Зображення автора
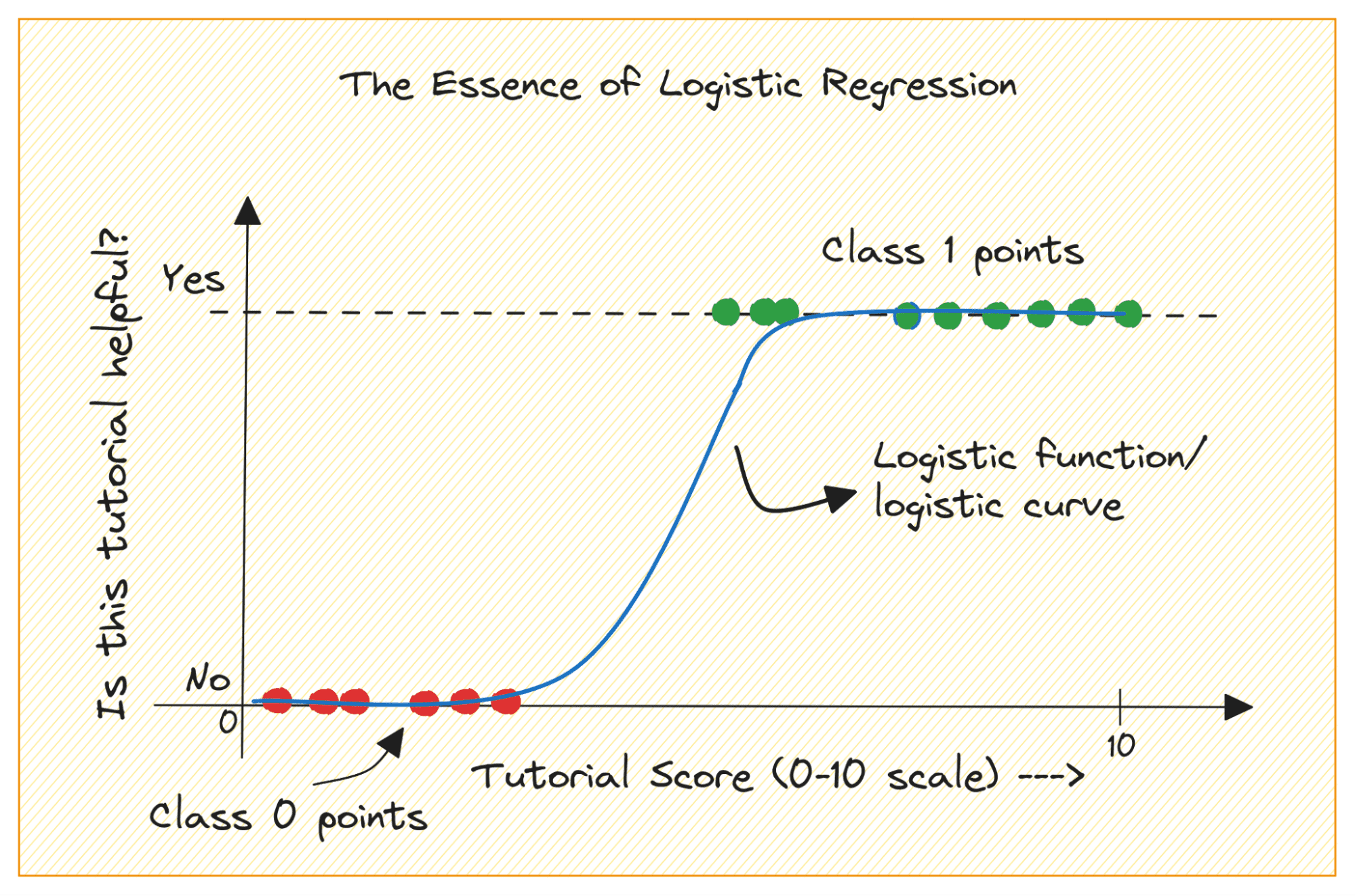
Коли ви починаєте працювати з машинним навчанням, логістична регресія є одним із перших алгоритмів, які ви додасте до свого інструментарію. Це простий і надійний алгоритм, який зазвичай використовується для завдань двійкової класифікації.
Розглянемо задачу двійкової класифікації з класами 0 і 1. Логістична регресія підбирає логістичну або сигмоїдну функцію до вхідних даних і передбачає ймовірність того, що точка даних запиту належить до класу 1. Цікаво, так?
