AWS Glue Studio тепер інтегровано з AWS Клей DataBrew. AWS Glue Studio — це графічний інтерфейс, який дозволяє легко створювати, запускати та відстежувати завдання вилучення, трансформації та завантаження (ETL) у Клей AWS. DataBrew — це візуальний інструмент підготовки даних, який дає змогу очищати та нормалізувати дані без написання коду. Понад 200 трансформацій, які він надає, тепер доступні для використання у візуальному завданні AWS Glue Studio.
У DataBrew a рецепт це набір кроків перетворення даних, які ви можете створювати інтерактивно в його інтуїтивно зрозумілому візуальному інтерфейсі. У цій публікації ви побачите, як створити рецепт у DataBrew, а потім застосувати його як частину візуального ETL-завдання AWS Glue Studio.
Існуючі користувачі DataBrew також отримають вигоду від цієї інтеграції — тепер ви можете запускати свої рецепти як частину більшого візуального робочого процесу з усіма іншими компонентами, які надає AWS Glue Studio, на додаток до можливості використовувати розширену конфігурацію завдань і останню версію механізму AWS Glue. .
Ця інтеграція приносить певні переваги існуючим користувачам обох інструментів:
- У вас є централізований перегляд загальної діаграми ETL в AWS Glue Studio
- Ви можете інтерактивно визначити рецепт, переглядаючи значення, статистику та розподіл на консолі DataBrew, а потім повторно використовувати перевірену логіку обробки з версіями у візуальних завданнях AWS Glue Studio
- Ви можете оркеструвати кілька рецептів DataBrew у завданні AWS Glue ETL або навіть кілька завдань за допомогою робочих процесів AWS Glue
- Рецепти DataBrew тепер можуть використовувати такі функції роботи AWS Glue, як закладки для поступової обробки даних, автоматичні повтори, автоматичне масштабування або групування невеликих файлів для більшої ефективності.
Огляд рішення
У нашому фіктивному випадку використання вимога полягає в тому, щоб очистити набір синтетичних медичних претензій, створений для цієї публікації, який має деякі проблеми з якістю даних, введені навмисно, щоб продемонструвати можливості DataBrew щодо підготовки даних. Потім дані про претензії вводяться в каталог (так що вони видимі для аналітиків), після збагачення його деякими відповідними відомостями про відповідних постачальників медичних послуг, що надходять з окремого джерела.
Рішення складається з візуального завдання AWS Glue Studio, яке читає два файли CSV із заявами та постачальниками відповідно. Завдання застосовує рецепт першого з них для вирішення проблем із якістю, вибирає стовпці з другого, об’єднує обидва набори даних і, нарешті, зберігає результат у Служба простого зберігання Amazon (Amazon S3), створюючи таблицю в каталозі, щоб вихідні дані можна було використовувати іншими інструментами, наприклад Амазонка Афіна.
Створіть рецепт DataBrew
Почніть із реєстрації сховища даних для файлу претензій. Це дозволить вам створити рецепт в інтерактивному редакторі, використовуючи фактичні дані, щоб ви могли оцінити результат перетворень, коли ви їх визначаєте.
- Завантажте CSV-файл претензій за таким посиланням: alabama_claims_data_Jun2023.csv.
- На консолі DataBrew виберіть Набори даних на панелі навігації, а потім виберіть Підключіть новий набір даних.
- Виберіть варіант Завантаження файлу.
- для Назва набору даних, введіть
Alabama claims. - для Виберіть файл для завантаження, виберіть файл, який ви щойно завантажили на свій комп’ютер.
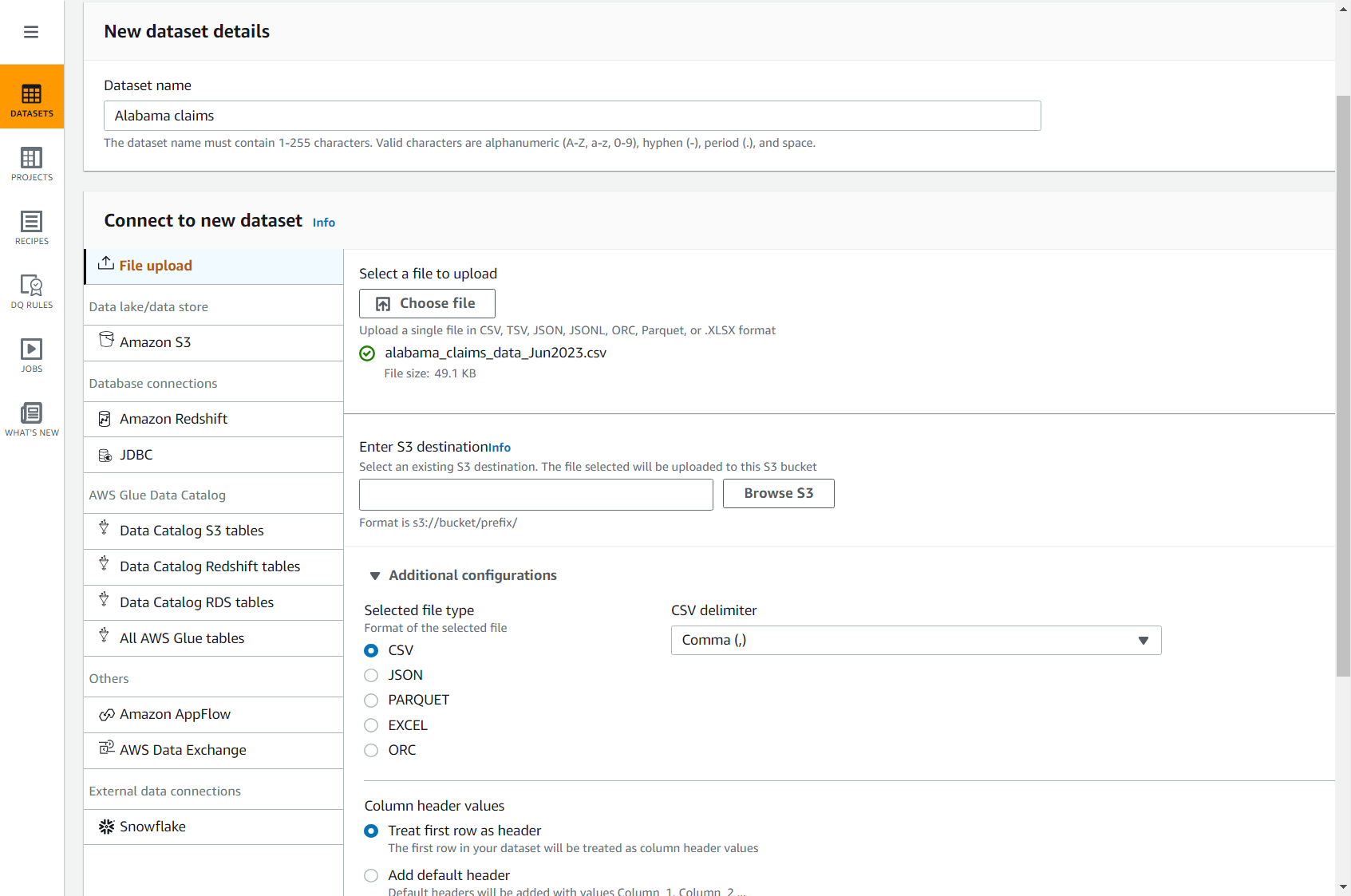
- для Введіть пункт призначення S3, введіть або перейдіть до сегмента у своєму обліковому записі та регіоні.
- Залиште решту параметрів за замовчуванням (CSV, розділений комами та заголовок) і завершіть створення набору даних.
- Вибирати Проекти на панелі навігації, а потім виберіть Створити проект.
- для Назва проекту, назвіть це
ClaimsCleanup. - під Деталі рецепта, Для Рецепт додаєтьсявиберіть Створіть новий рецепт, назвіть це
ClaimsCleanup-recipeі виберітьAlabama claimsнабір даних, який ви щойно створили.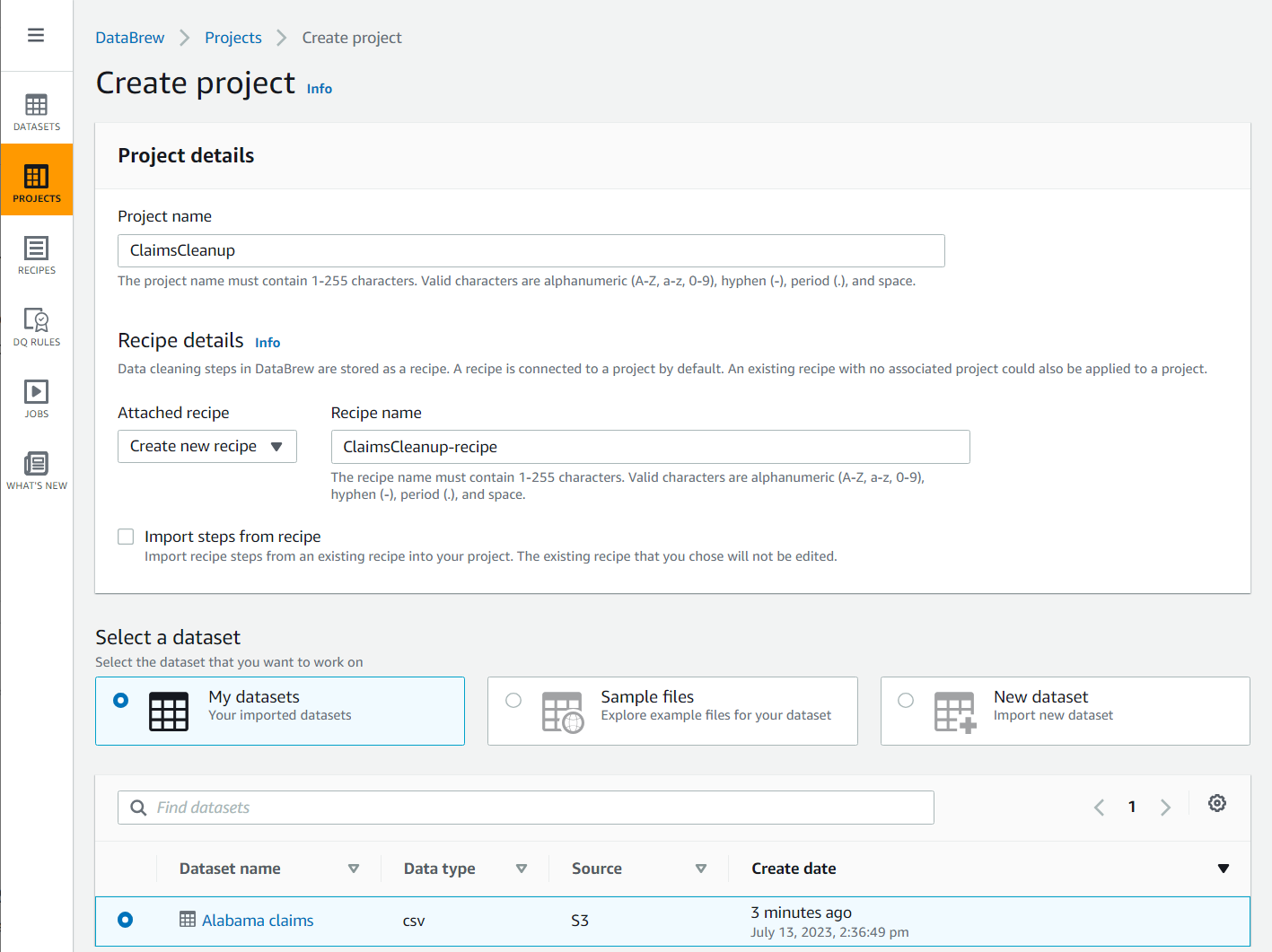
- Виберіть роль, яка підходить для DataBrew або створіть новий і завершіть створення проекту.
