OpenAI Whisper це розширена модель автоматичного розпізнавання мовлення (ASR) з ліцензією MIT. Технологія ASR знаходить застосування в службах транскрипції, голосових помічниках і покращенні доступності для людей з вадами слуху. Ця найсучасніша модель напрацьована на величезному та різноманітному наборі багатомовних і багатозадачних контрольованих даних, зібраних з Інтернету. Його висока точність і адаптивність роблять його цінним активом для широкого спектру голосових завдань.
У постійному розвитку машинного навчання та штучного інтелекту, Amazon SageMaker забезпечує комплексну екосистему. SageMaker дає змогу дослідникам даних, розробникам і організаціям розробляти, навчати, розгортати та керувати моделями машинного навчання в масштабі. Пропонуючи широкий спектр інструментів і можливостей, він спрощує весь робочий процес машинного навчання, від попередньої обробки даних і розробки моделі до легкого розгортання та моніторингу. Зручний інтерфейс SageMaker робить його ключовою платформою для розкриття повного потенціалу штучного інтелекту, утверджуючи його як кардинальне рішення у сфері штучного інтелекту.
У цій публікації ми розпочинаємо дослідження можливостей SageMaker, особливо зосереджуючись на розміщенні моделей Whisper. Ми детально розглянемо два методи для цього: один використовує модель Whisper PyTorch, а інший використовує реалізацію Hugging Face моделі Whisper. Крім того, ми проведемо поглиблений аналіз варіантів висновків SageMaker, порівнюючи їх за такими параметрами, як швидкість, вартість, розмір корисного навантаження та масштабованість. Цей аналіз дає змогу користувачам приймати зважені рішення під час інтеграції моделей Whisper у їхні конкретні варіанти використання та системи.
Огляд рішення
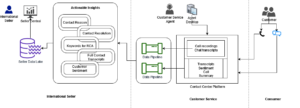
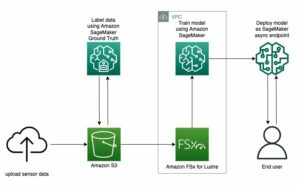
На наступній діаграмі показано основні компоненти цього рішення.
- Щоб розмістити модель на Amazon SageMaker, першим кроком є збереження артефактів моделі. Ці артефакти відносяться до важливих компонентів моделі машинного навчання, необхідних для різних програм, включаючи розгортання та перенавчання. Вони можуть містити параметри моделі, файли конфігурації, компоненти попередньої обробки, а також метадані, такі як деталі версії, авторство та будь-які примітки, пов’язані з її продуктивністю. Важливо зазначити, що моделі Whisper для реалізації PyTorch і Hugging Face складаються з різних артефактів моделі.
- Далі ми створюємо власні сценарії висновків. У цих сценаріях ми визначаємо спосіб завантаження моделі та визначаємо процес висновку. Тут ми також можемо включити спеціальні параметри за потреби. Крім того, ви можете перерахувати необхідні пакети Python у a
requirements.txtфайл. Під час розгортання моделі ці пакети Python автоматично встановлюються на етапі ініціалізації. - Потім ми вибираємо контейнери глибокого навчання (DLC) PyTorch або Hugging Face, надані та підтримувані AWS. Ці контейнери є попередньо зібраними образами Docker із фреймворками глибокого навчання та іншими необхідними пакетами Python. Для отримання додаткової інформації ви можете перевірити це link.
- За допомогою артефактів моделі, власних сценаріїв висновку та вибраних DLC ми створимо моделі Amazon SageMaker для PyTorch і Hugging Face відповідно.
- Нарешті, моделі можна розгорнути на SageMaker і використовувати з такими параметрами: кінцеві точки висновку в реальному часі, завдання пакетного перетворення та кінцеві точки асинхронного висновку. Ми розглянемо ці варіанти більш детально пізніше в цій публікації.
Приклад блокнота та код для цього рішення доступні тут GitHub сховище.
