Студія Amazon SageMaker забезпечує повністю кероване рішення для спеціалістів із обробки даних для інтерактивного створення, навчання та розгортання моделей машинного навчання (ML). Завдання для ноутбуків Amazon SageMaker дозвольте дослідникам даних запускати свої блокноти на вимогу або за розкладом кількома клацаннями миші в SageMaker Studio. З цим запуском ви можете програмно запускати блокноти як завдання за допомогою API, наданих Трубопроводи Amazon SageMaker, функція оркестровки робочого процесу ML Amazon SageMaker. Крім того, за допомогою цих API можна створити багатоетапний робочий процес машинного навчання з кількома залежними блокнотами.
SageMaker Pipelines — це рідний інструмент оркестровки робочого процесу для побудови конвеєрів машинного навчання, які використовують переваги прямої інтеграції SageMaker. Кожен конвеєр SageMaker складається з кроки, які відповідають окремим завданням, таким як обробка, навчання або використання обробки даних Amazon EMR. Завдання блокнота SageMaker тепер доступні як вбудований тип кроку в конвеєрах SageMaker. Ви можете використовувати цей крок завдання для блокнота, щоб легко запускати блокноти як завдання за допомогою лише кількох рядків коду за допомогою SDK для Amazon SageMaker Python. Крім того, ви можете з’єднати кілька залежних блокнотів, щоб створити робочий процес у формі спрямованих ациклічних графіків (DAG). Потім ви можете запускати ці завдання блокнотів або DAG, а також керувати ними та візуалізувати їх за допомогою SageMaker Studio.
Зараз дослідники даних використовують SageMaker Studio для інтерактивної розробки своїх блокнотів Jupyter, а потім використовують завдання блокнотів SageMaker для запуску цих блокнотів як запланованих завдань. Ці завдання можна виконувати негайно або за розкладом, що повторюється, без потреби працівників обробки даних рефакторювати код як модулі Python. Деякі поширені випадки використання для цього включають:
- Довгий біг-ноутбуки у фоновому режимі
- Регулярний запуск моделі висновку для створення звітів
- Перехід від підготовки невеликих вибіркових наборів даних до роботи з петабайтними великими даними
- Перенавчання та розгортання моделей на деякій каденції
- Планування завдань для моніторингу якості моделі або дрейфу даних
- Вивчення простору параметрів для кращих моделей
Незважаючи на те, що завдяки цій функції працівники обробки даних легко автоматизують автономні блокноти, робочі процеси ML часто складаються з кількох блокнотів, кожен з яких виконує певне завдання зі складними залежностями. Наприклад, блокнот, який відстежує дрейф даних моделі, повинен мати попередній етап, який дозволяє видобувати, перетворювати та завантажувати (ETL) і обробляти нові дані, а також пост-етап оновлення моделі та навчання, якщо помічено значний дрейф. . Крім того, дослідники даних можуть захотіти запустити весь цей робочий процес за регулярним розкладом, щоб оновити модель на основі нових даних. Щоб ви могли легко автоматизувати свої блокноти та створювати такі складні робочі процеси, завдання для блокнотів SageMaker тепер доступні як крок у SageMaker Pipelines. У цій публікації ми покажемо, як ви можете вирішити такі випадки використання за допомогою кількох рядків коду:
- Програмно запустіть окремий блокнот негайно або за регулярним розкладом
- Створюйте багатоетапні робочі процеси ноутбуків як DAG для безперервної інтеграції та безперервної доставки (CI/CD), якими можна керувати через інтерфейс користувача SageMaker Studio
Огляд рішення
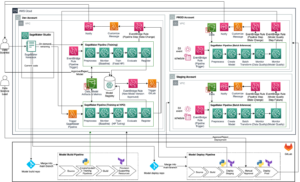
Наступна діаграма ілюструє архітектуру нашого рішення. Ви можете використовувати SageMaker Python SDK для запуску окремого завдання блокнота або робочого процесу. Ця функція створює навчальне завдання SageMaker для запуску блокнота.
