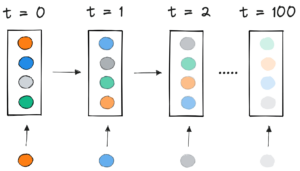
Vi introducerar Packed BERT för 2x träningshastighet i naturlig språkbehandling
Kolla in den här nya BERT-packningsalgoritmen för effektivare träning.
By Dr Mario Michael Krell, huvudansvarig för maskininlärning på Graphcore & Matej Kosec, AI Applications Specialist på Graphcore

Bild av författare.
Genom att använda en ny packningsalgoritm har vi snabbat upp Natural Language Processing med mer än 2 gånger under utbildningen av BERT-Large. Vår nya packningsteknik tar bort stoppning, vilket möjliggör betydligt effektivare beräkningar.
Vi misstänker att detta också kan tillämpas på genomik och proteinveckningsmodeller och andra modeller med skeva längdfördelningar för att få en mycket bredare inverkan i olika industrier och applikationer.
Vi introducerade Graphcores mycket effektiva Non-Negative Least Squares Histogram-Packing-algoritm (eller NNLSHP) såväl som vår BERT-algoritm som tillämpas på packade sekvenser i ett nytt dokument [1].
Computational Waste i NLP på grund av sekvensutfyllnad
Vi började undersöka nya sätt att optimera BERT-utbildning samtidigt som vi arbetade med vår senaste benchmark-inlämningar till MLPerf™. Målet var att utveckla användbara optimeringar som lätt kunde användas i verkliga applikationer. BERT var ett naturligt val som en av modellerna att fokusera på för dessa optimeringar, eftersom den används flitigt inom industrin och av många av våra kunder.
Det förvånade oss verkligen att höra att i vår egen BERT-Large-utbildningsapplikation som använder Wikipedia-datauppsättningen, var 50 % av tokens i datamängden utfyllnad – vilket resulterade i mycket slöseri med datoranvändning.
Att utfylla sekvenser för att justera dem alla till samma längd är ett vanligt tillvägagångssätt som används med GPU:er, men vi tyckte att det skulle vara värt att prova ett annat tillvägagångssätt.
Sekvenser har en stor variation i längd av två skäl:
- Den underliggande Wikipedia-datan visar en stor variation i dokumentlängd
- Själva BERT-förbehandlingen minskar slumpmässigt storleken på extraherade dokument som kombineras för att generera en träningssekvens
Att fylla upp längden till den maximala längden på 512 resulterar i att 50 % av alla polletter är utfyllnadspoletter. Att ersätta de 50 % av stoppningen med riktiga data kan resultera i att 50 % mer data bearbetas med samma beräkningsansträngning och därmed 2x snabbare under optimala förhållanden.

Figur 1: Wikipedia-datauppsättningsdistributioner. Bild av författare.
Är detta specifikt för Wikipedia? Nej.
Tja, är det då specifikt för språk? Nej.
I själva verket finns skeva längdfördelningar överallt: i språk, genomik och proteinveckning. Figurerna 2 och 3 visar distributioner för SQuAD 1.1-datauppsättningarna och GLUE-datauppsättningarna.

Figur 2: SQuAD 1.1 BERT förträning av datasetsekvenslängdhistogram för maximal sekvenslängd på 384. Bild av författare.

