คุณได้ดูบทช่วยสอนทั้งหมดแล้ว ตอนนี้คุณเข้าใจวิธีการทำงานของโครงข่ายประสาทเทียมแล้ว คุณได้สร้างตัวแยกประเภทแมวและสุนัข คุณลองใช้ RNN ระดับอักขระครึ่งตัวที่เหมาะสม คุณคือหนึ่งเดียว pip install tensorflow ห่างจากการสร้างเทอร์มิเนเตอร์ใช่ไหม ผิด.

ส่วนสำคัญของการเรียนรู้เชิงลึกคือการค้นหาไฮเปอร์พารามิเตอร์ที่เหมาะสม เหล่านี้เป็นตัวเลขที่นางแบบ ไม่ได้ เรียน
ในบทความนี้ ฉันจะแนะนำคุณเกี่ยวกับไฮเปอร์พารามิเตอร์ทั่วไป (และสำคัญ) บางตัวที่คุณจะพบบนท้องถนนของคุณสู่อันดับ #1 บนกระดานผู้นำ Kaggle นอกจากนี้ ฉันยังจะแสดงอัลกอริธึมที่ทรงพลังให้คุณเลือกไฮเปอร์พารามิเตอร์ได้อย่างชาญฉลาด
ไฮเปอร์พารามิเตอร์ในการเรียนรู้เชิงลึก
พารามิเตอร์ไฮเปอร์พารามิเตอร์ถือเป็นปุ่มปรับแต่งโมเดลของคุณ
ระบบโฮมเธียเตอร์ 7.1 Dolby Atmos ที่สวยงามพร้อมซับวูฟเฟอร์ที่ให้เสียงเบสที่เกินขอบเขตการได้ยินของหูมนุษย์จะไม่มีประโยชน์หากคุณตั้งค่าเครื่องรับ AV เป็นสเตอริโอ

ในทำนองเดียวกัน inception_v3 ที่มีพารามิเตอร์ล้านล้านจะไม่ทำให้คุณผ่าน MNIST หากไฮเปอร์พารามิเตอร์ของคุณปิดอยู่
ทีนี้มาดูที่ปุ่มหมุนเพื่อปรับแต่งกันก่อนที่เราจะพูดถึงวิธีการหมุนในการตั้งค่าที่เหมาะสมกัน
อัตราการเรียนรู้
อาจเป็นไฮเปอร์พารามิเตอร์ที่สำคัญที่สุด นั่นคือ อัตราการเรียนรู้ การพูดอย่างคร่าวๆ จะควบคุมว่าโครงข่ายประสาทของคุณจะ "เรียนรู้" ได้เร็วเพียงใด
เหตุใดเราจึงไม่เพิ่มสิ่งนี้และใช้ชีวิตบนช่องทางที่รวดเร็ว?

ไม่ง่ายอย่างนั้น จำไว้ว่า ในการเรียนรู้อย่างลึกซึ้ง เป้าหมายของเราคือ ลดฟังก์ชั่นการสูญเสีย. หากอัตราการเรียนรู้สูงเกินไป การสูญเสียของเราจะเริ่มกระโดดไปทุกที่และไม่เคยมาบรรจบกัน

และหากอัตราการเรียนรู้น้อยเกินไป โมเดลจะใช้เวลานานเกินไปในการมาบรรจบกัน ดังที่แสดงไว้ด้านบน
โมเมนตัม
เนื่องจากบทความนี้เน้นเรื่องการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ ฉันจะไม่อธิบายแนวคิดทั้งหมดของ โมเมนตัม. แต่โดยสรุป ค่าคงที่โมเมนตัมสามารถคิดได้ว่าเป็นมวลของลูกบอลที่กลิ้งลงมาบนพื้นผิวของฟังก์ชันการสูญเสีย
ยิ่งลูกบอลหนักเท่าไหร่ก็ยิ่งตกลงมาเร็วเท่านั้น แต่ถ้าหนักเกินไปก็อาจติดหรือทะลุเป้าได้

การออกกลางคัน
หากคุณกำลังสัมผัสธีมที่นี่ ฉันจะพาคุณไปที่ อมาร์ บูธีราชาบทความเกี่ยวกับการออกกลางคัน

