ในโลกสมัยใหม่ ธุรกิจส่วนใหญ่พึ่งพาพลังของข้อมูลขนาดใหญ่และการวิเคราะห์เพื่อขับเคลื่อนการเติบโต การลงทุนเชิงกลยุทธ์ และการมีส่วนร่วมกับลูกค้า ข้อมูลขนาดใหญ่เป็นค่าคงที่พื้นฐานในโฆษณาที่ตรงเป้าหมาย การตลาดเฉพาะบุคคล คำแนะนำผลิตภัณฑ์ การสร้างข้อมูลเชิงลึก การปรับราคาให้เหมาะสม การวิเคราะห์ความรู้สึก การวิเคราะห์เชิงคาดการณ์ และอื่นๆ อีกมากมาย
ข้อมูลมักถูกรวบรวมจากหลายแหล่ง แปลง จัดเก็บ และประมวลผลใน Data Lake ภายในองค์กรหรือบนคลาวด์ แม้ว่าการนำเข้าข้อมูลครั้งแรกจะค่อนข้างไม่สำคัญและสามารถทำได้ผ่านสคริปต์แบบกำหนดเองที่พัฒนาขึ้นภายในองค์กรหรือเครื่องมือ ETL (Extract Transform Load) แบบดั้งเดิม แต่ปัญหาก็กลายเป็นเรื่องที่ซับซ้อนอย่างรวดเร็วและมีค่าใช้จ่ายสูงในการแก้ไข เนื่องจากบริษัทต้อง:
- จัดการวงจรชีวิตของข้อมูลทั้งหมด – เพื่อวัตถุประสงค์ในการดูแลทำความสะอาดและการปฏิบัติตามข้อกำหนด
- เพิ่มประสิทธิภาพการจัดเก็บ - เพื่อลดค่าใช้จ่ายที่เกี่ยวข้อง
- ลดความซับซ้อนของสถาปัตยกรรม – ผ่านการนำโครงสร้างพื้นฐานของคอมพิวเตอร์กลับมาใช้ใหม่
- ประมวลผลข้อมูลแบบค่อยเป็นค่อยไป – ผ่านการจัดการสถานะที่มีประสิทธิภาพ
- ใช้นโยบายเดียวกันกับข้อมูลแบทช์และสตรีมโดยไม่ต้องใช้ความพยายามซ้ำซ้อน
