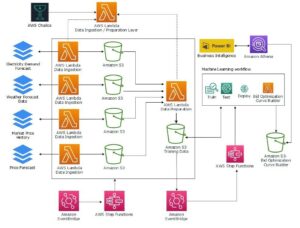
Вбудовування відіграє ключову роль у обробці природної мови (NLP) і машинному навчанні (ML). Вбудовування тексту відноситься до процесу перетворення тексту в числове представлення, яке знаходиться у великому векторному просторі. Ця техніка досягається завдяки використанню алгоритмів ML, які дозволяють зрозуміти значення та контекст даних (семантичні зв’язки) і вивчати складні зв’язки та шаблони в даних (синтаксичні зв’язки). Отримані векторні представлення можна використовувати для широкого кола застосувань, таких як пошук інформації, класифікація тексту, обробка природної мови та багато інших.
Текстові вставки Amazon Titan це модель вбудованого тексту, яка перетворює текст природною мовою, що складається з окремих слів, фраз або навіть великих документів, у числове представлення, яке можна використовувати для таких випадків використання, як пошук, персоналізація та кластеризація на основі семантичної подібності.
У цій публікації ми обговорюємо модель Amazon Titan Text Embeddings, її функції та приклади використання.
Деякі ключові поняття включають:
- Числове представлення тексту (вектори) фіксує семантику та зв’язки між словами
- Для порівняння схожості тексту можна використовувати розширені вбудовування
- Багатомовні вбудовані тексти можуть ідентифікувати значення в різних мовах
Як фрагмент тексту перетворюється на вектор?
Існує кілька методів перетворення речення у вектор. Одним із популярних методів є використання алгоритмів вбудовування слів, таких як Word2Vec, GloVe або FastText, а потім агрегування вставок слів для формування векторного представлення на рівні речення.
Іншим поширеним підходом є використання великих мовних моделей (LLM), таких як BERT або GPT, які можуть забезпечити контекстуальне вбудовування цілих речень. Ці моделі базуються на архітектурах глибокого навчання, таких як Transformers, які можуть більш ефективно отримувати контекстну інформацію та зв’язки між словами в реченні.
Навіщо нам потрібна модель вбудовування?
Вбудовування векторів є основоположним для LLM для розуміння семантичних ступенів мови, а також дозволяє LLM добре виконувати наступні завдання NLP, такі як аналіз настроїв, розпізнавання іменованих об’єктів і класифікація тексту.
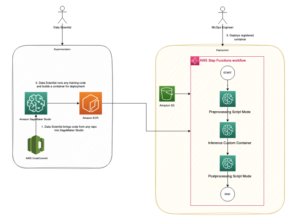
На додаток до семантичного пошуку ви можете використовувати вбудовування, щоб розширити свої підказки для отримання точніших результатів за допомогою Retrieval Augmented Generation (RAG), але щоб використовувати їх, вам потрібно буде зберігати їх у базі даних із векторними можливостями.
Модель Amazon Titan Text Embeddings оптимізовано для пошуку тексту, щоб увімкнути випадки використання RAG. Це дає вам змогу спочатку перетворити ваші текстові дані в числове представлення або вектори, а потім використовувати ці вектори для точного пошуку відповідних уривків із векторної бази даних, дозволяючи вам максимально використовувати ваші власні дані в поєднанні з іншими базовими моделями.
Оскільки Amazon Titan Text Embeddings є керованою моделлю Amazon Bedrock, він пропонується як повністю безсерверний досвід. Ви можете використовувати його через Amazon Bedrock REST API або AWS SDK. Обов’язковими параметрами є текст, вбудовування якого ви хочете створити, і modelID параметр, який представляє назву моделі Amazon Titan Text Embeddings. Наступний код є прикладом використання AWS SDK для Python (Boto3):
Результат буде виглядати приблизно так:
Відноситься до Налаштування Amazon Bedrock boto3 щоб дізнатися більше про встановлення необхідних пакетів, підключіться до Amazon Bedrock і запустіть моделі.
