Вступ
Об'єднання штучний інтелект (ШІ) та артистизм відкриває нові шляхи творчого цифрового мистецтва, головним чином через дифузійні моделі. Ці моделі виділяються в творчому поколінні штучного інтелекту, пропонуючи підхід, відмінний від звичайних нейронних мереж. Ця стаття відправляє вас у дослідницьку подорож у глибини дифузійних моделей, з’ясовуючи їхній унікальний механізм у створенні візуально приголомшливих і творчо багатих творів мистецтва. Зрозумійте нюанси дифузійних моделей і зрозумійте їхню роль у переосмисленні мистецького вираження через призму передових технологій ШІ.

Мета навчання
- Зрозуміти фундаментальні концепції дифузійних моделей у ШІ.
- Дослідіть різницю між моделями дифузії та традиційними нейронними мережами в створенні мистецтва.
- Проаналізуйте процес створення мистецтва за допомогою дифузійних моделей.
- Оцініть творчі та естетичні наслідки ШІ в цифровому мистецтві.
- Обговоріть етичні міркування у творах мистецтва, створених штучним інтелектом.
Ця стаття була опублікована як частина Blogathon Data Science.
Зміст
Розуміння моделей дифузії

Дифузійні моделі революціонізують генеративний штучний інтелект, представляючи унікальний метод створення зображень, що відрізняється від звичайних методів, таких як генеративні змагальні мережі (GAN). Починаючи з випадкового шуму, ці моделі поступово вдосконалюють його, нагадуючи художника, який налаштовує картину, в результаті чого виходять складні та цілісні зображення.
Цей поступовий процес уточнення відображає методичну природу дифузії. Тут кожна ітерація тонко змінює шум, наближаючи його до кінцевого художнього бачення. Результат — це не просто продукт випадковості, а вдосконалений витвір мистецтва, що відрізняється своєю прогресією та завершеністю.
Кодування для дифузійних моделей вимагає глибокого розуміння нейронних мереж і систем машинного навчання, таких як TensorFlow або PyTorch. Отриманий код є складним і потребує тривалого навчання на великих наборах даних, щоб досягти тонких ефектів, які спостерігаються в мистецтві, створеному ШІ.
Застосування стійкої дифузії в мистецтві
Поява генераторів штучного інтелекту, таких як стабільні дифузійні моделі, вимагає складного кодування на таких платформах, як TensorFlow або PyTorch. Ці моделі виділяються своєю здатністю методично перетворювати випадковість у структуру, подібно до художника, який відточує попередній ескіз у яскравий шедевр.
Стабільні дифузійні моделі змінюють арт-сцену ШІ, створюючи впорядковані зображення з випадковості, уникаючи конкурентної динаміки, характерної для GAN. Вони чудово втілюють концептуальні підказки у візуальне мистецтво, сприяючи синергічному танцю між можливостями ШІ та людською винахідливістю. Використовуючи PyTorch, ми спостерігаємо, як ці моделі періодично вдосконалюють хаос у ясність, відображаючи шлях художника від зароджувальної ідеї до відшліфованого творіння.
Експерименти з мистецтвом, створеним штучним інтелектом
Ця демонстрація занурюється в захоплюючий світ мистецтва, створеного штучним інтелектом, за допомогою згорткової нейронної мережі під назвою ConvDiffusionModel. Ця модель тренується на різноманітних образах мистецтва, включаючи малюнки, картини, скульптури та гравюри, отримані з цей набір даних Kaggle. Наша мета — дослідити здатність моделі вловлювати та відтворювати складну естетику цих творів мистецтва.
Архітектура моделі та навчання
Архітектурне проектування
ConvDiffusionModel, за своєю суттю, є дивом нейронної інженерії, що містить складну архітектуру кодера-декодера, адаптовану до вимог покоління мистецтва. Структура моделі являє собою складну нейронну мережу, яка об’єднує вдосконалені механізми кодера-декодера, спеціально відточені для створення мистецтва. Завдяки додатковим згортковим шарам і пропускаючим з’єднанням, які імітують художню інтуїцію, модель може аналізувати та повторно збирати мистецтво з глибоким розумінням композиції та стилю.
