Сьогодні ми робимо доступною нову можливість для Клей AWS Каталог даних що дозволяє генерувати статистику на рівні стовпця для таблиць AWS Glue. Ця статистика тепер інтегрована з оптимізаторами на основі витрат (CBO). Амазонка Афіна і Amazon Спектр червоного зсуву, що призвело до покращення продуктивності запитів і потенційної економії коштів.
Озера даних призначені для зберігання величезних обсягів необроблених, неструктурованих або напівструктурованих даних за низькою ціною, і організації спільно використовують ці набори даних між кількома відділами та групами. Запити до цих великих наборів даних читають величезні обсяги даних і можуть виконувати складні операції з’єднання з кількома наборами даних. Під час розмови з нашими клієнтами ми дізналися, що одним із складних аспектів продуктивності озера даних є те, як оптимізувати ці аналітичні запити, щоб вони виконувалися швидше.
Оптимізація продуктивності озера даних особливо важлива для запитів із кількома об’єднаннями, і саме тут оптимізатори на основі вартості допомагають найбільше. Для того, щоб CBO працював, статистичні дані стовпців потрібно збирати та оновлювати на основі змін у даних. Ми запускаємо можливість генерувати статистичні дані на рівні стовпців, такі як кількість окремих, кількість нульових значень, максимальне та мінімальне значення для таких файлів, як Parquet, ORC, JSON, Amazon ION, CSV, XML у таблицях AWS Glue. З цим запуском клієнти тепер мають інтегрований наскрізний досвід, де статистика таблиць Glue збирається та зберігається в каталозі Glue AWS і стає доступною для аналітичних служб для покращеного планування та виконання запитів.
Використовуючи цю статистику, оптимізатори на основі витрат покращують плани виконання запитів і підвищують продуктивність запитів, що виконуються в Amazon Athena та Amazon Redshift Spectrum. Наприклад, CBO може використовувати статистику стовпця, таку як кількість окремих значень і кількість нульових значень, щоб покращити прогнозування рядків. Прогнозування рядків — це кількість рядків із таблиці, які буде повернуто певним кроком на етапі планування запиту. Чим точніші прогнози рядків, тим ефективніші кроки виконання запиту. Це призводить до швидшого виконання запитів і потенційного зниження витрат. Деякі з конкретних оптимізацій, які CBO може застосувати, включають перевпорядкування об’єднань і зсув агрегацій на основі статистики, доступної для кожної таблиці та стовпця.
Для клієнтів, які використовують сітка даних з Формування озера AWS дозволи, таблиці від різних виробників даних каталогізуються в облікових записах централізованого керування. Оскільки вони генерують статистику для таблиць у централізованому каталозі та надають доступ до цих таблиць споживачам, запити до цих таблиць в облікових записах споживачів автоматично покращуватимуть продуктивність запитів. У цій публікації ми продемонструємо можливість AWS Glue Data Catalog генерувати статистику стовпців для наших зразків таблиць.
Огляд рішення
Щоб продемонструвати ефективність цієї можливості, ми використовуємо галузевий стандартний набір даних TPC-DS 3 ТБ, який зберігається в Amazon Simple Storage Service (Amazon S3) публічне відро. Ми порівняємо продуктивність запитів до та після створення статистики стовпців для таблиць, запустивши запити в Amazon Athena та Amazon Redshift Spectrum. Ми надаємо запити, які використовувалися в цій публікації, і радимо спробувати власні запити, дотримуючись робочого процесу, як показано в наведених нижче деталях.
Робочий процес складається з наступних етапів високого рівня:
- Каталогізація Amazon S3 Bucket: Використовуйте AWS Glue Crawler, щоб сканувати призначене відро Amazon S3, видобувати метадані та безперешкодно зберігати їх у каталозі даних AWS Glue. Ми будемо запитувати ці таблиці за допомогою Amazon Athena та Amazon Redshift Spectrum.
- Створення статистики стовпців: Використовуйте розширені можливості AWS Glue Data Catalog, щоб генерувати вичерпну статистику стовпців для просканованих даних, надаючи тим самим цінну інформацію про набір даних.
- Запити за допомогою Amazon Athena та Amazon Redshift Spectrum: Оцініть вплив статистики стовпців на продуктивність запитів, використовуючи Amazon Athena та Amazon Redshift Spectrum для виконання запитів до набору даних.
Наступна діаграма ілюструє архітектуру рішення.
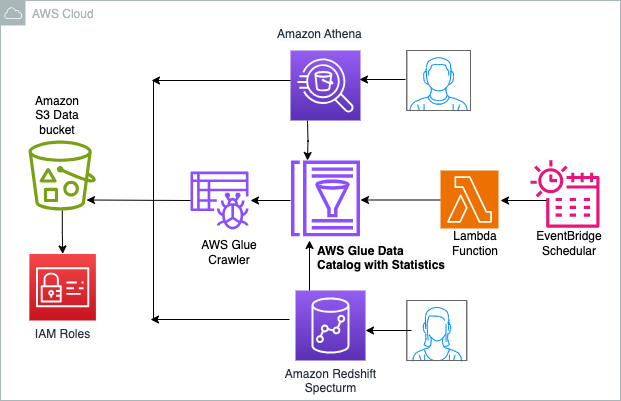
Проходження
Для реалізації рішення ми виконуємо наступні кроки:
- Налаштуйте ресурси за допомогою AWS CloudFormation.