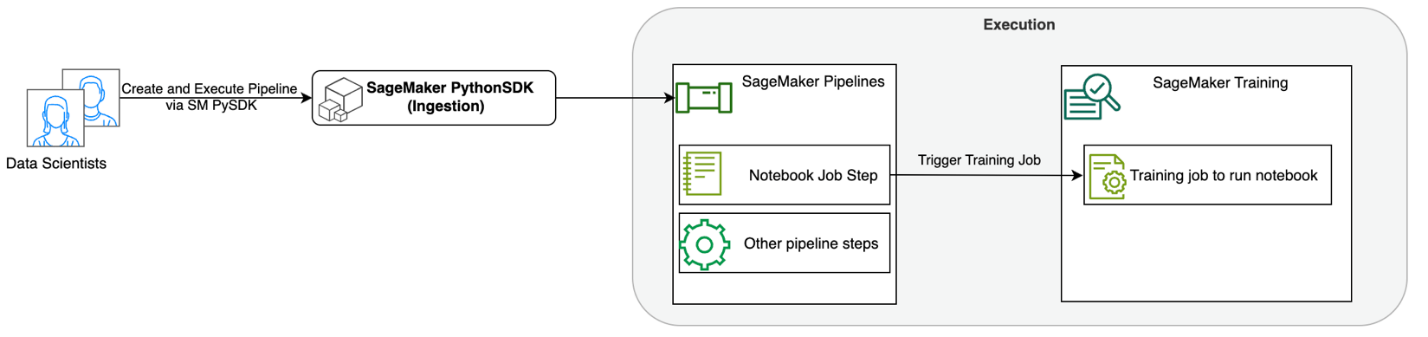
У наступних розділах ми розглядаємо зразок використання ML і демонструємо кроки для створення робочого циклу завдань ноутбука, передачі параметрів між різними кроками блокнота, планування робочого процесу та моніторингу його через SageMaker Studio.
Для нашої проблеми ML у цьому прикладі ми створюємо модель аналізу настроїв, яка є типом завдання класифікації тексту. Найпоширеніші застосування аналізу настроїв включають моніторинг соціальних мереж, управління підтримкою клієнтів і аналіз відгуків клієнтів. У цьому прикладі використовується набір даних Stanford Sentiment Treebank (SST2), який складається з рецензій на фільми разом із цілим числом (0 або 1), яке вказує на позитивні чи негативні настрої рецензії.
Нижче наведено приклад a data.csv файл, що відповідає набору даних SST2, і показує значення в перших двох стовпцях. Зауважте, що файл не повинен мати заголовка.
| Колонка 1 | Колонка 2 |
| 0 | приховати нові виділення від батьківських одиниць |
| 0 | не містить дотепності, лише напружені ґеги |
| 1 | який любить своїх героїв і повідомляє щось досить прекрасне про людську природу |
| 0 | залишається повністю задоволеним тим, що залишався незмінним у всьому |
| 0 | про найгірші кліше про помсту кретинам, які могли вигадати режисери |
| 0 | це надто трагічно, щоб заслуговувати на таке поверхове ставлення |
| 1 | демонструє, що режисер таких голлівудських блокбастерів, як патріотичні ігри, все ще може створити невеликий, особистий фільм із емоційним шумом. |
У цьому прикладі ML ми повинні виконати кілька завдань:
- Виконайте розробку функцій, щоб підготувати цей набір даних у форматі, зрозумілому нашій моделі.
- Після проектування функцій запустіть етап навчання з використанням Transformers.
- Налаштуйте груповий висновок за допомогою точно налаштованої моделі, щоб допомогти передбачити настрої щодо нових відгуків, які надходять.
- Налаштуйте етап моніторингу даних, щоб ми могли регулярно відстежувати наші нові дані на будь-який дрейф у якості, який може вимагати від нас перенавчати вагові коефіцієнти моделі.
Завдяки цьому запуску завдання блокнота як етапу конвеєрів SageMaker ми можемо організувати цей робочий процес, який складається з трьох окремих кроків. Кожен крок робочого процесу розробляється в окремому блокноті, який потім перетворюється на незалежні кроки завдань блокнота та з’єднується як конвеєр:
- Попередня обробка – Завантажте публічний набір даних SST2 з Служба простого зберігання Amazon (Amazon S3) і створіть файл CSV для запуску блокнота на кроці 2. Набір даних SST2 — це набір даних класифікації тексту з двома мітками (0 і 1) і стовпцем тексту для категоризації.
- Навчання – Візьміть сформований файл CSV і запустіть точне налаштування за допомогою BERT для класифікації тексту з використанням бібліотек Transformers. Ми використовуємо блокнот для підготовки тестових даних як частину цього кроку, який є залежним для етапу тонкого налаштування та пакетного висновку. Після завершення точного налаштування цей блокнот запускається за допомогою функції run magic і готує тестовий набір даних для вибіркового висновку за допомогою точно налаштованої моделі.
- Трансформувати та контролювати – Виконайте пакетний висновок і налаштуйте якість даних за допомогою моніторингу моделі, щоб отримати пропозицію базового набору даних.