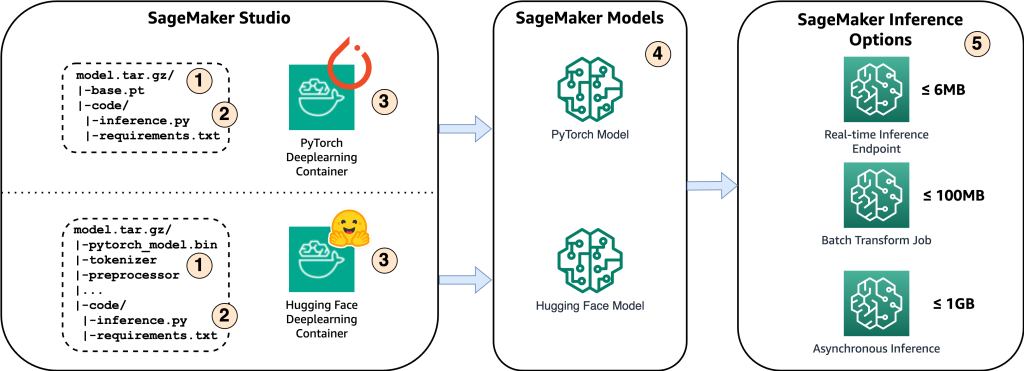
Рисунок 1. Огляд ключових компонентів рішення
Проходження
Розміщення моделі Whisper на Amazon SageMaker
У цьому розділі ми пояснимо, як розмістити модель Whisper на Amazon SageMaker за допомогою PyTorch і Hugging Face Frameworks відповідно. Щоб експериментувати з цим рішенням, вам потрібен обліковий запис AWS і доступ до служби Amazon SageMaker.
Фреймворк PyTorch
- Збережіть артефакти моделі
Першим варіантом розміщення моделі є використання Офіційний пакет Whisper для Python, який можна встановити за допомогою pip install openai-whisper. Цей пакет надає модель PyTorch. Під час збереження артефактів моделі в локальному сховищі першим кроком є збереження параметрів моделі, які можна вивчати, таких як ваги моделі та зміщення кожного шару в нейронній мережі, у вигляді файлу «pt». Ви можете вибрати з різних розмірів моделей, зокрема «крихітний», «базовий», «маленький», «середній» і «великий». Великі розміри моделі пропонують вищу точність, але ціною довшої затримки висновку. Крім того, вам потрібно зберегти словник стану моделі та словник розмірів, які містять словник Python, який зіставляє кожен шар або параметр моделі PyTorch з відповідними параметрами, які можна вивчати, разом з іншими метаданими та спеціальними конфігураціями. Код нижче показує, як зберегти артефакти Whisper PyTorch.
- Виберіть DLC
Наступним кроком буде вибір із цього попередньо зібраного DLC link. Будьте обережні, вибираючи правильний образ, враховуючи такі параметри: фреймворк (PyTorch), фреймворк, завдання (висновок), версія Python і апаратне забезпечення (тобто GPU). Рекомендується використовувати найновіші версії фреймворку та Python, коли це можливо, оскільки це призводить до кращої продуктивності та усунення відомих проблем і помилок із попередніх випусків.
- Створюйте моделі Amazon SageMaker
Далі ми використовуємо SageMaker Python SDK для створення моделей PyTorch. Важливо пам’ятати про додавання змінних середовища під час створення моделі PyTorch. За замовчуванням TorchServe може обробляти лише файли розміром до 6 МБ, незалежно від використовуваного типу висновку.
