Амазонська червона зміна це швидке, повністю кероване петабайтне хмарне сховище даних, яке дозволяє легко та економічно ефективно аналізувати всі ваші дані за допомогою стандартного SQL та наявних інструментів бізнес-аналітики (BI). Сьогодні десятки тисяч клієнтів використовують Amazon Redshift для аналізу ексабайтів даних і виконання аналітичних запитів, що робить його найпоширенішим хмарним сховищем даних. Amazon Redshift доступний як у безсерверній, так і в ініціалізованій конфігурації.
Amazon Redshift дає вам прямий доступ до даних, які зберігаються в Служба простого зберігання Amazon (Amazon S3) за допомогою запитів SQL і об’єднання даних у вашому сховищі даних і озері даних. За допомогою Amazon Redshift ви можете запитувати дані у своєму озері даних S3 за допомогою центрального центру Клей AWS metastore із вашого сховища даних Redshift.
Amazon Redshift підтримує запити до різноманітних форматів даних, таких як CSV, JSON, Parquet і ORC, а також форматів таблиць, таких як Apache Hudi та Delta. Amazon Redshift також підтримує запити вкладених даних зі складними типами даних, як-от структура, масив і карта.
Завдяки цій можливості Amazon Redshift розширює ваше петабайтне сховище даних до ексабайтного озера даних на Amazon S3 економічно ефективним способом.
Apache Iceberg — це найновіший формат таблиці, який зараз підтримується в попередній версії Amazon Redshift. У цій публікації ми покажемо вам, як надсилати запити до таблиць Iceberg за допомогою Amazon Redshift, а також ознайомимося з підтримкою та параметрами Iceberg.
Огляд рішення
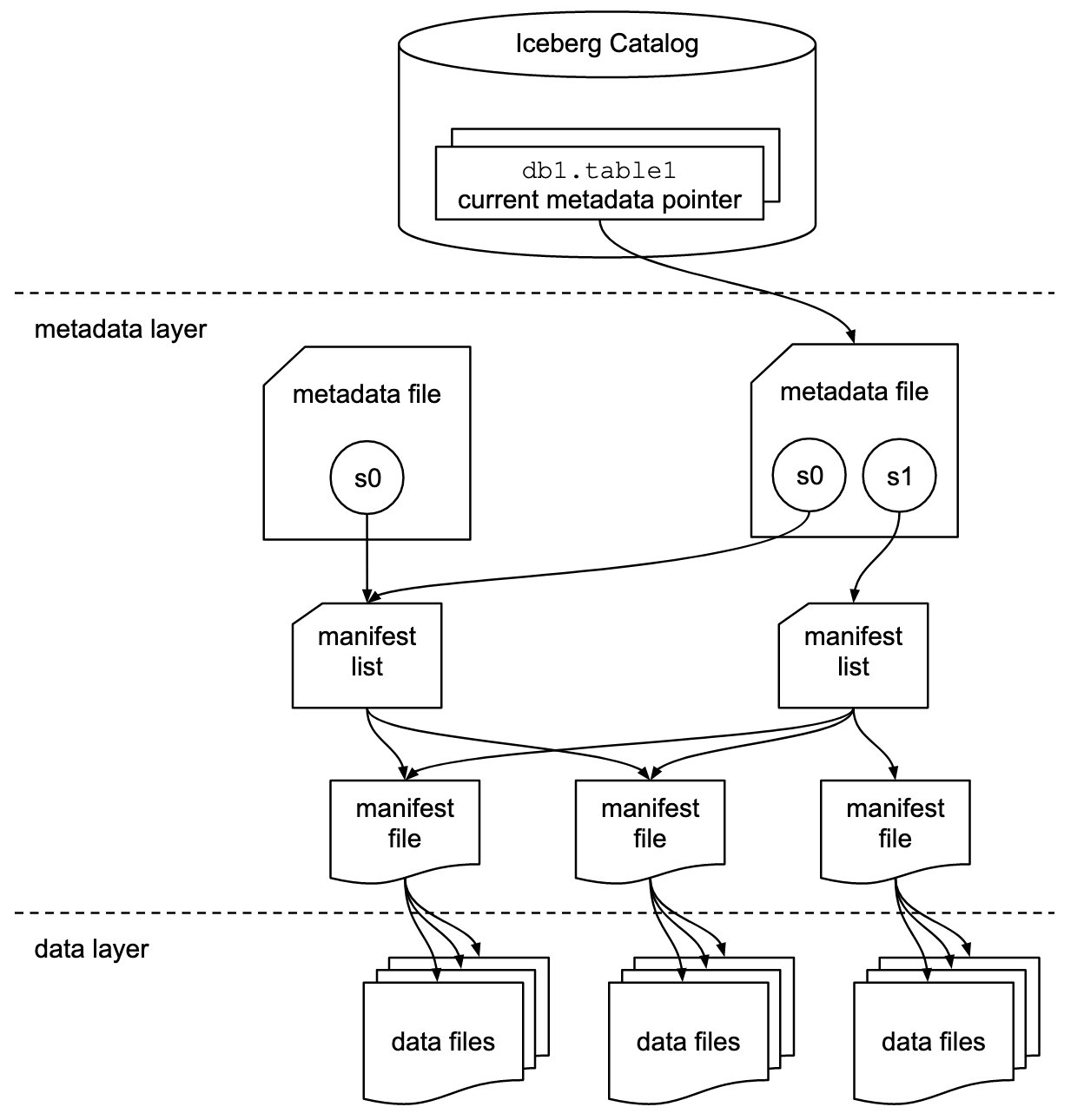
Айсберг Апач це формат відкритої таблиці для дуже великих аналітичних наборів даних у петабайтах. Iceberg керує великими колекціями файлів у вигляді таблиць і підтримує сучасні аналітичні операції озера даних, такі як запити на вставку, оновлення, видалення та подорожі в часі на рівні записів. Специфікація Iceberg дозволяє безперебійну еволюцію таблиць, наприклад еволюцію схем і розділів, а її дизайн оптимізовано для використання на Amazon S3.
Iceberg зберігає покажчик метаданих для всіх файлів метаданих. Коли запит SELECT читає таблицю Iceberg, система запитів спочатку переходить до каталогу Iceberg, а потім отримує запис про розташування останнього файлу метаданих, як показано на наступній схемі.