У цьому підручнику ми дізнаємося про логістичну регресію з нуля, охоплюючи:
- Логістична (або сигмоїдна) функція
- Як ми переходимо від лінійної до логістичної регресії
- Як працює логістична регресія
Нарешті, ми створимо просту модель логістичної регресії класифікувати радіолокаційні сигнали від іоносфери.
Перш ніж дізнатися більше про логістичну регресію, давайте розглянемо, як працює логістична функція. Логістична (або сигмоїдна функція) визначається як:

Коли ви будуєте графік сигмоїдної функції, це виглядатиме так:
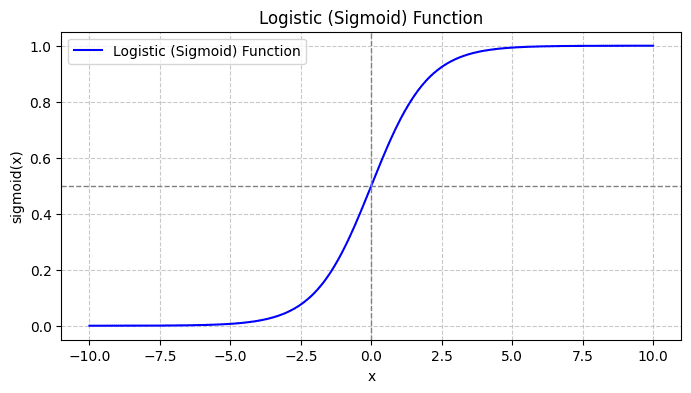
Зі сюжету бачимо, що:
- Коли x = 0, σ(x) приймає значення 0.5.
- Коли x наближається до +∞, σ(x) наближається до 1.
- Коли x наближається до -∞, σ(x) наближається до 0.
Отже, для всіх реальних вхідних даних сигмоїдна функція тисне їх, щоб вони приймали значення в діапазоні [0, 1].
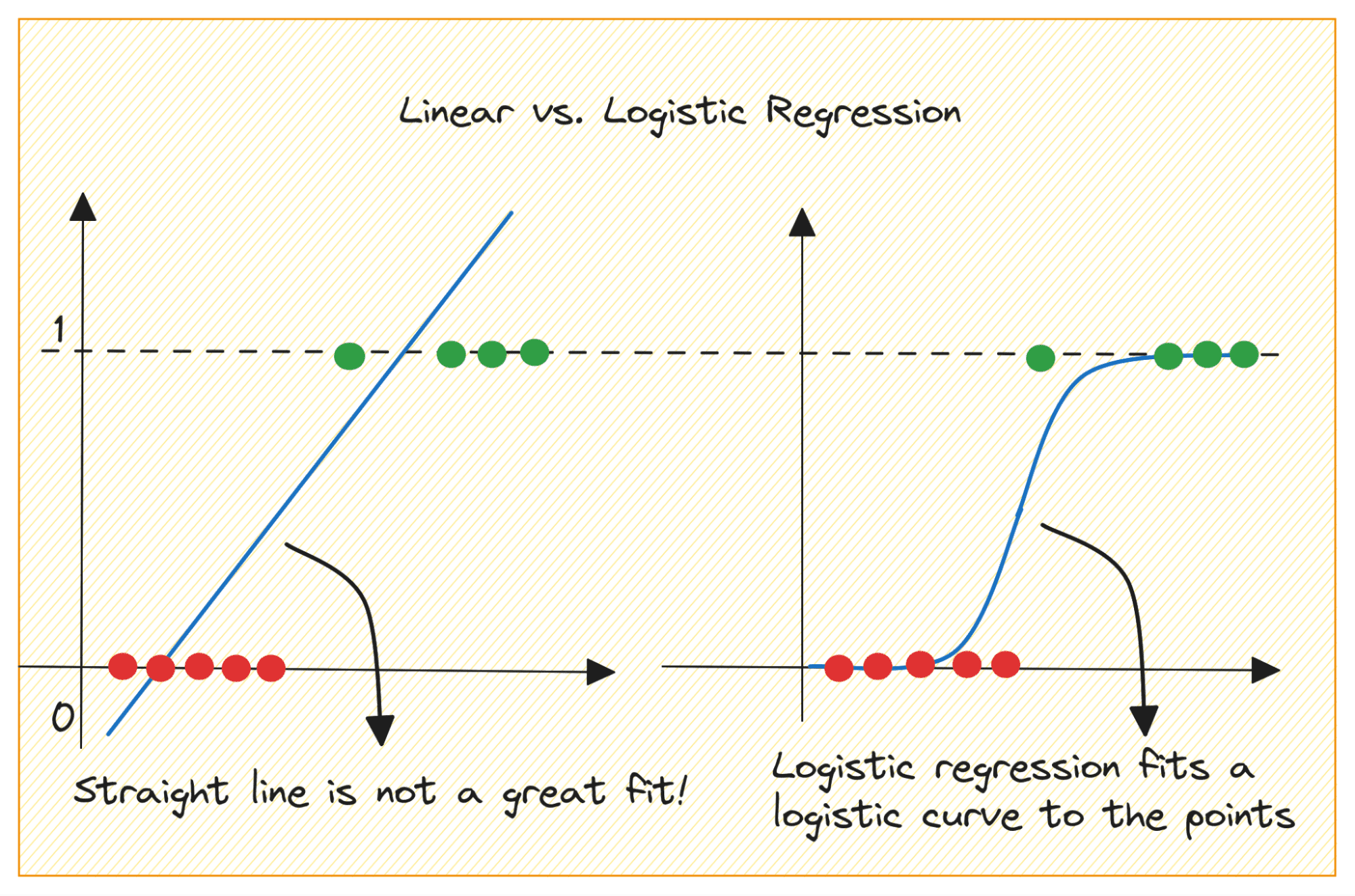
Давайте спочатку обговоримо, чому ми не можемо використовувати лінійну регресію для задачі бінарної класифікації.
У задачі двійкової класифікації виходом є категорична мітка (0 або 1). Оскільки лінійна регресія передбачає безперервні результати, які можуть бути меншими за 0 або більшими за 1, вона не має сенсу для розглянутої проблеми.
