
Bild av författare
Clustering är en populär oövervakad maskininlärningsteknik, vilket innebär att den används för datauppsättningar där målvariabeln eller resultatvariabeln inte tillhandahålls.
I oövervakat lärande har algoritmer till uppgift att fånga mönstren och relationerna i data utan någon förexisterande kunskap eller vägledning.
Vad gör klustring? Den grupperar liknande datapunkter, vilket gör det möjligt för oss att upptäcka dolda mönster och relationer i vår data.
I den här artikeln kommer vi att utforska de olika tillgängliga klustringsalgoritmerna och deras respektive användningsfall, tillsammans med viktiga utvärderingsmått för att bedöma kvaliteten på klustringsresultaten.
Vi kommer också att visa hur man utvecklar flera klustringsalgoritmer samtidigt med det populära Python-biblioteket scikit-learn.
Slutligen kommer vi att lyfta fram några av de mest kända verkliga tillämpningarna som använde klustring, och diskuterar de algoritmer som används och de utvärderingsmått som används.
Men först, låt oss bekanta oss med klustringsalgoritmerna.
Nedan hittar du en översikt över klustringsalgoritmerna och korta definitioner.
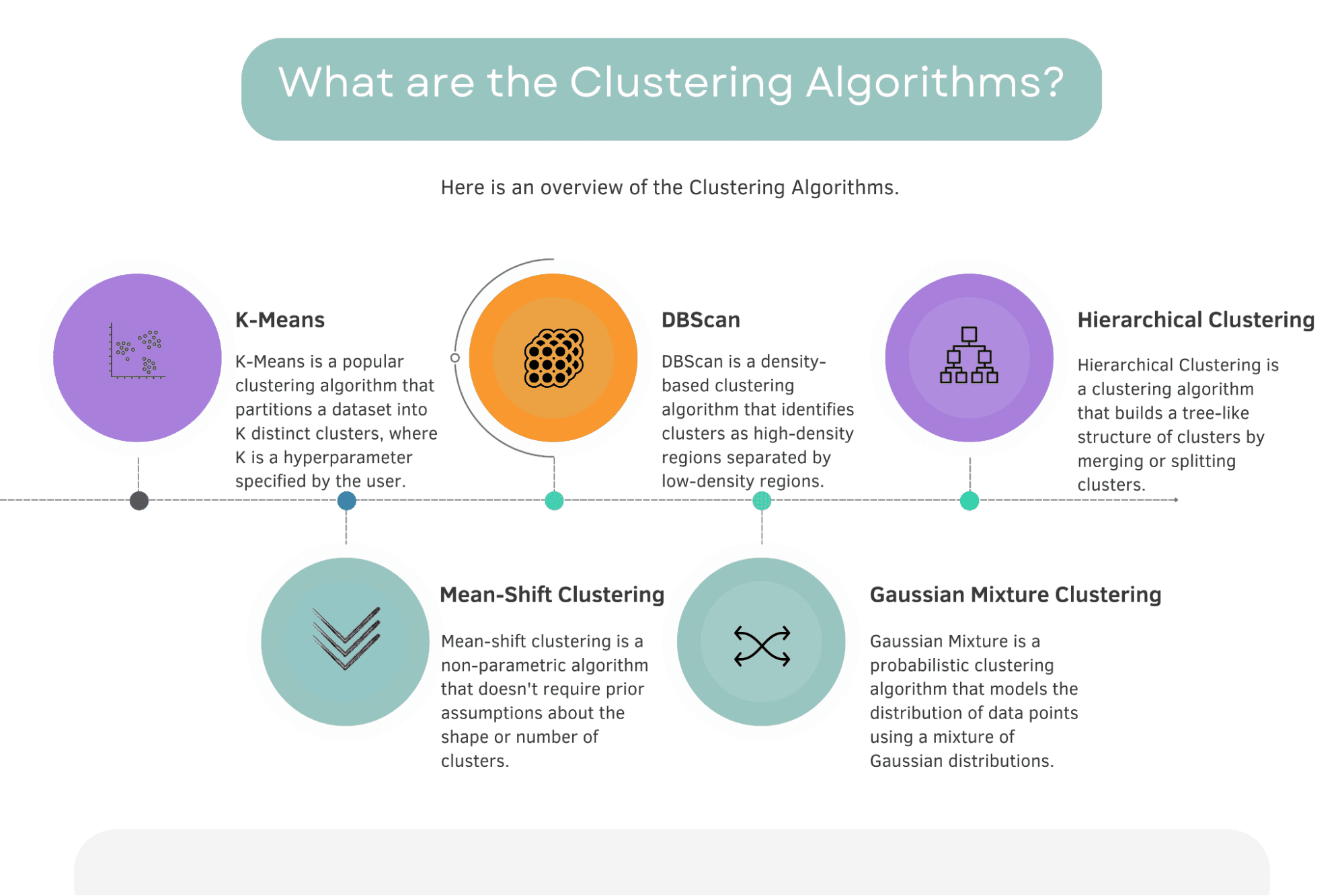
Bild av författare
Enligt officiell dokumentation från scikit-learn finns det 11 olika klustringsalgoritmer: K-Means, Affinity propagation, Mean Shift, Special Clustering, Hierarchical Clustering, Agglomerative Clustering, DBScan, Optics, Gaussian Mixture, Birch, Bisecting K-Means.
Här du kan hitta den officiella dokumentationen.
Det här avsnittet kommer att utforska de 5 mest kända och viktiga klustringsalgoritmerna. De är K-Means, Mean-Shift, DBScan, Gaussian Mixture och Hierarchical Clustering.
Innan vi dyker djupare, låt oss titta på följande graf. Den visar hur dessa fem algoritmer fungerar på sex olika strukturerade datamängder.
