Зображення на фрімуфільми on Freepik
Це епоха, коли прорив ШІ відбувається щодня. Кілька років тому у нас було небагато публічно створених ШІ, але зараз ця технологія доступна кожному. Це чудово підходить для багатьох окремих творців або компаній, які хочуть суттєво скористатися перевагами технології для розробки чогось складного, що може зайняти багато часу.
Одним із найнеймовірніших проривів, які змінюють нашу роботу, є випуск Модель GPT-3.5 від OpenAI. Що таке модель GPT-3.5? Якщо я дозволю моделі говорити за себе. У такому випадку відповідь така: «високорозвинена модель штучного інтелекту в області обробки природної мови з великими вдосконаленнями у створенні контекстуально точного та релевантного текстуt ”.
OpenAI надає API для моделі GPT-3.5, який ми можемо використовувати для розробки простого додатка, такого як текстовий підсумовувач. Для цього ми можемо використати Python для безпроблемної інтеграції API моделі в заплановану програму. Як виглядає процес? Давайте вникнемо в це.
Перед виконанням цього підручника необхідно виконати кілька обов’язкових умов, зокрема:
– Знання Python, включаючи знання використання зовнішніх бібліотек та IDE
– Розуміння API та керування кінцевою точкою за допомогою Python
– Наявність доступу до OpenAI API
Щоб отримати доступ до OpenAI API, ми повинні зареєструватися на Платформа розробника OpenAI і відвідайте ключі API перегляду у своєму профілі. В Інтернеті натисніть кнопку «Створити новий секретний ключ», щоб отримати доступ до API (див. зображення нижче). Не забудьте зберегти ключі, оскільки після цього вони не відображатимуться.

Зображення автора
З усіма підготовчими даними, давайте спробуємо зрозуміти основи моделі OpenAI API.
Команда Модель сімейства GPT-3.5 було визначено для багатьох мовних завдань, і кожна модель сімейства перевершує деякі завдання. Для цього навчального прикладу ми використаємо gpt-3.5-turbo оскільки це була рекомендована поточна модель на момент написання цієї статті через її можливості та економічну ефективність.
Ми часто використовуємо text-davinci-003 у підручнику OpenAI, але ми використаємо поточну модель для цього підручника. Ми б покладалися на ChatCompletion кінцева точка замість Завершення, оскільки поточна рекомендована модель – це модель чату. Навіть якщо назва була моделлю чату, вона працює для будь-якого мовного завдання.
Спробуємо розібратися, як працює API. По-перше, нам потрібно встановити поточні пакети OpenAI.
pip install openai
Після завершення встановлення пакета ми спробуємо використовувати API, підключившись через кінцеву точку ChatCompletion. Однак, перш ніж продовжити, нам потрібно налаштувати середовище.
У вашій улюбленій IDE (для мене це VS Code) створіть два файли під назвою .env та summarizer_app.py, схожий на зображення нижче.
Зображення автора
Команда summarizer_app.py де ми б створили наш простий додаток підсумовування, і .env файл, де ми будемо зберігати наш ключ API. З міркувань безпеки завжди радимо відокремлювати наш ключ API в іншому файлі, а не жорстко кодувати їх у файлі Python.
У .env файл введіть наступний синтаксис і збережіть файл. Замініть your_api_key_here фактичним ключем API. Не змінюйте ключ API на рядковий об’єкт; нехай як є.
OPENAI_API_KEY=your_api_key_here
Щоб краще зрозуміти API GPT-3.5; ми б використали наступний код для створення слова summarizer.
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
У наведеному вище коді показано, як ми взаємодіємо з моделлю OpenAI API GPT-3.5. Використовуючи API ChatCompletion, ми створюємо бесіду та отримуємо очікуваний результат після проходження підказки.
Давайте розберемо кожну частину, щоб краще зрозуміти їх. У першому рядку ми використовуємо openai.ChatCompletion.create код для створення відповіді на запит, який ми передаємо в API.
