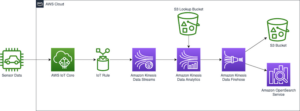
Z uvedbo funkcije nevronskega iskanja za Storitev Amazon OpenSearch v OpenSearch 2.9 je zdaj enostavno integrirati z modeli AI/ML za omogočanje semantičnega iskanja in drugih primerov uporabe. Storitev OpenSearch podpira leksikalno in vektorsko iskanje od uvedbe funkcije k-najbližjega soseda (k-NN) leta 2020; vendar je konfiguracija semantičnega iskanja zahtevala izgradnjo ogrodja za integracijo modelov strojnega učenja (ML) za vnos in iskanje. Funkcija nevronskega iskanja olajša pretvorbo besedila v vektor med zaužitjem in iskanjem. Ko med iskanjem uporabite nevronsko poizvedbo, se poizvedba prevede v vdelavo vektorjev in k-NN se uporabi za vrnitev najbližjih vdelav vektorjev iz korpusa.
Če želite uporabiti nevronsko iskanje, morate nastaviti model ML. Priporočamo konfiguracijo priključkov AI/ML za storitve AI in ML AWS (kot npr Amazon SageMaker or Amazon Bedrock) ali alternative tretjih oseb. Od različice 2.9 v storitvi OpenSearch se konektorji AI/ML integrirajo z nevronskim iskanjem, da poenostavijo in operacionalizirajo prevajanje vašega podatkovnega korpusa in poizvedb v vdelane vektorje, s čimer odstranijo večino zapletenosti vektorske hidracije in iskanja.