Це створить сеанс із використанням конфігурованої підмножини даних. Після ініціалізації сеансу ви можете помітити, що деякі клітинки мають недійсні або відсутні значення.
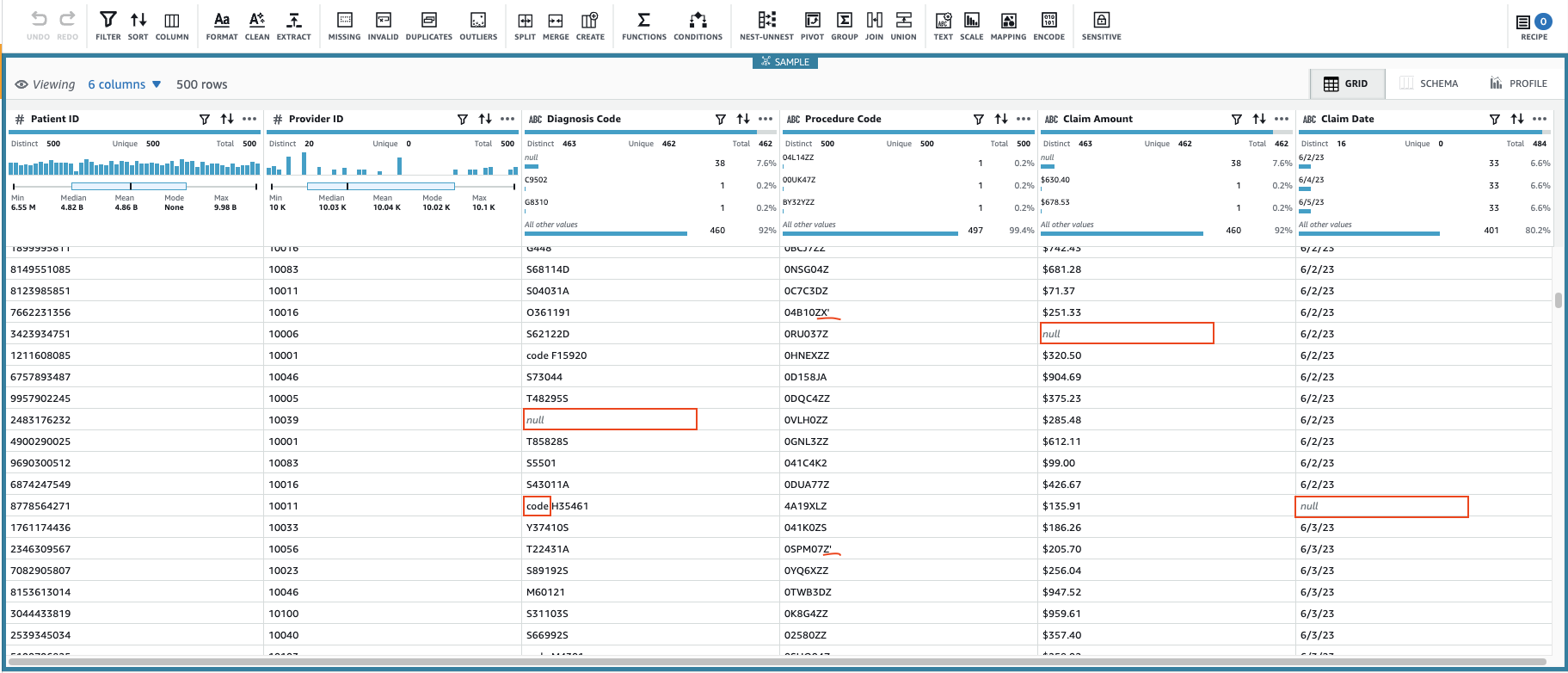
На додаток до відсутніх значень у стовпцях Код діагнозу, Сума позову та Дата претензії, деякі значення в даних мають додаткові символи: Код діагнозу значення іноді мають префікс «код» (з пробілом) і Процесуальний кодекс за значеннями іноді йдуть одинарні лапки.
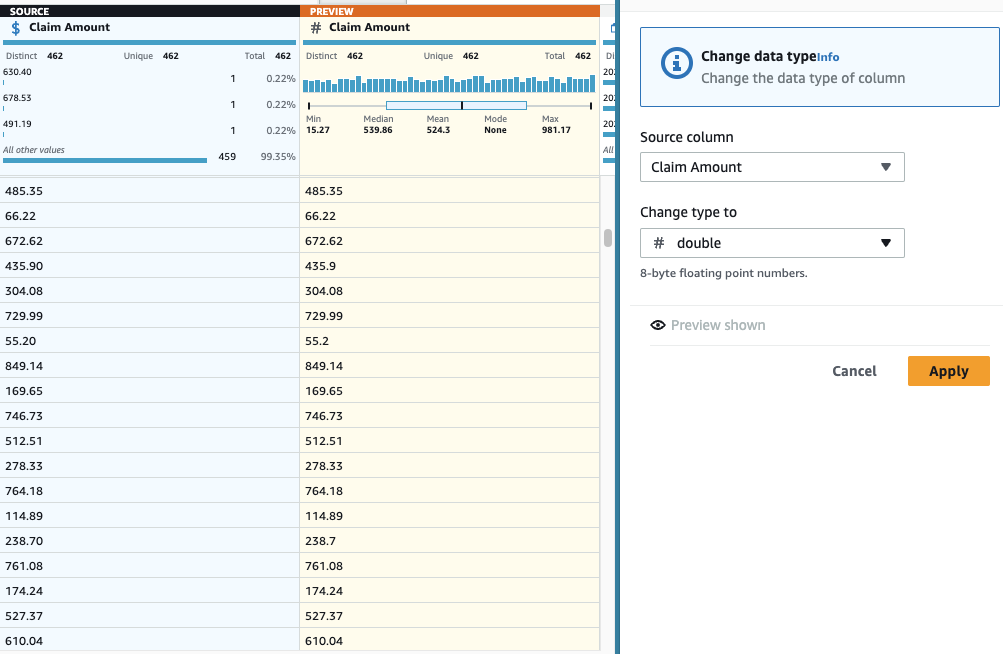
Сума позову значення, ймовірно, використовуватимуться для деяких обчислень, тому перетворіть їх у число та Дані претензії має бути перетворено на тип дати.
Тепер, коли ми визначили проблеми з якістю даних, які потрібно вирішити, нам потрібно вирішити, як діяти в кожному випадку.
Ви можете додати кроки рецепту кількома способами, включно з використанням контекстного меню стовпця, панелі інструментів угорі або зі зведення рецепта. Використовуючи останній метод, ви можете шукати вказаний тип кроку, щоб відтворити рецепт, створений у цій публікації.
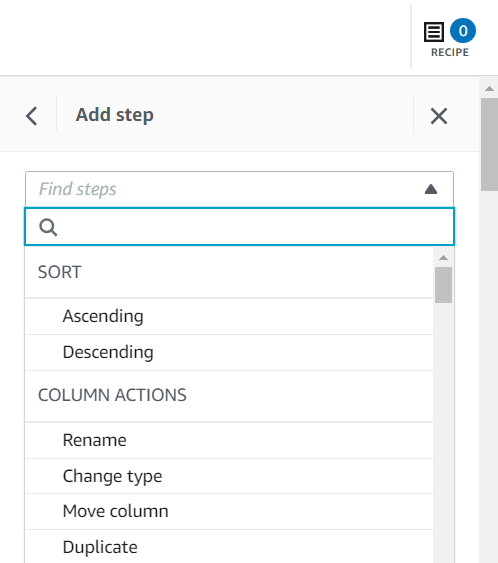
Сума позову має важливе значення для цього випадку використання, і рішення полягає у видаленні таких рядків.
- Додайте крок Видаліть відсутні значення.
- для Вихідна колонкавиберіть Сума позову.
- Залиште дію за умовчанням Видалити рядки з відсутніми значеннями І вибирай Застосовувати щоб зберегти його.
