Slika avtorja
When you are getting started with machine learning, logistic regression is one of the first algorithms you’ll add to your toolbox. It’s a simple and robust algorithm, commonly used for binary classification tasks.
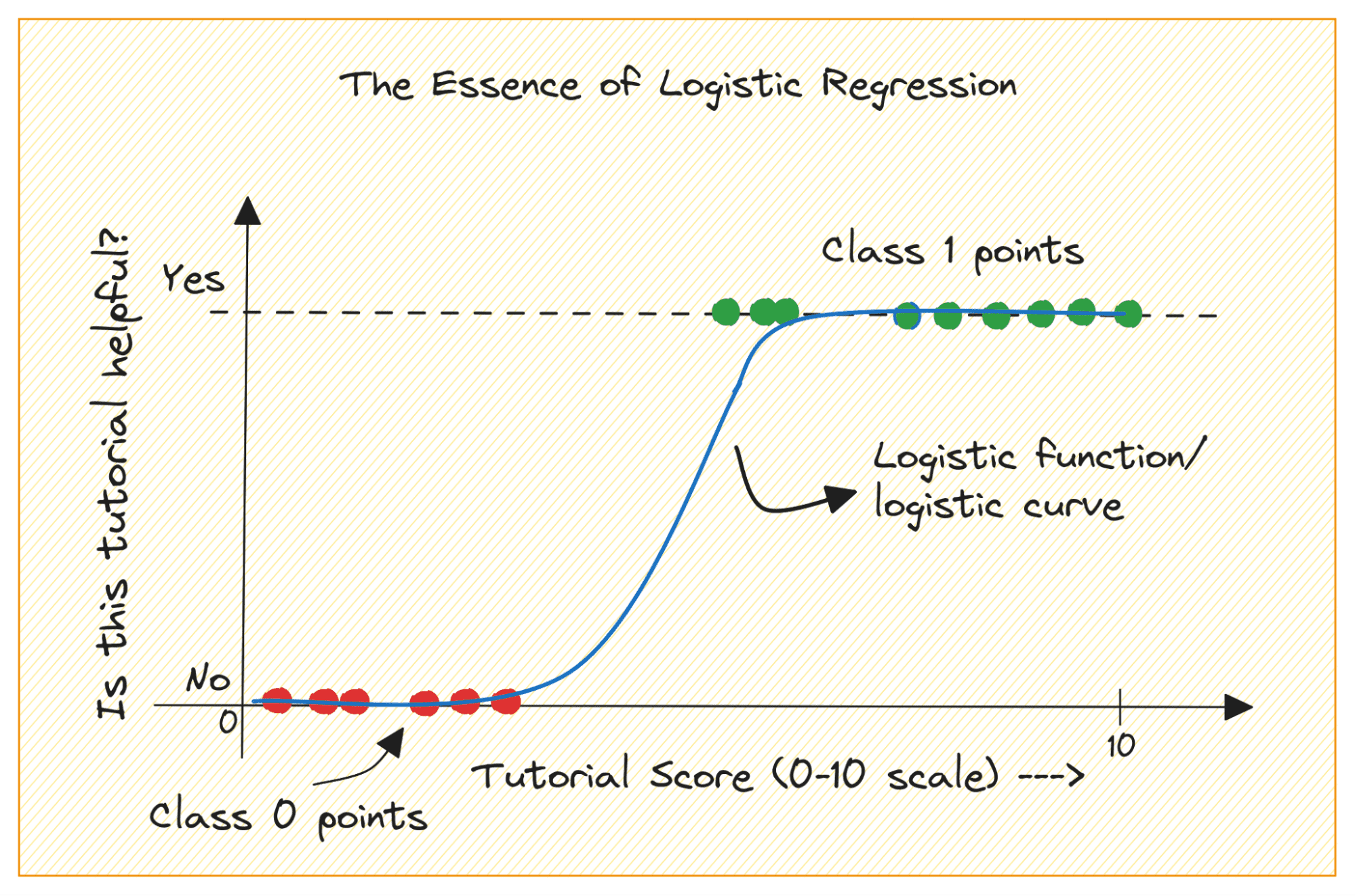
Razmislite o problemu binarne klasifikacije z razredoma 0 in 1. Logistična regresija prilagodi logistično ali sigmoidno funkcijo vhodnim podatkom in napove verjetnost, da podatkovna točka poizvedbe pripada razredu 1. Zanimivo, kajne?
