Tako kot skoraj vsi kupci želite tudi vi porabiti čim manj in hkrati doseči najboljšo možno učinkovitost. To pomeni, da morate biti pozorni na razmerje med ceno in zmogljivostjo. z Amazon RedShift, lahko si privoščiš svojo torto in jo tudi poješ! Amazon Redshift zagotavlja do 4.9-krat nižje stroške na uporabnika in do 7.9-krat boljše razmerje med ceno in zmogljivostjo kot druga skladišča podatkov v oblaku pri delovnih obremenitvah v resničnem svetu z uporabo naprednih tehnik, kot je skaliranje sočasnosti za podporo več sto sočasnim uporabnikom, izboljšano kodiranje nizov za hitrejše izvajanje poizvedb , in Amazon Redshift brez strežnika izboljšave zmogljivosti. Nadaljujte z branjem, če želite razumeti, zakaj je razmerje med ceno in zmogljivostjo pomembno in kako je razmerje med ceno in zmogljivostjo Amazon Redshift merilo za to, koliko stane doseganje določene ravni zmogljivosti pri delovni obremenitvi, in sicer ROI v uspešnosti (donosnost naložbe).
Ker sta cena in zmogljivost vključena v izračun cene in uspešnosti, obstajata dva načina razmišljanja o ceni in uspešnosti. Prvi način je ohraniti ceno konstantno: če imate za porabiti 1 USD, koliko zmogljivosti dobite od svojega podatkovnega skladišča? Baza podatkov z boljšim razmerjem med ceno in zmogljivostjo bo zagotovila boljšo zmogljivost za vsak porabljen 1 USD. Če torej ohranjate ceno konstantno pri primerjavi dveh podatkovnih skladišč, ki staneta enako, bo baza podatkov z boljšim razmerjem med ceno in zmogljivostjo hitreje izvajala vaše poizvedbe.. Drugi način gledanja na razmerje med ceno in uspešnostjo je ohranjanje zmogljivosti nespremenjene: če morate svojo delovno obremenitev končati v 10 minutah, koliko bo to stalo? Baza podatkov z boljšim razmerjem med ceno in zmogljivostjo bo opravila vašo delovno obremenitev v 10 minutah po nižji ceni. Če torej ohranjate konstantno zmogljivost pri primerjavi dveh podatkovnih skladišč, ki sta dimenzionirani za zagotavljanje enake zmogljivosti, bo baza podatkov z boljšim razmerjem med ceno in zmogljivostjo stala manj in vam prihranila denar.
Nazadnje, še en pomemben vidik razmerja med ceno in zmogljivostjo je predvidljivost. Vedeti, koliko bo stalo vaše podatkovno skladišče, ko se število uporabnikov podatkovnega skladišča povečuje, je ključnega pomena za načrtovanje. Ne bi smel zagotavljati le najboljšega razmerja med ceno in zmogljivostjo danes, temveč bi se moral tudi predvidljivo širiti in zagotavljati najboljše razmerje med ceno in zmogljivostjo, ko je dodanih več uporabnikov in delovnih obremenitev. Idealno podatkovno skladišče bi moralo imeti linearna lestvica— povečanje vašega podatkovnega skladišča za zagotavljanje dvakratne prepustnosti poizvedb bi moralo v idealnem primeru stati dvakrat več (ali manj).
V tej objavi delimo rezultate uspešnosti, da ponazorimo, kako Amazon Redshift zagotavlja bistveno boljše razmerje med ceno in zmogljivostjo v primerjavi z vodilnimi alternativnimi skladišči podatkov v oblaku. To pomeni, da če za Amazon Redshift porabite enak znesek kot za eno od teh drugih podatkovnih skladišč, boste z Amazon Redshift dosegli boljšo učinkovitost. Druga možnost je, če prilagodite gručo Redshift tako, da zagotavlja enako zmogljivost, boste videli nižje stroške v primerjavi s temi alternativami.
Cena-zmogljivost za dejanske delovne obremenitve
Z Amazon Redshift lahko poganjate zelo široko paleto delovnih obremenitev, od paketne obdelave kompleksnih poročil, ki temeljijo na ekstrahiranju, preoblikovanju in nalaganju (ETL), in analitike pretakanja v realnem času do nadzornih plošč poslovne inteligence (BI) z nizko zakasnitvijo, ki potrebujejo na stotine ali celo tisoče uporabnikov hkrati z odzivnimi časi manj kot sekunde in vse vmes. Eden od načinov, kako nenehno izboljšujemo razmerje med ceno in zmogljivostjo za naše stranke, je nenehno pregledovanje telemetrije zmogljivosti programske in strojne opreme iz flote Redshift ter iskanje priložnosti in primerov uporabe strank, kjer lahko še izboljšamo zmogljivost Amazon Redshift.
Nekateri nedavni primeri optimizacije delovanja, ki jih poganja telemetrija voznega parka, vključujejo:
- Optimizacije poizvedb nizov – Z analizo, kako je Amazon Redshift obdelal različne vrste podatkov v floti Redshift, smo ugotovili, da bi optimizacija poizvedb, ki vsebujejo veliko nizov, prinesla veliko korist pri delovnih obremenitvah naših strank. (O tem bomo podrobneje razpravljali kasneje v tej objavi.)
