Daha yetenekli, daha hızlı, daha küçük ve daha düşük güçlü sistemlere doğru ilerleyen Moore Yasası, yazılıma 30 yılı aşkın bir süre boyunca tamamen yarı iletken süreç evrimi konusunda ücretsiz bir yolculuk sağladı. Bilgi işlem donanımı her yıl iyileştirilmiş performans/alan/güç ölçümleri sunarak yazılımın karmaşıklık açısından genişlemesine ve hiçbir olumsuzluk olmadan daha fazla yetenek sunmasına olanak tanıdı. Daha sonra kolay zaferler daha az kolay hale geldi. Daha gelişmiş süreçler, birim alan başına daha yüksek kapı sayıları sağlamaya devam etti ancak performans ve güçteki kazanımlar azalmaya başladı. Yenilik beklentilerimiz durmadığından, donanım mimarisindeki ilerlemeler bu boşluğu doldurmada daha önemli hale geldi.

Çekirdek sayısını artırmaya yönelik sürücüler
Bu yönde atılan ilk adımlardan biri, çekirdekler arasında eş zamanlı görevlerin bir karışımını iş parçacığı veya sanallaştırma yoluyla toplam verimi hızlandırmak için çok çekirdekli CPU'ların kullanılmasıydı; etkin olmayan çekirdeklerin rölantiye alınması veya kapatılmasıyla ihtiyaç duyulan gücün azaltılması. Çok çekirdekli çekirdek günümüzde standarttır ve çok çekirdekli (bir çip üzerinde daha da fazla CPU) trendi, AWS, Azure, Alibaba ve diğerlerinin bulut platformlarında bulunan sunucu örneği seçeneklerinde zaten belirgindir.
Çok/çok çekirdekli mimariler ileriye doğru bir adımdır ancak CPU kümeleri aracılığıyla paralellik kaba tanelidir ve Amdahl yasası sayesinde kendi performans ve güç sınırlarına sahiptir. Mimariler daha heterojen hale geldi; görüntü, ses ve diğer özel ihtiyaçlar için hızlandırıcılar eklendi. Yapay zeka hızlandırıcıları ayrıca sistolik dizilere ve alana özgü diğer tekniklere geçerek ince taneli paralelliği de zorladı. Bu, ChatGPT'nin 175 milyar parametreyle ortaya çıkmasına ve GPT-3'ün 4 trilyon parametreli (bugünün yapay zeka sistemlerinden çok daha karmaşık olan) GPT-100'e dönüşmesine ve yapay zeka hızlandırıcılarında daha özel hızlandırma özelliklerini zorlayana kadar oldukça iyi çalışıyordu.
Farklı bir açıdan bakıldığında, otomotiv uygulamalarındaki çoklu sensör sistemleri artık daha iyi çevre bilinci ve geliştirilmiş PPA için tek SoC'lere entegre ediliyor. Burada otomotivdeki yeni özerklik seviyeleri, birden fazla sensör türünden gelen girdilerin 2X, 4X veya 8X oranında kopyalanan alt sistemlerde tek bir cihazda birleştirilmesine bağlıdır.
Michał Siwinski'ye (Arteris'in CMO'su) göre, geniş bir uygulama yelpazesinde birden fazla tasarım ekibiyle bir aydan fazla süren tartışmalardan alınan örnekler, bu ekiplerin yetenek, performans ve güç hedeflerini karşılamak için aktif olarak daha yüksek çekirdek sayılarına yöneldiğini gösteriyor. Bana bu eğilimin hızlandığını gördüklerini söyledi. Süreç ilerlemeleri hala SoC kapı sayımlarına yardımcı oluyor ancak performans ve güç hedeflerini karşılama sorumluluğu artık kesin olarak mimarların elinde.