Figur 3: GLUE datasetsekvenslängdhistogram för maximal sekvenslängd på 128. Bild av författare.
Hur kan vi hantera de olika längderna samtidigt som vi undviker beräkningsslöseri?
Nuvarande tillvägagångssätt kräver olika beräkningskärnor för olika längder eller för ingenjören att programmatiskt ta bort stoppningen och sedan lägga till den igen upprepade gånger för varje uppmärksamhetsblock och förlustberäkning. Att spara beräkningar genom att spränga koden och göra den mer komplex var inte tilltalande, så vi sökte efter något bättre. Kan vi inte bara sätta ihop flera sekvenser i ett paket med en maximal längd och bearbeta allt tillsammans? Det visar sig att vi kan!
Detta tillvägagångssätt kräver tre nyckelingredienser:
- En effektiv algoritm för att bestämma vilka prover som ska sättas ihop för att ha så lite kvarvarande stoppning som möjligt
- Justering av BERT-modellen för att bearbeta paket istället för sekvenser
- Och justera hyperparametrarna
Förpackning
Till en början verkade det osannolikt att du skulle kunna packa en stor datamängd som Wikipedia mycket effektivt. Detta problem är allmänt känt som bin-packing. Även när packningen är begränsad till tre sekvenser eller färre, skulle det resulterande problemet fortfarande vara starkt NP-komplett, utan en effektiv algoritmisk lösning. Befintliga heuristikpaketeringsalgoritmer var inte lovande eftersom de hade en komplexitet på minst O(n logg(n)), var n är antalet sekvenser (~16 miljoner för Wikipedia). Vi var intresserade av tillvägagångssätt som skulle skala bra till miljontals sekvenser.
Två knep hjälpte oss att minska komplexiteten drastiskt:
- Begränsa antalet sekvenser i ett paket till tre (för vår första lösning)
- Arbetar enbart på histogrammet för sekvenslängd med en fack för varje förekommande längd
Vår maximala sekvenslängd var 512. Så när vi flyttade till histogrammet minskade dimensionen och komplexiteten från 16 miljoner sekvenser till 512 längder. Genom att tillåta maximalt tre sekvenser i ett paket minskade antalet tillåtna längdkombinationer till 22K. Detta inkluderade redan tricket att kräva att sekvenserna sorteras efter längd i förpackningen. Så varför inte prova 4 sekvenser? Detta ökade antalet kombinationer från 22K till 940K, vilket var för mycket för vår första modelleringsmetod. Dessutom har djup 3 redan uppnått anmärkningsvärt hög packningseffektivitet.
Ursprungligen trodde vi att användning av mer än tre sekvenser i ett paket skulle öka beräkningskostnaderna och påverka konvergensbeteendet under träning. Men för att stödja applikationer som inferens, som kräver ännu snabbare realtidspackning, utvecklade vi den mycket effektiva algoritmen Non-Negative Least Squares Histogram-Packing (NNLSHP).
Non-negative Least Squares Histogram-Packing (NNLSHP)
Bin packning formuleras ganska ofta som ett matematiskt optimeringsproblem. Men med 16 miljoner sekvenser (eller fler) är detta inte praktiskt. Enbart problemvariablerna skulle överskrida de flesta maskiners minne. Det matematiska programmet för ett histogrambaserat tillvägagångssätt är ganska snyggt. För enkelhetens skull bestämde vi oss för minsta kvadraters tillvägagångssätt (Ax=b) med histogramvektor b. Vi utökade den genom att begära strategivektorn x att vara icke-negativ och lägga till vikter för att möjliggöra mindre stoppning.
Den knepiga delen var strategimatrisen. Varje kolumn har en maximal summa av tre och kodar för vilka sekvenser som packas ihop för att exakt matcha den önskade totala längden; 512 i vårt fall. Raderna kodar var och en av de potentiella kombinationerna för att nå en längd som den totala längden. Strategivektorn x är vad vi letade efter, vilket beskriver hur ofta vi väljer vilken av 20k kombinationerna. Intressant nog valdes bara runt 600 kombinationer ut i slutet. För att få en exakt lösning räknas strategin in x skulle behöva vara positiva heltal, men vi insåg att en ungefärlig avrundad lösning med bara icke-negativa x var tillräckligt. För en ungefärlig lösning kan en enkel lösare användas för att få ett resultat inom 30 sekunder.

