Bild av frimufilms on Freepik
Det här är en era där AI:s genombrott kommer dagligen. Vi hade inte många AI-genererade offentligt för några år sedan, men nu är tekniken tillgänglig för alla. Det är utmärkt för många enskilda kreatörer eller företag som vill dra nytta av tekniken för att utveckla något komplext, vilket kan ta lång tid.
Ett av de mest otroliga genombrotten som förändrar hur vi arbetar är releasen av GPT-3.5-modell från OpenAI. Vad är GPT-3.5-modellen? Om jag låter modellen prata för sig själva. I så fall är svaret "en mycket avancerad AI-modell inom området naturlig språkbehandling, med stora förbättringar för att generera kontextuellt korrekt och relevant textt ”.
OpenAI tillhandahåller ett API för GPT-3.5-modellen som vi kan använda för att utveckla en enkel app, till exempel en textsammanfattning. För att göra det kan vi använda Python för att sömlöst integrera modellens API i vår avsedda applikation. Hur ser processen ut? Låt oss gå in i det.
Det finns några förutsättningar innan du följer den här handledningen, inklusive:
– Kunskaper om Python, inklusive kunskap om att använda externa bibliotek och IDE
– Förståelse för API:er och hantering av slutpunkten med Python
– Att ha tillgång till OpenAI API:er
För att få åtkomst till OpenAI API:er måste vi registrera oss på OpenAI Developer Platform och besök Visa API-nycklarna i din profil. På webben klickar du på knappen "Skapa ny hemlig nyckel" för att få API-åtkomst (se bilden nedan). Kom ihåg att spara nycklarna, eftersom de inte kommer att visas nycklarna efter det.

Bild av författare
Med alla förberedelser redo, låt oss försöka förstå grunderna i OpenAI API-modellen.
Smakämnen GPT-3.5 familjemodell specificerades för många språkuppgifter, och varje modell i familjen utmärker sig i vissa uppgifter. För detta handledningsexempel skulle vi använda gpt-3.5-turbo eftersom det var den rekommenderade nuvarande modellen när den här artikeln skrevs för dess förmåga och kostnadseffektivitet.
Vi använder ofta text-davinci-003 i OpenAI-handledningen, men vi skulle använda den nuvarande modellen för denna handledning. Vi skulle lita på ChatCompletion endpoint istället för Completion eftersom den nuvarande rekommenderade modellen är en chattmodell. Även om namnet var en chattmodell, fungerar det för alla språkuppgifter.
Låt oss försöka förstå hur API:et fungerar. Först måste vi installera de nuvarande OpenAI-paketen.
pip install openai
Efter att vi har installerat klart paketet kommer vi att försöka använda API:t genom att ansluta via ChatCompletion-slutpunkten. Men vi måste ställa in miljön innan vi fortsätter.
I din favorit-IDE (för mig är det VS-kod), skapa två filer som heter .env och summarizer_app.py, liknande bilden nedan.
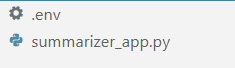
Bild av författare
Smakämnen summarizer_app.py är där vi skulle bygga vår enkla summarizer-applikation, och .env filen är där vi skulle lagra vår API-nyckel. Av säkerhetsskäl rekommenderas det alltid att separera vår API-nyckel i en annan fil istället för att hårdkoda dem i Python-filen.
I .env lägg in följande syntax och spara filen. Ersätt your_api_key_here med din faktiska API-nyckel. Ändra inte API-nyckeln till ett strängobjekt; låt dem vara som de är.
OPENAI_API_KEY=your_api_key_here
För att förstå GPT-3.5 API bättre; vi skulle använda följande kod för att generera ordet summarizer.
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
Ovanstående kod är hur vi interagerar med OpenAI APIs GPT-3.5-modell. Med ChatCompletion API skapar vi en konversation och kommer att få det avsedda resultatet efter att ha klarat uppmaningen.
Låt oss dela upp varje del för att förstå dem bättre. I den första raden använder vi openai.ChatCompletion.create kod för att skapa svaret från prompten som vi skulle skicka in i API:t.