Особливості Amazon Titan Text Embeddings
За допомогою Amazon Titan Text Embeddings ви можете вводити до 8,000 токенів, що робить його ідеальним для роботи з окремими словами, фразами або цілими документами залежно від вашого випадку використання. Amazon Titan повертає вихідні вектори розмірності 1536, надаючи йому високий ступінь точності, а також оптимізуючи для отримання економічно ефективних результатів з низькою затримкою.
Amazon Titan Text Embeddings підтримує створення та запити вбудованих текстів понад 25 різними мовами. Це означає, що ви можете застосувати модель до своїх випадків використання без необхідності створювати та підтримувати окремі моделі для кожної мови, яку ви хочете підтримувати.
Наявність єдиної моделі вбудовування, навченої багатьма мовами, забезпечує такі ключові переваги:
- Більш широкий охоплення – Підтримуючи понад 25 мов із коробки, ви можете розширити охоплення своїх програм для користувачів і вмісту на багатьох міжнародних ринках.
- Послідовна продуктивність – Завдяки уніфікованій моделі, що охоплює кілька мов, ви отримуєте узгоджені результати для різних мов замість окремої оптимізації для кожної мови. Модель навчена цілісно, тож ви отримуєте перевагу в різних мовах.
- Багатомовна підтримка запитів – Amazon Titan Text Embeddings дозволяє запитувати вбудовані тексти будь-якою з підтримуваних мов. Це забезпечує гнучкість для отримання семантично подібного вмісту різними мовами, не обмежуючись однією мовою. Ви можете створювати програми, які надсилають запити й аналізують багатомовні дані, використовуючи той самий уніфікований простір вбудовування.
На момент написання цієї статті підтримуються такі мови:
- арабська
- Китайська (спрощене письмо)
- Китайський традиційний)
- Czech
- нідерландська
- англійська
- французька
- німецька
- давньоєврейську
- хінді
- італійська
- японський
- каннада
- корейський
- малаялам
- маратхі
- полірування
- португальська
- російська
- іспанська
- шведську мову
- філіппінська тагальська
- тамільська
- телугу
- турецька
Використання Amazon Titan Text Embeddings із LangChain
LangChain це популярна платформа з відкритим вихідним кодом для роботи з генеративними моделями штучного інтелекту та допоміжними технологіями. Він включає а Клієнт BedrockEmbeddings який зручно обгортає Boto3 SDK шаром абстракції. The BedrockEmbeddings клієнт дозволяє вам працювати з текстом і вбудованими напрямами, не знаючи деталей запиту JSON або структури відповіді. Ось простий приклад:
Ви також можете використовувати LangChain BedrockEmbeddings поряд із клієнтом Amazon Bedrock LLM, щоб спростити впровадження RAG, семантичного пошуку та інших шаблонів, пов’язаних із вбудовуванням.
Випадки використання для вбудовування
Незважаючи на те, що RAG наразі є найпопулярнішим варіантом використання для роботи з вбудованими елементами, існує багато інших варіантів використання, у яких можна застосувати вбудовані засоби. Нижче наведено кілька додаткових сценаріїв, у яких ви можете використовувати вбудовування для вирішення конкретних проблем самостійно або у співпраці з LLM:
- Питання і відповідь – Вбудовування може допомогти підтримувати інтерфейси запитань і відповідей через шаблон RAG. Генерація вбудовувань у поєднанні з векторною базою даних дозволяє знаходити близькі збіги між запитаннями та вмістом у сховищі знань.
- Індивідуальні рекомендації – Подібно до запитань і відповідей, ви можете використовувати вбудовування, щоб знаходити місця відпочинку, коледжі, транспортні засоби чи інші продукти на основі критеріїв, наданих користувачем. Це може мати форму простого списку збігів, або ви можете використовувати LLM для обробки кожної рекомендації та пояснення, наскільки вона задовольняє критерії користувача. Ви також можете використати цей підхід для створення власних «10 найкращих» статей для користувача на основі його конкретних потреб.
- Управління даними – Якщо у вас є джерела даних, які не зіставляються чітко одне з одним, але у вас є текстовий вміст, який описує запис даних, ви можете використовувати вбудовування для виявлення потенційних дублікатів записів. Наприклад, ви можете використовувати вбудовування, щоб ідентифікувати повторювані кандидати, які можуть використовувати інше форматування, абревіатури або навіть перекладені імена.
