การขูดเว็บอาจเป็นเครื่องมือที่มีประสิทธิภาพในการดึงข้อมูลจากเว็บไซต์ แต่ก็อาจเป็นกระบวนการที่ซับซ้อนและใช้เวลานานเช่นกัน โชคดีที่ Google ชีตนำเสนอโซลูชันที่เป็นมิตรกับผู้ใช้สำหรับการคัดลอกข้อมูลจากเว็บไซต์โดยไม่จำเป็นต้องเขียนโค้ดที่ซับซ้อน ด้วยการใช้ประโยชน์จากพลังของ Google ชีต คุณสามารถดึงข้อมูลจากหน้าเว็บและวิเคราะห์ข้อมูลด้วยวิธีต่างๆ ได้อย่างง่ายดาย ในบล็อกนี้ ฉันจะแนะนำคุณตลอดกระบวนการใช้ Google ชีตเพื่อขูดหน้าเว็บและช่วยคุณปลดล็อกศักยภาพของการขูดเว็บสำหรับโครงการของคุณเอง เริ่มกันเลย!
การขูดเว็บอาจใช้เวลานาน ซับซ้อน และเกี่ยวข้องกับการเขียนโค้ดจำนวนมาก สำหรับผู้ที่ไม่ได้เขียนโค้ด Google ชีตเป็นทางเลือกที่ยอดเยี่ยมสำหรับการขูดเว็บ การขูดเว็บของ Google ชีตไม่ต้องเขียนโค้ดและมีวิธีมากมายในการวิเคราะห์ข้อมูลเว็บไซต์
ในบล็อกนี้เราจะดูวิธีใช้ Google ชีตเพื่อขูดหน้าเว็บอย่างง่ายดาย เริ่มกันเลย!
เหตุใดจึงต้องใช้ Google ชีตสำหรับการขูดเว็บ
มีเหตุผลหลายประการที่ทำให้ Google ชีตเป็นเครื่องมือที่ยอดเยี่ยมสำหรับการขูดเว็บ:
- Google ชีตใช้งานง่ายและมีอินเทอร์เฟซที่คุ้นเคย
- ไม่จำเป็นต้องมีความรู้ด้านภาษาโปรแกรม
- Google ชีตสามารถเข้าถึงได้จากทุกที่
- Google ชีตใช้งานได้ฟรี ทำให้ราคาไม่แพงสำหรับบุคคลทั่วไปและธุรกิจขนาดเล็ก
- Google ทำงานร่วมกับเครื่องมือ Suite อื่นๆ ได้อย่างง่ายดาย
- คุณสามารถใช้มาโครหรือสคริปต์เพื่อทำงานการขูดเว็บโดยอัตโนมัติ
- คุณสามารถวิเคราะห์ข้อมูลที่คัดลอกมาได้อย่างง่ายดายโดยใช้สูตรของ Google ชีต
แยกข้อความจากหน้าเว็บใดก็ได้ในคลิกเดียว ตรงไปที่ Nanonets มีดโกนเว็บไซต์, เพิ่ม URL แล้วคลิก “ขูด” และดาวน์โหลดข้อความหน้าเว็บเป็นไฟล์ทันที ทดลองใช้ฟรีตอนนี้
ฟังก์ชั่นใดที่จะใช้สำหรับ Google Sheets Web Scraping
ต่อไปนี้คือฟังก์ชันบางอย่างที่คุณอาจใช้เมื่อต้องการขูดหน้าเว็บโดยใช้ Google ชีต