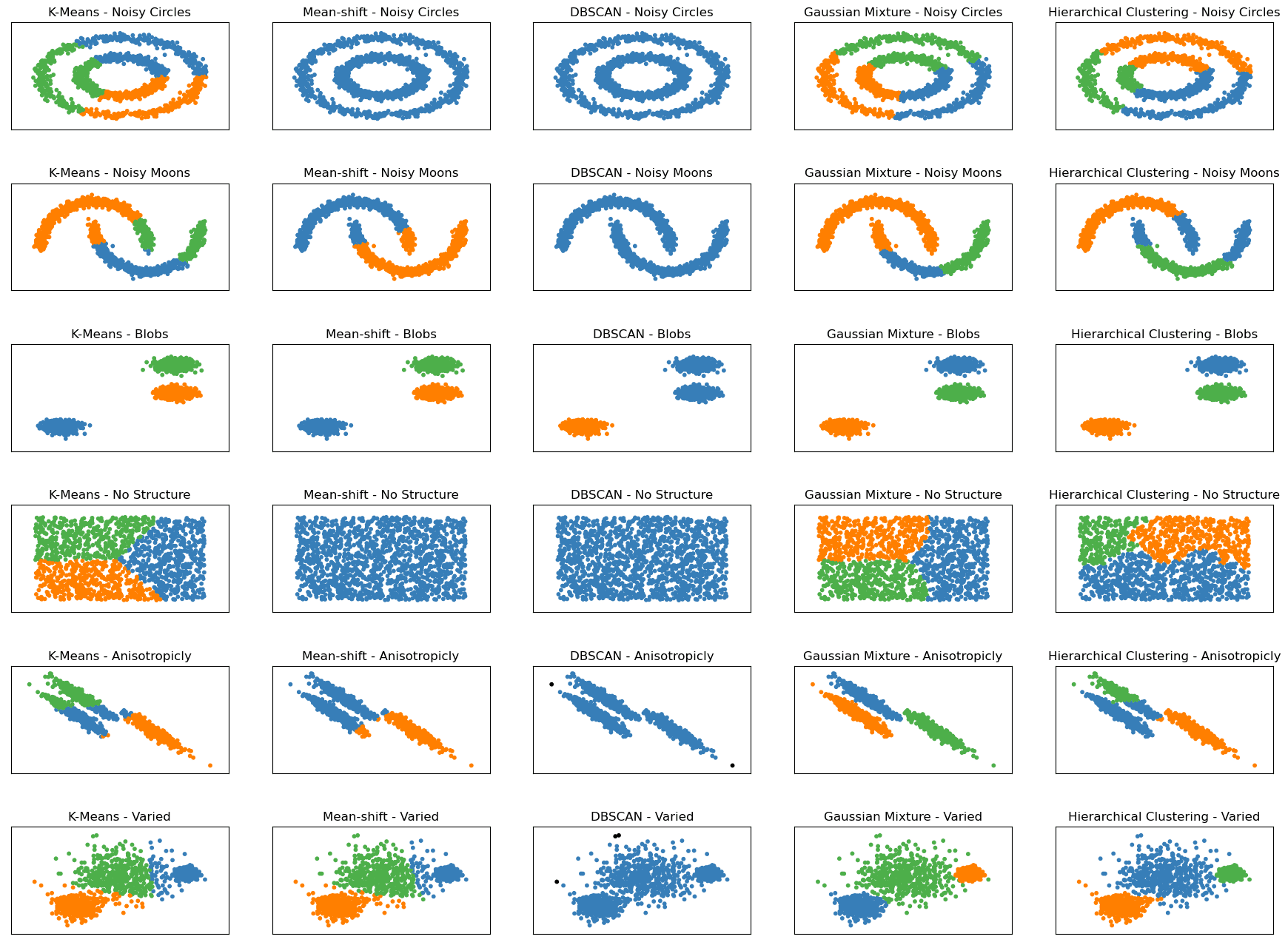
Clustering Algoritmer – Bild efter författare
I scikit-learn dokumentation, hittar du liknande grafer som inspirerade bilden ovan. Jag begränsade det till de fem mest kända klustringsalgoritmerna och lade till datasetets struktur längs algoritmnamnet, t.ex. K-Means – Noisy Moons eller K-Means Varied.
Det visas sex olika datauppsättningar, alla genererade med hjälp av scikit-learn:
- Bullriga cirklar: Denna datauppsättning består av en stor cirkel som innehåller en mindre cirkel som inte är perfekt centrerad. Data har också slumpmässigt gaussiskt brus lagt till.
- Noisy Moons: Denna datauppsättning består av två sammanflätade halvmåneformer som inte är linjärt separerbara. Data har också slumpmässigt gaussiskt brus lagt till.
- Blobbar: Denna datauppsättning består av slumpmässigt genererade blobbar som är relativt enhetliga i storlek och form. Datauppsättningen innehåller tre blobbar.
- Ingen struktur: Denna datauppsättning består av slumpmässigt genererade datapunkter utan någon inneboende struktur eller klustringsmönster.
- Anisotropiskt fördelad: Denna datauppsättning består av slumpmässigt genererade datapunkter som är anisotropiskt fördelade. Datapunkterna genereras med en specifik transformationsmatris för att göra dem förlängda längs vissa axlar.
- Varierande: Denna datauppsättning består av slumpmässigt genererade blobbar med olika varianser. Datauppsättningen innehåller tre blobbar, var och en med olika standardavvikelser.
Att se diagrammen och hur varje algoritm fungerar på dem hjälper oss att jämföra hur bra våra algoritmer presterar på varje datamängd. Detta kan hjälpa dig i ditt dataprojekt om din data har samma struktur som i dessa grafer.
Låt oss nu gräva djupare in i dessa fem algoritmer, börja med K-Means-algoritmen.
K-medel
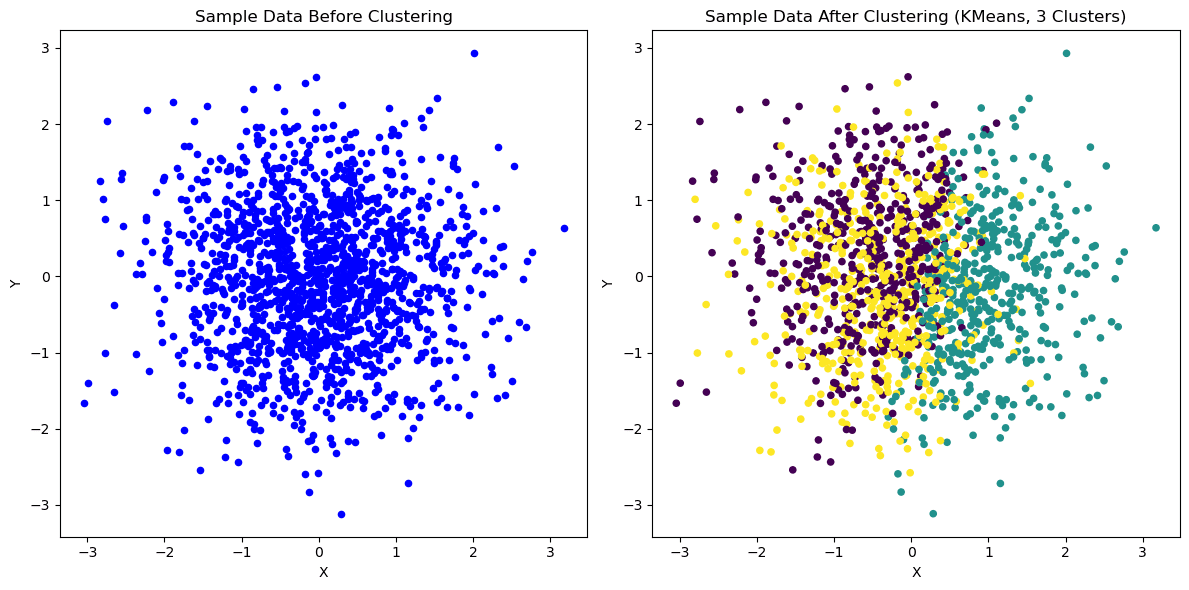
K-Means 2D | Bild av författare
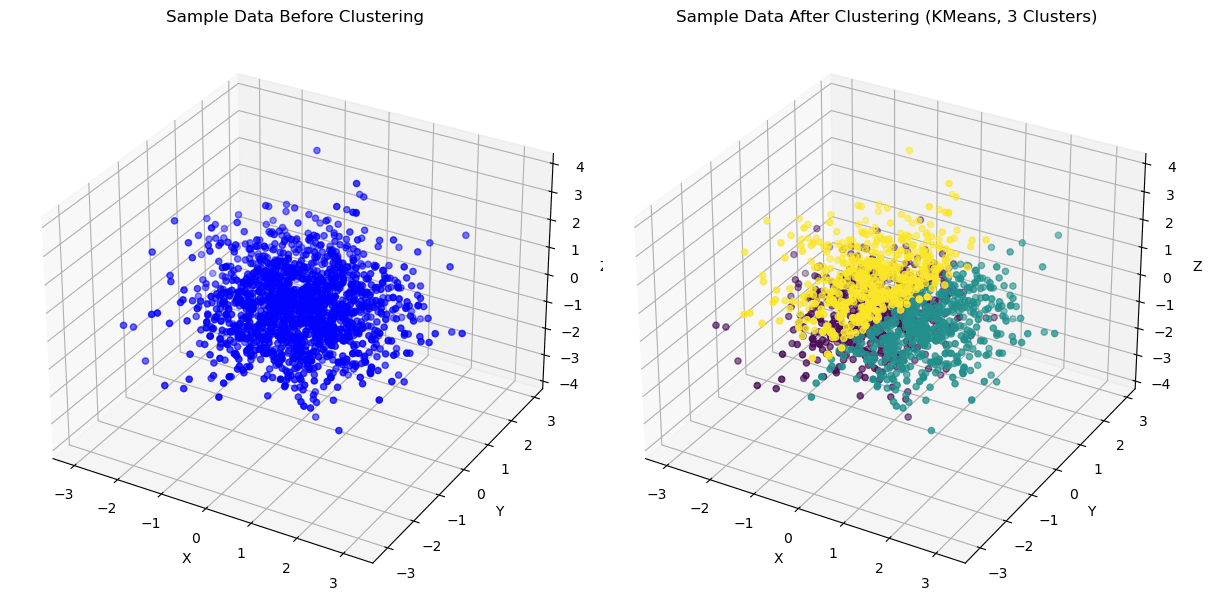
K betyder 3D | Bild av författare
K-Means är en populär klustringsalgoritm som delar upp en datauppsättning i K distinkta kluster, där K är en hyperparameter som specificeras av användaren.