- Avtomatizirani materializirani pogledi – Ugotovili smo, da stranke Amazon Redshift pogosto izvajajo številne poizvedbe, ki imajo skupne vzorce podpoizvedb. Več različnih poizvedb lahko na primer združi iste tri tabele z istim pogojem združevanja. Amazon Redshift lahko zdaj samodejno ustvari in vzdržuje materializirane poglede in nato pregledno prepiše poizvedbe za uporabo materializiranih pogledov z uporabo strojno naučenega avtomatiziran materializiran pogled funkcija avtonomije v Amazon Redshift. Ko so omogočeni, lahko avtomatizirani materializirani pogledi pregledno povečajo zmogljivost poizvedb za ponavljajoče se poizvedbe brez posredovanja uporabnika. (Upoštevajte, da avtomatizirani materializirani pogledi niso bili uporabljeni v nobenem od primerjalnih rezultatov, obravnavanih v tej objavi).
- Delovne obremenitve z visoko sočasnostjo – Opažamo, da je vedno pogostejši primer uporabe Amazon Redshift za opravljanje delovnih obremenitev, podobnih nadzorni plošči. Za te delovne obremenitve so značilni želeni odzivni časi na poizvedbe enomestnih sekund ali manj, pri čemer desetine ali stotine sočasnih uporabnikov izvajajo poizvedbe hkrati s pikčastim in pogosto nepredvidljivim vzorcem uporabe. Prototipni primer tega je nadzorna plošča BI, ki jo podpira Amazon Redshift in ima skokovit promet v ponedeljek zjutraj, ko veliko število uporabnikov začne svoj teden.
Zlasti delovne obremenitve z visoko sočasnostjo imajo zelo široko uporabnost: večina delovnih obremenitev podatkovnega skladišča deluje sočasno in ni neobičajno, da na stotine ali celo tisoče uporabnikov hkrati izvaja poizvedbe na Amazon Redshift. Amazon Redshift je bil zasnovan tako, da ohranja odzivne čase na poizvedbe predvidljive in hitre. Redshift Serverless to stori samodejno namesto vas, tako da po potrebi doda in odstrani računalništvo, da ohrani odzivni čas poizvedbe hiter in predvidljiv. To pomeni, da se bo nadzorna plošča brez podpore Redshift Serverless, ki se hitro naloži, ko do nje dostopa en ali dva uporabnika, še naprej hitro nalagala, tudi če jo nalaga več uporabnikov hkrati.
Za simulacijo te vrste delovne obremenitve smo uporabili merilo uspešnosti, izpeljano iz TPC-DS z naborom podatkov 100 GB. TPC-DS je industrijsko standardno merilo uspešnosti, ki vključuje različne tipične poizvedbe v skladišču podatkov. Pri tem sorazmerno majhnem obsegu 100 GB se poizvedbe v tem primerjalnem preizkusu izvajajo na Redshift Serverless v povprečju nekaj sekund, kar je reprezentativno