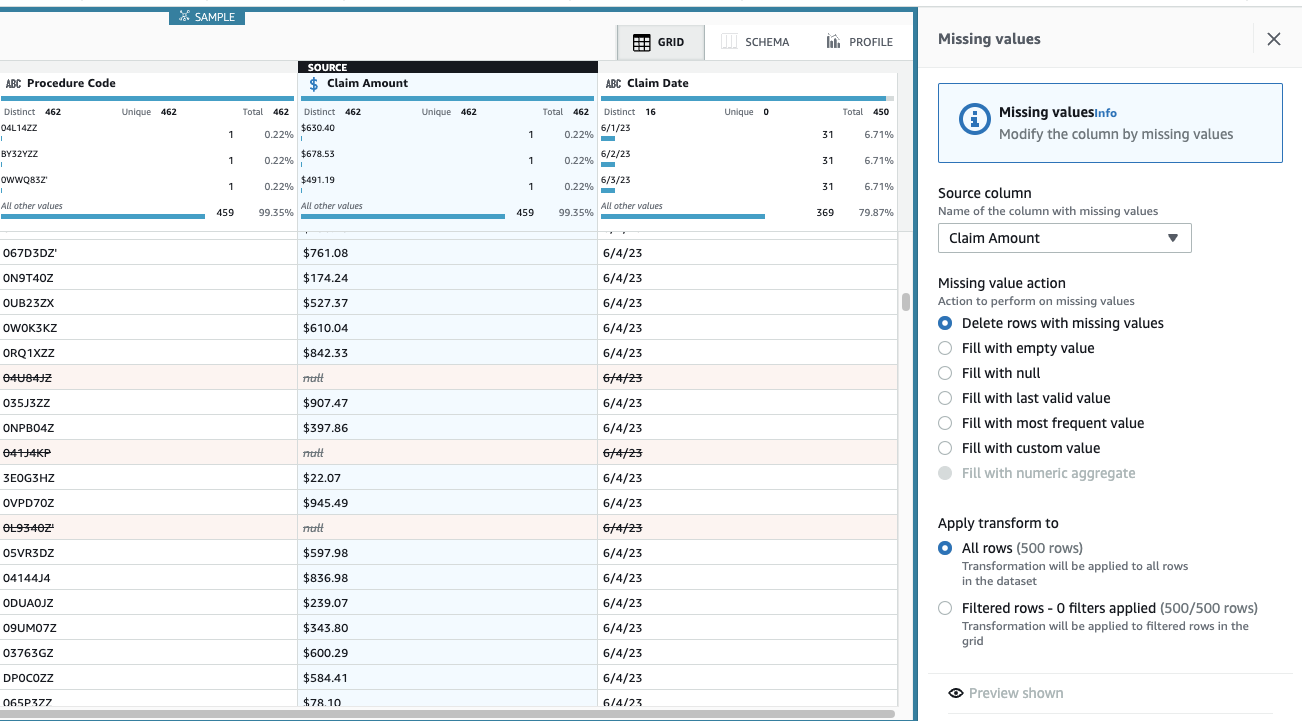
Подання тепер оновлено, щоб відобразити застосування кроку, а рядки з відсутніми сумами більше не існують.
Код діагнозу може бути порожнім, тому це прийнятно, але у випадку Дата претензії, ми хочемо мати обґрунтовану оцінку. Рядки в даних відсортовано в хронологічному порядку, тому ви можете призначити відсутні дати, використовуючи дійсне значення попереднього перегляду з попередніх рядків. Якщо припустити, що кожен день має претензії, найбільшою помилкою було б призначити його дню попереднього перегляду, якби це була перша претензія цього дня без дати; для ілюстрації, давайте вважати цю потенційну помилку прийнятною.
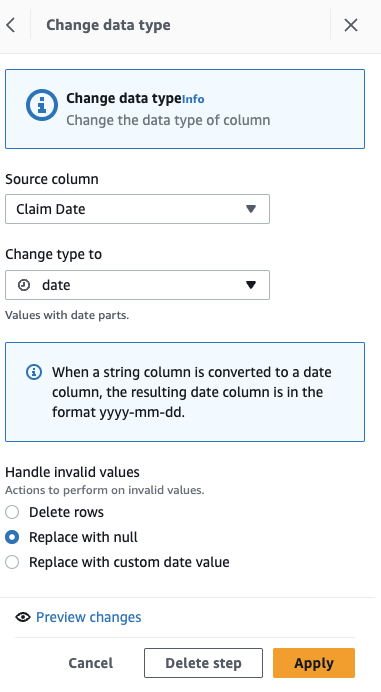
Спочатку перетворіть стовпець із рядка на тип дати.
- Додайте крок Змінити тип.
- Вибирати Дата претензії як колонка і дата як тип, потім виберіть Застосовувати.
- Тепер, щоб зробити імпутацію відсутніх дат, додайте крок Заповніть або введіть пропущені значення.
- Виберіть «Заповнити останнім дійсним значенням» як дію та виберіть Дата претензії як джерело.
- Вибирати Попередній перегляд змін щоб підтвердити його, потім виберіть Застосовувати щоб зберегти крок.
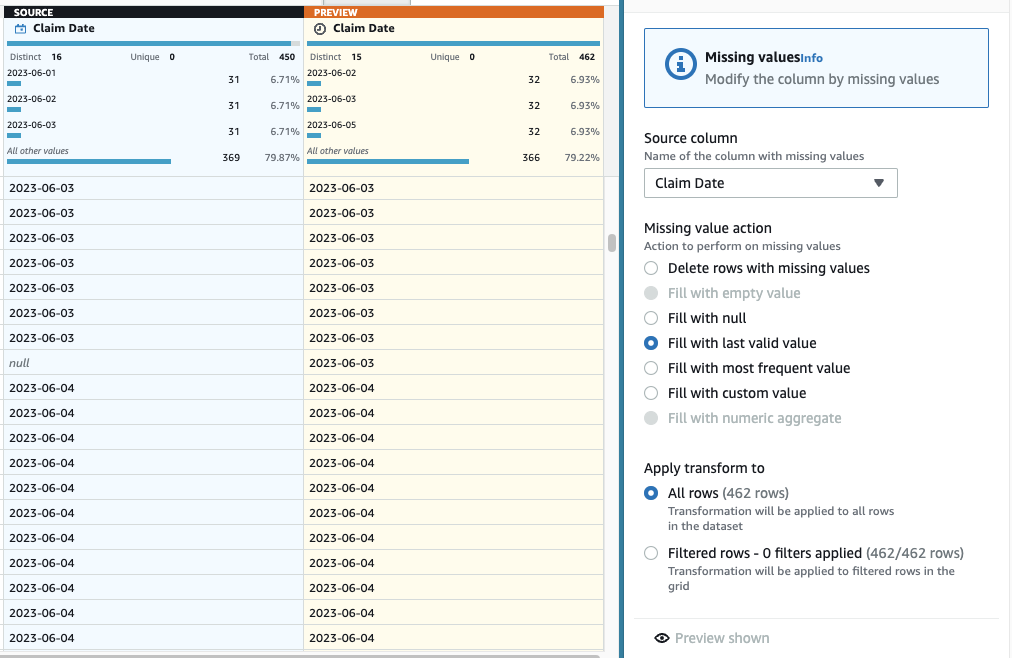
Наразі ваш рецепт має складатися з трьох кроків, як показано на наступному знімку екрана.
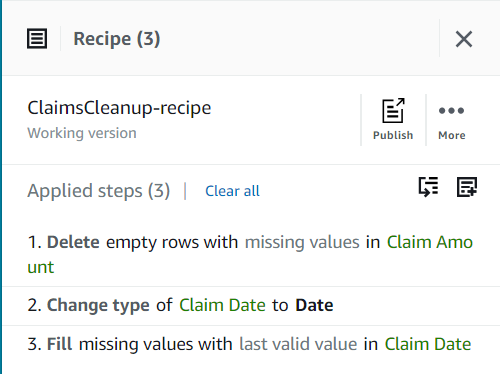
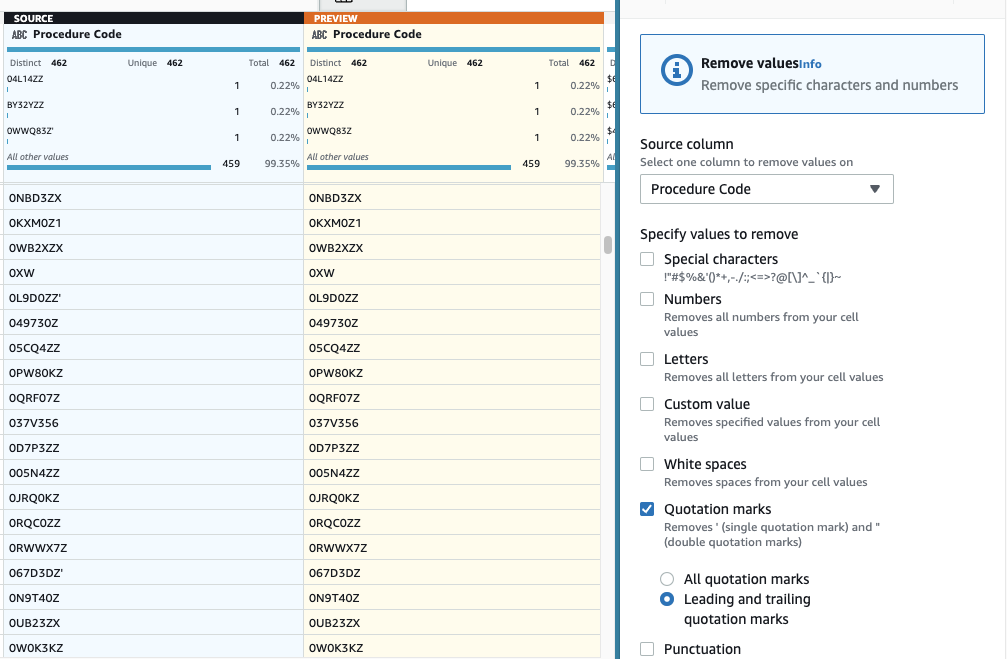
- Далі додайте крок Зняти лапки.
- Виберіть Процесуальний кодекс стовпець і виберіть Початкові та кінцеві лапки.
- Перегляньте, щоб переконатися, що він має бажаний ефект, і застосуйте новий крок.
- Додайте крок Видаліть спеціальні символи.