V tej objavi prikazujemo, kako konfigurirati priključke AI/ML za zunanje modele prek konzole OpenSearch Service.
Pregled rešitve
Natančneje, ta objava vas vodi skozi povezovanje z modelom v SageMakerju. Nato vas vodimo skozi uporabo konektorja za konfiguracijo semantičnega iskanja v storitvi OpenSearch kot primer primera uporabe, ki je podprt prek povezave z modelom ML. Integracije Amazon Bedrock in SageMaker so trenutno podprte v uporabniškem vmesniku konzole OpenSearch Service, seznam integracij prve in tretje osebe, ki jih podpira uporabniški vmesnik, pa se bo še naprej povečeval.
Za vse modele, ki niso podprti prek uporabniškega vmesnika, jih lahko nastavite z uporabo razpoložljivih API-jev in Načrti ML. Za več informacij glejte Uvod v modele OpenSearch. Načrte za vsak priključek najdete v ML Commons GitHub repozitorij.
Predpogoji
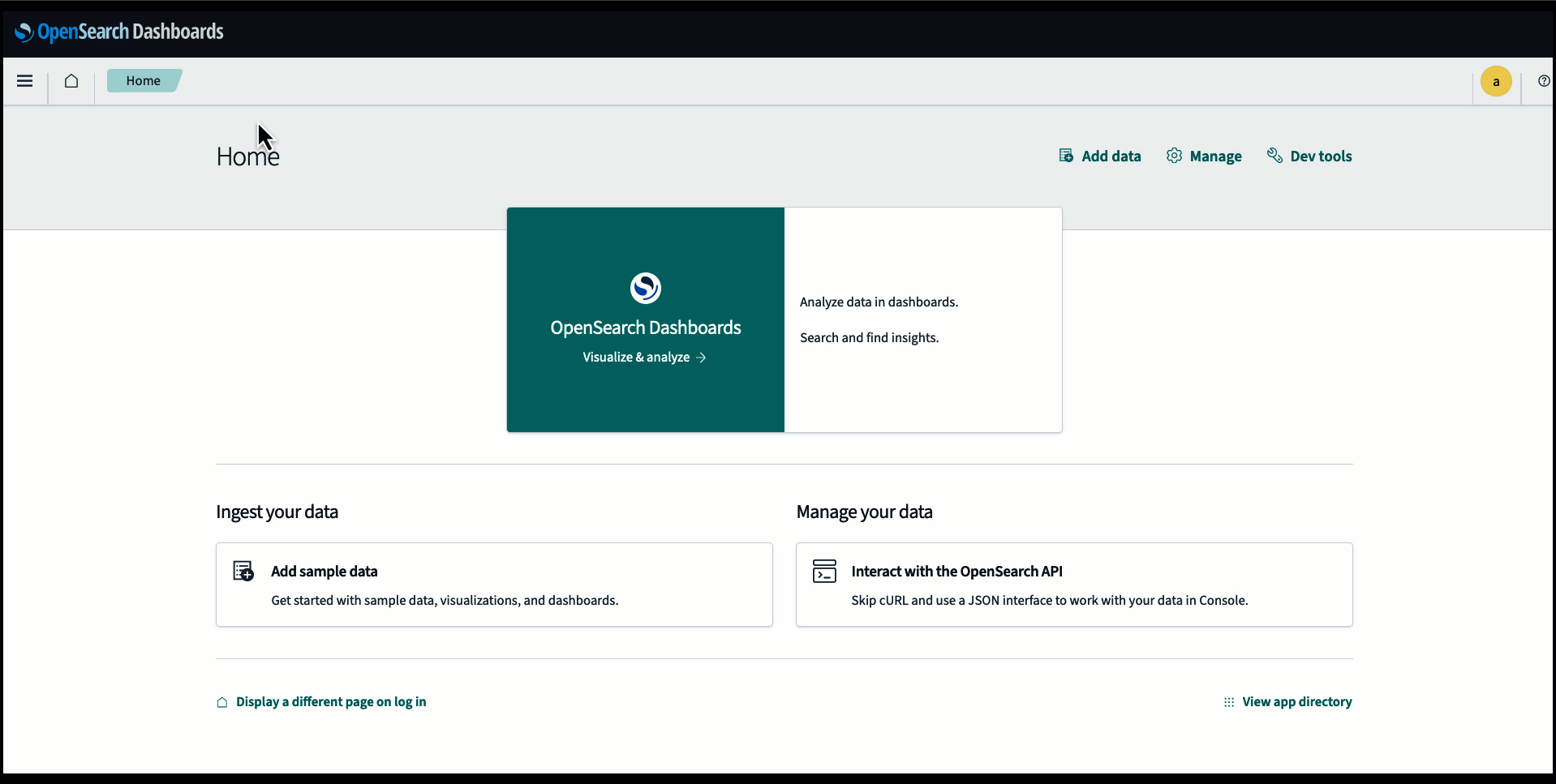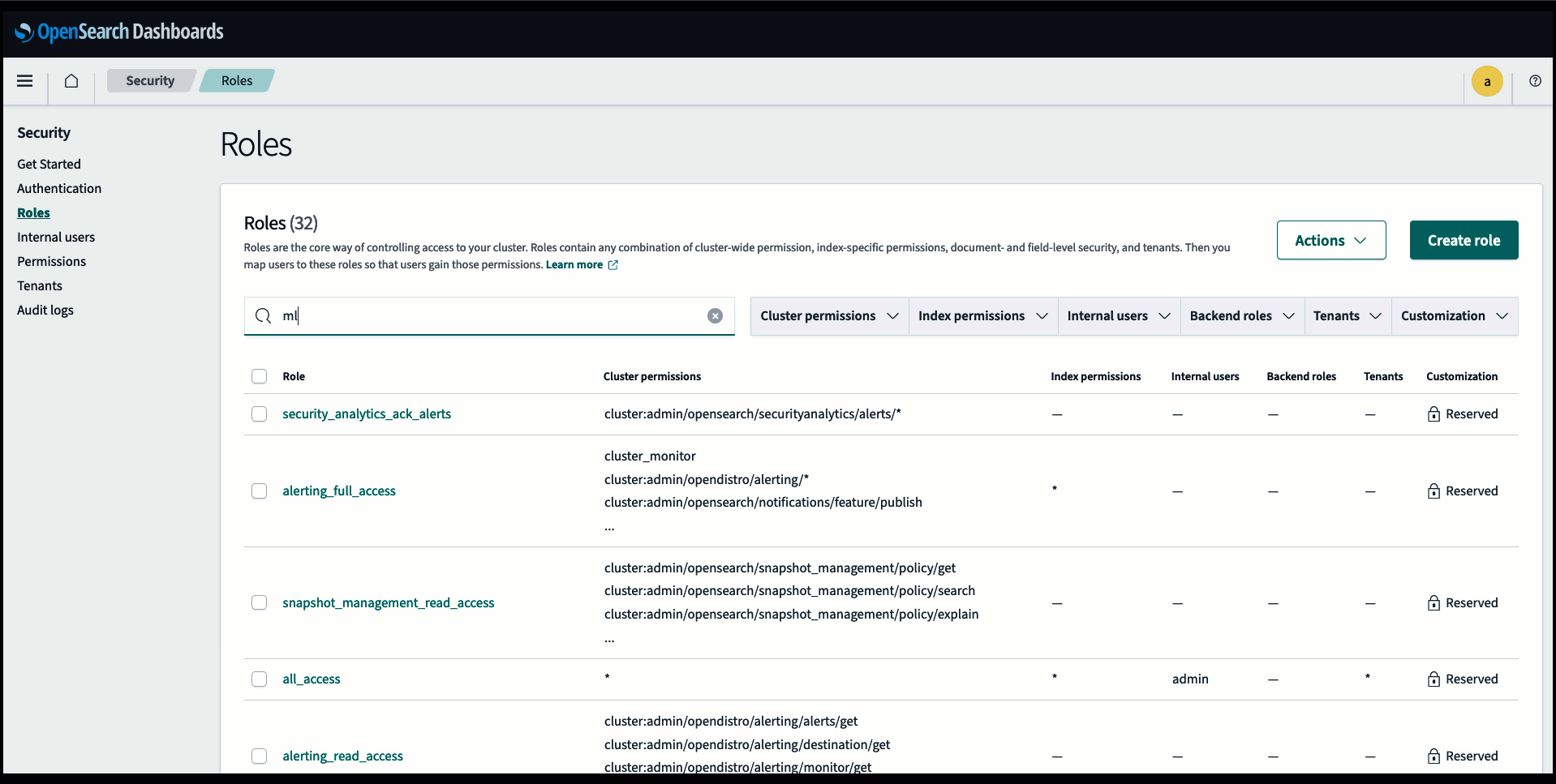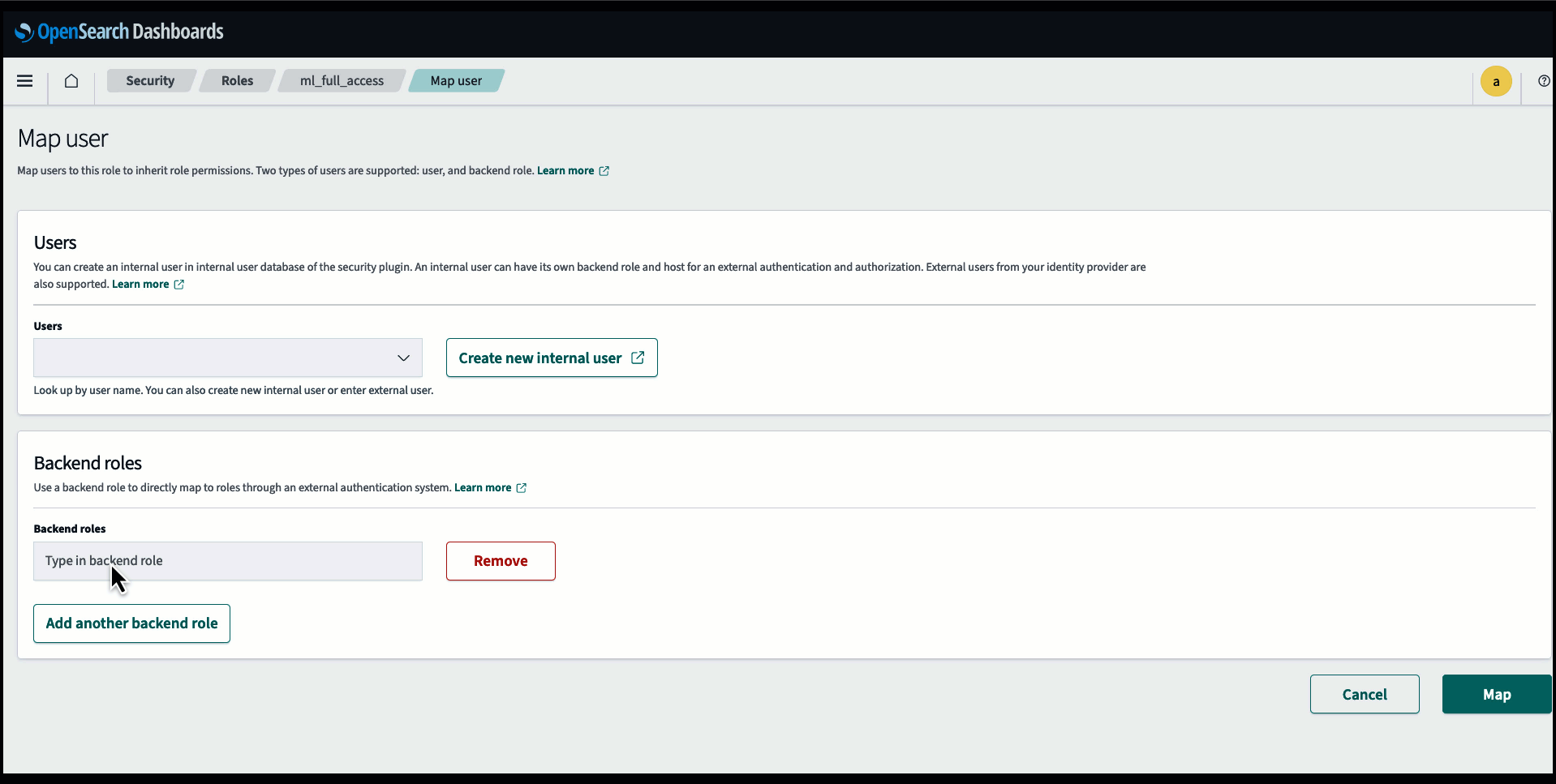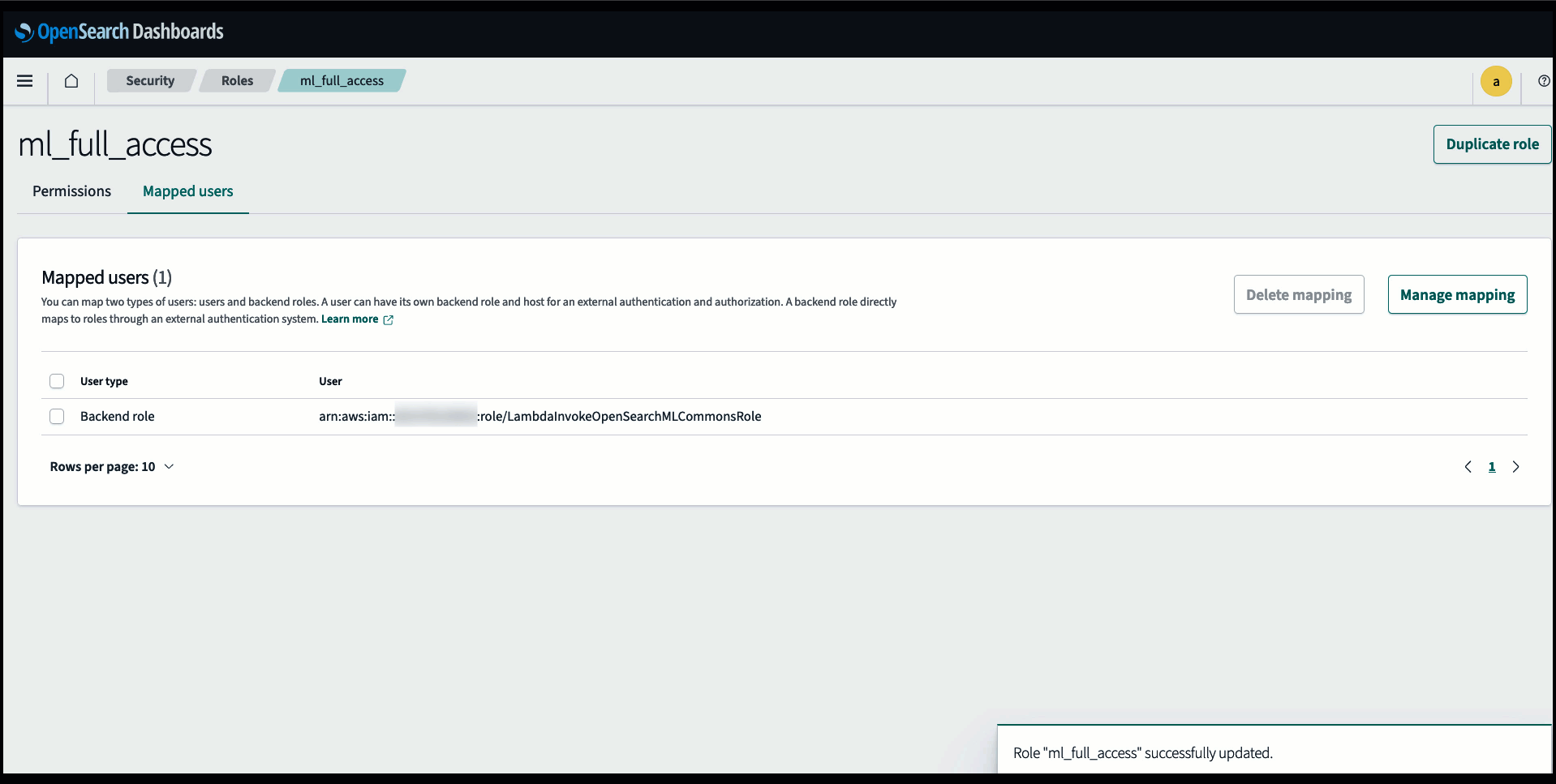
