з Amazon EMR 6.15 ми запустили Формування озера AWS засновані на тонкому контролі доступу (FGAC) у форматах відкритих таблиць (OTF), включаючи Apache Hudi, Apache Iceberg і Delta lake. Це дозволяє спростити безпеку та керування озера транзакційних даних забезпечуючи керування доступом на рівні таблиць, стовпців і рядків із вашими завданнями Apache Spark. Багато великих корпоративних компаній прагнуть використовувати своє озеро транзакційних даних, щоб отримати інформацію та покращити процес прийняття рішень. Ви можете побудувати архітектуру будинку біля озера за допомогою Amazon EMR, інтегрованої з Lake Formation для FGAC. Ця комбінація послуг дозволяє проводити аналіз даних у вашому озері транзакційних даних, забезпечуючи безпечний і контрольований доступ.
Компонент сервера записів Amazon EMR підтримує функцію фільтрації даних на рівні таблиць, стовпців, рядків, клітинок і вкладених атрибутів. Він розширює підтримку форматів Hive, Apache Hudi, Apache Iceberg і Delta lake як для операцій читання (включаючи подорожі в часі та додаткові запити), так і для операцій запису (за операторами DML, такими як INSERT). Крім того, у версії 6.15 Amazon EMR представляє захист контролю доступу для свого веб-інтерфейсу додатків, наприклад кластерного сервера історії Spark, сервера часової шкали Yarn та інтерфейсу користувача Yarn Resource Manager.
У цій публікації ми демонструємо, як застосувати FGAC на Апач Худі таблиці з використанням Amazon EMR, інтегрованого з Lake Formation.
Приклад використання озера даних транзакцій
Клієнти Amazon EMR часто використовують формати відкритих таблиць для підтримки своїх потреб у транзакціях ACID і подорожі в часі в озері даних. Зберігаючи історичні версії, подорожі в часі озера даних забезпечують такі переваги, як аудит і відповідність, відновлення та відкат даних, відтворюваний аналіз і дослідження даних у різні моменти часу.
Іншим популярним випадком використання озера даних транзакцій є інкрементний запит. Інкрементний запит відноситься до стратегії запиту, яка зосереджена на обробці та аналізі лише нових або оновлених даних у озері даних з часу останнього запиту. Ключова ідея додаткових запитів полягає у використанні метаданих або механізмів відстеження змін для визначення нових або змінених даних після останнього запиту. Виявивши ці зміни, система запитів може оптимізувати запит для обробки лише відповідних даних, значно скорочуючи час обробки та вимоги до ресурсів.
Огляд рішення
У цій публікації ми демонструємо, як реалізувати FGAC у таблицях Apache Hudi за допомогою Amazon EMR on Обчислювальна хмара Amazon Elastic (Amazon EC2) інтегровано з Lake Formation. Apache Hudi — це платформа транзакційного озера даних з відкритим кодом, яка значно спрощує поступову обробку даних і розробку конвеєрів даних. Ця нова функція FGAC підтримує всі OTF. Окрім демонстрації з Hudi тут, ми будемо стежити за іншими таблицями OTF в інших блогах. Ми використовуємо ноутбуки in Студія Amazon SageMaker для читання та запису даних Hudi через різні дозволи доступу користувачів через кластер EMR. Це відображає реальні сценарії доступу до даних, наприклад, якщо інженерному користувачеві потрібен повний доступ до даних для усунення несправностей на платформі даних, тоді як аналітикам даних може знадобитися лише доступ до підмножини цих даних, яка не містить особистої інформації (PII). ). Інтеграція з утворенням озера через Роль середовища виконання Amazon EMR додатково дає змогу покращити захист даних і спростити керування даними для робочих навантажень Amazon EMR. Це рішення забезпечує безпечне та контрольоване середовище для доступу до даних, що відповідає різноманітним потребам і вимогам безпеки різних користувачів і ролей в організації.
Наступна діаграма ілюструє архітектуру рішення.
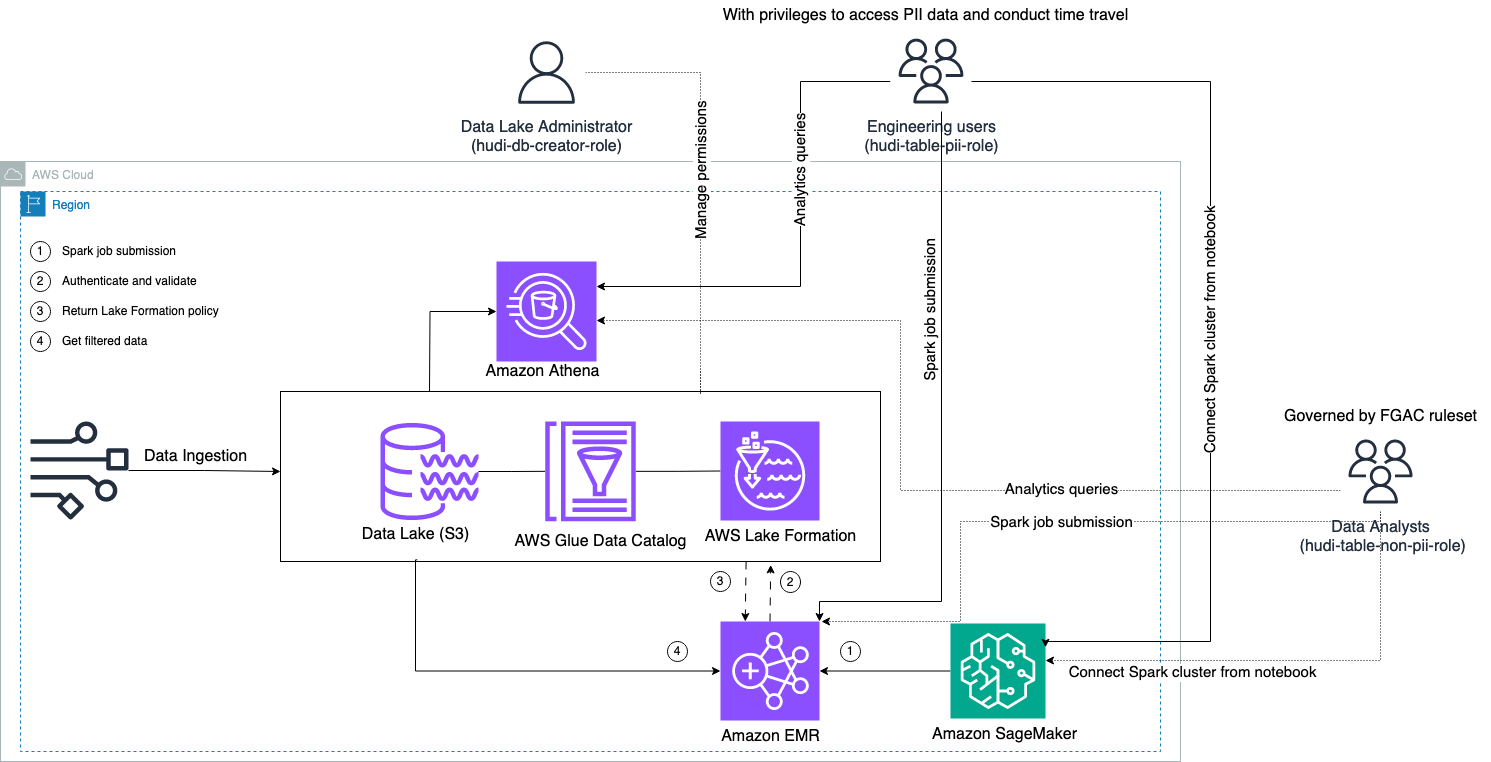
Ми проводимо процес прийому даних, щоб перемістити (оновити та вставити) набір даних Hudi до Служба простого зберігання Amazon (Amazon S3) і зберегти або оновити схему таблиці в Клей AWS Каталог даних. З нульовим переміщенням даних ми можемо запитувати таблицю Hudi, керовану Lake Formation, через різні служби AWS, такі як Амазонка Афіна, Amazon EMR та Amazon SageMaker.
Коли користувачі надсилають завдання Spark через будь-яку кінцеву точку кластера EMR (EMR Steps, Livy, EMR Studio та SageMaker), Lake Formation перевіряє їхні привілеї та наказує кластеру EMR відфільтрувати конфіденційні дані, наприклад дані ідентифікаційної інформації.
Це рішення має три різні типи користувачів з різними рівнями дозволів на доступ до даних Hudi:
- hudi-db-creator-role – Це використовується адміністратором озера даних, який має привілеї для виконання операцій DDL, таких як створення, зміна та видалення об’єктів бази даних. Вони можуть визначати правила фільтрації даних на Lake Formation для контролю доступу до даних на рівні рядків і стовпців. Ці правила FGAC гарантують, що озеро даних захищено та відповідає вимогам щодо конфіденційності даних.
- hudi-table-pii-role – Це використовується інженерними користувачами. Інженерні користувачі здатні виконувати подорожі в часі та інкрементні запити як за Copy-on-Write (CoW), так і за Merge-on-Read (MoR). Вони також мають право доступу до ідентифікаційної інформації на основі будь-яких позначок часу.
- hudi-table-non-pii-role – Цим користуються аналітики даних. Права доступу до даних аналітиків регулюються правилами FGAC, які контролюються адміністраторами озера даних. Вони не мають видимості в стовпцях, що містять ідентифікаційну інформацію, як-от імена та адреси. Крім того, вони не можуть отримати доступ до рядків даних, які не відповідають певним умовам. Наприклад, користувачі можуть отримати доступ лише до рядків даних, які належать їхній країні.
Передумови
Ви можете завантажити три блокноти, використані в цій публікації, з GitHub репо.
Перш ніж розгортати рішення, переконайтеся, що у вас є:
Щоб налаштувати дозволи, виконайте такі дії:
- Увійдіть у свій обліковий запис AWS за допомогою свого адміністратора користувача IAM.
