Slika avtorja
Na voljo je veliko tečajev in virov o strojnem učenju in podatkovni znanosti, zelo malo pa o podatkovnem inženirstvu. To odpira nekaj vprašanj. Je to težko področje? Ali ponuja nizko plačilo? Ali ne velja za enako razburljivo kot druge tehnološke vloge? Vendar pa je resničnost taka, da številna podjetja aktivno iščejo talente za podatkovni inženiring in ponujajo znatne plače, ki včasih presegajo 200,000 USD. Podatkovni inženirji igrajo ključno vlogo kot arhitekti podatkovnih platform, saj oblikujejo in gradijo temeljne sisteme, ki omogočajo učinkovito delovanje podatkovnih znanstvenikov in strokovnjakov za strojno učenje.
Da bi rešil to vrzel v industriji, je DataTalkClub uvedel transformativen in brezplačen bootcamp, “Zoomcamp podatkovnega inženiringa“. Ta tečaj je zasnovan tako, da opolnomoči začetnike ali strokovnjake, ki želijo zamenjati poklic, z bistvenimi veščinami in praktičnimi izkušnjami na področju podatkovnega inženiringa.
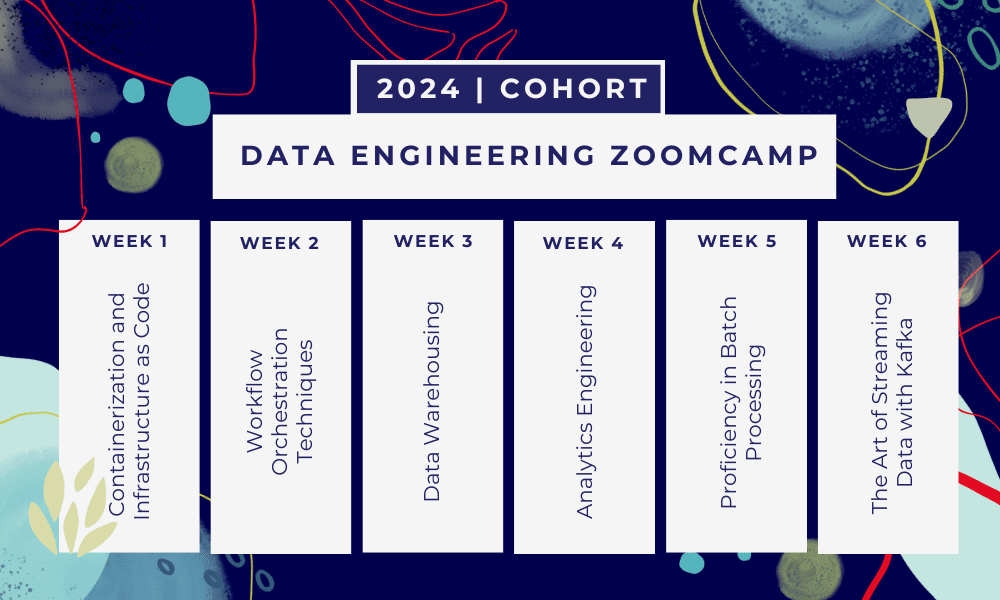
To je 6-tedenski bootcamp kjer se boste učili skozi več tečajev, bralnega gradiva, delavnic in projektov. Na koncu vsakega modula boste dobili domačo nalogo, s katero boste vadili naučeno.
- Teden 1: Uvod v GCP, Docker, Postgres, Terraform in nastavitev okolja.
- Teden 2: Orkestracija poteka dela z Mage.
- Teden 3: Skladiščenje podatkov z BigQuery in strojno učenje z BigQuery.
- Teden 4: Analitični inženir z dbt, Google Data Studio in Metabase.
- Teden 5: Paketna obdelava s Sparkom.
- Teden 6: Pretakanje s Kafko.