- Раціоналізація портфоліо програм – Коли ви прагнете узгодити портфоліо програм між материнською компанією та придбанням, не завжди очевидно, з чого почати пошук потенційного збігу. Якість даних керування конфігурацією може бути обмежуючим фактором, і може бути важко координувати команди, щоб зрозуміти ландшафт додатків. Використовуючи семантичне зіставлення з вбудовуваннями, ми можемо швидко проаналізувати портфоліо програм, щоб визначити програми-кандидати з високим потенціалом для раціоналізації.
- Групування вмісту – Ви можете використовувати вбудовування, щоб полегшити групування схожого вмісту за категоріями, про які ви можете не знати заздалегідь. Наприклад, припустімо, що у вас є колекція електронних листів клієнтів або онлайн-оглядів продуктів. Ви можете створити вбудовування для кожного елемента, а потім запустити ці вбудовування k-означає кластеризацію щоб визначити логічне групування занепокоєнь клієнтів, похвал або скарг на продукт або інших тем. Потім ви можете створити цілеспрямовані підсумки з вмісту цих груп за допомогою LLM.
Приклад семантичного пошуку
У нашій приклад на GitHub, ми демонструємо просту програму пошуку вбудованих елементів із Amazon Titan Text Embeddings, LangChain і Streamlit.
Приклад зіставляє запит користувача з найближчими записами векторної бази даних у пам’яті. Потім ми відображаємо ці збіги безпосередньо в інтерфейсі користувача. Це може бути корисним, якщо ви хочете усунути неполадки програми RAG або безпосередньо оцінити модель вбудовування.
Для простоти ми використовуємо in-memory ФАЙС база даних для зберігання та пошуку вбудованих векторів. У масштабному сценарії реального світу ви, ймовірно, захочете використовувати постійне сховище даних, як векторний механізм для Amazon OpenSearch Serverless або pgvector розширення для PostgreSQL.
Спробуйте кілька підказок із веб-програми різними мовами, наприклад такі:
- Як я можу контролювати своє використання?
- Як я можу налаштувати моделі?
- Які мови програмування я можу використовувати?
- Comment mes données sont-elles sécurisées ?
- 私のデータはどのように保護されていますか?
- Quais fornecedores de modelos estão disponíveis por meio do Bedrock?
- In welchen Regionen ist Amazon Bedrock verfügbar?
- 有哪些级别的支持?
Зверніть увагу, що хоча вихідний матеріал був англійською мовою, запити іншими мовами були зіставлені з відповідними записами.
Висновок
Можливості створення тексту базових моделей дуже захоплюючі, але важливо пам’ятати, що розуміння тексту, пошук релевантного вмісту в сукупності знань і встановлення зв’язків між уривками є вирішальними для досягнення повної цінності генеративного ШІ. Протягом наступних років ми продовжуватимемо спостерігати за появою нових і цікавих випадків використання вбудовувань, оскільки ці моделі продовжуватимуть вдосконалюватися.
Наступні кроки
Ви можете знайти додаткові приклади вбудованих блокнотів або демонстраційних програм на наступних семінарах:
Про авторів
 Джейсон Стеле є старшим архітектором рішень в AWS, розташованому в Новій Англії. Він працює з клієнтами, щоб узгодити можливості AWS з їхніми найбільшими бізнес-завданнями. Поза роботою він проводить час, будуючи речі та дивлячись комікси зі своєю родиною.
Джейсон Стеле є старшим архітектором рішень в AWS, розташованому в Новій Англії. Він працює з клієнтами, щоб узгодити можливості AWS з їхніми найбільшими бізнес-завданнями. Поза роботою він проводить час, будуючи речі та дивлячись комікси зі своєю родиною.
 Нітін Євсевій є старшим архітектором корпоративних рішень в AWS, має досвід розробки програмного забезпечення, корпоративної архітектури та штучного інтелекту/ML. Він глибоко захоплений дослідженням можливостей генеративного ШІ. Він співпрацює з клієнтами, щоб допомогти їм створювати добре архітектурні додатки на платформі AWS, і присвячує себе вирішенню технологічних проблем і допомозі в їхній хмарній подорожі.