På nästa rad har vi våra hyperparametrar som vi använder för att förbättra våra textuppgifter. Här är sammanfattningen av varje hyperparameterfunktion:
model: Modellfamiljen vi vill använda. I den här handledningen använder vi den nuvarande rekommenderade modellen (gpt-3.5-turbo).max_tokens: Den övre gränsen för de genererade orden av modellen. Det hjälper till att begränsa längden på den genererade texten.temperature: Modellens slumpmässighet, med en högre temperatur, innebär ett mer mångsidigt och kreativt resultat. Värdeintervallet är mellan 0 och oändligt, även om värden över 2 inte är vanliga.top_p: Top P eller top-k sampling eller kärnsampling är en parameter för att styra samplingspoolen från utmatningsfördelningen. Till exempel betyder värde 0.1 att modellen bara samplar utdata från de översta 10 % av distributionen. Värdeintervallet var mellan 0 och 1; högre värden innebär ett mer varierat resultat.frequency_penalty: Straffet för upprepningstoken från utgången. Värdeintervallet mellan -2 och 2, där positiva värden skulle undertrycka modellen från att upprepa token medan negativa värden uppmuntrar modellen att använda mer upprepade ord. 0 betyder inget straff.messages: Parametern där vi skickar vår textprompt som ska bearbetas med modellen. Vi skickar en lista med ordböcker där nyckeln är rollobjektet (antingen "system", "användare" eller "assistent") som hjälper modellen att förstå sammanhanget och strukturen samtidigt som värdena är sammanhanget.- Rollen "system" är de fastställda riktlinjerna för modellens "assistent" beteende,
- Rollen "användare" representerar uppmaningen från personen som interagerar med modellen,
- Rollen "assistent" är svaret på "användar"-prompten
Efter att ha förklarat parametern ovan kan vi se att messages parametern ovan har två ordboksobjekt. Den första ordboken är hur vi ställer in modellen som en textsammanfattning. Den andra är där vi skulle skicka vår text och få sammanfattningen.
I den andra ordboken ser du även variabeln person_type och prompt. De person_type är en variabel som jag använde för att styra den sammanfattade stilen, som jag kommer att visa i handledningen. Medan prompt är där vi skulle skicka vår text för att sammanfattas.
Fortsätt med handledningen, placera koden nedan i summarizer_app.py fil och vi ska försöka gå igenom hur funktionen nedan fungerar.
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
Koden ovan är där vi skapar en Python-funktion som skulle acceptera olika parametrar som vi har diskuterat tidigare och returnera textsammanfattningen.
Prova funktionen ovan med din parameter och se utdata. Låt oss sedan fortsätta med handledningen för att skapa en enkel applikation med det strömbelysta paketet.
Strömbelyst är ett Python-paket med öppen källkod designat för att skapa webbappar för maskininlärning och datavetenskap. Det är lätt att använda och intuitivt, så det rekommenderas för många nybörjare.
Låt oss installera det streamlit-paketet innan vi fortsätter med handledningen.
pip install streamlit
När installationen är klar lägger du in följande kod i summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
Försök att köra följande kod i din kommandotolk för att starta programmet.
streamlit run summarizer_app.py
Om allt fungerar bra kommer du att se följande applikation i din standardwebbläsare.
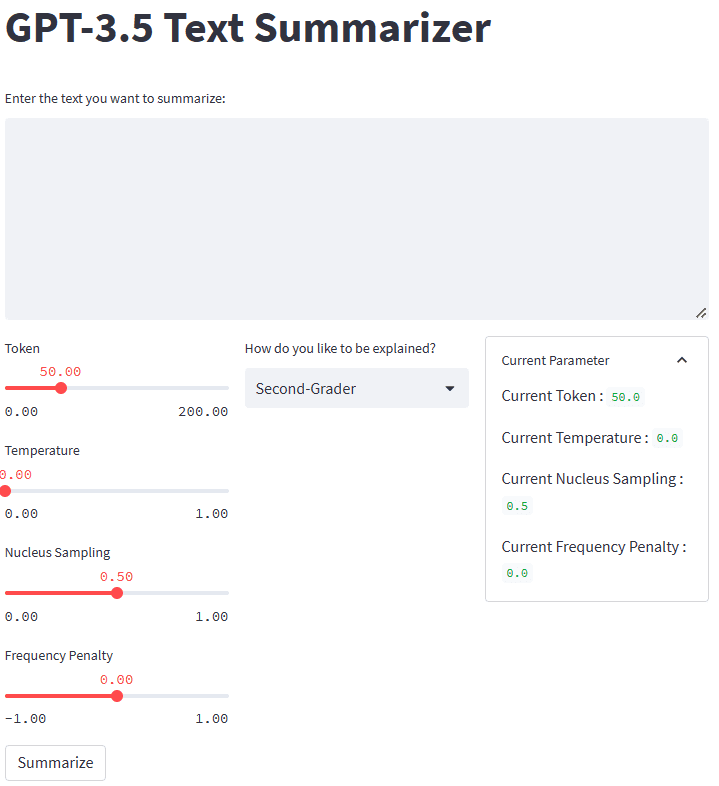
Bild av författare
Så, vad hände i koden ovan? Låt mig kort förklara varje funktion vi använde:
.st.title: Ange titeltexten för webbapplikationen..st.write: Skriver argumentet i applikationen; det kan vara allt annat än en strängtext..st.text_area: Ange ett område för textinmatning som kan lagras i variabeln och användas för uppmaningen till vår textsammanfattning.st.columns: Objektbehållare för att ge interaktion sida vid sida..st.slider: Tillhandahåll en skjutreglage med inställda värden som användaren kan interagera med. Värdet lagras i en variabel som används som modellparameter..st.selectbox: Tillhandahåll en urvalswidget så att användarna kan välja den sammanfattningsstil de vill ha. I exemplet ovan använder vi fem olika stilar..st.expander: Tillhandahåll en behållare som användare kan expandera och hålla flera objekt..st.button: Tillhandahåller en knapp som kör den avsedda funktionen när användaren trycker på den.
