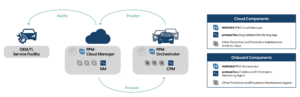
RISC-V ในฐานะสถาปัตยกรรมชุดคำสั่ง (ISA) เติบโตอย่างรวดเร็วในด้านความสำคัญเชิงพาณิชย์และความเกี่ยวข้องนับตั้งแต่เปิดตัวสู่ชุมชนเปิดในปี 2015 โดยดึงดูดผู้จำหน่าย IP จำนวนมากที่ปัจจุบันให้บริการคอร์ RTL ที่หลากหลาย โรเจอร์ เอสปาซา ซีอีโอและผู้ก่อตั้ง กึ่งไดนามิกส์ได้นำเสนอในงาน RISC-V เกี่ยวกับวิธีการปรับแต่ง IP ของตนสำหรับความท้าทายในการประมวลผลที่ต้องใช้แบนด์วิธสูงและแกนประมวลผลประสิทธิภาพสูงพร้อมหน่วยเวกเตอร์ Semidynamics ก่อตั้งขึ้นในปี 2016 โดยมีบาร์เซโลนาเป็นสำนักงานใหญ่ และมีลูกค้าอยู่ในสหรัฐอเมริกาและเอเชียแล้ว โดยนำเสนอ RISC-V IP ที่ปรับแต่งได้สองรายการ:
- Avispado – RISCV64GCV ตามลำดับ รองรับ AXI และ CHI
- Atrevido – RISCV64GC ที่ไม่อยู่ในลำดับ รองรับ AXI และ CHI
CPU ทั่วไปมีคอร์ขนาดใหญ่จำนวนหนึ่งและแคชขนาดใหญ่ ทำให้ง่ายต่อการตั้งโปรแกรมแม้ว่าจะไม่ได้มีประสิทธิภาพสูงก็ตาม
ในทางตรงกันข้าม GPU มีคอร์ขนาดเล็กจำนวนมากที่ให้ประสิทธิภาพสูงสำหรับโค้ดแบบขนาน แต่จะยากกว่าในการตั้งโปรแกรมและเพิ่มเวลาแฝงในการสื่อสารผ่านบัส PCIe เมื่อข้อมูลจำเป็นต้องส่งไปมาระหว่าง CPU และ GPU

แนวทางที่ Espasa คือการใช้คอร์ RISC-V ที่เชื่อมต่อกับคอร์ประมวลผล ซึ่งทำให้ง่ายต่อการตั้งโปรแกรม ประสิทธิภาพที่สูงขึ้นสำหรับโค้ดแบบขนาน และเสนอเวลาแฝงในการสื่อสารเป็นศูนย์ CPU และหน่วยเวกเตอร์มอบสิ่งที่ดีที่สุดของทั้งสองโลก

ข้อกำหนด RISC-V บันทึกการลงทะเบียนเวกเตอร์ 32 รายการ และคุณสามารถเพิ่มแกนเวกเตอร์จำนวนหนึ่ง พร้อมกับการเชื่อมต่อกับแคชของคุณภายในหน่วยเวกเตอร์

ด้วย Semidynamics IP คุณสามารถปรับแต่งจำนวน Vector Cores ได้: 4, 8, 16, 32 อีกวิธีในการดูสิ่งนี้ก็คือ โปรดทราบว่า Vector Cores 4 ตัวเป็นแบบ 256 บิต สูงสุดถึง 32 Vector Cores ซึ่งเป็น 2,048 บิต
ผู้ใช้ IP ยังเลือกประเภทข้อมูล: FP64, FP32, FP16, BF16, INT64, INT32, INT16, INT8 สำหรับแอปพลิเคชัน AI พวกเขาอาจเลือกประเภทข้อมูล FP16, BF16 ในขณะที่แอปพลิเคชัน HPC สามารถเลือก FP64, FP32
การปรับแต่งประการที่สามคือ Vector Register Length ซึ่งเพื่อให้ได้ประสิทธิภาพที่มากขึ้นและพลังงานที่ต่ำกว่า คุณสามารถทำให้การลงทะเบียนเวกเตอร์มีขนาดใหญ่กว่าหน่วยเวกเตอร์ได้
นี่คือแผนภาพบล็อกของ Atrevideo 423-V8:

หน่วยเวกเตอร์ไม่อยู่ในลำดับโดยสิ้นเชิง ซึ่งเป็นลักษณะเฉพาะของผู้จำหน่าย IP RISC-V การรวมกันของหน่วยเวกเตอร์และหน่วย Gazzillion สามารถสตรีมข้อมูลที่มากกว่า 60 ไบต์/รอบ

เส้นสีม่วงแสดงประสิทธิภาพการอ่าน และใน L1 Cache คือ 20-60 ไบต์/รอบ เครื่องอื่นๆ แสดงแบนด์วิดท์ลดลงอย่างรวดเร็วหลังจากออกจาก L1 Cache ในขณะที่วิธีการนี้ดำเนินต่อไป โดยแบนราบที่ 56 แม้แต่ไปที่หน่วยความจำ DDR แสดงแบนด์วิธ 40 ด้วยอัตรานาฬิกา 1.0GHz ที่ทำให้แบนด์วิธ 40 GB/s
ลูกค้า IP สามารถเพิ่มโค้ด RTL ของตนเองที่เชื่อมต่อกับ Vector Unit เพื่อวัตถุประสงค์ของตนเองได้
ประสิทธิภาพการคูณเมทริกซ์มีความสำคัญในปริมาณงาน AI และใน OOO V8 Vector Unit จะมีจุดสูงสุดที่ 16 FP64 FLOPS/รอบ และ 99% ของจุดสูงสุดสำหรับขนาดเมทริกซ์ >= 400 สำหรับเมทริกซ์ขนาดเล็กขนาด 24×24 ประสิทธิภาพคือ 7 FP64 FLOPS/รอบ หรือ 50% ของจุดสูงสุด การคูณเมทริกซ์สำหรับ FP16 โดยใช้หน่วยเวกเตอร์ที่มี 8 แกนเวกเตอร์มีจุดสูงสุดที่ 64 FP16 FLOPS/รอบ และ 99% ของจุดสูงสุดสำหรับ M >= 600
เกณฑ์มาตรฐานการตรวจจับวัตถุแบบเรียลไทม์ที่เรียกว่า YOLO (คุณดูเพียงครั้งเดียว) ทำงานบนแพลตฟอร์ม Atrevido 423-V8 และแสดงให้เห็นประสิทธิภาพต่อแกนเวกเตอร์ที่สูงขึ้น 58% มากกว่าคู่แข่ง ผลลัพธ์เหล่านี้มีไว้สำหรับวิดีโอที่มี 24 เลเยอร์ 5.56 Gops/frame และพารามิเตอร์ประมาณ 9M