У наступному рядку ми маємо наші гіперпараметри, які ми використовуємо для покращення наших текстових завдань. Ось підсумок кожної функції гіперпараметра:
model: сімейство моделей, яке ми хочемо використовувати. У цьому посібнику ми використовуємо поточну рекомендовану модель (gpt-3.5-turbo).max_tokens: Верхня межа слів, згенерованих моделлю. Це допомагає обмежити довжину згенерованого тексту.temperature: випадковий вихід моделі з вищою температурою означає більш різноманітний і творчий результат. Діапазон значень — від 0 до нескінченності, хоча значення більше 2 не є поширеними.top_p: вибірка Top P або top-k або вибірка ядра є параметром для керування пулом вибірки з вихідного розподілу. Наприклад, значення 0.1 означає, що модель відбирає вихідні дані лише з 10% верхніх розподілів. Діапазон значень був від 0 до 1; вищі значення означають більш різноманітний результат.frequency_penalty: Штраф за маркер повторення з виведення. Діапазон значень від -2 до 2, де позитивні значення пригнічують модель повторюваного маркера, тоді як негативні значення спонукають модель використовувати більше повторюваних слів. 0 означає відсутність штрафу.messages: Параметр, куди ми передаємо наше текстове запрошення для обробки з моделлю. Ми передаємо список словників, де ключ є об’єктом ролі («система», «користувач» або «помічник»), який допомагає моделі зрозуміти контекст і структуру, тоді як значення є контекстом.- Рольова «система» — це встановлені керівні принципи моделі поведінки «помічника»,
- Роль «користувач» представляє підказку від особи, яка взаємодіє з моделлю,
- Роль «помічник» — це відповідь на підказку «користувач».
Пояснивши параметр вище, ми бачимо, що messages Параметр вище має два об’єкти словника. Перший словник - це те, як ми встановлюємо модель як підсумовувач тексту. По-друге, ми передаємо наш текст і отримуємо результат підсумовування.
У другому словнику ви також побачите змінну person_type та prompt, person_type це змінна, яку я використовував для керування коротким стилем, який я покажу в підручнику. У той час як prompt куди ми б передали наш текст, який потрібно підсумувати.
Продовжуючи навчальний посібник, розмістіть наведений нижче код у summarizer_app.py файл, і ми спробуємо проаналізувати, як працює наведена нижче функція.
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
У наведеному вище коді ми створюємо функцію Python, яка прийматиме різні параметри, які ми обговорювали раніше, і повертатиме текстовий підсумковий вихід.
Спробуйте функцію вище з вашим параметром і подивіться результат. Тоді давайте продовжимо урок, щоб створити просту програму з пакетом streamlit.
Стрітліт це пакет Python з відкритим вихідним кодом, призначений для створення веб-додатків машинного навчання та обробки даних. Він простий у використанні та інтуїтивно зрозумілий, тому його рекомендують багатьом початківцям.
Давайте встановимо пакет streamlit перед тим, як продовжити навчальний посібник.
pip install streamlit
Після завершення встановлення вставте наступний код у summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
Спробуйте запустити наступний код у командному рядку, щоб запустити програму.
streamlit run summarizer_app.py
Якщо все працює добре, ви побачите наступну програму у своєму браузері за умовчанням.
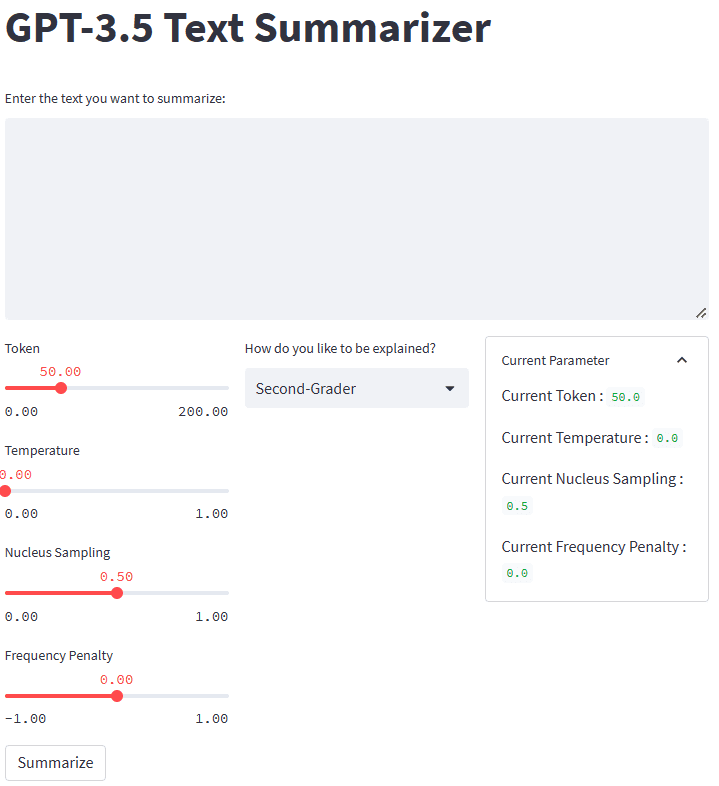
Зображення автора
Отже, що сталося в коді вище? Дозвольте мені коротко пояснити кожну функцію, яку ми використовували:
.st.title: надайте текст заголовка веб-програми..st.write: записує аргумент у програму; це може бути що завгодно, окрім переважно рядкового тексту..st.text_area: надайте область для введення тексту, яку можна зберегти у змінній і використовувати для запиту для нашого текстового підсумку.st.columns: Контейнери об’єктів для забезпечення паралельної взаємодії..st.slider: надайте віджет-повзунок із встановленими значеннями, з якими користувач може взаємодіяти. Значення зберігається у змінній, яка використовується як параметр моделі..st.selectbox: надайте користувачам віджет вибору для вибору потрібного стилю підсумовування. У прикладі вище ми використовуємо п’ять різних стилів..st.expander: надайте контейнер, який користувачі можуть розгорнути та вмістити кілька об’єктів..st.button: надайте кнопку, яка запускає призначену функцію, коли користувач натискає її.