za to, kar pričakujejo uporabniki, ki nalagajo interaktivno nadzorno ploščo BI. Izvedli smo med 1–200 sočasnimi preizkusi tega merila uspešnosti in simulirali med 1–200 uporabniki, ki so poskušali naložiti nadzorno ploščo hkrati. Ponovili smo tudi preizkus z več priljubljenimi alternativnimi skladišči podatkov v oblaku, ki prav tako podpirajo samodejno povečevanje (če ste seznanjeni z objavo Amazon Redshift še naprej vodi v razmerju med ceno in zmogljivostjo, konkurenta A nismo vključili, ker ne podpira samodejnega povečanja). Izmerili smo povprečni odzivni čas na poizvedbo, kar pomeni, kako dolgo bi uporabnik čakal, da se poizvedbe končajo (ali da se naloži nadzorna plošča). Rezultati so prikazani v naslednji tabeli.
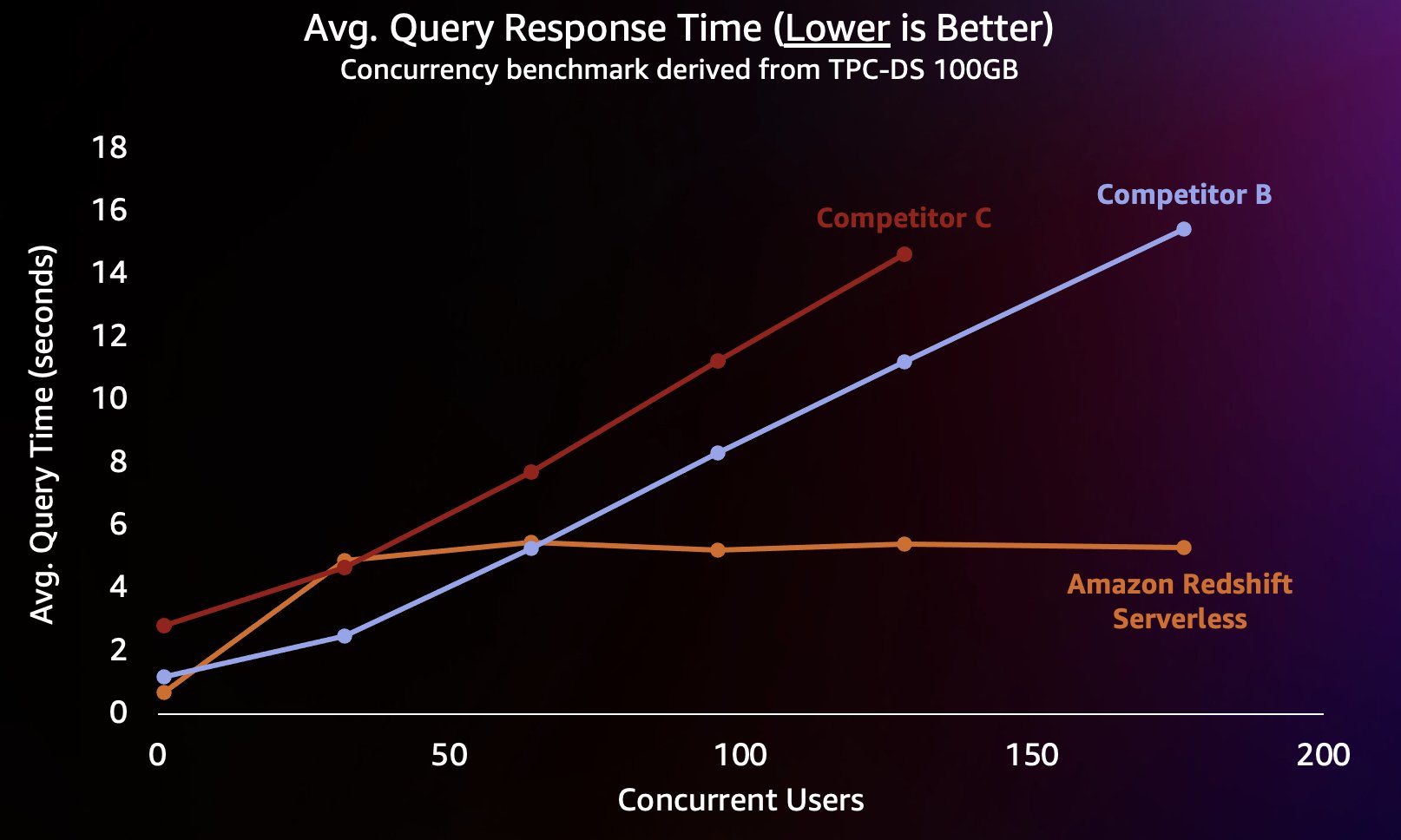
Konkurent B se dobro prilagaja do približno 64 sočasnih poizvedb, na tej točki pa ne more zagotoviti dodatnega računanja in poizvedbe se začnejo postavljati v čakalno vrsto, kar vodi do daljših odzivnih časov na poizvedbe. Čeprav se konkurent C lahko samodejno prilagaja, se prilagaja na nižjo prepustnost poizvedb kot Amazon Redshift in konkurent B in ne more vzdrževati nizkih časov izvajanja poizvedb. Poleg tega ne podpira poizvedb v čakalni vrsti, ko mu zmanjka računalništva, kar mu preprečuje, da bi se razširil nad približno 128 sočasnih uporabnikov. Pošiljanje dodatnih poizvedb poleg tega sistem zavrne.
Tukaj lahko Redshift Serverless vzdržuje razmeroma dosleden odzivni čas na poizvedbo pri približno 5 sekundah, tudi če na stotine uporabnikov izvaja poizvedbe hkrati. Povprečni odzivni časi na poizvedbe za konkurenta B in C se enakomerno povečujejo, ko se povečuje obremenitev skladišč, zaradi česar morajo uporabniki čakati dlje (do 16 sekund), da se njihove poizvedbe vrnejo, ko je podatkovno skladišče zasedeno. To pomeni, da če uporabnik poskuša osvežiti nadzorno ploščo (ki lahko ob ponovnem nalaganju celo odda več sočasnih poizvedb), bi lahko Amazon Redshift ohranjal čase nalaganja nadzorne plošče veliko bolj dosledne, tudi če nadzorno ploščo nalaga desetine ali stotine drugih uporabnikov hkrati.
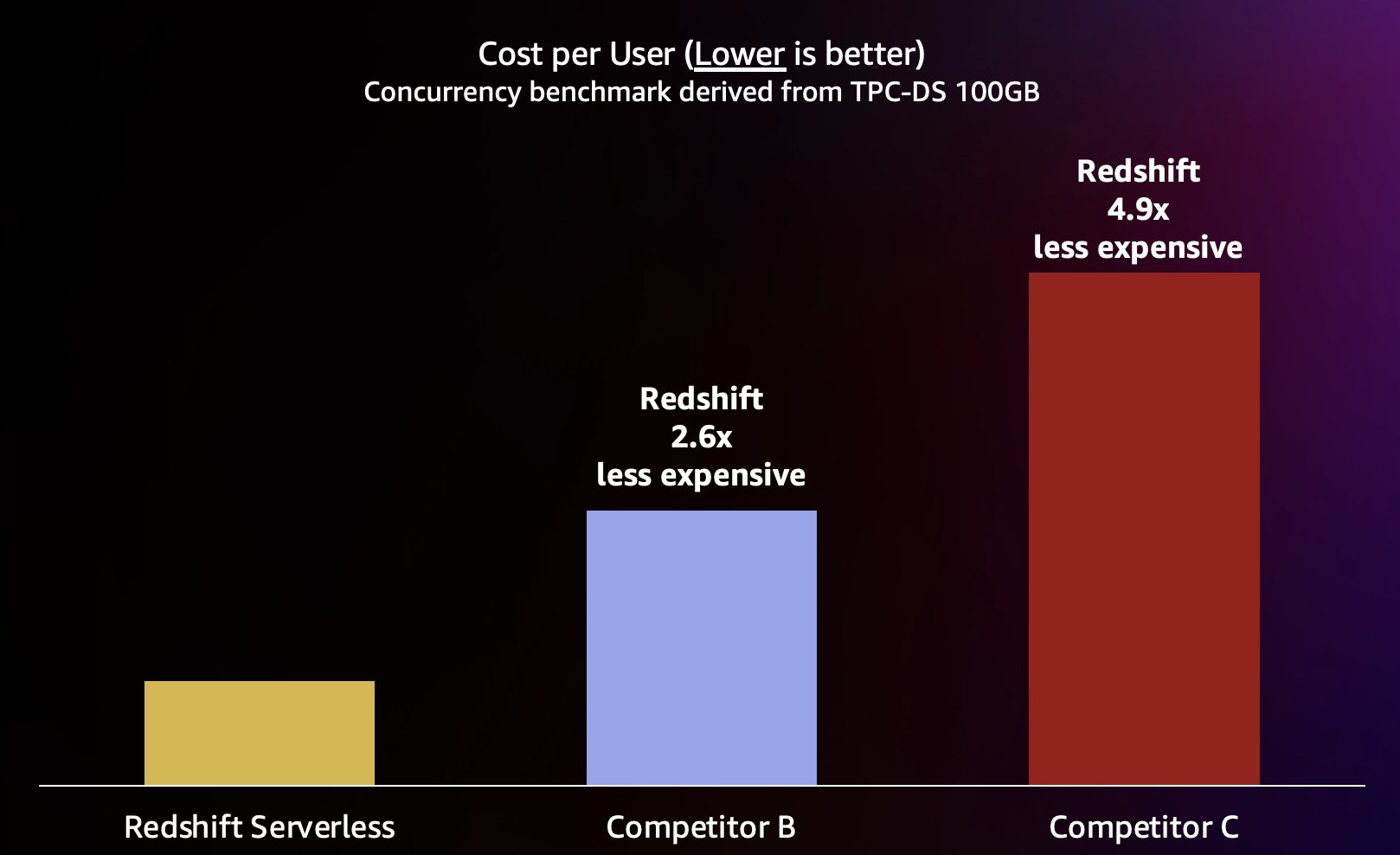