Preden povežete model prek konzole OpenSearch Service, ustvarite domeno OpenSearch Service. Zemljevid an AWS upravljanje identitete in dostopa (IAM) vloga po imenu LambdaInvokeOpenSearchMLCommonsRole kot zaledna vloga na ml_full_access vlogo z uporabo varnostnega vtičnika na nadzornih ploščah OpenSearch, kot je prikazano v naslednjem videu. Potek dela integracij OpenSearch Service je vnaprej napolnjen za uporabo LambdaInvokeOpenSearchMLCommonsRole Privzeta vloga IAM za ustvarjanje povezovalnika med domeno OpenSearch Service in modelom, nameščenim v SageMakerju. Če uporabljate vlogo IAM po meri pri integracijah konzole OpenSearch Service, se prepričajte, da je vloga po meri preslikana kot zaledna vloga z ml_full_access dovoljenja pred uvedbo predloge.
Razmestite model z uporabo AWS CloudFormation
Naslednji videoposnetek prikazuje korake za uporabo konzole OpenSearch Service za razmestitev modela v nekaj minutah na Amazon SageMaker in ustvarjanje ID-ja modela prek priključkov AI. Prvi korak je izbira integracije v navigacijskem podoknu na konzoli OpenSearch Service AWS, ki vodi do seznama razpoložljivih integracij. Integracija je nastavljena prek uporabniškega vmesnika, ki vas bo pozval k potrebnim vnosom.
