Як часто проекти машинного навчання успішно розгортаються? Не досить часто. Є багато of промисловість дослідження показ що проекти ML зазвичай не приносять прибутків, але мало хто оцінює співвідношення невдач і успіху з точки зору спеціалістів із обробки даних – людей, які розробляють ті самі моделі, які ці проекти мають розгортати.
слідом за опитування спеціалістів із обробки даних який я провів з KDnuggets минулого року, цьогорічного провідного дослідження Data Science Survey Rexer Analytics, яку проводить консалтингова компанія з машинного навчання, розглянула це питання – частково тому, що Карл Рексер, засновник і президент компанії, дозволив вашій справді взяти участь, спонукаючи до включення питань про успішне розгортання (частина моєї роботи під час однорічної роботи професора аналітики, яку я обіймав в УВА Дарден).
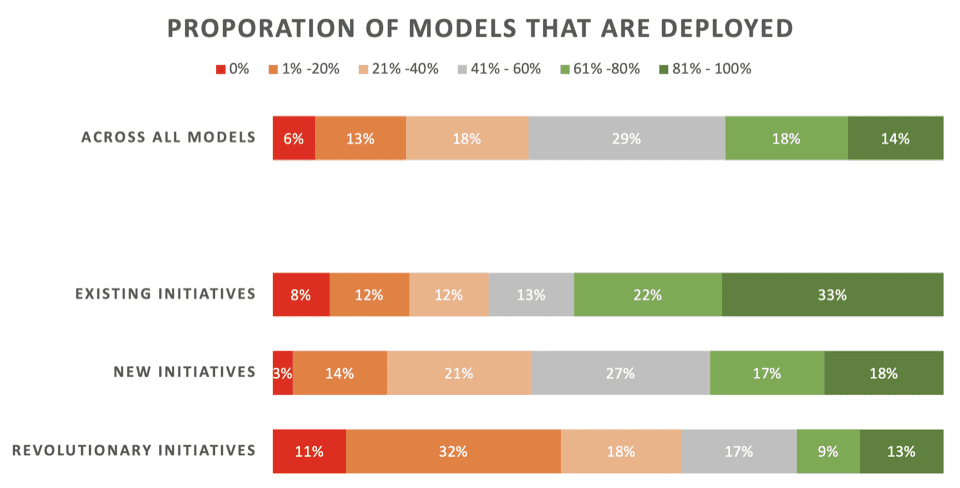
Новини не чудові. Лише 22% дослідників даних кажуть, що їхні «революційні» ініціативи – моделі, розроблені для впровадження нових процесів чи можливостей – зазвичай застосовуються. 43% кажуть, що 80% або більше не вдається розгорнути.
Через всі види проектів машинного навчання, включаючи оновлення моделей для існуючих розгортань, лише 32% кажуть, що їхні моделі зазвичай розгортаються.
Ось детальні результати цієї частини опитування, представлені компанією Rexer Analytics, з розподілом показників розгортання за трьома видами ініціатив МЛ:
Умовні позначення:
- Існуючі ініціативи: Моделі, розроблені для оновлення/оновлення існуючої моделі, яка вже була успішно розгорнута
- Нові ініціативи: Моделі, розроблені для покращення існуючого процесу, для якого ще не було розгорнуто жодної моделі
- Революційні ініціативи: Моделі, розроблені для створення нових процесів або можливостей
На мій погляд, ця боротьба за розгортання випливає з двох основних факторів: ендемічного недостатнього планування та відсутності конкретної видимості зацікавлених сторін у бізнесі. Багато фахівців з обробки даних і бізнес-лідерів не усвідомлюють, що передбачувана реалізація ML має бути спланована дуже детально та активно здійснюватися з самого початку кожного проекту ML.
Фактично, я написав нову книгу саме про це: The AI Playbook: Оволодіння рідкісним мистецтвом розгортання машинного навчання. У цій книзі я представляю шестиетапну практику, орієнтовану на розгортання, для впровадження проектів машинного навчання від концепції до розгортання, яку я називаю bizML (попередньо замовте тверду обкладинку або електронну книгу та отримайте безкоштовну розширену копію версії аудіокниги зразу).