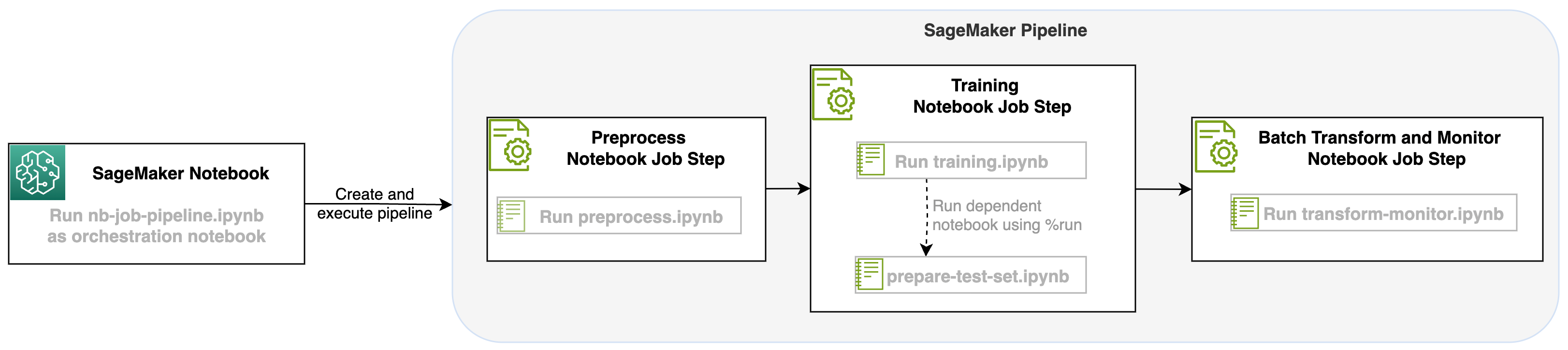
Запустіть зошити
Зразок коду для цього рішення доступний на GitHub.
Створення кроку завдання блокнота SageMaker подібне до створення інших кроків SageMaker Pipeline. У цьому прикладі блокнота ми використовуємо SageMaker Python SDK для організації робочого процесу. Щоб створити крок блокнота в SageMaker Pipelines, ви можете визначити такі параметри:
- Вхідний блокнот – Ім’я блокнота, який цей крок блокнота керуватиме. Тут ви можете передати локальний шлях до вхідного блокнота. За бажанням, якщо цей блокнот має інші блокноти, які він працює, ви можете передати їх у
AdditionalDependenciesпараметр кроку завдання блокнота. - URI зображення – Зображення Docker за кроком завдання блокнота. Це можуть бути попередньо визначені зображення, які вже надає SageMaker, або спеціальне зображення, яке ви визначили та надіслали Реєстр контейнерів Amazon Elastic (Amazon ECR). Зверніться до розділу міркувань у кінці цієї публікації, щоб дізнатися про підтримувані зображення.
- Назва ядра – Назва ядра, яке ви використовуєте в SageMaker Studio. Ця специфікація ядра зареєстрована в зображенні, яке ви надали.
- Тип екземпляра (необов'язково) - The Обчислювальна хмара Amazon Elastic Тип екземпляра (Amazon EC2) за завданням блокнота, яке ви визначили та виконуватимете.
- Параметри (необов'язково) – Параметри, які ви можете передати, які будуть доступні для вашого ноутбука. Їх можна визначити в парах ключ-значення. Крім того, ці параметри можна змінювати між різними запусками завдань ноутбука або конвеєрними запусками.
У нашому прикладі всього п’ять блокнотів:
- nb-job-pipeline.ipynb – Це наш основний блокнот, де ми визначаємо наш конвеєр і робочий процес.
- preprocess.ipynb – Цей блокнот є першим кроком у нашому робочому процесі та містить код, який витягне загальнодоступний набір даних AWS і створить із нього файл CSV.
- навчання.ipynb – Цей блокнот є другим кроком у нашому робочому процесі та містить код для отримання CSV із попереднього кроку та проведення локального навчання та тонкого налаштування. Цей крок також залежить від
prepare-test-set.ipynbблокнот, щоб отримати тестовий набір даних для вибіркового висновку за допомогою точно налаштованої моделі. - підготувати-тест-набір.ipynb – Цей блокнот створює тестовий набір даних, який наш навчальний блокнот використовуватиме на другому етапі конвеєра та використовуватиме для вибіркового висновку з точно налаштованою моделлю.
- transform-monitor.ipynb – Цей ноутбук є третім кроком у нашому робочому процесі. Він використовує базову модель BERT і виконує завдання пакетного перетворення SageMaker, а також налаштовує якість даних за допомогою моніторингу моделі.
Далі проходимося по основному блокноту nb-job-pipeline.ipynb, який об’єднує всі підблокноти в конвеєр і запускає наскрізний робочий процес. Зауважте, що хоча в наступному прикладі блокнот запускається лише один раз, ви також можете запланувати повторний запуск конвеєра. Відноситься до Документація SageMaker для детальних інструкцій.