Крім того, пряма лінія може не найкраще підходити, якщо вихідні мітки належать до однієї з двох категорій.
Зображення автора
Отже, як ми перейдемо від лінійної до логістичної регресії? У лінійній регресії прогнозований вихід визначається як:
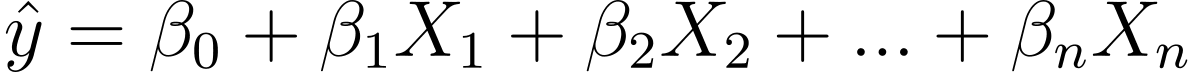
Де βs – це коефіцієнти, а X_is – предиктори (або особливості).
Без втрати загальності припустимо, що X_0 = 1:

Отже, ми можемо мати більш стислий вираз:
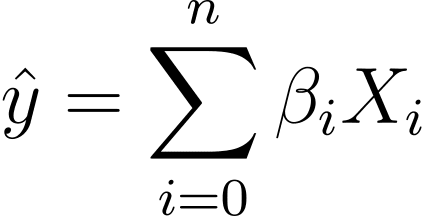
У логістичній регресії нам потрібна прогнозована ймовірність p_i в інтервалі [0,1]. Ми знаємо, що логістична функція тисне вхідні дані, щоб вони приймали значення в інтервалі [0,1].
Отже, підключивши цей вираз до логістичної функції, ми отримаємо прогнозовану ймовірність у вигляді:
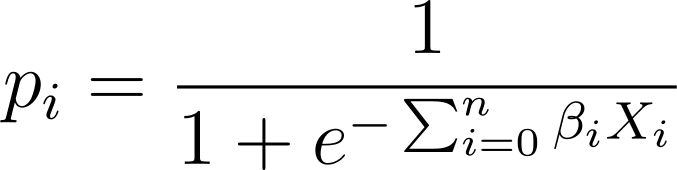
Отже, як знайти логістичну криву, яка найкраще підходить для заданого набору даних? Щоб відповісти на це питання, давайте розберемося в оцінці максимальної ймовірності.
Оцінка максимальної правдоподібності (MLE) використовується для оцінки параметрів моделі логістичної регресії шляхом максимізації функції правдоподібності. Давайте розберемо процес MLE у логістичній регресії та те, як функція витрат сформульована для оптимізації за допомогою градієнтного спуску.