Ключова зацікавлена сторона проекту ML – особа, відповідальна за операційну ефективність, яку необхідно покращити, наприклад керівник напряму діяльності – потребує чіткого уявлення про те, як саме ML покращить їхню діяльність і яку цінність очікується від покращення. Їм це потрібно, щоб остаточно дати дозвіл на розгортання моделі, а також щоб перед цим зважити виконання проекту на всіх етапах перед розгортанням.
Але продуктивність ML часто не вимірюється! Коли опитування Rexer запитало: «Як часто ваша компанія/організація оцінює ефективність аналітичних проектів?» лише 48% дослідників даних сказали «Завжди» або «Здебільшого». Це досить дико. Це має бути більше 99% або 100%.
І коли продуктивність вимірюється, то це з точки зору технічних показників, які є загадковими та здебільшого не мають відношення до зацікавлених сторін у бізнесі. Науковці даних знають краще, але зазвичай не дотримуються – частково, оскільки інструменти ML зазвичай обслуговують лише технічні показники. Згідно з опитуванням, спеціалісти з обробки даних оцінюють такі ключові показники ефективності бізнесу, як ROI та дохід, як найважливіші показники, але вони вказують технічні показники, такі як підйом і AUC, як найбільш часто вимірювані.
Технічні показники продуктивності «фундаментально марні для зацікавлених сторін у бізнесі та не пов’язані з ними», відповідно до Harvard Data Science Review. Ось чому: вони лише кажуть вам відносний продуктивність моделі, наприклад її порівняння з припущенням або іншою базовою лінією. Бізнес-метрики говорять вам про це абсолютний бізнес-цінність, яку очікується від моделі, або, під час оцінки після розгортання, що вона довела, що це забезпечує. Такі показники необхідні для проектів ML, орієнтованих на розгортання.
Окрім доступу до бізнес-метрик, бізнес-стейкхолдерам також потрібно наростити. Коли опитування Rexer запитало: «Чи менеджери та особи, які приймають рішення у вашій організації, які повинні схвалити розгортання моделі, достатньо обізнані, щоб приймати такі рішення з достатньою інформацією?» лише 49% респондентів відповіли «Здебільшого» або «Завжди».
Ось що, на мою думку, відбувається. «Клієнт» фахівця з обробки даних, зацікавлена сторона в бізнесі, часто охолоне, коли справа доходить до дозволу на розгортання, оскільки це означатиме внесення значних операційних змін у хліб з маслом компанії, її найбільш масштабні процеси. Вони не мають контекстної рамки. Наприклад, вони дивуються: «Як я можу зрозуміти, наскільки ця модель, яка за своїми характеристиками далеко не досконала, як кришталева куля, насправді допоможе?» Таким чином проект гине. Тоді творче додавання певного позитивного ефекту до «отриманих ідей» служить для того, щоб акуратно заховати невдачу під килим. Ажіотаж ШІ залишається незмінним, навіть якщо потенційна цінність, мета проекту, втрачається.
Щодо цієї теми – заохочення зацікавлених сторін – я викладу свою нову книгу, Посібник зі штучним інтелектом, ще раз. Охоплюючи практику bizML, книга також підвищує кваліфікацію бізнес-професіоналів, надаючи життєво важливу, але дружню дозу напівтехнічних базових знань, необхідних усім зацікавленим сторонам, щоб керувати проектами машинного навчання або брати участь у них від кінця до кінця. Це об’єднує бізнес-професіоналів і фахівців із обробки даних, щоб вони могли тісно співпрацювати, спільно встановлюючи точні для прогнозування чого покликане машинне навчання, наскільки добре воно прогнозує та як його прогнози застосовуються для покращення операцій. Ці основні принципи створюють або руйнують кожну ініціативу – правильне їхнє використання прокладає шлях до розгортання машинного навчання, орієнтованого на цінності.
Можна з упевненістю сказати, що тут все складно, особливо для нових ініціатив МЛ, які вперше пробують. Оскільки абсолютна сила штучного інтелекту втрачає здатність постійно надолужувати
менше реалізованої вартості, ніж обіцяно, буде все більше і більше тиску, щоб довести операційну цінність ML.? Тож я кажу: випередьте це зараз – почніть прищеплювати ефективнішу культуру співпраці між підприємствами та орієнтоване на розгортання керівництво проектом!