นำเข้าHTML:
แยกตารางและรายการออกจากหน้า HTML
=IMPORTHTML(url, query, index)- url: นี่คือลิงค์ของหน้าเว็บที่คุณต้องการคัดลอก
- คิวรี: ชนิดข้อมูล – ตาราง รายการ
- ดัชนี: หากคุณต้องการแยกตารางเฉพาะ คุณสามารถใช้สิ่งนี้ได้
ตัวอย่าง:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)","table",1)อิมพอร์ตเอ็กซ์เอ็มแอล:
แยกข้อมูลจากหน้า XML
=IMPORTXML(url, xpath_query)- url: นี่คือลิงค์ไปยังหน้าเว็บที่คุณต้องการคัดลอก
- xpath_query: นิพจน์ XPath ที่ระบุข้อมูลที่คุณต้องการแยก
ตัวอย่าง:
=IMPORTXML("https://www.w3schools.com/xml/note.xml", "//note/to")ข้อมูลนำเข้า:
แยกข้อมูลจากไฟล์ CSV และ TSV
=IMPORTDATA(url)- url: URL ของไฟล์ CSV หรือ TSV ที่คุณต้องการดึงข้อมูลออกมา
ตัวอย่าง:
=IMPORTDATA("https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-size-bands.csv")REGEXEXTRACT:
ฟังก์ชันนี้สามารถแยกข้อมูลที่ตรงกับรูปแบบนิพจน์ทั่วไป
=REGEXEXTRACT(text, regular_expression)- ข้อความ: ข้อความที่คุณต้องการค้นหารูปแบบ
- Regular_expression: รูปแบบที่คุณต้องการจับคู่
ตัวอย่าง:
=REGEXEXTRACT("1 pound = $1.40", "$d+.d+")หมายเหตุ: ฟังก์ชันเหล่านี้อาจใช้ไม่ได้กับทุกเว็บไซต์ ขึ้นอยู่กับเค้าโครงของเว็บไซต์ ในกรณีที่คุณต้องการข้อมูลเพิ่มเติม คุณสามารถใช้บทช่วยสอนการขูดเว็บโดยใช้ Python และ Java หรือใช้เครื่องมือเปลี่ยนเว็บไซต์เป็นข้อความ เช่น Nanonets
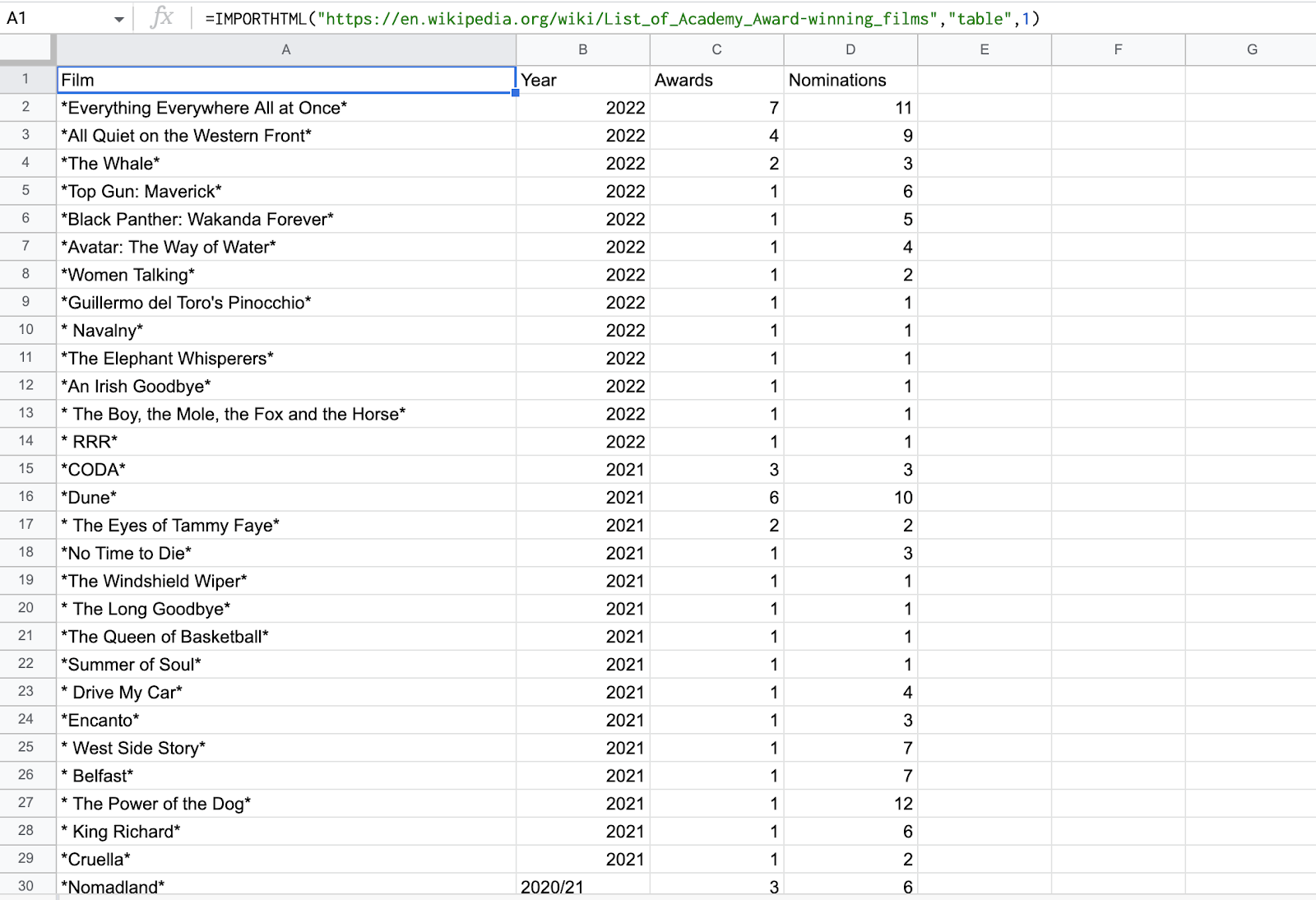
มาลองแยกตาราง HTML ลงใน Google ชีต เราจะพยายามขูดตารางจาก รายชื่อภาพยนตร์ที่ได้รับรางวัล Academy หน้า Wikipedia
- เปิด Google ชีต
- ในเซลล์ใหม่ ให้พิมพ์ =IMPORTHTML(url, query, index)
1. รหัสของเราจะกลายเป็น