- โยกย้ายระหว่าง On-prem และ Cloud – โดยใช้ความพยายามน้อยที่สุด
มันอยู่ที่ไหน อาปาเช่ ก็อบลินการจัดการข้อมูลแบบโอเพ่นซอร์สและระบบบูรณาการเข้ามา Apache Gobblin มีความสามารถที่เหนือชั้นซึ่งสามารถใช้ทั้งหมดหรือบางส่วนขึ้นอยู่กับความต้องการของธุรกิจ
ในส่วนนี้ เราจะเจาะลึกถึงความสามารถต่างๆ ของ Apache Gobblin ที่ช่วยในการจัดการกับความท้าทายที่ระบุไว้ก่อนหน้านี้
การจัดการวงจรชีวิตข้อมูลทั้งหมด
Apache Gobblin มอบขอบเขตของความสามารถในการสร้างท่อส่งข้อมูลที่สนับสนุนชุดการดำเนินการวงจรชีวิตข้อมูลทั้งหมดบนชุดข้อมูล
- นำเข้าข้อมูล – จากหลายแหล่งไปจนถึงแหล่งเก็บ ตั้งแต่ฐานข้อมูล, Rest API, เซิร์ฟเวอร์ FTP/SFTP, Filers, CRM เช่น Salesforce และ Dynamics และอื่นๆ
- ทำซ้ำข้อมูล – ระหว่าง Data Lake หลายแห่งด้วยความสามารถพิเศษสำหรับ Hadoop Distributed File System ผ่าน Distcp-NG
- ล้างข้อมูล – โดยใช้นโยบายการเก็บรักษา เช่น Time-based, Newest K, Versioned หรือหลายนโยบายร่วมกัน
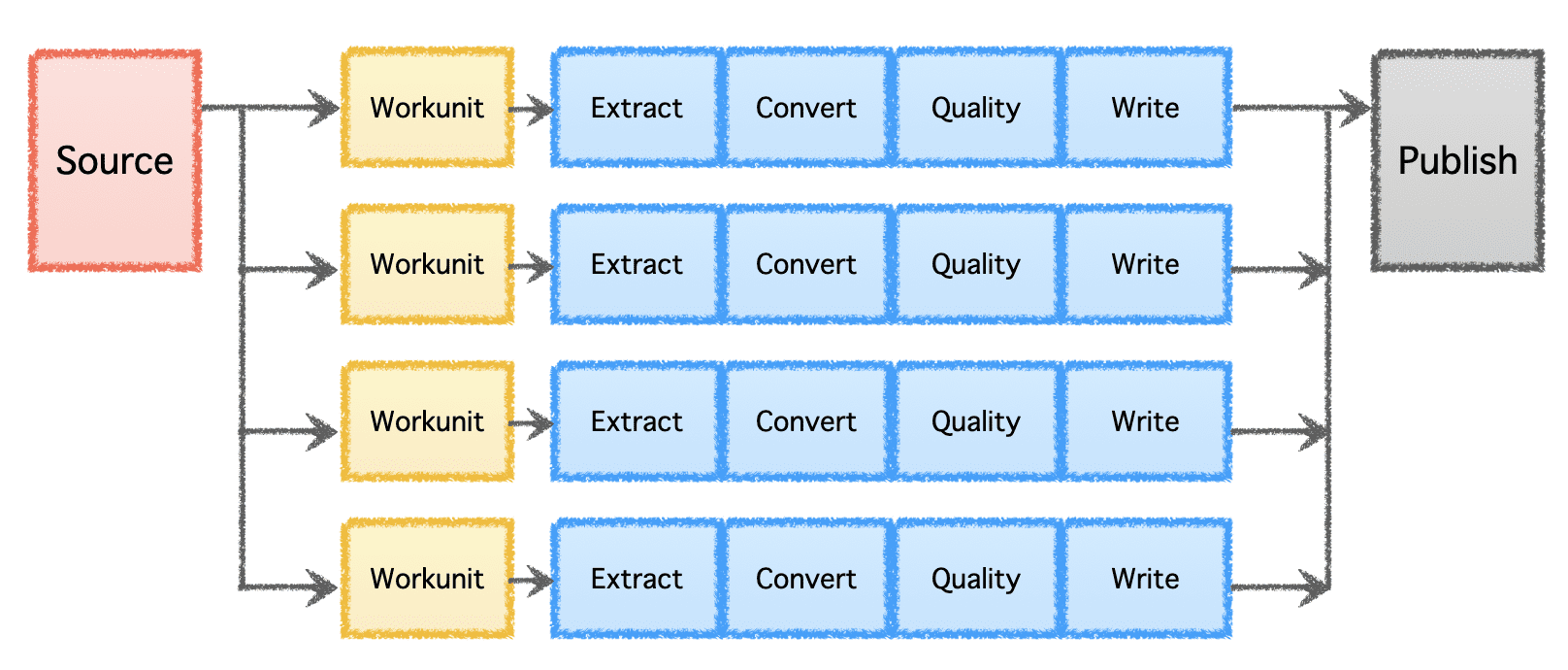
ขั้นตอนตรรกะของ Gobblin ประกอบด้วย 'แหล่งที่มา' ที่กำหนดการกระจายงานและสร้าง 'หน่วยงาน' จากนั้น 'หน่วยงาน' เหล่านี้จะถูกเลือกเพื่อดำเนินการเป็น 'งาน' ซึ่งรวมถึงการแยก การแปลง