Slika iz DataTalksClub/data-engineering-zoomcamp
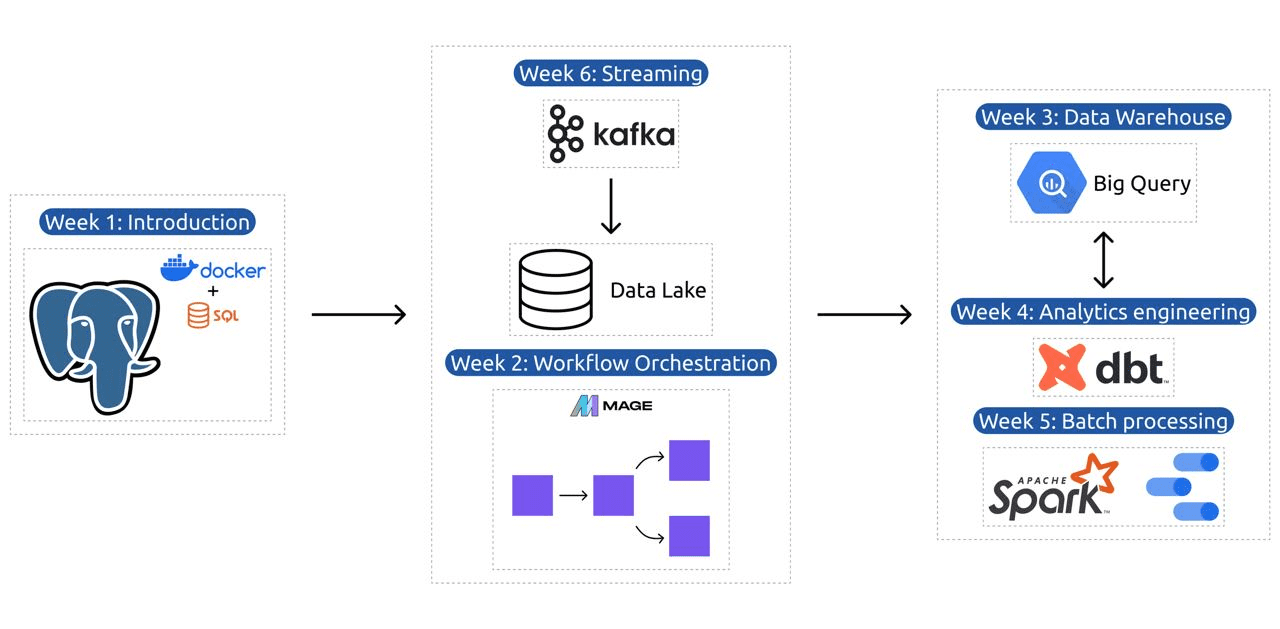
Učni načrt vsebuje 6 modulov, 2 delavnici in projekt, ki pokriva vse, kar potrebujete, da postanete profesionalni podatkovni inženir.
Modul 1: Obvladovanje kontejnerizacije in infrastrukture kot kode
V tem modulu boste spoznali Docker in Postgres, začenši z osnovami in nadaljevali s podrobnimi vadnicami o ustvarjanju podatkovnih cevovodov, izvajanju Postgresa z Dockerjem in več.
Modul pokriva tudi osnovna orodja, kot so pgAdmin, Docker-compose in teme za osvežitev SQL, z izbirno vsebino o omrežju Docker in posebnim postopkom za uporabnike podsistema Windows Linux. Na koncu vas tečaj seznani z GCP in Terraformom, ki zagotavlja celovito razumevanje kontejnerizacije in infrastrukture kot kode, bistvenega pomena za sodobna okolja v oblaku.
Modul 2: Tehnike orkestracije poteka dela
Modul ponuja poglobljeno raziskovanje Mage, inovativnega odprtokodnega hibridnega okvira za pretvorbo in integracijo podatkov. Ta modul se začne z osnovami orkestracije delovnega toka, napreduje do praktičnih vaj z Mage, vključno z nastavitvijo prek Dockerja in gradnjo cevovodov ETL iz API-ja v Postgres in Google Cloud Storage (GCS) ter nato v BigQuery.
Mešanica videoposnetkov, virov in praktičnih nalog v modulu zagotavlja celovito učno izkušnjo, ki učence opremi z veščinami za upravljanje zahtevnih delovnih tokov podatkov s programom Mage.