- Кодер: Кодер — це аналітичне око моделі, яке ретельно вивчає кожне вхідне зображення до найдрібніших деталей. Коли зображення проходять через згорткові шари кодера, вони поступово стискаються в латентний простір — компактне, закодоване представлення оригінального твору мистецтва. Наш кодер не тільки ретельно перевіряє вхідні зображення, але тепер робить це з розширеною глибиною сприйняття завдяки додатковим шарам і методам пакетної нормалізації. Це розширене дослідження дозволяє отримати багатше, згущене представлення всередині прихованого простору, віддзеркалюючи глибоке споглядання художником предмета.
- Декодер: На відміну від цього, декодер виконує роль творчої руки моделі, беручи абстрактні ескізи з кодера та вдихаючи в них життя. Він реконструює твір мистецтва з прихованого простору, шар за шаром, деталь за деталлю, поки не з’явиться повне зображення. Наш декодер має переваги пропускання з’єднань і може реконструювати ілюстрацію з більшою точністю. Він повертається до абстрактної сутності введення та поступово прикрашає його, досягаючи відтворення, яке більш вірно відповідає вихідному матеріалу. Покращені шари працюють узгоджено, щоб гарантувати, що кінцеве зображення є яскравим, складним твором, що відображає артистизм введення.
Тренувальний процес
Навчання ConvDiffusionModel — це подорож художнім ландшафтом, що охоплює 150 епох. Кожна епоха являє собою повний прохід через увесь набір даних, при цьому модель прагне уточнити своє розуміння та підвищити точність створених нею зображень.
- Гібридна функція втрати: В основі навчання лежить функція втрат середньоквадратичної помилки (MSE). Ця функція кількісно визначає різницю між оригінальним шедевром і відтвореною моделлю, забезпечуючи чітку метрику для мінімізації. Ми представимо компонент втрати сприйняття, отриманий із попередньо навченої мережі VGG, який доповнює метрику середньої квадратичної помилки (MSE). Ця стратегія подвійних втрат спонукає модель поважати художню цілісність оригіналів, одночасно вдосконалюючи технічне відтворення їхніх деталей.
- оптимізатор: Завдяки швидкості навчання, яка динамічно регулюється планувальником, оптимізатор Adam керує навчанням моделі з підвищеною проникливістю. Цей адаптивний підхід гарантує, що прогрес моделі в навчанні відтворювати та інновувати мистецтво є стабільним та надійним.
- Ітерація та вдосконалення: Навчальні ітерації - це танець між збереженням художньої сутності та пошуком технічного відтворення. З кожним циклом модель наближається до синтезу вірності та креативності.
- Візуалізація прогресу: зображення зберігаються через регулярні проміжки часу під час навчання, щоб візуалізувати прогрес моделі. Ці знімки пропонують вікно в криву навчання моделі, демонструючи, як еволюціонує створене нею мистецтво, стаючи чіткішим, детальнішим і художньо узгодженішим з кожною епохою.



Це продемонстровано за допомогою наступного фрагмента коду:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Візуалізація створеного твору мистецтва
Прояв майстерності, створеної штучним інтелектом
З ConvDiffusionModel тепер повністю навчено, фокус зміщується від абстрактного до конкретного — від потенціалу до реалізації мистецтва, створеного штучним інтелектом. Подальший фрагмент коду матеріалізує вивчені художні можливості моделі, перетворюючи вхідні дані на цифрове полотно вираження.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()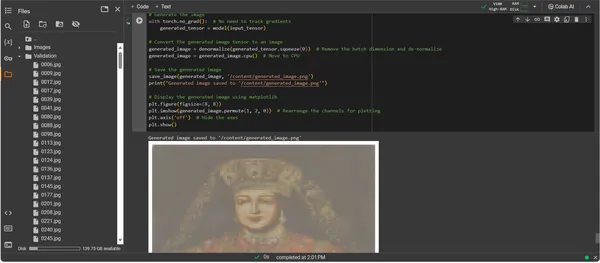

Покрокове керівництво по створенню коду ілюстрації
- Воскресіння моделі: Першим кроком у створенні ілюстрації є відновлення нашої навченої ConvDiffusionModel. Вивчені вагові коефіцієнти моделі завантажуються та переходять у режим оцінки, створюючи основу для створення без подальшої зміни її параметрів.