Для нашого першого кроку роботи з ноутбуком ми передаємо параметр із відром S3 за замовчуванням. Ми можемо використовувати це відро, щоб викидати будь-які артефакти, які ми хочемо, доступні для наших інших етапів конвеєра. Для першого зошита (preprocess.ipynb), ми знімаємо загальнодоступний набір даних поїзда AWS SST2 і створюємо з нього навчальний файл CSV, який надсилаємо в це відро S3. Перегляньте наступний код:
Потім ми можемо перетворити цей блокнот на a NotebookJobStep з таким кодом у нашому головному блокноті:
Тепер, коли у нас є зразок файлу CSV, ми можемо почати навчання нашої моделі в нашому навчальному блокноті. Наш навчальний блокнот приймає той самий параметр, що й відро S3, і витягує набір навчальних даних із цього місця. Потім ми виконуємо тонке налаштування за допомогою об’єкта тренера Transformers із таким фрагментом коду:
Після тонкого налаштування ми хочемо запустити деякий пакетний висновок, щоб побачити, як працює модель. Це робиться за допомогою окремого блокнота (prepare-test-set.ipynb) у тому самому локальному шляху, який створює тестовий набір даних для виконання висновків за допомогою нашої навченої моделі. Ми можемо запустити додатковий зошит у нашому навчальному зошиті з такою чарівною клітинкою:
Ми визначаємо цю додаткову залежність блокнота в AdditionalDependencies параметр у нашому другому кроці роботи з блокнотом:
Ми також маємо вказати, що крок завдання блокнота для навчання (крок 2) залежить від кроку завдання блокнота попередньої обробки (крок 1) за допомогою add_depends_on Виклик API наступним чином:
Наш останній крок полягає в тому, що модель BERT запустить пакетне перетворення SageMaker, а також налаштує збір даних і якість через монітор моделі SageMaker. Зауважте, що це відрізняється від використання вбудованого Перетворення or захоплення кроки через трубопроводи. Наш блокнот для цього кроку виконуватиме ті самі API, але відстежуватиметься як крок завдання ноутбука. Цей крок залежить від кроку Training Job Step, який ми визначили раніше, тому ми також фіксуємо його за допомогою прапораdependent_on.
Після визначення різних кроків нашого робочого процесу ми можемо створити та запустити наскрізний конвеєр:
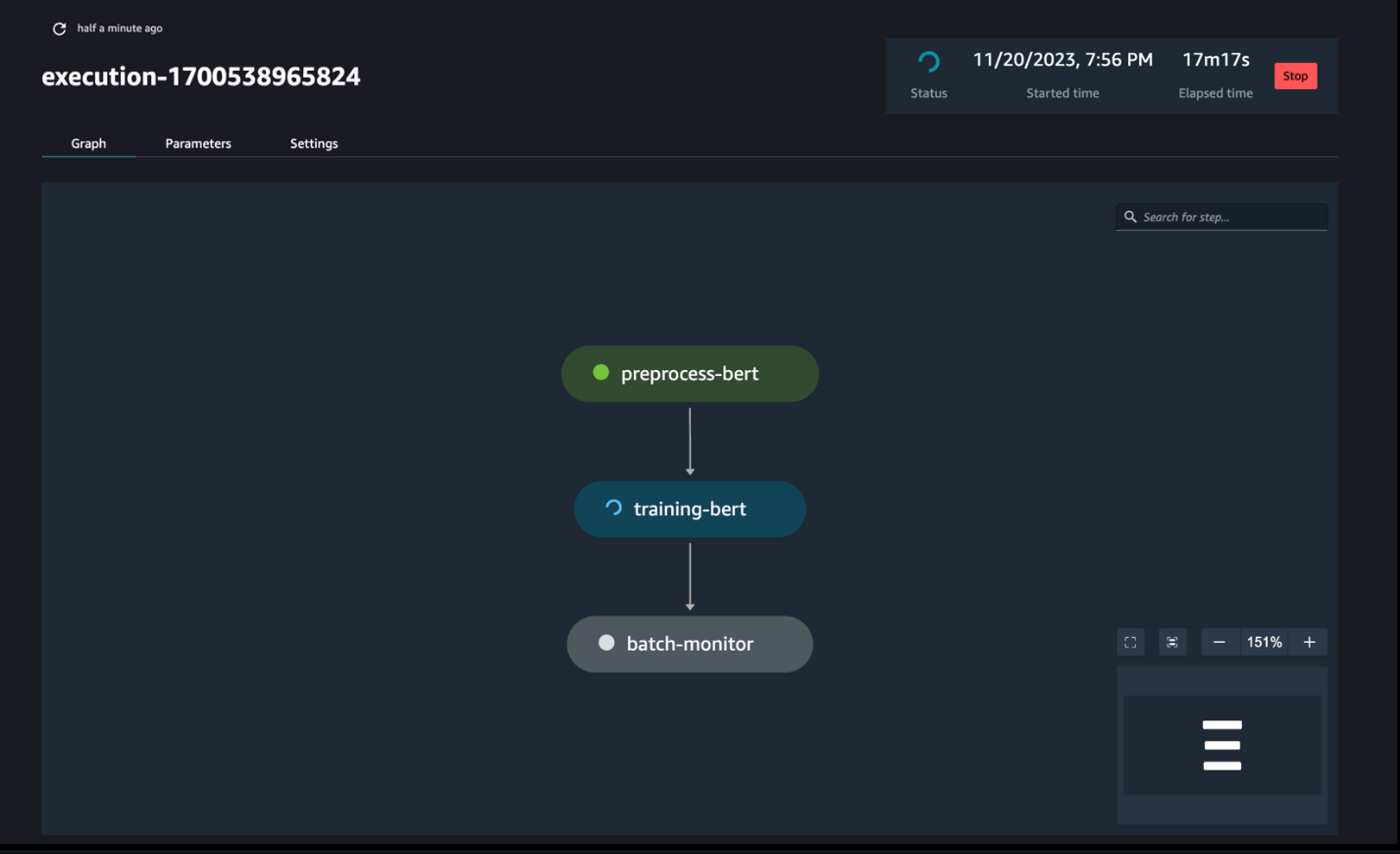
Стежити за ходом трубопроводу
Ви можете відстежувати та контролювати виконання кроків ноутбука через SageMaker Pipelines DAG, як показано на наступному знімку екрана.