แต่เพื่อให้ทบทวนได้อย่างรวดเร็ว การออกกลางคันเป็นเทคนิคการทำให้เป็นมาตรฐานที่เสนอโดยเจฟฟ์ ฮินตัน ซึ่งสุ่มตั้งค่าการเปิดใช้งานในโครงข่ายประสาทเทียมเป็น 0 โดยมีความน่าจะเป็นเท่ากับ (p) ซึ่งจะช่วยป้องกันไม่ให้โครงข่ายประสาทจดจำข้อมูลมากเกินไป (การจดจำ) ข้อมูลเมื่อเทียบกับการเรียนรู้
(p) เป็นไฮเปอร์พารามิเตอร์
สถาปัตยกรรม — จำนวนเลเยอร์ เซลล์ประสาทต่อเลเยอร์ ฯลฯ
อีกแนวคิดหนึ่ง (ค่อนข้างเร็ว) คือการทำให้สถาปัตยกรรมของโครงข่ายประสาทเทียมนั้นเป็นไฮเปอร์พารามิเตอร์
แม้ว่าโดยทั่วไปแล้วเราไม่ได้ทำให้เครื่องจักรเข้าใจสถาปัตยกรรมของแบบจำลองของเรา (ไม่เช่นนั้นนักวิจัย AI จะตกงาน) เทคนิคใหม่บางอย่างเช่น ค้นหาสถาปัตยกรรมประสาท ได้นำแนวคิดนี้ไปปฏิบัติด้วยระดับความสำเร็จที่แตกต่างกัน
ถ้าคุณเคยได้ยินคำว่า ออโต้เอ็มแอลนี่เป็นวิธีที่ Google ทำโดยพื้นฐาน: ทำให้ทุกอย่างเป็นไฮเปอร์พารามิเตอร์แล้ว โยน TPU นับพันล้านก้อนให้กับปัญหาแล้วปล่อยให้มันแก้ไขเอง.
แต่สำหรับพวกเราส่วนใหญ่ที่ต้องการจัดประเภทแมวและสุนัขด้วยเครื่องจักรราคาประหยัดที่รวมเข้าด้วยกันหลังจากการขายในวัน Black Friday ถึงเวลาแล้วที่เราจะคิดหาวิธีทำให้โมเดลการเรียนรู้เชิงลึกเหล่านั้นใช้งานได้จริง
อัลกอริธึมการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์
ค้นหากริด
นี่เป็นวิธีที่ง่ายที่สุดในการรับไฮเปอร์พารามิเตอร์ที่ดี แท้จริงแล้วเป็นเพียงกำลังดุร้าย
อัลกอริทึม: ลองใช้ไฮเปอร์พารามิเตอร์จำนวนหนึ่งจากชุดของไฮเปอร์พารามิเตอร์ที่กำหนด และดูว่าสิ่งใดใช้ได้ผลดีที่สุด
ข้อดี: ง่ายพอสำหรับนักเรียนชั้นประถมศึกษาปีที่ XNUMX ที่จะนำไปใช้ สามารถต่อขนานกันได้อย่างง่ายดาย
จุดด้อย: อย่างที่คุณอาจเดาได้ว่ามันมีราคาแพงมากในการคำนวณ (เนื่องจากวิธีการเดรัจฉานทั้งหมด)
ฉันควรใช้: อาจจะไม่. การค้นหากริดนั้นไม่มีประสิทธิภาพอย่างมาก แม้ว่าคุณจะต้องการให้ความเรียบง่าย คุณก็ควรใช้การค้นหาแบบสุ่ม
สุ่มค้นหา
ทั้งหมดอยู่ในชื่อ — การค้นหาแบบสุ่ม สุ่ม.
อัลกอริทึม: ลองใช้ไฮเปอร์พารามิเตอร์แบบสุ่มจำนวนหนึ่งจากการแจกแจงแบบสม่ำเสมอบนพื้นที่ไฮเปอร์พารามิเตอร์บางตัว และดูว่าแบบใดทำงานได้ดีที่สุด
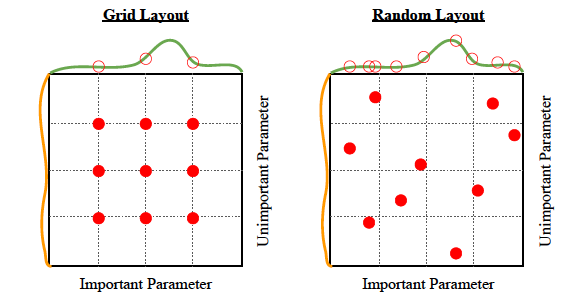
ข้อดี: สามารถต่อขนานกันได้อย่างง่ายดาย ง่ายเหมือนการค้นหากริด แต่นิดหน่อย ประสิทธิภาพที่ดีขึ้นดังภาพประกอบด้านล่าง:

จุดด้อย: แม้ว่าจะให้ประสิทธิภาพที่ดีกว่าการค้นหาแบบกริด แต่ก็ยังมีการประมวลผลแบบเข้มข้น
ฉันควรใช้: หากการขนานกันเล็กน้อยและความเรียบง่ายมีความสำคัญสูงสุด ให้ดำเนินการเลย แต่ถ้าคุณสามารถสละเวลาและความพยายาม คุณจะได้รับรางวัลครั้งใหญ่โดยใช้ Bayesian Optimization
การเพิ่มประสิทธิภาพแบบเบย์
ต่างจากวิธีอื่นๆ ที่เราเคยเห็นมา การเพิ่มประสิทธิภาพแบบเบย์ใช้ความรู้เกี่ยวกับการทำซ้ำของอัลกอริทึมก่อนหน้านี้ ด้วยการค้นหาตารางและการค้นหาแบบสุ่ม การคาดเดาไฮเปอร์พารามิเตอร์แต่ละรายการจะเป็นอิสระจากกัน แต่ด้วยวิธีแบบเบส์ ทุกครั้งที่เราเลือกและลองใช้ไฮเปอร์พารามิเตอร์ต่างๆ กัน ซึ่งเป็นนิ้วที่นำไปสู่ความสมบูรณ์แบบ

แนวคิดเบื้องหลังการปรับแต่งไฮเปอร์พารามิเตอร์แบบเบย์นั้นยาวและมีรายละเอียดมาก ดังนั้นเพื่อหลีกเลี่ยงโพรงกระต่ายมากเกินไป ฉันจะให้ส่วนสำคัญกับคุณที่นี่ แต่อย่าลืมอ่านต่อ กระบวนการเกาส์เซียน และ การเพิ่มประสิทธิภาพแบบเบย์โดยทั่วไป, ถ้านั่นคือสิ่งที่คุณสนใจ
โปรดจำไว้ว่า เหตุผลที่เราใช้อัลกอริธึมการปรับแต่งไฮเปอร์พารามิเตอร์เหล่านี้ก็คือ เป็นไปไม่ได้ที่จะประเมินตัวเลือกไฮเปอร์พารามิเตอร์หลายรายการทีละรายการ ตัวอย่างเช่น สมมติว่าเราต้องการหาอัตราการเรียนรู้ที่ดีด้วยตนเอง สิ่งนี้จะเกี่ยวข้องกับการกำหนดอัตราการเรียนรู้ การฝึกโมเดลของคุณ การประเมิน การเลือกอัตราการเรียนรู้ที่แตกต่างกัน การฝึกคุณสร้างแบบจำลองตั้งแต่เริ่มต้นอีกครั้ง การประเมินใหม่อีกครั้ง และวงจรจะดำเนินต่อไป
ปัญหาคือ “การฝึกโมเดลของคุณ” อาจใช้เวลาหลายวัน (ขึ้นอยู่กับความซับซ้อนของปัญหา) กว่าจะเสร็จ ดังนั้น คุณจะสามารถลองใช้อัตราการเรียนรู้เพียงไม่กี่ครั้งเมื่อถึงกำหนดส่งกระดาษสำหรับการประชุม และคุณรู้อะไรไหม คุณยังไม่ได้เริ่มเล่นกับโมเมนตัมด้วยซ้ำ อ๊ะ.