- Виберіть Сума позову і, щоб бути точнішим, виберіть Користувацькі спеціальні символи І введіть
$та цінності Введіть власні спеціальні символи.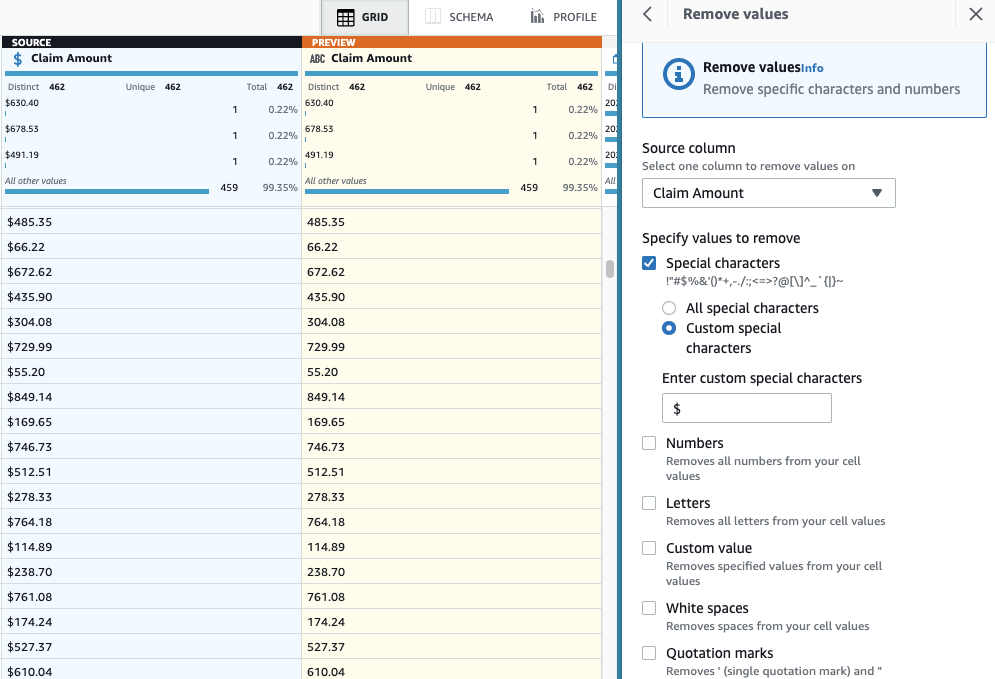
- Додавати Змінити тип наступити на колону Сума позову І вибирай подвійний як тип.
- Як останній крок, щоб видалити зайвий префікс «code», додайте a Замінити значення або шаблон крок.
- Виберіть колонку Код діагнозу, А для Введіть спеціальне значення, введіть
code(з пробілом у кінці).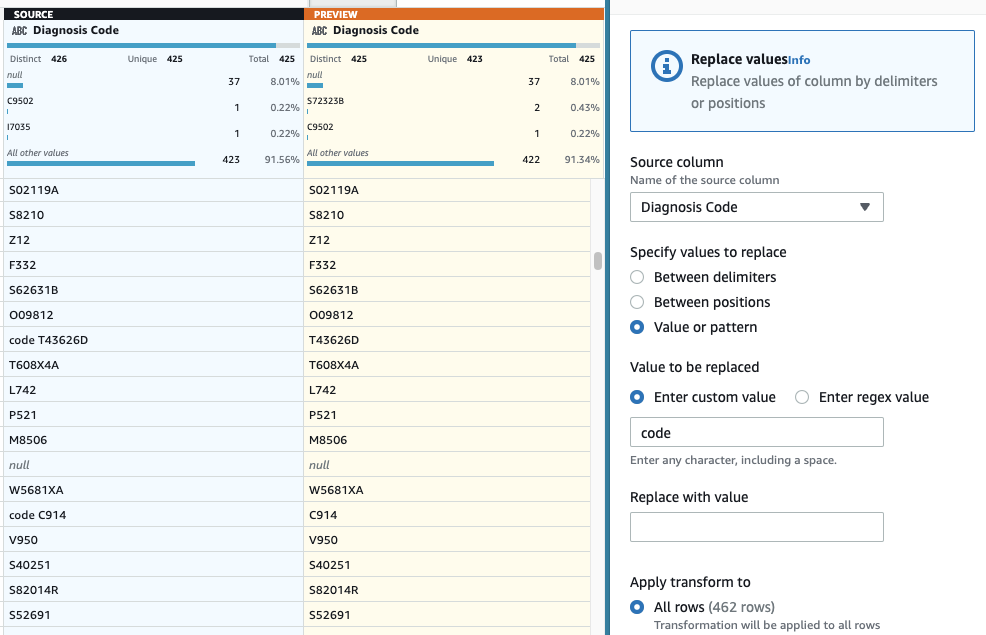
Тепер, коли ви усунули всі проблеми з якістю даних, виявлені у зразку, опублікуйте проект як рецепт.
- Вибирати Публікувати в Рецепт введіть додатковий опис і завершіть публікацію.
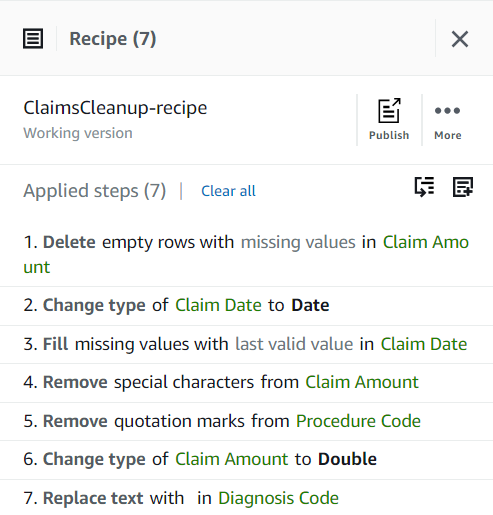
Кожного разу, коли ви публікуєте, створюватиметься інша версія рецепту. Пізніше ви зможете вибрати, яку версію рецепту використовувати.
Створіть візуальне завдання ETL в AWS Glue Studio
Далі ви створюєте завдання, яке використовує рецепт. Виконайте наступні дії:
- На консолі AWS Glue Studio виберіть Візуальний ETL у навігаційній панелі.
- Вибирати Візуал із чистим полотном і створити візуальну роботу.
- У верхній частині вакансії замініть «Вакансія без назви» назвою на свій вибір.
- на опис роботи на вкладці вкажіть роль, яку використовуватиме завдання.
Це має бути Управління ідентифікацією та доступом AWS (Я Є) роль підходить для клею AWS з дозволами на Amazon S3 і AWS Glue Data Catalog. Зауважте, що роль, яку раніше використовували для DataBrew, не можна використовувати для виконання завдань, тому її не буде вказано в Роль IAM спадне меню тут.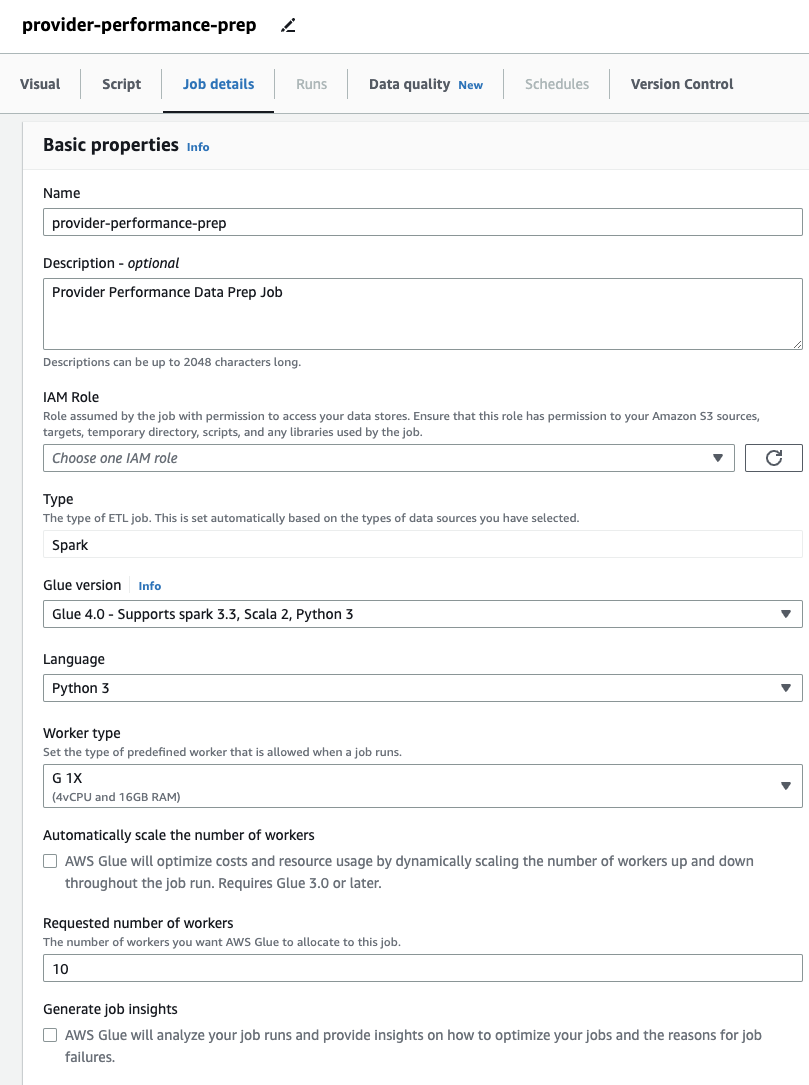
Якщо ви раніше використовували лише завдання DataBrew, зауважте, що в AWS Glue Studio ви можете вибрати параметри продуктивності та вартості, зокрема розмір робочої частини, автоматичне масштабування та Гнучке виконання, а також використовувати останню версію середовища виконання AWS Glue 4.0 і отримати переваги від значних покращень продуктивності, які вона забезпечує. Для цієї роботи ви можете використовувати параметри за замовчуванням, але зменшіть потрібну кількість працівників з міркувань економії. Для цього прикладу підійде два робітника. - на Візуальний вкладку, додайте джерело S3 і назвіть його
Providers. - для S3 URL, введіть
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.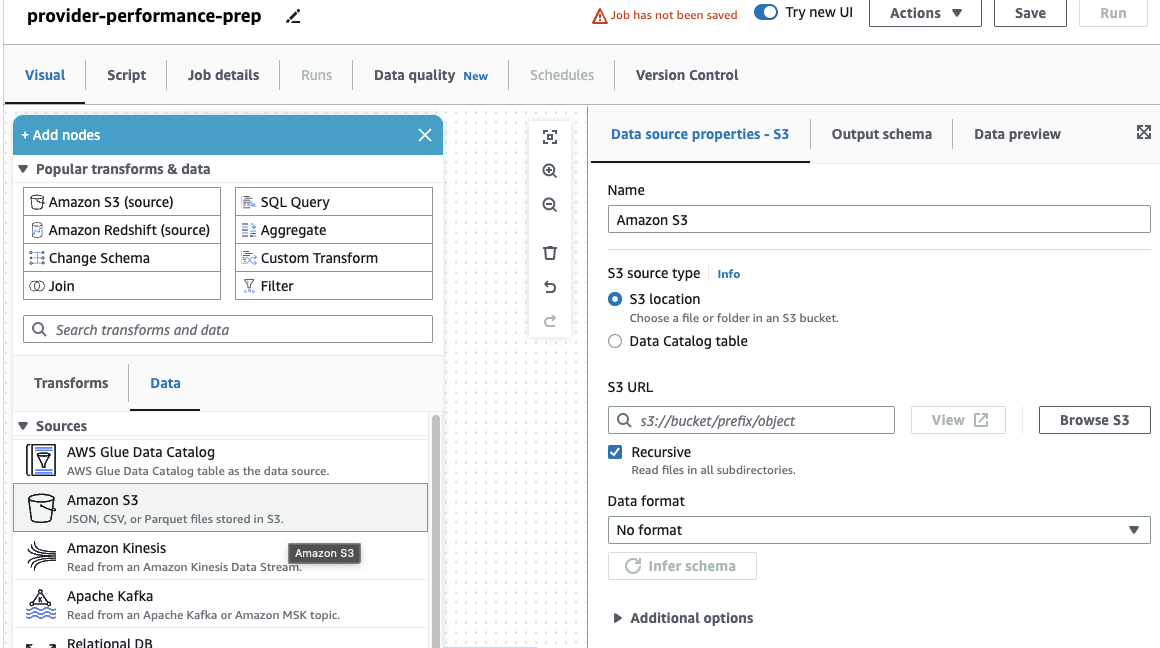
- Виберіть формат як CSV І вибирай Виведіть схему.