การตรวจสอบคุณภาพ และการเขียนข้อมูลไปยังปลายทาง ขั้นตอนสุดท้าย 'การเผยแพร่ข้อมูล' จะตรวจสอบความถูกต้องของการดำเนินการไปป์ไลน์ที่ประสบความสำเร็จและส่งข้อมูลเอาต์พุตแบบอะตอม หากปลายทางรองรับ
ภาพโดยผู้เขียน
เพิ่มประสิทธิภาพ Storage
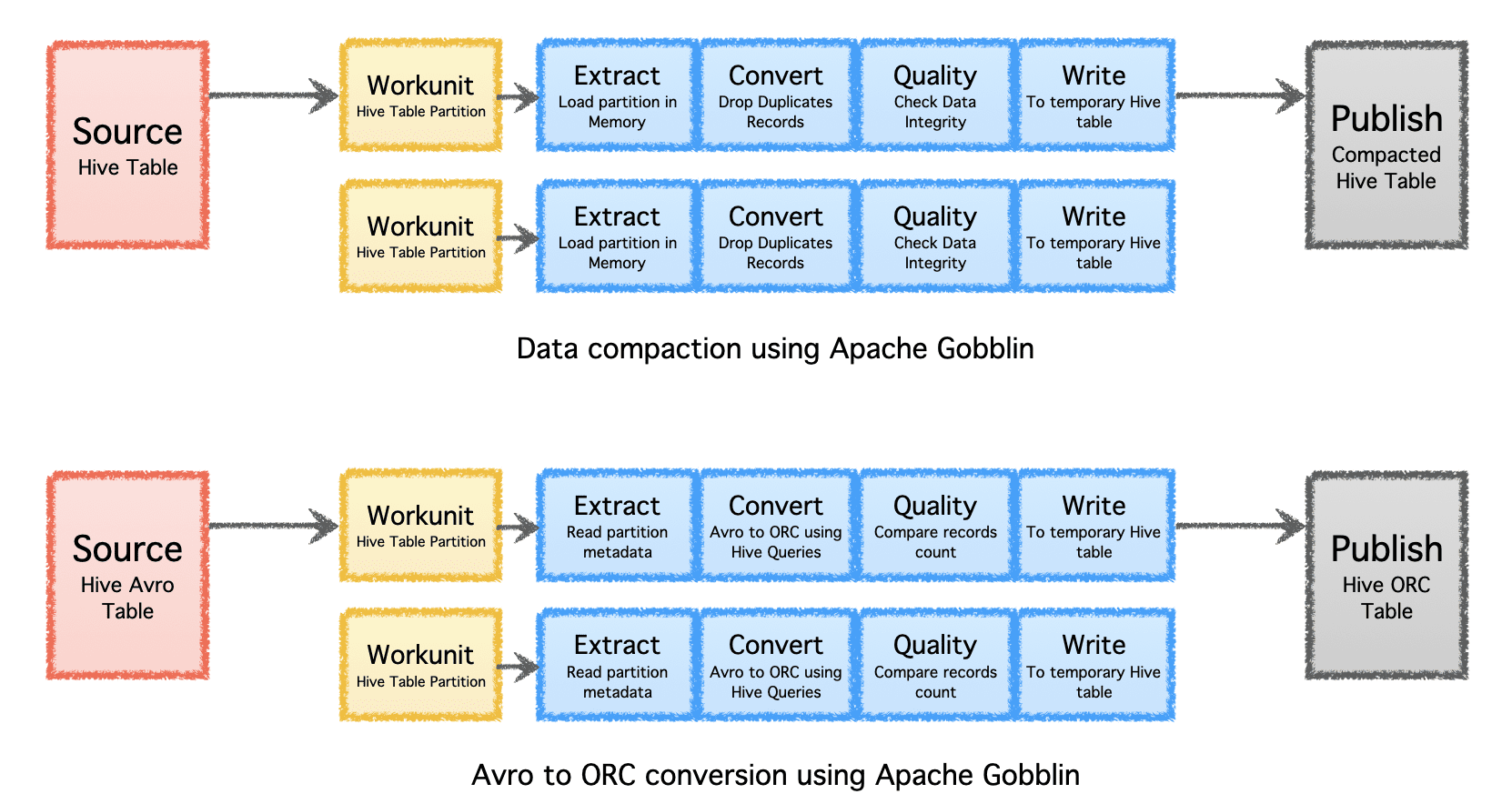
Apache Gobblin สามารถช่วยลดจำนวนพื้นที่จัดเก็บข้อมูลที่จำเป็นสำหรับข้อมูลผ่านการประมวลผลข้อมูลภายหลังการส่งผ่านข้อมูลหรือการจำลองแบบโดยการบดอัดหรือการแปลงรูปแบบ
- การบีบอัด – ข้อมูลหลังการประมวลผลเพื่อขจัดข้อมูลที่ซ้ำกันตามฟิลด์หรือฟิลด์คีย์ทั้งหมดของเรคคอร์ด ตัดแต่งข้อมูลเพื่อเก็บเพียงเรคคอร์ดเดียวที่มีการประทับเวลาล่าสุดด้วยคีย์เดียวกัน
- Avro เป็น ORC – เป็นกลไกการแปลงรูปแบบพิเศษเพื่อแปลงรูปแบบ Avro ตามแถวที่ได้รับความนิยมให้เป็นรูปแบบ ORC ตามคอลัมน์ที่ปรับให้เหมาะสมที่สุด
ภาพโดยผู้เขียน
ลดความซับซ้อนของสถาปัตยกรรม
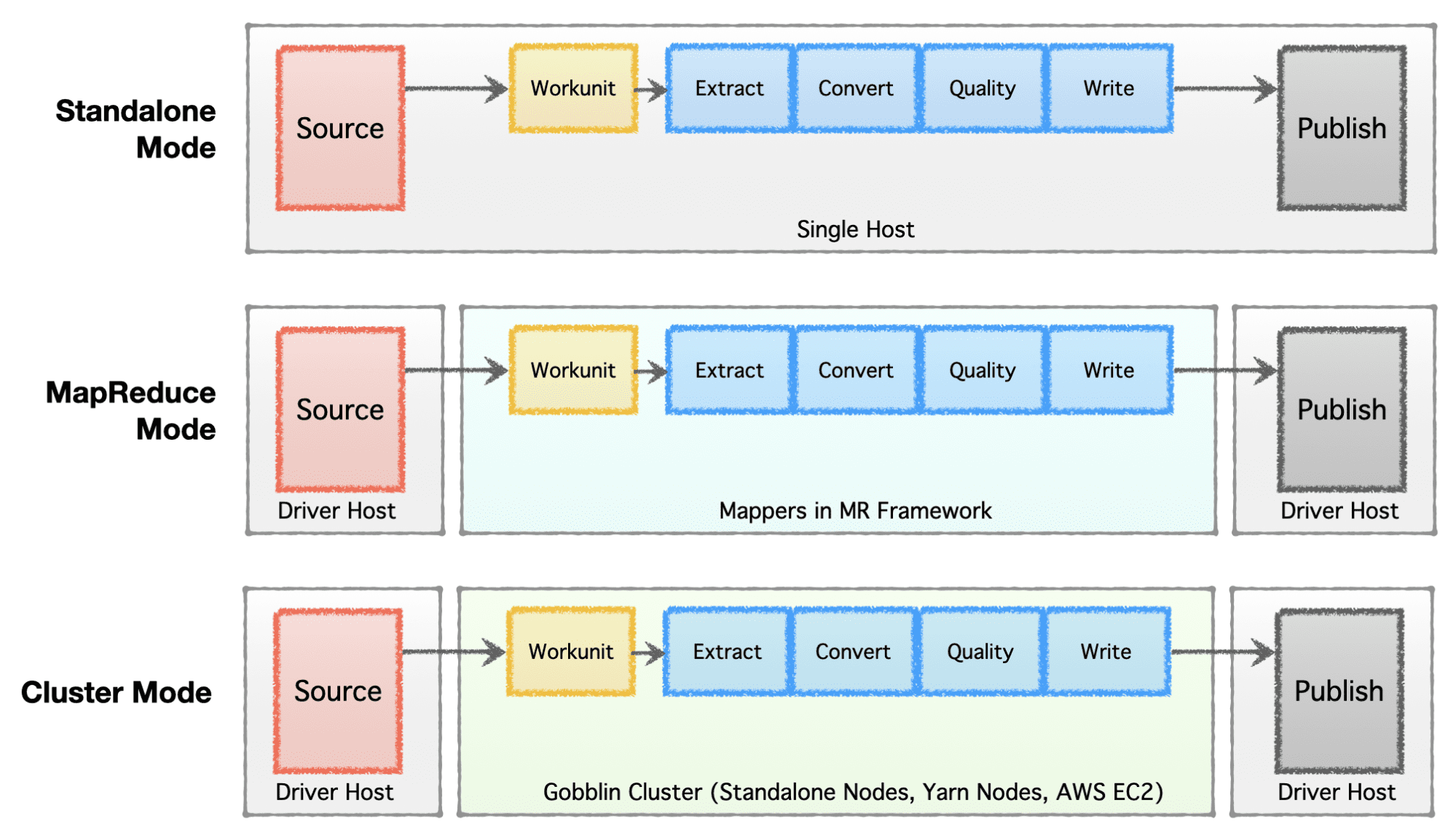
ขึ้นอยู่กับระยะของบริษัท (เริ่มต้นจนถึงระดับองค์กร) ข้อกำหนดด้านขนาด และสถาปัตยกรรมที่เกี่ยวข้อง บริษัทต่างๆ ต้องการตั้งค่าหรือพัฒนาโครงสร้างพื้นฐานข้อมูลของตน Apache Gobblin มีความยืดหยุ่นสูงและรองรับรูปแบบการดำเนินการที่หลากหลาย