У наступній таблиці показано налаштування для різних версій PyTorch:
| Рамки | Змінні середовища |
| PyTorch 1.8 (на основі TorchServe) | "TS_MAX_REQUEST_SIZE': '100000000'" TS_MAX_RESPONSE_SIZE': '100000000'" TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (на основі MMS) | "MMS_MAX_REQUEST_SIZE': '1000000000'" MMS_MAX_RESPONSE_SIZE': '1000000000'" MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Визначте метод завантаження моделі в inference.py
У звичаї inference.py сценарію, ми спочатку перевіряємо наявність графічного процесора, сумісного з CUDA. Якщо такий GPU доступний, ми призначаємо 'cuda' пристрій до DEVICE змінна; інакше ми призначаємо 'cpu' пристрій. Цей крок гарантує, що модель розміщено на доступному обладнанні для ефективного обчислення. Ми завантажуємо модель PyTorch за допомогою пакета Whisper Python.
Рамка «Обіймати обличчя».
- Збережіть артефакти моделі
Другий варіант - використовувати Шепіт обіймаючого обличчя впровадження. Модель можна завантажити за допомогою AutoModelForSpeechSeq2Seq клас трансформери. Параметри, які можна вивчати, зберігаються у двійковому файлі (bin) за допомогою save_pretrained метод. Токенізатор і препроцесор також потрібно зберегти окремо, щоб модель Hugging Face працювала належним чином. Крім того, ви можете розгорнути модель на Amazon SageMaker безпосередньо з Hugging Face Hub, установивши дві змінні середовища: HF_MODEL_ID та HF_TASK. Для отримання додаткової інформації зверніться до цього веб-сторінка.
- Виберіть DLC
Подібно до фреймворку PyTorch, ви можете вибрати попередньо зібраний DLC Hugging Face із того самого link. Переконайтеся, що ви вибрали DLC, який підтримує найновіші трансформери Hugging Face і включає підтримку GPU.
- Створюйте моделі Amazon SageMaker
Так само ми використовуємо SageMaker Python SDK для створення моделей Hugging Face. Модель Hugging Face Whisper має обмеження за замовчуванням, коли вона може обробляти лише аудіосегменти тривалістю до 30 секунд. Щоб усунути це обмеження, ви можете включити chunk_length_s параметр у змінній середовища під час створення моделі Hugging Face, а потім передайте цей параметр у настроюваний сценарій висновку під час завантаження моделі. Нарешті, установіть змінні середовища, щоб збільшити розмір корисного навантаження та час очікування відповіді для контейнера Hugging Face.
| Рамки | Змінні середовища |
|
Контейнер висновків HuggingFace (на основі MMS) |
"MMS_MAX_REQUEST_SIZE': '2000000000'" MMS_MAX_RESPONSE_SIZE': '2000000000'" MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Визначте метод завантаження моделі в inference.py
Під час створення спеціального сценарію висновку для моделі Hugging Face ми використовуємо конвеєр, що дозволяє нам передавати chunk_length_s як параметр. Цей параметр дозволяє моделі ефективно обробляти довгі аудіофайли під час висновку.
Вивчення різних варіантів висновків на Amazon SageMaker
Кроки для вибору параметрів висновку однакові для моделей PyTorch і Hugging Face, тому ми не будемо розрізняти їх нижче. Однак варто зазначити, що на момент написання цього допису безсерверний висновок опція від SageMaker не підтримує графічні процесори, тому ми виключаємо цю опцію для цього випадку використання.
Ми можемо розгорнути модель як кінцеву точку реального часу, надаючи відповіді за мілісекунди. Однак важливо зазначити, що цей параметр обмежено обробкою вхідних даних розміром менше 6 МБ. Ми визначаємо серіалізатор як аудіо серіалізатор, який відповідає за перетворення вхідних даних у відповідний формат для розгорнутої моделі. Ми використовуємо екземпляр GPU для висновків, що дозволяє прискорити обробку аудіофайлів. Вхідними даними є аудіофайл із локального сховища.
Другий варіант висновку — це завдання пакетного перетворення, яке здатне обробляти вхідні дані розміром до 100 МБ. Однак цей метод може зайняти кілька хвилин затримки. Кожен екземпляр може обробляти лише один пакетний запит за раз, а ініціація та завершення екземпляра також потребують кількох хвилин. Результати висновків зберігаються в Amazon Simple Storage Service (Amazon S3) після завершення завдання пакетного перетворення.