Тепер схема перерахована на Схема виведення за допомогою заголовка файлу.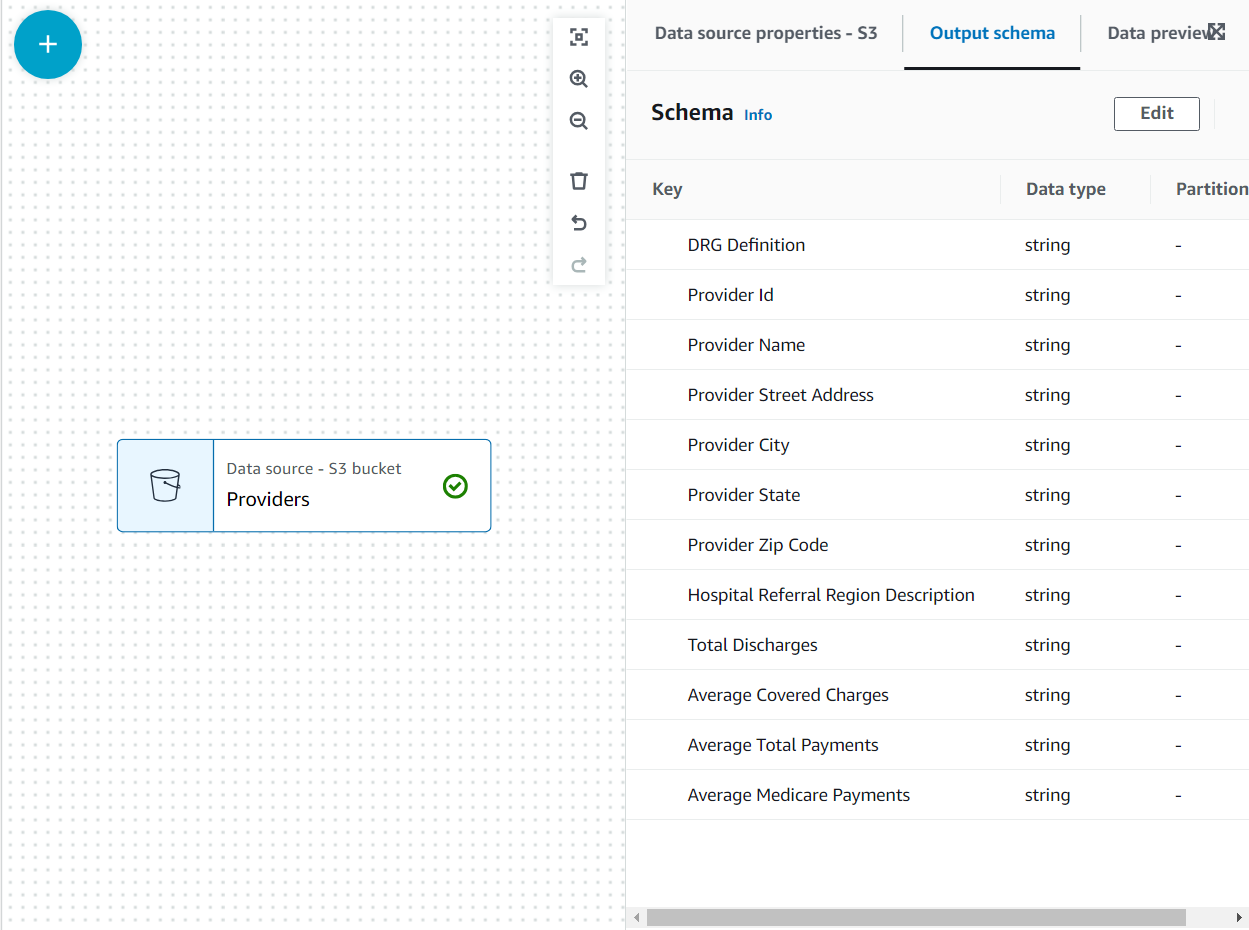
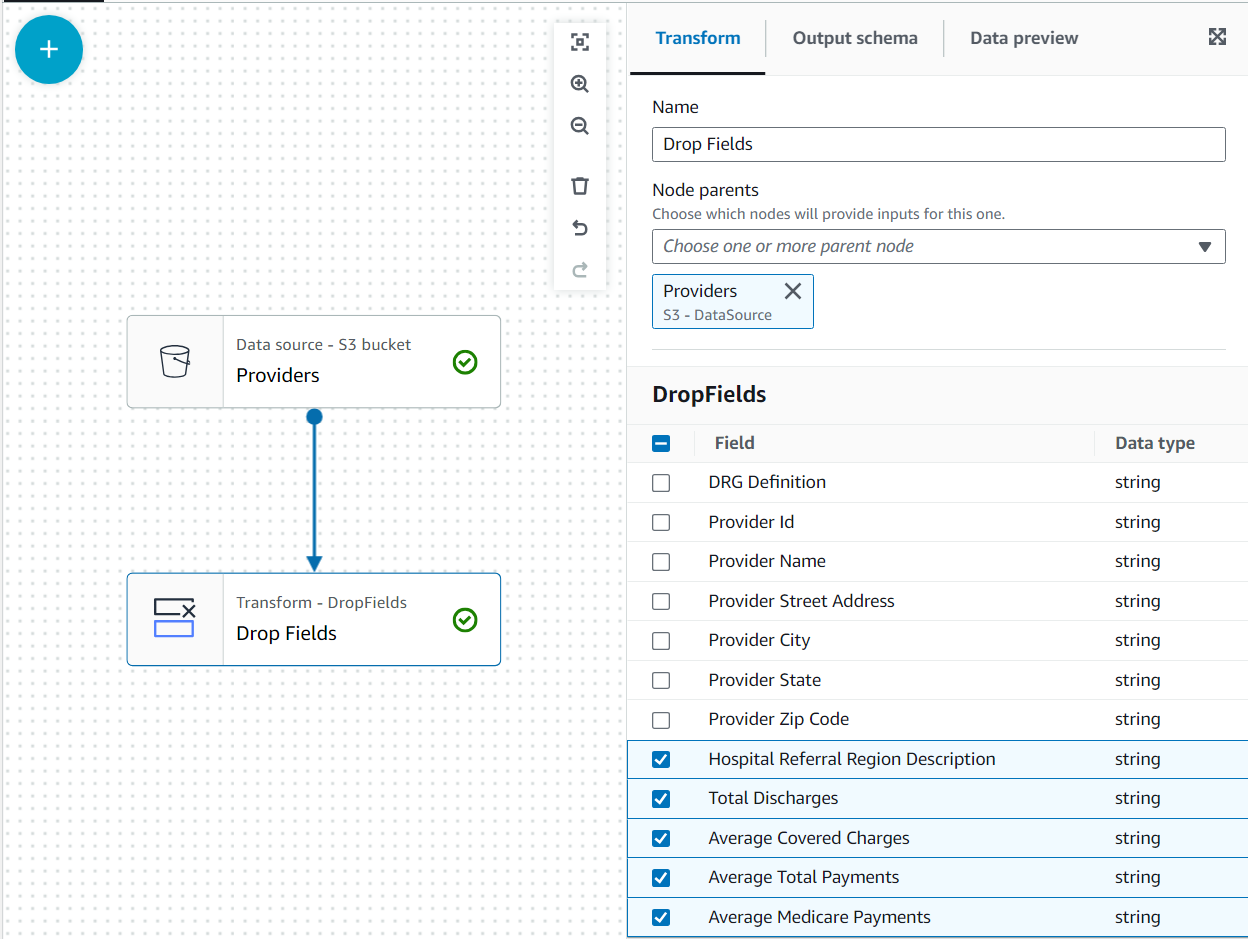
У цьому випадку використання рішення полягає в тому, що не всі стовпці в наборі даних провайдерів потрібні, тому ми можемо відкинути решту.
- З Провайдери вибрано вузол, додайте a Опустіть поля transform (якщо ви не вибрали батьківський вузол, він його не матиме; у такому випадку призначте батьківський вузол вручну).
- Виберіть усі поля після Поштовий індекс постачальника.
Пізніше ці дані будуть додані претензіями штату Алабама за допомогою постачальника; однак цей другий набір даних не має зазначеного стану. Ми можемо використовувати знання даних, щоб оптимізувати об’єднання, фільтруючи дані, які нам дійсно потрібні.
- Додавати фільтр трансформуватися як дитина Опустіть поля.