- โหมดสแตนด์อโลน – เพื่อทำงานเป็นกระบวนการสแตนด์อโลนบนกล่องโลหะเปล่า เช่น โฮสต์เดี่ยวสำหรับกรณีการใช้งานที่เรียบง่ายและสถานการณ์ที่มีความต้องการน้อย
- โหมด MapReduce – เพื่อรันเป็นงาน MapReduce บนโครงสร้างพื้นฐาน Hadoop สำหรับกรณีข้อมูลขนาดใหญ่เพื่อจัดการชุดข้อมูลในระดับเพตะไบต์
- โหมดคลัสเตอร์: แบบสแตนด์อโลน – เพื่อเรียกใช้เป็นคลัสเตอร์ที่สนับสนุนโดย Apache Helix และ Apache Zookeeper บนชุดเครื่องเปล่าหรือโฮสต์เพื่อจัดการสเกลขนาดใหญ่โดยไม่ขึ้นกับเฟรมเวิร์ก Hadoop MR
- โหมดคลัสเตอร์: Yarn – เพื่อเรียกใช้เป็นคลัสเตอร์บน Native Yarn โดยไม่มีเฟรมเวิร์ก Hadoop MR
- โหมดคลัสเตอร์: AWS – เพื่อเรียกใช้เป็นคลัสเตอร์บนคลาวด์สาธารณะของ Amazon เช่น AWS สำหรับโครงสร้างพื้นฐานที่โฮสต์บน AWS
ภาพโดยผู้เขียน
ประมวลผลข้อมูลทีละน้อย
ในระดับที่มีนัยสำคัญซึ่งมีไปป์ไลน์ข้อมูลหลายตัวและมีปริมาณมาก ข้อมูลจำเป็นต้องได้รับการประมวลผลเป็นชุดและเมื่อเวลาผ่านไป ดังนั้นจึงจำเป็นต้องมีการเช็คพอยต์เพื่อให้ไปป์ไลน์ข้อมูลสามารถดำเนินการต่อจากจุดที่ค้างไว้ในครั้งก่อนและดำเนินการต่อไปได้ Apache Gobblin รองรับลายน้ำต่ำและสูง และสนับสนุนความหมายการจัดการสถานะที่มีประสิทธิภาพผ่าน State Store บน HDFS, AWS S3, MySQL และอื่นๆ อย่างโปร่งใส