V tej vadnici se bomo naučili o logistični regresiji od začetka in pokrili:
- Logistična (ali sigmoidna) funkcija
- Kako preidemo iz linearne v logistično regresijo
- Kako deluje logistična regresija
Na koncu bomo zgradili preprost model logistične regresije razvrstiti RADARJEVE povratke iz ionosfere.
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

Ko narišete sigmoidno funkcijo, bo videti takole:
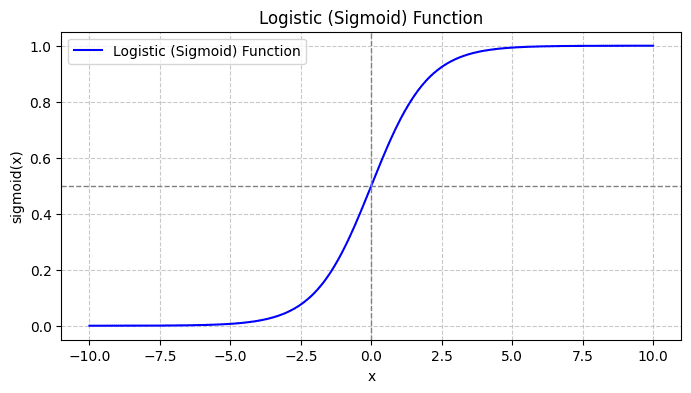
Iz risbe vidimo, da:
- Ko je x = 0, ima σ(x) vrednost 0.5.
- Ko se x približa +∞, se σ(x) približa 1.
- Ko se x približa -∞, se σ(x) približa 0.
Torej za vse realne vhode sigmoidna funkcija stisne, da prevzamejo vrednosti v območju [0, 1].
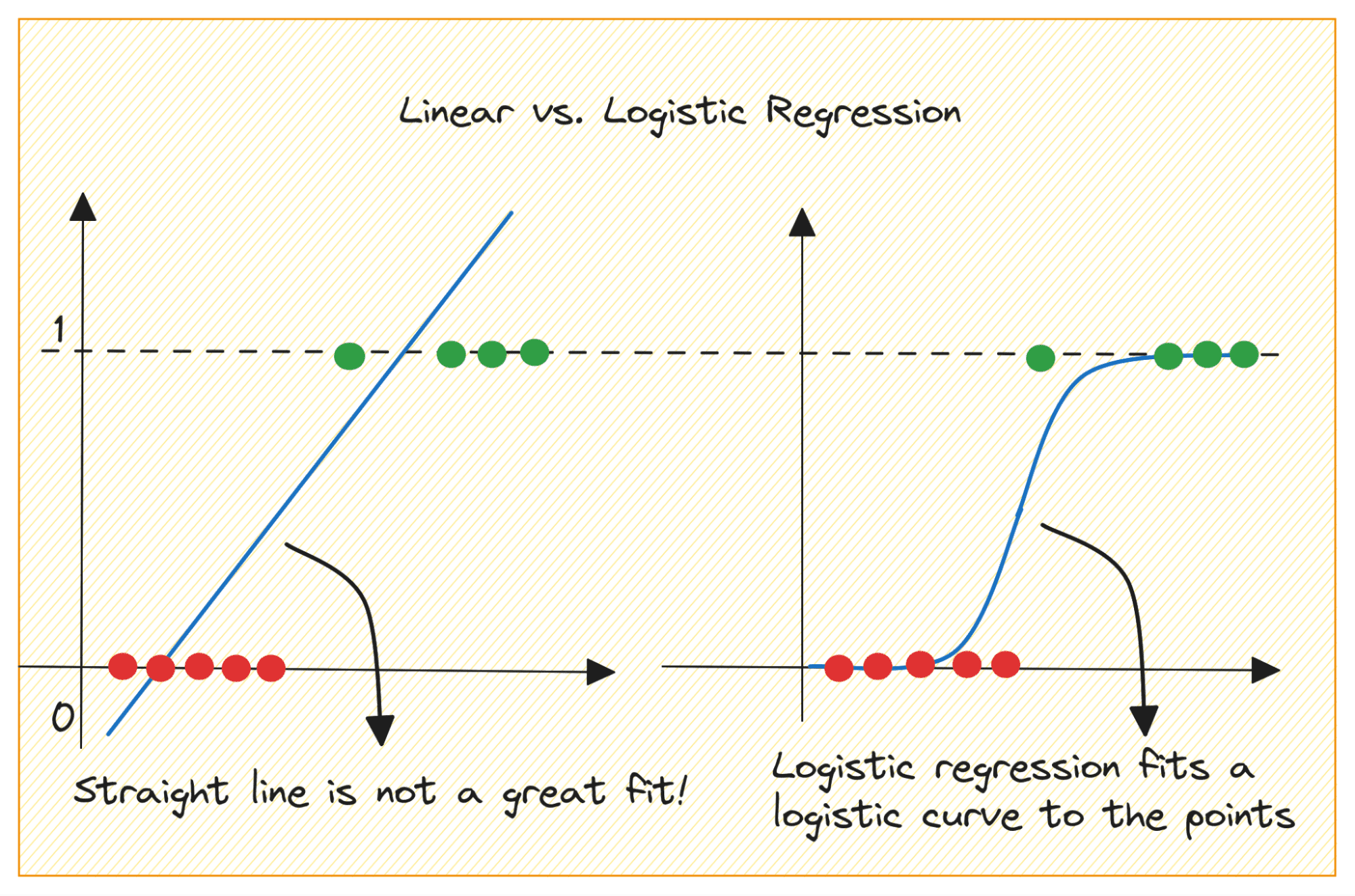
Let’s first discuss why we cannot use linear regression for a binary classification problem.
V problemu binarne klasifikacije je rezultat kategorična oznaka (0 ali 1). Ker linearna regresija napoveduje izhode z zveznimi vrednostmi, ki so lahko manjši od 0 ali večji od 1, ni smiselna za obravnavani problem.
Tudi ravna črta morda ne bo najbolj ustrezala, če izhodne oznake pripadajo eni od obeh kategorij.