สรุป
การเลือกผู้จำหน่าย IP RISC-V นั้นเป็นงานที่ซับซ้อน ดังนั้นการทราบเกี่ยวกับผู้จำหน่ายเช่น Semidynamics สามารถช่วยให้คุณเข้าใจได้ดีขึ้นว่าแนวทางที่ปรับแต่งสามารถรันปริมาณงานเฉพาะของคุณได้อย่างมีประสิทธิภาพสูงสุดได้อย่างไร ด้วย Semidynamics คุณสามารถเลือกระหว่างตัวเลือกสถาปัตยกรรม เช่น เรียงลำดับหรือไม่เรียงลำดับ โดยมีหรือไม่มีหน่วยเวกเตอร์ก็ได้ ตัวเลขที่รายงานจากผู้ขาย IP รายนี้มีแนวโน้มที่ดี และฉันหวังว่าจะประกาศในอนาคตของพวกเขา
วิดีโอที่เกี่ยวข้อง
แชร์โพสต์นี้ผ่าน:
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. ยานยนต์ / EVs, คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ChartPrime. ยกระดับเกมการซื้อขายของคุณด้วย ChartPrime เข้าถึงได้ที่นี่.
- BlockOffsets การปรับปรุงการเป็นเจ้าของออฟเซ็ตด้านสิ่งแวดล้อมให้ทันสมัย เข้าถึงได้ที่นี่.
- ที่มา: https://semiwiki.com/ip/333718-risc-v-64-bit-ip-for-high-performance/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 16
- 200
- 2015
- 2016
- 24
- 32
- 40
- 60
- 7
- 8
- a
- เกี่ยวกับเรา
- เพิ่ม
- หลังจาก
- AI
- ตาม
- แล้ว
- ด้วย
- ในหมู่
- an
- และ
- ประกาศ
- อื่น
- การใช้งาน
- เข้าใกล้
- ในเชิงสถาปัตยกรรม
- สถาปัตยกรรม
- เป็น
- AS
- เอเชีย
- At
- การจูงใจ
- กลับ
- แบนด์วิดธ์
- บาร์เซโลนา
- BE
- มาตรฐาน
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ใหญ่
- ที่ใหญ่กว่า
- บิต
- ปิดกั้น
- ทั้งสอง
- รถบัส
- แต่
- by
- แคช
- ที่เรียกว่า
- CAN
- สามารถ
- ผู้บริหารสูงสุด
- ซีอีโอและผู้ก่อตั้ง
- ความท้าทาย
- ทางเลือก
- Choose
- นาฬิกา
- รหัส
- รหัส
- การผสมผสาน
- เชิงพาณิชย์
- การสื่อสาร
- ชุมชน
- คู่แข่ง
- ซับซ้อน
- คำนวณ
- งานที่เชื่อมต่อ
- การเชื่อมต่อ
- ตรงกันข้าม
- แกน
- ได้
- ซีพียู
- ลูกค้า
- ปรับแต่งได้
- การปรับแต่ง
- ปรับแต่ง
- การปรับแต่ง
- ข้อมูล
- การตรวจพบ
- เอกสาร
- หล่น
- ง่าย
- อย่างมีประสิทธิภาพ
- แม้
- เหตุการณ์
- สำหรับ
- ออกมา
- ข้างหน้า
- ก่อตั้งขึ้นเมื่อ
- ผู้สร้าง
- ราคาเริ่มต้นที่
- อย่างเต็มที่
- อนาคต
- ได้รับ
- ไป
- GPU
- เจริญเติบโต
- กำมือ
- ยาก
- มี
- ช่วย
- จุดสูง
- สูงกว่า
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HPC
- hq
- HTTPS
- i
- ความสำคัญ
- สำคัญ
- in
- ภายใน
- IP
- IT
- ITS
- jpg
- รู้ดี
- ใหญ่
- ความแอบแฝง
- ชั้น
- การออกจาก
- ความยาว
- กดไลก์
- Line
- ดู
- ลด
- เครื่อง
- ทำ
- ทำให้
- การทำ
- หลาย
- มดลูก
- ความกว้างสูงสุด
- อาจ..
- หน่วยความจำ
- นาที
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ความต้องการ
- หมายเหตุ
- ตอนนี้
- จำนวน
- ตัวเลข
- วัตถุ
- การตรวจจับวัตถุ
- of
- การเสนอ
- on
- ครั้งเดียว
- เพียง
- เปิด
- or
- ใบสั่ง
- อื่นๆ
- ออก
- เกิน
- ของตนเอง
- Parallel
- พารามิเตอร์
- ผ่าน
- จุดสูงสุด
- ต่อ
- การปฏิบัติ
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- บวก
- โพสต์
- อำนาจ
- นำเสนอ
- โครงการ
- แวว
- ให้
- ให้
- วัตถุประสงค์
- อย่างรวดเร็ว
- รวดเร็ว
- คะแนน
- อ่าน
- เรียลไทม์
- ทะเบียน
- ลงทะเบียน
- ปล่อย
- ความสัมพันธ์กัน
- รายงาน
- ต้องการ
- ผลสอบ
- วิ่ง
- ชุด
- โชว์
- แสดงให้เห็นว่า
- แสดงให้เห็นว่า
- ตั้งแต่
- ขนาด
- เล็ก
- So
- โดยเฉพาะ
- สเปค
- ที่พริ้ว
- ที่สนับสนุน
- งาน
- กว่า
- ที่
- พื้นที่
- บล็อก
- ของพวกเขา
- พวกเขา
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- ที่สาม
- นี้
- แต่?
- ตลอด
- ไปยัง
- สอง
- ชนิด
- ตามแบบฉบับ
- เข้าใจ
- เป็นเอกลักษณ์
- หน่วย
- หน่วย
- us
- ใช้
- ผู้ใช้
- การใช้
- ความหลากหลาย
- ผู้ขาย
- ผู้ขาย
- ผ่านทาง
- วีดีโอ
- คือ
- ทาง..
- คือ
- เมื่อ
- ที่
- ในขณะที่
- กับ
- ไม่มี
- ของโลก
- Yolo
- เธอ
- ของคุณ
- ลมทะเล
- เป็นศูนย์