- Запустіть AWS Glue Crawler у публічному сегменті Amazon S3, щоб отримати список набору даних TPC-DS розміром 3 ТБ.
- Запустіть запити в Amazon Athena та Amazon Redshift і запишіть тривалість запиту
- Створення статистики для таблиць AWS Glue Data Catalog
- Виконайте запити в Amazon Athena та Amazon Redshift і порівняйте тривалість запиту з попереднім виконанням
- Додатково: плануйте завдання зі статистикою стовпців AWS Glue за допомогою AWS Lambda та планувальника Amazon EventBridge
Налаштуйте ресурси за допомогою AWS CloudFormation
Ця публікація включає AWS CloudFormation шаблон для швидкого налаштування. Ви можете переглянути та налаштувати його відповідно до своїх потреб. Шаблон створює такі ресурси:
- Віртуальна приватна хмара Amazon (Amazon VPC), публічна підмережа, приватні підмережі та таблиці маршрутів.
- Безсерверна робоча група та простір імен Amazon Redshift.
- Кроулер AWS Glue для сканування загальнодоступного сегмента Amazon S3 і створення таблиці для каталогу Glue Data Catalog для набору даних TPC-DS
- Бази даних і таблиці каталогу AWS Glue
- Відро Amazon S3 для зберігання результатів Athena.
- Управління ідентифікацією та доступом AWS (AWS IAM) користувачів і політик.
- Планувальник AWS Lambda та Amazon Event Bridge для планування статистики AWS Glue Column
Щоб запустити стек AWS CloudFormation, виконайте такі дії:
примітки: таблиці каталогу даних AWS Glue створюються за допомогою загальнодоступного сегмента s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/, розміщений у us-east-1 область. Якщо ви маєте намір розгорнути цей шаблон AWS CloudFormation в іншому регіоні, необхідно або скопіювати дані у відповідний регіон, або надати спільний доступ до даних у вашому розгорнутому регіоні, щоб вони були доступні з Amazon Redshift.
- Увійти в Консоль управління AWS як AWS Identity and Access Management (AWS IAM) адміністратор
- Виберіть Launch Stack, щоб розгорнути шаблон AWS CloudFormation.

- Вибирати МАЙБУТНІ.