Slika avtorja
Kako torej preidemo iz linearne v logistično regresijo? Pri linearni regresiji je predvideni rezultat podan z:
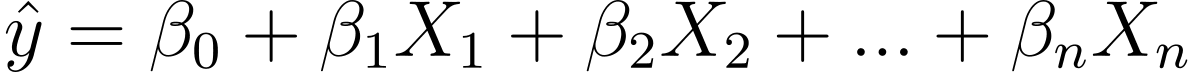
Kjer so β koeficienti in X_is napovedovalci (ali lastnosti).
Brez izgube splošnosti predpostavimo, da je X_0 = 1:

Tako lahko imamo bolj jedrnat izraz:
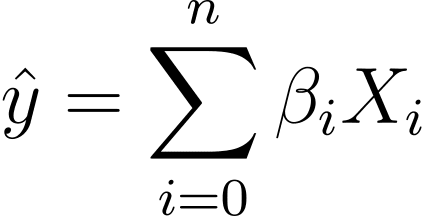
Pri logistični regresiji potrebujemo napovedano verjetnost p_i v intervalu [0,1]. Vemo, da logistična funkcija stisne vhode tako, da prevzamejo vrednosti v intervalu [0,1].
Torej, če ta izraz vključimo v logistično funkcijo, imamo predvideno verjetnost kot:
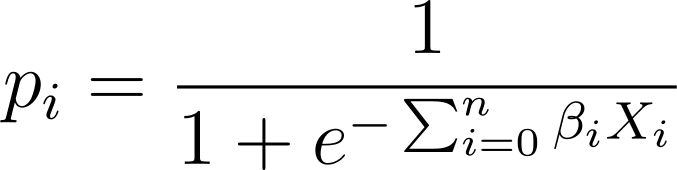
Torej, kako najdemo najbolj primerno logistično krivuljo za dani nabor podatkov? Da bi odgovorili na to, poglejmo oceno največje verjetnosti.
Ocena največje verjetnosti (MLE) is used to estimate the parameters of the logistic regression model by maximizing the likelihood function. Let’s break down the process of MLE in logistic regression and how the cost function is formulated for optimization using gradient descent.