Оскільки streamlit автоматично розробляв інтерфейс користувача, слідуючи заданому коду зверху вниз, ми могли б більше зосередитися на взаємодії.
З усіма частинами на місці, давайте спробуємо нашу програму підсумовування з текстовим прикладом. Для нашого прикладу я б використав Сторінка теорії відносності у Вікіпедії текст для конспектування. З параметром за замовчуванням і стилем другого класу ми отримуємо наступний результат.
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
Ви можете отримати інший результат, ніж наведений вище. Давайте спробуємо стиль Домогосподарок і трохи налаштуємо параметр (Жетона 100, Температура 0.5, Вибірка ядра 0.5, Штраф частоти 0.3).
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
Як ми бачимо, існує різниця в стилі для того самого тексту, який ми надаємо. З підказкою про зміну та параметром наша програма може бути більш функціональною.
Загальний вигляд нашої програми для підсумовування тексту можна побачити на зображенні нижче.
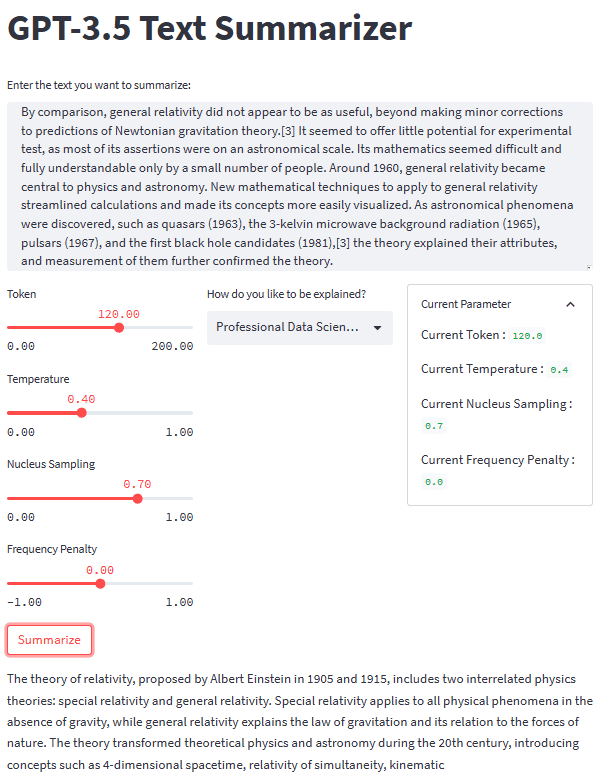
Зображення автора
Це навчальний посібник зі створення додатків для узагальнення тексту за допомогою GPT-3.5. Ви можете ще більше налаштувати додаток і розгорнути його.
Генеративний штучний інтелект зростає, і ми повинні використати цю можливість, створивши фантастичну програму. У цьому підручнику ми дізнаємося, як працюють GPT-3.5 OpenAI API і як їх використовувати для створення програми підсумовування тексту за допомогою Python і пакета streamlit.