อัลกอริทึม: วิธีแบบเบย์พยายามสร้างฟังก์ชัน (แม่นยำยิ่งขึ้น การกระจายความน่าจะเป็นเหนือฟังก์ชันที่เป็นไปได้) ซึ่งจะประเมินว่าแบบจำลองของคุณดีเพียงใด อาจ เป็นทางเลือกของไฮเปอร์พารามิเตอร์ ด้วยการใช้ฟังก์ชันโดยประมาณนี้ (เรียกว่าฟังก์ชันตัวแทนในวรรณคดี) คุณไม่จำเป็นต้องผ่านชุด ฝึก ประเมินการวนซ้ำมากเกินไป เนื่องจากคุณสามารถปรับไฮเปอร์พารามิเตอร์ให้เหมาะสมกับฟังก์ชันตัวแทนได้
ตัวอย่างเช่น สมมติว่าเราต้องการย่อฟังก์ชันนี้ (คิดว่ามันเหมือนกับพร็อกซีสำหรับฟังก์ชันการสูญเสียของโมเดลของคุณ):

ฟังก์ชันตัวแทนเสมือนมาจากสิ่งที่เรียกว่ากระบวนการเกาส์เซียน (หมายเหตุ: มีวิธีอื่นในการสร้างแบบจำลองฟังก์ชันตัวแทนเสมือน แต่ฉันจะใช้กระบวนการเกาส์เซียน) อย่างที่ฉันบอกไป ฉันจะไม่ใช้อนุพันธ์ทางคณิตศาสตร์หนักๆ แต่นี่คือสิ่งที่พูดถึง Bayesians และ Gaussians ทั้งหมดมีดังนี้:
$$ mathbb{P} (F_n(X)|X_n) = frac{e^{-frac12 F_n^T Sigma_n^{-1} F_n}}{sqrt{(2pi)^n |Sigma_n|}} $$
ซึ่งเป็นที่ยอมรับว่าเป็นคำหนึ่ง แต่เราลองมาทำลายมันลง
ทางซ้ายมือกำลังบอกคุณว่ามีการแจกแจงความน่าจะเป็นที่เกี่ยวข้อง เมื่อมองเข้าไปในวงเล็บ เราจะเห็นว่าเป็นการแจกแจงความน่าจะเป็นของ ( F_n(X) ) ซึ่งเป็นฟังก์ชันที่ไม่ตั้งใจ ทำไม เพราะจำไว้ว่า เรากำลังกำหนดการกระจายความน่าจะเป็นเหนือฟังก์ชันที่เป็นไปได้ทั้งหมด ไม่ใช่แค่ฟังก์ชันเฉพาะ โดยพื้นฐานแล้ว ทางด้านซ้ายบอกว่าความน่าจะเป็นที่ฟังก์ชันจริงที่แมปไฮเปอร์พารามิเตอร์กับเมตริกของโมเดล (เช่น ความถูกต้องในการตรวจสอบความถูกต้อง โอกาสในการบันทึก อัตราข้อผิดพลาดในการทดสอบ ฯลฯ) คือ ( F_n(X) ) จากข้อมูลตัวอย่าง (X_n) เท่ากับสิ่งที่อยู่ทางขวามือ
ตอนนี้เรามีฟังก์ชันเพื่อเพิ่มประสิทธิภาพแล้ว เราก็ปรับให้เหมาะสม
นี่คือสิ่งที่กระบวนการเกาส์เซียนจะดูเหมือนก่อนที่เราจะเริ่มกระบวนการปรับให้เหมาะสม:

ใช้เครื่องมือเพิ่มประสิทธิภาพที่คุณชื่นชอบ (ข้อดีเช่นการเพิ่มความคาดหวังสูงสุด) แต่อย่างใด เพียงทำตามสัญญาณ (หรือการไล่ระดับสี) และก่อนที่คุณจะรู้ คุณก็จะจบลงที่จุดต่ำสุดในพื้นที่ของคุณ
หลังจากการวนซ้ำสองสามครั้ง กระบวนการเกาส์เซียนจะดีขึ้นในการประมาณฟังก์ชันเป้าหมาย:

ไม่ว่าคุณจะใช้วิธีการใดก็ตาม ตอนนี้คุณได้พบ `argmin` . แล้ว ของฟังก์ชันตัวแทน เซอร์ไพรส์ เซอร์ไพรส์ อาร์กิวเมนต์ที่ย่อฟังก์ชันตัวแทนให้เหลือน้อยที่สุดคือ (ค่าประมาณของ) ไฮเปอร์พารามิเตอร์ที่เหมาะสมที่สุด! เย้.
ผลลัพธ์สุดท้ายควรมีลักษณะดังนี้:

ใช้ไฮเปอร์พารามิเตอร์ที่ "เหมาะสมที่สุด" เหล่านี้เพื่อฝึกวิ่งบนโครงข่ายประสาทของคุณ และคุณควรเห็นการปรับปรุงบ้าง แต่คุณยังสามารถใช้ข้อมูลใหม่นี้เพื่อทำซ้ำกระบวนการปรับให้เหมาะสม Bayesian ทั้งหมดอีกครั้งและอีกครั้งและอีกครั้ง คุณสามารถเรียกใช้ Bayesian loop ได้หลายครั้งตามที่คุณต้องการ แต่ให้ระวัง คุณกำลังคำนวณสิ่งต่างๆ เครดิต AWS เหล่านั้นไม่ได้มาฟรี คุณรู้ไหม หรือพวกเขา...
ข้อดี: การเพิ่มประสิทธิภาพ Bayesian ให้ผลลัพธ์ที่ดีกว่าทั้งการค้นหาแบบกริดและการค้นหาแบบสุ่ม
จุดด้อย: มันไม่ง่ายที่จะขนานกัน
ฉันควรใช้มัน: ในกรณีส่วนใหญ่ ใช่! ข้อยกเว้นเพียงอย่างเดียวคือถ้า
- คุณเป็นผู้เชี่ยวชาญด้านการเรียนรู้เชิงลึกและไม่ต้องการความช่วยเหลือจากอัลกอริธึมการประมาณที่เลวทรามต่ำช้า
- คุณสามารถเข้าถึงทรัพยากรการคำนวณมากมาย และสามารถขนานการค้นหาแบบกริดและการค้นหาแบบสุ่มอย่างหนาแน่น
- หากคุณเป็นนักเนิร์ดสถิติที่เล่นบ่อย / ต่อต้าน Bayesian
แนวทางสำรองในการหาอัตราการเรียนรู้ที่ดี
ในวิธีการทั้งหมดที่เราเคยเห็นมา มีธีมพื้นฐานอยู่อย่างหนึ่ง: ทำให้งานของวิศวกรการเรียนรู้ของเครื่องเป็นไปโดยอัตโนมัติ ซึ่งยิ่งใหญ่และทั้งหมด จนกว่าเจ้านายของคุณจะเข้าใจและตัดสินใจแทนที่คุณด้วยการ์ด RTX Titan 4 ใบ ฮะ. เดาว่าคุณน่าจะติดอยู่กับการค้นหาด้วยตนเอง

แต่อย่าสิ้นหวัง มีการวิจัยเชิงรุกในด้านการทำให้นักวิจัยทำน้อยลงและได้เงินมากขึ้นพร้อมๆ กัน และหนึ่งในแนวคิดที่ได้ผลดีมากคือการทดสอบช่วงอัตราการเรียนรู้ ซึ่งเท่าที่ฉันรู้ ปรากฏครั้งแรกใน กระดาษโดย Leslie Smith.
บทความนี้เป็นเรื่องเกี่ยวกับวิธีการกำหนดเวลา (เปลี่ยนแปลง) อัตราการเรียนรู้เมื่อเวลาผ่านไป การทดสอบช่วง LR (อัตราการเรียนรู้) เป็นก้อนทองคำที่ผู้เขียนเพิ่งทำหล่นลงด้านข้าง
เมื่อคุณใช้ตารางอัตราการเรียนรู้ที่เปลี่ยนอัตราการเรียนรู้จากค่าต่ำสุดไปจนถึงค่าสูงสุด เช่น อัตราการเรียนรู้แบบวัฏจักร or การไล่ระดับสีสุ่มด้วยการรีสตาร์ทที่อบอุ่นผู้เขียนแนะนำให้เพิ่มอัตราการเรียนรู้เป็นเส้นตรงหลังจากการทำซ้ำแต่ละครั้งจากค่าน้อยไปมาก (เช่น 1e-7 ไปยัง 1e-1) ประเมินการสูญเสียในการทำซ้ำแต่ละครั้ง และวางแผนการสูญเสีย (หรือทดสอบข้อผิดพลาดหรือความแม่นยำ) เทียบกับอัตราการเรียนรู้ในระดับบันทึก โครงเรื่องของคุณควรมีลักษณะดังนี้:

ตามที่ระบุไว้ในโครงเรื่อง คุณจะต้องใช้กำหนดตารางอัตราการเรียนรู้เพื่อตีกลับระหว่างอัตราการเรียนรู้ต่ำสุดและสูงสุด ซึ่งพบได้จากการดูโครงเรื่องและพยายามมองพื้นที่นั้นด้วยการไล่ระดับสีที่ชันที่สุด
นี่คือตัวอย่างแผนภาพการทดสอบช่วง LR (DenseNet ฝึกบน CIFAR10) จาก Colab . ของเรา สมุดบันทึก:

ตามกฎทั่วไป หากคุณไม่ได้ทำสิ่งตารางอัตราการเรียนรู้แฟนซี เพียงแค่ตั้งค่าอัตราการเรียนรู้คงที่ของคุณเป็นลำดับความสำคัญที่ต่ำกว่าค่าต่ำสุดบนโครงเรื่อง ในกรณีนี้ก็จะประมาณว่า 1e-2.
ส่วนที่ยอดเยี่ยมที่สุดเกี่ยวกับวิธีการนี้ นอกจากจะใช้งานได้ดีจริง ๆ และช่วยให้คุณประหยัดเวลา ความพยายาม และการคำนวณที่จำเป็นในการค้นหาไฮเปอร์พารามิเตอร์ที่ดีด้วยอัลกอริธึมอื่น ๆ ก็คือ แทบไม่มีต้นทุนในการคำนวณเพิ่มเติม
ในขณะที่อัลกอริธึมอื่นๆ ได้แก่ การค้นหาแบบกริด การค้นหาแบบสุ่ม และ การเพิ่มประสิทธิภาพแบบเบย์กำหนดให้คุณต้องเรียกใช้โครงการทั้งหมดโดยสัมพันธ์กับเป้าหมายในการฝึกโครงข่ายประสาทที่ดี การทดสอบช่วง LR เป็นเพียงการดำเนินการวนรอบการฝึกที่เรียบง่ายและสม่ำเสมอ และติดตามตัวแปรสองสามตัวไปพร้อมกัน
นี่คือประเภทของความเร็วคอนเวอร์เจนซ์ที่คุณสามารถคาดหวังได้เมื่อใช้อัตราการเรียนรู้ที่เหมาะสมที่สุด (จากตัวอย่างใน สมุดบันทึก):

ทีมงานทำการทดสอบช่วง LR ที่ รวดเร็ว.aiและคุณควรดูที่ห้องสมุดของพวกเขาเพื่อใช้การทดสอบช่วง LR (พวกเขาเรียกมันว่า ตัวค้นหาอัตราการเรียนรู้) ตลอดจนอัลกอริธึมอื่น ๆ อีกมากมายได้อย่างง่ายดาย
สำหรับนักปฏิบัติการเรียนรู้เชิงลึกที่มีความซับซ้อนมากขึ้น
สนใจมีสมุดจดด้วยจ้า ไฟฉาย ที่ดำเนินการข้างต้น ซึ่งอาจช่วยให้คุณเข้าใจกระบวนการฝึกอบรมเบื้องหลังได้ดีขึ้น ตรวจสอบออก โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
ช่วยตัวเองด้วยความพยายาม