При налаштуванні пакетного трансформатора обов'язково включайте max_payload = 100 для ефективної обробки великих корисних навантажень. Вхідними даними має бути шлях Amazon S3 до аудіофайлу або папка Amazon S3 Bucket, яка містить список аудіофайлів, кожен розміром менше 100 МБ.
Пакетне перетворення розділяє об’єкти Amazon S3 у вхідних даних за ключем і відображає об’єкти Amazon S3 на екземпляри. Наприклад, якщо у вас є кілька аудіофайлів, один екземпляр може обробити input1.wav, а інший екземпляр може обробити файл з іменем input2.wav для покращення масштабованості. Пакетне перетворення дозволяє налаштувати max_concurrent_transforms щоб збільшити кількість запитів HTTP до кожного окремого контейнера трансформатора. Однак важливо зазначити, що значення (max_concurrent_transforms* max_payload) не має перевищувати 100 Мб.
Нарешті, Amazon SageMaker Asynchronous Inference ідеально підходить для одночасної обробки кількох запитів, пропонуючи помірну затримку та підтримуючи корисне навантаження введення до 1 ГБ. Ця опція забезпечує відмінну масштабованість, уможливлюючи конфігурацію групи автоматичного масштабування для кінцевої точки. Коли виникає сплеск запитів, він автоматично масштабується для обробки трафіку, а після обробки всіх запитів кінцева точка зменшується до 0, щоб заощадити кошти.
За допомогою асинхронного висновку результати автоматично зберігаються в сегменті Amazon S3. В AsyncInferenceConfig, ви можете налаштувати сповіщення про успішне або невдале завершення. Шлях введення вказує на розташування аудіофайлу в Amazon S3. Щоб отримати додаткові відомості, зверніться до коду на GitHub.
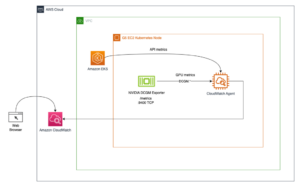
Додатково: Як згадувалося раніше, у нас є можливість налаштувати групу автомасштабування для кінцевої точки асинхронного висновку, що дозволяє їй обробляти раптовий сплеск запитів на висновки. Тут наведено приклад коду GitHub сховище. На наведеній нижче діаграмі ви можете спостерігати лінійну діаграму, яка відображає два показники з Amazon CloudWatch: ApproximateBacklogSize та ApproximateBacklogSizePerInstance. Спочатку, коли було запущено 1000 запитів, лише один екземпляр був доступний для обробки висновку. Протягом трьох хвилин розмір відставання постійно перевищував три (будь ласка, зверніть увагу, що ці числа можна налаштувати), і група автомасштабування у відповідь випустила додаткові екземпляри, щоб ефективно очистити відставання. Це призвело до значного зниження в ApproximateBacklogSizePerInstance, що дозволяє обробляти невиконані запити набагато швидше, ніж на початковому етапі.

Рисунок 2. Лінійна діаграма, що ілюструє тимчасові зміни показників Amazon CloudWatch
Порівняльний аналіз за варіантами висновків
Порівняння для різних варіантів висновків базується на загальних випадках обробки аудіо. Висновок у реальному часі пропонує найшвидшу швидкість висновку, але обмежує розмір корисного навантаження до 6 МБ. Цей тип висновку підходить для систем аудіокоманд, де користувачі керують пристроями або програмним забезпеченням або взаємодіють із ними за допомогою голосових команд або голосових інструкцій. Голосові команди, як правило, невеликі за розміром, і низька затримка логічного висновку має вирішальне значення для того, щоб транскрибовані команди могли швидко ініціювати подальші дії. Пакетне перетворення ідеально підходить для запланованих офлайн-завдань, коли розмір кожного аудіофайлу менше 100 МБ, і немає спеціальних вимог щодо швидкого часу відповіді висновку. Асинхронний висновок дозволяє завантажувати до 1 ГБ і пропонує помірну затримку висновку. Цей тип висновків добре підходить для транскрибування фільмів, серіалів і записів конференцій, де потрібно обробити більші аудіофайли.