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1) =IMPORTHTML(“https://th.wikipedia.org/wiki/List_of_Academy_Award-winning_films”,”ตาราง”,1)
จะขูดตารางแรกในหน้าวิกิพีเดีย
3. ตรวจสอบผลลัพธ์
จะขูดข้อมูลโดยใช้การขูดเว็บของ Google ชีตได้อย่างไร
มาดูวิธีขูดชื่อ คำอธิบาย H1 และอื่นๆ โดยใช้ Google ชีต เพื่อเริ่มต้นกับการขูด H1 ด้วย Google ชีต เราจะใช้ฟังก์ชัน IMPORTXML สำหรับสิ่งนี้โดยเฉพาะ หน้านาโนเน็ต. นี่คือขั้นตอน:
- เปิด Google ชีตใหม่หรือที่มีอยู่
- ในเซลล์ ให้พิมพ์สูตรต่อไปนี้:
=IMPORTXML(“https://nanonets.com/image-to-text”, “//h1/text()”)- ในการแยกแท็ก H1 ให้ใช้นิพจน์ XPath ต่อไปนี้: //h1/text()
- หากต้องการแยกแท็กชื่อ ให้ใช้นิพจน์ XPath ต่อไปนี้: //title/text()
- หากต้องการแยกแท็กคำอธิบายเมตา ให้ใช้นิพจน์ XPath ต่อไปนี้: //meta[@name='description']/@content
- หากต้องการแยกลิงก์ของเพจทั้งหมด ให้ใช้นิพจน์ XPath ต่อไปนี้: //a/@href
กด Enter แล้ว Google ชีตจะขูดข้อมูลโดยอัตโนมัติและแสดงในเซลล์ที่เลือก
จากนั้นคุณสามารถคัดลอกสูตรไปยังเซลล์อื่นเพื่อคัดลอกข้อมูลเพิ่มเติมจากหน้าเว็บเดียวกันหรือหน้าเว็บอื่น
แยกข้อความจากหน้าเว็บใดก็ได้ในคลิกเดียว ตรงไปที่ Nanonets มีดโกนเว็บไซต์, เพิ่ม URL แล้วคลิก “ขูด” และดาวน์โหลดข้อความหน้าเว็บเป็นไฟล์ทันที ทดลองใช้ฟรีตอนนี้
ข้อเสียของการใช้ Google Sheets Web Scraper คืออะไร
- Google ชีตมีความสามารถจำกัด เมื่อพูดถึงเค้าโครงที่ซับซ้อน จะไม่สามารถจัดการกับเนื้อหาไดนามิกได้
- อาจมีความคลาดเคลื่อนของข้อมูลเมื่อทำการขูดข้อมูลโดยใช้สูตรการขูดเว็บของ Google ชีต
- เมื่อคัดลอกข้อมูลจากเว็บไซต์ คุณอาจคัดลอกข้อมูลที่ละเอียดอ่อนหรือเป็นความลับโดยไม่ได้ตั้งใจ ซึ่งอาจทำให้เกิดความกังวลด้านความเป็นส่วนตัวและความปลอดภัย โดยเฉพาะอย่างยิ่งหากข้อมูลที่คัดลอกมาถูกแชร์หรือเก็บไว้ในตำแหน่งที่ไม่ปลอดภัย