- Трансформація зображення: Щоб забезпечити узгодженість із режимом навчання, вхідні зображення обробляються за допомогою тієї ж послідовності перетворень. Це включає зміну розміру відповідно до вхідних розмірів моделі, перетворення тензорів для сумісності з PyTorch і нормалізацію на основі статистичного профілю навчальних даних.
- Утиліта денормалізації: Спеціальна функція скасовує ефекти попередньої обробки, змінюючи масштаб тензора відповідно до діапазону кольорів оригінального зображення. Цей крок необхідний для перетворення згенерованого результату у візуально точне представлення.
- Підготовка вхідних даних: Зображення завантажується та піддається вищезгаданим перетворенням. Важливо відзначити, що це зображення служить музою, від якої ШІ черпатиме натхнення — тихий шепіт розпалює синтетичну уяву моделі.
- Синтез ілюстрації: У делікатному танці прямого поширення модель інтерпретує вхідний тензор, дозволяючи своїм шарам співпрацювати у створенні нового художнього бачення. Виконайте цей процес без відстеження градієнтів, оскільки зараз ми перебуваємо у сфері застосування, а не навчання.
- Перетворення зображення: Тензорний вихід моделі, який тепер містить цифрову ілюстрацію, денормалізується, переводячи створення моделі назад у знайомий простір кольору та світла, який може оцінити наше око.
- Відкриття творів мистецтва: Трансформований тензор розміщується на цифровому полотні, кульмінацією якого є збережений файл зображення. Цей файл є вікном у творчу душу ШІ, статичним відлунням динамічного процесу, який дав йому життя.
- Пошук творів мистецтва: Сценарій завершується збереженням створеного зображення за вказаним шляхом і повідомленням про його завершення. Збережене зображення, синтез вивчених мистецьких принципів і нової творчості, готове до демонстрації та споглядання.
Аналіз результату
Вихід ConvDiffusionModel представляє фігуру з чітким нахилом до історичного мистецтва. Одягнене в вишукане вбрання зображення, створене штучним інтелектом, перегукується з величчю класичних портретів, але має виразний сучасний відтінок. Одяг об’єкта має багату текстуру, поєднуючи вивчені візерунки моделі з новою інтерпретацією. Витончені риси обличчя та тонка гра світла й тіні демонструють тонке розуміння штучним інтелектом традиційних художніх технік. Цей твір є свідченням витонченої підготовки моделі, що відображає елегантний синтез історичного мистецтва крізь призму вдосконаленого машинного навчання. По суті, це цифрова данина минулому, створена за допомогою алгоритмів сьогодення.
Виклики та етичні міркування
Впровадження дифузійних моделей для створення мистецтва пов’язане з кількома проблемами та етичними міркуваннями, які слід враховувати:
- Походження даних: Навчальні набори даних потрібно відповідально підбирати. Перевірка того, що дані, які використовуються для навчання дифузійних моделей, не містять творів, захищених авторським правом, без відповідного дозволу.
- Упередженість і представництво: Моделі штучного інтелекту можуть увічнити упередження у своїх навчальних даних. Забезпечення різноманітних і інклюзивних наборів даних є важливим, щоб уникнути посилення стереотипів у створеному ШІ мистецтві.
- Контроль над виходом: Оскільки дифузійні моделі можуть генерувати широкий спектр результатів, необхідно встановити межі для запобігання створенню неприйнятного або образливого вмісту.
- Правова база: Відсутність надійної законодавчої бази для вирішення нюансів штучного інтелекту в творчому процесі є проблемою. Законодавство має розвиватися, щоб захистити права всіх залучених сторін.
Висновок
Розвиток моделей дифузії в штучному інтелекті та мистецтві знаменує епоху трансформації, яка поєднує точність обчислень з естетичним дослідженням. Їхня подорож у світ мистецтва підкреслює значний інноваційний потенціал, але супроводжується складнощами. Баланс між оригінальністю, впливом, етичною творчістю та повагою до існуючих творів є невід’ємною частиною мистецького процесу.
Ключові винесення
- Дифузійні моделі знаходяться в авангарді трансформаційного зрушення в творчості. Вони пропонують нові цифрові інструменти, які розширюють полотно художнього вираження за межі традиційних кордонів.