Нітін Євсевій є старшим архітектором корпоративних рішень в AWS, має досвід розробки програмного забезпечення, корпоративної архітектури та штучного інтелекту/ML. Він глибоко захоплений дослідженням можливостей генеративного ШІ. Він співпрацює з клієнтами, щоб допомогти їм створювати добре архітектурні додатки на платформі AWS, і присвячує себе вирішенню технологічних проблем і допомозі в їхній хмарній подорожі.
 Радж Патхак є головним архітектором рішень і технічним радником великих компаній зі списку Fortune 50 і середніх фінансових установ (FSI) у Канаді та Сполучених Штатах. Він спеціалізується на програмах машинного навчання, таких як генеративний ШІ, обробка природної мови, інтелектуальна обробка документів і MLOps.
Радж Патхак є головним архітектором рішень і технічним радником великих компаній зі списку Fortune 50 і середніх фінансових установ (FSI) у Канаді та Сполучених Штатах. Він спеціалізується на програмах машинного навчання, таких як генеративний ШІ, обробка природної мови, інтелектуальна обробка документів і MLOps.
 Мані Хануджа є технічним керівником – Generative AI Specialists, автором книги – Applied Machine Learning and High Performance Computing on AWS, і членом ради директорів ради жінок у виробничій освіті. Вона керує проектами машинного навчання (ML) у різних областях, таких як комп’ютерне бачення, обробка природної мови та генеративний ШІ. Вона допомагає клієнтам створювати, навчати та розгортати великі моделі машинного навчання в масштабі. Вона виступає на внутрішніх і зовнішніх конференціях, таких як re:Invent, Women in Manufacturing West, вебінарах YouTube і GHC 23. У вільний час вона любить довго бігати вздовж пляжу.
Мані Хануджа є технічним керівником – Generative AI Specialists, автором книги – Applied Machine Learning and High Performance Computing on AWS, і членом ради директорів ради жінок у виробничій освіті. Вона керує проектами машинного навчання (ML) у різних областях, таких як комп’ютерне бачення, обробка природної мови та генеративний ШІ. Вона допомагає клієнтам створювати, навчати та розгортати великі моделі машинного навчання в масштабі. Вона виступає на внутрішніх і зовнішніх конференціях, таких як re:Invent, Women in Manufacturing West, вебінарах YouTube і GHC 23. У вільний час вона любить довго бігати вздовж пляжу.
 Марк Рой є головним архітектором машинного навчання для AWS, допомагаючи клієнтам проектувати та створювати рішення AI/ML. Робота Марка охоплює широкий спектр випадків використання ML, головний інтерес до комп’ютерного бачення, глибокого навчання та масштабування ML на підприємстві. Він допомагав компаніям у багатьох галузях, включаючи страхування, фінансові послуги, медіа та розваги, охорону здоров’я, комунальні послуги та виробництво. Марк має шість сертифікатів AWS, у тому числі спеціальність ML. До того як приєднатися до AWS, Марк понад 25 років працював архітектором, розробником і технологічним лідером, у тому числі 19 років у сфері фінансових послуг.