Як параметри реального часу, так і асинхронного висновку забезпечують можливості автоматичного масштабування, дозволяючи примірникам кінцевої точки автоматично збільшувати або зменшувати масштаб залежно від обсягу запитів. У випадках відсутності запитів автомасштабування видаляє непотрібні екземпляри, допомагаючи вам уникнути витрат, пов’язаних із підготовленими екземплярами, які не використовуються активно. Однак для висновку в реальному часі необхідно зберегти принаймні один постійний екземпляр, що може призвести до вищих витрат, якщо кінцева точка працює безперервно. Навпаки, асинхронний висновок дозволяє зменшити обсяг екземпляра до 0, коли він не використовується. Під час налаштування завдання пакетного перетворення можна використовувати кілька екземплярів для обробки завдання та налаштувати max_concurrent_transforms, щоб дозволити одному екземпляру обробляти кілька запитів. Таким чином, усі три варіанти висновків пропонують чудову масштабованість.
Очищення
Після завершення використання рішення видаліть кінцеві точки SageMaker, щоб уникнути додаткових витрат. Ви можете використовувати наданий код для видалення кінцевих точок реального часу та асинхронного висновку відповідно.
Висновок
У цій публікації ми показали вам, як розгортання моделей машинного навчання для обробки аудіо стає все більш важливим у різних галузях. На прикладі моделі Whisper ми продемонстрували, як розмістити моделі ASR з відкритим кодом на Amazon SageMaker за допомогою підходів PyTorch або Hugging Face. Дослідження охоплювало різні варіанти висновків на Amazon SageMaker, пропонуючи уявлення про ефективну обробку аудіоданих, прогнозування та ефективне управління витратами. Ця публікація має на меті надати знання дослідникам, розробникам і дослідникам даних, зацікавленим у використанні моделі Whisper для завдань, пов’язаних із аудіо, і прийняття обґрунтованих рішень щодо стратегій логічного висновку.
Щоб отримати докладнішу інформацію про розгортання моделей на SageMaker, зверніться до цього Керівництво розробника. Крім того, модель Whisper можна розгорнути за допомогою SageMaker JumpStart. Для отримання додаткової інформації, будь ласка, перевірте Моделі Whisper для автоматичного розпізнавання мовлення тепер доступні в Amazon SageMaker JumpStart пост
Не соромтеся перевірити блокнот і код для цього проекту на GitHub і поділіться з нами своїм коментарем.
Про автора
 Ін Хоу, доктор філософії, є архітектором прототипування машинного навчання в AWS. Основні сфери її інтересів охоплюють глибоке навчання з акцентом на GenAI, комп’ютерне зір, НЛП та прогнозування даних часових рядів. У вільний час вона із задоволенням проводить якісні моменти зі своєю сім’єю, занурюється в романи та здійснює походи в національні парки Великобританії.