- У мистецтві, розширеному штучним інтелектом, для підтримки цілісності цифрового мистецтва в пріоритеті етичний збір навчальних даних і повага до інтелектуальної власності творців.
- Конвергенція мистецького бачення та технологічних інновацій відкриває двері для симбіотичних стосунків між художниками та розробниками ШІ. Створюйте середовище співпраці, яке може дати початок новаторському мистецтву.
- Вкрай важливо переконатися, що створене штучним інтелектом мистецтво представляє широкий спектр перспектив. Включайте різноманітні дані, які відображають багатство різних культур і поглядів, таким чином сприяючи інклюзивності.
- Зростаючий інтерес до мистецтва, створеного штучним інтелектом, вимагає створення міцної правової бази. Ці рамки повинні прояснити питання авторського права, визнати внески та регулювати комерційне використання творів мистецтва, створених ШІ.
Світанок цієї мистецької еволюції пропонує шлях, наповнений творчим потенціалом, але потребує уважної опіки. Ми зобов’язані розвивати ландшафт, де процвітає поєднання штучного інтелекту та мистецтва, керуючись відповідальними та культурно чутливими практиками.
ЧАСТІ ЗАПИТАННЯ
A. Дифузійні моделі — це генеративні алгоритми ML, які створюють зображення, починаючи з шаблону випадкового шуму та поступово формуючи його в узгоджену картину. Цей процес схожий на те, як художник починає з чистого полотна та повільно додає шари деталей.
A. GAN, дифузійні моделі не вимагають окремої мережі для оцінки результату. Вони працюють шляхом повторного додавання та видалення шуму, що часто призводить до отримання більш детальних і нюансованих зображень.
A. Так, дифузійні моделі можуть генерувати оригінальні твори мистецтва, вивчаючи набір даних зображень. Однак на оригінальність впливає різноманітність і обсяг навчальних даних. Тривають дебати щодо етики використання існуючих творів мистецтва для навчання цих моделей.
A. Етичні проблеми включають уникнення порушення авторських прав на мистецтво, створене ШІ. Повага до оригінальності митців, запобігання упередженню та забезпечення прозорості творчого процесу ШІ.
A. Майбутнє мистецтва, створеного штучним інтелектом, виглядає багатообіцяючим, оскільки дифузійні моделі пропонують нові інструменти для художників і творців. Ми можемо очікувати, що ми побачимо більш витончені та заплутані твори мистецтва з розвитком технологій. Проте творче співтовариство має керуватися етичними міркуваннями та працювати над чіткими вказівками та найкращими практиками.
Медіафайли, показані в цій статті, не належать Analytics Vidhya та використовуються на розсуд Автора.
споріднений
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :є
- : ні
- :де
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- здатність
- МЕНЮ
- вище
- РЕЗЮМЕ
- точний
- Achieve
- досягнення
- Адам
- адаптивний
- додати
- Додатковий
- адреса
- Відрегульований
- просунутий
- аванси
- прихід
- змагальність
- AI
- ai мистецтво
- подібний
- алгоритми
- ВСІ
- Дозволити
- дозволяє
- an
- Аналітичний
- аналітика
- Аналітика Vidhya
- та
- Оголошуючи
- додаток
- цінувати
- підхід
- архітектура
- ЕСТЬ
- Art
- стаття
- художник
- художній
- художньо
- артистизм
- Художники
- витвір мистецтва
- художні твори
- AS
- At
- збільшено
- авторизації
- доступний
- проспекти
- уникнути
- уникає
- Оси
- назад
- поганий
- Балансування
- заснований
- BE
- становлення
- Переваги
- КРАЩЕ
- передового досвіду
- між
- За
- зміщення
- упередження
- порожній
- змішування
- блогатон
- народжений
- обидва
- Межі
- дихання
- заповнення
- Приносить
- широкий
- приніс
- бурхливий