Če želite nastaviti integracijo, morate zagotoviti le končno točko domene OpenSearch Service in podati ime modela za enolično identifikacijo povezave modela. Predloga privzeto uporablja model transformatorjev stavkov Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Ko izberete Ustvari sklad, ste preusmerjeni na Oblikovanje oblaka AWS konzola. Predloga CloudFormation uporablja arhitekturo, podrobno prikazano v naslednjem diagramu.

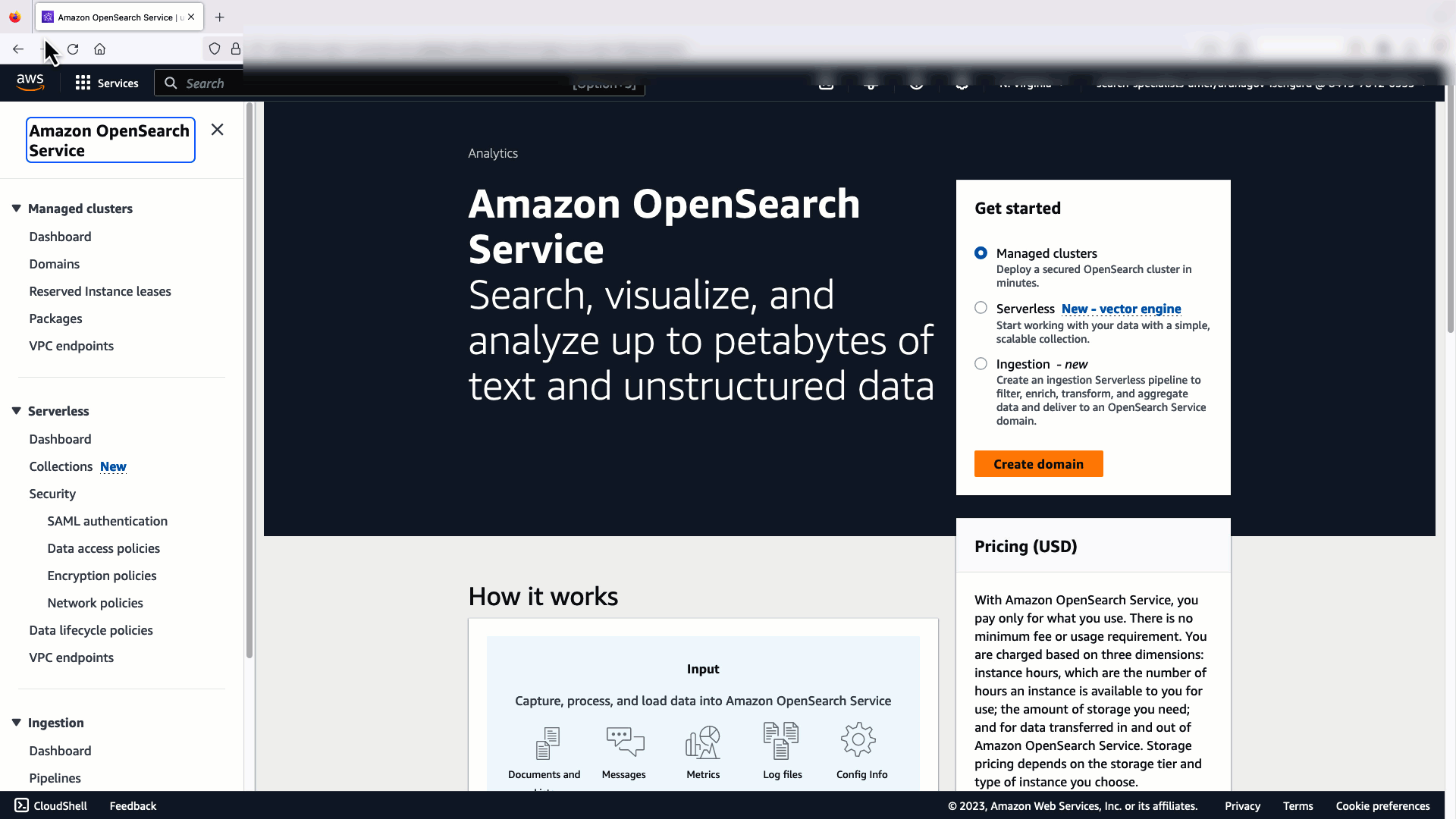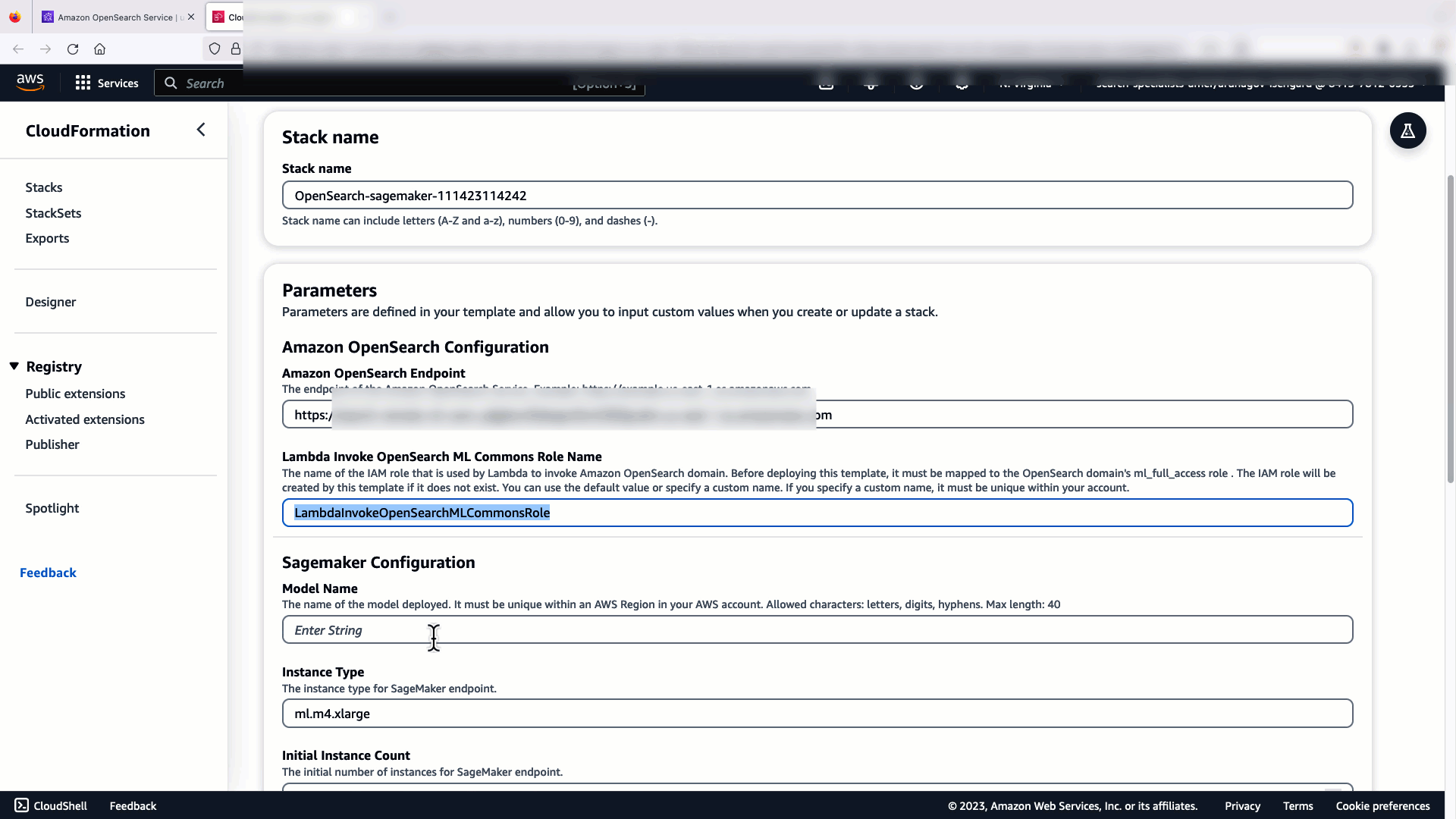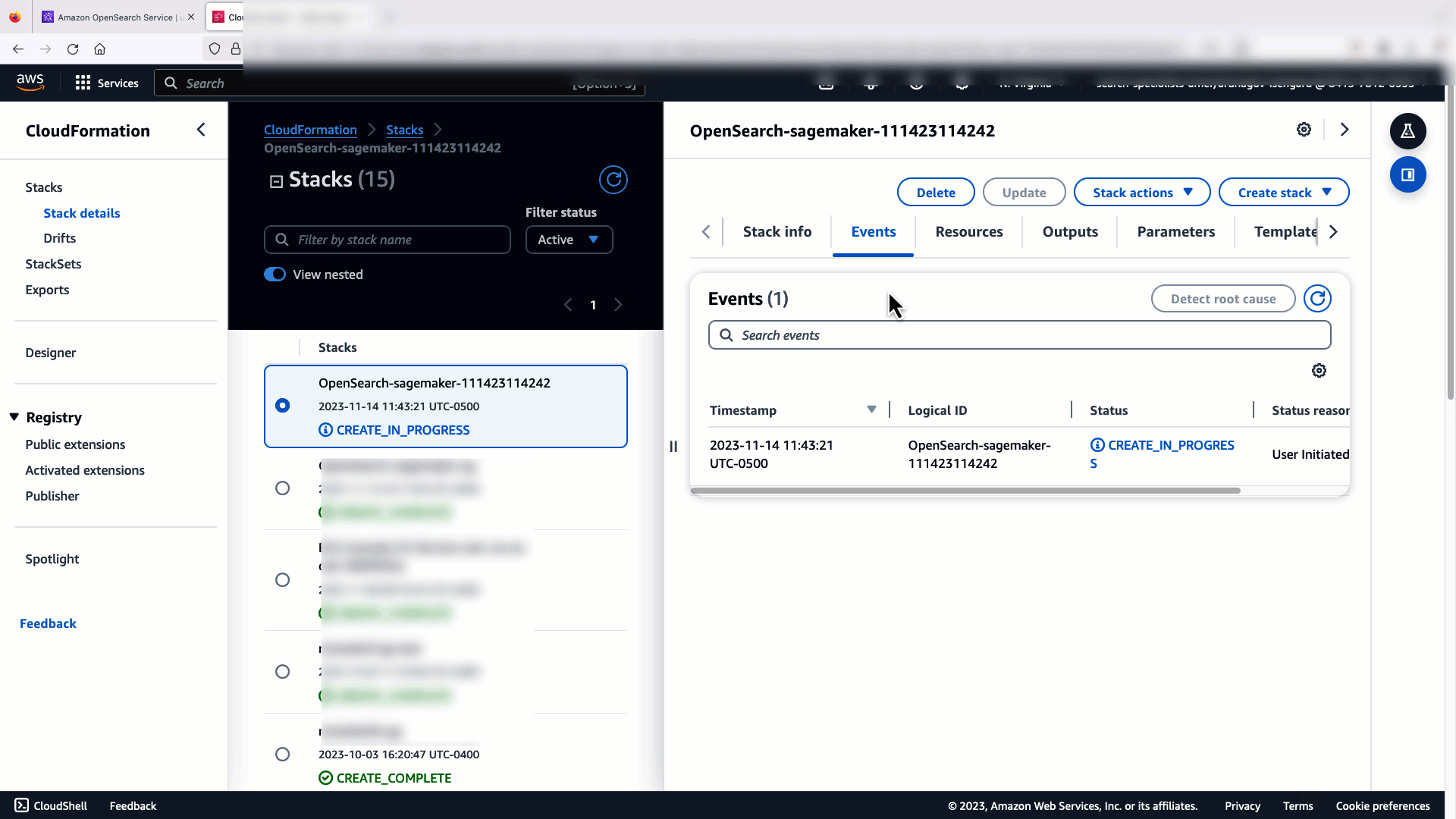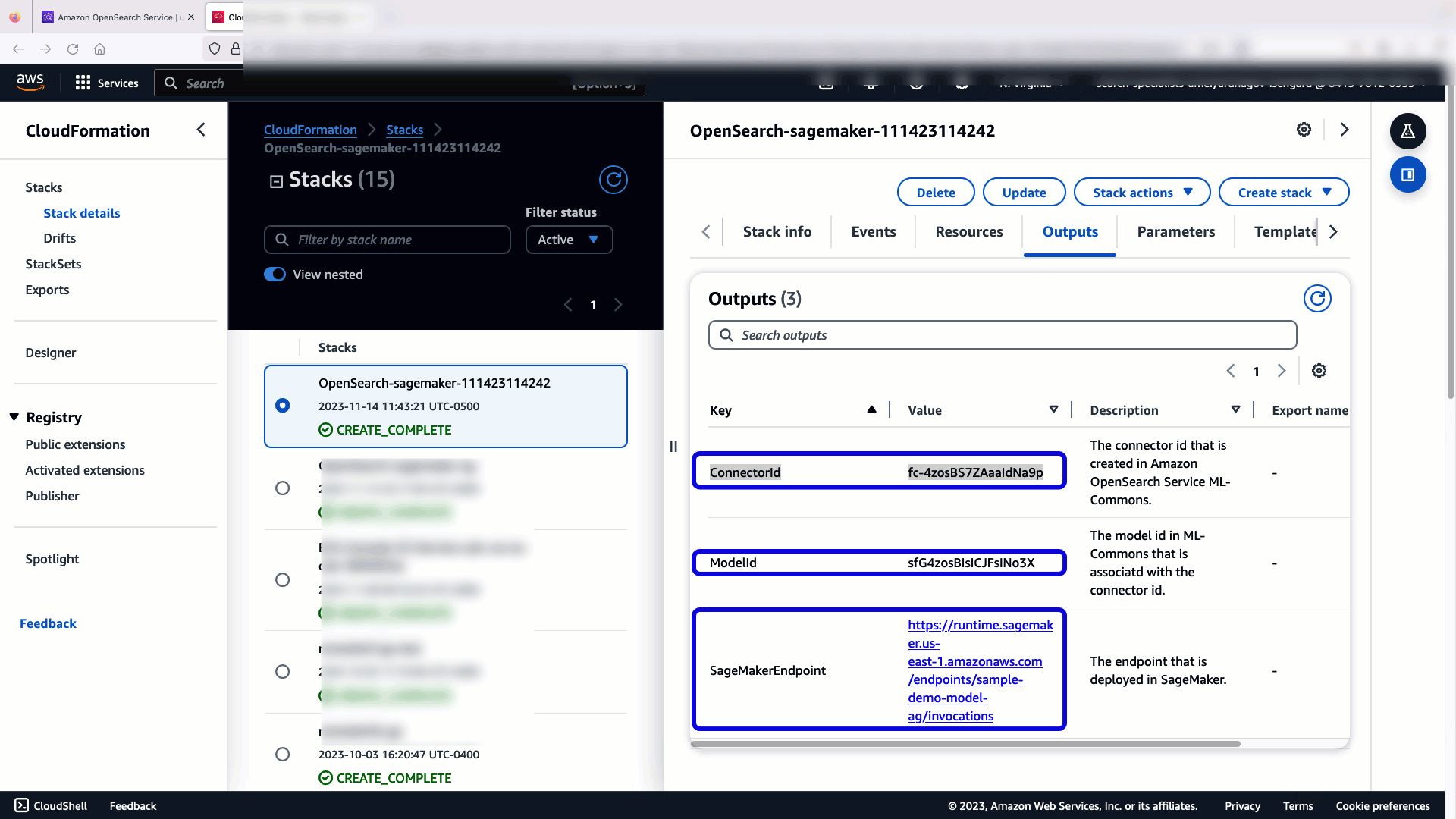
Sklad CloudFormation ustvari AWS Lambda aplikacija, ki uporablja model iz Preprosta storitev shranjevanja Amazon (Amazon S3), ustvari konektor in ustvari ID modela v izhodu. Ta ID modela lahko nato uporabite za ustvarjanje semantičnega indeksa.
Če privzeti model all-MiniLM-L6-v2 ne služi vašemu namenu, lahko uvedete kateri koli model vdelave besedila po vaši izbiri na izbranem gostitelju modela (SageMaker ali Amazon Bedrock), tako da zagotovite svoje artefakte modela kot