Для більш детальних результатів з Наукове дослідження даних Rexer Analytics за 2023 рік, Натисніть тут. Це найбільше опитування професіоналів із науки про дані та аналітики в галузі. Він складається приблизно з 35 відкритих запитань із вибіркою відповідей, які охоплюють набагато більше, ніж лише рівень успішності розгортання – сім загальних галузей науки та практики інтелектуального аналізу даних: (1) Область і цілі, (2) Алгоритми, (3) Моделі, ( 4) Інструменти (використані пакети програмного забезпечення), (5) Технологія, (6) Виклики та (7) Майбутнє. Він проводиться як послуга (без корпоративного спонсорства) для наукової спільноти даних, а результати зазвичай оголошуються на конференція Machine Learning Week і розповсюджуються у вільно доступних підсумкових звітах.
Ця стаття є результатом роботи автора, який протягом одного року обіймав посаду професора аналітики з нагоди 200-річчя тіла в Дарденській школі бізнесу UVA, яка зрештою завершилася публікацією The AI Playbook: Оволодіння рідкісним мистецтвом розгортання машинного навчання (пропозиція безкоштовної аудіокниги).
Ерік Зігель, Ph.D., є провідним консультантом і колишнім професором Колумбійського університету, який робить машинне навчання зрозумілим і захоплюючим. Він є засновником Світ прогнозної аналітики і Світ глибокого навчання серії конференцій, які обслуговували понад 17,000 2009 відвідувачів з XNUMX року, інструктор відомого курсу Лідерство та практика машинного навчання – наскрізна майстерність, популярний оратор, якого замовляли Понад 100 основних виступівта виконавчий редактор Часи машинного навчання. Він автор бестселера Прогнозна аналітика: можливість передбачити, хто натисне, купить, збреше чи помре, який використовувався в курсах у понад 35 університетах, і він отримав нагороди за викладання, коли був професором Колумбійського університету, де він співав навчальні пісні своїм учням. Ерік також публікує доповіді з аналітики та соціальної справедливості. Слідуйте за ним @predictanalytic.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- : має
- :є
- : ні
- :де
- $UP
- 000
- 1
- 17
- 35%
- 7
- a
- здатність
- МЕНЮ
- доступ
- відомий
- За
- через
- насправді
- адресований
- просунутий
- після
- агресивно
- попереду
- AI
- алгоритми
- ВСІ
- дозволено
- вже
- Також
- завжди
- am
- an
- Аналітичний
- аналітика
- та
- оголошений
- Інший
- схвалювати
- приблизно
- Arcane
- ЕСТЬ
- області
- Art
- стаття
- AS
- At
- учасники
- аук
- автор
- доступний
- нагороди
- геть
- фон
- Базова лінія
- BE
- оскільки
- було
- перед тим
- Вірити
- бестселер
- Краще
- книга
- Хліб
- Перерва
- Розрив
- бізнес
- Бізнес-лідери
- але
- купити
- by
- call
- званий
- CAN
- можливості
- захоплююча
- проблеми
- зміна
- заряд
- вибір
- клацання
- клієнт
- холодний
- співпрацювати
- співробітництво
- Columbia
- COM
- Приходити
- приходить
- зазвичай
- співтовариство
- компанія
- Компанії
- дизайн
- бетон
- проводиться
- конференція
- складається
- консультування
- консультант
- контекстуальний
- безперестанку
- внесок
- Корпоративний
- курс
- курси
- обкладинка
- покриття
- Творчо
- cs
- культура
- дані
- видобуток даних
- наука про дані
- вчений даних
- ті що приймають рішення
- рішення
- глибоко
- доставляти
- надання
- розгортання
- розгорнути
- розгортання
- розгортання
- деталь
- докладно
- розвивати
- розвиненою
- відключившись
- do
- робить
- Дон
- Не знаю