Algoritmen fungerar genom att tilldela varje datapunkt till närmaste klustertyngdpunkt och sedan räkna om tyngdpunkten baserat på medelvärdet av alla datapunkter i det klustret.
Denna process fortsätter tills tyngdpunkterna inte längre rör sig eller ett specificerat maximalt antal iterationer har uppnåtts.
Det har också använts i olika verkliga tillämpningar, såsom kundsegmentering inom e-handel, sjukdomsklustring inom sjukvården och bildkomprimering i datorseende.
Fortsätt läsa för att se de verkliga tillämpningarna av K-Means eller andra algoritmer. Vi kommer att komma till det i de senare avsnitten.
DBScan
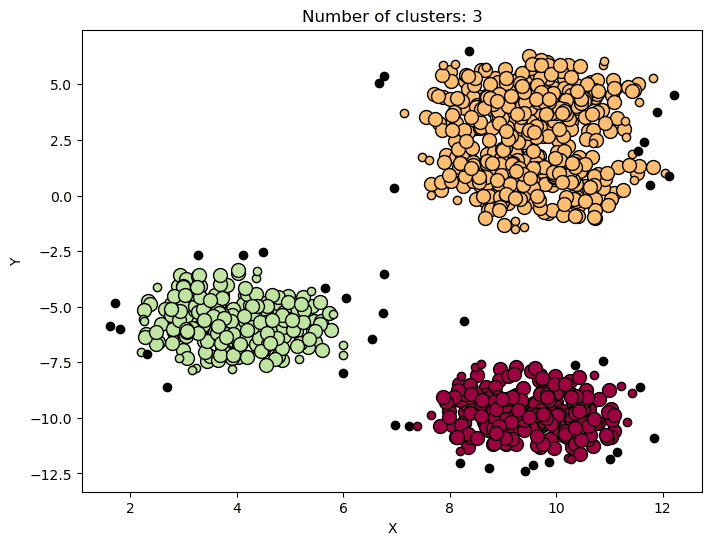
DBScan | Bild av författare
DBScan (Density-Based Spatial Clustering of Applications with Noise) är en densitetsbaserad klustringsalgoritm som identifierar kluster som högdensitetsregioner åtskilda av lågdensitetsregioner.
Algoritmen grupperar punkter som ligger nära varandra baserat på en täthetströskel och ett minsta antal punkter.
DBScan används ofta för avvikande detektering, rumslig klustring och bildsegmentering, där målet är att identifiera distinkta kluster i data samtidigt som det hanterar brusiga eller extrema datapunkter.
Hierarkisk klustring
Hierarkisk klustring | Bild av författare
Hierarchical Clustering är en klustringsalgoritm som bygger en trädliknande struktur av kluster genom att slå samman eller dela kluster.
Beroende på tillvägagångssättet kan algoritmen vara agglomerativ (nedifrån och upp) eller delande (som grafen ovan).
Hierarchical Clustering har använts i olika verkliga tillämpningar som sociala nätverksanalyser, bildsegmentering och ekologisk forskning, där målet är att identifiera meningsfulla relationer mellan kluster och subkluster.
Mean-Shift Clustering
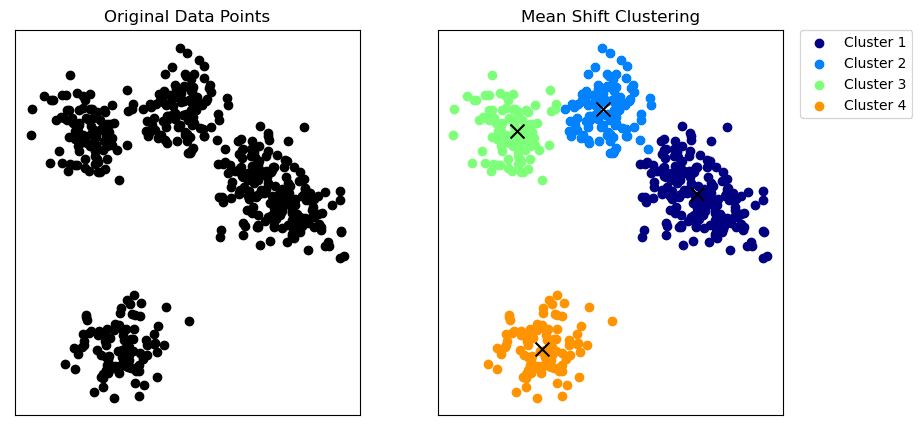
Mean-Shift Clustering | Bild av författare
Medelförskjutningsklustring är en icke-parametrisk algoritm som inte kräver tidigare antaganden om formen eller antalet kluster.
Algoritmen fungerar genom att skifta varje datapunkt mot det lokala medelvärdet (x i grafen ovan) tills konvergens, där kärndensitetsfunktionen uppskattar det lokala medelvärdet.
Algoritmen för medelförskjutning identifierar kluster som regioner med hög densitet i funktionsutrymmet.
Mean-shift-klustring har använts i verkliga applikationer som bildsegmentering, objektspårning i videoövervakning och avvikelse av anomali i nätverksintrångsdetektering, där målet är att identifiera distinkta regioner eller mönster i datan.