Переконайтеся, що ви вus-east-1Регіон.
- Створіть відро S3 у
us-east-1Регіон (наприклад,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Далі ми вмикаємо Lake Formation by зміна стандартної моделі дозволів.
- Увійдіть у консоль Lake Formation як адміністратор.
- Вибирати Параметри каталогу даних при адміністрація у навігаційній панелі.
- під Дозволи за замовчуванням для новостворених баз даних і таблиць, зніміть вибір Використовуйте лише контроль доступу IAM для нових баз даних та Використовуйте лише контроль доступу IAM для нових таблиць у нових базах даних.
- Вибирати зберегти.
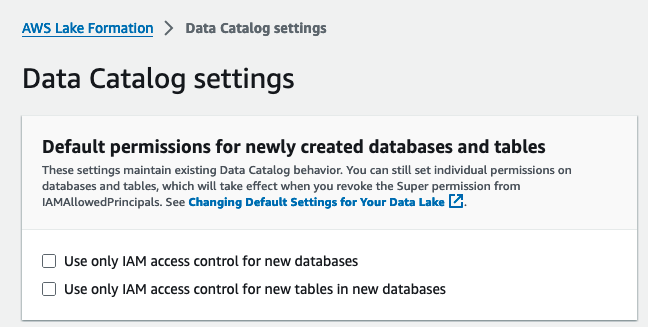
Крім того, вам потрібно скасувати IAMAllowedPrincipals для ресурсів (баз даних і таблиць), створених, якщо ви запустили Lake Formation із параметром за замовчуванням.
Нарешті, ми створюємо пару ключів для Amazon EMR.
- На консолі Amazon EC2 виберіть Ключові пари у навігаційній панелі.
- Вибирати Створіть пару ключів.
- для ІМ'Я, введіть назву (наприклад
emr-fgac-hudi-keypair). - Вибирати Створіть пару ключів.
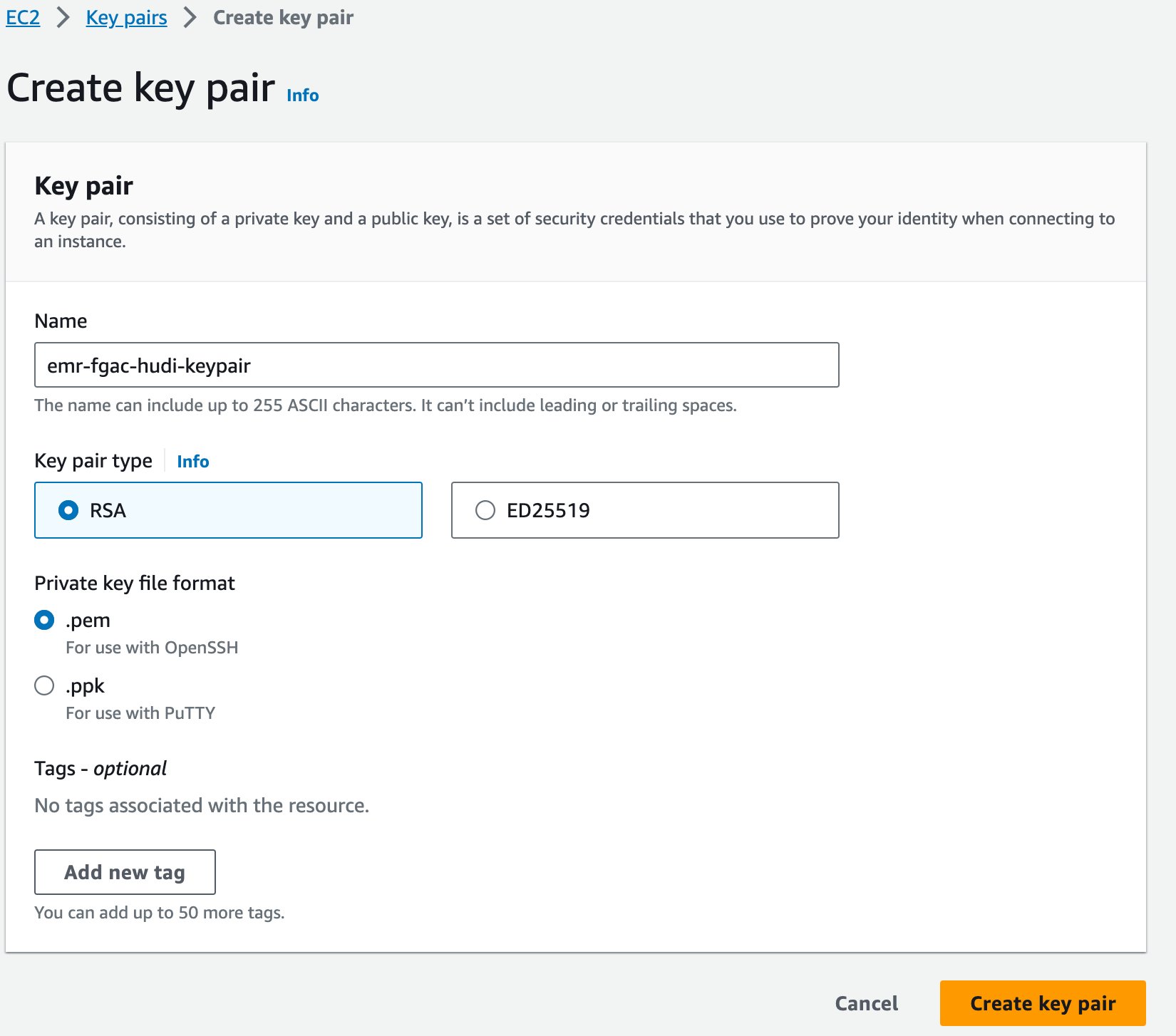
Згенерована пара ключів (для цієї публікації, emr-fgac-hudi-keypair.pem) буде збережено на вашому локальному комп’ютері.
Далі створюємо AWS Cloud9 інтерактивне середовище розробки (IDE).
- На консолі AWS Cloud9 виберіть Середовища у навігаційній панелі.
- Вибирати Створити середовище.
- для ІМ'Я¸ введіть назву (наприклад,
emr-fgac-hudi-env). - Збережіть інші налаштування за замовчуванням.
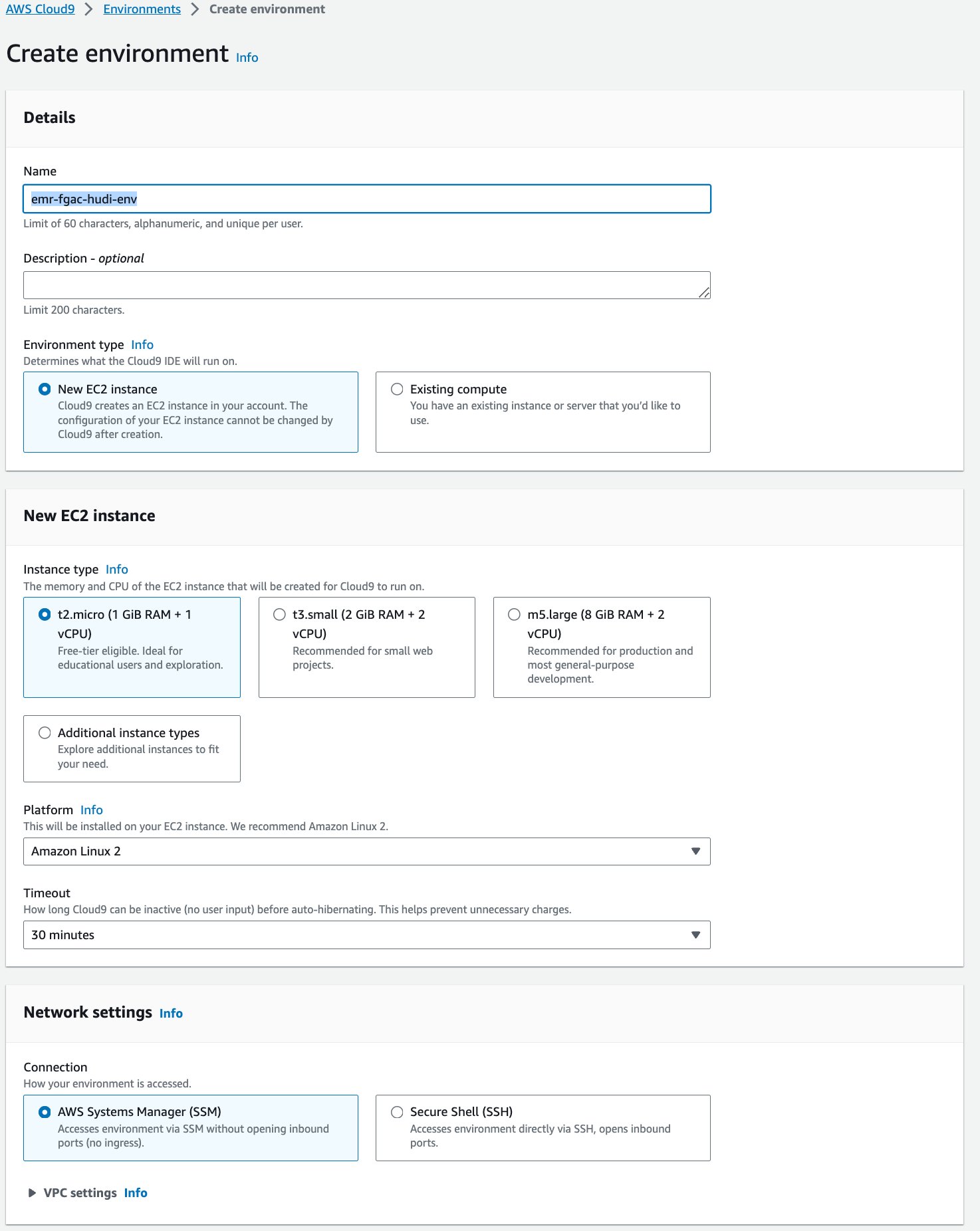
- Вибирати Створювати.