Тепер Amazon Redshift підтримує таблиці Apache Iceberg, що дозволяє клієнтам озера даних виконувати аналітичні запити лише для читання узгодженим способом. Це дає змогу легко керувати своїми таблицями в озерах транзакційних даних і підтримувати їх.
Amazon Redshift підтримує власну схему Apache Iceberg і можливості еволюції розділів за допомогою Каталог даних AWS Glue, усуваючи потребу змінювати визначення таблиць для додавання нових розділів або переміщення та обробки великих обсягів даних для зміни схеми існуючої таблиці озера даних. Amazon Redshift використовує статистику стовпців, що зберігається в метаданих таблиці Apache Iceberg, щоб оптимізувати свої плани запитів і зменшити кількість сканувань файлів, необхідних для виконання запитів.
У цій публікації ми використовуємо Загальнодоступний набір даних жовтого таксі від NYC Taxi & Limousine Commission як наші вихідні дані. Набір даних містить файли даних у Паркет Apache формат на Amazon S3. Ми використовуємо Амазонка Афіна щоб перетворити цей набір даних Parquet, а потім використовувати Спектр червоного зсуву Amazon надсилати запити та об’єднуватися з локальною таблицею Redshift, виконувати видалення та оновлення на рівні рядків і еволюцію розділів, усе це координується через каталог даних AWS Glue в озері даних S3.
Передумови
Ви повинні мати такі передумови:
Перетворення даних Parquet на таблицю Iceberg
Для цієї посади вам потрібно Загальнодоступний набір даних жовтого таксі від Комісії з таксі та лімузинів Нью-Йорка доступний у форматі Iceberg. Ви можете завантажити файли, а потім за допомогою Athena перетворити набір даних Parquet на таблицю Iceberg або звернутися до Створіть озеро даних Apache Iceberg за допомогою Amazon Athena, Amazon EMR та AWS Glue допис у блозі для створення таблиці Iceberg.
У цій публікації ми використовуємо Athena для перетворення даних. Виконайте наступні дії:
- Завантажте файли за попереднім посиланням або скористайтеся Інтерфейс командного рядка AWS (AWS CLI), щоб скопіювати файли з загальнодоступного сегмента S3 за 2020 і 2021 роки до вашого сегмента S3 за допомогою такої команди:
Для отримання додаткової інформації зверніться до Налаштування Amazon Redshift CLI.
- Створити базу даних
Icebergdbі створіть таблицю за допомогою Athena, яка вказує на файли формату Parquet, використовуючи такий оператор: - Перевірте дані в таблиці Parquet за допомогою такого SQL:

- Створіть таблицю Iceberg в Athena за допомогою наступного коду. Нижче ви можете побачити властивості типу таблиці як таблиця Iceberg із форматом Parquet і швидким стисненням
create tableзаява. Вам потрібно оновити розташування S3 перед запуском SQL. Також зауважте, що стіл Iceberg розділений на перегородкиYearключ - Після створення таблиці завантажте дані в таблицю Iceberg за допомогою попередньо завантаженої таблиці Parquet
nyc_taxi_yellow_parquetз таким SQL: - Після завершення оператора SQL перевірте дані в таблиці Iceberg
nyc_taxi_yellow_iceberg. Цей крок є обов’язковим перед переходом до наступного кроку. - Ви можете перевірити, що таблиця nyc_taxi_yellow_iceberg знаходиться у форматі таблиці Iceberg і розділена на стовпець Year за допомогою такої команди:



Створіть зовнішню схему в Amazon Redshift
У цьому розділі ми демонструємо, як створити зовнішню схему в Amazon Redshift, яка вказує на базу даних AWS Glue icebergdb щоб запитати таблицю Iceberg nyc_taxi_yellow_iceberg що ми бачили в попередньому розділі за допомогою Athena.
Увійдіть до Redshift через Редактор запитів версії 2 або клієнт SQL і виконайте таку команду (зверніть увагу, що база даних AWS Glue icebergdb і використовується інформація про регіон):

Щоб дізнатися про створення зовнішніх схем в Amazon Redshift, див створити зовнішню схему
Після створення зовнішньої схеми spectrum_iceberg_schema, ви можете запитати таблицю Iceberg в Amazon Redshift.
Запитуйте таблицю Iceberg в Amazon Redshift
Виконайте наступний запит у редакторі запитів v2. Зауважте, що spectrum_iceberg_schema це назва зовнішньої схеми, створеної в Amazon Redshift і nyc_taxi_yellow_iceberg це таблиця в базі даних AWS Glue, яка використовується в запиті:
Дані запиту на наступному знімку екрана показують, що таблицю AWS Glue у форматі Iceberg можна запитувати за допомогою Redshift Spectrum.

Перевірте план пояснення запиту до таблиці Iceberg
Ви можете використати наступний запит, щоб отримати результат пояснення плану, який показує формат ICEBERG:

Перевірте оновлення на узгодженість даних
Після завершення оновлення таблиці Iceberg ви можете надіслати запит Amazon Redshift, щоб переглянути сумісне подання даних у транзакціях. Виконаємо запит, вибравши a vendorid і для певної посадки та висадки:

Далі оновіть значення passenger_count до 4 і trip_distance до 9.4 за vendorid і певні дати посадки та висадки в Афіні:

Нарешті, запустіть такий запит у редакторі запитів v2, щоб побачити оновлене значення passenger_count та trip_distance:
Як показано на наступному знімку екрана, операції оновлення таблиці Iceberg доступні в Amazon Redshift.