- На наступній сторінці залиште всі параметри за замовчуванням або внесіть відповідні зміни відповідно до ваших вимог МАЙБУТНІ.
- Перегляньте деталі на останній сторінці та виберіть Я визнаю, що AWS CloudFormation може створювати ресурси IAM.
- Вибирати Створювати.
Завершення цього стеку може зайняти близько 10 хвилин, після чого ви зможете переглянути розгорнутий стек на консолі AWS CloudFormation.
Запустіть AWS Glue Crawlers, створені стеком AWS CloudFormation
Щоб запустити сканери, виконайте такі кроки:
- На консолі AWS Glue to AWS Glue Consoleвиберіть «Сканери» в розділі «Каталог даних» на навігаційній панелі.
- Знайдіть і запустіть два сканера
tpcdsdb-without-statsтаtpcdsdb-with-stats. Це може зайняти кілька хвилин.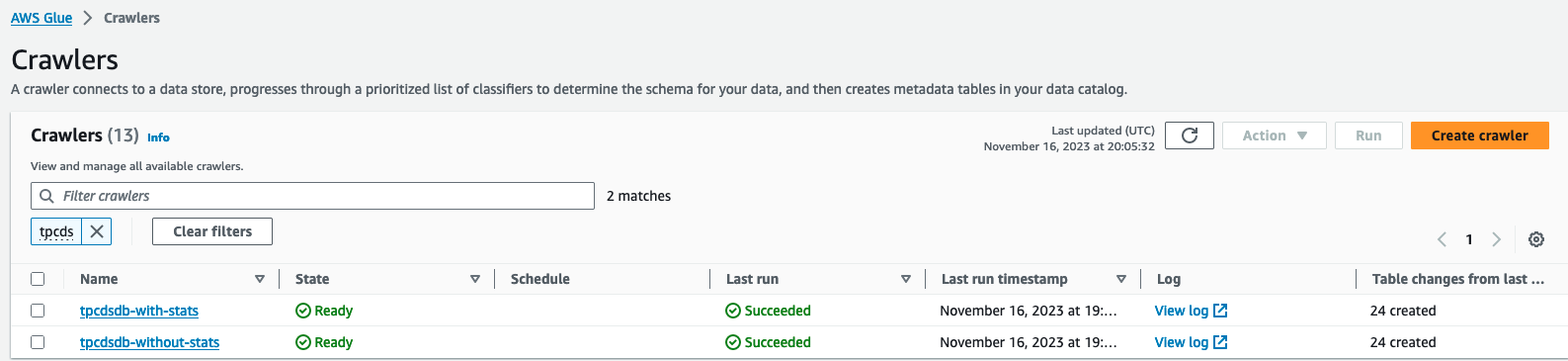
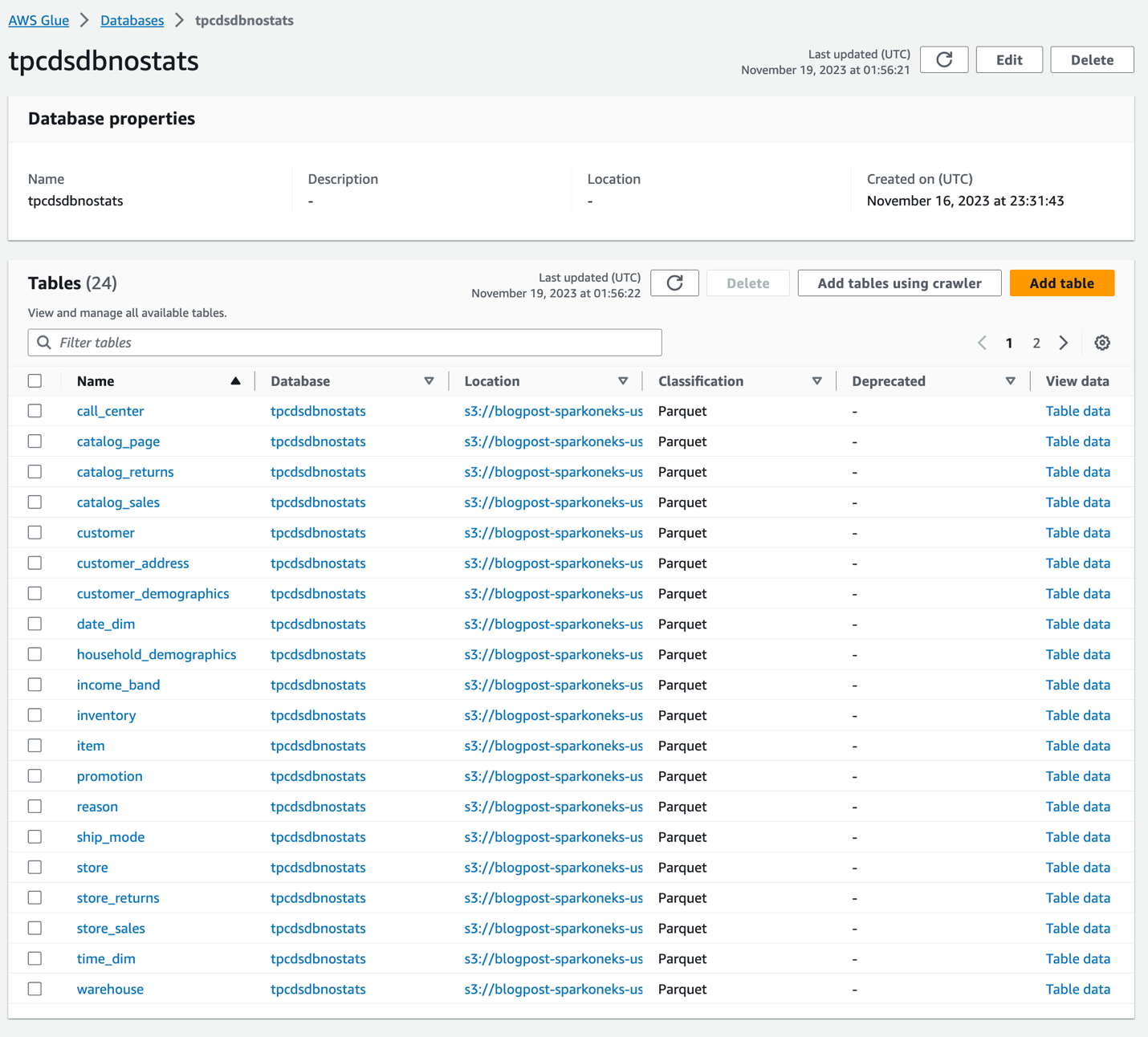
Після успішного завершення сканер створить дві ідентичні бази даних tpcdsdbnostats та tpcdsdbwithstats. Столи в tpcdsdbnostats не матиме статистики, і ми використовуватимемо їх як довідкові. Ми генеруємо статистику по таблицях в tpcdsdbwithstats. Будь ласка, переконайтеся, що у вас є ці дві бази даних і базові таблиці з AWS Glue Console. База даних tpcdsdbnostats виглядатиме так, як показано нижче. Наразі для цих таблиць не генерується статистика.
Запустіть наданий запит за допомогою Amazon Athena для таблиць без статистики
Щоб запустити запит в Amazon Athena для таблиць без статистики, виконайте такі кроки:
- Завантажте запити athena з тут.
- На Амазонці Консоль Athena, виберіть наданий запит по одному для таблиць у базі даних
tpcdsdbnostats. - Виконайте запит і запишіть Час виконання для кожного запиту.

Запустіть наданий запит за допомогою Amazon Redshift Spectrum у таблицях без статистики
Щоб запустити запит в Amazon Redshift, виконайте такі дії:
- Завантажте запити Amazon Redshift із тут.
- на Redshift редактор запитів v2, виконайте Redshift Query для таблиць без статистики із завантаженого запиту.
- Запустіть запит і запишіть виконання кожного запиту.