Ker lahko Amazon Redshift zagotovi zelo visoko prepustnost poizvedb za kratke poizvedbe (kot smo pisali v Amazon Redshift še naprej vodi v razmerju med ceno in zmogljivostjo), prav tako je sposoben obravnavati te višje sočasnosti pri povečanju učinkovitosti in s tem po znatno nižji ceni. Da bi to količinsko opredelili, pogledamo razmerje med ceno in zmogljivostjo z uporabo objavljenih cene na zahtevo za vsako od skladišč v predhodnem testu, prikazano v naslednji tabeli. Omeniti velja, da uporaba Rezervirani primerki (RI), zlasti 3-letni RI-ji, kupljeni z možnostjo vsega vnaprejšnjega plačila, ima najnižje stroške za zagon Amazon Redshift na Provisioned clusters, kar ima za posledico najboljše razmerje med ceno in zmogljivostjo v primerjavi z možnostmi RI na zahtevo ali drugimi možnostmi RI.

Torej ne samo, da lahko Amazon Redshift zagotovi boljšo zmogljivost pri višjih sočasnostih, ampak to lahko stori tudi po znatno nižjih stroških. Vsaka podatkovna točka v grafikonu cene in uspešnosti je enakovredna stroškom izvajanja primerjalne vrednosti pri določeni sočasnosti. Ker je razmerje med ceno in zmogljivostjo linearno, lahko strošek izvajanja primerjalne vrednosti pri kateri koli sočasnosti delimo s sočasnostjo (število sočasnih uporabnikov v tem grafikonu), da nam povedo, koliko stane dodajanje vsakega novega uporabnika za to določeno primerjalno vrednost.
Prejšnje rezultate je enostavno ponoviti. Vse poizvedbe, uporabljene v merilu uspešnosti, so na voljo v našem GitHub repozitorij in zmogljivost se meri z zagonom podatkovnega skladišča, omogočanjem skaliranja sočasnosti na Amazon Redshift (ali ustrezno funkcijo samodejnega skaliranja v drugih skladiščih), nalaganjem podatkov takoj po namestitvi (brez ročnega prilagajanja ali nastavitve, specifične za bazo podatkov) in nato zagonom sočasni tok poizvedb pri sočasnosti od 1–200 v korakih po 32 v vsakem podatkovnem skladišču. Isti repo GitHub se sklicuje na vnaprej ustvarjene (in nespremenjene) podatke TPC-DS v Preprosta storitev shranjevanja Amazon (Amazon S3) v različnih obsegih z uporabo uradnega kompleta za generiranje podatkov TPC-DS.
Optimiziranje delovnih obremenitev z nizi
Kot smo že omenili, ekipa Amazon Redshift nenehno išče nove priložnosti za zagotavljanje še boljšega razmerja med ceno in zmogljivostjo za naše stranke. Ena izboljšava, ki smo jo pred kratkim uvedli in je bistveno izboljšana zmogljivost, je optimizacija, ki pospeši delovanje poizvedb prek podatkov niza. Na primer, morda boste želeli poiskati skupni prihodek, ustvarjen iz maloprodajnih trgovin v New Yorku s poizvedbo, kot je SELECT sum(price) FROM sales WHERE city = ‘New York’. Ta poizvedba uporablja predikat nad podatki niza (city = ‘New York’). Kot si lahko predstavljate, je obdelava podatkov nizov vseprisotna v aplikacijah za skladiščenje podatkov.