- доза
- вниз
- водіння
- під час
- кожен
- редактор
- Ефективний
- ефективність
- включіть
- кінець
- кінець в кінець
- ендемічний
- підвищувати
- досить
- Еріком
- особливо
- істотний
- необхідності
- налагодження
- Ефір (ETH)
- оцінки
- Навіть
- Кожен
- приклад
- виконання
- виконавчий
- існуючий
- очікуваний
- факт
- фактори
- FAIL
- Провал
- далеко
- ноги
- кілька
- поле
- стежити
- для
- Примусово
- Колишній
- засновник
- Рамки
- Безкоштовна
- вільно
- дружній
- від
- майбутнє
- отримала
- Загальне
- в цілому
- отримати
- отримання
- Цілі
- великий
- Відбувається
- Мати
- he
- Герой
- допомога
- його
- його
- Як
- HTML
- HTTP
- HTTPS
- обман
- i
- IBM
- важливо
- удосконалювати
- поліпшення
- in
- початок
- У тому числі
- включення
- промисловість
- провідний в галузі
- Ініціатива
- ініціативи
- розуміння
- призначених
- в
- вводити
- isn
- IT
- ЙОГО
- просто
- тільки один
- Карл
- KDnuggets
- ключ
- Лейтмотив
- Дитина
- Знати
- знання
- не вистачає
- найбільших
- останній
- Минулого року
- вести
- Лідери
- Керівництво
- провідний
- вивчення
- брехня
- як
- список
- ll
- Втрачає
- втрачений
- машина
- навчання за допомогою машини
- головний
- зробити
- РОБОТИ
- Робить
- менеджер
- Менеджери
- манера
- багато
- Освоєння
- значити
- означав
- вимір
- виміряний
- Метрика
- Mining
- MIT
- ML
- модель
- Моделі
- більше
- найбільш
- в основному
- багато
- множинний
- повинен
- my
- Необхідність
- потреби
- Нові
- новини
- немає
- зараз
- of
- часто
- on
- ONE
- ті,
- тільки
- оперативний
- операції
- or
- порядок
- організація
- з
- пакети
- сторінка
- частина
- брати участь
- мостить
- досконалість
- продуктивність
- виступає
- людина
- перспектива
- запланований
- plato
- Інформація про дані Платона
- PlatoData
- штекер
- популярний
- положення
- позитивний
- потенціал
- влада
- практика
- Попереднє замовлення
- дорогоцінний
- точно
- передбачати
- Прогнози
- Прогнози
- представлений
- президент
- тиск
- досить
- процес
- процеси
- Product
- професіонали
- Професор
- проект
- проектів
- пообіцяв
- Доведіть
- доведений
- Публікація
- Видає
- мета
- Ставить
- Поклавши
- питання
- питань
- Рамп
- пандус
- ранжувати
- РІДНІ
- ставки
- співвідношення
- досягати
- зрозумів,
- визнавати
- залишається
- Звіти
- респонденти
- результати
- Умови повернення
- revenue
- революційний
- право
- скелястий
- ROI
- звичайно
- прогін
- s
- сейф
- Зазначений
- то ж
- say
- шкала
- Школа
- наука
- вчений
- Вчені
- Серія
- служити
- служив
- служить
- обслуговування
- сім
- загальні
- значний
- з
- So
- соціальна
- Софтвер
- деякі
- Гучномовець
- Спін
- спонсорство
- етапи
- зацікавлені сторони
- зацікавлених сторін
- старт
- стебла
- Як і раніше
- боротьба
- Студентам
- успіх
- успішний
- Успішно
- такі
- РЕЗЮМЕ
- Огляд
- Розгортки
- T
- цільове
- Навчання
- технічний
- Технологія
- сказати
- terms
- ніж
- Що
- Команда
- їх
- Їх
- потім
- Там.
- Ці
- вони
- це
- три
- по всьому
- Таким чином
- час
- до
- інструменти
- тема
- по-справжньому
- два
- Зрештою
- при
- розуміти
- зрозуміло
- університети
- університет
- на
- використовуваний
- приведення в дію
- зазвичай
- значення
- Ve
- дуже
- через
- вид
- видимість
- життєво важливий
- було
- шлях..
- week
- важать
- ДОБРЕ
- Що
- коли
- який
- в той час як
- ВООЗ
- чому
- Wild
- волі
- з
- без
- Виграв
- дивуватися
- Work
- б
- письмовий
- рік
- ще
- ви
- вашу
- зефірнет