dostopen objekt S3. Lahko pa izberete eno od naslednjih možnosti vnaprej usposobljeni jezikovni modeli in ga namestite v SageMaker. Za navodila za nastavitev končne točke in modelov glejte Razpoložljive slike Amazon SageMaker.
SageMaker je popolnoma upravljana storitev, ki združuje širok nabor orodij za omogočanje visoko zmogljivega in poceni ML za vsak primer uporabe, ki zagotavlja ključne prednosti, kot so spremljanje modela, gostovanje brez strežnika in avtomatizacija delovnega toka za stalno usposabljanje in uvajanje. SageMaker vam omogoča gostovanje in upravljanje življenjskega cikla modelov za vdelavo besedila ter njihovo uporabo za izvajanje semantičnih iskalnih poizvedb v storitvi OpenSearch. Ko je povezan, SageMaker gosti vaše modele, storitev OpenSearch pa se uporablja za poizvedovanje na podlagi rezultatov sklepanja iz SageMakerja.
Oglejte si razporejeni model prek nadzornih plošč OpenSearch
Če želite preveriti, ali je predloga CloudFormation uspešno razmestila model v domeno OpenSearch Service in pridobiti ID modela, lahko uporabite ML Commons REST GET API prek orodij za razvijalce OpenSearch Dashboards.