Figur 4: Exempel på en strategimatris för sekvenslängd 8 och packningsdjup 3. Raderna står för sekvenserna med längd 1–8 som packas ihop och kolumnerna står för alla möjliga längdkombinationer i ett paket utan särskild ordning. Bild av författare.
I slutet var vi tvungna att fixa några prover som inte fick någon strategi men de var minimala. Vi utvecklade också en variantlösare som tvingar fram att varje sekvens packas, eventuellt med stoppning, och har en viktning beroende på stoppningen. Det tog mycket längre tid, och lösningen var inte mycket bättre.
Shortest-Pack-First Histogram Packing
NNLSHP levererade en tillräcklig packningsmetod för oss. Men vi undrade om vi teoretiskt kunde få ett snabbare online-kapabelt tillvägagångssätt och ta bort begränsningen av att bara sätta ihop 3 sekvenser.
Därför tog vi lite inspiration från befintliga packningsalgoritmer men fokuserade fortfarande på histogrammen.
Det finns fyra ingredienser för vår första algoritm, Shortest-pack-first histogram-packing (SPFHP):
- Arbeta på histogrammets räkningar från längsta sekvenser till kortaste
- Om den aktuella sekvenslängden inte passar in i något paket, starta en ny uppsättning paket
- Om det finns flera passningar, ta paketet där summan av sekvenslängden är kortast och ändra antalet respektive
- Kontrollera igen för anpassningar av de återstående antalet
Detta tillvägagångssätt var det enklaste att implementera och tog bara 0.02 sekunder.
En variant var att ta den största summan av sekvenslängd istället för de kortaste och delade räkningarna för att få mer perfekt passform. Sammantaget förändrade detta inte effektiviteten mycket men ökade kodkomplexiteten mycket.
Hur shortest-pack-first histogrampackning fungerar. Animation av författare.
Wikipedia, SQuAD 1.1, GLUE packningsresultat
Tabell 1, 2 och 3 visar packningsresultaten för våra två föreslagna algoritmer. Förpackningsdjup beskriver det maximala antalet packade sekvenser. Packningsdjup 1 är BERT-implementeringen. Det maximalt förekommande packdjupet, om ingen gräns är satt, betecknas med ett extra "max". De antal förpackningar beskriver längden på den nya packade datamängden. Effektivitet (CT-värde) är procentandelen riktiga tokens i den packade datamängden. De packningsfaktor beskriver den resulterande potentiella hastigheten jämfört med packningsdjup 1.
Vi hade fyra huvudsakliga observationer:
- Ju mer skev fördelning, desto större är fördelarna med att packa.
- Alla datauppsättningar drar nytta av packning. Vissa till och med med mer än en faktor 2.
- SPFHP blir effektivare när packningsdjupet inte är begränsat.
- För ett maximalt antal 3 packade sekvenser, ju mer komplex NNLSHP är, desto effektivare är den (99.75 mot 89.44).

Tabell 1: Nyckelprestandaresultat för föreslagna packningsalgoritmer (SPFHP och NNLSHP) på Wikipedia. Bild av författare.

Tabell 2: Prestandaresultat av föreslagna packningsalgoritmer för SQUaD 1.1 BERT förträning. Bild av författaren.

Tabell 3: Prestandaresultat av föreslagna packningsalgoritmer för GLUE-datauppsättningen. Endast baslinjen och SPFHP-packningsresultaten utan att begränsa packningsdjupet visas. Bild av författaren.
BERT bearbetningsjustering
Något intressant med BERT-arkitekturen är att den mesta bearbetningen sker på tokennivå, vilket betyder att den inte stör vår packning. Det finns bara fyra komponenter som behöver justeras: uppmärksamhetsmasken, MLM-förlusten, NSP-förlusten och noggrannheten.
Nyckeln för alla fyra metoder för att hantera olika antal sekvenser var vektorisering och användning av ett maximalt antal sekvenser som kan sammanfogas. För uppmärksamhet hade vi redan en mask för att ta itu med stoppningen. Att utöka detta till flera sekvenser var enkelt, vilket kan ses i följande TensorFlow-pseudokod. Konceptet är att vi såg till att uppmärksamheten var begränsad till de separata sekvenserna och inte kan sträcka sig längre än så.
Kodprov för uppmärksamhetsmask.