Eftersom streamlit automatiskt skulle designa användargränssnittet efter den givna koden från topp till botten, kunde vi fokusera mer på interaktionen.
Med alla bitar på plats, låt oss prova vår sammanfattningsapplikation med ett textexempel. För vårt exempel skulle jag använda Relativitetsteorin Wikipedia-sida text som ska sammanfattas. Med en standardparameter och andraklassningsstil får vi följande resultat.
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
Du kan få ett annat resultat än det ovanstående. Låt oss prova Housewives-stilen och justera parametern lite (Token 100, Temperatur 0.5, Nucleus Sampling 0.5, Frequency Penalty 0.3).
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
Som vi kan se finns det en skillnad i stil för samma text som vi tillhandahåller. Med en ändringsuppmaning och parameter kan vår applikation vara mer funktionell.
Det övergripande utseendet på vår textsammanfattningsapplikation kan ses i bilden nedan.
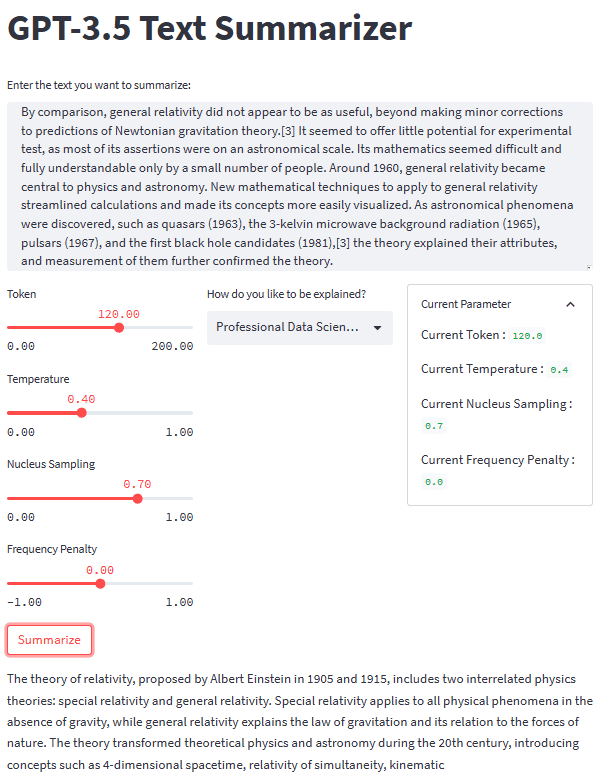
Bild av författare
Det är handledningen för att skapa text summarizer-applikationsutveckling med GPT-3.5. Du kan justera applikationen ytterligare och distribuera applikationen.
Generativ AI ökar, och vi borde utnyttja möjligheten genom att skapa en fantastisk applikation. I den här handledningen kommer vi att lära oss hur GPT-3.5 OpenAI API:erna fungerar och hur man använder dem för att skapa en textsammanfattningsapplikation med hjälp av Python och strömbelyst paket.