Марк Рой є головним архітектором машинного навчання для AWS, допомагаючи клієнтам проектувати та створювати рішення AI/ML. Робота Марка охоплює широкий спектр випадків використання ML, головний інтерес до комп’ютерного бачення, глибокого навчання та масштабування ML на підприємстві. Він допомагав компаніям у багатьох галузях, включаючи страхування, фінансові послуги, медіа та розваги, охорону здоров’я, комунальні послуги та виробництво. Марк має шість сертифікатів AWS, у тому числі спеціальність ML. До того як приєднатися до AWS, Марк понад 25 років працював архітектором, розробником і технологічним лідером, у тому числі 19 років у сфері фінансових послуг.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- : має
- :є
- : ні
- :де
- $UP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- МЕНЮ
- абстракція
- Прийняти
- точність
- точний
- точно
- досягнутий
- досягнення
- придбання
- через
- доповнення
- Додатковий
- Перевага
- радник
- попереду
- AI
- Моделі AI
- AI / ML
- алгоритми
- вирівнювати
- ВСІ
- дозволяти
- Дозволити
- дозволяє
- по
- пліч-о-пліч
- Також
- завжди
- Amazon
- Amazon Web Services
- an
- аналіз
- аналізувати
- та
- відповідь
- будь-який
- додаток
- застосування
- прикладної
- Застосовувати
- підхід
- архітектура
- архітектури
- ЕСТЬ
- ПЛОЩА
- статті
- AS
- допомагати
- At
- збільшення
- збільшено
- автор
- доступний
- AWS
- заснований
- BE
- Пляж
- буття
- Переваги
- між
- рада
- рада директорів
- тіло
- книга
- Box
- будувати
- Створюємо
- бізнес
- але
- by
- CAN
- Канада
- кандидат
- кандидатів
- можливості
- захоплення
- захвати
- випадок
- випадків
- категорії
- сертифікація
- сертифікати
- проблеми
- класифікація
- клієнт
- близько
- хмара
- Кластеризація
- код
- збір
- коледжі
- поєднання
- загальний
- Компанії
- компанія
- порівняти
- скарги
- комплекс
- комп'ютер
- Комп'ютерне бачення
- обчислення
- поняття
- Турбота
- конференції
- конфігурація
- З'єднуватися
- зв'язку
- Зв'язки
- послідовний
- зміст
- контекст
- контекстуальний
- продовжувати
- зручно
- конвертувати
- перероблений
- співробітництво
- координуючи
- рентабельним
- може
- покриття
- охоплює
- створювати
- створення
- Критерії
- вирішальне значення
- В даний час
- виготовлений на замовлення
- клієнт
- Клієнти
- налаштувати
- дані
- Database
- de
- присвячених
- глибокий
- глибоке навчання
- глибоко
- визначати
- Ступінь
- Демонстрація
- демонструвати
- розгортання
- описує
- дизайн
- напрямки
- деталі
- Розробник
- різний
- важкий
- Розмір
- безпосередньо
- Директори
- обговорювати
- дисплей
- do
- документ
- документація
- домени
- Не знаю
- кожен
- Освіта
- фактично
- або
- повідомлення електронної пошти
- вбудовування
- з'являтися
- включіть
- дозволяє
- двигун
- Машинобудування
- England
- англійська
- підприємство
- Рішення для підприємств
- розваги
- Весь
- повністю
- суб'єкта
- Ефір (ETH)
- оцінювати
- Навіть
- приклад
- Приклади
- захоплюючий
- Розширювати
- досвід
- досвідчений
- Пояснювати
- Дослідження
- розширення
- зовнішній
- фасилітувати
- фактор
- сім'я
- риси
- кілька
- фінансовий
- фінансові послуги
- знайти
- виявлення
- Перший
- Гнучкість
- увагу
- після
- для
- форма
- стан
- фонд
- Рамки
- Безкоштовна
- від
- Повний
- фундаментальний
- породжувати
- покоління
- генеративний
- Генеративний ШІ
- отримати
- отримання
- дає
- рукавичка
- Go
- найбільший
- було
- Мати
- he
- охорона здоров'я
- допомога
- допоміг
- допомогу
- допомагає
- її
- Високий
- Високопродуктивні обчислювальні системи
- його
- тримає
- Як
- How To
- HTML
- HTTPS
- i
- ідентифікувати
- if
- реалізації
- імпорт
- важливо
- удосконалювати
- in
- В інших
- включати
- includes
- У тому числі
- промисловості
- інформація
- вхід
- встановлювати