Gaussisk blandningsklustring
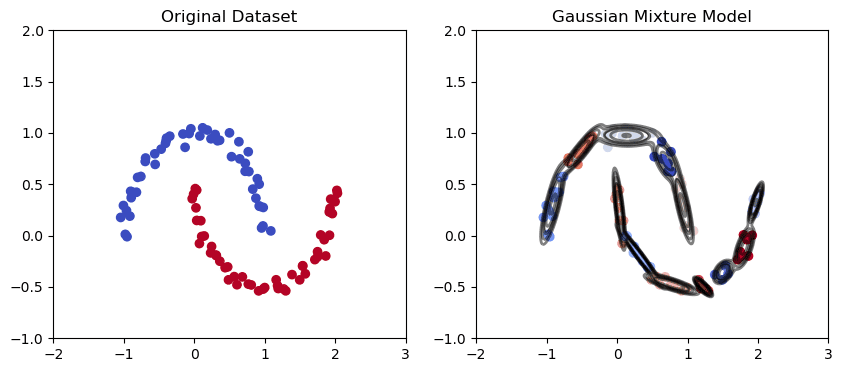
Gaussisk blandningsmodell i den månformade datamängden | Bild av författare
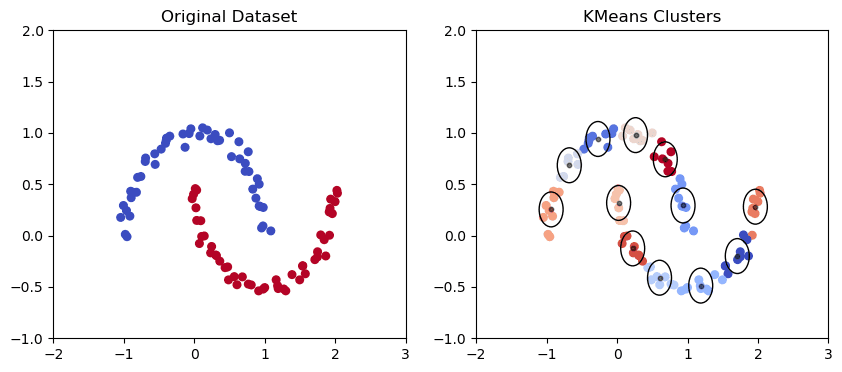
K Means Clustering Model i den månformade datamängden | Bild av författare
Gaussisk blandning är en probabilistisk klustringsalgoritm som modellerar fördelningen av datapunkter med hjälp av en blandning av Gaussfördelningar. Algoritmen anpassar en uppsättning Gauss-fördelningar till data, där varje Gauss motsvarar ett separat kluster.
Gaussisk blandning har använts i olika verkliga tillämpningar som taligenkänning, genuttrycksanalys och ansiktsigenkänning, där målet är att modellera den underliggande fördelningen av data och identifiera kluster baserat på de anpassade Gauss-fördelningarna.
Som vi kan se från grafen ovan har den Gaussiska blandningen en bättre förmåga att fånga trender i elliptiska datapunkter enligt ovan och rita elliptiska kluster.
Sammantaget har varje klustringsalgoritm sina unika styrkor och svagheter. Valet av algoritm beror på problemet och datasetets egenskaper.
Att förstå nyanserna i varje algoritm och dess användningsfall är avgörande för att uppnå korrekta och meningsfulla resultat.
Efter att ha tillämpat algoritmen måste du utvärdera dess prestanda för att se om det finns utrymme för förbättringar eller ändra algoritmen om prestandan för din algoritm inte uppfyller kriterierna. För att göra det bör du använda utvärderingsmått.
Här är en översikt över de mest populära.
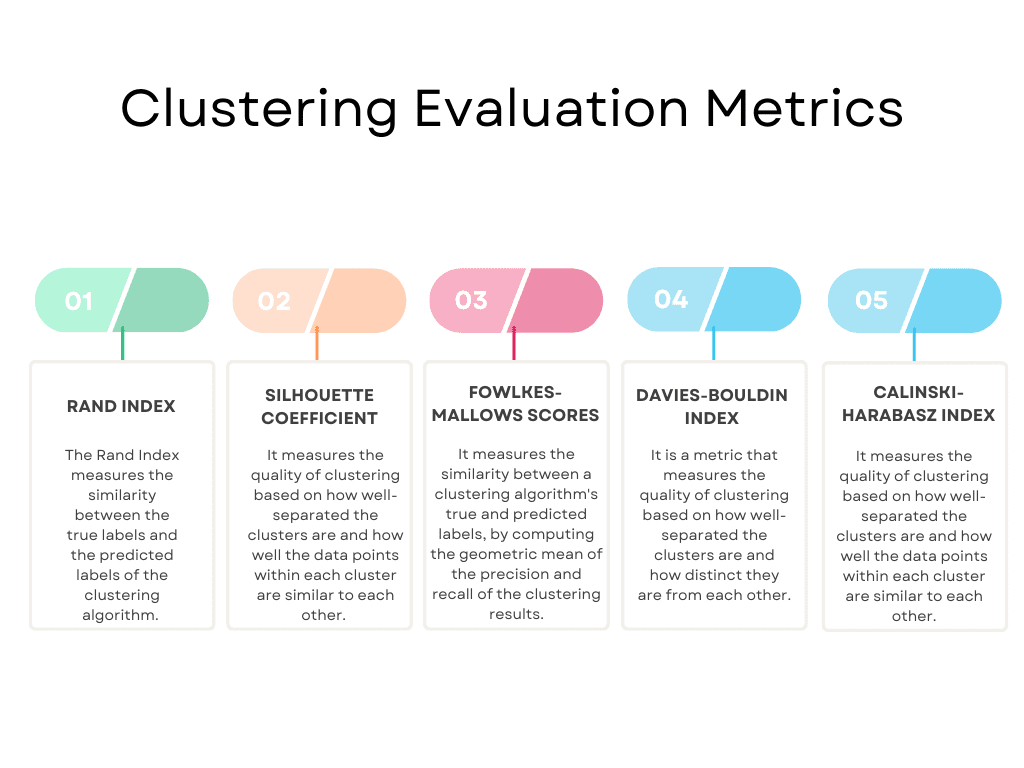
Bild av författare
Dessa är naturligtvis inte alla. Du kan få hela listan på scikit-learn. Den listar följande utvärderingsmått: Randindex, ömsesidig informationsbaserad poäng, Silhouette Coefficient, Fowlkes-Mallows poäng, Homogenitet, Fullständighet, V-mått, Calinski-Harabasz Index, Davies-Bouldin Index, Contingency Matrix, Pair Confusion Matrix.
Här du kan se de officiella dokumenten.
Vi kommer att hålla oss till de populära och börja med Rand Index.
Rand Index
Randindexet utvärderar likheten mellan de verkliga klusteretiketterna och de förutsagda klusteretiketterna.
Indexet sträcker sig från 0 till 1, där 1 indikerar en perfekt matchning mellan de sanna och förutspådda etiketterna.
Randindex används ofta i bildsegmentering, textklustring och dokumentklustring, där de verkliga beteckningarna för data är kända.
Siluettkoefficient
Silhouette Coefficient mäter kvaliteten på klustring baserat på hur väl separerade klustren är och hur lika datapunkterna inom varje kluster är.
Koefficienten sträcker sig från -1 till 1, där 1 indikerar ett väl separerat och kompakt kluster och -1 indikerar en felaktig kluster.
Silhouette Coefficient används ofta i marknadssegmentering, kundprofilering och produktrekommendationer, där målet är att identifiera meningsfulla kluster baserat på kundernas beteende och preferenser.
Fowlkes-Mallows gör mål
Fowlkes-Mallows-indexet är uppkallat efter två forskare, Edward Fowlkes och SG Mallows, som föreslog måttet 1983.
Indexet mäter likheten mellan en klustringsalgoritms sanna och förutspådda etiketter.
Poängen varierar från 0 till 1, där 1 indikerar en perfekt matchning mellan de sanna och förutspådda etiketterna.
Fowlkes-Mallows-poängen används ofta i bildsegmentering, textklustring och dokumentklustring, där de verkliga beteckningarna för data är kända.