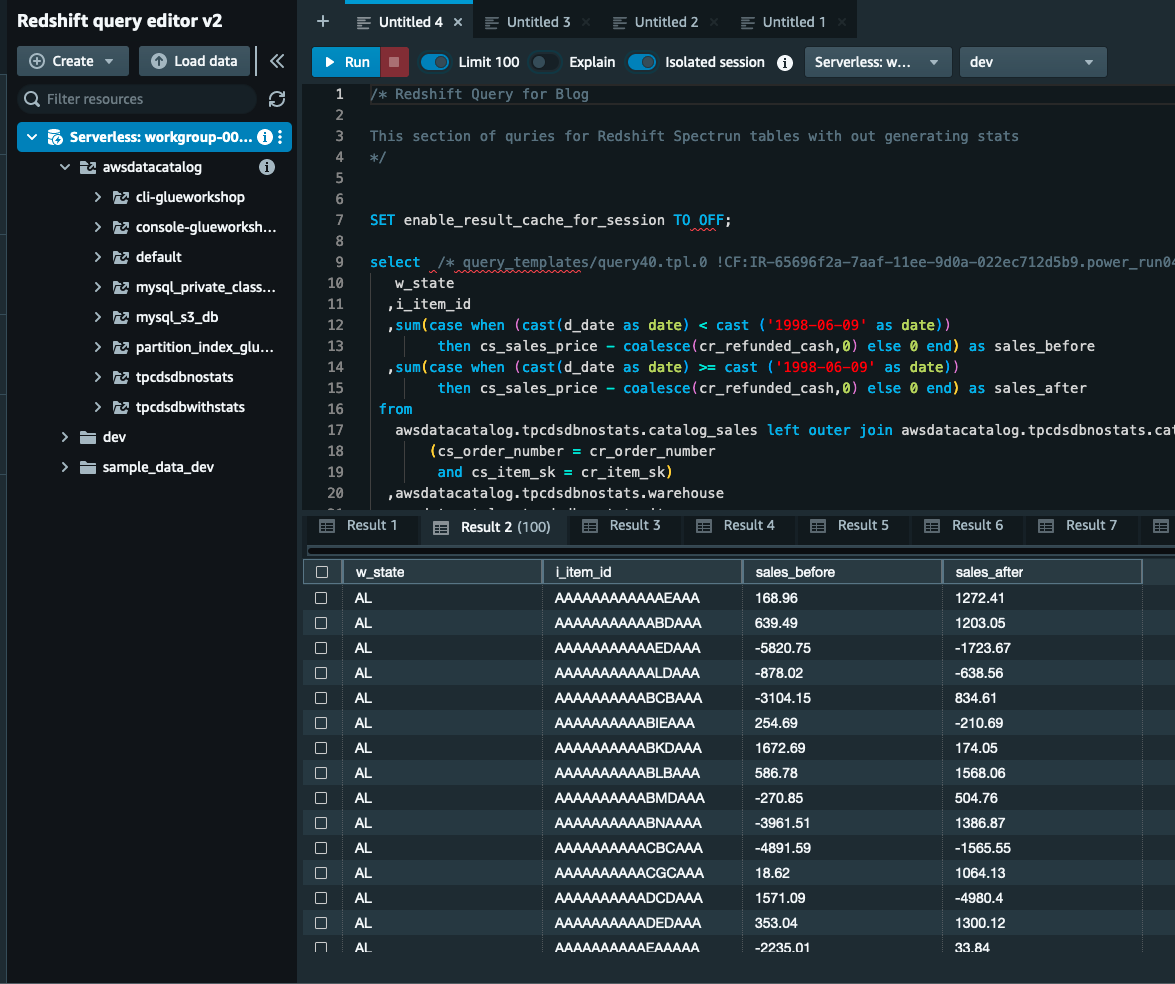
Створення статистичних даних для таблиць AWS Glue Catalog
Щоб створити статистику таблиць AWS Glue Catalog, виконайте такі кроки:
- перейдіть до AWS Glue Console і виберіть бази даних під Каталог даних.
- Натисніть на
tpcdsdbwithstatsбазу даних, і вона перерахує всі доступні таблиці. - Виберіть будь-яку з цих таблиць (наприклад,
call_center). - До Колонка статистики – нова та виберіть Створення статистики.
- Зберегти параметр за замовчуванням. Під Виберіть колонки тримати Таблиця (всі стовпці) і під Параметри вибірки рядків тримати Всі рядки, Під IAM вибір ролі Блог AWSGluestats і виберіть Створення статистики.