Розбиття оцінки максимальної правдоподібності
Як обговорювалося, ми моделюємо ймовірність того, що двійковий результат виникає як функцію однієї або кількох змінних (або ознак):
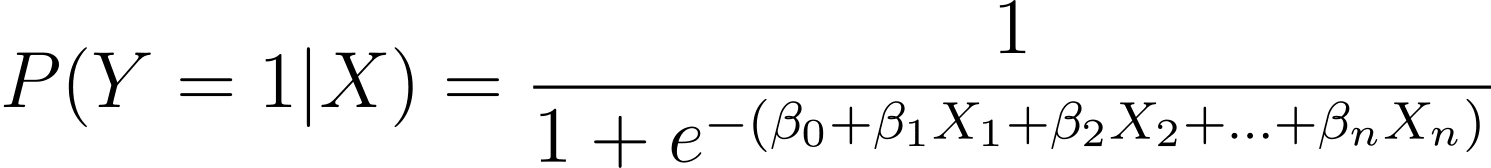
Тут βs є параметрами або коефіцієнтами моделі. X_1, X_2,…, X_n – змінні предиктора.
MLE прагне знайти значення β, які максимізують вірогідність спостережуваних даних. Функція правдоподібності, позначена як L(β), представляє ймовірність спостереження заданих результатів для заданих значень предиктора за моделлю логістичної регресії.
Формулювання функції логарифму правдоподібності
Щоб спростити процес оптимізації, прийнято працювати з функцією логарифмічної правдоподібності. Оскільки він перетворює добутки ймовірностей у суми логарифмів ймовірностей.
Функція логарифму правдоподібності для логістичної регресії визначається як:
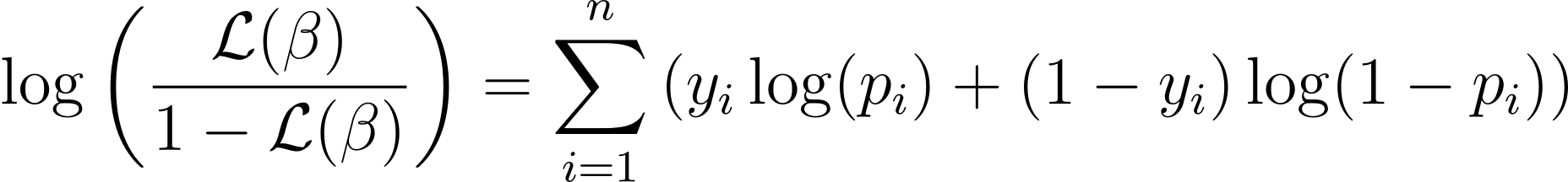
Тепер, коли ми знаємо суть логарифмічної правдоподібності, давайте приступимо до формулювання функції витрат для логістичної регресії та подальшого градієнтного спуску для пошуку найкращих параметрів моделі
Функція витрат для логістичної регресії
Щоб оптимізувати модель логістичної регресії, нам потрібно максимізувати логарифм правдоподібності. Таким чином, ми можемо використовувати від’ємну логарифм правдоподібності як функцію вартості для мінімізації під час навчання. Від’ємна логарифмічна ймовірність, яку часто називають логістичними втратами, визначається як:
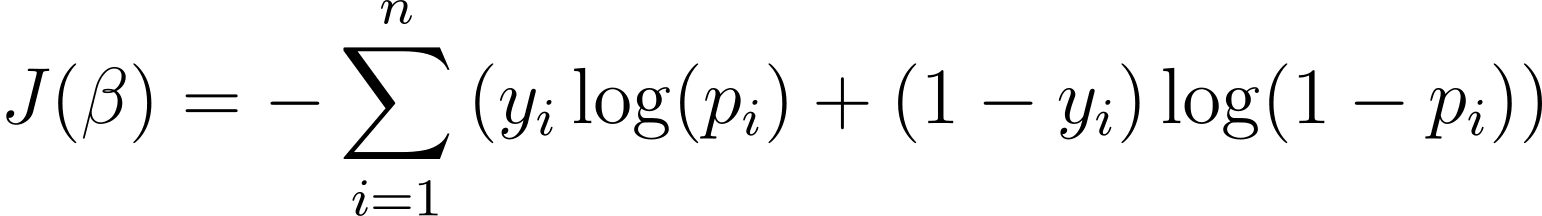
Таким чином, метою алгоритму навчання є знаходження значень ? які мінімізують цю функцію витрат. Градієнтний спуск — це алгоритм оптимізації, який зазвичай використовується для знаходження мінімуму цієї функції вартості.