Davies-Bouldin Index
Davies-Bouldin Index är uppkallat efter två forskare, David L. Davies och Donald W. Bouldin, som föreslog måttet 1979.
Indexet sträcker sig från 0 till oändligt, med lägre värden som indikerar bättre klustringskvalitet.
Det är praktiskt för att identifiera det optimala antalet kluster i data och för att upptäcka fall där klustren överlappar eller är för lika varandra. Indexet antar dock att klustren är sfäriska och har liknande densiteter, vilket kanske inte alltid håller i verkliga datamängder.
Davies-Bouldin Index används ofta inom marknadssegmentering, kundprofilering och produktrekommendationer, där målet är att identifiera meningsfulla kluster baserat på kundernas beteende och preferenser.
Calinski-Harabasz Index
Calinski-Harabasz Index är uppkallat efter T. Calinski och J. Harabasz, som föreslog måttet 1974.
Calinski-Harabasz Index mäter kvaliteten på klustring baserat på hur väl separerade klustren är och hur väl datapunkterna inom varje kluster liknar varandra.
Indexet sträcker sig från 0 till oändligt, med högre värden som indikerar bättre klustring.
Calinski-Harabasz Index används ofta i marknadssegmentering, kundprofilering och produktrekommendationer, där målet är att identifiera meningsfulla kluster baserat på kundernas beteende och preferenser.
Jämföra utvärderingsmått

Bild av författare
För Rand Index, Silhouette Coefficient och Fowlkes-Mallows-poäng indikerar högre värden bättre klustringsprestanda.
Bästa poängen är 1.
För Davies-Bouldin Index indikerar lägre värden bättre klustringsprestanda.
Bästa poängen är 0.
För Calinski-Harabasz Index indikerar de högsta poängen bättre prestanda.
Bästa poängen är ∞. (oändlighet.)
I teorin skulle det bästa betyget för Calinski-Harabasz (CH) Index vara oändligt, eftersom det skulle indikera en extremt hög spridning mellan kluster jämfört med spridning inom kluster. Att uppnå ett oändligt CH-indexvärde är dock inte realistiskt i praktiken.
Det finns ingen fast övre gräns för bästa poäng, eftersom det beror på specifika data och klustring.
Glöm inte: det finns ingen algoritm eller skript som är perfekt. Om du uppnår de bästa poängen med någon av dessa utvärderingsmått är det ganska troligt att din modell är överanpassad.
Syftet här är att tillämpa flera klustringsalgoritmer på Iris-datauppsättningen och beräkna deras prestanda med hjälp av olika utvärderingsmått.
Här kommer vi att använda IRIS-datauppsättningen.
Du kan hitta denna datauppsättning här..
Irisdatauppsättningen är en berömd klassificeringsdatauppsättning av flera klasser som innehåller 150 prover av irisblommor, som var och en har fyra funktioner (längd och bredd på foderblad och kronblad).

Bild från Maskininlärning i R för nybörjare
Det finns tre klasser i datasetet som representerar tre typer av irisblommor.
Datauppsättningen används ofta för maskininlärning och mönsterigenkänningsuppgifter, särskilt för att testa och jämföra olika klassificeringsalgoritmer. Den introducerades av den brittiske statistikern och biologen Ronald Fisher 1936.
Här kommer vi att skriva koden, som importerar de nödvändiga biblioteken för att ladda datamängden, implementerar fem klustringsalgoritmer (DBSCAN, K-Means, Hierarchical Clustering, Gaussian Mixture Model och Mean Shift), och utvärderar deras prestanda med hjälp av fem mätvärden.
För att göra det kommer vi att lägga till utvärderingsmått och algoritmer i ordböckerna och tillämpa dem med två för loopar varandra.
Men vi har ett undantag här. De rand_score och fowlkes_mallows_score funktioner jämför klustringsresultat med sanna etiketter, så vi lägger till om-annas block att tillhandahålla det.
Sedan kommer vi att lägga till dessa resultat i dataramen för att göra ytterligare analys.
Här är koden.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import ( DBSCAN, KMeans, AgglomerativeClustering, MeanShift,
)
from sklearn.mixture import GaussianMixture
from sklearn.metrics import ( silhouette_score, calinski_harabasz_score, davies_bouldin_score, rand_score, fowlkes_mallows_score,
) # Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target # Implement clustering algorithms
dbscan = DBSCAN(eps=0.5, min_samples=5)
kmeans = KMeans(n_clusters=3, random_state=42)
agglo = AgglomerativeClustering(n_clusters=3)
gmm = GaussianMixture(n_components=3, covariance_type="full")
ms = MeanShift() # Evaluate clustering algorithms with three evaluation metrics
labels = { "DBSCAN": dbscan.fit_predict(X), "K-Means": kmeans.fit_predict(X), "Hierarchical": agglo.fit_predict(X), "Gaussian Mixture": gmm.fit_predict(X), "Mean Shift": ms.fit_predict(X),
} metrics = { "Silhouette Score": silhouette_score, "Calinski Harabasz Score": calinski_harabasz_score, "Davies Bouldin Score": davies_bouldin_score, "Rand Score": rand_score, "Fowlkes-Mallows Score": fowlkes_mallows_score,
} for name, label in labels.items(): for metric_name, metric_func in metrics.items(): if metric_name in ["Rand Score", "Fowlkes-Mallows Score"]: score = metric_func(y, label) else: score = metric_func(X, label) pred_df = pred_df.append( {"Algorithm": name, "Metric": metric_name, "Score": score}, ignore_index=True, )
# Display the DataFrame
pred_df.head(10)
Här är utgången.
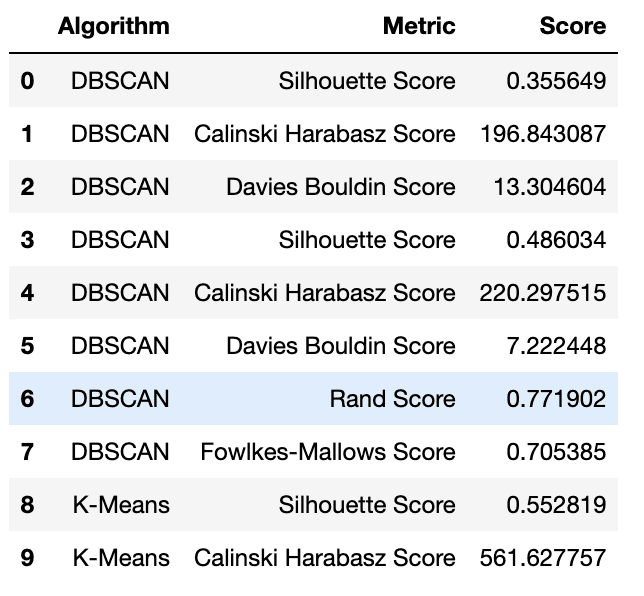
Prediction DataFrame | Bild av författare
Låt oss nu göra en visualisering för att se resultatet bättre. Här är syftet att skapa bilder av klustringsalgoritmens utvärderingsmått.
Följande kod pivoterar data för att ha algoritmer som kolumner och mätvärden som rader och genererar sedan stapeldiagram för varje mätvärde. Detta möjliggör enkel jämförelse av klustringsalgoritmernas prestanda över olika utvärderingsmått.