- Назвіть це
Alabama providersі додайте умову, якій має відповідати станAL.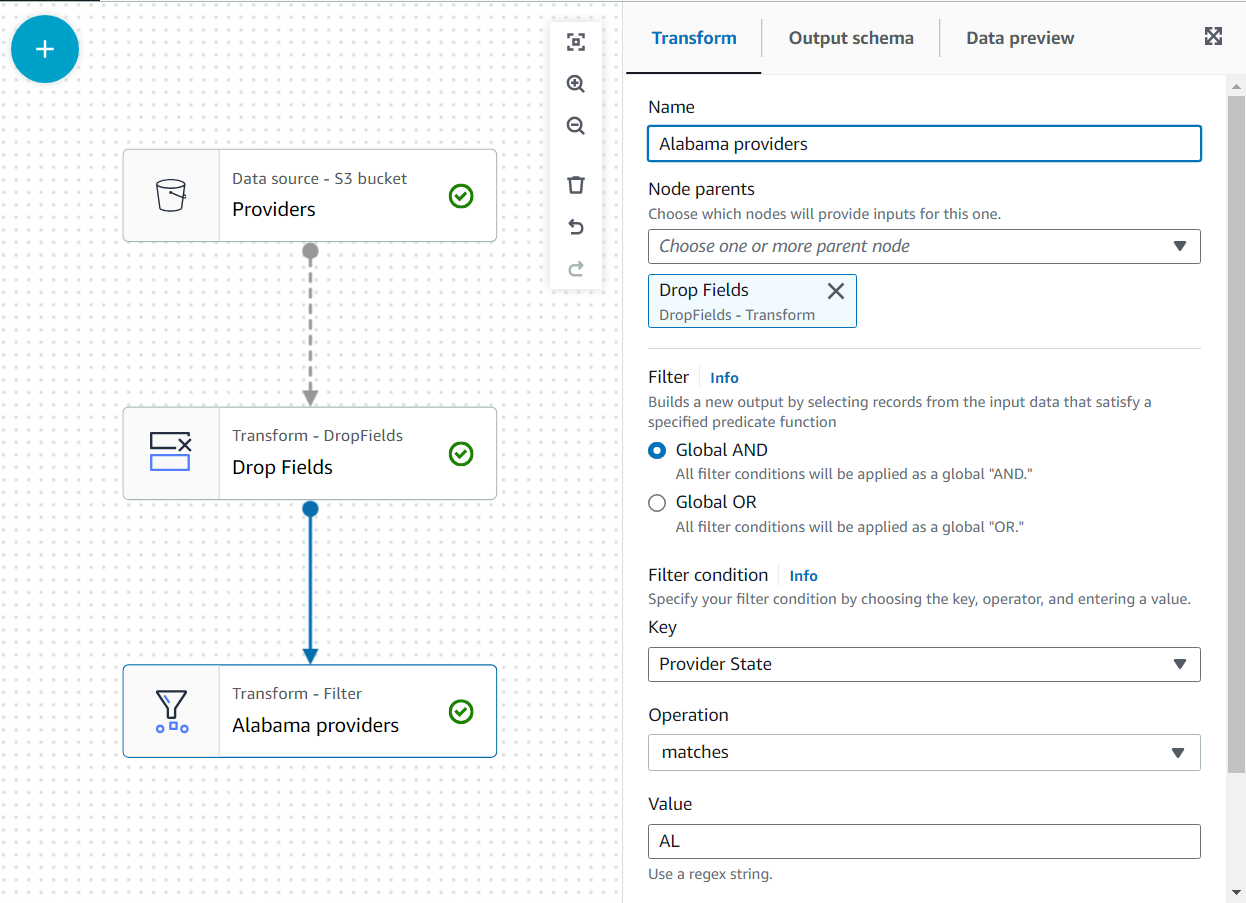
- Додайте друге джерело (нове джерело S3) і назвіть його
Alabama claims. - Для входу S3 URL, відкрийте DataBrew на окремій вкладці веб-переглядача, виберіть «Набори даних» на панелі навігації та скопіюйте в таблицю розташування, указане в таблиці для Алабама стверджує (скопіюйте текст, що починається з s3://, а не пов’язане посилання http). Потім поверніться до візуального завдання, вставте його як S3 URL; якщо це правильно, ви побачите в Схема виведення перелічені поля даних.
- Виберіть формат CSV і виведіть схему так само, як і з іншим джерелом.
- Як дочірній елемент цього джерела, шукайте в Додайте вузли меню для
recipeІ вибирай Рецепт підготовки даних.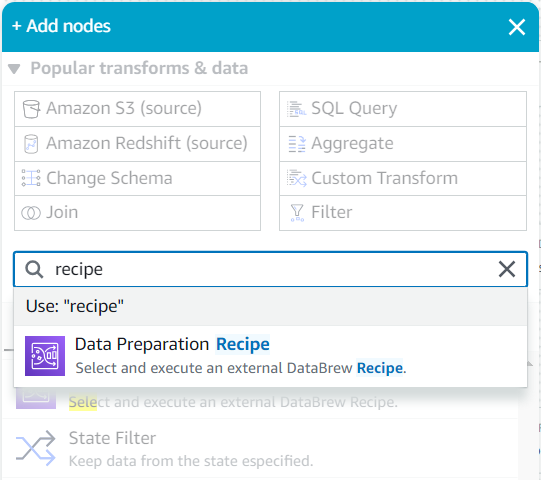
- У властивостях цього нового вузла дайте йому назву
Claim cleanup recipeі виберіть рецепт і версію, які ви опублікували раніше. - Ви можете переглянути кроки рецепта тут і скористатися посиланням на DataBrew, щоб внести зміни, якщо це необхідно.
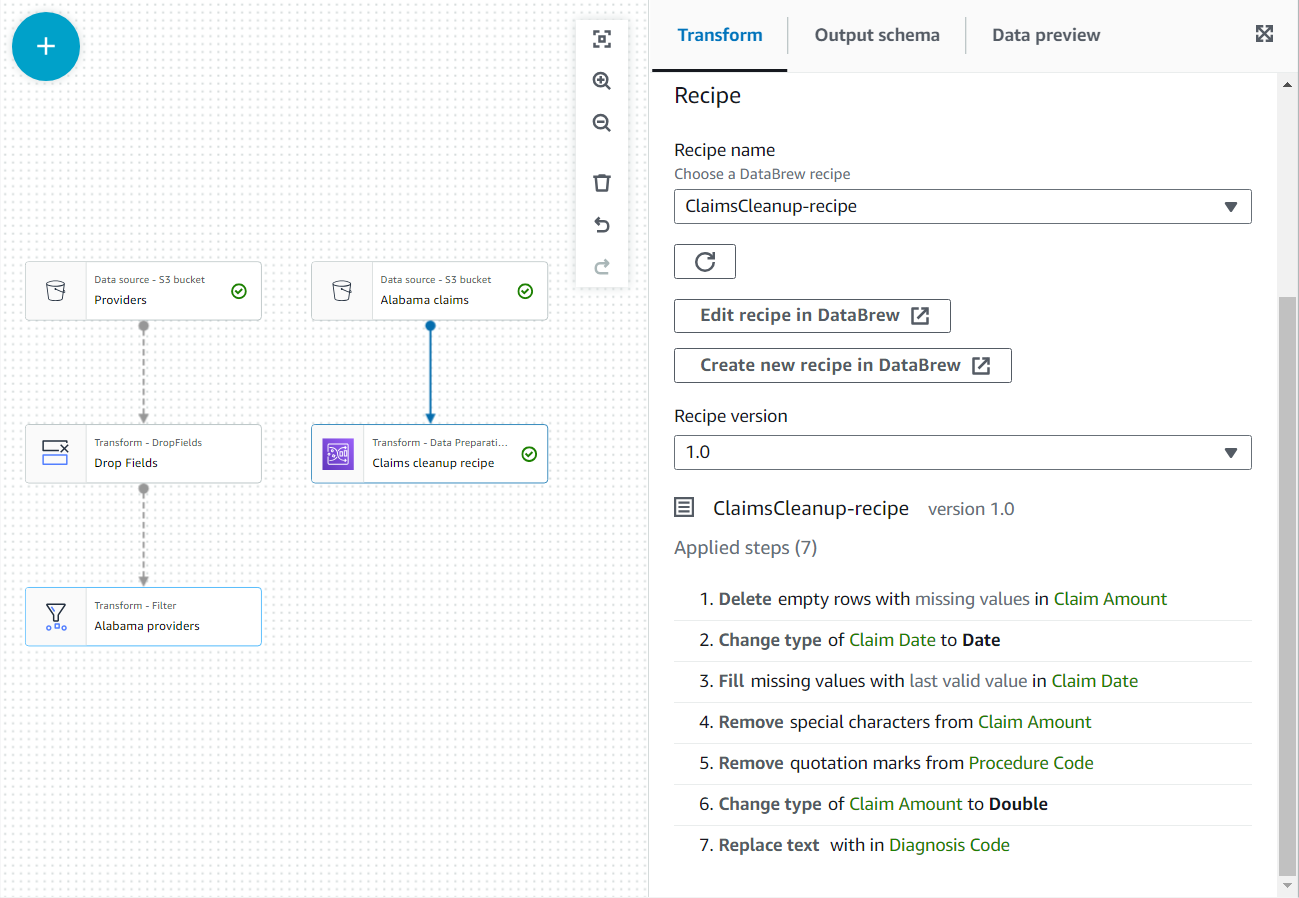
- Додавати Приєднайся до вузол і виберіть обидва Провайдери штату Алабама та Вимагайте рецепти очищення як батько.
- Додайте умову приєднання, що дорівнює ідентифікатору постачальника з обох джерел.
- На останньому кроці додайте вузол S3 як ціль (зверніть увагу, що під час пошуку першим є вузол; переконайтеся, що ви вибрали версію, яка вказана як ціль).
- У конфігурації вузла залиште формат за замовчуванням JSON і введіть URL-адресу S3, на яку роль вакансії має дозвіл на запис.
Крім того, зробіть вихідні дані доступними у вигляді таблиці в каталозі.
- У Параметри оновлення каталогу даних виберіть другий варіант Створіть таблицю в каталозі даних і під час наступних запусків оновіть схему та додайте нові розділи, а потім виберіть базу даних, у якій ви маєте дозвіл створювати таблиці.