Da bi kvantificirali, kako pogosto delovne obremenitve strank dostopajo do nizov, smo izvedli podrobno analizo uporabe vrste podatkov nizov z uporabo telemetrije voznega parka več deset tisoč skupin strank, ki jih upravlja Amazon Redshift. Naša analiza kaže, da v 90 % grozdov stolpci z nizi predstavljajo vsaj 30 % vseh stolpcev, v 50 % grozdov pa stolpci z nizi predstavljajo vsaj 50 % vseh stolpcev. Poleg tega večina vseh poizvedb, ki se izvajajo na platformi skladišča podatkov v oblaku Amazon Redshift, dostopa do vsaj enega stolpca niza. Drug pomemben dejavnik je, da so podatki niza zelo pogosto nizke kardinalnosti, kar pomeni, da stolpci vsebujejo relativno majhen nabor edinstvenih vrednosti. Na primer, čeprav an orders tabela, ki predstavlja podatke o prodaji, lahko vsebuje milijarde vrstic, an order_status stolpec v tej tabeli lahko vsebuje le nekaj edinstvenih vrednosti v teh milijardah vrstic, kot npr pending, in processin completed.
Od tega pisanja je večina stolpcev nizov v Amazon Redshift stisnjenih z LZO or ZSTD algoritmi. To so dobri algoritmi stiskanja za splošne namene, vendar niso zasnovani tako, da bi izkoriščali podatke niza z nizko kardinalnostjo. Zlasti zahtevajo, da se podatki dekompresirajo, preden se z njimi operira, in so manj učinkoviti pri uporabi pasovne širine pomnilnika strojne opreme. Za podatke z nizko kardinalnostjo obstaja druga vrsta kodiranja, ki je lahko bolj optimalna: BYTEDICT. To kodiranje uporablja shemo kodiranja slovarja, ki motorju zbirke podatkov omogoča, da deluje neposredno nad stisnjenimi podatki, ne da bi jih bilo treba najprej razpakirati.
Za nadaljnje izboljšanje razmerja med ceno in zmogljivostjo pri delovnih obremenitvah z nizi, Amazon Redshift zdaj uvaja dodatne izboljšave zmogljivosti, ki pospešijo skeniranje in vrednotenje predikatov v primerjavi s stolpci nizov z nizko kardinalnostjo, ki so kodirani kot BYTEDICT, med 5–63-krat hitreje (glejte rezultate v naslednji razdelek) v primerjavi z alternativnimi kompresijskimi kodiranji, kot sta LZO ali ZSTD. Amazon Redshift doseže to izboljšanje zmogljivosti z vektorizacijo pregledov nad lahkimi, CPE-učinkovitimi, BYTEDICT-kodiranimi stolpci nizov z nizko kardinalnostjo. Te optimizacije obdelave nizov učinkovito uporabljajo pasovno širino pomnilnika, ki jo omogoča sodobna strojna oprema, in omogočajo analitiko v realnem času preko podatkov nizov. Te na novo uvedene zmožnosti delovanja so optimalne za stolpce nizov z nizko kardinalnostjo (do nekaj sto edinstvenih vrednosti nizov).
Če omogočite, lahko samodejno izkoristite to novo visoko zmogljivo izboljšavo niza avtomatska optimizacija tabele v vašem podatkovnem skladišču Amazon Redshift. Če za vaše mize nimate omogočene samodejne optimizacije tabel, lahko prejemate priporočila od Amazon Redshift Advisor v konzoli Amazon Redshift o primernosti stolpca niza za kodiranje BYTEDICT. Definirate lahko tudi nove tabele, ki imajo stolpce nizov z nizko kardinalnostjo s kodiranjem BYTEDICT. Izboljšave nizov v Amazon Redshift so zdaj na voljo v vseh regijah AWS, kjer Amazon Redshift je na voljo.
Rezultati uspešnosti
Za merjenje vpliva naših izboljšav nizov na zmogljivost smo ustvarili nabor podatkov 10 TB (tera bajt), ki je sestavljen iz podatkov nizov z nizko kardinalnostjo. Ustvarili smo tri različice podatkov z uporabo kratkih, srednjih in dolgih nizov, ki ustrezajo 25., 50. in 75. percentilu dolžin nizov iz telemetrije flote Amazon Redshift. Te podatke smo dvakrat naložili v Amazon Redshift, pri čemer smo jih v enem primeru kodirali s stiskanjem LZO, v drugem pa s stiskanjem BYTEDICT. Nazadnje smo izmerili učinkovitost poizvedb, ki so zahtevne za skeniranje in vrnejo veliko vrstic (90 % tabele), srednje število vrstic (50 % tabele) in nekaj vrstic (1 % tabele) nad tem nizkim številom. -nabori podatkov nizov kardinalnosti. Rezultati uspešnosti so povzeti v naslednji tabeli.

Poizvedbe s predikati, ki se ujemajo z visokim odstotkom vrstic, so z novim vektoriziranim kodiranjem BYTEDICT v primerjavi z LZO zabeležile 5–30-kratne izboljšave, medtem ko so poizvedbe s predikati, ki se ujemajo z nizkim odstotkom vrstic, v tem internem merilu uspešnosti izboljšale 10–63-krat.