Här är koden.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt # Pivot the data to have algorithms as columns and metrics as rows
pivoted_df = pred_df.pivot( index="Metric", columns="Algorithm", values="Score"
) # Define the three metrics to plot
metrics = [ "Silhouette Score", "Calinski Harabasz Score", "Davies Bouldin Score",
] # Define a colormap to use for each algorithm
cmap = plt.get_cmap("Set3") # Plot a bar chart for each metric
fig, axs = plt.subplots(nrows=1, ncols=3, figsize=(15, 5)) # Add a main title to the figure
fig.suptitle("Comparing Evaluation Metrics", fontsize=16, fontweight="bold") for i, metric in enumerate(metrics): ax = pivoted_df.loc[metric].plot(kind="bar", ax=axs[i], rot=45) ax.set_xticklabels(ax.get_xticklabels(), ha="right") ax.set_ylabel(metric) ax.set_title(metric, fontstyle="italic") # Iterate through the algorithm names and set the color for each bar for j, alg in enumerate(pivoted_df.columns): ax.get_children()[j].set_color(cmap(j))
plt.show()
Här är utgången.
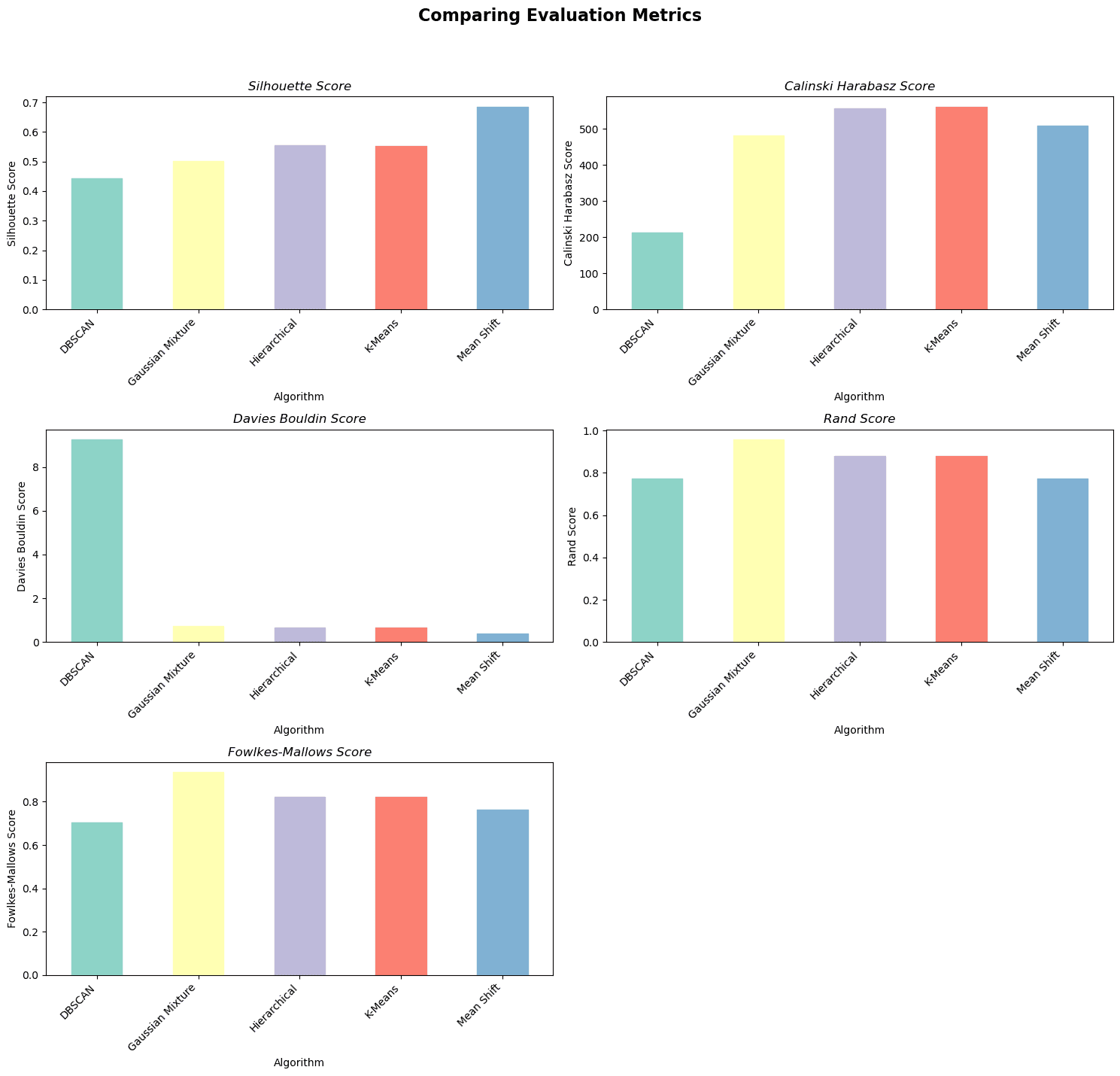
Bild av författare
Sammanfattningsvis presterar Mean Shift-algoritmen bäst enligt Silhouette Score och Davies Bouldin Score.
K-Means-algoritmen presterar bäst enligt Calinski Harabasz-poängen, och GMM presterar bäst enligt Rand- och Fowlkes-Mallows-poängen.
Det finns ingen tydlig vinnare bland klustringsalgoritmerna, eftersom var och en presterar bra på olika mätvärden.
Valet av den bästa algoritmen beror på de specifika kraven och den vikt som tilldelas varje utvärderingsmått i ditt klustringsproblem.
Låt oss nu se de verkliga exemplen på både våra algoritmer och utvärderingsmått för att förstå logiken ännu mer.
Här är översikten över de exempel vi kommer att prata om i detalj.
Bild av författare
Personalisering av supermarknadskedjor

Bild av författare
Exempel från verkligheten: En stormarknadskedja vill skapa personliga marknadsföringskampanjer för sina kunder. De använder K-Means-klustring för att segmentera kunder baserat på deras köpvanor, demografi och butiksbesöksfrekvens. Dessa segment hjälper företaget att skräddarsy sina marknadsföringsbudskap för att engagera sig bättre och betjäna sina kunder.
Algoritm: K-betyder kluster
K-Means är vald för att det är en enkel, effektiv och allmänt använd klustringsalgoritm som fungerar bra med stora datamängder. Den kan snabbt identifiera mönster och skapa distinkta kundsegment baserat på indatafunktionerna.
Utvärderingsstatistik: Silhouette Betyg
Silhouette Score används för att utvärdera kvaliteten på kundsegmentering genom att mäta hur väl varje datapunkt passar in i sitt tilldelade kluster jämfört med andra kluster. Detta hjälper till att säkerställa att klustren är kompakta och väl åtskilda, vilket är viktigt för att skapa effektiva personliga marknadsföringskampanjer.
Bedräglig transaktion

Bild av författare
Exempel från verkligheten: Ett kreditkortsföretag vill upptäcka bedrägliga transaktioner. De använder DBSCAN för att gruppera transaktioner baserat på faktorer som transaktionsbelopp, tid och plats. Ovanliga transaktioner som inte passar in i något kluster flaggas som potentiella bedrägerier för vidare utredning.
Algoritm: DBSCAN
DBSCAN är vald för att det är en densitetsbaserad klustringsalgoritm som kan identifiera kluster av varierande former och storlekar, samt detektera bruspunkter som inte tillhör något kluster. Detta gör den lämplig för att upptäcka ovanliga mönster eller extremvärden, såsom potentiellt bedrägliga transaktioner.
Utvärderingsstatistik: Silhouette Betyg
Silhouette Score väljs som ett utvärderingsmått i det här fallet eftersom det hjälper till att bedöma effektiviteten av DBSCAN genom att separera normala transaktioner från potentiella extremvärden som representerar bedrägeri.