แน่นอนว่าอัลกอริธึมเหล่านี้ไม่ได้ผลในทางปฏิบัติเสมอไป มีหลายปัจจัยที่ต้องพิจารณาเมื่อฝึกโครงข่ายประสาท เช่น วิธีที่คุณจะประมวลผลข้อมูลล่วงหน้า กำหนดแบบจำลองของคุณ และทำให้คอมพิวเตอร์มีประสิทธิภาพมากพอที่จะเรียกใช้สิ่งที่แย่ได้
นาโนเน็ต ให้ API ที่ใช้งานง่ายเพื่อ ฝึกฝนและปรับใช้การเรียนรู้เชิงลึกแบบกำหนดเอง โมเดล ดูแลงานหนักทั้งหมด รวมถึงการเสริมข้อมูล การเรียนรู้การถ่ายโอน และใช่ การเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์!
นาโนเน็ต ใช้การค้นหาแบบ Bayesian บนคลัสเตอร์ GPU ขนาดใหญ่เพื่อค้นหาชุดไฮเปอร์พารามิเตอร์ที่เหมาะสมโดยที่คุณไม่ต้องกังวลว่าจะต้องเสียเงินกับกราฟิกการ์ดล่าสุดและ out of bounds for axis 0.
เมื่อพบรุ่นที่ดีที่สุดแล้ว นาโนเน็ต ให้บริการบนคลาวด์เพื่อให้คุณทดสอบโมเดลโดยใช้อินเทอร์เฟซบนเว็บหรือรวมเข้ากับโปรแกรมของคุณโดยใช้โค้ด 2 บรรทัด
บอกลาโมเดลที่สมบูรณ์แบบน้อยกว่า
สรุป
ในบทความนี้ เราได้พูดถึงไฮเปอร์พารามิเตอร์และวิธีเพิ่มประสิทธิภาพสองสามวิธี แต่มันหมายความว่าอย่างไร?
ในขณะที่เราพยายามมากขึ้นเรื่อยๆ เพื่อทำให้เทคโนโลยี AI เป็นประชาธิปไตย การปรับพารามิเตอร์ไฮเปอร์พารามิเตอร์อัตโนมัติอาจเป็นขั้นตอนในทิศทางที่ถูกต้อง ช่วยให้คนทั่วไปเช่นคุณและฉันสร้างแอปพลิเคชันการเรียนรู้เชิงลึกที่น่าทึ่งโดยไม่ต้องมีปริญญาเอกคณิตศาสตร์
ในขณะที่คุณสามารถโต้แย้งได้ว่าการทำให้โมเดลหิวกระหายพลังในการประมวลผลทิ้งโมเดลที่ดีที่สุดไว้ในมือของผู้ที่สามารถจ่ายพลังการประมวลผลดังกล่าวได้ แต่บริการคลาวด์เช่น AWS และ Nanonets ช่วยให้สามารถเข้าถึงเครื่องที่มีประสิทธิภาพในระบอบประชาธิปไตย ทำให้การเรียนรู้เชิงลึกเข้าถึงได้มากขึ้น
แต่โดยพื้นฐานแล้ว สิ่งที่เราเป็น จริง ทำที่นี่โดยใช้คณิตศาสตร์เพื่อแก้ปัญหาคณิตศาสตร์มากขึ้น สิ่งที่น่าสนใจไม่เพียงเพราะว่าเสียงของเมตาเป็นอย่างไร แต่ยังเป็นเพราะความง่ายในการตีความผิดด้วย