- Коли IDE буде готова, виберіть відкритий щоб його відкрити.
- У IDE AWS Cloud9 на філе меню, виберіть Завантажте локальні файли.

- Завантажте файл пари ключів (
emr-fgac-hudi-keypair.pem). - Виберіть знак плюс і виберіть Новий термінал.
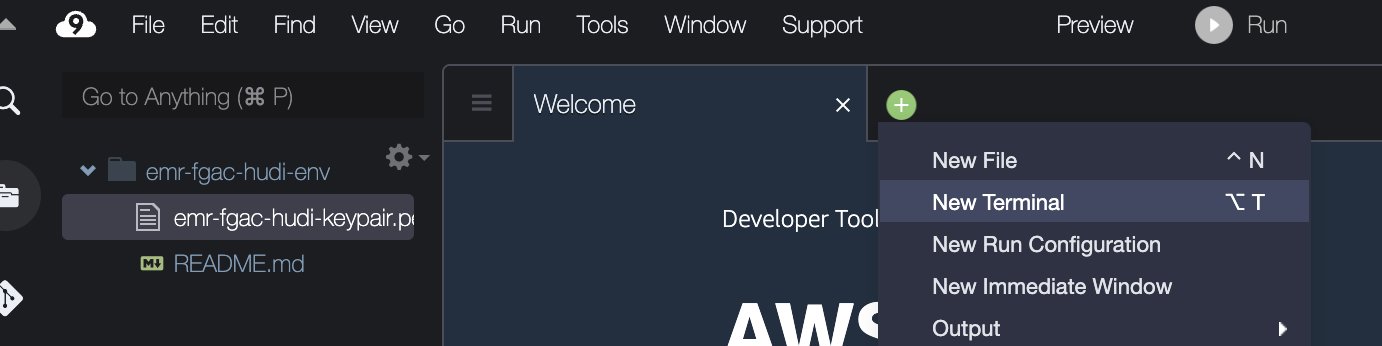
- У терміналі введіть такі командні рядки:
Зверніть увагу, що приклад коду є доказом концепції лише для демонстраційних цілей. Для виробничих систем використовуйте довірений центр сертифікації (CA) для видачі сертифікатів. Відноситься до Надання сертифікатів для шифрування даних під час передачі за допомогою шифрування Amazon EMR for details.
Розгорніть рішення через AWS CloudFormation
Ми надаємо AWS CloudFormation шаблон, який автоматично налаштовує такі служби та компоненти:
- Відро S3 для озера даних. Він містить зразок набору даних TPC-DS.
- Кластер EMR із конфігурацією безпеки та ввімкненим публічним DNS.
- Ролі IAM у середовищі виконання EMR із детальними дозволами Lake Formation:
- -hudi-db-creator-role – Ця роль використовується для створення бази даних і таблиць Apache Hudi.
- -худі-стіл-піі-роль – Ця роль надає дозвіл запитувати всі стовпці таблиць Hudi, включаючи стовпці з ідентифікаційною інформацією.
- -hudi-table-non-pii-роль – Ця роль надає дозвіл на запити таблиць Hudi, які відфільтрували стовпці ідентифікаційної інформації за Lake Formation.
- Ролі виконання SageMaker Studio, які дозволяють користувачам виконувати свої відповідні ролі середовища виконання EMR.
- Мережеві ресурси, такі як VPC, підмережі та групи безпеки.
Виконайте наступні кроки, щоб розгорнути ресурси:
- Вибирати Швидке створення стека щоб запустити стек CloudFormation.
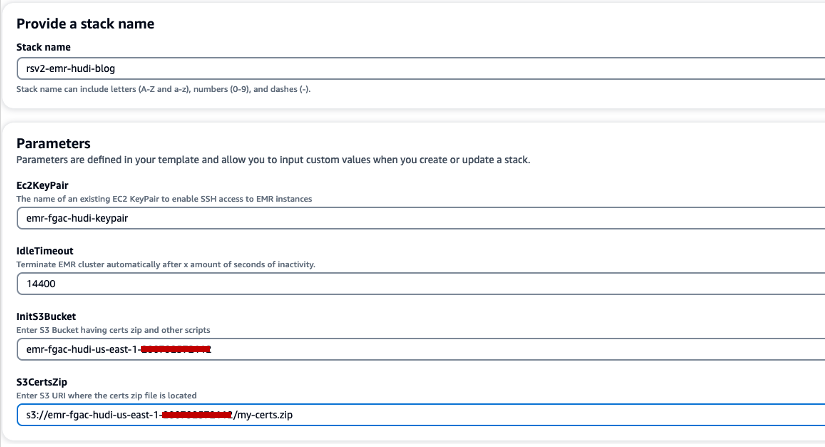
- для Назва стека, введіть назву стека (наприклад,
rsv2-emr-hudi-blog). - для Ec2KeyPair, введіть назву вашої пари ключів.
- для IdleTimeout, введіть тайм-аут простою для кластера EMR, щоб уникнути оплати за кластер, коли він не використовується.
- для InitS3Bucket, введіть назву сегмента S3, яку ви створили, щоб зберегти файл .zip сертифіката шифрування Amazon EMR.
- для S3CertsZip, введіть S3 URI файлу .zip сертифіката шифрування Amazon EMR.
- Select Я розумію, що AWS CloudFormation може створювати ресурси IAM із власними іменами.
- Вибирати Створити стек.
Розгортання стеку CloudFormation займає приблизно 10 хвилин.
Налаштуйте Lake Formation для інтеграції Amazon EMR
Виконайте наступні кроки, щоб налаштувати Lake Formation:
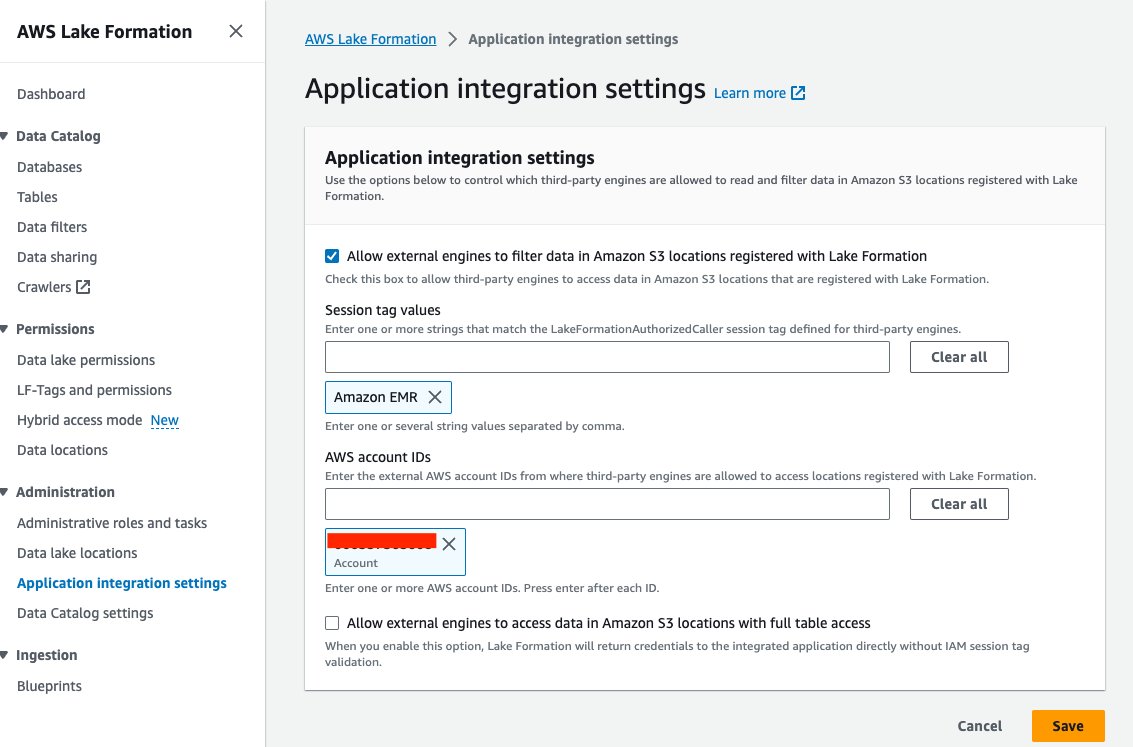
- На консолі Lake Formation виберіть Налаштування інтеграції програми при адміністрація у навігаційній панелі.
- Select Дозволити зовнішнім механізмам фільтрувати дані в розташуваннях Amazon S3, зареєстрованих у Lake Formation.
- Вибирати Amazon EMR та цінності Значення тегів сесії.
- Введіть ідентифікатор свого облікового запису AWS для Ідентифікатори облікових записів AWS.
- Вибирати зберегти.