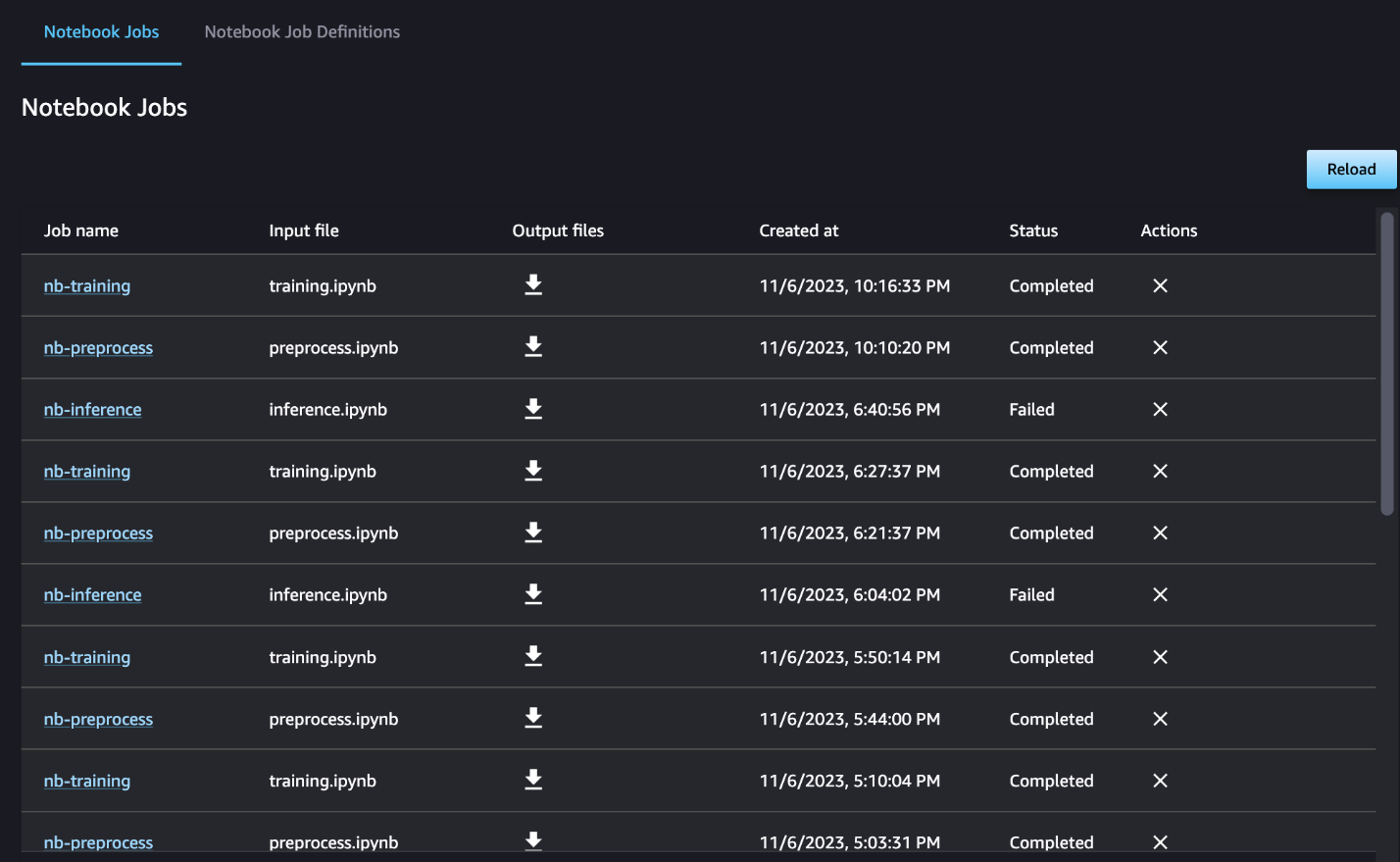
Ви також можете додатково відстежувати виконання окремих блокнотів на інформаційній панелі завдань блокнота та перемикати вихідні файли, створені за допомогою інтерфейсу користувача SageMaker Studio. У разі використання цієї функції за межами SageMaker Studio ви можете визначити користувачів, які можуть відстежувати стан виконання на інформаційній панелі завдання блокнота за допомогою тегів. Додаткову інформацію про теги, які потрібно включити, див Переглядайте завдання свого блокнота та завантажуйте результати на інформаційній панелі інтерфейсу користувача Studio.
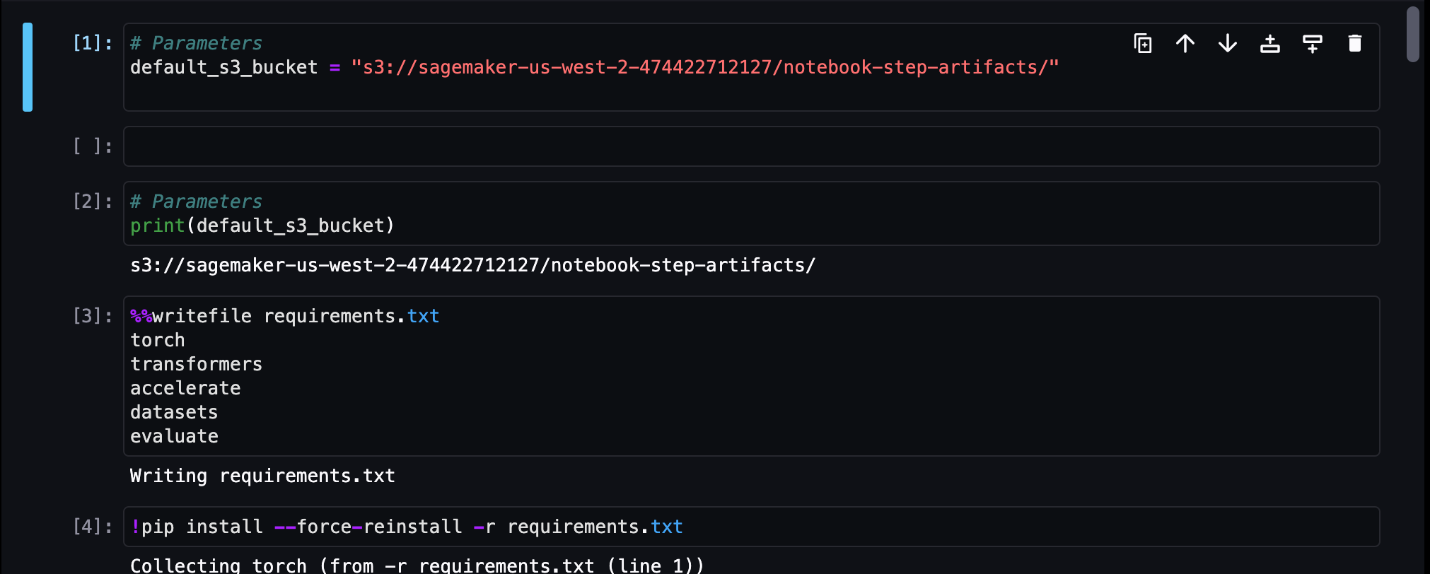
У цьому прикладі ми виводимо отримані завдання блокнота до каталогу під назвою outputs у вашому локальному шляху з кодом проходження конвеєра. Як показано на наступному знімку екрана, тут ви можете побачити вихідні дані вашого блокнота введення, а також будь-які параметри, які ви визначили для цього кроку.
Прибирати
Якщо ви дотримувалися нашого прикладу, обов’язково видаліть створений конвеєр, завдання блокнота та дані s3, завантажені зразками блокнотів.
Міркування
Нижче наведено кілька важливих міркувань щодо цієї функції.