Redshift Serverless cena-zmogljivost
Poleg rezultatov zmogljivosti visoke sočasnosti, predstavljenih v tej objavi, smo uporabili tudi primerjalno vrednost Cloud Data Warehouse, ki izhaja iz TPC-DS, da primerjamo razmerje med ceno in zmogljivostjo Redshift Serverless z drugimi podatkovnimi skladišči z uporabo večjega nabora podatkov 3TB. Izbrali smo podatkovna skladišča, ki so imela podobno ceno, v tem primeru znotraj 10 % od 32 USD na uro z uporabo javno dostopnih cen na zahtevo. Ti rezultati kažejo, da tako kot primerki Amazon Redshift RA3 tudi Redshift Serverless zagotavlja boljše razmerje med ceno in zmogljivostjo v primerjavi z drugimi vodilnimi skladišči podatkov v oblaku. Kot vedno lahko te rezultate ponovimo z uporabo naših skriptov SQL v našem GitHub repozitorij.

Priporočamo vam, da preizkusite Amazon Redshift z lastnim dokaz koncepta delovne obremenitve kot najboljši način, da vidite, kako lahko Amazon Redshift izpolni vaše potrebe po analitiki podatkov.
Poiščite najboljše razmerje med ceno in zmogljivostjo za vaše delovne obremenitve
Merila uspešnosti, uporabljena v tej objavi, so izpeljana iz industrijskega standardnega merila uspešnosti TPC-DS in imajo naslednje značilnosti:
- Shema in podatki se uporabljajo nespremenjeni iz TPC-DS.
- Poizvedbe so ustvarjene z uporabo uradnega kompleta TPC-DS s parametri poizvedbe, ustvarjenimi z uporabo privzetega naključnega semena kompleta TPC-DS. Različice poizvedb, ki jih je odobril TPC, se uporabljajo za skladišče, če skladišče ne podpira narečja SQL privzete poizvedbe TPC-DS.
- Test vključuje 99 poizvedb TPC-DS SELECT. Ne vključuje vzdrževalnih in pretočnih korakov.
- Za posamezen preskus sočasnosti 3 TB so bili izvedeni trije zagoni napajanja, najboljši zagon pa je izbran za vsako podatkovno skladišče.
- Cena-zmogljivost za poizvedbe TPC-DS se izračuna kot cena na uro (USD), pomnožena z časom izvajanja primerjalnega preizkusa v urah, kar je enako strošku izvajanja primerjalnega preizkusa. Najnovejše objavljene cene na zahtevo se uporabljajo za vsa podatkovna skladišča in ne cene rezerviranih primerkov, kot je bilo omenjeno prej.
Temu pravimo primerjalno merilo skladišča podatkov v oblaku in z uporabo skriptov, poizvedb in podatkov, ki so na voljo v našem GitHub repozitorij. Izpeljan je iz meril uspešnosti TPC-DS, kot je opisano v tej objavi, in kot tak ni primerljiv z objavljenimi rezultati TPC-DS, ker rezultati naših testov niso v skladu z uradno specifikacijo.
zaključek
Amazon Redshift je zavezan zagotavljanju najboljše cene in zmogljivosti v industriji za najrazličnejše delovne obremenitve. Redshift Serverless se linearno spreminja z najboljšim (najnižjim) razmerjem med ceno in zmogljivostjo ter podpira na stotine sočasnih uporabnikov in hkrati ohranja dosledne odzivne čase na poizvedbe. Na podlagi rezultatov testa, obravnavanih v tej objavi, ima Amazon Redshift do 2.6-krat boljše razmerje med ceno in zmogljivostjo pri enaki ravni sočasnosti v primerjavi z najbližjim konkurentom (konkurent B). Kot smo že omenili, vam uporaba rezerviranih primerkov s 3-letno vnaprejšnjo možnostjo zagotavlja najnižje stroške za zagon Amazon Redshift, kar ima za posledico še boljše razmerje med ceno in zmogljivostjo v primerjavi s cenami primerkov na zahtevo, ki smo jih uporabili v tej objavi. Naš pristop k nenehnemu izboljševanju zmogljivosti vključuje edinstveno kombinacijo obsedenosti strank, da bi razumeli primere uporabe strank in z njimi povezana ozka grla glede razširljivosti, skupaj z nenehno analizo podatkov o voznem parku za prepoznavanje priložnosti za znatno optimizacijo delovanja.
Vsaka delovna obremenitev ima edinstvene značilnosti, tako da, če šele začenjate, a dokaz koncepta je najboljši način, da razumete, kako lahko Amazon Redshift zniža vaše stroške in hkrati zagotovi boljšo učinkovitost. Ko izvajate lasten dokaz koncepta, je pomembno, da se osredotočite na prave meritve – prepustnost poizvedb (število poizvedb na uro), odzivni čas in razmerje med ceno in zmogljivostjo. Odločitev, ki temelji na podatkih, lahko sprejmete tako, da sami izvedete dokaz koncepta oz s pomočjo iz AWS ali a partner za sistemsko integracijo in svetovanje.
Če želite biti na tekočem z najnovejšimi dogodki v Amazon Redshift, sledite Kaj je novega v Amazon Redshift krmo.
O avtorjih
 Stefan Gromoll je višji inženir za zmogljivost pri ekipi Amazon Redshift, kjer je odgovoren za merjenje in izboljšanje uspešnosti Redshift. V prostem času rad kuha, se igra s svojimi tremi fanti in seka drva.
Stefan Gromoll je višji inženir za zmogljivost pri ekipi Amazon Redshift, kjer je odgovoren za merjenje in izboljšanje uspešnosti Redshift. V prostem času rad kuha, se igra s svojimi tremi fanti in seka drva.