Razčlenitev ocene največje verjetnosti
Kot smo razpravljali, modeliramo verjetnost, da se pojavi binarni izid kot funkcijo ene ali več napovednih spremenljivk (ali značilnosti):
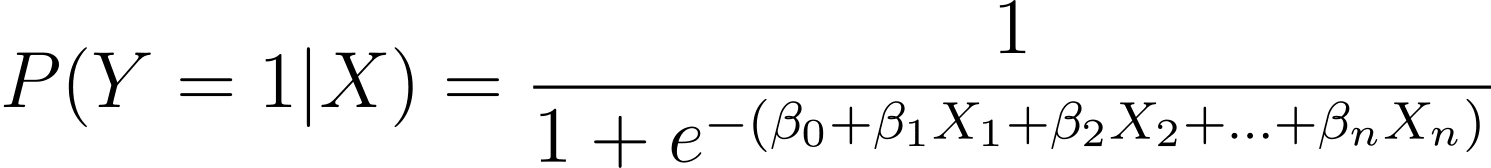
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
Cilj MLE je najti vrednosti β, ki povečajo verjetnost opazovanih podatkov. Funkcija verjetnosti, označena kot L(β), predstavlja verjetnost opazovanja danih rezultatov za dane napovedovalne vrednosti v logističnem regresijskem modelu.
Oblikovanje funkcije log-verjetnosti
To simplify the optimization process, it’s common to work with the log-likelihood function. Because it transforms products of probabilities into sums of log probabilities.
Funkcija log verjetnosti za logistično regresijo je podana z:
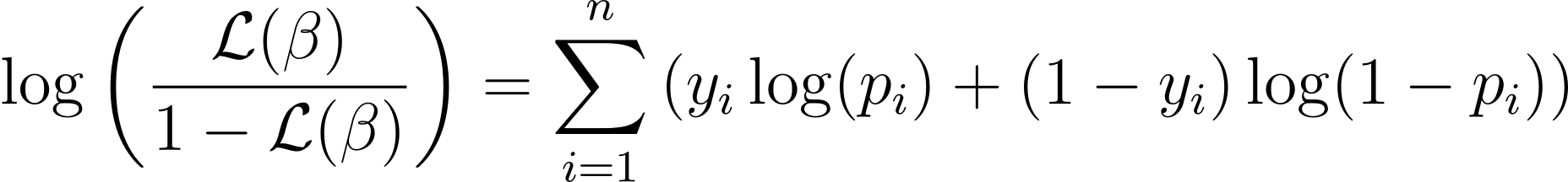
Now that we know the essence of log-likelihood, let’s proceed to formulate the cost function for logistic regression and subsequently gradient descent for finding the best model parameters
Funkcija stroškov za logistično regresijo
Za optimizacijo logističnega regresijskega modela moramo čim bolj povečati log-verjetnost. Tako lahko uporabimo negativno log-verjetnost kot funkcijo stroškov za minimiziranje med usposabljanjem. Negativna log-verjetnost, ki se pogosto imenuje logistična izguba, je opredeljena kot:
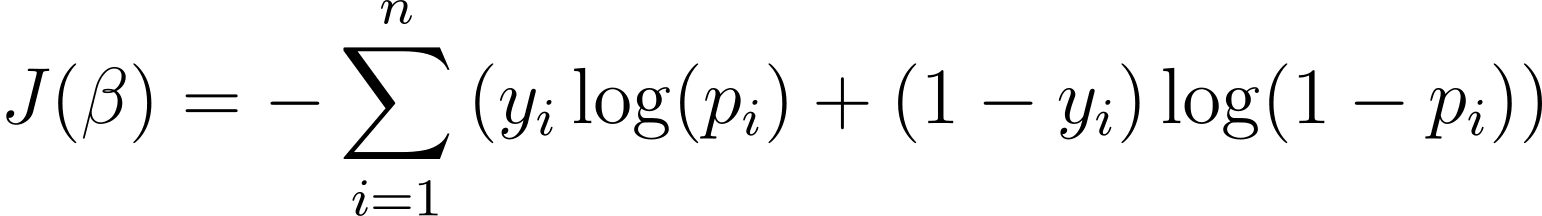
Cilj učnega algoritma je torej najti vrednosti ? ki minimizirajo to stroškovno funkcijo. Gradientni spust je pogosto uporabljen optimizacijski algoritem za iskanje minimuma te stroškovne funkcije.