Delavnica 1: Strategije vnosa podatkov
Na prvi delavnici boste obvladali gradnjo učinkovitih cevovodov za vnos podatkov. Delavnica se osredotoča na bistvene veščine, kot je pridobivanje podatkov iz API-jev in datotek, normalizacija in nalaganje podatkov ter tehnike postopnega nalaganja. Po zaključku te delavnice boste sposobni ustvarjati učinkovite podatkovne cevovode kot višji podatkovni inženir.
Modul 3: Skladiščenje podatkov
Modul je poglobljeno raziskovanje shranjevanja in analize podatkov, s poudarkom na skladiščenju podatkov z uporabo BigQuery. Zajema ključne koncepte, kot sta particioniranje in združevanje v gruče, in se poglobi v najboljše prakse BigQuery. Modul napreduje v napredne teme, zlasti integracijo strojnega učenja (ML) z BigQuery, poudarja uporabo SQL za ML in zagotavlja vire za prilagajanje hiperparametrov, predprocesiranje funkcij in uvajanje modela.
Modul 4: Analitični inženiring
Modul analitičnega inženiringa se osredotoča na gradnjo projekta z uporabo dbt (Data Build Tool) z obstoječim skladiščem podatkov, bodisi BigQuery ali PostgreSQL.
Modul zajema nastavitev dbt v oblaku in lokalnem okolju, uvajanje konceptov analitičnega inženiringa, ETL proti ELT in modeliranje podatkov. Zajema tudi napredne funkcije dbt, kot so inkrementalni modeli, oznake, kljuke in posnetki.
Na koncu modul predstavi tehnike za vizualizacijo pretvorjenih podatkov z orodji, kot sta Google Data Studio in Metabase, ter zagotavlja vire za odpravljanje težav in učinkovito nalaganje podatkov.
Modul 5: Strokovnost v paketni obdelavi
Ta modul pokriva paketno obdelavo z uporabo Apache Spark, začenši z uvodom v paketno obdelavo in Spark, skupaj z navodili za namestitev za Windows, Linux in MacOS.
Vključuje raziskovanje Spark SQL in DataFrames, pripravo podatkov, izvajanje operacij SQL in razumevanje notranjosti Spark. Končno se zaključi z izvajanjem Spark v oblaku in integracijo Spark z BigQuery.
Modul 6: Umetnost pretakanja podatkov s Kafko
Modul se začne z uvodom v koncepte pretočne obdelave, čemur sledi poglobljeno raziskovanje Kafke, vključno z njenimi osnovami, integracijo s Confluent Cloud in praktičnimi aplikacijami, ki vključujejo proizvajalce in potrošnike.
Modul pokriva tudi konfiguracijo in tokove Kafka, obravnava teme, kot so združevanje tokov, testiranje, okna in uporaba Kafka ksqldb & Connect. Poleg tega se osredotoča na okolja Python in JVM, ki vključuje Faust za obdelavo tokov Python, Pyspark – Structured Streaming in primere Scala za Kafka Streams.
Delavnica 2: Pretočna obdelava s SQL
Naučili se boste obdelovati in upravljati pretočne podatke z RisingWave, ki zagotavlja stroškovno učinkovito rešitev z izkušnjo v slogu PostgreSQL za krepitev vaših aplikacij za obdelavo tokov.
Projekt: Real-World Data Engineering Application
Cilj tega projekta je implementacija vseh konceptov, ki smo se jih naučili v tem tečaju, za izgradnjo podatkovnega cevovoda od konca do konca. Ustvarjali boste nadzorno ploščo, sestavljeno iz dveh ploščic, tako da boste izbrali nabor podatkov, zgradili cevovod za obdelavo podatkov in jih shranili v podatkovno jezero, zgradili cevovod za prenos obdelanih podatkov iz podatkovnega jezera v podatkovno skladišče, preoblikovali podatke v podatkovnem skladišču in njihovo pripravo za nadzorno ploščo ter končno izgradnjo nadzorne plošče za vizualno predstavitev podatkov.