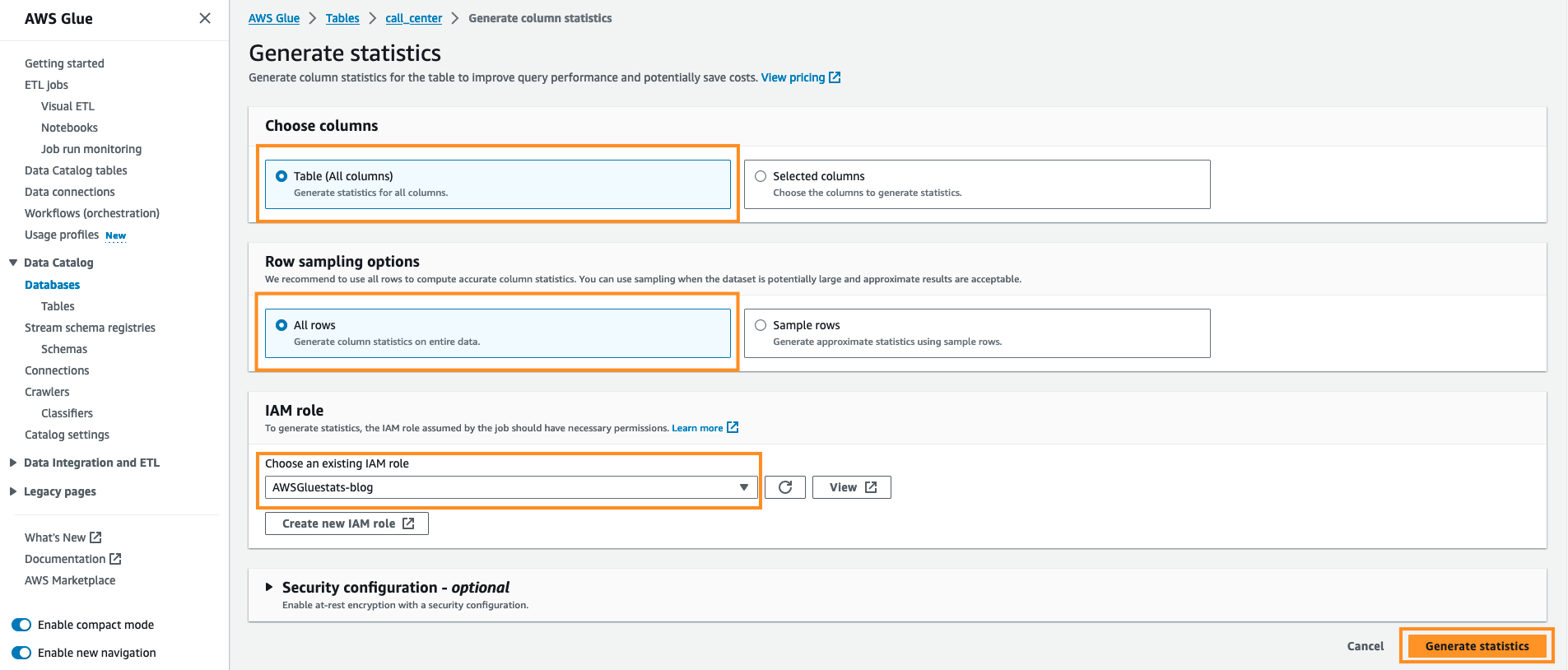
Ви зможете побачити статус запуску статистики, як показано на наступній ілюстрації:

Після створення статистики для таблиць AWS Glue Catalog ви зможете переглянути детальну статистику стовпців для цієї таблиці:
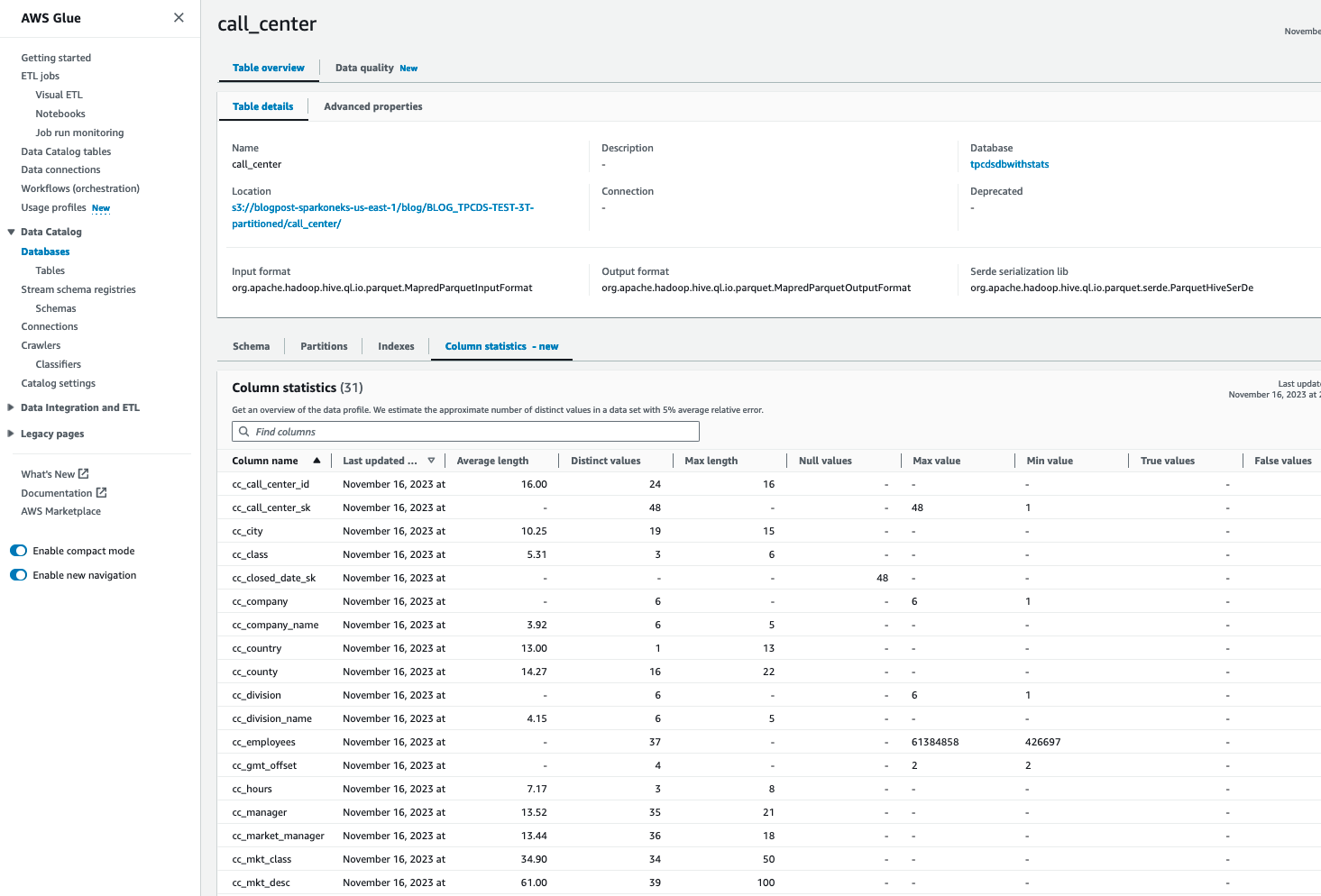
Повторіть кроки 2–5, щоб створити статистику для всіх необхідних таблиць, наприклад catalog_sales, catalog_returns, warehouse, item, date_dim, store_sales, customer, customer_address, web_sales, time_dim, ship_mode, web_site, web_returns. Крім того, ви можете слідувати «Заплануйте запуски статистики AWS Glue” у кінці цього блогу, щоб створити статистику для всіх таблиць. Після цього оцініть ефективність кожного запиту.