Створіть уніфікований перегляд локальної таблиці та історичних даних в Amazon Redshift
Як сучасна стратегія архітектури даних ви можете організувати історичні дані або дані, до яких звертаються рідше, в озері даних і зберігати дані, до яких часто звертаються, у сховищі даних Redshift. Це забезпечує гнучкість керування аналітикою в масштабі та пошуку найбільш економічно ефективного архітектурного рішення.
У цьому прикладі ми завантажуємо дані за 2 роки в таблицю Redshift; решта даних залишається в озері даних S3, оскільки до цього набору даних запитують рідше.
- Використовуйте наступний код, щоб завантажити дані за 2 роки в
nyc_taxi_yellow_recentтаблиця в Amazon Redshift, отримана з таблиці Iceberg:
- Далі ви можете видалити дані за останні 2 роки з таблиці Iceberg за допомогою такої команди в Athena, оскільки ви завантажили дані в таблицю Redshift на попередньому кроці:

Після виконання цих кроків таблиця Redshift містить дані за 2 роки, а решта даних – у таблиці Iceberg в Amazon S3.
- Створіть подання за допомогою
nyc_taxi_yellow_icebergАйсберг стіл іnyc_taxi_yellow_recentтаблиця в Amazon Redshift: - Тепер запитайте перегляд, залежно від умов фільтра, Redshift Spectrum скануватиме дані Iceberg, таблицю Redshift або обидва. Наведений нижче приклад запиту повертає певну кількість записів із кожної з вихідних таблиць шляхом сканування обох таблиць:

Еволюція розділів
Айсберг використовує прихована перегородка, що означає, що вам не потрібно вручну додавати розділи для ваших таблиць Apache Iceberg. Нові значення розділів або нові специфікації розділів (додавання або видалення стовпців розділів) у таблицях Apache Iceberg автоматично визначаються за допомогою Amazon Redshift, і для оновлення розділів у визначенні таблиці не потрібно виконувати ручні операції. Наступний приклад демонструє це.
У нашому прикладі, якщо Айсберг табл nyc_taxi_yellow_iceberg спочатку була розділена роками, а пізніше колоною vendorid було додано як додатковий стовпець розділу, тоді Amazon Redshift може безперешкодно надсилати запити до таблиці Iceberg nyc_taxi_yellow_iceberg з двома різними схемами поділу протягом певного періоду часу.