Daha fazla çekirdek, daha fazla ara bağlantı
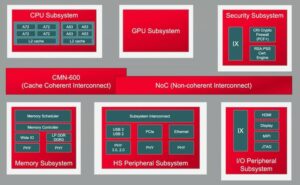
Bir çip üzerinde daha fazla çekirdek, bu çekirdekler arasında daha fazla veri bağlantısı anlamına gelir. Komşu işleme elemanları arasında bir hızlandırıcı içinde, yerel önbelleğe, seyrek matris için hızlandırıcılara ve diğer özel işlemlere. Hızlandırıcı kutucukları ve sistem düzeyi veri yolları arasına hiyerarşik bağlantı ekleyin. Çip üzerinde ağırlık depolama, sıkıştırmayı açma, yayınlama, toplama ve yeniden sıkıştırma için bağlantı ekleyin. Çalışma önbelleği için HBM bağlantısı ekleyin. Gerekirse bir füzyon motoru ekleyin.
CPU tabanlı kontrol kümesinin bu çoğaltılmış alt sistemlerin her birine ve tüm olağan işlevlere (codec'ler, bellek yönetimi, güvenlik adası ve uygunsa güven kökü, çoklu çipli bir uygulama ise UCIe, yüksek bant genişliğine sahip I/O için PCIe) bağlanması gerekir. ve ağ iletişimi için Ethernet veya fiber.
Bu, ürünün pazarlanabilirliği açısından doğrudan sonuçları olan çok fazla ara bağlantı demektir. 16nm'nin altındaki süreçlerde NoC altyapısı artık alana %10-12 katkıda bulunuyor. Daha da önemlisi, çekirdekler arasındaki iletişim yolu olduğundan performans ve güç üzerinde önemli bir etkiye sahip olabilir. Optimumun altında bir uygulamanın, beklenen mimari performansını ve güç kazanımlarını israf etmesi veya daha da kötüsü, çok sayıda yeniden tasarım döngüsünün birbirine yaklaşmasıyla sonuçlanması tehlikesi vardır. Ancak karmaşık bir SoC kat planında iyi bir uygulama bulmak, halihazırda sıkı olan tasarım programlarında yavaş deneme yanılma optimizasyonlarına bağlıdır. Karmaşık NoC hiyerarşilerinden tam performansı ve güç desteğini garanti etmek için fiziksel olarak duyarlı NoC tasarımına geçiş yapmamız ve bu optimizasyonları daha hızlı yapmamız gerekiyor.
Fiziksel olarak farkında olan NoC tasarımları Moore yasasını yolunda tutuyor
Moore yasası ölmemiş olabilir ancak günümüzde performans ve güçteki ilerlemeler süreçten ziyade mimariden ve NoC ara bağlantısından geliyor. Mimari, daha fazla hızlandırıcı çekirdeği, hızlandırıcıların içinde daha fazla hızlandırıcıyı ve çip üzerinde daha fazla alt sistem çoğaltmasını zorluyor. Bunların hepsi çip üzerindeki ara bağlantının karmaşıklığını artırır. Tasarımlar çekirdek sayısını artırıp 16 nm ve altındaki proses geometrilerine geçtikçe, SoC ve alt sistemlerini kapsayan çok sayıda NoC ara bağlantısı, yalnızca fiziksel olarak bilinçli ağ aracılığıyla fiziksel ve zamanlama kısıtlamalarına karşı en iyi şekilde uygulandığında bu karmaşık tasarımların tam potansiyelini destekleyebilir. çip tasarımında.
Siz de bu trendler konusunda endişeleniyorsanız Arteris FlexNoC 5 IP teknolojisi hakkında daha fazla bilgi edinmek isteyebilirsiniz. İŞTE.