Запустіть наданий запит за допомогою Athena Console у таблицях статистики
- На Амазонці Консоль Афіна, виконайте Athena Query для таблиць зі статистикою із завантаженого запиту.
- Запустіть і запишіть виконання кожного запиту.
У нашому прикладі виконання запитів до таблиць ми спостерігали час виконання запиту згідно з таблицею нижче. Ми побачили явне покращення продуктивності запитів у діапазоні від 13 до 55%.
Покращення часу запиту Athena
| Запити TPC-DS 3T | без статистики клею (сек) | зі статистикою клею (сек) | підвищення продуктивності (%) |
| Запит 2 | 33.62 | 15.17 | 55% |
| Запит 4 | 132.11 | 72.94 | 45% |
| Запит 14 | 134.77 | 91.48 | 32% |
| Запит 28 | 55.99 | 39.36 | 30% |
| Запит 38 | 29.32 | 25.58 | 13% |
Запустіть наданий запит за допомогою Amazon Redshift Spectrum у таблицях статистики
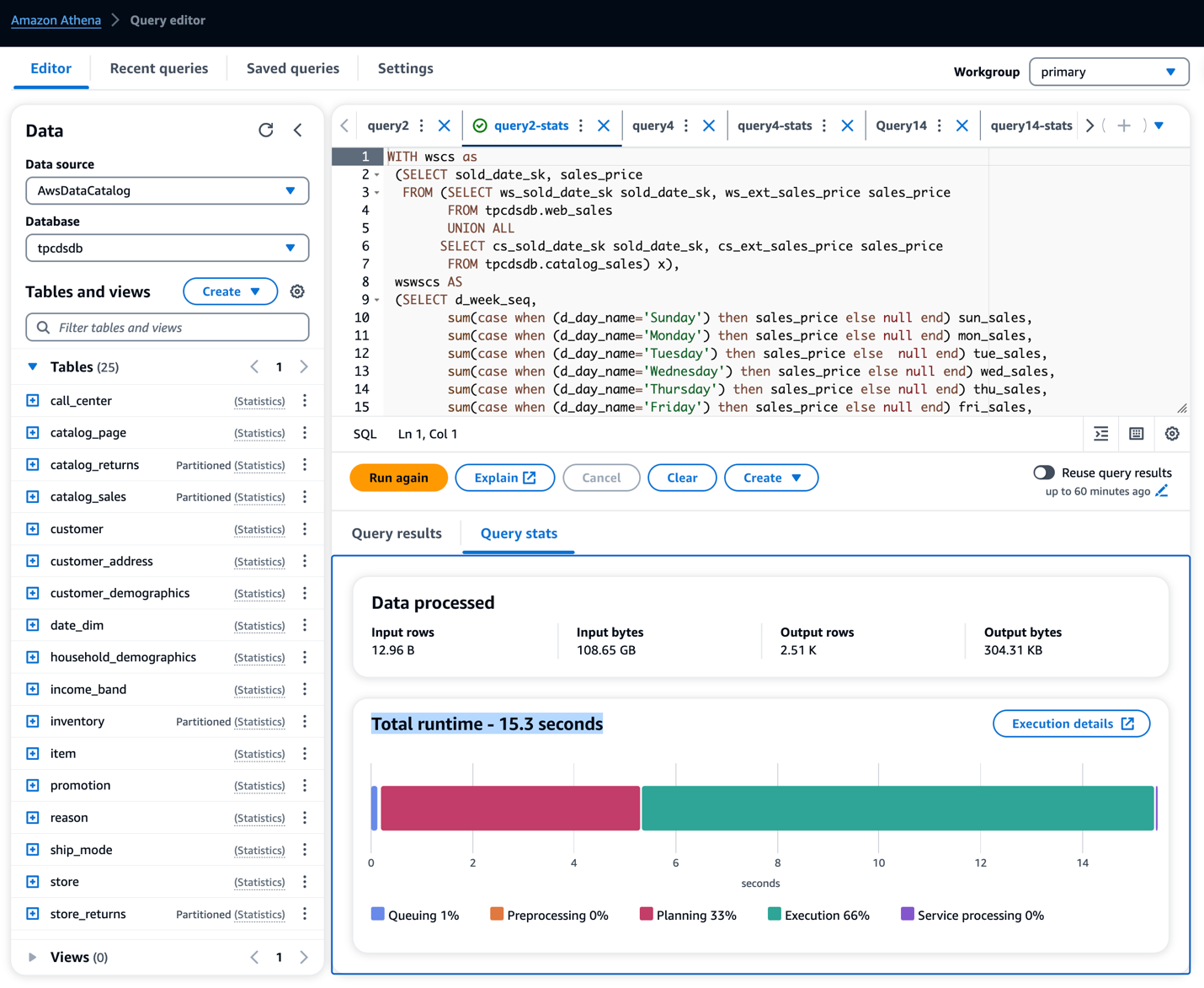
- На Амазонці Redshift редактор запитів v2, виконайте Redshift Query для таблиць зі статистикою із завантаженого запиту.