Градієнтний спуск у логістичній регресії
Градієнтний спуск є ітеративним алгоритмом оптимізації, який оновлює параметри моделі β в протилежному напрямку градієнта функції витрат відносно β. Правило оновлення на кроці t+1 для логістичної регресії з використанням градієнтного спуску таке:
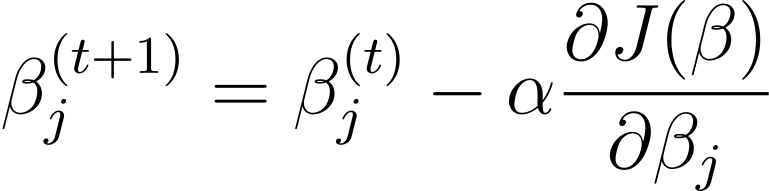
Де α – швидкість навчання.
Часткові похідні можна обчислити за допомогою ланцюгового правила. Градієнтний спуск ітеративно оновлює параметри — до конвергенції — з метою мінімізації логістичних втрат. У міру сходження він знаходить оптимальні значення β, які максимізують вірогідність спостережуваних даних.
Тепер, коли ви знаєте, як працює логістична регресія, давайте побудуємо прогнозну модель за допомогою бібліотеки scikit-learn.
Ми будемо використовувати набір даних іоносфери зі сховища машинного навчання UCI для цього підручника. Набір даних складається з 34 числових характеристик. Вихід є двійковим, один із «хороших» або «поганих» (позначається «g» або «b»). Вихідний ярлик «хороший» стосується результатів RADAR, які виявили певну структуру в іоносфері.
Крок 1 – Завантаження набору даних
Спочатку завантажте набір даних і прочитайте його у фрейм даних pandas:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Крок 2 – Вивчення набору даних
Давайте подивимося на кілька перших рядків фрейму даних:
# Display the first few rows of the DataFrame
df.head()
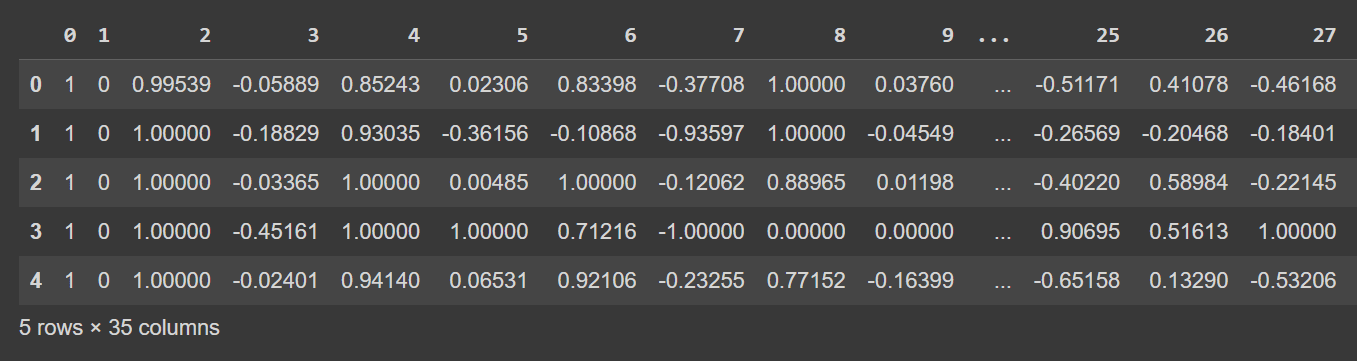
Урізаний результат df.head()
Отримаємо трохи інформації про набір даних: кількість ненульових значень і типи даних кожного зі стовпців:
# Get information about the dataset
print(df.info())
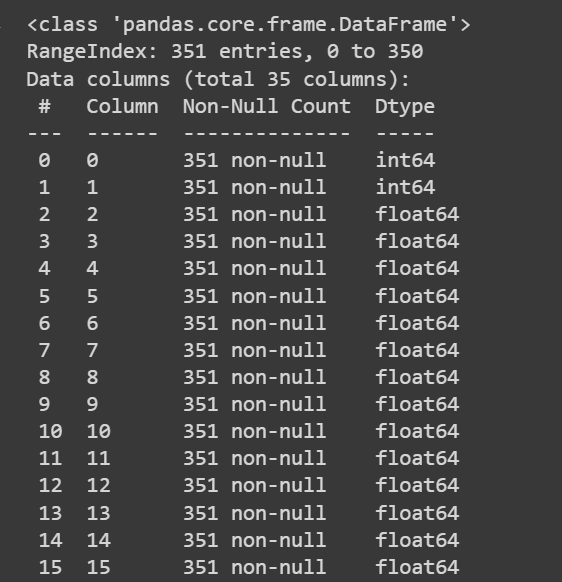 Урізаний вихід df.info()
Урізаний вихід df.info()
Оскільки ми маємо всі числові функції, ми також можемо отримати деяку описову статистику за допомогою describe() метод у кадрі даних:
# Get descriptive statistics of the dataset
print(df.describe())
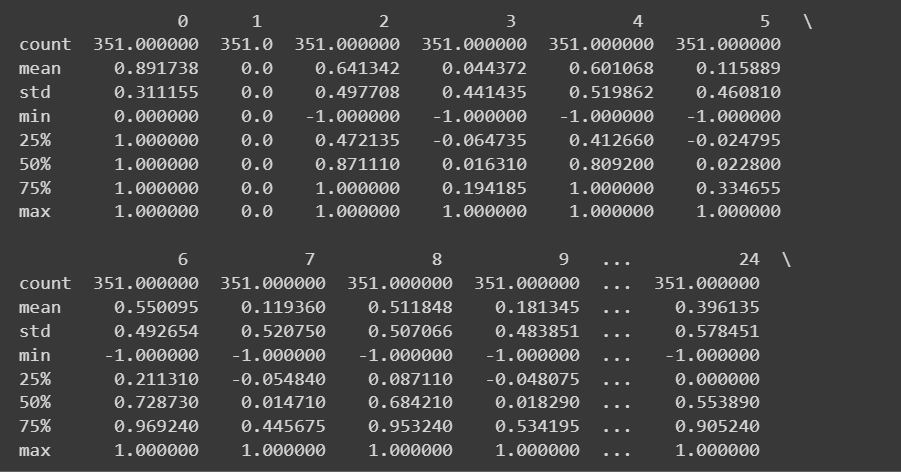
Урізаний результат df.describe()
Зараз імена стовпців від 0 до 34, включаючи мітку. Оскільки набір даних не надає описових імен для стовпців, він просто посилається на них як attribute_1 до attribute_34, якщо ви хочете, ви можете перейменувати стовпці кадру даних, як показано:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Примітка. Цей крок необов’язковий. Ви можете продовжити з назвами стовпців за замовчуванням, якщо хочете.
# Display the first few rows of the DataFrame
df.head()
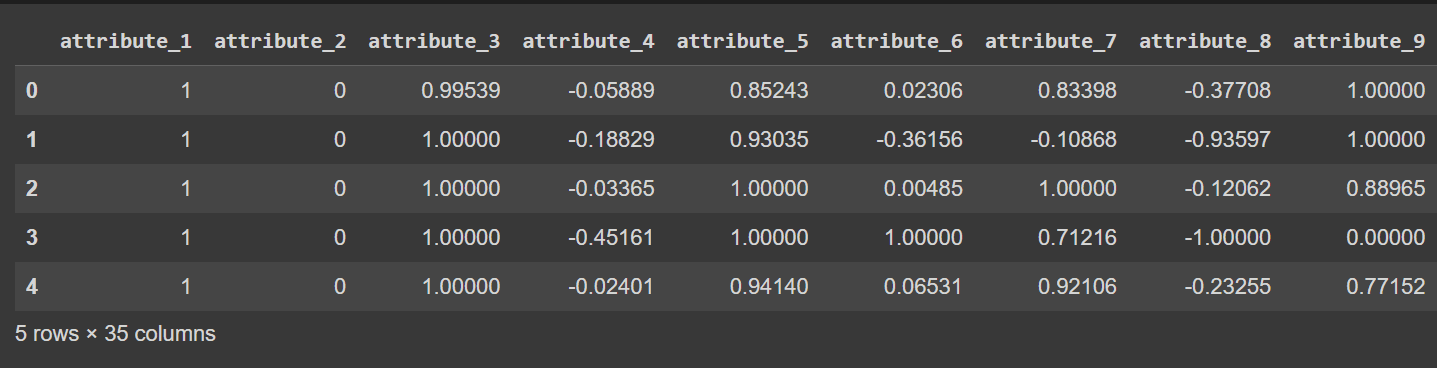
Усічений результат df.head() [після перейменування стовпців]
Крок 3 – Перейменування міток класів і візуалізація розподілу класів
Оскільки вихідні мітки класу є «g» і «b», нам потрібно відобразити їх на 1 і 0 відповідно. Ви можете зробити це за допомогою map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Давайте також візуалізуємо розподіл міток класів:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
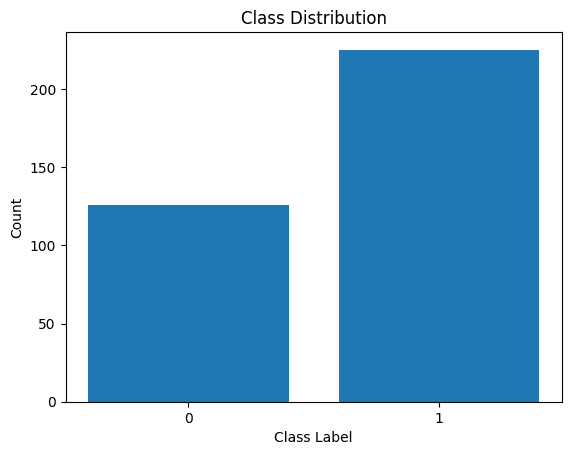
Розподіл міток класів
Ми бачимо, що є дисбаланс у розподілі. Існує більше записів, що належать до класу 1, ніж до класу 0. Ми впораємося з цим дисбалансом класів під час побудови моделі логістичної регресії.