- Призначити
alabama_claimsяк ім'я і вибрати Дата претензії як ключ розділу (це для ілюстрації; крихітна таблиця, як ця, насправді не потребує розділів, якщо подальші дані не будуть додані пізніше).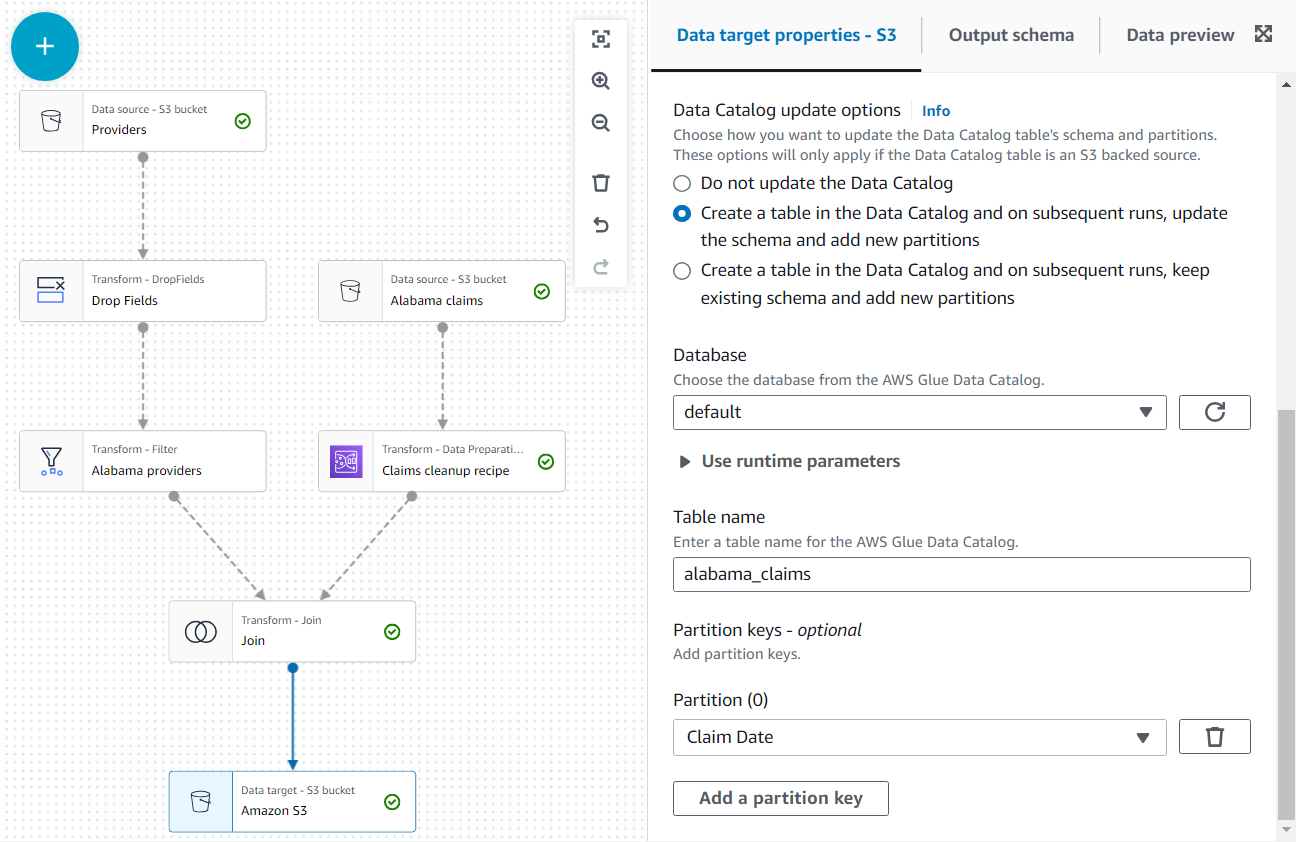
- Тепер ви можете зберегти та запустити завдання.
- на Runs Ви можете відстежувати процес і переглядати детальні показники роботи за допомогою посилання ID завдання.
Робота має тривати кілька хвилин.
- Коли завдання буде завершено, перейдіть до консолі Athena.
- Пошук столу
alabama_claimsу вибраній базі даних і за допомогою контекстного меню виберіть Таблиця попереднього перегляду, який виконуватиме простий оператор SELECT * SQL для таблиці.
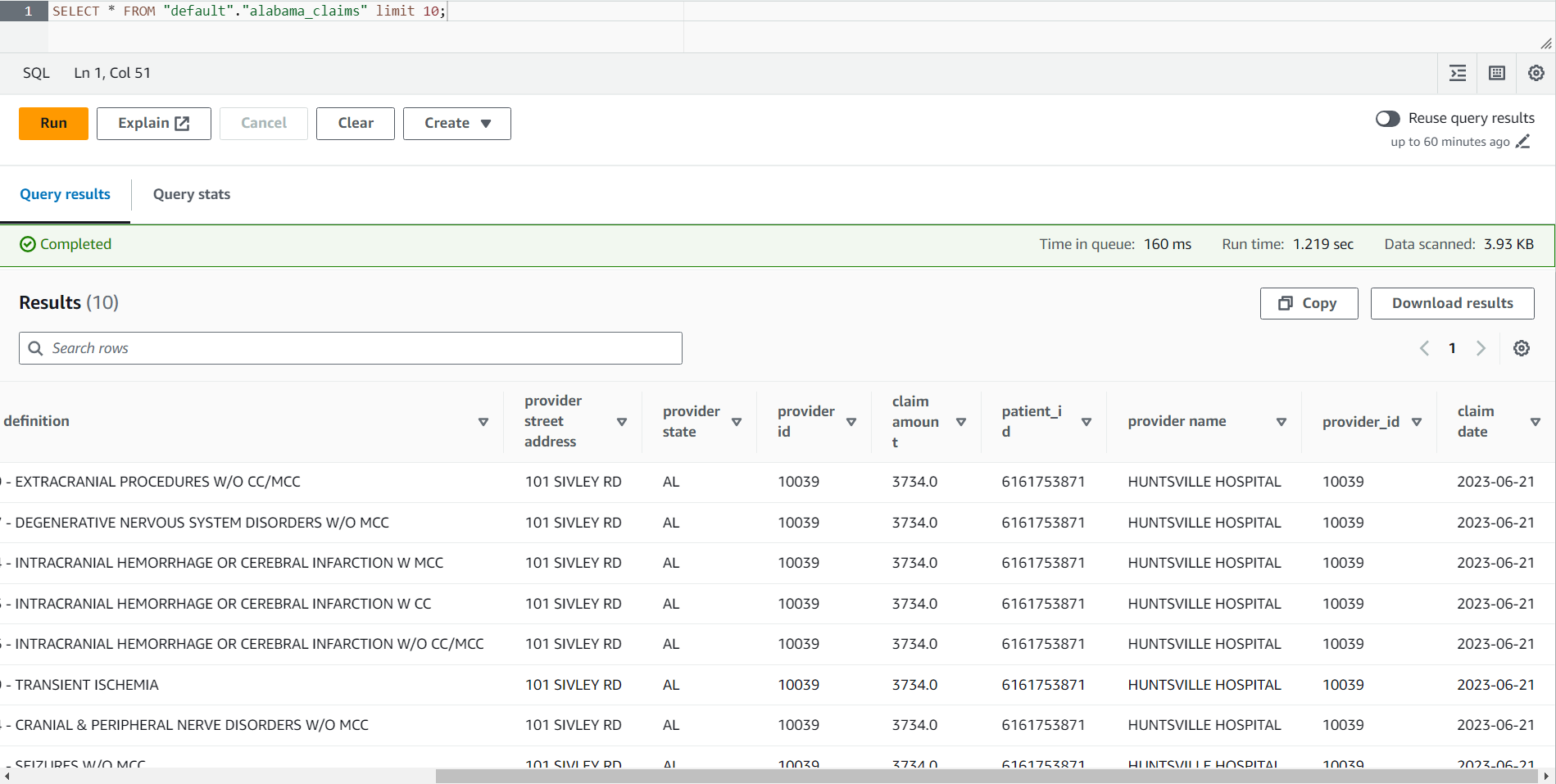
Ви можете побачити в результаті завдання, що дані були очищені за рецептом DataBrew і збагачені об’єднанням AWS Glue Studio.
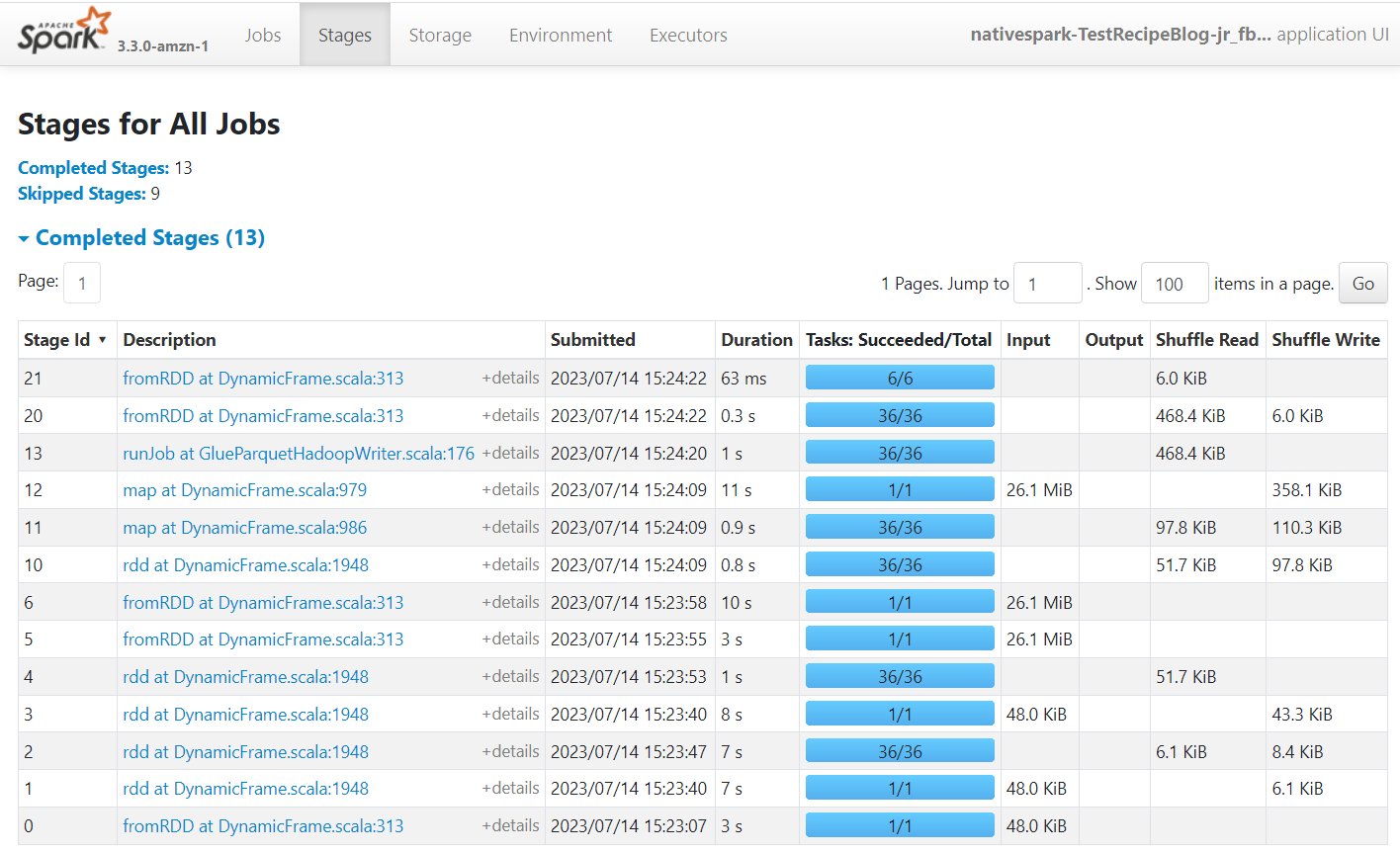
Apache Spark — це механізм, який запускає завдання, створені в AWS Glue Studio. За допомогою інтерфейсу користувача Spark у журналах подій, які він створює, ви можете переглядати статистику щодо плану роботи та запуску, що може допомогти вам зрозуміти, як виконується ваша робота та потенційні вузькі місця продуктивності. Наприклад, для цього завдання на великому наборі даних ви можете порівняти вплив явної фільтрації стану постачальника перед виконанням об’єднання або визначити, чи можете ви отримати користь від додавання перетворення автобалансу для покращення паралелізму.