Figur 5: Exempel noll-ett-mask
För förlustberäkningen packar vi i princip upp sekvenserna och beräknar de separata förlusterna, så att vi så småningom erhåller medelvärdet av förlusterna över sekvenserna (istället för paket).
För MLM-förlusten ser koden ut så här:
Kodprov för förlustberäkning.
För NSP-förlusten och noggrannheten är principen densamma. I våra offentliga exempel kan du hitta respektive kod med vår inhouse PopART ramverk.
Wikipedia omkostnader och snabbhetsuppskattning
Med vår modifiering av BERT hade vi två frågor:
- Hur mycket omkostnader för det med sig?
- Hur mycket beror overheaden på det maximala antalet sekvenser som sätts ihop i ett paket?
Eftersom databeredning i BERT kan vara krångligt använde vi en genväg och kompilerade koden för flera olika packningsdjup och jämförde respektive (uppmätta) cykler. Resultaten visas i tabell 4. Med OH, betecknar vi den procentuella minskningen av genomströmningen på grund av ändringar i modellen för att möjliggöra packning (såsom maskeringsschemat för uppmärksamhet och den ändrade förlustberäkningen). De insåg snabbhet är kombinationen av hastigheten på grund av packning (den packningsfaktor) och minskningen i genomströmning på grund av OH.

Tabell 4: Beräknad snabbhetsjämförelse av föreslagna packningsalgoritmer (SPFHP och NNLSHP) på Wikipedia. Bild av författare.
Tack vare vektoriseringstekniken är overheaden förvånansvärt liten och det finns ingen nackdel med att packa ihop många sekvenser.
Hyperparameter-justeringar
Med packning fördubblar vi den effektiva batchstorleken (i genomsnitt). Det betyder att vi måste justera träningshyperparametrarna. Ett enkelt knep är att halvera antalet gradientackumulering för att behålla samma effektiva genomsnittliga batchstorlek som innan träningen. Genom att använda en benchmarkinställning med förtränade kontrollpunkter kan vi se att noggrannhetskurvorna matchar perfekt.

Figur 6: Jämförelse av inlärningskurvor för packad och uppackad bearbetning med reducerad batchstorlek för det packade tillvägagångssättet. Bilder av författare.
Noggrannheten matchar: MLM-träningsförlusten kan vara något annorlunda i början men kommer snabbt ikapp. Denna initiala skillnad kan komma från små justeringar av uppmärksamhetslagren som kan ha varit partiska mot korta sekvenser i den tidigare träningen.
För att undvika en avmattning hjälper det ibland att behålla den ursprungliga batchstorleken densamma och justera hyperparametrarna till den ökade effektiva batchstorleken (fördubblats). De viktigaste hyperparametrarna att överväga är betaparametrarna och inlärningshastigheterna. Ett vanligt tillvägagångssätt är att fördubbla batchstorleken, vilket i vårt fall minskade prestandan. Om vi tittar på statistiken för LAMB-optimeraren kan vi bevisa att en höjning av betaparametern till kraften i packningsfaktorn motsvarar att träna flera batcher i följd för att hålla momentum och hastighet jämförbara.

Figur 7: Jämförelse av inlärningskurvor för packad och uppackad bearbetning med heuristik applicerad. Bilder av författare.
Våra experiment visade att att ta beta till kraften två är en bra heuristik. I detta scenario förväntas kurvorna inte matcha eftersom en ökning av satsstorleken vanligtvis minskar konvergenshastigheten i betydelsen prover/epoker tills en målnoggrannhet uppnås.
Nu är frågan om vi i det praktiska scenariot verkligen får den förväntade hastigheten?