- Обмеження SDK – Крок завдання блокнота можна створити лише за допомогою SDK SageMaker Python.
- Обмеження зображення – Крок роботи блокнота підтримує такі зображення:
Висновок
З цим запуском працівники обробки даних тепер можуть програмно запускати свої блокноти з кількома рядками коду за допомогою SageMaker Python SDK. Крім того, ви можете створювати складні багатоетапні робочі процеси за допомогою своїх ноутбуків, значно скорочуючи час, необхідний для переходу від ноутбука до конвеєра CI/CD. Після створення конвеєра ви можете використовувати SageMaker Studio для перегляду та запуску DAG для своїх конвеєрів, а також для керування та порівняння прогонів. Незалежно від того, чи плануєте ви наскрізні робочі процеси ML або їх частину, ми радимо вам спробувати робочі процеси на основі ноутбуків.
Про авторів
 Анчіт Гупта є старшим менеджером із продуктів Amazon SageMaker Studio. Вона зосереджується на створенні інтерактивних робочих процесів із науки про дані та інженерії даних із середовища розробки SageMaker Studio. У вільний час вона любить готувати, грати в настільні/карткові ігри та читати.
Анчіт Гупта є старшим менеджером із продуктів Amazon SageMaker Studio. Вона зосереджується на створенні інтерактивних робочих процесів із науки про дані та інженерії даних із середовища розробки SageMaker Studio. У вільний час вона любить готувати, грати в настільні/карткові ігри та читати.
 Рам Вегіражу є архітектором ML у команді SageMaker Service. Він зосереджується на допомозі клієнтам створювати й оптимізувати свої рішення AI/ML на Amazon SageMaker. У вільний час любить подорожувати та писати.
Рам Вегіражу є архітектором ML у команді SageMaker Service. Він зосереджується на допомозі клієнтам створювати й оптимізувати свої рішення AI/ML на Amazon SageMaker. У вільний час любить подорожувати та писати.
 Едуард Сан є старшим SDE, який працює в SageMaker Studio в Amazon Web Services. Він зосереджений на створенні інтерактивного рішення ML та спрощенні взаємодії з клієнтами для інтеграції SageMaker Studio з популярними технологіями в інженерії даних та екосистемою ML. У вільний час Едвард є великим шанувальником кемпінгу, походів і риболовлі та любить проводити час із сім’єю.
Едуард Сан є старшим SDE, який працює в SageMaker Studio в Amazon Web Services. Він зосереджений на створенні інтерактивного рішення ML та спрощенні взаємодії з клієнтами для інтеграції SageMaker Studio з популярними технологіями в інженерії даних та екосистемою ML. У вільний час Едвард є великим шанувальником кемпінгу, походів і риболовлі та любить проводити час із сім’єю.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- : має
- :є
- :де
- $UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- МЕНЮ
- доступною
- ациклічні
- Додатковий
- Додатково
- Перевага
- після
- AI / ML
- ВСІ
- дозволяє
- по
- вже
- Також
- хоча
- Amazon
- Amazon EC2
- Amazon SageMaker
- Студія Amazon SageMaker
- Amazon Web Services
- an
- аналіз
- Аналізуючи
- та
- будь-який
- API
- Інтерфейси
- застосування
- архітектура
- ЕСТЬ
- AS
- At
- автоматизувати
- доступний
- AWS
- база
- заснований
- Базова лінія
- BE
- красивий
- було
- за
- буття
- Краще
- між
- Великий
- будувати
- Створюємо
- вбудований
- але
- by
- call
- званий
- кемпінг
- CAN
- захоплення
- випадок
- випадків
- осередок
- символи
- класифікація
- код
- Колонка
- Колони
- комбінати
- Приходити
- загальний
- порівняти
- повний
- комплекс
- складається
- У складі
- обчислення
- Проводити
- підключений
- міркування
- складається
- Контейнер
- містить
- безперервний
- конвертувати
- перероблений
- приготування
- Відповідний
- може
- створювати
- створений
- створює
- створення
- В даний час
- виготовлений на замовлення
- клієнт
- Досвід клієнтів
- підтримка клієнтів
- Клієнти
- DAG
- приладова панель
- дані
- моніторинг даних
- Підготовка даних
- обробка даних
- якість даних
- наука про дані
- набори даних
- дефолт