Gradientni spust v logistični regresiji
Gradientni spust je iterativni optimizacijski algoritem, ki posodobi parametre modela β v nasprotni smeri gradienta stroškovne funkcije glede na β. Pravilo posodobitve v koraku t+1 za logistično regresijo z uporabo gradientnega spuščanja je naslednje:
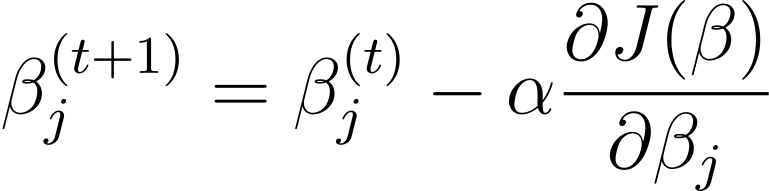
Kjer je α stopnja učenja.
Delne odvode je mogoče izračunati z uporabo verižnega pravila. Gradientni spust iterativno posodablja parametre – do konvergence – s ciljem zmanjšati logistične izgube. Ko konvergira, najde optimalne vrednosti β, ki povečajo verjetnost opazovanih podatkov.
Zdaj, ko veste, kako deluje logistična regresija, zgradimo napovedni model z uporabo knjižnice scikit-learn.
Uporabili bomo nabor podatkov o ionosferi iz repozitorija strojnega učenja UCI za to vadnico. Nabor podatkov obsega 34 numeričnih značilnosti. Izhod je binarni, eden izmed "dober" ali "slab" (označen z "g" ali "b"). Izhodna oznaka "dobro" se nanaša na rezultate RADAR, ki so zaznali neko strukturo v ionosferi.
1. korak – nalaganje nabora podatkov
Najprej prenesite nabor podatkov in ga preberite v podatkovni okvir pandas:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)2. korak – Raziskovanje nabora podatkov
Let’s take a look at the first few rows of the dataframe:
# Display the first few rows of the DataFrame
df.head()
Skrajšan izhod df.head()
Let’s get some information about the dataset: the number of non-null values and the data types of each of the columns:
# Get information about the dataset
print(df.info())
 Skrajšan izhod df.info()
Skrajšan izhod df.info()
Ker imamo vse numerične funkcije, lahko z uporabo dobimo tudi nekaj opisne statistike describe() metoda v podatkovnem okviru:
# Get descriptive statistics of the dataset
print(df.describe())
Skrajšan izhod df.describe()
Imena stolpcev so trenutno od 0 do 34 – vključno z oznako. Ker nabor podatkov ne zagotavlja opisnih imen za stolpce, se nanje nanaša le kot attribute_1 do attribute_34, če želite, lahko preimenujete stolpce podatkovnega okvira, kot je prikazano:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Opomba: ta korak je izključno neobvezen. Če želite, lahko nadaljujete s privzetimi imeni stolpcev.
# Display the first few rows of the DataFrame
df.head()
Skrajšan izpis df.head() [po preimenovanju stolpcev]
3. korak – Preimenovanje oznak razredov in vizualizacija porazdelitve razredov
Ker sta oznaki izhodnega razreda 'g' in 'b', ju moramo preslikati v 1 oziroma 0. To lahko storite z uporabo map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Predstavimo tudi distribucijo oznak razreda:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
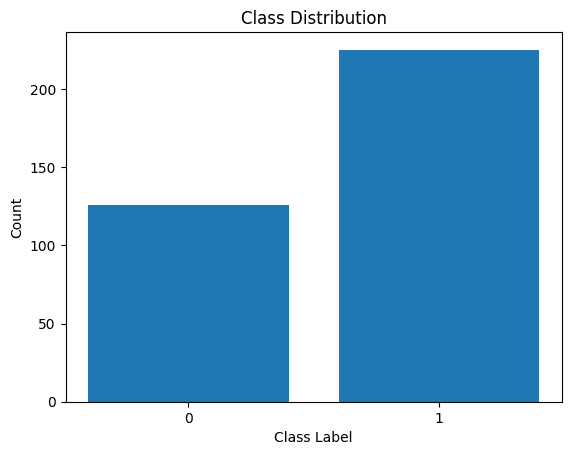
Porazdelitev oznak razredov
Vidimo, da je v distribuciji neravnovesje. Obstaja več zapisov, ki pripadajo razredu 1 kot razredu 0. To neravnovesje razreda bomo obravnavali pri izdelavi modela logistične regresije.