- але
- by
- обчислювати
- званий
- CAN
- полотно
- можливості
- можливості
- захоплення
- виклик
- проблеми
- канали
- хаос
- характеристика
- перевірка
- контроль
- зажим
- ясність
- клас
- ясно
- ясніше
- ближче
- код
- Кодування
- КОГЕРЕНТНИЙ
- співпрацювати
- спільний
- color
- приходить
- комерційний
- співтовариство
- компактний
- сумісність
- конкурентоспроможний
- повний
- завершення
- комплекс
- складності
- компонент
- склад
- обчислювальна
- обчислення
- поняття
- концептуальний
- Турбота
- концерт
- робить висновок
- Зв'язки
- Вважати
- міркування
- містити
- зміст
- контрастність
- внески
- звичайний
- Зближення
- Перетворення
- перетворення
- згорткова нейронна мережа
- авторське право
- порушення авторських прав
- Core
- корумпований
- центральний процесор
- створений
- створювати
- створення
- створення
- Креатив
- Творчо
- креативність
- Творці
- вирішальне значення
- кульмінацією
- Культивувати
- культурно
- Куратор
- крива
- виготовлений на замовлення
- цикл
- танець
- дані
- набори даних
- дебати
- глибокий
- визначаючи
- запити
- продемонстрований
- глибина
- Глибини
- Отриманий
- призначені
- деталь
- докладно
- деталі
- розробників
- пристрій
- відрізняються
- різниця
- різний
- радіомовлення
- цифровий
- цифрове мистецтво
- в цифровому вигляді
- Розмір
- розміри
- розсуд
- дисплей
- показ
- чіткий
- відмінність
- Різне
- різноманітність
- do
- робить
- Двері
- малювати
- Креслення
- під час
- динамічний
- динамічно
- динаміка
- e
- кожен
- нудьгувати
- відлуння
- ефекти
- Розробити
- ще
- виникає
- кодований
- охоплювати
- охоплюючий
- Машинобудування
- підвищена
- забезпечувати
- гарантує
- забезпечення
- Весь
- Навколишнє середовище
- епоха
- епохи
- Епоха
- помилка
- сутність
- істотний
- установа
- Ефір (ETH)
- етичний
- етика
- оцінка
- Кожен
- еволюція
- еволюціонувати
- еволюціонували
- еволюціонує
- експертиза
- перевершувати
- Крім
- існуючий
- Розширювати
- експансивний
- очікувати
- дослідження
- дослідити
- вираз
- розширений
- обширний
- очей
- очі
- лицьової
- вірний
- false
- знайомий
- захоплюючий
- риси
- Показуючи
- вірність
- Рисунок
- філе
- Файли
- остаточний
- закінчення
- Перший
- Сфокусувати
- після
- для
- передній край
- Вперед
- Сприяти
- виховання
- Рамки
- каркаси
- від
- повністю
- функція
- функціональний
- фундаментальний
- далі
- злиття
- майбутнє
- Отримувати
- ГАН
- збір
- дав
- породжувати
- генерується
- породжує
- покоління
- генеративний
- генеративні змагальні мережі
- Генеративний ШІ
- генератори
- Давати
- мета
- GPU
- градієнти
- поступово
- велич
- схопити
- великий
- новаторський
- керуватися
- керівні вказівки
- Гід
- рука
- Запрягання
- Серце
- тут
- приховувати
- основний момент
- історичний
- проведення
- дань
- честь
- Як
- Однак
- HTTPS
- людина
- i
- ідея
- if
- запалює
- зображення
- зображень
- уяву
- імператив
- реалізації
- наслідки
- імпорт
- важливо
- удосконалювати
- in
- includes
- Включно
- Інклюзивність
- включати
- збільшений
- зростаючий
- Складно
- вплив
- під впливом
- порушення
- винахідливість
- оновлювати
- інновація
- вхід
- витрати
- розуміння
- інтегральний
- Інтеграція
- цілісність
- інтелектуальний
- інтелектуальна власність
- інтерес
- інтерпретація
- в
- складний
- вводити
- інтуїція
- залучений
- питання
- IT
- ітерація
- ітерації
- ЙОГО
- подорож
- JPG
- суддя
- відсутність
- ландшафт
- шар
- шарів
- вчений
- вивчення
- легальний
- законодавча база
- Законодавство
- об'єктив
- лежить
- життя
- світло
- як
- погрузка
- ВИГЛЯДИ
- від
- втрати
- машина
- навчання за допомогою машини
- підтримувати