- Запустіть запит і запишіть виконання кожного запиту.
У нашому прикладі виконання запитів до таблиць ми спостерігали час виконання запиту згідно з таблицею нижче. Ми побачили явне покращення продуктивності запитів у діапазоні від 13 до 89%.
Покращення часу запиту Amazon Redshift Spectrum
| Запити TPC-DS 3T | без статистики клею (сек) | зі статистикою клею (сек) | підвищення продуктивності (%) |
| Запит 40 | 124.156 | 13.12 | 89% |
| Запит 60 | 29.52 | 16.97 | 42% |
| Запит 66 | 18.914 | 16.39 | 13% |
| Запит 95 | 308.806 | 200 | 35% |
| Запит 99 | 20.064 | 16 | 20% |
Розклад статистики AWS Glue
У цьому сегменті публікації ми проведемо вас через кроки планування запусків статистики стовпців AWS Glue за допомогою AWS Lambda і Amazon EventBridge Планувальник. Щоб спростити цей процес, у рамках розгортання стеку CloudFormation було створено функцію AWS Lambda та планувальник Amazon EventBridge.
- Налаштування функції AWS Lambda:
Для початку ми використовуємо функцію AWS Lambda, щоб ініціювати виконання завдання статистики стовпця AWS Glue. Функція AWS Lambda викликає start_column_statistics_task_run API через бібліотеку boto3 (AWS SDK для Python). Це створює основу для автоматизації оновлення статистики стовпців.
Давайте дослідимо функцію AWS Lambda:
-
- Перейти до Консоль AWS Glue Lambda.
- Select Функції і знайдіть
GlueTableStatisticsFunctionv1. - Для більш чіткого розуміння функції AWS Lambda рекомендуємо переглянути код у код розділ і вивчення змінних середовища під конфігурація.
- Конфігурація планувальника Amazon EventBridge
Наступний крок передбачає планування виклику функції AWS Lambda за допомогою Amazon Планувальник EventBridge. Планувальник налаштований на запуск функції AWS Lambda щодня в певний час – у цьому випадку о 08:00. Це гарантує регулярну та передбачувану роботу завдання статистики стовпця AWS Glue.
Тепер давайте дізнаємося, як можна оновити розклад:
Очищення
Щоб уникнути небажаних стягнень з вашого облікового запису AWS, видаліть ресурси AWS:
- Увійдіть у консоль AWS CloudFormation як адміністратор AWS IAM, який використовувався для створення стека AWS CloudFormation.
- Видаліть створений вами стек AWS CloudFormation.
Висновок
У цій публікації ми показали вам, як ви можете використовувати Каталог даних AWS Glue для створення статистики на рівні стовпців Клей AWS таблиці. Ця статистика тепер інтегрована з оптимізатором на основі витрат від Амазонка Афіна і Amazon Спектр червоного зсуву, що призвело до покращення продуктивності запитів і потенційної економії коштів. Відноситься до документи для підтримки Glue Catalog Statistic у різних аналітичних службах AWS.
Якщо у вас є запитання чи пропозиції, надішліть їх у розділі коментарів.
Про авторів
 Сандіп Адванкар є старшим менеджером із технічних продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
Сандіп Адванкар є старшим менеджером із технічних продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
 Навнит Шукла працює архітектором рішень спеціалістів AWS із фокусом на аналітиці. Він має великий ентузіазм у наданні допомоги клієнтам у виявленні цінної інформації з їхніх даних. Завдяки своєму досвіду він розробляє інноваційні рішення, які дають можливість підприємствам робити обґрунтований вибір на основі даних. Зокрема, Навніт Шукла є досвідченим автором книги під назвою Data Wrangling on AWS. До нього можна дістатися через LinkedIn.