เคล็ดลับ: การขูดเว็บของ Google ชีตเป็นทางเลือกที่ยอดเยี่ยมสำหรับงานการขูดเว็บที่ไม่ซับซ้อน เช่น ชื่อเมตา รายการ หรือการดึงข้อมูลตาราง สำหรับงานที่ซับซ้อน คุณควรใช้เครื่องมือขูดเว็บ
คำถามที่พบบ่อย
ฉันสามารถขูดเว็บด้วย Google ชีตได้หรือไม่
ใช่ Google ชีตมีคุณสมบัติในตัวเช่น IMPORTHTML, IMPORTXML, IMPORTDATA,
และ REGEXTRACT ที่ให้คุณเก็บข้อมูลจากเว็บไซต์ลงใน Google ชีตได้โดยตรง อย่างไรก็ตาม ฟังก์ชันอาจมีจำกัด และงานขูดเว็บที่ซับซ้อนมากขึ้นอาจต้องใช้เว็บสแครปเปอร์แยกต่างหากหรือเขียนโค้ดแบบกำหนดเอง
ฉันจะขูดข้อมูลลงใน Google ชีตได้อย่างไร
คุณสามารถขูดข้อมูลลงใน Google ชีตได้โดยใช้หนึ่งในฟังก์ชันที่มีมาให้ เช่น IMPORTHTML, IMPORTXML, IMPORTDATA หรือ REGEXTRACT ฟังก์ชันเหล่านี้ช่วยให้คุณสามารถดึงข้อมูลจากเว็บไซต์ ไฟล์ CSV หรือ TSV และจับคู่รูปแบบนิพจน์ทั่วไป เพียงระบุ URL ข้อความค้นหา ดัชนี หรือรูปแบบนิพจน์ทั่วไป จากนั้นข้อมูลจะถูกคัดลอกและบรรจุลงใน Google ชีตของคุณ
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://nanonets.com/blog/scrape-websites-using-google-sheets-formulas/
- :เป็น
- 1
- 11
- 2023
- 7
- a
- วิทยาลัย
- สามารถเข้าถึงได้
- เพิ่มเติม
- ราคาไม่แพง
- ทั้งหมด
- ทางเลือก
- วิเคราะห์
- และ
- ทุกแห่ง
- เป็น
- AS
- โดยอัตโนมัติ
- อัตโนมัติ
- รับรางวัลชนะเลิศ
- BE
- จะกลายเป็น
- บล็อก
- built-in
- ธุรกิจ
- by
- CAN
- ความสามารถในการ
- จับ
- กรณี
- เซลล์
- ตรวจสอบ
- คลิก
- ปิดหน้านี้
- รหัส
- การเข้ารหัส
- ซับซ้อน
- ความกังวลเกี่ยวกับ
- เนื้อหา
- ประเพณี
- ข้อมูล
- ขึ้นอยู่กับ
- ลักษณะ
- ต่าง
- โดยตรง
- แสดง
- ดาวน์โหลด
- พลวัต
- แต่ละ
- อย่างง่ายดาย
- เข้าสู่
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- ทุกๆ
- ยอดเยี่ยม
- ที่มีอยู่
- สารสกัด
- การสกัด