Bu gönderiyi şu yolla paylaş:
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :dır-dir
- $UP
- 100
- a
- Hakkımızda
- hızlandırmak
- hızlanan
- hızlanma
- hızlandırıcı
- hızlandırıcılar
- karşısında
- aktif
- ileri
- gelişmeler
- karşı
- AI
- AI sistemleri
- Alibaba
- Türkiye
- Izin
- zaten
- ve
- çıktı
- uygulamaları
- uygun
- mimari
- ARE
- ALAN
- AS
- At
- ses
- otomotiv
- mevcut
- farkındalık
- AWS
- masmavi
- Bant genişliği
- BE
- müşterimiz
- altında
- arasında
- Milyar
- yayın
- Otobüsler
- by
- önbellek
- CAN
- yetenekli
- ChatGPT
- yonga
- bulut
- Küme
- CMO
- nasıl
- Yakın İletişim
- karmaşık
- karmaşıklık
- hesaplamak
- eşzamanlı
- Sosyal medya
- Bağlantılar
- Bağlantı
- Sonuçları
- kısıtlamaları
- devam
- kontrol
- yakınsamak
- çekirdek
- işlemci
- TEHLİKE
- veri
- ölü
- teslim etmek
- teslim edilen
- bağlıdır
- Dizayn
- tasarımlar
- cihaz
- farklı
- direkt
- yön
- tartışmalar
- aşağı
- olumsuzlukları
- her
- Erken
- elemanları
- Motor
- çevre
- Hatta
- Her
- evrim
- gelişen
- Genişletmek
- beklentileri
- beklenen
- Daha hızlı
- Özellikler
- bulma
- sıkıca
- İçin
- ileri
- Ücretsiz
- itibaren
- ön
- tam
- fonksiyonlar
- füzyon
- Kazançlar
- Goller
- Tercih Etmenizin
- garanti
- kullanma
- Eller
- donanım
- Var
- yardım et
- okuyun
- Yüksek
- daha yüksek
- Karayolu
- HTTPS
- görüntü
- darbe
- uygulama
- uygulanan
- önemli
- gelişmiş
- in
- pasif
- Artırmak
- artan
- Altyapı
- Yenilikçilik
- örnek
- Bütünleştirme
- IP
- ada
- IT
- ONUN
- atlama
- Kanun
- ÖĞRENİN
- seviye
- seviyeleri
- sınırları
- yerel
- Çok
- yapmak
- yönetim
- Mart
- Matris
- maksimum genişlik
- Neden
- toplantı
- Bellek
- Metrikleri
- olabilir
- Ay
- Daha
- hareket
- hareketli
- çoklu
- gerek
- gerekli
- ihtiyaçlar
- ağ
- ağ
- yeni
- sayısız
- of
- on
- Opsiyonlar
- emir
- Diğer
- Diğer
- kendi
- parametreler
- performans
- fiziksel
- fiziksel olarak
- Platformlar
- Platon
- Plato Veri Zekası
- PlatoVeri
- Çivi
- potansiyel
- güç kelimesini seçerim
- Açılması
- güzel
- süreç
- Süreçler
- işleme
- PLATFORM
- yalnızca
- itti
- itme
- menzil
- daha doğrusu
- gerçek
- azaltarak
- çoğaltılmış
- kopya
- sorumluluk
- sonuç
- Binmek
- kök
- Güvenlik
- yarıiletken
- önemli
- beri
- tek
- gevşek
- yavaş
- daha küçük
- So
- Yazılım
- seyrek matris
- özel
- spot
- standart
- başladı
- adım
- Yine
- dur
- hafızası
- Önerdi
- destek
- sistem
- Sistemler
- görevleri
- takım
- teknikleri
- Teknoloji
- anlatır
- o
- The
- Bunlar
- İçinden
- verim
- zamanlama
- için
- bugün
- bugünkü
- Toplam
- eğilim
- Trendler
- Trilyon
- Güven
- Dönüş
- türleri
- altında
- birim
- üzerinden
- ağırlık
- İYİ
- hangi
- geniş
- Geniş ürün yelpazesi
- irade
- Kazandı
- ile
- içinde
- çalışma
- yıl
- yıl
- zefirnet