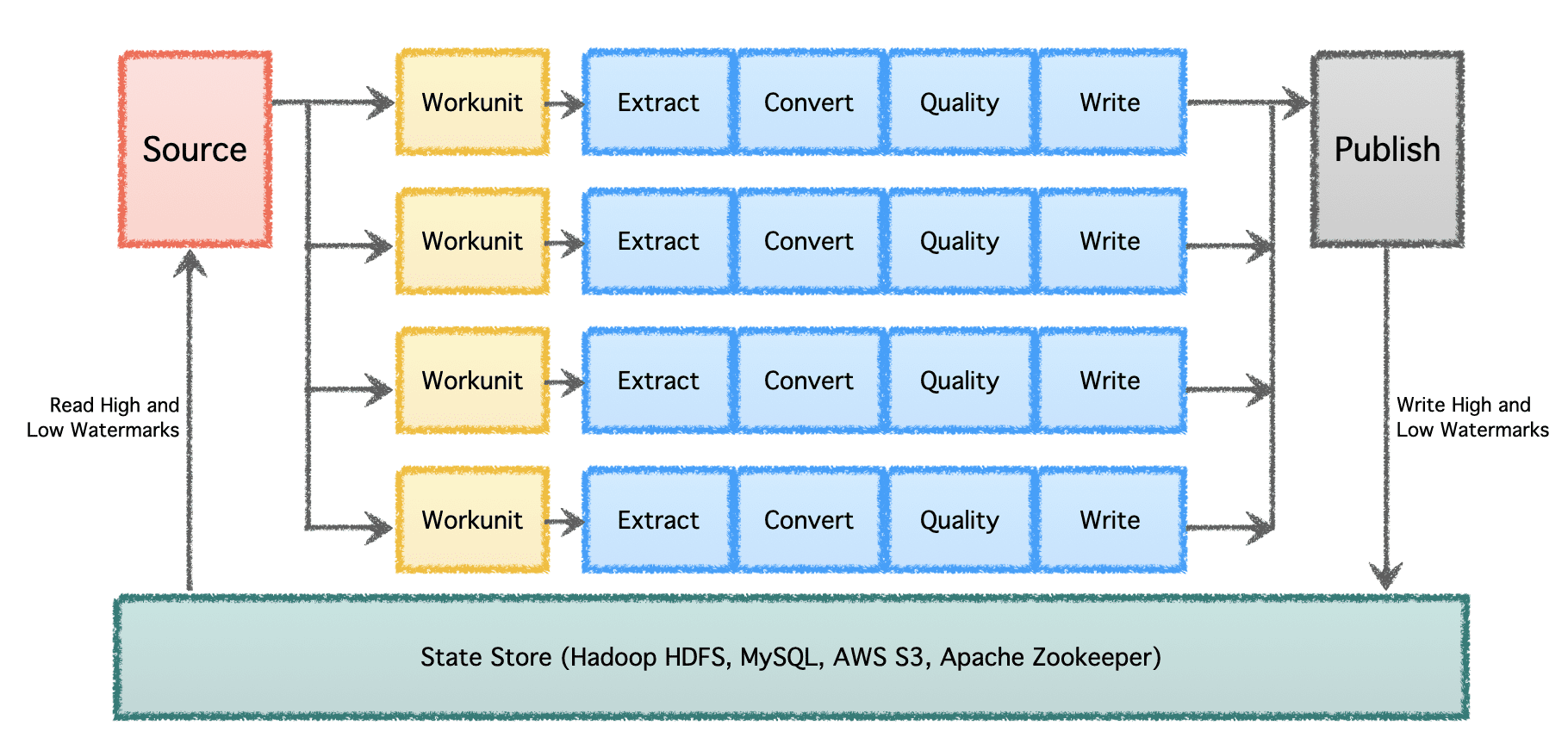
ภาพโดยผู้เขียน
นโยบายเดียวกันเกี่ยวกับข้อมูลแบทช์และสตรีม
ไปป์ไลน์ข้อมูลส่วนใหญ่ในปัจจุบันต้องเขียนสองครั้ง ครั้งแรกสำหรับข้อมูลแบทช์ และอีกครั้งสำหรับข้อมูลระยะใกล้หรือสตรีมมิง เพิ่มความพยายามเป็นสองเท่าและทำให้เกิดความไม่สอดคล้องกันในนโยบายและอัลกอริทึมที่ใช้กับไปป์ไลน์ประเภทต่างๆ Apache Gobblin แก้ปัญหานี้โดยอนุญาตให้ผู้ใช้สร้างไปป์ไลน์เพียงครั้งเดียวและรันบนข้อมูลทั้งแบบแบตช์และแบบสตรีมหากใช้ในโหมด Gobblin Cluster, Gobblin ในโหมด AWS หรือ Gobblin on Yarn mode
โยกย้ายระหว่างภายในองค์กรและคลาวด์
เนื่องจากโหมดอเนกประสงค์ที่สามารถทำงานภายในองค์กรบนกล่องเดียว คลัสเตอร์ของโหนด หรือระบบคลาวด์ จึงปรับใช้และใช้งาน Apache Gobblin ได้ทั้งในองค์กรและบนคลาวด์ ดังนั้น ผู้ใช้จึงเขียนไปป์ไลน์ข้อมูลเพียงครั้งเดียวและย้ายข้อมูลไปพร้อมกับการปรับใช้ Gobblin ระหว่างภายในองค์กรและระบบคลาวด์ได้อย่างง่ายดาย ตามความต้องการเฉพาะ
เนื่องจากสถาปัตยกรรมที่มีความยืดหยุ่นสูง ฟีเจอร์ที่ทรงพลัง และปริมาณข้อมูลจำนวนมากที่สามารถรองรับและประมวลผลได้ Apache Gobblin จึงถูกนำมาใช้ในโครงสร้างพื้นฐานการผลิตของ บริษัทเทคโนโลยีรายใหญ่ และเป็นสิ่งที่ต้องมีสำหรับการปรับใช้โครงสร้างพื้นฐานบิ๊กดาต้าในปัจจุบัน