Зауваження під час запиту таблиць Iceberg за допомогою Amazon Redshift
У період попереднього перегляду враховуйте наступне, використовуючи Amazon Redshift із таблицями Iceberg:
- Підтримуються лише таблиці Iceberg, визначені в каталозі даних AWS Glue.
- Команди зовнішньої таблиці CREATE або ALTER не підтримуються, що означає, що таблиця Iceberg уже має існувати в базі даних AWS Glue.
- Запити про подорожі в часі не підтримуються.
- Підтримуються версії Iceberg 1 і 2. Додаткову інформацію про версії у форматі Iceberg див Версійність формату.
- Список підтримуваних типів даних із таблицями Iceberg див Підтримувані типи даних у таблицях Apache Iceberg (попередній перегляд).
- Вартість запиту до таблиці Iceberg така ж, як і для доступу до будь-яких інших форматів даних за допомогою Amazon Redshift.
Щоб отримати додаткові відомості щодо попереднього перегляду таблиць у форматі Iceberg, див Використання таблиць Apache Iceberg із Amazon Redshift (попередній перегляд).
Відгуки клієнтів
«Tinuiti, найбільша незалежна маркетингова фірма, що працює з великими обсягами даних щодня, повинна мати надійне озеро даних і стратегію сховища даних, щоб наші команди аналізу ринку могли зберігати й аналізувати всі дані наших клієнтів у простий, доступний і безпечний спосіб. , і надійний спосіб», — говорить Джастін Манус, директор з технологій Tinuiti. «Підтримка Amazon Redshift таблиць Apache Iceberg у нашому озері даних, яке є єдиним джерелом правди, вирішує критичну проблему щодо оптимізації продуктивності та доступності та ще більше спрощує наші конвеєри інтеграції даних, щоб отримати доступ до всіх даних, отриманих із різних джерел, і забезпечити роботу нашого потенціал бренду клієнтів».
Висновок
У цій публікації ми показали вам приклад запиту таблиці Iceberg у Redshift за допомогою файлів, що зберігаються в Amazon S3, каталогізованих як таблиця в каталозі даних AWS Glue, і продемонстрували деякі ключові функції, як-от ефективне оновлення та видалення на рівні рядків, і досвід розвитку схеми для користувачів, щоб розблокувати потужність великих даних за допомогою Athena.
Ви можете використовувати Amazon Redshift для виконання запитів до таблиць озера даних у різних файлах і форматах таблиць, наприклад Апач Худі та Озеро Дельта, а тепер с Apache Iceberg (попередній перегляд), який надає додаткові параметри для потреб ваших сучасних архітектур даних.
Ми сподіваємося, що це стане чудовою відправною точкою для запитів таблиць Iceberg в Amazon Redshift.
Про авторів
 Рохіт Бансал є архітектором аналітичних рішень в AWS. Він спеціалізується на Amazon Redshift і працює з клієнтами над створенням аналітичних рішень нового покоління за допомогою інших служб AWS Analytics.
Рохіт Бансал є архітектором аналітичних рішень в AWS. Він спеціалізується на Amazon Redshift і працює з клієнтами над створенням аналітичних рішень нового покоління за допомогою інших служб AWS Analytics.
 Сатіш Сатія є старшим інженером з продуктів Amazon Redshift. Він затятий ентузіаст великих даних, який співпрацює з клієнтами по всьому світу, щоб досягти успіху та задовольнити їхні потреби у сховищах даних та архітектурі озера даних.
Сатіш Сатія є старшим інженером з продуктів Amazon Redshift. Він затятий ентузіаст великих даних, який співпрацює з клієнтами по всьому світу, щоб досягти успіху та задовольнити їхні потреби у сховищах даних та архітектурі озера даних.
 Ранджан Бурман є архітектором аналітичних рішень в AWS. Він спеціалізується на Amazon Redshift і допомагає клієнтам створювати масштабовані аналітичні рішення. Має понад 16 років досвіду в різних технологіях баз даних і сховищ даних. Він захоплений автоматизацією та вирішенням проблем клієнтів за допомогою хмарних рішень.
Ранджан Бурман є архітектором аналітичних рішень в AWS. Він спеціалізується на Amazon Redshift і допомагає клієнтам створювати масштабовані аналітичні рішення. Має понад 16 років досвіду в різних технологіях баз даних і сховищ даних. Він захоплений автоматизацією та вирішенням проблем клієнтів за допомогою хмарних рішень.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. Автомобільні / електромобілі, вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- ChartPrime. Розвивайте свою торгову гру за допомогою ChartPrime. Доступ тут.