Ін Хоу, доктор філософії, є архітектором прототипування машинного навчання в AWS. Основні сфери її інтересів охоплюють глибоке навчання з акцентом на GenAI, комп’ютерне зір, НЛП та прогнозування даних часових рядів. У вільний час вона із задоволенням проводить якісні моменти зі своєю сім’єю, занурюється в романи та здійснює походи в національні парки Великобританії.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- прискорений
- доступ
- доступність
- рахунки
- точність
- через
- дії
- активно
- додавати
- Додатковий
- Додатково
- адреса
- регулювати
- просунутий
- AI
- Цілі
- ВСІ
- Дозволити
- дозволяє
- по
- Також
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- аналіз
- та
- Інший
- будь-який
- застосування
- підходи
- ЕСТЬ
- області
- масив
- штучний
- штучний інтелект
- AS
- активи
- помічники
- асоційований
- At
- аудіо
- Авторство
- автоматичний
- автоматично
- наявність
- доступний
- уникнути
- AWS
- база
- заснований
- BE
- ставати
- нижче
- Краще
- між
- упередження
- BIN
- обидва
- помилки
- але
- by
- CAN
- можливості
- здатний
- обережний
- випадків
- Зміни
- Графік
- перевірка
- Вибирати
- Вибираючи
- клас
- ясно
- код
- Приходити
- коментар
- загальний
- порівняння
- порівняння
- Зроблено
- завершення
- Компоненти
- всеосяжний
- обчислення
- комп'ютер
- Комп'ютерне бачення
- Проводити
- конференції
- конфігурація
- налаштувати
- конфігурування
- беручи до уваги
- послідовно
- містити
- Контейнер
- Контейнери
- постійно
- контрастність
- контроль
- перетворення
- виправити
- Відповідний
- Коштувати
- витрати
- може
- центральний процесор
- створювати
- створення
- вирішальне значення
- виготовлений на замовлення
- дані
- рішення
- зменшити
- глибокий
- глибоке навчання
- дефолт
- визначати
- продемонстрований
- розгортання
- розгорнути
- розгортання
- розгортання
- деталь
- докладно
- деталі
- розвивати
- розробників
- розробка
- пристрій
- прилади
- різний
- диференціювати
- Розмір
- безпосередньо
- показ
- занурення
- Різне
- Docker
- Ні
- справи
- вниз
- під час
- e
- кожен
- Раніше
- екосистема
- фактично
- ефективний
- продуктивно
- без зусиль
- або
- ще
- приступати
- повноваження
- включіть
- дозволяє
- дозволяє
- охоплювати
- Кінцева точка
- кінцеві точки
- підвищувати
- підвищення
- забезпечувати
- гарантує
- Весь
- Навколишнє середовище
- істотний
- налагодження
- Ефір (ETH)
- експертиза
- приклад
- перевищувати
- перевищений
- відмінно
- експеримент
- Пояснювати
- дослідження
- Дослідження
- Face
- не вдалося
- false
- сім'я
- ШВИДКО
- швидше
- швидкий
- кілька
- філе
- Файли
- знахідки
- Перший
- Сфокусувати
- фокусування
- після
- для
- формат
- Рамки
- каркаси
- Безкоштовна
- від
- Повний
- GPU
- Графічні процесори
- великий
- Group
- обробляти
- Обробка
- апаратні засоби
- Мати
- слух
- допомогу
- її
- Високий
- вище
- піший туризм
- господар
- хостинг
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- Концентратор
- HuggingFace
- i
- ідеальний
- if
- ілюструють
- зображення
- зображень
- реалізація
- реалізації
- імпорт
- важливо
- in
- поглиблений
- включати
- includes
- У тому числі
- включати
- Augmenter
- все більше і більше
- індивідуальний
- осіб
- промисловості
- інформація
- повідомив
- початковий
- спочатку
- ініціювання
- вхід
- витрати
- розуміння
- встановлювати
- екземпляр
- випадки
- інструкції
- Інтеграція
- Інтелект
- взаємодіяти
- інтерес
- зацікавлений
- інтерфейс
- в
- питання
- IT
- ЙОГО
- робота
- Джобс
- JPG
- ключ
- знання
- відомий
- ландшафт
- більше
- нарешті
- Затримка
- пізніше
- останній
- шар
- вести
- вивчення
- найменш
- використання
- ліцензія
- обмеження
- обмеженою
- Лінія
- список
- загрузка
- погрузка
- місцевий
- розташування
- Довго
- довше
- низький
- машина
- навчання за допомогою машини
- made
- головний
- зробити
- РОБОТИ
- Робить
- управляти
- управління
- карти
- Може..