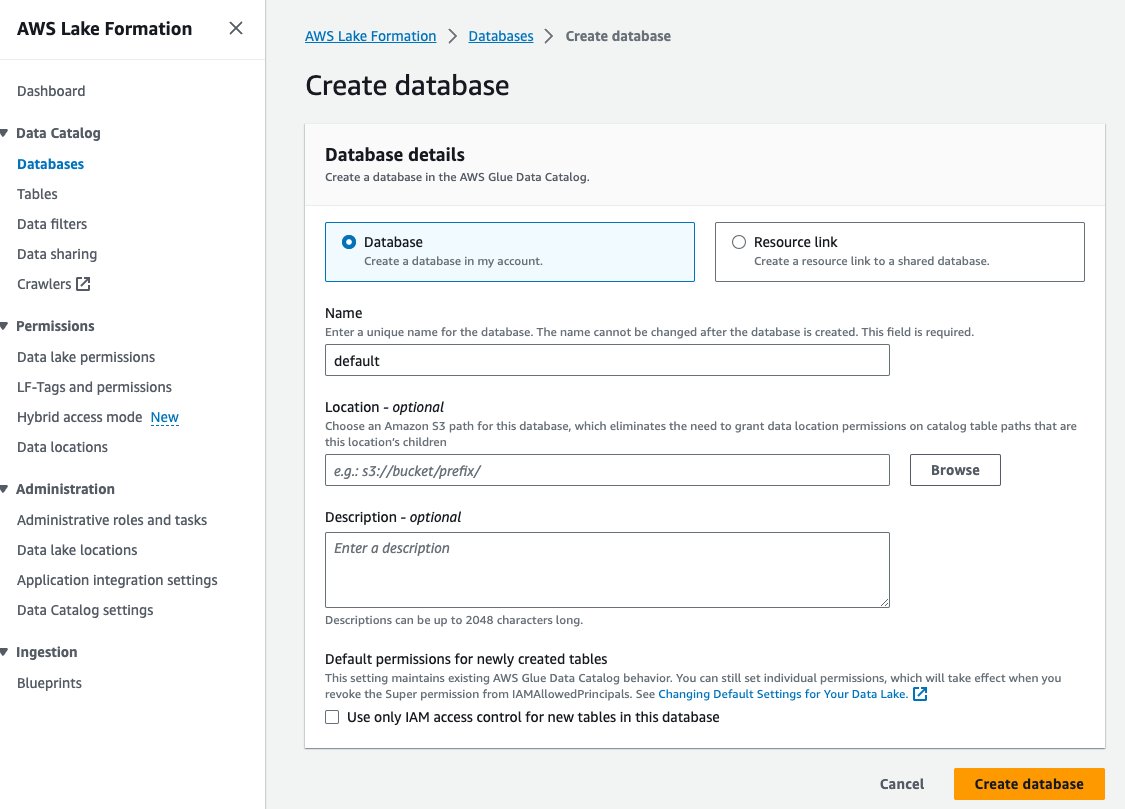
- Вибирати Бази даних при Каталог даних у навігаційній панелі.
- Вибирати Create database.
- для ІМ'Я, введіть за замовчуванням.
- Вибирати Create database.
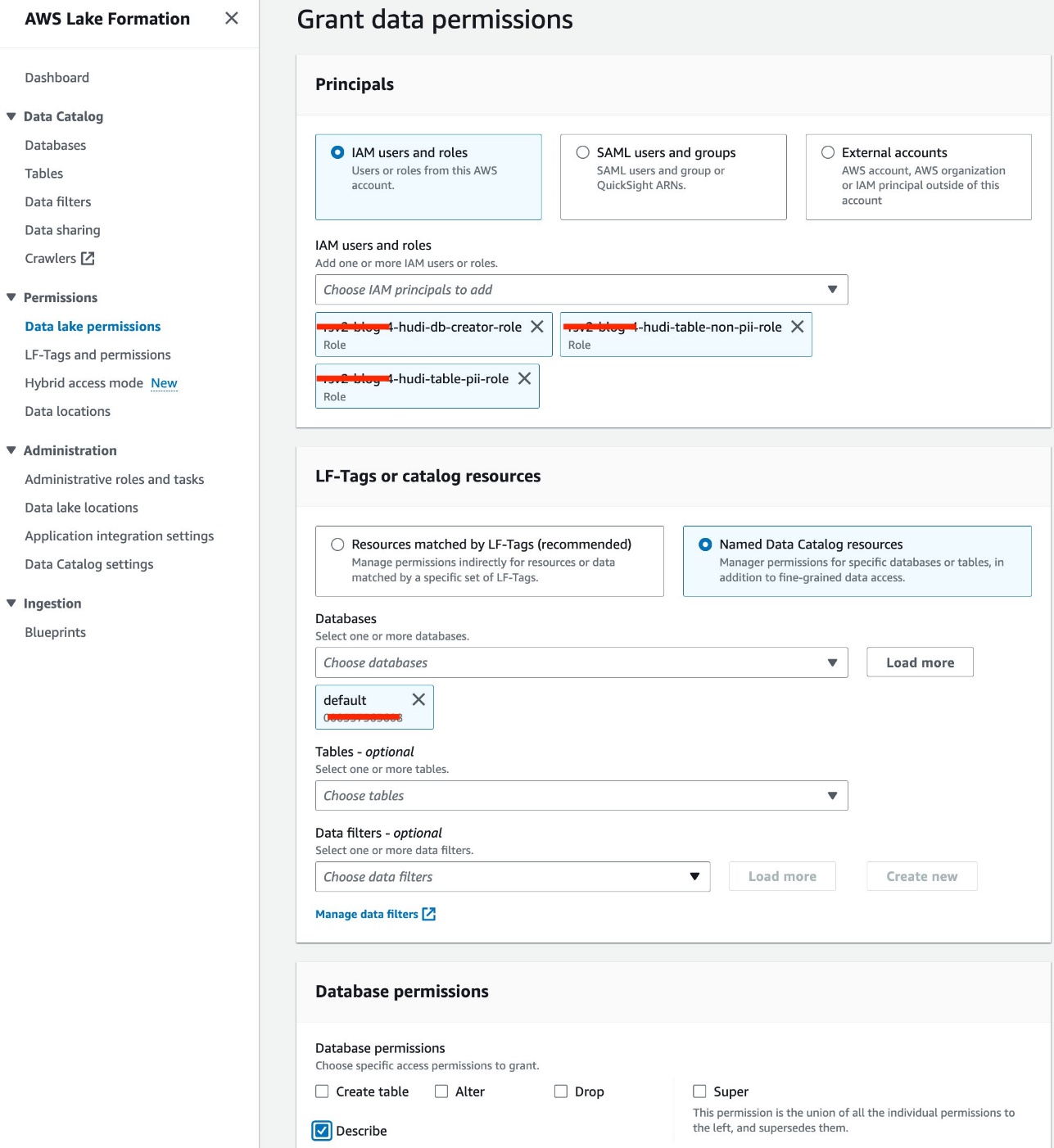
- Вибирати Дозволи озера даних при Дозволи у навігаційній панелі.
- Вибирати Грант.
- Select Користувачі та ролі IAM.
- Виберіть ролі IAM.
- для Бази даних, виберіть за замовчуванням.
- для Дозволи до бази данихвиберіть Описувати.
- Вибирати Грант.
Скопіюйте файл Hudi JAR в Amazon EMR HDFS
До використовувати Hudi з блокнотами Jupyter, вам потрібно виконати такі кроки для кластера EMR, включаючи копіювання файлу JAR Hudi з локального каталогу Amazon EMR до його сховища HDFS, щоб ви могли налаштувати сеанс Spark для використання Hudi:
- Авторизувати вхідний трафік SSH (порт 22).
- Скопіюйте значення для Загальнодоступний DNS основного вузла (наприклад, ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) із кластера EMR Підсумки .
- Поверніться до попереднього терміналу AWS Cloud9, який ви використовували для створення пари ключів EC2.
- Виконайте наведену нижче команду для SSH на основному вузлі EMR. Замініть покажчик місця заповнення своїм іменем хоста EMR DNS:
- Виконайте таку команду, щоб скопіювати файл Hudi JAR до HDFS:
Створіть базу даних Hudi і таблиці в Lake Formation
Тепер ми готові створити базу даних Hudi та таблиці з FGAC, увімкненим роллю середовища виконання EMR. The Роль середовища виконання EMR це роль IAM, яку можна вказати, коли ви надсилаєте завдання чи запит до кластера EMR.
Надайте дозвіл творцю бази даних
По-перше, давайте надамо дозвіл творцю бази даних Lake Formation<STACK-NAME>-hudi-db-creator-role:
- Увійдіть у свій обліковий запис AWS як адміністратор.
- На консолі Lake Formation виберіть Адміністративні ролі та завдання при адміністрація у навігаційній панелі.
- Переконайтеся, що вашого користувача для входу в AWS додано як адміністратора озера даних.
- У Творець бази даних розділ, вибрати Грант.
- для Користувачі та ролі IAMвиберіть
<STACK-NAME>-hudi-db-creator-role. - для Дозволи каталогувиберіть Create database.
- Вибирати Грант.
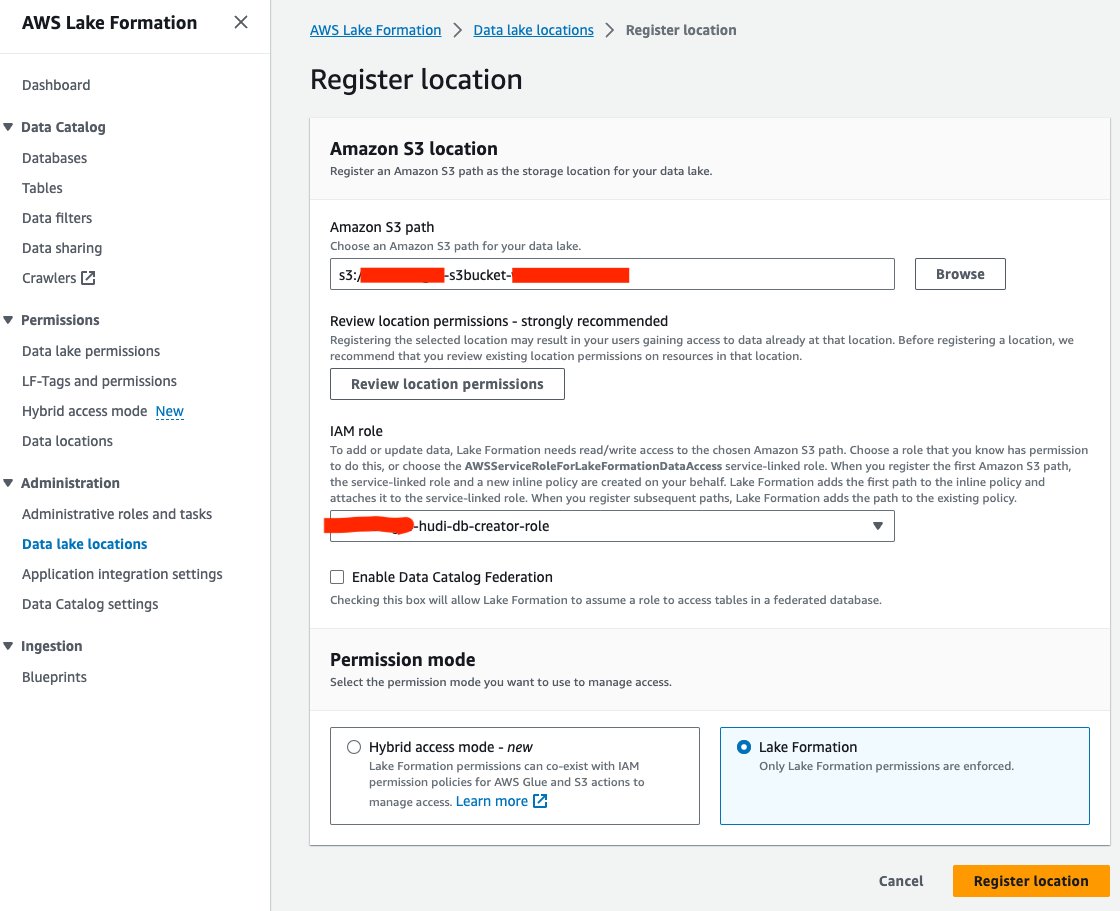
Зареєструйте розташування озера даних
Далі давайте зареєструємо розташування озера даних S3 у Формації озера:
- На консолі Lake Formation виберіть Розташування озера даних при адміністрація у навігаційній панелі.