- замість
- установи
- страхування
- Розумний
- Інтелектуальна обробка документів
- інтерес
- цікавий
- інтерфейс
- Інтерфейси
- внутрішній
- Міжнародне покриття
- в
- IT
- ЙОГО
- приєднання
- подорож
- JPG
- json
- ключ
- Знати
- Знання
- знання
- ландшафт
- мова
- мови
- великий
- шар
- вести
- лідер
- Веде за собою
- вивчення
- дозволяти
- як
- Ймовірно
- Сподобалося
- обмежуючий
- список
- llm
- логічний
- Довго
- подивитися
- шукати
- машина
- навчання за допомогою машини
- підтримувати
- зробити
- Робить
- вдалося
- управління
- виробництво
- багато
- карта
- позначити
- Марка
- ринки
- відповідає
- сірники
- узгодження
- матеріал
- me
- сенс
- засоби
- Медіа
- член
- метод
- може бути
- ML
- Алгоритми ML
- MLOps
- модель
- Моделі
- монітор
- більше
- найбільш
- Найбільш популярний
- кіно
- множинний
- my
- ім'я
- Названий
- Імена
- Природний
- Природна мова
- Обробка природних мов
- Необхідність
- нужденних
- потреби
- Нові
- наступний
- nlp
- ноутбуки
- Очевидний
- of
- запропонований
- on
- ONE
- онлайн
- відкрити
- з відкритим вихідним кодом
- оптимізований
- оптимізуючий
- or
- порядок
- Інше
- інші
- наші
- з
- вихід
- поза
- над
- власний
- пакети
- парний
- параметр
- параметри
- материнська компанія
- уривки
- пристрасний
- Викрійки
- моделі
- для
- виконувати
- продуктивність
- Втілення
- фрази
- частина
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- Play
- будь ласка
- популярний
- BY
- портфель
- портфелі
- можливостей
- пошта
- postgresql
- потенціал
- влада
- первинний
- Головний
- друк
- попередній
- проблеми
- процес
- обробка
- Product
- Відгуки про товар
- Продукти
- Програмування
- мови програмування
- проектів
- підказок
- власником
- забезпечувати
- за умови
- забезпечує
- Python
- якість
- запити
- запит
- питання
- питань
- Швидко
- ганчіркою
- діапазон
- RE
- досягати
- Реальний світ
- визнання
- Рекомендація
- рекомендації
- запис
- облік
- відноситься
- Відносини
- доречний
- запам'ятати
- Сховище
- подання
- представляє
- запросити
- вимагається
- відповідь
- REST
- обмежений
- в результаті
- результати
- пошук
- Умови повернення
- Відгуки
- Роль
- прогін
- пробіжки
- s
- то ж
- say
- шкала
- Масштабування
- сценарій
- сценарії
- Sdk
- Пошук
- побачити
- смисловий
- семантика
- старший
- пропозиція
- настрій
- окремий
- Без сервера
- Послуги
- вона
- аналогічний
- простий
- простота
- спрощений
- спростити
- один
- SIX
- So
- Софтвер
- розробка програмного забезпечення
- Рішення
- ВИРІШИТИ
- Розв’язування
- деякі
- що в сім'ї щось
- Source
- Джерела
- Простір
- Говорить
- Фахівці
- спеціалізується
- Спеціальність
- конкретний
- старт
- почалася
- Штати
- зберігати
- структур
- такі
- підтримка
- Підтриманий
- Підтримуючий
- Опори
- Приймати
- завдання
- команди
- технології
- технічний
- техніка
- методи
- Технології
- Технологія
- сказати
- текст
- Класифікація тексту
- генерація тексту
- Що
- Команда
- Джерело
- їх
- Їх
- Теми
- потім
- Там.
- Ці
- речі
- це
- ті
- хоча?
- через
- час
- велетень
- до
- Жетони
- традиційний
- поїзд
- навчений
- Трансформатори
- перетворення
- розуміти
- розуміння
- єдиний
- United
- Сполучені Штати
- Використання
- використання
- використання випадку
- використовуваний
- корисний
- користувач
- Інтерфейс користувача
- користувачі
- використання
- комунальні послуги
- відпустку
- значення
- різний
- Транспортні засоби
- дуже
- через
- бачення
- хотіти
- було
- спостереження
- we
- Web
- Веб-додаток
- веб-сервіси
- Вебінари
- ДОБРЕ
- були
- West
- коли
- який
- в той час як
- широкий
- Широкий діапазон
- волі
- з
- в
- без
- жінки
- слово
- слова
- Work
- робочий
- працює
- Семінари
- б
- запис
- лист
- років
- ви
- вашу
- YouTube
- зефірнет