Figur 8: Jämförelse av inlärningskurvor för packad och uppackad bearbetning i optimerad inställning. Bilder av författare.
Ja det gör vi! Vi fick en extra hastighet eftersom vi komprimerade dataöverföringen.
Slutsats
Att packa ihop meningar kan spara datoransträngning och miljö. Denna teknik kan implementeras i alla ramar inklusive PyTorch och TensorFlow. Vi fick en tydlig 2x speed-up och på vägen utökade vi den senaste tekniken inom packningsalgoritmer.
Andra tillämpningar som vi är nyfikna på är genomik och proteinveckning där liknande datafördelningar kan observeras. Visionstransformatorer kan också vara ett intressant område för att applicera packade bilder i olika storlekar. Vilka applikationer tror du skulle fungera bra? Vi vill gärna höra från dig!
Få åtkomst till koden på GitHub
Tack
Tack till våra kollegor i Graphcores applikationsteknikteam, Sheng Fu och Mrinal Iyer, för deras bidrag till detta arbete och tack till Douglas Orr från Graphcores forskningsteam för hans värdefulla feedback.
Referensprojekt
[1] M. Kosec, S. Fu, MM Krell, Förpackning: Mot 2x NLP BERT Acceleration (2021), arXiv
Dr Mario Michael Krell är huvudansvarig för maskininlärning på Graphcore. Mario har forskat och utvecklat algoritmer för maskininlärning i mer än 12 år och skapat mjukvara för så olika branscher som robotteknik, fordonsindustri, telekommunikation och hälsovård. På Graphcore bidrog han till vår imponerande MLPerf-inlämningar och har en passion för att accelerera nya icke-standardiserade modeller som ungefärlig Bayesiansk beräkning för statistisk COVID-19-dataanalys.
Matej Kosec är en AI Applications Specialist på Graphcore i Palo Alto. Han har tidigare arbetat som AI-forskare på autonom körning på NIO i San Jose, och har en magisterexamen i flygteknik och astronautik från Stanford University.
Ursprungliga. Skickas om med tillstånd.
Relaterat:
- "
- &
- 2021
- 7
- Annat
- Aeronautik
- AI
- algoritm
- algoritmer
- Alla
- tillåta
- analys
- animering
- Ansökan
- tillämpningar
- arkitektur
- OMRÅDE
- runt
- Konst
- bil
- fordonsindustrin
- autonom
- Baslinje
- riktmärke
- beta
- byta
- koda
- Kolumn
- Gemensam
- Compute
- bidrog
- Covid-19
- Skapa
- Aktuella
- Kunder
- datum
- dataanalys
- datavetenskap
- djupt lärande
- utveckla
- DID
- Dimensionera
- Direktör
- dokument
- drivande
- Effektiv
- effektivitet
- ingenjör
- Teknik
- Miljö
- Förnamn
- passa
- Fast
- Fokus
- Ramverk
- genomik
- god
- GPUs
- hälso-och sjukvård
- Hög
- Hur ser din drömresa ut
- HTTPS
- bild
- Inverkan
- Inklusive
- Öka
- industrier
- industrin
- Inspiration
- Intervju
- undersöka
- IT
- Jobb
- Nyckel
- kunskap
- språk
- Large
- leda
- LÄRA SIG
- inlärning
- Nivå
- Begränsad
- älskar
- maskininlärning
- Framställning
- mask
- Match
- miljon
- ML
- modell
- Momentum
- Naturligt språk
- Naturlig språkbehandling
- Propert
- neural
- nlp
- nummer
- nätet
- öppet
- öppen källkod
- Övriga
- Papper
- prestanda
- kraft
- Principal
- Program
- Protein
- allmän
- Python
- pytorch
- rates
- realtid
- skäl
- minska
- regression
- forskning
- Resultat
- robotik
- San
- San Jose
- sparande
- Skala
- Vetenskap
- vetenskapsmän
- Sök
- vald
- känsla
- in
- inställning
- Kort
- Enkelt
- Storlek
- Small
- So
- Mjukvara
- fart
- delas
- stanford
- Stanford University
- starta
- Ange
- statistik
- Upplevelser för livet
- Strategi
- stödja
- Målet
- telekommunikationer
- tensorflow
- token
- tokens
- topp
- Utbildning
- universitet
- us
- Hastighet
- syn
- wikipedia
- inom
- Arbete
- fungerar
- värt
- X
- år