En högre Silhouette Score indikerar att klustren av vanliga transaktioner är väl separerade från varandra och bruspunkterna (outliers). Denna separation gör det lättare att identifiera och flagga misstänkta transaktioner som avviker avsevärt från normala mönster.
Cancer Genomics Relation
Bild av författare
Exempel från verkligheten: Forskare som studerar cancergenomik vill förstå sambanden mellan olika typer av cancerceller. De använder Hierarchical Clustering för att gruppera celler baserat på deras genuttrycksmönster. De resulterande klustren hjälper dem att identifiera likheter och skillnader mellan cancertyper och utveckla riktade terapier.
Algoritm: Agglomerativ hierarkisk klustring
Agglomerative Hierarchical Clustering är vald för att det skapar en trädliknande struktur (dendrogram) som gör det möjligt för forskare att visualisera och tolka relationerna mellan cancerceller på flera nivåer av granularitet. Detta tillvägagångssätt kan avslöja kapslade undergrupper av celler och hjälper forskare att förstå den hierarkiska organisationen av cancertyper baserat på deras genuttrycksmönster.
Utvärderingsvärden: Calinski-Harabasz Index
Calinski-Harabasz-indexet väljs i det här fallet eftersom det mäter förhållandet mellan klusterspridning och dispersion inom kluster. För cancergenomik hjälper det forskare att utvärdera klustringskvaliteten i termer av hur distinkta och väl åtskilda grupperna av cancerceller är baserat på deras genuttrycksmönster.
Autonom bil
Bild av författare
Exempel från verkligheten: En självkörande bilfirma vill förbättra bilens förmåga att identifiera föremål i sin omgivning. De använder Mean-Shift Clustering för att segmentera bilder som tagits av bilens kameror i olika regioner baserat på färg och textur, vilket hjälper bilen att känna igen och spåra föremål som fotgängare och andra fordon.
Algoritm: Genomsnittlig skiftklustring
Mean Shift-klustring väljs eftersom det är en icke-parametrisk, densitetsbaserad algoritm som automatiskt kan anpassa sig till den underliggande strukturen och skalan av datan.
Detta gör den särskilt lämplig för bildsegmenteringsuppgifter, där antalet kluster eller regioner kanske inte är känt i förväg, och formerna på regionerna kan vara komplexa och oregelbundna.
Utvärderingsvärden: Fowlkes-Mallows Score (FMS)
Fowlkes-Mallows-poängen väljs i det här fallet eftersom den mäter likheten mellan två klustringar, vanligtvis jämför algoritmens utdata med en jordsanningsklustring.
I samband med självkörande bilar kan FMS användas för att bedöma hur väl Mean Shift-klustringsalgoritmen segmenterar bilderna jämfört med människomärkta segmentering.
Nyheter Rekommendation

Bild av författare
Exempel från verkligheten: En nyhetsplattform online vill gruppera artiklar i ämnen för att förbättra innehållsrekommendationer för sina användare. De använder Gaussiska blandningsmodeller för att gruppera artiklar baserade på egenskaper som extraherats från deras texter, såsom ordfrekvens och termsamförekomst. Genom att identifiera distinkta ämnen kan plattformen rekommendera artiklar som är mer relevanta för en användares intressen.
Algoritm: Gaussisk blandningsmodell (GMM) klustring
Gaussiska blandningsmodeller väljs eftersom de är ett probabilistiskt, generativt tillvägagångssätt som kan modellera komplexa, överlappande kluster. Detta är särskilt användbart för textdata, där artiklar kan tillhöra flera ämnen eller har delade funktioner. GMM kan fånga dessa nyanser och ge en mjuk klustring, som tilldelar varje artikel en sannolikhet att tillhöra varje ämne.
Utvärderingsvärden: Silhouette Coefficient
Silhouette-koefficienten är vald för att den mäter kompaktheten och separationen av klustren, vilket hjälper till att bedöma kvaliteten på ämnesuppgifterna.
En högre siluettkoefficient indikerar att artiklarna inom ett ämne är mer lika varandra och skiljer sig från andra ämnen, vilket är viktigt för korrekta innehållsrekommendationer.
Om du vill veta mer om Unsupervised algoritmer, här kan du samla mer information om "Oövervakade inlärningsalgoritmer”. Kolla också in "Övervakad vs oövervakad inlärning” de två tillvägagångssätten som vi bör känna till i en värld av maskininlärning.
Sammanfattningsvis är klustring en viktig oövervakad inlärningsteknik som används för att hitta likheter eller mönster i data utan förkunskaper om klassetiketter.
Vi diskuterade olika klustringsalgoritmer, inklusive K-Means, Mean Shift, DBScan, Gaussian Mixture och Hierarchical Clustering, tillsammans med deras användningsfall och verkliga tillämpningar.
Dessutom undersökte vi olika utvärderingsmått, inklusive Silhouette Coefficient, Calinski-Harabasz Index och Davies-Bouldin Index, som hjälper oss att bedöma kvaliteten på klustringsresultat.
Vi lärde oss också hur man utvecklar flera klustringsalgoritmer samtidigt med scikit-learn och utvärderade dem med hjälp av de mätvärden vi redan hade upptäckt.
Slutligen diskuterade vi några populära applikationer som använde klustringsalgoritmer för att lösa verkliga problem.
Om du fortfarande har frågor, här är en artikel som förklarar Clustering och dess algoritmer.
Clustering har ett brett utbud av applikationer, från kundsegmentering inom marknadsföring till bildigenkänning i datorseende, och det är ett viktigt verktyg för att upptäcka dolda mönster och insikter i data.
Nate Rosidi är datavetare och inom produktstrategi. Han är också adjungerad professor som undervisar i analys och är grundaren av StrataScratch, en plattform som hjälper datavetare att förbereda sig för sina intervjuer med riktiga intervjufrågor från toppföretag. Ta kontakt med honom Twitter: StrataScratch or LinkedIn.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/05/clustering-scikitlearn-tutorial-unsupervised-learning.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-with-scikit-learn-a-tutorial-on-unsupervised-learning
- : har
- :är
- :inte
- :var
- 1
- 10
- 11
- 15%
- 27
- 2D
- 3d
- a
- förmåga
- Om Oss
- ovan
- Enligt
- exakt
- Uppnå
- uppnå
- tvärs
- anpassa
- lägga till
- lagt till
- avancera
- Efter
- Syftet
- algoritm
- algoritmer
- Alla
- tillåter
- längs
- redan
- också
- alltid
- bland
- mängd
- an
- analys
- analytics
- och
- vilken som helst
- tillämpningar
- Ansök
- Tillämpa
- tillvägagångssätt
- tillvägagångssätt
- ÄR
- Artikeln
- artiklar
- AS
- delad
- At
- automatiskt
- tillgänglig
- genomsnitt
- AXLAR
- AXS
- bar
- baserat
- BE
- därför att
- varit
- BÄST
- Bättre
- mellan
- nål
- båda
- bunden
- Brittiska
- bygger
- by
- beräkna
- kameror
- Kampanjer
- KAN
- Kan få
- Cancer
- Cancerceller
- fånga
- Fångande
- bil
- kortet
- bilar
- Vid
- fall
- Celler
- centrerad
- vissa
- kedja
- byta
- egenskaper
- Diagram
- Diagram
- ta
- val
- valda
- Circle
- cirklar
- klass
- klasser
- klassificering
- klar
- Stäng
- kluster
- klustring
- koda
- samla
- färg
- Kolonner
- COM
- vanligen
- Företag
- företag
- jämföra
- jämfört
- jämförande
- jämförelse
- fullborda
- komplex
- dator
- Datorsyn
- slutsats
- förvirring
- Kontakta
- innehåller
- innehåll
- sammanhang
- fortsätta
- fortsätter
- Konvergens
- motsvarar
- Naturligtvis
- skapa
- skapar
- Skapa
- kredit
- kreditkort
- kriterier
- avgörande
- kund
- kundbeteende
- Kunder
- datum
- datapunkter
- datavetare
- datauppsättning
- datauppsättningar
- David
- djupare
- Demografi
- demonstrera
- densitet
- beror
- detalj
- Detektering
- utveckla
- avvikelse
- skillnader
- olika
- GRÄV
- Upptäck
- upptäckt
- upptäcka
- diskuteras
- diskutera
- Sjukdom
- Dispersion
- Visa
- distinkt
- distribueras
- fördelning
- Distributioner
- do
- dokumentera
- dokumentation
- dokument
- gör
- donation
- donald
- ritning
- e
- e-handel
- varje
- lättare
- lätt
- Ekologisk
- Edward
- Effektiv
- effektivitet
- effektiv
- annars
- anställd
- möjliggör
- engagera
- säkerställa
- väsentlig
- uppskattningar
- utvärdera
- utvärderade
- utvärdering
- Även
- exempel
- undantag
- förklara
- utforska
- utforskas
- Uttrycket
- extremt
- Ansikte
- ansiktsigenkänning
- faktorer
- bekant
- kända
- Leverans
- Funktioner
- Fig.