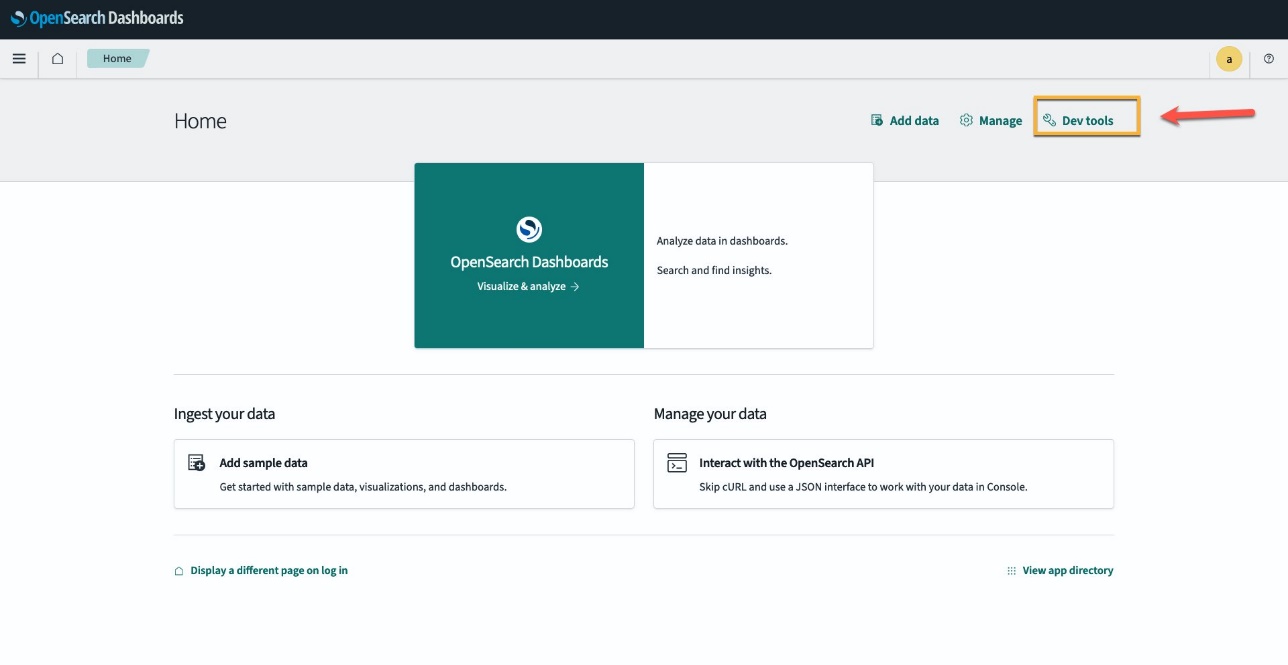
GET _plugins REST API zdaj ponuja dodatne API-je za ogled stanja modela. Naslednji ukaz vam omogoča ogled statusa oddaljenega modela:
Kot je prikazano na naslednjem posnetku zaslona, a DEPLOYED status v odgovoru nakazuje, da je model uspešno nameščen v gruči OpenSearch Service.

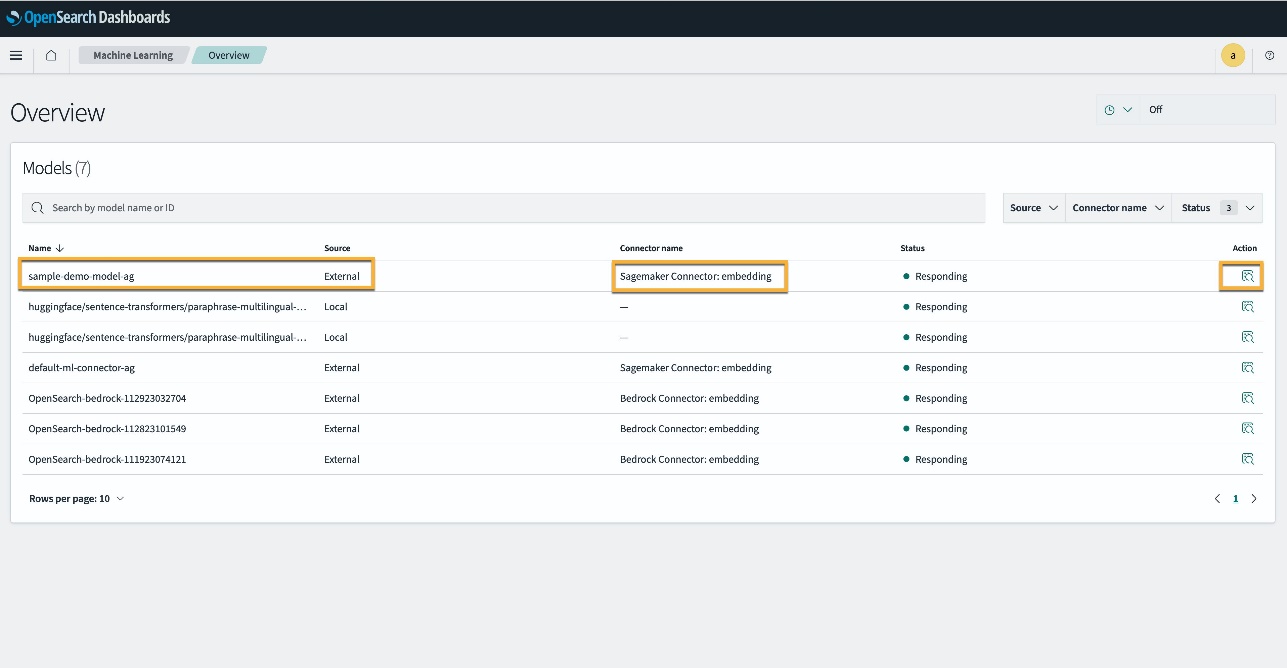
Druga možnost je, da si ogledate model, ki je nameščen na vaši domeni OpenSearch Service, z uporabo strojno učenje strani nadzornih plošč OpenSearch.

Na tej strani so navedene informacije o modelih in statusi vseh nameščenih modelov.

Ustvarite nevronski cevovod z ID-jem modela
Ko je status modela prikazan kot bodisi DEPLOYED v Dev Tools ali zeleno in Odzivanje na nadzornih ploščah OpenSearch lahko uporabite ID modela za izgradnjo svojega živčnega cevovoda za vnos. Naslednji cevovod za vnos se izvaja v orodjih za razvijalce OpenSearch Dashboards v vaši domeni. Zamenjajte ID modela z enoličnim ID-jem, ustvarjenim za model, uveden v vaši domeni.

Ustvarite semantični iskalni indeks z uporabo nevronskega cevovoda kot privzetega cevovoda
Zdaj lahko definirate svojo preslikavo indeksa s privzetim cevovodom, konfiguriranim za uporabo novega nevronskega cevovoda, ki ste ga ustvarili v prejšnjem koraku. Prepričajte se, da so vektorska polja deklarirana kot knn_vector in dimenzije so primerne za model, ki je nameščen na SageMaker. Če ste obdržali privzeto konfiguracijo za razmestitev modela all-MiniLM-L6-v2 na SageMakerju, obdržite naslednje nastavitve, kot so, in zaženite ukaz v Orodjih za razvijalce.

Zaužijte vzorčne dokumente za ustvarjanje vektorjev
Za to predstavitev lahko zaužijete vzorčni maloprodajni demostore katalog izdelkov do novega semantic_demostore kazalo. Zamenjajte uporabniško ime, geslo in končno točko domene s podatki o svoji domeni in vnesite neobdelane podatke v storitev OpenSearch:

Preverite nov indeks semantic_demostore
Zdaj, ko ste vnesli svoj nabor podatkov v domeno OpenSearch Service, preverite, ali so zahtevani vektorji ustvarjeni s preprostim iskanjem za pridobivanje vseh polj. Preverite, ali so polja opredeljena kot knn_vectors imajo zahtevane vektorje.

Primerjajte leksikalno iskanje in semantično iskanje, ki ga poganja nevronsko iskanje, z orodjem Primerjaj rezultate iskanja
O Orodje za primerjavo rezultatov iskanja na nadzornih ploščah OpenSearch je na voljo za produkcijske delovne obremenitve. Lahko se pomaknete do Primerjajte rezultate iskanja strani in primerjajte rezultate poizvedbe med leksikalnim iskanjem in nevronskim iskanjem, konfiguriranim za uporabo prej ustvarjenega ID-ja modela.