- згаданий
- метадані
- метод
- методика
- Метрика
- може бути
- мілісекунд
- протокол
- MIT
- ML
- модель
- Моделі
- поміркованому
- Моменти
- моніторинг
- більше
- кіно
- багато
- множинний
- повинен
- Названий
- National
- національні парки
- необхідно
- Необхідність
- необхідний
- мережу
- Нейронний
- нейронної мережі
- наступний
- nlp
- немає
- увагу
- ноутбук
- примітки
- сповіщення
- Повідомлення
- відзначивши,
- зараз
- номер
- номера
- об'єкт
- об'єкти
- спостерігати
- of
- пропонувати
- пропонує
- Пропозиції
- офіційний
- offline
- on
- один раз
- ONE
- тільки
- з відкритим вихідним кодом
- працює
- варіант
- Опції
- or
- порядок
- організації
- OS
- Інше
- інакше
- з
- огляд
- пакет
- пакети
- параметр
- параметри
- парки
- проходити
- шлях
- виконувати
- продуктивність
- фаза
- трубопровід
- основний
- розміщений
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- будь ласка
- точок
- це можливо
- пошта
- потенціал
- прогноз
- Прогнози
- запобігати
- попередній
- первинний
- процес
- оброблена
- обробка
- процесор
- проект
- правильно
- макетування
- забезпечувати
- за умови
- забезпечує
- забезпечення
- Python
- піторх
- якість
- діапазон
- реального часу
- царство
- визнання
- рекомендований
- записаний
- Знижений
- послатися
- Незалежно
- пов'язаний
- Релізи
- запам'ятати
- видаляти
- видаляє
- Сховище
- запросити
- запитів
- вимагати
- вимагається
- вимога
- Дослідники
- відповідно
- відповідь
- відповіді
- відповідальний
- результат
- призвело до
- результати
- зберігся
- перепідготовка
- повертати
- мудрець
- то ж
- зберегти
- зберігаються
- економія
- масштабованість
- шкала
- ваги
- плановий
- Вчені
- сценарій
- scripts
- другий
- seconds
- розділ
- сегменти
- вибрати
- обраний
- вибирає
- Серія
- обслуговування
- Послуги
- комплект
- установка
- налаштування
- Поділитись
- вона
- Повинен
- показав
- Шоу
- вимикання
- значний
- простий
- спрощує
- Розмір
- розміри
- невеликий
- менше
- So
- Софтвер
- рішення
- конкретний
- конкретно
- зазначений
- мова
- Розпізнавання мови
- швидкість
- Витрати
- говорять
- старт
- стан
- впроваджений
- Крок
- заходи
- зберігання
- стратегії
- наступні
- успішний
- такі
- раптовий
- підходящий
- підтримка
- Підтримуючий
- Опори
- Переконайтеся
- сплеск
- Systems
- таблиця
- Приймати
- взяття
- Завдання
- завдання
- Технологія
- ніж
- Що
- Команда
- Великобританія
- їх
- Їх
- потім
- Там.
- отже
- Ці
- вони
- це
- три
- час
- Часовий ряд
- times
- до
- інструменти
- факел
- трафік
- поїзд
- навчений
- Перетворення
- трансформатор
- Трансформатори
- викликати
- спрацьовує
- tv
- Серіали
- два
- тип
- типово
- Uk
- при
- розблокування
- на
- us
- використання
- використовуваний
- зручно
- користувачі
- використання
- утиліта
- використовувати
- використовує
- Цінний
- значення
- змінна
- різний
- величезний
- версія
- бачення
- Голос
- голосові команди
- обсяг
- чекати
- хотіти
- було
- we
- Web
- веб-сервіси
- ДОБРЕ
- були
- коли
- коли б ні
- який
- Шепіт
- широкий
- Широкий діапазон
- з
- в
- робочий
- працює
- вартість
- лист
- ви
- вашу
- зефірнет