Cornellius Yudha Wijaya är biträdande chef för datavetenskap och dataskribent. Medan han arbetar heltid på Allianz Indonesia älskar han att dela Python- och Data-tips via sociala medier och skrivande media.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :är
- ][s
- $UPP
- 1
- 100
- 28
- 7
- a
- Om oss
- ovan
- Acceptera
- tillgång
- tillgänglig
- exakt
- förvärva
- avancerat
- Fördel
- Efter
- AI
- Alla
- Allianz
- Även
- alltid
- och
- Annan
- svara
- api
- API-åtkomst
- API: er
- app
- Ansökan
- Application Development
- appar
- ÄR
- OMRÅDE
- Argumentet
- Artikeln
- AS
- Assistent
- astronomi
- At
- automatiskt
- grundläggande
- BE
- därför att
- innan
- Nybörjare
- nedan
- Bättre
- mellan
- Bit
- Svart
- svarta hål
- Botten
- Box
- Ha sönder
- genombrott
- genombrott
- i korthet
- webbläsare
- SLUTRESULTAT
- Knappen
- by
- kallas
- KAN
- Vid
- Århundrade
- byta
- val
- klick
- koda
- Kolonner
- kommande
- Gemensam
- Företag
- fullbordan
- komplex
- Begreppen
- Anslutning
- Behållare
- Behållare
- innehåll
- sammanhang
- fortsätta
- kontroll
- Konversation
- kunde
- skapa
- Skapa
- Kreativ
- skaparna
- Aktuella
- dagligen
- datum
- datavetenskap
- datavetare
- Standard
- distribuera
- Designa
- utformade
- utveckla
- Utvecklare
- Utveckling
- Skillnaden
- olika
- Upptäck
- diskuteras
- fördelning
- flera
- inte
- ner
- varje
- antingen
- uppmuntra
- Slutpunkt
- ange
- Miljö
- Era
- Eter (ETH)
- Även
- alla
- allt
- exempel
- utmärkt
- exekvera
- Bygga ut
- Förklara
- förklarade
- Förklarar
- extern
- familj
- fantastisk
- Favoriten
- få
- fält
- Fil
- Filer
- Förnamn
- Fokus
- efter
- För
- Krafter
- Frekvens
- från
- fungera
- funktionella
- ytterligare
- Allmänt
- generera
- genereras
- generera
- skaffa sig
- ges
- gravitations
- Gravitationsvågor
- tyngdkraften
- riktlinjer
- Arbetsmiljö
- hänt
- Har
- har
- hjälpa
- hjälpte
- hjälp
- hjälper
- här.
- högre
- höggradigt
- hålla
- Hål
- Hur ser din drömresa ut
- How To
- Hur vi arbetar
- Men
- HTTPS
- i
- idéer
- bild
- importera
- med Esport
- förbättra
- förbättringar
- in
- innefattar
- Inklusive
- otroligt
- individuellt
- Indonesien
- Oändlighet
- initiera
- ingång
- installera
- installera
- istället
- integrera
- interagera
- interagera
- interaktion
- införa
- intuitiv
- IT
- DESS
- jpg
- KDnuggets
- Nyckel
- nycklar
- kunskap
- språk
- Lag
- LÄRA SIG
- inlärning
- Längd
- bibliotek
- tycka om
- BEGRÄNSA
- linje
- Lista
- Lång
- länge sedan
- se
- ser ut som
- Maskinen
- maskininlärning
- chef
- många
- betyder
- Media
- meddelande
- kanske
- modell
- mer
- mest
- flytta
- multipel
- namn
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Natur
- Behöver
- negativ
- Nya
- Nästa
- objektet
- objekt
- få
- of
- on
- ONE
- öppen källkod
- OpenAI
- Möjlighet
- Alternativet
- OS
- Övriga
- produktion
- övergripande
- paket
- paket
- parameter
- parametrar
- del
- Förbi
- personen
- fysisk
- Fysik
- bitar
- Plats
- Planeter
- plato
- Platon Data Intelligence
- PlatonData
- poolen
- positiv
- förutsäga
- förutsättningar
- tidigare
- process
- bearbetning
- professionell
- Profil
- föreslagen
- ge
- ger
- allmän
- sätta
- Python
- slumpmässighet
- område
- snarare
- redo
- skäl
- rekommenderas
- registrera
- förhållande
- frigöra
- relevanta
- ihåg
- repetitiva
- ersätta
- representerar
- respons
- resultera
- avkastning
- stigande
- Roll
- Körning
- Samma
- Save
- Vetenskap
- Forskare
- sömlöst
- Andra
- Secret
- §
- säkerhet
- Val
- separat
- in
- Dela
- skall
- show
- visas
- signifikant
- liknande
- Enkelt
- reglaget
- smarta
- So
- Social hållbarhet
- sociala medier
- några
- något
- Utrymme
- speciell
- specificerade
- Stjärnor
- lagra
- lagras
- Sträng
- struktur
- student
- stil
- stilar
- sådana
- sammanfatta
- SAMMANFATTNING
- syntax
- system
- Ta
- Diskussion
- Talks
- uppgift
- uppgifter
- Teknologi
- den där
- Smakämnen
- lagen
- världen
- Dem
- sig själva
- teoretiska
- Dessa
- saker
- tre
- Genom
- tid
- Tips
- Titel
- till
- token
- topp
- transformerad
- handledning
- ui
- förstå
- förståelse
- universitet
- us
- användning
- Användare
- användare
- utnyttja
- värde
- Värden
- olika
- Omfattande
- via
- utsikt
- Besök
- vs
- kontra kod
- vågor
- webb
- webbapplikation
- VÄL
- Vad
- Vad är
- som
- medan
- VEM
- wikipedia
- kommer
- med
- inom
- utan
- ord
- ord
- Arbete
- arbetssätt
- fungerar
- världen
- skulle
- författare
- skrivning
- skriven
- år
- Din
- zephyrnet