- Вибирати Зареєструвати місцезнаходження.
- для Шлях Amazon S3, Виберіть перегорнути і виберіть відро озера даних S3. (
<STACK_NAME>s3bucket-XXXXXXX), створений зі стеку CloudFormation. - для Роль IAMвиберіть
<STACK-NAME>-hudi-db-creator-role. - для Режим дозволувиберіть Формування озера.
- Вибирати Зареєструвати місцезнаходження.
Надати дозвіл на місцезнаходження даних
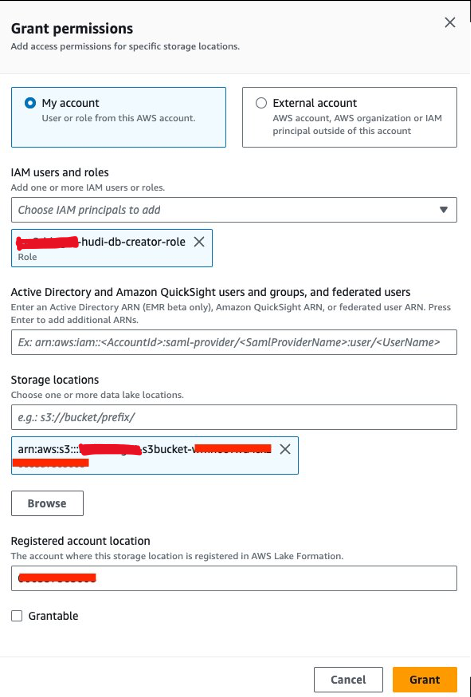
Далі нам потрібно надати грант<STACK-NAME>-hudi-db-creator-roleдозвіл на розташування даних:
- На консолі Lake Formation виберіть Розташування даних при Дозволи у навігаційній панелі.
- Вибирати Грант.
- для Користувачі та ролі IAMвиберіть
<STACK-NAME>-hudi-db-creator-role. - для Місця зберігання, увійдіть у відро S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - Вибирати Грант.
Підключіться до кластера EMR
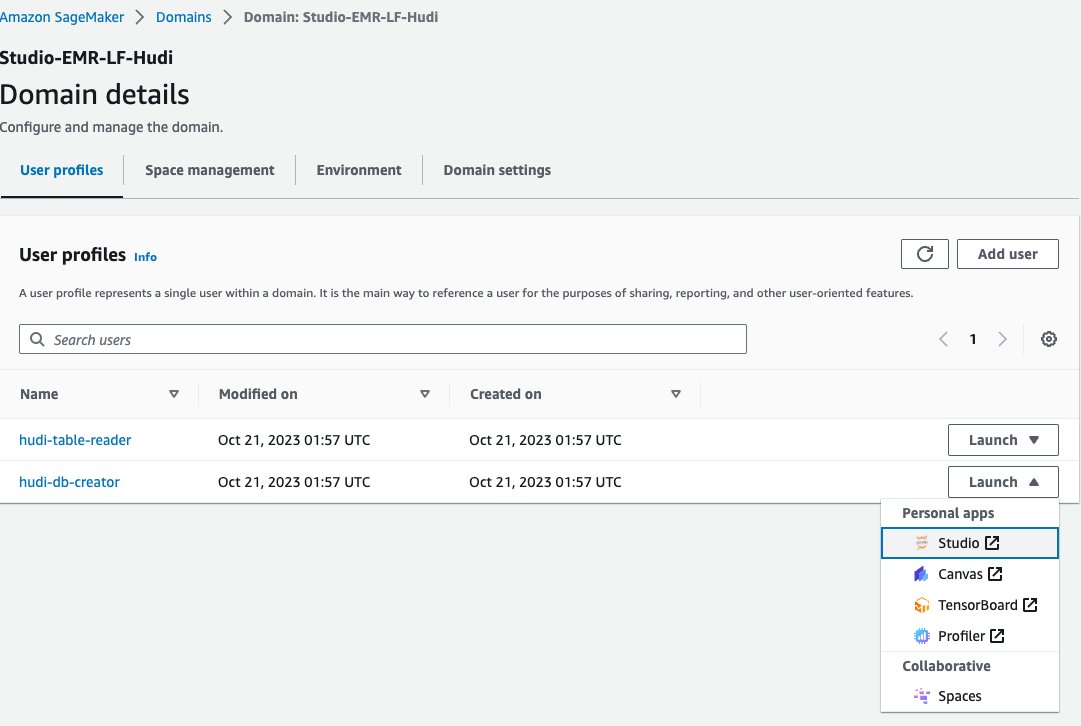
Тепер давайте використаємо блокнот Jupyter у SageMaker Studio для підключення до кластера EMR із роллю середовища виконання EMR творця бази даних:
- На консолі SageMaker виберіть Домени у навігаційній панелі.
- Виберіть домен
<STACK-NAME>-Studio-EMR-LF-Hudi. - на Запуск меню поруч із профілем користувача
<STACK-NAME>-hudi-db-creatorвиберіть Studio.
- Завантажте зошит rsv2-hudi-db-creator-notebook.
- Виберіть піктограму завантаження.
- Виберіть завантажений блокнот Jupyter і виберіть відкритий.
- Відкрийте завантажений блокнот.
- для зображеннявиберіть SparkMagic.
- для Ядровиберіть PySpark.
- Залиште інші налаштування за замовчуванням і виберіть Select.
- Вибирати кластер для підключення до кластера EMR.

- Виберіть EMR на кластері EC2 (
<STACK-NAME>-EMR-Cluster), створений за допомогою стека CloudFormation. - Вибирати З'єднуватися.
- для Роль виконання EMRвиберіть
<STACK-NAME>-hudi-db-creator-role. - Вибирати З'єднуватися.
Створення бази даних і таблиць
Тепер ви можете виконувати кроки в блокноті, щоб створити базу даних і таблиці Hudi. Основні кроки такі:
- Коли ви запускаєте блокнот, налаштуйте
“spark.sql.catalog.spark_catalog.lf.managed":"true"щоб повідомити Spark, що spark_catalog захищено Lake Formation. - Створіть таблиці Hudi за допомогою наступного Spark SQL.
- Вставте дані з вихідної таблиці в таблиці Hudi.
- Знову вставте дані в таблиці Hudi.
Запитуйте таблиці Hudi через Lake Formation за допомогою FGAC
Створивши базу даних і таблиці Hudi, ви готові надсилати запити до таблиць за допомогою детального контролю доступу за допомогою Lake Formation. Ми створили два типи таблиць Hudi: Copy-On-Write (COW) і Merge-On-Read (MOR). Таблиця COW зберігає дані у форматі стовпців (Parquet), і кожне оновлення створює нову версію файлів під час запису. Це означає, що для кожного оновлення Hudi перезаписує весь файл, що може потребувати більше ресурсів, але забезпечує швидше читання. MOR, з іншого боку, вводиться для випадків, коли COW може бути неоптимальним, особливо для великих робочих навантажень, пов’язаних із записом або зміною. У таблиці MOR щоразу, коли відбувається оновлення, Hudi записує лише рядок для зміненого запису, що зменшує вартість і забезпечує запис із низькою затримкою. Однак швидкість читання може бути нижчою порівняно з таблицями COW.
Надати дозвіл на доступ до таблиці
Ми використовуємо роль IAM<STACK-NAME>-hudi-table-pii-roleдля запиту Hudi COW і MOR, що містять стовпці ідентифікаційної інформації. Спочатку ми надаємо дозвіл на доступ до таблиці через Lake Formation:
- На консолі Lake Formation виберіть Дозволи озера даних при Дозволи у навігаційній панелі.
- Вибирати Грант.
- Вибирати
<STACK-NAME>-hudi-table-pii-roleта цінності Користувачі та ролі IAM. - Виберіть
rsv2_blog_hudi_db_1база даних для Бази даних. - для таблиці, виберіть чотири таблиці Hudi, які ви створили в блокноті Jupyter.