- คุ้นเคย
- คุณสมบัติ
- เนื้อไม่มีมัน
- ไฟล์
- ภาพยนตร์
- ชื่อจริง
- ดังต่อไปนี้
- สำหรับ
- สูตร
- โชคดี
- ฟรี
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ฟังก์ชั่น
- ฟังก์ชั่น
- ได้รับ
- รัฐบาล
- ยิ่งใหญ่
- ให้คำแนะนำ
- จัดการ
- หัว
- ช่วย
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- i
- ระบุ
- in
- ดัชนี
- บุคคล
- ข้อมูล
- รวม
- อินเตอร์เฟซ
- รวมถึง
- IT
- ชวา
- แค่หนึ่ง
- ความรู้
- ภาษา
- แบบ
- การใช้ประโยชน์
- กดไลก์
- ถูก จำกัด
- LINK
- การเชื่อมโยง
- รายการ
- ที่ตั้ง
- Lot
- แมโคร
- การทำ
- หลาย
- การจับคู่
- Meta
- อาจ
- ข้อมูลเพิ่มเติม
- จำเป็นต้อง
- ต้อง
- ใหม่
- of
- เสนอ
- on
- ONE
- ใบสั่ง
- อื่นๆ
- ของตนเอง
- หน้า
- ในสิ่งที่สนใจ
- แบบแผน
- รูปแบบ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ประชากร
- ที่มีศักยภาพ
- ปอนด์
- อำนาจ
- ที่มีประสิทธิภาพ
- ความเป็นส่วนตัว
- ความเป็นส่วนตัวและความปลอดภัย
- กระบวนการ
- การเขียนโปรแกรม
- โครงการ
- ให้
- หลาม
- ยก
- เหตุผล
- ปกติ
- ต้องการ
- ต้อง
- รีสอร์ท
- s
- เดียวกัน
- การขูด
- สคริปต์
- ค้นหา
- ความปลอดภัย
- เลือก
- มีความละเอียดอ่อน
- แยก
- หลาย
- ที่ใช้ร่วมกัน
- น่า
- ง่าย
- ง่ายดาย
- เล็ก
- ธุรกิจขนาดเล็ก
- So
- ทางออก
- บาง
- โดยเฉพาะ
- ข้อความที่เริ่ม
- สถิติ
- ขั้นตอน
- เก็บไว้
- อย่างเช่น
- ชุด
- ตาราง
- การสกัดตาราง
- TAG
- งาน
- ที่
- พื้นที่
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- ตลอด
- ต้องใช้เวลามาก
- ชื่อหนังสือ
- ชื่อ
- ไปยัง
- เครื่องมือ
- เครื่องมือ
- บทเรียน
- ปลดล็อก
- ไม่มั่นคง
- URL
- ใช้
- ที่ใช้งานง่าย
- ความหลากหลาย
- วิธี
- เว็บ
- การขูดเว็บ
- Website
- เว็บไซต์
- วิกิพีเดีย
- จะ
- กับ
- ไม่มี
- งาน
- เขียน
- การเขียน
- XML
- ของคุณ
- ลมทะเล