- визначати
- певний
- доставка
- Попит
- залежно
- Залежність
- залежний
- залежить
- розгортання
- розгортання
- докладно
- деталі
- розвивати
- розвиненою
- різний
- прямий
- спрямований
- Директор
- чіткий
- Docker
- справи
- зроблений
- вниз
- скачати
- дамп
- кожен
- легко
- екосистема
- Едвард
- включіть
- дозволяє
- заохочувати
- кінець
- кінець в кінець
- Машинобудування
- Весь
- епоха
- Ефір (ETH)
- приклад
- виконувати
- виконання
- досвід
- додатково
- витяг
- сім'я
- вентилятор
- далеко
- особливість
- зворотний зв'язок
- кілька
- філе
- Файли
- Фільм
- режисери
- Перший
- рибальський
- п'ять
- увагу
- фокусується
- потім
- після
- слідує
- для
- форма
- формат
- від
- повністю
- функціональність
- Крім того
- Games
- породжувати
- графіки
- Мати
- he
- допомога
- допомогу
- її
- тут
- піший туризм
- його
- Голлівуд
- Як
- HTML
- HTTP
- HTTPS
- людина
- if
- ілюструє
- зображення
- зображень
- негайно
- імпорт
- важливо
- in
- включати
- незалежний
- вказує
- індивідуальний
- вхід
- екземпляр
- інструкції
- інтегрувати
- інтеграція
- інтерактивний
- в
- IT
- ЙОГО
- робота
- Джобс
- JPG
- просто
- етикетка
- етикетки
- останній
- запуск
- вивчення
- libraries
- Лінія
- ліній
- загрузка
- місцевий
- розташування
- Довго
- любить
- машина
- навчання за допомогою машини
- магія
- головний
- РОБОТИ
- управляти
- вдалося
- управління
- менеджер
- Медіа
- Заслуга
- може бути
- ML
- модель
- Моделі
- модифікований
- Модулі
- монітор
- моніторинг
- монітори
- більше
- найбільш
- рухатися
- фільм
- множинний
- повинен
- ім'я
- рідний
- Необхідність
- необхідний
- негативний
- Нові
- немає
- увагу
- ноутбук
- ноутбуки
- зараз
- об'єкт
- of
- часто
- on
- ONE
- тільки
- Оптимізувати
- or
- оркестровка
- Інше
- наші
- з
- вихід
- виходи
- поза
- пар
- параметр
- параметри
- частина
- проходити
- Проходження
- шлях
- виконувати
- виконанні
- персонал
- трубопровід
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- популярний
- позитивний
- пошта
- передбачати
- підготовка
- Готувати
- Готує
- підготовка
- попередній
- раніше
- Проблема
- обробка
- Product
- менеджер по продукції
- забезпечувати
- за умови
- забезпечує
- громадськість
- Тягне
- цілей
- Штовхати
- штовхнув
- Python
- якість
- швидше
- R
- швидше
- Читати
- читання
- повторювані
- зниження
- Рефактор
- послатися
- зареєстрований
- регулярно
- залишатися
- ПОВТОРНО
- вимагати
- в результаті
- огляд
- Відгуки
- прогін
- біг
- пробіжки
- мудрець
- Трубопроводи SageMaker
- то ж
- Незадоволений
- розклад
- плановий
- Планові роботи
- планування
- наука
- Вчені
- Sdk
- другий
- розділ
- розділам
- побачити
- бачив
- старший
- настрій
- окремий
- обслуговування
- Послуги
- Сесія
- комплект
- установка
- кілька
- форми
- вона
- Повинен
- Показувати
- демонстрації
- показаний
- Шоу
- значний
- істотно
- аналогічний
- простий
- спрощення
- один
- невеликий
- менше
- уривок
- So
- соціальна
- соціальні медіа
- рішення
- Рішення
- ВИРІШИТИ
- деякі
- що в сім'ї щось
- Простір
- конкретний
- Витрати
- автономні
- Станфорд
- старт
- Статус
- Крок
- заходи
- Як і раніше
- зберігання
- просто
- студія
- такі
- Sun
- підтримка
- Підтриманий
- Опори
- Переконайтеся
- Приймати
- приймає
- Завдання
- завдання
- команда
- Технології
- тест
- текст
- Класифікація тексту
- Що
- Команда
- їх
- Їх
- потім
- Ці
- третій
- це
- ті
- три
- через
- час
- до
- разом
- занадто
- інструмент
- Усього:
- трек
- поїзд
- навчений
- Навчання
- Перетворення
- Трансформатори
- Подорож
- викликати
- ПЕРЕГЛЯД
- два
- тип
- ui
- розуміти
- Оновити
- us
- використання
- використання випадку
- використовуваний
- користувачі
- використовує
- використання
- використовує
- Цінності
- різний
- через
- вид
- візуалізувати
- ходити
- хотіти
- we
- Web
- веб-сервіси
- коли
- Чи
- який
- в той час як
- ВООЗ
- волі
- з
- в
- без
- робочі
- робочий
- Робочі процеси
- робочий
- найгірше
- лист
- ви
- вашу
- зефірнет