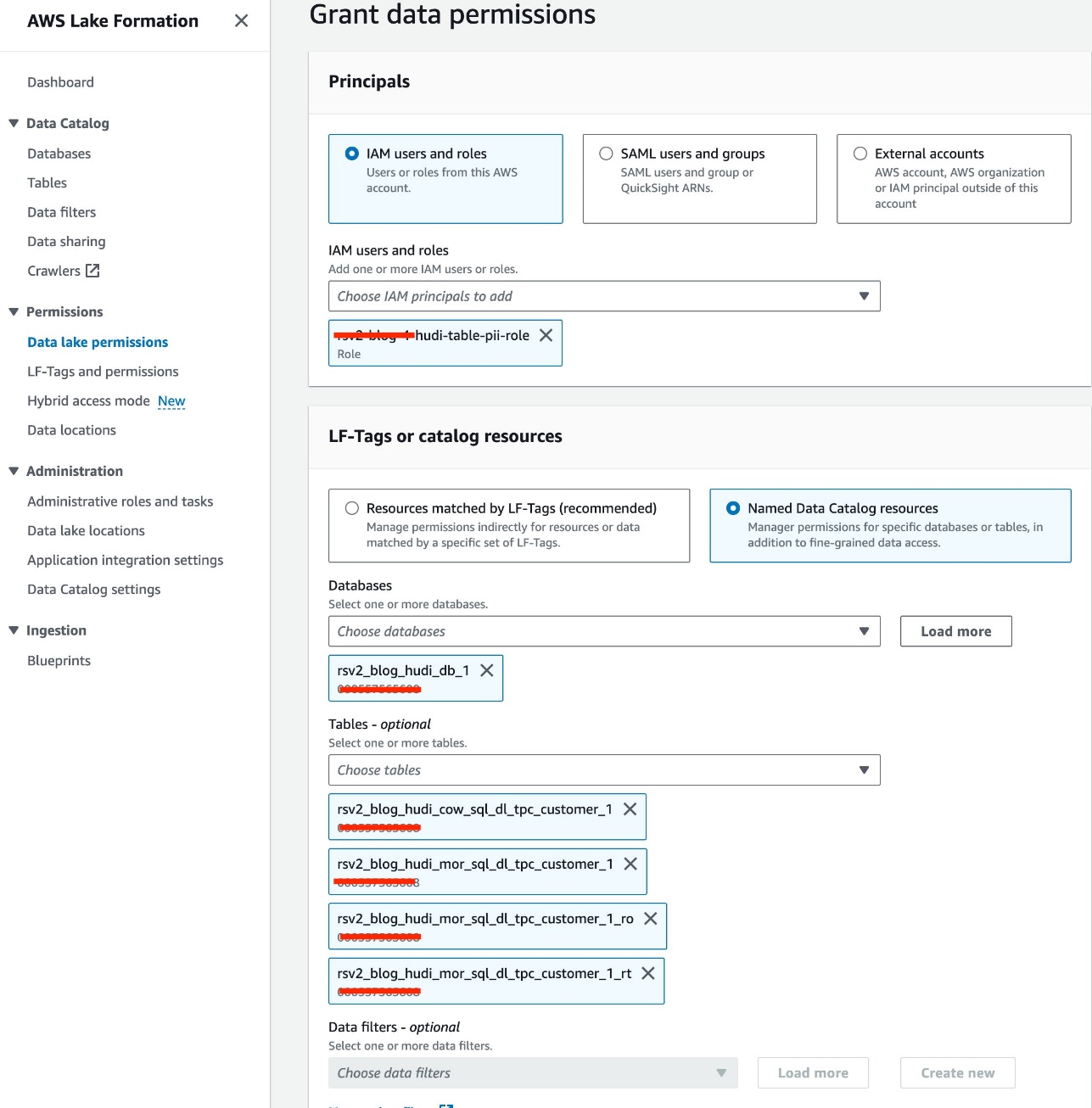
- для Дозволи для таблицівиберіть Select.
- Вибирати Грант.
Стовпці запиту ідентифікаційної інформації
Тепер ви готові запустити блокнот для запиту таблиць Hudi. Виконайте кроки, подібні до попереднього розділу, щоб запустити блокнот у SageMaker Studio:
- На консолі SageMaker перейдіть до
<STACK-NAME>-Studio-EMR-LF-Hudiдомен - на Запуск меню поруч із
<STACK-NAME>-hudi-table-readerпрофіль користувача, виберіть Studio. - Завантажте завантажений блокнот rsv2-hudi-table-pii-reader-notebook.
- Відкрийте завантажений блокнот.
- Повторіть кроки налаштування блокнота та підключіться до того самого кластера EMR, але використовуйте роль
<STACK-NAME>-hudi-table-pii-role.
На поточному етапі кластер EMR із підтримкою FGAC має запитувати стовпець часу фіксації Hudi для виконання додаткових запитів і подорожі в часі. Він не підтримує синтаксис Spark «timestamp as of». Spark.read(). Ми активно працюємо над інтеграцією підтримки обох дій у майбутні випуски Amazon EMR із увімкненим FGAC.
Тепер ви можете виконувати кроки в зошиті. Нижче наведено кілька виділених кроків.
- Запустіть запит на знімок.
- Запустіть інкрементний запит.
- Виконайте запит подорожі в часі.
- Виконуйте запити до таблиць MOR, оптимізовані для читання та в реальному часі.
Запитуйте таблиці Hudi за допомогою фільтрів даних на рівні стовпців і рядків
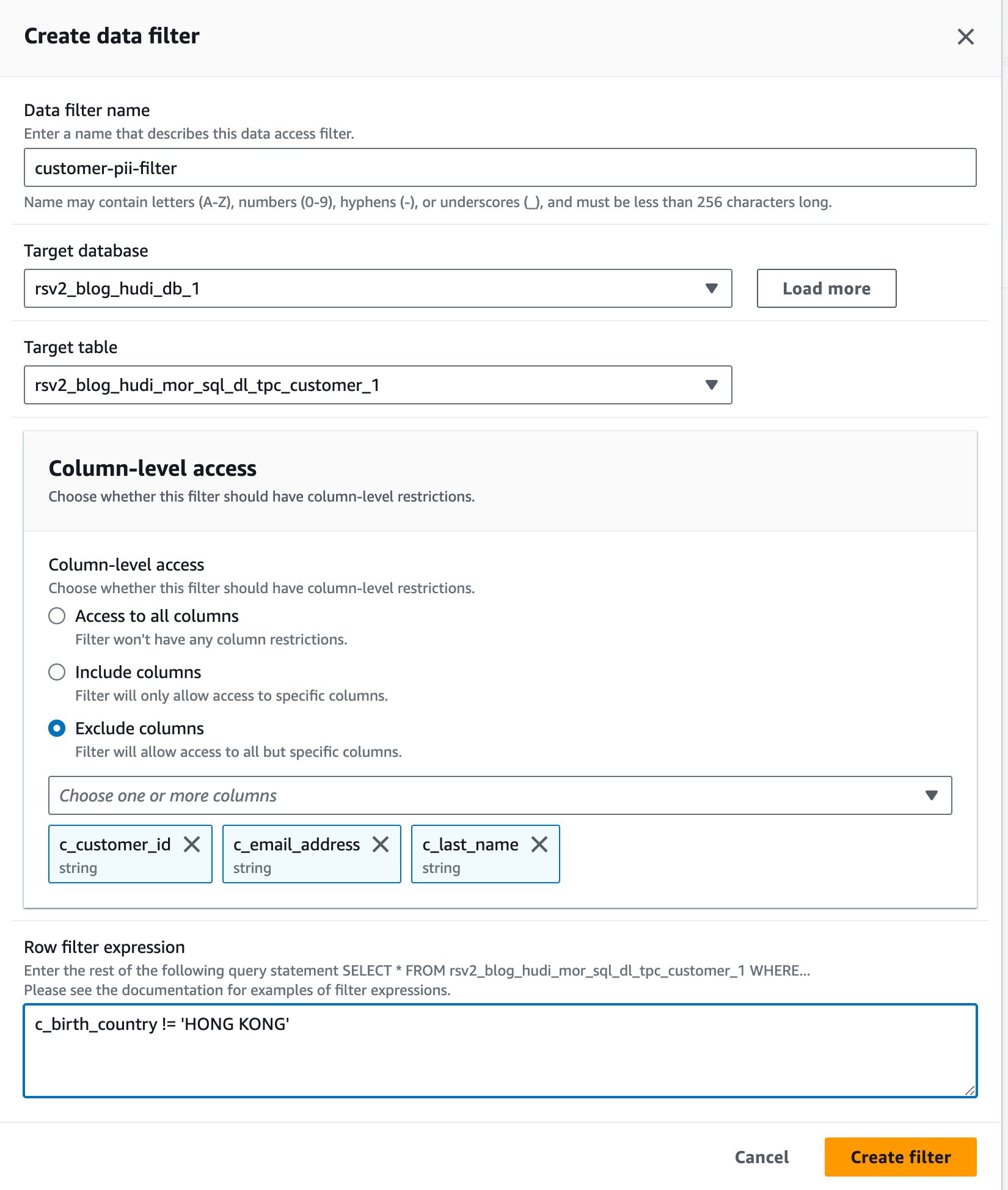
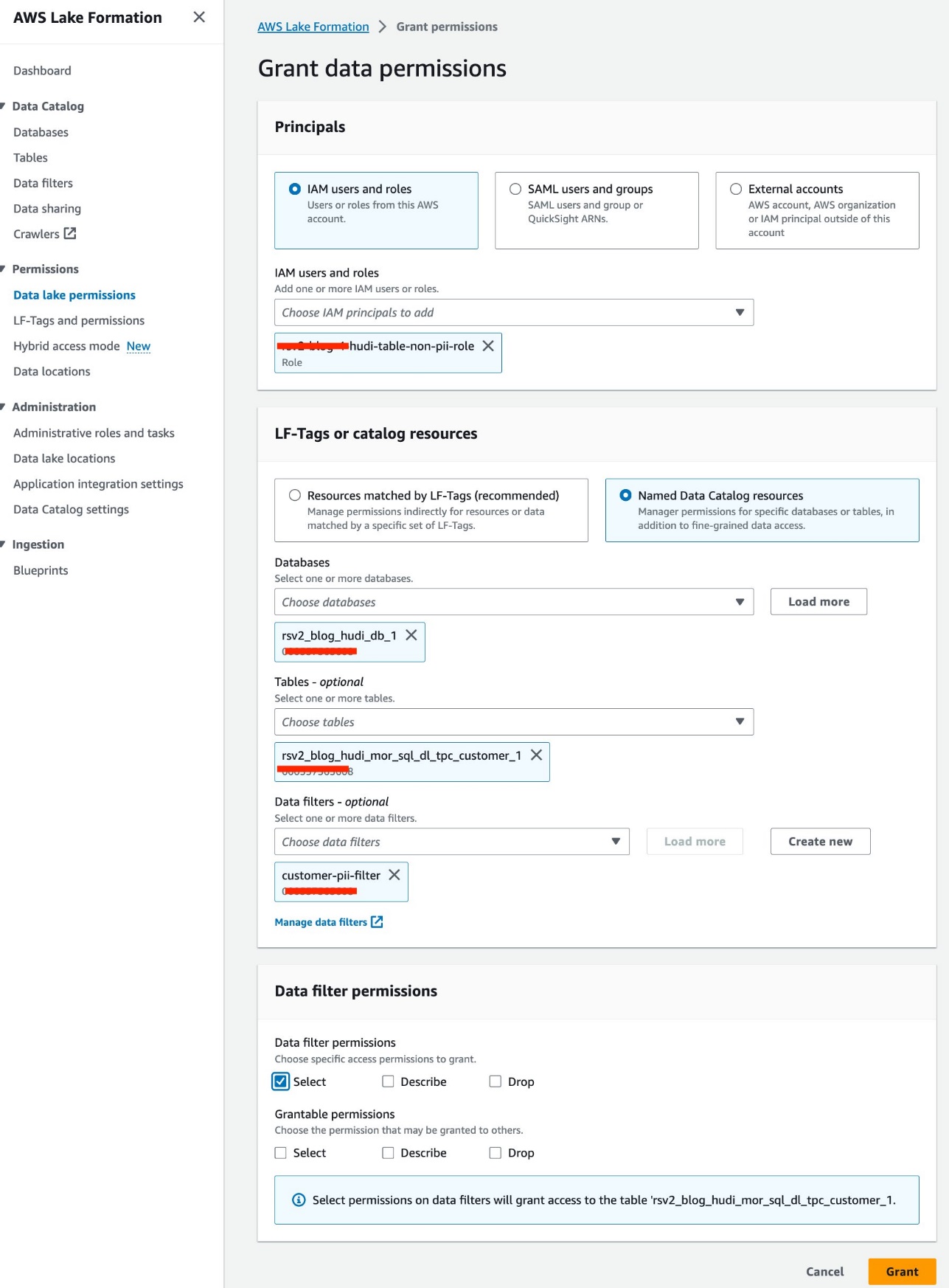
Ми використовуємо роль IAM<STACK-NAME>-hudi-table-non-pii-roleдля запиту таблиць Hudi. Ця роль не має права запитувати жодні стовпці, що містять ідентифікаційну інформацію. Ми використовуємо фільтри даних на рівні стовпців і рядків Lake Formation для реалізації детального контролю доступу:
- На консолі Lake Formation виберіть Фільтри даних при Каталог даних у навігаційній панелі.
- Вибирати Створити новий фільтр.
- для Назва фільтра даних, введіть
customer-pii-filter. - Вибирати
rsv2_blog_hudi_db_1та цінності Цільова база даних. - Вибирати
rsv2_blog_hudi_mor_sql_dl_customer_1та цінності Цільова таблиця. - Select Виключити стовпці і оберіть
c_customer_id,c_email_addressтаc_last_nameстовпчики. -
Що натомість? Створіть віртуальну версію себе у
c_birth_country != 'HONG KONG'та цінності Вираз фільтра рядка. - Вибирати Створіть фільтр.
- Вибирати Дозволи озера даних при Дозволи у навігаційній панелі.
- Вибирати Грант.
- Вибирати
<STACK-NAME>-hudi-table-non-pii-roleта цінності Користувачі та ролі IAM. - Вибирати
rsv2_blog_hudi_db_1та цінності Бази даних. - Вибирати
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1та цінності таблиці. - Вибирати
customer-pii-filterта цінності Фільтри даних. - для Дозволи фільтра данихвиберіть Select.
- Вибирати Грант.
Давайте виконаємо подібні кроки, щоб запустити блокнот у SageMaker Studio:
- На консолі SageMaker перейдіть до домену
Studio-EMR-LF-Hudi. - на Запуск меню для
hudi-table-readerпрофіль користувача, виберіть Studio. - Завантажте завантажений блокнот rsv2-hudi-table-non-pii-reader-notebook І вибирай відкритий.
- Повторіть кроки налаштування блокнота та підключіться до того самого кластера EMR, але виберіть роль
<STACK-NAME>-hudi-table-non-pii-role.
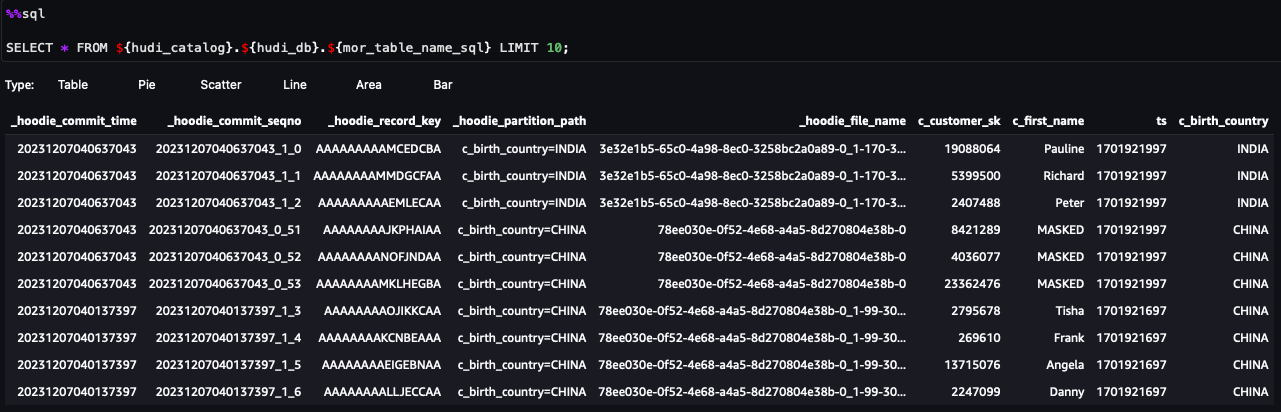
Тепер ви можете виконувати кроки в зошиті. З результатів запиту ви можете побачити, що застосовано FGAC через фільтр даних Lake Formation. Роль не може бачити стовпці ідентифікаційної інформаціїc_customer_id,c_last_name та c_email_address. Також ряди зHONG KONGбули відфільтровані.