Крок 5 – Попередня обробка набору даних
Давайте зберемо функції та виведемо такі мітки:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Після поділу набору даних на набори тренувань і тестування нам потрібно попередньо обробити набір даних.
Коли є багато числових функцій — кожна потенційно різного масштабу — нам потрібно попередньо обробити числові функції. Поширеним методом є їх перетворення таким чином, щоб вони відповідали розподілу з нульовим середнім і одиничною дисперсією.
Команда StandardScaler з модуля попередньої обробки scikit-learn допомагає нам досягти цього.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Крок 6 – Побудова моделі логістичної регресії
Тепер ми можемо створити класифікатор логістичної регресії. The LogisticRegression клас є частиною модуля linear_model scikit-learn.
Зверніть увагу, що ми встановили class_weight параметр «збалансований». Це допоможе нам пояснити класовий дисбаланс. Призначаючи ваги кожному класу — обернено пропорційно кількості записів у класах.
Після створення екземпляра класу ми можемо адаптувати модель до навчального набору даних:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Крок 7 – Оцінка моделі логістичної регресії
Ви можете зателефонувати до predict() метод отримання прогнозів моделі.
Окрім оцінки точності, ми також можемо отримати класифікаційний звіт із такими показниками, як точність, запам’ятовування та оцінка F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
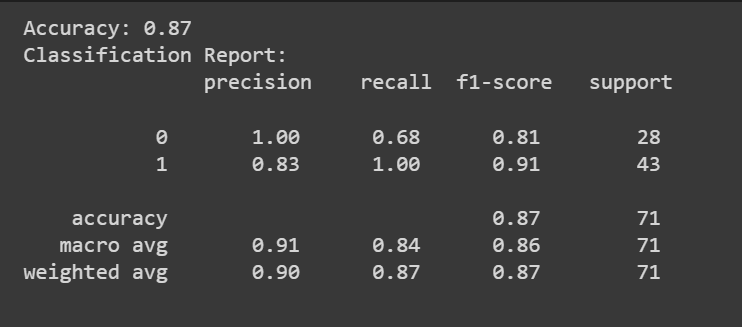
Вітаємо, ви закодували свою першу модель логістичної регресії!
У цьому підручнику ми детально дізналися про логістичну регресію: від теорії та математики до кодування класифікатора логістичної регресії.
Наступним кроком спробуйте створити модель логістичної регресії для відповідного набору даних на ваш вибір.
Набір даних Ionosphere ліцензовано згідно з a Creative Commons Attribution 4.0 International (CC BY 4.0) ліцензія:
Sigillito, V., Wing, S., Hutton, L., and Baker, K.. (1989). Іоносфера. Репозиторій машинного навчання UCI. https://doi.org/10.24432/C5W01B.