За замовчуванням завдання зберігатиме журнали подій Apache Spark у шляху s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Щоб переглядати завдання, потрібно встановити сервер історії за допомогою один із доступних методів.
Прибирати
Якщо вам більше не потрібне це рішення, ви можете видалити файли, створені на Amazon S3, таблицю, створену завданням, рецепт DataBrew і завдання AWS Glue.
Висновок
У цій публікації ми показали, як ви можете використовувати AWS DataBrew для створення рецепта за допомогою наданого інтерактивного редактора, а потім використовувати опублікований рецепт як частину візуального ETL-завдання AWS Glue Studio. Ми включили кілька прикладів типових завдань, які потрібні під час підготовки даних і введення даних у таблиці AWS Glue Catalog.
У цьому прикладі використано один рецепт у візуальному завданні, але можна використовувати кілька рецептів на різних етапах процесу ETL, а також повторно використовувати той самий рецепт у кількох завданнях.
Ці рішення AWS Glue дозволяють ефективно створювати просунуті конвеєри ETL, які легко створювати та підтримувати без написання коду. Ви можете почати створювати рішення, які поєднують обидва інструменти вже сьогодні.
Про авторів
 Михайло Смирнов є старшим розробником програмного забезпечення в команді AWS Glue і частиною команди розробників AWS Glue DataBrew. Поза роботою його інтереси включають навчання гри на гітарі та подорожі з родиною.
Михайло Смирнов є старшим розробником програмного забезпечення в команді AWS Glue і частиною команди розробників AWS Glue DataBrew. Поза роботою його інтереси включають навчання гри на гітарі та подорожі з родиною.
 Гонсало Еррерос є старшим архітектором великих даних у команді AWS Glue. Перебуваючи в Дубліні, Ірландія, він допомагає клієнтам досягти успіху з рішеннями для великих даних на основі AWS Glue. У вільний час він любить настільні ігри та катається на велосипеді.
Гонсало Еррерос є старшим архітектором великих даних у команді AWS Glue. Перебуваючи в Дубліні, Ірландія, він допомагає клієнтам досягти успіху з рішеннями для великих даних на основі AWS Glue. У вільний час він любить настільні ігри та катається на велосипеді.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. Автомобільні / електромобілі, вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- BlockOffsets. Модернізація екологічної компенсаційної власності. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- : має
- :є
- : ні
- $UP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- Здатний
- МЕНЮ
- прийнятний
- прийнятий
- доступ
- рахунки
- дію
- фактичний
- додавати
- доданий
- додати
- доповнення
- адреса
- просунутий
- після
- Алабама
- ВСІ
- дозволяти
- Також
- Amazon
- Amazon Web Services
- суми
- an
- аналітики
- та
- будь-який
- Apache
- Apache Spark
- додаток
- Застосовувати
- ЕСТЬ
- AS
- асоційований
- At
- автор
- автоматичний
- автоматичний
- доступний
- AWS
- Клей AWS
- назад
- заснований
- BE
- перед тим
- буття
- користь
- Переваги
- Великий
- Великий даних
- порожній
- рада
- Настільні ігри
- закладки
- обидва
- Приносить
- браузер
- будувати
- але
- by
- CAN
- можливості
- випадок
- каталог
- Клітини
- централізована
- зміна
- Зміни
- символи
- дитина
- вибір
- Вибирати
- стверджувати
- претензій
- код
- Колонка
- Колони
- об'єднувати
- майбутній
- загальний
- порівняти
- повний
- Компоненти
- комп'ютер
- стан
- конфігурація
- Вважати
- складається
- Консоль
- контекст
- конвертувати
- перероблений
- виправити
- Відповідний
- Коштувати
- може
- створювати
- створений
- створення
- створення
- виготовлений на замовлення
- Клієнти
- дані
- Підготовка даних
- обробка даних
- якість даних
- Database
- набори даних
- Дата
- Дати
- день
- угода
- вирішувати
- рішення
- дефолт
- демонструвати
- description
- бажаний
- докладно
- деталі
- DEV
- розробка
- команда розвитку
- DID
- різний
- чіткий
- розподіл
- do
- Ні
- справи
- Долар
- подвійний
- Падіння
- Дублін
- кожен
- легко
- редактор
- ефект
- фактично
- дозволяє
- кінець
- двигун
- інженер
- Збагачений
- збагачення
- Що натомість? Створіть віртуальну версію себе у
- помилка
- істотний
- Ефір (ETH)
- оцінювати
- Навіть
- Event
- Кожен
- кожен день
- приклад
- Приклади
- існуючий
- додатково
- витяг
- сім'я
- далеко
- риси
- кілька
- Поля
- філе
- Файли
- заповнювати
- фільтрувати
- фільтрація
- в кінці кінців
- Перший
- потім
- після
- для
- формат
- від
- далі
- Games
- генерується
- Давати
- великий
- Мати
- he
- допомога
- допомагає
- тут
- його
- історія
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- IAM
- ID
- ідентифікований
- ідентифікувати
- Особистість
- if
- Impact
- удосконалювати
- поліпшення
- in
- включати
- включені
- У тому числі
- зазначений
- вхід
- розуміння
- встановлювати
- екземпляр
- інтегрований
- інтеграція
- інтерактивний
- інтерес
- інтереси
- інтерфейс
- в
- введені
- інтуїтивний
- Ірландія
- питання
- IT
- ЙОГО
- робота
- Джобс
- приєднатися
- приєднався
- JPG
- json
- просто
- тримати
- ключ
- знання
- великий
- більше
- найбільших
- останній
- пізніше
- останній
- вивчення
- Залишати
- як
- Ймовірно
- LINK
- Перераховані
- загрузка
- розташування
- логіка
- довше
- підтримувати
- зробити
- РОБОТИ
- вручну
- матч
- медичний
- Меню
- метод
- методика
- Метрика
- протокол
- відсутній
- монітор
- більше
- множинний
- повинен
- ім'я
- Переміщення
- навігація
- Необхідність
- необхідний
- потреби
- Нові
- немає
- вузол
- Зверніть увагу..
- зараз
- номер
- of
- on
- ONE
- тільки
- відкрити
- Оптимізувати
- варіант
- Опції
- or
- порядок
- Інше
- наші
- вихід
- поза
- над
- загальний
- pane
- частина
- частини
- шлях
- продуктивність
- виконанні
- дозвіл
- Дозволи
- план
- plato
- Інформація про дані Платона
- PlatoData
- Play
- це можливо
- пошта
- потенціал
- підготовка
- попередній перегляд
- попередні перегляди
- процес
- обробка
- випускає
- проект
- властивості
- за умови
- Постачальник
- провайдери
- забезпечує
- Публікація
- публікувати
- опублікований
- мета
- цілей
- якість
- лапки
- насправді
- розумний
- рецепт
- Рецепти
- зменшити
- відображати
- регіон
- реєструючий
- доречний
- видаляти
- замінювати
- просив
- вимагається
- вимога
- відповідно
- REST
- результат
- результати
- знову використовувати
- огляд
- Роль
- прогін
- пробіжки
- то ж
- зберегти
- шкала
- Масштабування
- Пошук
- другий
- розділ
- побачити
- бачачи
- обраний
- окремий
- Послуги
- Сесія
- комплект
- налаштування
- Повинен
- показав
- показаний
- підпис
- значний
- простий
- один
- Розмір
- невеликий
- So
- так далеко
- Софтвер
- рішення
- Рішення
- деякі
- Source
- Джерела
- Простір
- Іскритися
- спеціальний
- конкретний
- зазначений
- SQL
- старт
- Починаючи
- стан
- Заява
- статистика
- Крок
- заходи
- зберігання
- зберігати
- просто
- рядок
- студія
- наступні
- процвітати
- такі
- підходящий
- РЕЗЮМЕ
- Переконайтеся
- синтетичний
- таблиця
- Приймати
- Мета
- завдання
- команда
- перевірений
- Що
- Команда
- Джерело
- Держава
- Їх
- потім
- Там.
- це
- три
- час
- до
- сьогодні
- інструмент
- інструменти
- топ
- трек
- Перетворення
- Перетворення
- перетворень
- Подорож
- два
- тип
- ui
- при
- розуміти
- Оновити
- оновлений
- URL
- корисний
- використання
- використання випадку
- використовуваний
- користувачі
- використовує
- використання
- ПЕРЕВІР
- значення
- Цінності
- перевірити
- версія
- вид
- видимий
- хотіти
- було
- способи
- we
- Web
- веб-сервіси
- ДОБРЕ
- були
- коли
- який
- волі
- з
- без
- Work
- робочий
- робочі
- робочий
- б
- запис
- лист
- ви
- вашу
- зефірнет
- Zip