Прибирати
Коли ви закінчите експериментувати з рішенням, ми рекомендуємо очистити ресурси, виконавши наведені нижче дії, щоб уникнути неочікуваних витрат:
- Закрийте програми SageMaker Studio для профілів користувачів.
Кластер EMR буде автоматично видалено після закінчення часу очікування.
- Видалити Еластична файлова система Amazon Том (Amazon EFS), створений для домену.
- Спорожніть відра S3 створений стеком CloudFormation.
- На консолі AWS CloudFormation видаліть стек.
Висновок
У цій публікації ми використали Apachi Hudi, один із типів таблиць OTF, щоб продемонструвати цю нову функцію для забезпечення детального контролю доступу до Amazon EMR. Ви можете визначити детальні дозволи в Lake Formation для таблиць OTF і застосувати їх за допомогою запитів Spark SQL до кластерів EMR. Ви також можете використовувати такі функції транзакційного озера даних, як запуск запитів на знімки, інкрементні запити, подорожі в часі та запити DML. Зверніть увагу, що ця нова функція охоплює всі таблиці OTF.
Ця функція запущена, починаючи з версії Amazon EMR 6.15 райони де доступний Amazon EMR. Завдяки інтеграції Amazon EMR із Lake Formation ви можете впевнено керувати великими даними та обробляти їх, відкриваючи аналітику та сприяючи прийняттю обґрунтованих рішень, зберігаючи при цьому безпеку даних і управління.
Щоб дізнатися більше, див Увімкніть утворення озер за допомогою Amazon EMR і не соромтеся зв’язатися зі своїми архітекторами рішень AWS, які можуть допомогти вам у подорожі з даними.
Про автора
 Раймонд Лай є старшим архітектором рішень, який спеціалізується на обслуговуванні потреб великих корпоративних клієнтів. Його досвід полягає в наданні допомоги клієнтам у перенесенні складних корпоративних систем і баз даних на AWS, створенні корпоративних сховищ даних і платформ озер даних. Реймонд чудово справляється з визначенням і розробкою рішень для випадків використання AI/ML, і він приділяє особливу увагу безсерверним рішенням AWS і розробці архітектури, керованої подіями.
Раймонд Лай є старшим архітектором рішень, який спеціалізується на обслуговуванні потреб великих корпоративних клієнтів. Його досвід полягає в наданні допомоги клієнтам у перенесенні складних корпоративних систем і баз даних на AWS, створенні корпоративних сховищ даних і платформ озер даних. Реймонд чудово справляється з визначенням і розробкою рішень для випадків використання AI/ML, і він приділяє особливу увагу безсерверним рішенням AWS і розробці архітектури, керованої подіями.
 Бін Ван, PhD, є старшим аналітичним фахівцем, архітектором рішень в AWS, має понад 12 років досвіду роботи в індустрії машинного навчання, приділяючи особливу увагу рекламі. Він володіє досвідом обробки природної мови (NLP), систем рекомендацій, різноманітних алгоритмів ML та операцій ML. Він глибоко захоплений застосуванням ML/DL і методів великих даних для вирішення проблем реального світу.
Бін Ван, PhD, є старшим аналітичним фахівцем, архітектором рішень в AWS, має понад 12 років досвіду роботи в індустрії машинного навчання, приділяючи особливу увагу рекламі. Він володіє досвідом обробки природної мови (NLP), систем рекомендацій, різноманітних алгоритмів ML та операцій ML. Він глибоко захоплений застосуванням ML/DL і методів великих даних для вирішення проблем реального світу.