Бала Прія С є розробником і технічним автором з Індії. Їй подобається працювати на стику математики, програмування, науки про дані та створення контенту. Сфери її інтересів і знань включають DevOps, науку про дані та обробку природної мови. Вона любить читати, писати, кодувати та кави! Зараз вона навчається та ділиться своїми знаннями зі спільнотою розробників, створюючи навчальні посібники, інструкції, думки тощо.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :є
- : ні
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- МЕНЮ
- рахунки
- точність
- Achieve
- додавати
- доповнення
- після
- Цілі
- алгоритм
- алгоритми
- ВСІ
- Також
- an
- та
- відповідь
- підходи
- ЕСТЬ
- області
- AS
- припустити
- At
- авторство
- b
- пекар
- Збалансований
- бар
- BE
- оскільки
- належність
- КРАЩЕ
- Перерва
- будувати
- Створюємо
- by
- call
- CAN
- не може
- категорії
- ланцюг
- вибір
- клас
- класів
- класифікація
- закодований
- Кодування
- збирати
- Колонка
- Колони
- загальний
- зазвичай
- Commons
- співтовариство
- включає
- лаконічний
- зміст
- контент-створення
- конвертувати
- Коштувати
- покриття
- створювати
- створення
- В даний час
- крива
- дані
- точки даних
- наука про дані
- набір даних
- дефолт
- певний
- Похідні
- деталь
- виявлено
- Розробник
- DevOps
- різний
- напрям
- обговорювати
- обговорювалися
- дисплей
- розподіл
- do
- робить
- вниз
- скачати
- під час
- кожен
- сутність
- оцінити
- оцінки
- експертиза
- Дослідження
- вираз
- риси
- кілька
- знайти
- виявлення
- знахідки
- Перший
- відповідати
- стежити
- слідує
- для
- FRAME
- від
- функція
- отримати
- отримання
- даний
- Go
- мета
- великий
- Земля
- Гід
- рука
- обробляти
- Мати
- допомога
- допомагає
- її
- Як
- HTTPS
- ICS
- if
- дисбаланс
- імпорт
- in
- включати
- індекс
- Індію
- індекси
- інформація
- вхід
- витрати
- інтерес
- цікавий
- перетин
- в
- IT
- просто
- KDnuggets
- Знати
- знання
- етикетка
- етикетки
- мова
- УЧИТЬСЯ
- вчений
- вивчення
- менше
- дозволяти
- бібліотека
- ліцензія
- Ліцензований
- як
- ймовірність
- Сподобалося
- Лінія
- погрузка
- журнал
- подивитися
- виглядає як
- від
- машина
- навчання за допомогою машини
- зробити
- багато
- карта
- математики
- matplotlib
- Максимізувати
- максимізація
- максимальний
- Може..
- значити
- метод
- Метрика
- мінімізувати
- мінімальний
- модель
- Моделі
- Модулі
- більше
- рухатися
- Імена
- Природний
- Природна мова
- Обробка природних мов
- Необхідність
- негативний
- наступний
- номер
- спостерігається
- of
- часто
- on
- ONE
- Думка
- протилежний
- оптимальний
- оптимізація
- Оптимізувати
- or
- Результат
- Результати
- вихід
- виходи
- панди
- параметр
- параметри
- частина
- частин
- plato
- Інформація про дані Платона
- PlatoData
- точка
- точок
- потенційно
- Точність
- передвіщений
- Прогнози
- інтелектуального
- Прогноз
- Прогнози
- надавати перевагу
- ймовірність
- Проблема
- продовжити
- процес
- обробка
- Продукти
- Програмування
- забезпечувати
- суто
- Python
- радар
- діапазон
- ставка
- Читати
- читання
- реальний
- облік
- називають
- відноситься
- регресія
- звітом
- Сховище
- представляє
- запросити
- повага
- відповідно
- Умови повернення
- огляд
- міцний
- Правило
- s
- наука
- scikit-вчитися
- рахунок
- побачити
- сенс
- комплект
- набори
- поділ
- вона
- показаний
- простий
- спростити
- So
- деякі
- розкол
- почалася
- статистика
- Крок
- прямий
- структура
- Згодом
- такі
- підходящий
- сум
- Приймати
- приймає
- Мета
- завдання
- технічний
- тест
- Тестування
- ніж
- Що
- Команда
- Їх
- теорія
- Там.
- отже
- вони
- це
- через
- до
- Інструменти
- поїзд
- навчений
- Навчання
- Перетворення
- перетворення
- намагатися
- підручник
- навчальні посібники
- два
- Типи
- при
- розуміти
- блок
- Оновити
- Updates
- URL
- us
- рахунок США
- використання
- використовуваний
- використання
- значення
- Цінності
- візуалізувати
- we
- коли
- який
- чому
- Вікіпедія
- волі
- крило
- з
- Work
- робочий
- працює
- б
- письменник
- лист
- X
- так
- ви
- вашу
- зефірнет
- нуль