Korak 5 – Predhodna obdelava nabora podatkov
Zberimo funkcije in izpisne oznake takole:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Po razdelitvi nabora podatkov na nabore vlakov in testov moramo nabor podatkov predhodno obdelati.
Kadar obstaja veliko numeričnih funkcij – vsaka na potencialno drugačnem merilu – moramo predhodno obdelati numerične funkcije. Običajna metoda je, da jih transformiramo tako, da sledijo porazdelitvi z nič povprečjem in enotsko varianco.
O StandardScaler iz modula za predprocesiranje scikit-learn nam pomaga doseči to.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Korak 6 – Izdelava modela logistične regresije
Zdaj lahko ustvarimo klasifikator logistične regresije. The LogisticRegression razred je del modula linear_model scikit-learn.
Upoštevajte, da smo nastavili class_weight parameter na "uravnotežen". To nam bo pomagalo razložiti razredno neravnovesje. Z dodeljevanjem uteži vsakemu razredu – obratno sorazmerno s številom zapisov v razredih.
Po instanciranju razreda lahko prilagodimo model naboru podatkov za usposabljanje:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Korak 7 – Vrednotenje modela logistične regresije
Lahko pokličete predict() metoda za pridobitev napovedi modela.
Poleg ocene točnosti lahko dobimo tudi poročilo o klasifikaciji z metrikami, kot so natančnost, priklic in rezultat F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
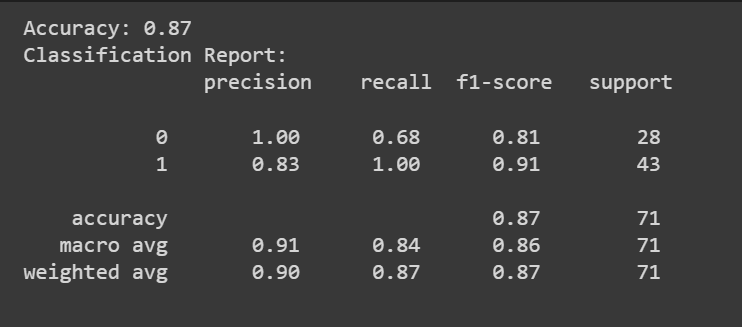
Čestitamo, kodirali ste svoj prvi logistični regresijski model!
V tej vadnici smo se podrobno seznanili z logistično regresijo: od teorije in matematike do kodiranja klasifikatorja logistične regresije.
Kot naslednji korak poskusite zgraditi logistični regresijski model za ustrezen nabor podatkov po vaši izbiri.
Nabor podatkov Ionosphere je licenciran pod a Creative Commons Attribution 4.0 International (CC BY 4.0) licenca:
Sigillito, V., Wing, S., Hutton, L. in Baker, K.. (1989). Ionosfera. Repozitorij strojnega učenja UCI. https://doi.org/10.24432/C5W01B.
