- ВСІ
- дозволяти
- дозволено
- дозволяє
- тільки
- вже
- Також
- хоча
- завжди
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- кількість
- an
- аналізи
- аналіз
- та
- Інший
- будь-який
- API
- додаток
- прикладної
- підхід
- відповідний
- приблизний
- приблизно
- архітектура
- ЕСТЬ
- AS
- асоційований
- припущення
- At
- приєднувати
- Спроби
- увагу
- автоматично
- доступний
- середній
- уникнути
- AWS
- b
- баланси
- Балансування
- ширина смуги
- заснований
- В основному
- дозування
- Байєсівський
- BE
- оскільки
- стає
- перед тим
- поведінка
- за
- буття
- Вірити
- еталонний тест
- бенчмаркінг
- тести
- корисний
- користь
- Переваги
- КРАЩЕ
- Краще
- між
- За
- Блокувати
- Блог
- пов'язаний
- широкий
- широко
- бюджет
- будувати
- але
- by
- cache
- обчислювати
- розрахований
- званий
- CAN
- Може отримати
- можливості
- потужність
- шапки
- який
- випадок
- випадків
- Викликати
- осередок
- певний
- зміна
- заміна
- характеристика
- Вибирати
- вибраний
- ясність
- очевидно
- клієнт
- код
- Комунікація
- порівняти
- комплекс
- Компоненти
- всеосяжний
- обчислення
- обчислювальна
- обчислювальна потужність
- обчислення
- обчислення
- комп'ютер
- Комп'ютерне бачення
- одночасно
- стан
- Умови
- конференції
- конфігурація
- Вважати
- вважається
- вважає
- обмеження
- спожитий
- містить
- контекст
- безперервний
- постійно
- Відповідний
- Коштувати
- витрати
- вважати
- центральний процесор
- створювати
- критичний
- сирий
- Поточний
- крива
- виготовлений на замовлення
- Клієнти
- дані
- Вирішивши
- рішення
- Декодування
- зменшити
- зменшується
- присвячених
- дефолт
- визначати
- певний
- Визначає
- Ступінь
- демонструвати
- демонструє
- залежний
- Залежно
- залежить
- розгортання
- розгорнути
- розгортання
- розгортання
- розгортання
- розгортає
- глибина
- Отриманий
- описаний
- дизайн
- бажаний
- деталь
- деталі
- Визначати
- визначає
- розвивати
- пристрій
- прилади
- різний
- важкий
- зменшується
- обговорювати
- обговорювалися
- чіткий
- розподілений
- Ні
- домінувати
- Не знаю
- час простою
- dr
- управляти
- керований
- водіння
- два
- Герцог
- герцогський університет
- під час
- динамічно
- кожен
- Раніше
- фактично
- продуктивно
- вісім
- або
- охоплювати
- стикаючись
- кінець в кінець
- Кінцева точка
- кінцеві точки
- закінчується
- досить
- Що натомість? Створіть віртуальну версію себе у
- підприємств
- Весь
- Навколишнє середовище
- рівним
- Так само
- помилка
- помилки
- особливо
- оцінити
- Ефір (ETH)
- Навіть
- врешті-решт
- Кожен
- точно
- приклад
- перевищений
- Крім
- проявляти
- існує
- дорогий
- досвід
- досвідчений
- пояснення
- дослідити
- досліджує
- вираз
- факт
- фактор
- фактори
- FAIL
- сокіл
- сімей
- сім'я
- реально
- особливість
- риси
- кілька
- Рисунок
- остаточний
- в кінці кінців
- знайти
- виявлення
- Перший
- відповідати
- Сфокусувати
- фокусується
- після
- для
- Колишній
- формула
- Вперед
- фонд
- чотири
- від
- Повний
- повністю
- принципово
- далі
- Крім того
- Ф'ючерси
- Отримувати
- прибуток
- Загальне
- породжувати
- генерується
- генерує
- породжує
- покоління
- Грузія
- отримати
- даний
- Цілі
- добре
- є
- GPU
- Графічні процесори
- великий
- Зростає
- Зростання
- гарантувати
- Охорона
- керівництво
- обробляти
- апаратні засоби
- Мати
- he
- голови
- сильно
- допомога
- допомагає
- тут
- Високий
- на вищому рівні
- вище
- найвищий
- його
- тримати
- Горизонтальний
- годину
- ГОДИННИК
- Як
- How To
- Однак
- HTTPS
- i
- ICLR
- ID
- ідеальний
- в ідеалі
- ідентифікувати
- if
- Іллінойс
- негайно
- Impact
- Вплив
- імпорт
- важливо
- важливо
- удосконалювати
- поліпшення
- поліпшення
- поліпшується
- in
- включати
- включені
- У тому числі
- включення
- Вхідний
- Augmenter
- збільшений
- Збільшує
- зростаючий
- індивідуальний
- вхід
- витрати
- екземпляр
- випадки
- замість
- зацікавлений
- інтереси
- Проміжний
- в
- включає в себе
- IT
- ЙОГО
- JPG
- виправданий
- ключі
- Дитина
- затока
- мова
- великий
- Великі підприємства
- більше
- найбільших
- Затримка
- пізніше
- останній
- шар
- вести
- УЧИТЬСЯ
- вивчення
- догляд
- залишити
- довжина
- бібліотека
- життя
- як
- Ймовірно
- МЕЖА
- обмеження
- обмеженою
- рамки
- Лінія
- список
- Лама
- загрузка
- погрузка
- розташування
- довше
- подивитися
- низький
- знизити
- найнижчий
- машина
- навчання за допомогою машини
- made
- підтримувати
- зробити
- багато
- Максимізувати
- максимізує
- максимізація
- максимальний
- Може..