- BlockOffsets. Модернізація екологічної компенсаційної власності. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- МЕНЮ
- доступ
- доступний
- доступність
- доступ до
- Achieve
- через
- додавати
- доданий
- Додатковий
- адреси
- доступний
- ВСІ
- дозволяє
- вже
- Також
- Amazon
- Амазонка Афіна
- Amazon EMR
- Amazon Web Services
- суми
- an
- Аналітичний
- Аналітичний
- аналітика
- аналізувати
- та
- будь-який
- Apache
- архітектура
- ЕСТЬ
- навколо
- масив
- AS
- At
- автоматично
- автоматизація
- доступний
- AWS
- Клей AWS
- основа
- оскільки
- перед тим
- буття
- Великий
- Великий даних
- обов'язковий
- Блог
- обидва
- марка
- будувати
- бізнес
- бізнес-аналітика
- by
- CAN
- можливості
- можливості
- каталог
- центральний
- певний
- виклик
- зміна
- головний
- Головний технічний директор
- клієнт
- хмара
- код
- Колекції
- Колонка
- Колони
- повний
- комплекс
- Умови
- Вважати
- міркування
- послідовний
- містить
- конвертувати
- узгоджений
- рентабельним
- створювати
- створений
- створення
- критичний
- клієнт
- дані про клієнтів
- Клієнти
- щодня
- дані
- інтеграція даних
- Озеро даних
- сховище даних
- Database
- набори даних
- Дати
- дефолт
- певний
- визначення
- Визначення
- Дельта
- демонструвати
- продемонстрований
- демонструє
- Залежно
- дизайн
- деталі
- виявлено
- DEV
- різний
- безпосередньо
- Не знаю
- подвійний
- скачати
- кожен
- легко
- легко
- редактор
- ефективний
- або
- усуваючи
- дозволяє
- двигун
- інженер
- ентузіаст
- запис
- Ефір (ETH)
- еволюція
- приклад
- існувати
- існуючий
- досвід
- Пояснювати
- дослідити
- продовжується
- зовнішній
- додатково
- ШВИДКО
- риси
- філе
- Файли
- фільтрувати
- знайти
- Фірма
- Перший
- Гнучкість
- після
- для
- формат
- часто
- від
- повністю
- далі
- отримати
- дає
- земну кулю
- йде
- великий
- Group
- Ручки
- Мати
- he
- допомагає
- історичний
- надія
- Як
- How To
- HTML
- HTTP
- HTTPS
- if
- in
- незалежний
- інформація
- інтеграція
- Інтелект
- в
- IT
- ЙОГО
- приєднатися
- JPG
- json
- Джастін
- тримати
- ключ
- озеро
- великий
- найбільших
- останній
- пізніше
- останній
- УЧИТЬСЯ
- менше
- як
- МЕЖА
- Лінія
- LINK
- список
- загрузка
- місцевий
- розташування
- підтримувати
- РОБОТИ
- Робить
- управляти
- вдалося
- управляє
- манера
- керівництво
- вручну
- карта
- ринок
- Маркетинг
- засоби
- Зустрічатися
- метадані
- сучасний
- більше
- найбільш
- рухатися
- переміщення
- повинен
- ім'я
- рідний
- Необхідність
- необхідний
- потреби
- Нові
- наступний
- наступне покоління
- немає
- увагу
- зараз
- номер
- Нью-Йорк
- of
- Офіцер
- on
- відкрити
- операція
- операції
- Оптимізувати
- оптимізований
- оптимізуючий
- Опції
- or
- спочатку
- Інше
- наші
- вихід
- над
- сторінка
- пристрасний
- виконувати
- продуктивність
- period
- план
- плани
- plato
- Інформація про дані Платона
- PlatoData
- точка
- пошта
- потенціал
- влада
- передумови
- попередній перегляд
- попередній
- раніше
- проблеми
- процес
- Product
- властивості
- забезпечує
- громадськість
- запити
- читання
- облік
- зменшити
- регіон
- видаляти
- замінювати
- вимагається
- REST
- Умови повернення
- міцний
- прогін
- біг
- то ж
- бачив
- говорить
- масштабовані
- шкала
- сканування
- сканування
- сканування
- схеми
- безшовні
- плавно
- розділ
- безпечний
- побачити
- старший
- Без сервера
- Послуги
- комплект
- Повинен
- Показувати
- показав
- показаний
- Шоу
- простий
- один
- рішення
- Рішення
- Розв’язування
- деякі
- Source
- Джерела
- Про
- спеціаліст
- спеціалізується
- специфікація
- дані
- спектр
- SQL
- standard
- Починаючи
- Заява
- статистика
- Крок
- заходи
- зберігання
- зберігати
- зберігати
- магазинів
- Стратегія
- рядок
- успіх
- такі
- підтримка
- Підтриманий
- Опори
- таблиця
- команди
- Технології
- Технологія
- тензор
- ніж
- Що
- Команда
- Джерело
- їх
- потім
- Ці
- це
- тисячі
- через
- час
- подорож у часі
- відмітка часу
- до
- сьогодні
- інструменти
- транзакційний
- подорожувати
- Правда
- два
- тип
- Типи
- єдиний
- союз
- відімкнути
- Оновити
- оновлений
- Updates
- Використання
- використання
- використовуваний
- користувачі
- використовує
- використання
- ПЕРЕВІР
- значення
- Цінності
- різноманітність
- різний
- дуже
- через
- вид
- Обсяги
- Склад
- Складування
- було
- шлях..
- we
- Web
- веб-сервіси
- коли
- який
- ВООЗ
- широкий
- широко
- волі
- з
- працює
- рік
- років
- ви
- вашу
- зефірнет