Bala Priya C je razvijalec in tehnični pisec iz Indije. Rada dela na presečišču matematike, programiranja, znanosti o podatkih in ustvarjanja vsebin. Njena področja zanimanja in strokovnega znanja vključujejo DevOps, znanost o podatkih in obdelavo naravnega jezika. Uživa v branju, pisanju, kodiranju in kavi! Trenutno se uči in svoje znanje deli s skupnostjo razvijalcev, tako da piše vadnice, vodnike z navodili, mnenja in drugo.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- : je
- :ne
- $GOR
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- O meni
- Račun
- natančnost
- Doseči
- dodajte
- Poleg tega
- po
- Cilje
- algoritem
- algoritmi
- vsi
- Prav tako
- an
- in
- odgovor
- pristopi
- SE
- območja
- AS
- domnevati
- At
- avtorstvo
- b
- pek
- Uravnotežen
- bar
- BE
- ker
- pripadnosti
- BEST
- Break
- izgradnjo
- Building
- by
- klic
- CAN
- ne more
- kategorije
- verige
- izbira
- razred
- razredi
- Razvrstitev
- kodirano
- Kodiranje
- zbiranje
- Stolpec
- Stolpci
- Skupno
- pogosto
- Commons
- skupnost
- obsega
- zgoščeno
- vsebina
- ustvarjanje vsebine
- pretvorbo
- strošek
- kritje
- ustvarjajo
- Oblikovanje
- Trenutno
- krivulja
- datum
- podatkovne točke
- znanost o podatkih
- nabor podatkov
- privzeto
- opredeljen
- Izvedeni finančni instrumenti
- Podatki
- Zaznali
- Razvojni
- DevOps
- drugačen
- smer
- razpravlja
- razpravljali
- zaslon
- distribucija
- do
- ne
- navzdol
- prenesi
- med
- vsak
- Bistvo
- oceniti
- ocenjevanje
- strokovno znanje
- Raziskovati
- izraz
- Lastnosti
- Nekaj
- Najdi
- iskanje
- najdbe
- prva
- fit
- sledi
- sledi
- za
- FRAME
- iz
- funkcija
- dobili
- pridobivanje
- dana
- Go
- Cilj
- več
- Igrišče
- Vodniki
- strani
- ročaj
- Imajo
- pomoč
- Pomaga
- jo
- Kako
- HTTPS
- ICS
- if
- neravnovesje
- uvoz
- in
- vključujejo
- Indeks
- india
- indeksi
- Podatki
- vhod
- vhodi
- obresti
- Zanimivo
- križišče
- v
- IT
- samo
- KDnuggets
- Vedite
- znanje
- label
- Oznake
- jezik
- UČITE
- naučili
- učenje
- manj
- Naj
- Knjižnica
- Licenca
- Licencirano
- kot
- verjetnost
- všeč mi je
- vrstica
- nalaganje
- prijavi
- Poglej
- izgleda kot
- off
- stroj
- strojno učenje
- Znamka
- več
- map
- math
- matplotlib
- Povečajte
- maksimiranje
- največja
- Maj ..
- pomeni
- Metoda
- Meritve
- zmanjšajo
- minimalna
- Model
- modeli
- modul
- več
- premikanje
- Imena
- naravna
- Naravni jezik
- Obdelava Natural Language
- Nimate
- negativna
- Naslednja
- Številka
- opazovana
- of
- pogosto
- on
- ONE
- Mnenje
- Nasprotno
- optimalna
- optimizacija
- Optimizirajte
- or
- Rezultat
- rezultatov
- izhod
- izhodi
- pand
- parameter
- parametri
- del
- kosov
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- točke
- potencialno
- Precision
- napovedano
- Napovedi
- napovedno
- Predictor
- Napovedi
- raje
- verjetnost
- problem
- nadaljujte
- Postopek
- obravnavati
- Izdelki
- Programiranje
- zagotavljajo
- izključno
- Python
- radar
- območje
- Oceniti
- Preberi
- reading
- pravo
- evidence
- besedilu
- nanaša
- regresija
- poročilo
- Skladišče
- predstavlja
- zahteva
- spoštovanje
- oziroma
- vrne
- pregleda
- robusten
- Pravilo
- s
- Znanost
- scikit-učiti
- rezultat
- glej
- Občutek
- nastavite
- Kompleti
- delitev
- je
- pokazale
- Enostavno
- poenostavitev
- So
- nekaj
- po delih
- začel
- Statistika
- Korak
- naravnost
- Struktura
- Kasneje
- taka
- primerna
- vsote
- Bodite
- meni
- ciljna
- Naloge
- tehnični
- Test
- Testiranje
- kot
- da
- O
- Njih
- Teorija
- Tukaj.
- zato
- jih
- ta
- skozi
- do
- Toolbox
- Vlak
- usposobljeni
- usposabljanje
- Transform
- transformacije
- poskusite
- Navodila
- vaje
- dva
- Vrste
- pod
- razumeli
- Enota
- Nadgradnja
- posodobitve
- URL
- us
- ameriški račun
- uporaba
- Rabljeni
- uporabo
- vrednost
- Vrednote
- vizualizirati
- we
- kdaj
- ki
- zakaj
- Wikipedia
- bo
- Krilo
- z
- delo
- deluje
- deluje
- bi
- Pisatelj
- pisanje
- X
- ja
- jo
- Vaša rutina za
- zefirnet
- nič