- чудо
- шедевр
- матч
- матеріал
- matplotlib
- значити
- механізм
- механізми
- Медіа
- просто
- злиття
- метод
- методичний
- метрика
- мінімізувати
- хвилин
- відображає
- ML
- Алгоритми ML
- режим
- модель
- Моделі
- сучасний
- Модулі
- більше
- рухатися
- багато
- MUSE
- повинен
- Імена
- зародження
- природа
- Переміщення
- необхідно
- потреби
- мережу
- мереж
- Нейронний
- Нейронна інженерія
- нейронної мережі
- нейронні мережі
- Нові
- шум
- увагу
- роман
- зараз
- нюанси
- спостерігати
- спостерігається
- of
- від
- наступ
- пропонувати
- пропонує
- Пропозиції
- часто
- on
- постійний
- тільки
- Відкриється
- Оптимізувати
- or
- оригінал
- оригінальність
- Originals
- OS
- Інше
- наші
- з
- вихід
- виходи
- над
- яка перебуває у власності
- Картина
- Картини
- параметр
- параметри
- частина
- Сторони
- проходити
- Минуле
- шлях
- Викрійки
- моделі
- сприйняття
- вдосконалення
- виконувати
- перспективи
- картина
- частина
- частин
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- портрети
- потенціал
- практики
- Точність
- попередньо
- представити
- подарунки
- консервування
- запобігати
- попередження
- Принципи
- друк
- визначення пріоритетів
- процес
- оброблена
- виробництво
- Product
- профіль
- глибокий
- прогрес
- прогресія
- поступово
- перспективний
- сприяння
- підказок
- поширення
- правильний
- власність
- захист
- захищений
- походження
- забезпечення
- опублікований
- переслідування
- піторх
- кількісно
- випадковий
- випадковість
- діапазон
- ставка
- готовий
- царство
- визнавати
- Перевизначення
- удосконалювати
- рафінований
- що відображають
- Відображає
- режим
- регулярний
- відносини
- видалення
- надання
- копіювання
- подання
- представляє
- відтворення
- вимагати
- Вимагається
- схожий на
- переробити
- повага
- поважаючи
- відповідальний
- відповідально
- в результаті
- повертати
- одкровення
- Відроджувати
- здійснити революцію
- RGB
- Багаті
- праві
- Зростання
- міцний
- Роль
- то ж
- зберігаються
- економія
- сцена
- наука
- сфера
- сценарій
- побачити
- SELF
- чутливий
- окремий
- Послідовність
- служить
- комплект
- установка
- установка
- кілька
- тінь
- формуючи
- зсув
- Зміни
- Повинен
- демонстрації
- демонстрація
- показаний
- значний
- з
- Повільно
- уривок
- So
- складний
- Soul
- Source
- джерело
- Простір
- напруга
- конкретно
- спектр
- в квадраті
- стабільний
- Стажування
- стояти
- Починаючи
- статистичний
- стійкий
- Крок
- Стратегія
- прагнення
- структура
- Приголомшливий
- стиль
- тема
- наступні
- такі
- Симбіотичний
- синергетичний
- синтез
- синтетичний
- з урахуванням
- приймає
- взяття
- Мета
- технічний
- методи
- технологічний
- Технології
- Технологія
- тензорний потік
- заповіт
- Що
- Команда
- Майбутнє
- Джерело
- їх
- Їх
- Там.
- Ці
- вони
- це
- процвітає
- через
- Таким чином
- до
- інструменти
- факел
- Torchvision
- торкатися
- до
- Відстеження
- традиційний
- поїзд
- навчений
- Навчання
- Перетворення
- Перетворення
- перетворень
- перетворювальний
- перетворений
- перетворення
- перетворення
- прозорість
- правда
- намагатися
- розуміти
- розуміння
- створеного
- до
- Оприлюднює
- оновлення
- на
- us
- використання
- використовуваний
- використання
- утиліта
- дійсний
- перевірка
- через
- перегляд
- точки зору
- бачення
- візуальний
- візуальне мистецтво
- візуалізації
- візуалізувати
- візуально
- життєво важливий
- було
- we
- webp
- Що
- Що таке
- який
- в той час як
- Шепіт
- ВООЗ
- широкий
- Широкий діапазон
- волі
- вікно
- з
- в
- без
- Work
- працює
- світ
- X
- так
- ще
- ви
- зефірнет
- нуль