สามารถดูรายละเอียดเพิ่มเติมเกี่ยวกับ Apache Gobblin และวิธีการใช้งานได้ที่ https://gobblin.apache.org
อภิเศก ติวารี เป็นผู้จัดการอาวุโสที่ LinkedIn ซึ่งเป็นผู้นำองค์กร Big Data Pipelines ของบริษัท เขายังเป็นรองประธาน Apache Gobblin ที่ Apache Software Foundation และเป็นสมาชิกของ British Computer Society
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- ประสบความสำเร็จ
- ที่อยู่
- โฆษณา
- หลังจาก
- ช่วย
- อัลกอริทึม
- ทั้งหมด
- การอนุญาต
- จำนวน
- การวิเคราะห์
- การวิเคราะห์
- และ
- อาปาเช่
- APIs
- ประยุกต์
- สถาปัตยกรรม
- ที่เกี่ยวข้อง
- ผู้เขียน
- AWS
- ถอย
- ตาม
- จะกลายเป็น
- ระหว่าง
- ใหญ่
- ข้อมูลขนาดใหญ่
- กล่อง
- British
- ธุรกิจ
- ธุรกิจ
- ความสามารถในการ
- กรณี
- ความท้าทาย
- การตรวจสอบ
- เมฆ
- Cluster
- การผสมผสาน
- บริษัท
- บริษัท
- ซับซ้อน
- การปฏิบัติตาม
- คอมพิวเตอร์
- การคำนวณ
- คงที่
- สร้าง
- ต่อ
- การแปลง
- แปลง
- สร้าง
- ประเพณี
- ลูกค้า
- การมีส่วนร่วมของลูกค้า
- ข้อมูล
- โครงสร้างพื้นฐานข้อมูล
- การจัดการข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- ทั้งนี้ขึ้นอยู่กับ
- นำไปใช้
- การใช้งาน