Čiščenje
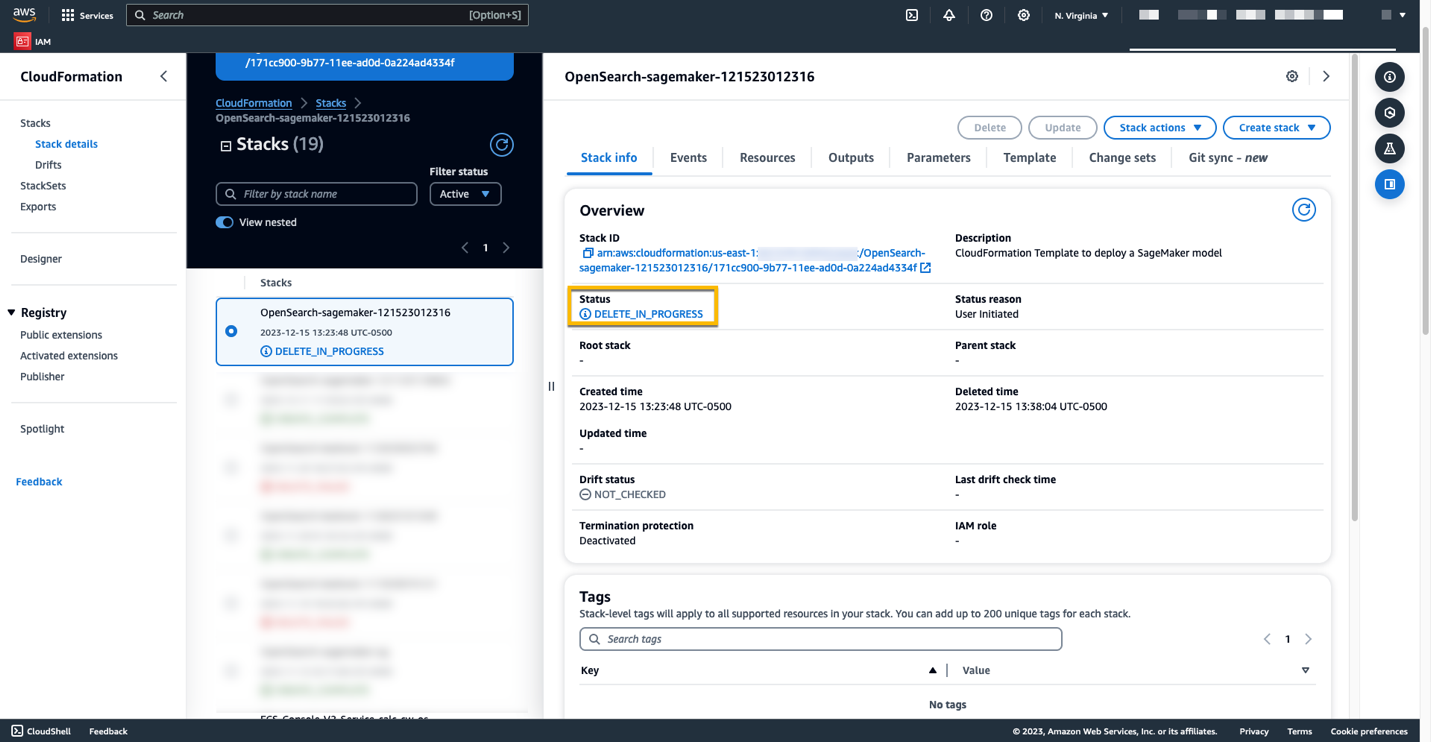
Vire, ki ste jih ustvarili po navodilih v tej objavi, lahko izbrišete tako, da izbrišete sklad CloudFormation. S tem boste izbrisali vire Lambda in vedro S3, ki vsebujejo model, ki je bil nameščen v SageMaker. Izvedite naslednje korake:
- Na konzoli AWS CloudFormation se pomaknite na stran s podrobnostmi o skladu.
- Izberite Brisanje.

- Izberite Brisanje potrditi.

Napredek brisanja sklada lahko spremljate na konzoli AWS CloudFormation.
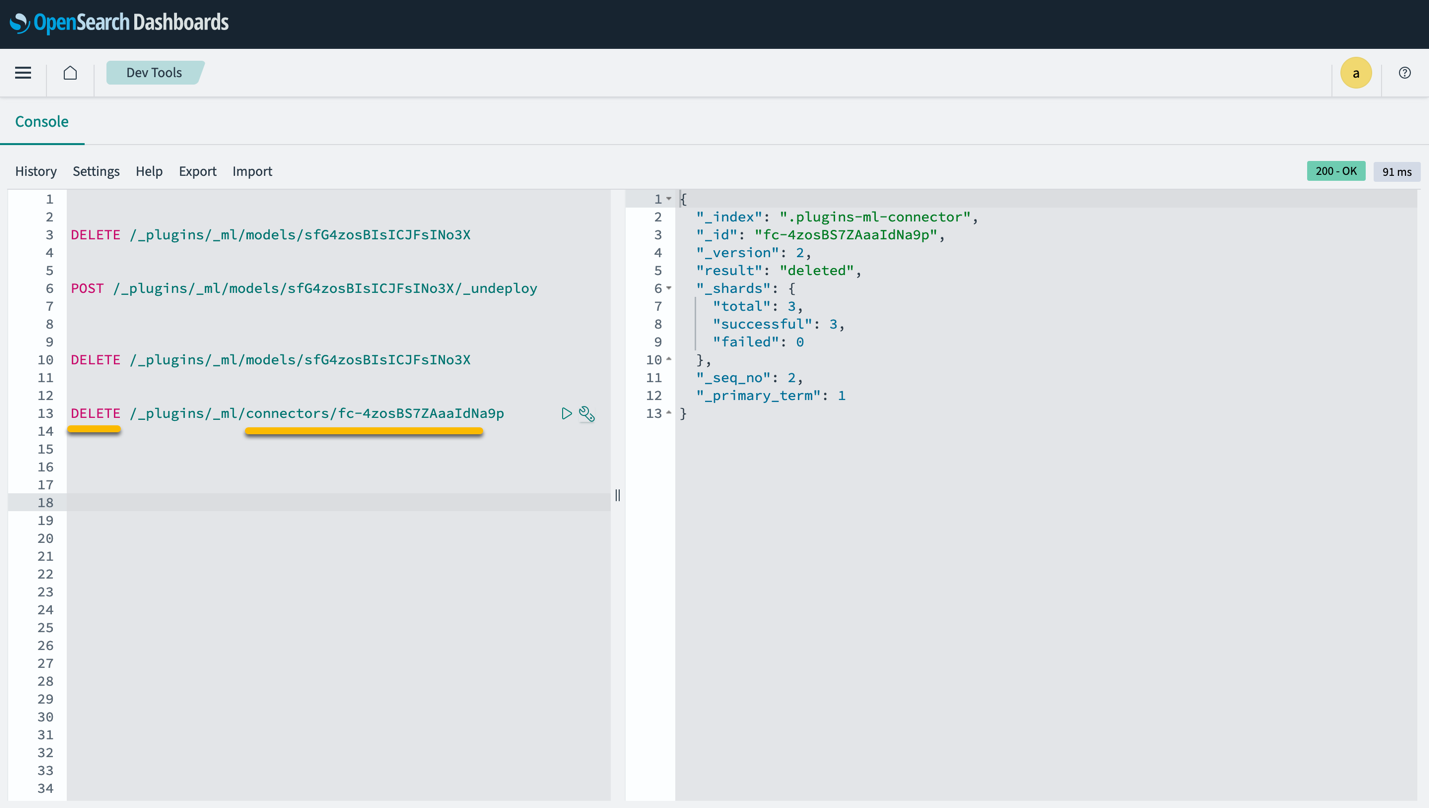
Upoštevajte, da brisanje sklada CloudFormation ne izbriše modela, nameščenega v domeni SageMaker, in ustvarjenega priključka AI/ML. To je zato, ker so ti modeli in konektor lahko povezani z več indeksi znotraj domene. Če želite posebej izbrisati model in z njim povezan konektor, uporabite API-je modela, kot je prikazano na naslednjih posnetkih zaslona.