Навнит Шукла працює архітектором рішень спеціалістів AWS із фокусом на аналітиці. Він має великий ентузіазм у наданні допомоги клієнтам у виявленні цінної інформації з їхніх даних. Завдяки своєму досвіду він розробляє інноваційні рішення, які дають можливість підприємствам робити обґрунтований вибір на основі даних. Зокрема, Навніт Шукла є досвідченим автором книги під назвою Data Wrangling on AWS. До нього можна дістатися через LinkedIn.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/enhance-query-performance-using-aws-glue-data-catalog-column-level-statistics/
- :є
- :де
- $UP
- 08
- 1
- 10
- 100
- 13
- 264
- 30
- a
- Здатний
- доступ
- управління доступом
- доступною
- виконано
- рахунки
- Рахунки
- точний
- визнавати
- через
- після
- ВСІ
- дозволяє
- Amazon
- Амазонка Афіна
- Amazon Web Services
- суми
- an
- Аналітичний
- аналітика
- та
- будь-який
- API
- відповідний
- архітектура
- ЕСТЬ
- ПЛОЩА
- навколо
- AS
- зовнішній вигляд
- оцінити
- допомагати
- At
- автор
- автоматично
- автоматизація
- доступний
- уникнути
- AWS
- AWS CloudFormation
- Клей AWS
- AWS Lambda
- заснований
- основа
- затока
- BE
- перед тим
- починати
- нижче
- Блог
- книга
- підсилює
- BRIDGE
- бізнес
- підприємства
- by
- Каліфорнія
- CAN
- можливості
- можливості
- випадок
- каталог
- централізована
- певний
- складні
- Зміни
- вантажі
- вибір
- Вибирати
- ясно
- ясніше
- клієнтів
- хмара
- код
- Колонка
- Колони
- коментарі
- порівняти
- повний
- Завершує
- комплекс
- всеосяжний
- налаштувати
- складається
- Консоль
- споживач
- Споживачі
- Відповідний
- Коштувати
- економія на витратах
- витрати
- гусеничний
- створювати
- створений
- створення
- Клієнти
- налаштувати
- щодня
- дані
- Озеро даних
- керовані даними
- Database
- базами даних
- набори даних
- дефолт
- демонструвати
- відомства
- розгортання
- розгорнути
- розгортання
- призначені
- призначений
- докладно
- деталі
- різний
- відкриття
- чіткий
- зроблений
- вниз
- тривалість
- під час
- e
- кожен
- редактор
- ефективність
- ефективний
- або
- уповноважувати
- включіть
- заохочувати
- кінець
- кінець в кінець
- підвищувати
- підвищена
- гарантує
- ентузіазм
- Навколишнє середовище
- особливо
- Ефір (ETH)
- оцінювати
- Event
- Вивчення
- приклад
- виконувати
- виконання
- досвід
- експертиза
- дослідити
- швидше
- кілька
- Файли
- остаточний
- Сфокусувати
- стежити
- після
- для
- від
- функція
- породжувати
- генерується
- генерує
- породжує
- покоління
- земну кулю
- управління
- основи
- керівництво
- Мати
- he
- допомагає
- Високий
- його
- відбувся
- Як
- How To
- HTML
- HTTP
- HTTPS
- IAM
- однаковий
- Особистість
- управління ідентифікацією та доступом
- if
- ілюструє
- Impact
- здійснювати
- важливо
- удосконалювати
- поліпшений
- поліпшення
- поліпшення
- поліпшується
- in
- включати
- includes
- повідомив
- інноваційний
- розуміння
- інтегрований
- мати намір
- в
- викликає
- включає в себе
- IT
- робота
- Джобс
- приєднатися
- з'єднання
- JPG
- json
- тримати
- озеро
- озера
- великий
- запуск
- запуск
- Веде за собою
- вчений
- рівень
- бібліотека
- як
- список
- подивитися
- виглядає як
- низький
- made
- зробити
- Робить
- управляти
- управління
- менеджер
- Макс
- Може..
- метадані
- може бути
- хвилин
- протокол
- більше
- більш ефективний
- найбільш
- множинний
- навігація
- Близько
- необхідно
- Необхідність
- потреби
- Нові
- наступний
- немає
- особливо
- увагу
- зараз
- номер
- спостерігається
- of
- on
- один раз
- ONE
- операції
- оптимізація
- Оптимізувати
- варіант
- or
- порядок
- організації
- наші
- з
- власний
- сторінка
- pane
- частина
- для
- виконувати
- продуктивність
- Дозволи
- планування
- плани
- plato
- Інформація про дані Платона
- PlatoData
- будь ласка
- pm
- Політика
- володіє
- пошта
- потенціал
- потенційно
- Передбачуваний
- прогноз
- Прогнози
- попередній
- приватний
- процес
- Виробники
- Product
- менеджер по продукції
- Продукти
- за умови
- забезпечення
- громадськість
- Python
- запити
- питань
- Швидко
- ранжування
- Сировина
- досяг
- Читати
- рекомендувати
- Знижений
- послатися
- посилання
- регіон
- регулярний
- вимога
- Вимога
- ресурси
- результат
- в результаті
- огляд
- рецензування
- Роль
- Маршрут
- ROW
- прогін
- біг
- пробіжки
- Економія
- бачив
- розклад
- планування
- Sdk
- плавно
- SEC
- розділ
- безпечний
- побачити
- сегмент
- вибрати
- старший
- Без сервера
- служить
- обслуговування
- Послуги
- набори
- установка
- Поділитись
- Повинен
- показав
- показаний
- простий
- рішення
- Рішення
- деякі
- спеціаліст
- конкретний
- спектр
- SQL
- стек
- Стажування
- статистика
- статистика
- Статус
- Крок
- заходи
- зберігання
- зберігати
- зберігати
- раціоналізувати
- сильний
- представляти
- підмережі
- підмережі
- Успішно
- такі
- костюм
- підтримка
- таблиця
- Приймати
- говорити
- команди
- технічний
- шаблон
- Що
- Команда
- їх
- Їх
- Там.
- тим самим
- Ці
- вони
- це
- ті
- через
- час
- під назвою
- до
- переводити
- викликати
- намагатися
- два
- при
- що лежить в основі
- розуміння
- небажаний
- Оновити
- оновлений
- використання
- використовуваний
- користувачі
- використання
- використовувати
- використовує
- Цінний
- Цінності
- різний
- величезний
- перевірити
- вид
- Віртуальний
- we
- Web
- веб-сервіси
- були
- коли
- який
- волі
- з
- в
- без
- Work
- робочий
- Робоча група
- працює
- б
- XML
- ямл
- ви
- вашу
- зефірнет