- การใช้งาน
- ปลายทาง
- รายละเอียด
- แน่นอน
- พัฒนา
- ต่าง
- กระจาย
- การกระจาย
- พลศาสตร์
- อย่างง่ายดาย
- ความพยายาม
- มีส่วนร่วม
- Enterprise
- อีเธอร์ (ETH)
- คาย
- การปฏิบัติ
- แพง
- สารสกัด
- การสกัด
- สุดโต่ง
- คุณสมบัติ
- มนุษย์
- สาขา
- เนื้อไม่มีมัน
- สุดท้าย
- มีความยืดหยุ่น
- รูป
- พบ
- รากฐาน
- กรอบ
- ราคาเริ่มต้นที่
- เชื้อเพลิง
- เต็ม
- รุ่น
- การเจริญเติบโต
- Hadoop
- จัดการ
- ช่วย
- จุดสูง
- อย่างสูง
- เจ้าภาพ
- เป็นเจ้าภาพ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTTPS
- in
- ประกอบด้วย
- อิสระ
- โครงสร้างพื้นฐาน
- โครงสร้างพื้นฐาน
- แรกเริ่ม
- ข้อมูลเชิงลึก
- บูรณาการ
- เปิดตัว
- เงินลงทุน
- IT
- การสัมภาษณ์
- KD นักเก็ต
- เก็บ
- คีย์
- ใหญ่
- ชื่อสกุล
- ล่าสุด
- ชั้นนำ
- โหลด
- ต่ำ
- เครื่อง
- การจัดการ
- ผู้จัดการ
- การตลาด
- กลไก
- โลหะ
- อพยพ
- โหมด
- โมเดล
- ทันสมัย
- โหมด
- ข้อมูลเพิ่มเติม
- มากที่สุด
- หลาย
- ต้องมี
- MySQL
- พื้นเมือง
- จำเป็น
- ความต้องการ
- ล่าสุด
- โหนด
- การเสนอ
- ONE
- โอเพนซอร์ส
- การดำเนินการ
- organizacja
- ที่ระบุไว้
- ส่วน
- ส่วนบุคคล
- เลือก
- ท่อ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- นโยบาย