แน่นอนว่าเรามาไกลจากยุคของการเจาะการ์ดและตารางติดตามมาจนถึงยุคที่เราปรับแต่งฟังก์ชันที่ปรับฟังก์ชันให้เหมาะสมซึ่งปรับฟังก์ชันให้เหมาะสมที่สุด แต่เราไม่สามารถสร้างเครื่องจักรที่สามารถ "คิด" ได้ด้วยตัวเอง
และนั่นไม่ได้ทำให้ท้อใจ แม้แต่น้อย เพราะหากมนุษย์สามารถทำอะไรได้มากโดยใช้สิ่งเล็กๆ น้อยๆ ให้จินตนาการว่าอนาคตจะเป็นอย่างไร เมื่อวิสัยทัศน์ของเรากลายเป็นสิ่งที่เรามองเห็นได้จริง
ดังนั้นเราจึงนั่งบนเก้าอี้ตาข่ายที่มีเบาะนั่งจ้องมองที่หน้าจอเทอร์มินัลที่ว่างเปล่า การกดแป้นพิมพ์ทุกครั้งทำให้เรา sudo มหาอำนาจที่สามารถล้างดิสก์ให้สะอาด
เราก็เลยนั่ง นั่งทั้งวัน เพราะความก้าวหน้าครั้งยิ่งใหญ่ต่อไปอาจจะแค่ครั้งเดียว pip install ไป
ขี้เกียจเขียนโค้ด? ไม่ต้องการใช้ทรัพยากรในการคำนวณใช่หรือไม่ ตรงไปที่ นาโนเน็ต และ เริ่มสร้างแบบจำลอง ในขณะนี้!
คุณอาจสนใจโพสต์ล่าสุดของเราที่:
ที่มา: https://nanonets.com/blog/hyperparameter-optimization/
- 7
- 9
- เข้า
- คล่องแคล่ว
- AI
- ขั้นตอนวิธี
- อัลกอริทึม
- ทั้งหมด
- amp
- APIs
- การใช้งาน
- สถาปัตยกรรม
- ข้อโต้แย้ง
- บทความ
- ศรุต
- อัตโนมัติ
- AV
- AWS
- ที่ดีที่สุด
- พันล้าน
- บิต
- Black
- ในวัน Black Friday
- สร้าง
- การก่อสร้าง
- พวง
- โทรศัพท์
- ซึ่ง
- กรณี
- เงินสด
- แมว
- เมฆ
- บริการคลาวด์
- รหัส
- ร่วมกัน
- คำนวณ
- การคำนวณ
- พลังคอมพิวเตอร์
- การประชุม
- อย่างต่อเนื่อง
- ค่าใช้จ่าย
- เครดิต
- ข้อมูล
- วัน
- การเรียนรู้ลึก ๆ
- สุนัข
- ปรับตัวลดลง
- วิศวกร
- ประมาณการ
- ฯลฯ
- FAST
- รูป
- พบ
- ชื่อจริง
- พอดี
- ปฏิบัติตาม
- ฟรี
- วันศุกร์
- FS
- ฟังก์ชัน
- อนาคต
- GIF
- GitHub
- ให้
- ทองคำ
- ดี
- GPU
- ยิ่งใหญ่
- ตะแกรง
- หัว
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- จุดสูง
- หน้าแรก
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTTPS
- หิว
- ความคิด
- นิ้ว
- รวมทั้ง
- ข้อมูล
- ร่วมมือ
- IT
- การสัมภาษณ์
- งาน
- การเก็บรักษา
- ความรู้
- ใหญ่
- ล่าสุด
- เรียนรู้
- การเรียนรู้
- ห้องสมุด
- วรรณคดี
- ในประเทศ
- โลโก้
- นาน
- เรียนรู้เครื่อง
- เครื่อง
- ส่วนใหญ่
- การทำ
- แผนที่
- คณิตศาสตร์
- ภาพบรรยากาศ
- กลาง
- meme
- Meta
- ตัวชี้วัด
- แบบ
- โมเมนตัม
- คือ
- สุทธิ
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- ตัวเลข
- ใบสั่ง
- อื่นๆ
- กระดาษ
- รูปแบบไฟล์ PDF
- การปฏิบัติ
- โพสต์
- อำนาจ
- โครงการ
- โครงการ
- หนังสือมอบฉันทะ
- หมัด
- พิสัย
- ราคา
- RE
- การวิจัย
- แหล่งข้อมูล
- ผลสอบ
- วิ่ง
- การขาย
- ขนาด
- จอภาพ
- ค้นหา
- บริการ
- ชุด
- การตั้งค่า
- สั้น
- สัญญาณ
- ง่าย
- เล็ก
- So
- แก้
- ช่องว่าง
- ความเร็ว
- ใช้จ่าย
- จุด
- เริ่มต้น
- ข้อความที่เริ่ม
- สถิติ
- ความสำเร็จ
- พื้นผิว
- แปลกใจ
- ระบบ
- เป้า
- เทคโนโลยี
- ทดสอบ
- ก้าวสู่อนาคต
- โรงละคร
- ชุดรูปแบบ
- เวลา
- ลู่
- การฝึกอบรม
- บทเรียน
- Unsplash
- us
- ประโยชน์
- ความคุ้มค่า
- นาฬิกา
- เว็บ
- WHO
- ลม
- งาน
- โรงงาน
- X







{kind=link}
{kind=link}
{kind=link}