Najprej undeploy model iz pomnilnika domene OpenSearch Service:

Nato lahko izbrišete model iz indeksa modelov:

Na koncu izbrišite konektor iz indeksa konektorjev:
zaključek
V tej objavi ste se naučili, kako razmestiti model v SageMakerju, ustvariti konektor AI/ML z uporabo konzole OpenSearch Service in zgraditi nevronski iskalni indeks. Zmožnost konfiguriranja konektorjev AI/ML v storitvi OpenSearch poenostavi postopek vektorske hidracije tako, da postanejo integracije v zunanje modele izvorne. Indeks nevronskega iskanja lahko ustvarite v nekaj minutah z uporabo cevovoda za nevronsko zaužitje in nevronskega iskanja, ki uporabljata ID modela za sprotno ustvarjanje vdelave vektorja med zaužitjem in iskanjem.
Če želite izvedeti več o teh priključkih AI/ML, glejte Amazon OpenSearch Service AI priključki za storitve AWS, Integracije predlog AWS CloudFormation za semantično iskanjein Ustvarjanje konektorjev za platforme ML tretjih oseb.
O avtorjih
 Aruna Govindaraju je Amazon OpenSearch Specialist Solutions Architect in je sodeloval s številnimi komercialnimi in odprtokodnimi iskalniki. Navdušena je nad iskanjem, ustreznostjo in uporabniško izkušnjo. Njeno strokovno znanje in izkušnje pri povezovanju signalov končnega uporabnika z vedenjem iskalnika je mnogim strankam pomagalo izboljšati njihovo izkušnjo iskanja.
Aruna Govindaraju je Amazon OpenSearch Specialist Solutions Architect in je sodeloval s številnimi komercialnimi in odprtokodnimi iskalniki. Navdušena je nad iskanjem, ustreznostjo in uporabniško izkušnjo. Njeno strokovno znanje in izkušnje pri povezovanju signalov končnega uporabnika z vedenjem iskalnika je mnogim strankam pomagalo izboljšati njihovo izkušnjo iskanja.
 Dagney Braun je glavni produktni vodja pri AWS, osredotočen na OpenSearch.
Dagney Braun je glavni produktni vodja pri AWS, osredotočen na OpenSearch.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :ima
- : je
- :ne
- $GOR
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- sposobnost
- O meni
- dostop
- dostopen
- Dodatne
- AI
- AI / ML
- vsi
- omogoča
- Prav tako
- alternative
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- in
- kaj
- API
- API-ji
- uporaba
- primerno
- Arhitektura
- SE
- AS
- povezan
- At
- Avtomatizacija
- Na voljo
- AWS
- Oblikovanje oblaka AWS
- Backend
- temeljijo
- BE
- ker
- vedenje
- Prednosti
- med
- tako
- Prinaša
- široka
- izgradnjo
- Building
- by
- CAN
- primeru
- primeri
- Katalog
- izbira
- Izberite
- izbran
- Grozd
- komercialna
- Commons
- primerjate
- dokončanje
- kompleksnost
- konfiguracija
- konfigurirano
- konfiguriranje
- Potrdi
- povezane
- Povezovanje
- povezava
- Konzole
- vsebujejo
- naprej
- neprekinjeno
- korelacijski
- ustvarjajo
- ustvaril
- ustvari
- Trenutno
- po meri
- Stranke, ki so
- nadzorne plošče
- datum
- privzeto
- opredeliti
- opredeljen
- dostavo
- Predstavitev
- izkazati
- dokazuje,
- razporedi
- razporejeni
- uvajanja
- uvajanje
- razpolaga
- opis
- podrobno
- Podrobnosti
- dev
- Dimenzije
- dimenzije
- Dokumenti
- Ne
- domena
- med
- vsak
- prej
- brez napora
- bodisi
- vdelava
- omogočajo
- Končna točka
- Motor
- Motorji
- zagotovitev
- Eter (ETH)
- Primer
- izkušnje
- strokovno znanje
- zunanja
- Obraz
- olajša
- Feature
- Področja
- Najdi
- prva
- osredotočena
- po
- za
- Okvirni
- iz
- v celoti
- ustvarjajo
- ustvarila
- ustvarja
- dobili
- gif
- GitHub
- Zelen
- Grow
- vodi
- Imajo
- pomagal
- jo
- visokozmogljivo
- gostitelj
- gostovanje
- Gostitelji
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- HuggingFace
- hidracijo
- IAM
- ID
- identificirati
- identiteta
- if
- izboljšanje
- in
- Indeks
- indekse
- označuje
- Podatki
- vhodi
- Namesto
- Navodila
- integrirati
- integracija
- integracije
- v
- Predstavitev
- IT
- ITS
- jpg
- json
- Imejte
- Ključne
- jezik
- kosilo
- UČITE
- naučili
- učenje
- življenski krog
- Seznam
- seznami
- nizkimi stroški
- stroj
- strojno učenje
- Znamka
- Izdelava
- upravljanje
- upravlja
- upravitelj
- več
- map
- kartiranje
- Spomin
- Metoda
- min
- ML
- Model
- modeli
- monitor
- spremljanje
- več
- veliko
- več
- morajo
- Ime
- materni
- Krmarjenje
- ostalo
- potrebno
- Nimate
- Nevronski
- Novo
- zdaj
- predmet
- of
- on
- ONE
- samo
- odprite
- open source
- or
- Ostalo
- izhod
- Stran
- podokno
- strastno
- Geslo
- Dovoljenja
- plinovod
- platon
- Platonova podatkovna inteligenca
- PlatoData
- vključiti
- Prispevek
- moč
- poganja
- prejšnja
- , ravnateljica
- Predhodna
- Postopek
- procesorji
- Izdelek
- produktni vodja
- proizvodnja
- Napredek
- Lastnosti
- zagotavljajo
- zagotavlja
- zagotavljanje
- Namen
- poizvedbe
- Surovi
- surovi podatki
- Priporočamo
- glejte
- daljinsko
- odstranjevanje
- zamenjajte
- obvezna
- viri
- Odgovor
- REST
- Rezultati
- Trgovina na drobno
- ohraniti
- vrnitev
- vloga
- poti
- Run
- sagemaker
- galerija
- Iskalnik
- iskalnik
- Iskalniki
- varnost
- glej
- izberite
- služijo
- Brez strežnika
- Storitev
- Storitve
- nastavite
- nastavitve
- je
- pokazale
- Razstave
- signali
- Enostavno
- poenostavlja
- poenostavitev
- saj
- rešitve
- vir
- specialist
- posebej
- sveženj
- Začetek
- Status
- Korak
- Koraki
- shranjevanje
- Uspešno
- taka
- Podprti
- Preverite
- Predloga
- besedilo
- da
- O
- njihove
- Njih
- POTEM
- s tem
- te
- tretjih oseb
- ta
- skozi
- do
- skupaj
- orodja
- usposabljanje
- Preoblikovanje
- prevod
- Res
- tip
- ui
- edinstven
- edinstveno
- uporaba
- primeru uporabe
- Rabljeni
- uporabnik
- Uporabniška izkušnja
- uporabo
- POTRDI
- preverjanje
- različica
- preko
- Video
- Poglej
- sprehodi
- je
- we
- web
- spletne storitve
- kdaj
- ki
- bo
- z
- v
- delal
- potek dela
- avtomatizacija dela
- jo
- Vaša rutina za
- zefirnet