- ยอดนิยม
- อำนาจ
- ที่มีประสิทธิภาพ
- การวิเคราะห์เชิงทำนาย
- ชอบ
- ประธาน
- ก่อนหน้านี้
- ราคา
- ปัญหา
- กระบวนการ
- ผลิตภัณฑ์
- การผลิต
- ให้
- สาธารณะ
- คลาวด์สาธารณะ
- ประกาศ
- คุณภาพ
- อย่างรวดเร็ว
- ตั้งแต่
- แนะนำ
- ระเบียน
- บันทึก
- ลด
- สัมพัทธ์
- การทำซ้ำ
- ความต้องการ
- ว่า
- REST
- เรซูเม่
- ความจำ
- แข็งแรง
- วิ่ง
- Salesforce
- เดียวกัน
- ขนาด
- ปรับ
- สคริปต์
- Section
- อรรถศาสตร์
- ระดับอาวุโส
- ความรู้สึก
- ชุด
- สำคัญ
- ง่าย
- เดียว
- สถานการณ์
- So
- สังคม
- ซอฟต์แวร์
- แก้
- แก้ปัญหา
- แหล่ง
- แหล่งที่มา
- เฉพาะ
- โดยเฉพาะ
- ระยะ
- สแตนด์อโลน
- การเริ่มต้น
- สถานะ
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- ยุทธศาสตร์
- กระแส
- ที่พริ้ว
- ที่ประสบความสำเร็จ
- ชุด
- สนับสนุน
- รองรับ
- ระบบ
- เป้าหมาย
- งาน
- เทคโนโลยี
- พื้นที่
- ของพวกเขา
- ดังนั้น
- ตลอด
- เวลา
- การประทับเวลา
- ไปยัง
- ในวันนี้
- เครื่องมือ
- แบบดั้งเดิม
- แปลง
- เปลี่ยน
- ชนิด
- พื้นฐาน
- หาตัวจับยาก
- ใช้
- ผู้ใช้
- ต่างๆ
- อเนกประสงค์
- ผ่านทาง
- Vice President
- ปริมาณ
- ไดรฟ์
- ที่
- ในขณะที่
- จะ
- ไม่มี
- งาน
- โลก
- เขียน
- การเขียน
- เขียน
- ลมทะเล