 Адітя Шах є інженером з розробки програмного забезпечення в AWS. Він цікавиться базами даних і двигунами сховищ даних і працював над оптимізацією продуктивності, відповідністю вимогам безпеки та ACID для механізмів, таких як Apache Hive і Apache Spark.
Адітя Шах є інженером з розробки програмного забезпечення в AWS. Він цікавиться базами даних і двигунами сховищ даних і працював над оптимізацією продуктивності, відповідністю вимогам безпеки та ACID для механізмів, таких як Apache Hive і Apache Spark.
 Мелодія Ян є старшим архітектором рішень для великих даних для Amazon EMR в AWS. Вона є досвідченим аналітичним лідером, який працює з клієнтами AWS, щоб надати рекомендації з найкращої практики та технічні поради, щоб допомогти їм досягти успіху в трансформації даних. Сфери її інтересів – фреймворки та автоматизація з відкритим кодом, інженерія даних та DataOps.
Мелодія Ян є старшим архітектором рішень для великих даних для Amazon EMR в AWS. Вона є досвідченим аналітичним лідером, який працює з клієнтами AWS, щоб надати рекомендації з найкращої практики та технічні поради, щоб допомогти їм досягти успіху в трансформації даних. Сфери її інтересів – фреймворки та автоматизація з відкритим кодом, інженерія даних та DataOps.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- МЕНЮ
- доступ
- рахунки
- визнавати
- дії
- активно
- доданий
- Додатково
- адреси
- адмін
- Адміністратори
- реклама
- рада
- після
- знову
- AI / ML
- алгоритми
- ВСІ
- дозволяти
- дозволено
- дозволяє
- пліч-о-пліч
- Також
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- аналіз
- аналітики
- Аналітичний
- аналітика
- Аналізуючи
- та
- будь-який
- Apache
- Apache Spark
- додаток
- прикладної
- Застосовувати
- Застосування
- архітектори
- архітектура
- ЕСТЬ
- області
- навколо
- AS
- допомогу
- Допомога
- допомагати
- припустити
- At
- аудит
- влада
- уповноважений
- автоматично
- Автоматизація
- доступний
- уникнути
- AWS
- AWS Cloud9
- AWS CloudFormation
- Формування озера AWS
- назад
- заснований
- BE
- було
- за
- буття
- Переваги
- крім
- КРАЩЕ
- Великий
- Великий даних
- блоги
- хвастощі
- обидва
- будувати
- але
- by
- CA
- CAN
- здатний
- нести
- проведення
- випадок
- випадків
- каталог
- громадське харчування
- певний
- сертифікат
- сертифікати
- сертифікація
- зміна
- змінилися
- Зміни
- Китай
- Вибирати
- Очищення
- Cloud9
- кластер
- код
- Колонка
- Колони
- COM
- поєднання
- commit
- Компанії
- порівняний
- повний
- дотримання
- компонент
- Компоненти
- обчислення
- комп'ютер
- концепція
- Умови
- Проводити
- впевнено
- конфігурація
- З'єднуватися
- Консоль
- будівництво
- контакт
- містити
- містить
- контроль
- контроль
- управління
- копіювання
- Відповідний
- Коштувати
- витрати
- країна
- охоплює
- створювати
- створений
- створює
- створення
- творець
- Поточний
- виготовлений на замовлення
- Клієнти
- дані
- доступ до даних
- аналіз даних
- Озеро даних
- Платформа даних
- конфіденційність даних
- обробка даних
- безпеку даних
- сховище даних
- Database
- базами даних
- Прийняття рішень
- глибоко
- дефолт
- визначати
- Дельта
- демонструвати
- демонстрація
- розгортання
- розгортання
- дизайн
- проектування
- деталі
- розробка
- різний
- чіткий
- Різне
- DNS
- do
- робить
- Ні
- домен
- зроблений
- Не знаю
- вниз
- скачати
- керований
- під час
- кожен
- ще
- включіть
- включений
- дозволяє
- шифрування
- кінець
- кінцеві точки
- примусове виконання
- двигун
- інженер
- Машинобудування
- Двигуни
- забезпечувати
- гарантує
- забезпечення
- Що натомість? Створіть віртуальну версію себе у
- підприємство
- корпоративні клієнти
- Весь
- Навколишнє середовище
- Ефір (ETH)
- Event
- Кожен
- приклад
- виконання
- існує
- досвід
- досвідчений
- експертиза
- дослідження
- продовжується
- зовнішній
- сприяння
- швидше
- особливість
- риси
- почувати
- філе
- Файли
- фільтрувати
- фільтрація
- Фільтри
- Перший
- Сфокусувати
- фокусується
- стежити
- після
- слідує
- для
- формат
- освіта
- чотири
- Рамки
- каркаси
- Безкоштовна
- від
- Виконати
- Повний
- функціональність
- далі
- майбутнє
- Отримувати
- генерується
- управління
- управляється
- надавати
- значно
- Group
- Групи
- керівництво
- рука
- Мати
- he
- її
- тут
- Виділено
- його
- історичний
- історія
- Вулик
- Гонконг
- Гонконг
- будинок
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- IAM
- ICON
- ID
- ідея
- ідентифікувати
- ідентифікує
- Idle
- if
- ілюструє
- здійснювати
- удосконалювати
- in
- includes
- У тому числі
- включення
- зростаючий
- Індію
- промисловість
- повідомити
- інформація
- повідомив
- вхід
- розуміння
- інтегрований
- Інтеграція
- інтеграція
- інтерактивний
- зацікавлений
- інтереси
- інтерфейс
- внутрішній
- в
- складний
- введені
- Вводить
- питання
- IT
- ЙОГО
- робота
- Джобс
- подорож
- JPG
- Jupyter Notebook
- ключ
- Гонконг
- озеро
- мова
- великий
- останній
- запуск
- запущений
- лідер
- УЧИТЬСЯ
- рівні
- лежить
- як
- МЕЖА
- ліній
- місцевий
- розташування
- місць
- Логін
- основний
- зробити
- управляти
- вдалося
- управління
- менеджер
- багато
- Може..
- засоби
- механізми
- засідання
- Меню
- метадані
- може бути
- мігруючи
- протокол
- ML
- Алгоритми ML
- модифікований
- більше
- руху
- ім'я
- Імена
- Природний
- Природна мова
- Обробка природних мов
- Переміщення
- навігація
- Необхідність
- потреби
- Нові
- Нова функція
- нещодавно
- наступний
- nlp
- вузол
- увагу
- ноутбук
- ноутбуки
- зараз
- об'єкти
- of
- часто
- on
- ONE
- тільки
- відкрити
- з відкритим вихідним кодом
- OpenSSL
- операції
- оптимальний
- Оптимізувати
- варіант
- Опції
- or
- порядок
- організація
- Інше
- з
- над
- пара
- pane
- приватність
- особливо
- пристрасний
- платіж
- продуктивність
- виконанні
- дозвіл
- Дозволи
- Особисто
- Вчений ступінь
- пій
- заповнювач
- платформа
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- будь ласка
- плюс
- точок
- популярний
- володіє
- пошта
- практика
- консервування
- попередній
- первинний
- недоторканність приватного життя
- привілей
- привілеї
- проблеми
- процес
- обробка
- Production
- профіль
- Профілі
- доказ
- доказ концепції
- захищений
- захист
- забезпечувати
- забезпечує
- забезпечення
- громадськість
- цілей
- запити
- Читати
- читання
- готовий
- Реальний світ
- реального часу
- рекомендувати
- запис
- відновлення
- знижує
- зниження
- послатися
- відноситься
- Відображає
- регіон
- реєструвати
- зареєстрований
- правила
- звільнити
- Релізи
- доречний
- замінювати
- вимагається
- Вимога
- ресурс
- ресурсомісткий
- ресурси
- результат
- результати
- праві
- Роль
- ролі
- ROW
- RSA
- Правила
- прогін
- біг
- мудрець
- то ж
- зберегти
- розділ
- безпечний
- Забезпечений
- безпеку
- побачити
- Шукати
- вибрати
- старший
- чутливий
- сервер
- Без сервера
- Послуги
- Сесія
- комплект
- набори
- налаштування
- установка
- вона
- підпис
- істотно
- аналогічний
- простий
- спрощує
- спростити
- з
- Знімок
- So
- Софтвер
- розробка програмного забезпечення
- рішення
- Рішення
- ВИРІШИТИ
- деякі
- Source
- Іскритися
- спеціаліст
- спеціалізується
- SQL
- стек
- Стажування
- старт
- почалася
- Починаючи
- заяви
- заходи
- зберігання
- магазинів
- Стратегія
- рядок
- студія
- представляти
- підмережі
- успіх
- такі
- РЕЗЮМЕ
- підтримка
- Опори
- Переконайтеся
- синтаксис
- Systems
- таблиця
- TAG
- приймає
- технічний
- методи
- шаблон
- термінал
- Що
- Команда
- Джерело
- їх
- Їх
- потім
- Там.
- Ці
- вони
- це
- три
- через
- час
- подорож у часі
- Терміни
- до
- Відстеження
- угода
- транзакційний
- Перетворення
- транзит
- подорожувати
- правда
- Довірений
- Ts
- два
- тип
- Типи
- ui
- при
- Unexpected
- невідомий
- розблокування
- Оновити
- оновлений
- відстоювання
- завантажено
- URI
- використання
- використання випадку
- використовуваний
- користувач
- користувачі
- використання
- перевіряє
- значення
- різний
- версія
- через
- видимість
- обсяг
- Склад
- Складування
- we
- Web
- веб-сервіси
- коли
- в той час як
- який
- в той час як
- ВООЗ
- волі
- з
- в
- працював
- робочий
- запис
- років
- ви
- вашу
- зефірнет
- нуль
- Zip