- Figur
- hitta
- Förnamn
- passa
- fixerad
- flaggad
- efter
- För
- grundare
- fyra
- RAM
- bedrägeri
- bedräglig
- Frekvens
- från
- full
- fungera
- funktioner
- ytterligare
- genereras
- genererar
- generativ
- genomik
- skaffa sig
- Målet
- diagram
- grafer
- grepp
- Grupp
- Gruppens
- vägleda
- hade
- sidan
- Arbetsmiljö
- praktisk
- Har
- har
- he
- hälso-och sjukvård
- hjälpa
- hjälpa
- hjälper
- här.
- dold
- Hög
- högre
- högsta
- Markera
- honom
- hålla
- Hur ser din drömresa ut
- How To
- Men
- html
- HTTPS
- i
- ICS
- identifierar
- identifiera
- identifiera
- if
- bild
- Bildigenkänning
- bildsegmentering
- bilder
- genomföra
- redskap
- importera
- vikt
- med Esport
- import
- förbättra
- förbättring
- in
- Inklusive
- index
- indikerar
- pekar på
- indikerar
- Oändlighet
- informationen
- inneboende
- ingång
- insikter
- inspirerat
- intressen
- Intervju
- intervjufrågor
- Intervjuer
- in
- introducerade
- intrångsdetektering
- Undersökningen
- IT
- iterationer
- DESS
- jpg
- KDnuggets
- Vet
- kunskap
- känd
- etikett
- Etiketter
- Large
- senare
- lärt
- inlärning
- Längd
- nivåer
- bibliotek
- Bibliotek
- tycka om
- sannolikt
- Begränsad
- Lista
- listor
- läsa in
- lokal
- läge
- Logiken
- längre
- se
- Maskinen
- maskininlärning
- Huvudsida
- göra
- GÖR
- marknad
- Marknadsföring
- Marknadsföringskampanjer
- Match
- matplotlib
- Matris
- maximal
- Maj..
- betyda
- betyder
- meningsfull
- betyder
- åtgärder
- mätning
- Möt
- sammanslagning
- meddelanden
- metriska
- Metrics
- minsta
- blandning
- modell
- modeller
- Moons
- mer
- mest
- Mest populär
- flytta
- MS
- multipel
- ömsesidigt
- namn
- Som heter
- namn
- nödvändigt för
- Behöver
- nät
- nyheter
- Nej
- Brus
- normala
- antal
- numpy
- objektet
- objekt
- of
- tjänsteman
- Ofta
- on
- gång
- ONE
- ettor
- nätet
- optik
- optimala
- or
- organisation
- Övriga
- vår
- ut
- Resultat
- produktion
- Översikt
- par
- pandor
- särskilt
- Mönster
- mönster
- perfekt
- utföra
- prestanda
- utför
- personlig
- pivot
- svänger
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poäng
- Populära
- potentiell
- potentiellt
- praktiken
- förutsagda
- preferenser
- Förbered
- Innan
- Sannolikheten
- Problem
- problem
- process
- Produkt
- Professor
- profilering
- projektet
- föreslagen
- ge
- förutsatt
- inköp
- Syftet
- Python
- kvalitet
- frågor
- snabbt
- rand
- slumpmässig
- slumpmässigt genererade
- område
- ratio
- kommit fram till
- Läsning
- verklig
- verkliga världen
- realistisk
- erkännande
- känner igen
- rekommenderar
- Rekommendation
- rekommendationer
- regioner
- regelbunden
- Förhållanden
- relativt
- relevanta
- representerar
- kräver
- Krav
- forskning
- forskare
- att
- resultera
- resulterande
- Resultat
- avslöjar
- höger
- Rum
- s
- Samma
- Skala
- Forskare
- vetenskapsmän
- scikit lära
- göra
- §
- sektioner
- se
- segmentet
- segmentering
- segment
- själv driving
- självkörande bil
- separat
- separerande
- tjänar
- in
- Forma
- former
- delas
- skifta
- SKIFTANDE
- Kort
- skall
- visas
- Visar
- signifikant
- liknande
- Likheterna
- Enkelt
- samtidigt
- SEX
- Storlek
- storlekar
- mindre
- So
- Social hållbarhet
- sociala nätverk
- Mjuk
- LÖSA
- några
- Utrymme
- rumsliga
- speciell
- specifik
- specificerade
- tal
- Taligenkänning
- standard
- starta
- Starta
- Stick
- Fortfarande
- lagra
- Strategi
- styrkor
- struktur
- strukturerade
- Studerar
- sådana
- lämplig
- SAMMANFATTNING
- övervakning
- misstänksam
- Diskussion
- Målet
- riktade
- uppgifter
- Undervisning
- villkor
- Testning
- den där
- Smakämnen
- Grafen
- världen
- deras
- Dem
- sedan
- Teorin
- Där.
- Dessa
- de
- detta
- tre
- tröskelvärde
- Genom
- tid
- Titel
- till
- tillsammans
- alltför
- verktyg
- topp
- ämne
- ämnen
- mot
- spår
- Spårning
- transaktion
- Transaktioner
- Transformation
- Trender
- sann
- handledning
- två
- typer
- typiskt
- underliggande
- förstå
- unika
- oövervakat lärande
- tills
- ovanlig
- us
- användning
- Begagnade
- Användare
- användare
- med hjälp av
- utnyttjas
- värde
- Värden
- olika
- fordon
- Video
- videoövervakning
- syn
- Besök
- visualisering
- visuella
- vs
- W
- vill
- vill
- var
- we
- VÄL
- om
- som
- medan
- VEM
- bred
- Brett utbud
- kommer
- vinnare
- med
- inom
- utan
- ord
- Arbete
- fungerar
- världen
- skulle
- skriva
- X
- dig
- Din
- zephyrnet