- сенс
- засоби
- вимірювання
- механізм
- механізми
- Зустрічатися
- пам'ять
- згаданий
- зустрів
- методика
- може бути
- мільйона
- мінімізувати
- мінімізація
- мінімальний
- незначний
- протокол
- Пом'якшити
- ML
- режим
- модель
- Моделі
- сучасний
- монітор
- більше
- найбільш
- множинний
- повинен
- природа
- обов'язково
- необхідно
- Необхідність
- NeurIPS
- Нові
- наступний
- немає
- особливо
- увагу
- зазначив,
- номер
- номера
- об'єкт
- спостереження
- спостерігати
- спостерігається
- отримувати
- Очевидний
- відбуваються
- трапляються
- Шанси
- of
- часто
- on
- ONE
- тільки
- операційний
- операція
- операції
- оптимальний
- Оптимізувати
- варіант
- or
- порядок
- Інше
- інші
- інакше
- наші
- вихід
- над
- документи
- Паралельні
- параметр
- параметри
- приватність
- проходити
- проходить
- моделі
- пауза
- для
- виконувати
- продуктивність
- виступає
- Вчений ступінь
- явище
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- плюс
- точка
- бідні
- заселений
- це можливо
- пошта
- влада
- Практичний
- попередній
- точно
- передбачати
- Передбачуваний
- прогноз
- Прогноз
- надавати перевагу
- представлений
- запобігати
- попередній
- раніше
- price
- ціни без прихованих комісій
- первинний
- Принципи
- Пріоритетність
- процес
- оброблена
- процеси
- обробка
- виробляти
- захист
- забезпечувати
- за умови
- забезпечує
- публічно
- опублікований
- мета
- запити
- підвищення
- ставки
- швидше
- співвідношення
- досягати
- реальний
- справжнє життя
- реального часу
- причина
- отримує
- рекомендувати
- рекомендації
- зменшити
- знижує
- послатися
- називають
- режим
- режими
- відносини
- Відносини
- залишатися
- решті
- залишається
- нагадування
- повторний
- відповідь
- копіювання
- звітом
- представляти
- запросити
- прохання
- запитів
- вимагати
- вимагається
- вимога
- Вимога
- Вимагається
- дослідження
- дослідник
- ресурс
- ресурси
- повага
- відповідь
- відповіді
- в результаті
- результати
- Умови повернення
- право
- Маршрутизація
- ROW
- Правило
- прогін
- біг
- мудрець
- то ж
- масштабовані
- шкала
- Масштабування
- сценарій
- сценарії
- вчений
- сфера
- другий
- seconds
- розділ
- розділам
- побачити
- бачив
- вибрати
- обраний
- вибирає
- вибір
- послати
- відправка
- старший
- сенс
- посланий
- окремий
- Послідовність
- Серія
- служив
- сервер
- сервери
- Послуги
- виступаючої
- Сесія
- комплект
- установка
- загострений
- заточування
- Поділитись
- поділ
- Зміни
- Повинен
- показав
- Шоу
- значний
- істотно
- аналогічний
- простий
- одночасно
- один
- Розмір
- невеликий
- менше
- So
- Софтвер
- Рішення
- деякі
- Source
- спеціаліст
- конкретний
- специфікації
- зазначений
- дані
- швидкість
- розкол
- спорадичний
- standard
- старт
- почалася
- починається
- Стартапи
- статистичний
- стійкий
- Крок
- заходи
- Як і раніше
- Стоп
- Вивчення
- наступні
- істотний
- такі
- підходящий
- підтримка
- Підтриманий
- система
- таблиця
- пошиття одягу
- Приймати
- Takeaways
- приймає
- команда
- технології
- методи
- як правило,
- термін
- terms
- тест
- ніж
- Що
- Команда
- Джерело
- їх
- потім
- теоретичний
- теорія
- Там.
- тим самим
- отже
- Ці
- вони
- речі
- це
- ті
- три
- через
- пропускна здатність
- час
- Часовий ряд
- times
- до
- разом
- знак
- Жетони
- занадто
- Усього:
- tp
- простежувати
- поїзд
- переклад
- переклади
- Перетворення
- трансформатор
- правда
- ПЕРЕГЛЯД
- два
- тип
- Типи
- типово
- при
- розуміти
- розуміння
- університет
- Використання
- використання
- використання випадку
- використовуваний
- користувач
- User Experience
- користувачі
- використовує
- використання
- використовувати
- дійсний
- значення
- Цінності
- варіації
- різноманітність
- перевірити
- різнобічний
- дуже
- через
- бачення
- vs
- чекати
- хотіти
- теплий
- було
- шлях..
- способи
- we
- Web
- веб-сервіси
- ДОБРЕ
- були
- Що
- Що таке
- коли
- коли б ні
- в той час як
- який
- в той час як
- ВООЗ
- волі
- з
- в
- без
- Work
- робочий
- б
- ще
- поступаючись
- ви
- вашу
- зефірнет