 Ravi Animi je višji vodja produktnega upravljanja v ekipi Amazon Redshift in upravlja več funkcionalnih področij storitve skladiščenja podatkov v oblaku Amazon Redshift, vključno z zmogljivostjo, prostorsko analitiko, pretakanjem in migracijskimi strategijami. Ima izkušnje z relacijskimi bazami podatkov, večdimenzionalnimi bazami podatkov, tehnologijami IoT, storitvami za shranjevanje in računalniško infrastrukturo ter pred kratkim kot ustanovitelj startupa z uporabo AI/globinskega učenja, računalniškega vida in robotike.
Ravi Animi je višji vodja produktnega upravljanja v ekipi Amazon Redshift in upravlja več funkcionalnih področij storitve skladiščenja podatkov v oblaku Amazon Redshift, vključno z zmogljivostjo, prostorsko analitiko, pretakanjem in migracijskimi strategijami. Ima izkušnje z relacijskimi bazami podatkov, večdimenzionalnimi bazami podatkov, tehnologijami IoT, storitvami za shranjevanje in računalniško infrastrukturo ter pred kratkim kot ustanovitelj startupa z uporabo AI/globinskega učenja, računalniškega vida in robotike.
 Aamer Šah je višji inženir v ekipi Amazon Redshift Service.
Aamer Šah je višji inženir v ekipi Amazon Redshift Service.
 Sanket Hase je vodja razvoja programske opreme v skupini Amazon Redshift Service.
Sanket Hase je vodja razvoja programske opreme v skupini Amazon Redshift Service.
 Orestis Polychroniou je glavni inženir v ekipi Amazon Redshift Service.
Orestis Polychroniou je glavni inženir v ekipi Amazon Redshift Service.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :ima
- : je
- :ne
- :kje
- $GOR
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Sposobna
- O meni
- pospeši
- dostop
- dostopna
- Dosega
- čez
- dodano
- dodajanje
- Poleg tega
- Dodatne
- napredno
- Prednost
- privoščiti
- proti
- algoritmi
- vsi
- omogoča
- Prav tako
- alternativa
- alternative
- Čeprav
- vedno
- Amazon
- Amazon Web Services
- znesek
- an
- Analiza
- analitika
- analiziranje
- in
- Še ena
- kaj
- aplikacije
- Uporaba
- pristop
- SE
- območja
- okoli
- AS
- vidik
- povezan
- At
- pozornosti
- avto
- Avtomatizirano
- Samodejno
- samodejno
- Na voljo
- povprečno
- AWS
- b
- pasovna širina
- temeljijo
- BE
- ker
- pred
- začetek
- počutje
- merilo
- meril
- koristi
- BEST
- Boljše
- med
- Poleg
- milijardah
- tako
- ozka grla
- Pasovi
- prinašajo
- široka
- poslovni
- Poslovna inteligenca
- zaseden
- vendar
- by
- torta
- izračuna
- izračun
- klic
- CAN
- Zmogljivosti
- primeru
- primeri
- lastnosti
- značilna
- Graf
- sekanje
- izbral
- mesto
- Cloud
- Grozd
- Stolpec
- Stolpci
- kombinacija
- storjeno
- Skupno
- primerljiva
- primerjate
- v primerjavi z letom
- primerjavo
- tekmovalec
- tekmovalci
- kompleksna
- izpolnjujejo
- Izračunajte
- računalnik
- Računalniška vizija
- Koncept
- sočasno
- stanje
- poteka
- dosledno
- Konzole
- stalna
- nenehno
- predstavljajo
- svetovanje
- vsebujejo
- stalno
- naprej
- se nadaljuje
- neprekinjeno
- stalno
- kuhanje
- Ustrezno
- strošek
- stroški
- skupaj
- ustvarjajo
- ključnega pomena
- stranka
- Stranke, ki so
- Armaturna plošča
- nadzorne plošče
- datum
- Analiza podatkov
- Podatkovna analiza
- obdelava podatkov
- nabor podatkov
- podatkovno skladišče
- skladišča podatkov
- Podatkov usmerjenih
- Baze podatkov
- baze podatkov
- nabor podatkov
- Datum
- Odločitev
- privzeto
- opredeliti
- poda
- dostavo
- daje
- Izpeljano
- opisano
- zasnovan
- želeno
- Podatki
- podrobno
- Razvoj
- razvoju
- drugačen
- neposredno
- razpravlja
- razpravljali
- raznolikost
- razdeli
- do
- ne
- Ne
- dont
- vozi
- vsak
- prej
- enostavno
- jesti
- Učinkovito
- učinkovite
- učinkovito
- omogočena
- omogočanje
- spodbujanje
- Motor
- inženir
- okrepljeno
- Izboljšave
- izboljšave
- Vnesite
- Enakovredna
- zlasti
- Eter (ETH)
- vrednotenja
- Tudi
- vse
- Primer
- Primeri
- pričakovati
- izkušnje
- ekstrakt
- Faktor
- seznanjeni
- daleč
- FAST
- hitreje
- Feature
- Nekaj
- končno
- Najdi
- konča
- prva
- FLET
- Osredotočite
- sledi
- po
- za
- je pokazala,
- Ustanovitelj
- iz
- funkcionalno
- nadalje
- glavni namen
- ustvarila
- generacija
- dobili
- pridobivanje
- GitHub
- daje
- dogaja
- dobro
- Pridelovanje
- raste
- ročaj
- strojna oprema
- Imajo
- ob
- he
- visoka
- več
- njegov
- držite
- gospodarstvo
- uro
- URE
- Kako
- HTML
- http
- HTTPS
- sto
- Stotine
- idealen
- idealno
- identificirati
- if
- ilustrirajte
- slika
- vpliv
- Pomembno
- pomemben vidik
- izboljšanje
- izboljšalo
- Izboljšanje
- Izboljšave
- izboljšanju
- in
- vključujejo
- vključuje
- Vključno
- Povečajte
- povečal
- Poveča
- označuje
- industriji
- Infrastruktura
- primer
- primerov
- integracija
- Intelligence
- interaktivno
- notranji
- intervencije
- v
- Uvedeno
- Predstavljamo
- naložbe
- vključuje
- Internet stvari
- IT
- ITS
- pridružite
- jpg
- samo
- Imejte
- Komplet
- Vedeti
- velika
- večja
- pozneje
- Zadnji
- najnovejši razvoj dogodkov
- začela
- začetek
- Vodja
- vodi
- učenje
- vsaj
- manj
- Stopnja
- lahek
- kot
- malo
- obremenitev
- nalaganje
- obremenitve
- nahaja
- Long
- več
- Poglej
- si
- nizka
- nižje
- najnižja
- vzdrževati
- vzdrževanje
- vzdrževanje
- Večina
- Znamka
- upravlja
- upravljanje
- upravitelj
- upravlja
- Navodilo
- več
- Stave
- Zadeve
- Maj ..