Корнеліус Юдха Віджая є помічником менеджера з питань науки про дані та автора даних. Працюючи повний робочий день в Allianz Indonesia, він любить ділитися порадами щодо Python і даних у соціальних мережах і друкованих ЗМІ.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :є
- ][стор
- $UP
- 1
- 100
- 28
- 7
- a
- МЕНЮ
- вище
- Прийняти
- доступ
- доступною
- точний
- набувати
- просунутий
- Перевага
- після
- AI
- ВСІ
- Allianz
- хоча
- завжди
- та
- Інший
- відповідь
- API
- Доступ до API
- Інтерфейси
- додаток
- додаток
- Розробка додатка
- додатка
- ЕСТЬ
- ПЛОЩА
- аргумент
- стаття
- AS
- Помічник
- астрономія
- At
- автоматично
- основний
- BE
- оскільки
- перед тим
- початківці
- нижче
- Краще
- між
- Біт
- Black
- чорних дір
- дно
- Box
- Перерва
- прорив
- прориви
- коротко
- браузер
- будувати
- button
- by
- званий
- CAN
- випадок
- Століття
- зміна
- вибір
- клацання
- код
- Колони
- майбутній
- загальний
- Компанії
- завершення
- комплекс
- поняття
- З'єднувальний
- Контейнер
- Контейнери
- зміст
- контекст
- продовжувати
- контроль
- Розмова
- може
- створювати
- створення
- Креатив
- Творці
- Поточний
- щодня
- дані
- наука про дані
- вчений даних
- дефолт
- розгортання
- дизайн
- призначений
- розвивати
- Розробник
- розробка
- різниця
- різний
- відкрити
- обговорювалися
- розподіл
- Різне
- Не знаю
- вниз
- кожен
- або
- заохочувати
- Кінцева точка
- Що натомість? Створіть віртуальну версію себе у
- Навколишнє середовище
- Епоха
- Ефір (ETH)
- Навіть
- все
- все
- приклад
- відмінно
- виконувати
- Розширювати
- Пояснювати
- пояснені
- Пояснює
- зовнішній
- сім'я
- фантастичний
- Улюблений
- кілька
- поле
- філе
- Файли
- Перший
- Сфокусувати
- після
- для
- Війська
- частота
- від
- функція
- функціональний
- далі
- Загальне
- породжувати
- генерується
- породжує
- отримати
- даний
- гравітаційний
- Гравітаційні хвилі
- вага
- керівні вказівки
- Обробка
- сталося
- Мати
- має
- допомога
- допоміг
- корисний
- допомагає
- тут
- вище
- дуже
- тримати
- Отвори
- Як
- How To
- Як ми працюємо
- Однак
- HTTPS
- i
- ідеї
- зображення
- імпорт
- важливо
- удосконалювати
- поліпшення
- in
- includes
- У тому числі
- неймовірний
- індивідуальний
- Індонезія
- Infinity
- ініціювати
- вхід
- встановлювати
- установка
- замість
- інтегрувати
- взаємодіяти
- взаємодіючих
- взаємодія
- введення
- інтуїтивний
- IT
- ЙОГО
- JPG
- KDnuggets
- ключ
- ключі
- знання
- мова
- закон
- УЧИТЬСЯ
- вивчення
- довжина
- libraries
- як
- МЕЖА
- Лінія
- список
- Довго
- багато часу
- подивитися
- виглядає як
- машина
- навчання за допомогою машини
- менеджер
- багато
- засоби
- Медіа
- повідомлення
- може бути
- модель
- більше
- найбільш
- рухатися
- множинний
- ім'я
- Природний
- Природна мова
- Обробка природних мов
- природа
- Необхідність
- негативний
- Нові
- наступний
- об'єкт
- об'єкти
- отримувати
- of
- on
- ONE
- з відкритим вихідним кодом
- OpenAI
- Можливість
- варіант
- OS
- Інше
- вихід
- загальний
- пакет
- пакети
- параметр
- параметри
- частина
- Проходження
- людина
- фізичний
- Фізика
- частин
- місце
- Планети
- plato
- Інформація про дані Платона
- PlatoData
- басейн
- позитивний
- прогнозування
- передумови
- раніше
- процес
- обробка
- професійний
- профіль
- запропонований
- забезпечувати
- забезпечує
- громадськість
- put
- Python
- випадковість
- діапазон
- швидше
- готовий
- Причини
- рекомендований
- реєструвати
- зв'язок
- звільнити
- доречний
- запам'ятати
- повторювані
- замінювати
- представляє
- відповідь
- результат
- повертати
- підвищення
- Роль
- прогін
- то ж
- зберегти
- наука
- вчений
- плавно
- другий
- секрет
- розділ
- безпеку
- вибір
- окремий
- комплект
- Поділитись
- Повинен
- Показувати
- показаний
- істотно
- аналогічний
- простий
- повзунок
- розумний
- So
- соціальна
- соціальні медіа
- деякі
- що в сім'ї щось
- Простір
- спеціальний
- зазначений
- Зірки
- зберігати
- зберігати
- рядок
- структура
- студент
- стиль
- Стилі
- такі
- підсумовувати
- РЕЗЮМЕ
- синтаксис
- система
- Приймати
- балаканина
- Переговори
- Завдання
- завдання
- Технологія
- Що
- Команда
- закон
- світ
- Їх
- самі
- теоретичний
- Ці
- речі
- три
- через
- час
- Поради
- назва
- до
- знак
- топ
- перетворений
- підручник
- ui
- розуміти
- розуміння
- університет
- us
- використання
- користувач
- користувачі
- використовувати
- значення
- Цінності
- різний
- величезний
- через
- вид
- візит
- vs
- проти коду
- хвилі
- Web
- Веб-додаток
- ДОБРЕ
- Що
- Що таке
- який
- в той час як
- ВООЗ
- Вікіпедія
- волі
- з
- в
- без
- слово
- слова
- Work
- робочий
- працює
- світ
- б
- письменник
- лист
- письмовий
- років
- вашу
- зефірнет