- kar pomeni,
- pomeni
- merjenje
- izmerjena
- merjenje
- srednje
- Srečati
- Spomin
- omenjeno
- morda
- migracije
- min
- sodobna
- Ponedeljek
- Denar
- več
- Poleg tega
- Najbolj
- veliko
- in sicer
- Nimate
- potrebna
- potrebe
- Novo
- NY
- New York City
- na novo
- Naslednja
- št
- Upoštevajte
- opozoriti
- Opažam
- zdaj
- Številka
- of
- Uradni
- pogosto
- on
- Na zahtevo
- ONE
- samo
- deluje
- upravlja
- Priložnosti
- optimalna
- optimizacija
- optimizacijo
- Možnost
- možnosti
- or
- Ostalo
- naši
- ven
- več
- lastne
- parametri
- zlasti
- Vzorec
- vzorci
- Plačajte
- Plačilo
- za
- odstotek
- performance
- načrtovanje
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- Točka
- Popular
- mogoče
- Prispevek
- moč
- Predvidljivo
- predstavljeni
- preprečuje
- Cena
- cenitev
- , ravnateljica
- obdelani
- obravnavati
- Izdelek
- upravljanje izdelkov
- dokazilo
- dokaz koncepta
- zagotavljajo
- javno
- objavljeno
- kupili
- poizvedbe
- hitro
- naključno
- Preberi
- resnični svet
- v realnem času
- prejeti
- nedavno
- Pred kratkim
- Priporočila
- reference
- regije
- Zavrnjeno..
- relativna
- relativno
- odstranjevanje
- ponovi
- ponavljajoč
- podvojeno
- Poročila
- predstavnik
- predstavlja
- zahteva
- pridržane
- Odgovor
- odgovorna
- rezultat
- Rezultati
- Trgovina na drobno
- vrnitev
- prihodki
- pregleda
- Pravica
- robotika
- ROI
- Run
- tek
- deluje
- prodaja
- Enako
- Shrani
- Videl
- Prilagodljivost
- Lestvica
- luske
- skaliranje
- skenira
- shema
- skripte
- drugi
- sekund
- Oddelek
- glej
- seme
- višji
- služijo
- Brez strežnika
- Storitev
- Storitve
- nastavite
- nastavitev
- več
- Delite s prijatelji, znanci, družino in partnerji :-)
- Kratke Hlače
- shouldnt
- Prikaži
- pokazale
- pomemben
- bistveno
- podobno
- Enostavno
- hkrati
- sam
- Velikosti
- velikosti
- majhna
- So
- Software
- Razvoj programske opreme
- prostorsko
- specifikacija
- določeno
- hitrost
- preživeti
- porabljen
- spike
- SQL
- Začetek
- začel
- zagon
- bivanje
- vztrajno
- Koraki
- shranjevanje
- trgovine
- naravnost
- strategije
- tok
- pretakanje
- String
- predloži
- taka
- primernosti
- podpora
- Podpora
- sistem
- miza
- Bodite
- sprejeti
- skupina
- tehnike
- Tehnologije
- povej
- deset
- Test
- testi
- kot
- da
- O
- njihove
- POTEM
- Tukaj.
- zato
- te
- jih
- mislim
- ta
- tisti,
- tisoče
- 3
- pretočnost
- čas
- krat
- do
- danes
- Skupaj za plačilo
- Prometa
- Transform
- pregledno
- poskusite
- poskuša
- Dvakrat
- dva
- tip
- Vrste
- tipičen
- povsod
- ne morem
- Občasni
- razumeli
- edinstven
- nepredvidljivo
- dokler
- us
- Uporaba
- ameriški dolar
- uporaba
- primeru uporabe
- Rabljeni
- uporabnik
- Uporabniki
- uporablja
- uporabo
- Vrednote
- raznolikost
- različnih
- zelo
- ogledov
- praktično
- Vizija
- Počakaj
- želeli
- Skladišče
- je
- način..
- načini
- we
- web
- spletne storitve
- teden
- Dobro
- so bili
- Kaj
- kdaj
- medtem ko
- ki
- medtem
- zakaj
- široka
- bo
- z
- v
- brez
- vredno
- bi
- pisanje
- Napisal
- york
- jo
- Vaša rutina za
- zefirnet