Podrobnosti o kohorti 2024
- Registracija: Vnesite zdaj
- Datum začetka: 15. januar 2024, ob 17:00 CET
- Samostojno učenje z vodeno podporo
- Kohortna mapa z domačimi nalogami in roki
- Interactive Slack skupnost za medvrstniško učenje
Predpogoji
- Osnovno kodiranje in veščine ukazne vrstice
- Temelj v SQL
- Python: koristen, vendar ni obvezen
Strokovni inštruktorji, ki vodijo vaše potovanje
- Ankush Khanna
- Victoria Perez Mola
- Aleksej Grigorev
- Matt Palmer
- Luis Oliveira
- Michael Shoemaker
Pridružite se naši kohorti 2024 in se začnite učiti z neverjetno skupnostjo podatkovnega inženiringa. Z usposabljanjem, ki ga vodijo strokovnjaki, praktičnimi izkušnjami in učnim načrtom, prilagojenim potrebam panoge, vas ta bootcamp ne le opremi s potrebnimi veščinami, ampak vas tudi postavi v ospredje donosne in zahtevane poklicne poti. Prijavite se še danes in spremenite svoje želje v resničnost!
Abid Ali Awan (@1abidaliawan) je certificiran strokovnjak za podatkovne znanstvenike, ki rad gradi modele strojnega učenja. Trenutno se osredotoča na ustvarjanje vsebin in pisanje tehničnih blogov o strojnem učenju in tehnologijah podatkovne znanosti. Abid ima magisterij iz tehnološkega managementa in diplomo iz telekomunikacijskega inženiringa. Njegova vizija je zgraditi izdelek AI z uporabo grafične nevronske mreže za študente, ki se borijo z duševnimi boleznimi.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :ima
- : je
- :ne
- :kje
- $GOR
- 000
- 1
- 15%
- 17
- 2024
- a
- Sposobna
- O meni
- aktivno
- Poleg tega
- naslavljanje
- napredno
- napredovanje
- po
- AI
- vsi
- skupaj
- Prav tako
- Neverjetno
- an
- Analiza
- Analitično
- analitika
- in
- in infrastrukturo
- Apache
- Apache Spark
- API
- API-ji
- aplikacije
- arhitekti
- SE
- Umetnost
- AS
- At
- Na voljo
- Osnove
- BE
- postanejo
- postajajo
- Začetniki
- koristno
- BEST
- najboljše prakse
- bigquery
- Blend
- blogi
- tako
- izgradnjo
- Building
- vendar
- by
- Kariera
- kariere
- Certified
- Cloud
- Cloud Storage
- grozdenje
- Koda
- Kodiranje
- Kohorta
- skupnost
- Podjetja
- dokončanje
- celovito
- koncepti
- zaključuje
- konfiguracija
- Sotočje
- Connect
- šteje
- Sestavljeno
- gradnjo
- Potrošniki
- Vsebuje
- vsebina
- ustvarjanje vsebine
- Tečaj
- tečaji
- prevleke
- ustvarjajo
- Ustvarjanje
- Oblikovanje
- ključnega pomena
- Trenutno
- Kurikulum
- Armaturna plošča
- datum
- podatkovni inženir
- Data jezero
- znanost o podatkih
- podatkovni znanstvenik
- shranjevanje podatkov
- podatkovno skladišče
- Datum
- Stopnja
- uvajanje
- zasnovan
- oblikovanje
- podrobno
- težko
- Lučki delavec
- vsak
- učinkovito
- učinkovite
- bodisi
- opolnomočiti
- omogočajo
- konec
- konec koncev
- inženir
- Inženiring
- Inženirji
- vpis
- zagotavlja
- okolje
- okolja
- bistvena
- Eter (ETH)
- vse
- Primeri
- zanimivo
- obstoječih
- izkušnje
- Strokovnjaki
- raziskovanje
- Raziskovati
- Se razširi
- Feature
- Lastnosti
- Featuring
- Nekaj
- Polje
- datoteke
- končno
- prva
- Osredotočite
- Osredotoča
- osredotoča
- sledili
- za
- ospredju
- Temeljno
- Okvirni
- brezplačno
- iz
- funkcija
- Osnove
- vrzel
- GCP
- dana
- Google Cloud
- graf
- Grafična nevronska mreža
- voden
- hands-on
- Imajo
- he
- poudarjanje
- njegov
- drži
- celosten
- domače naloge
- kljuke
- Vendar
- HTTPS
- Hybrid
- Uglaševanje hiperparametrov
- bolezen
- izvajati
- in
- Poglobljena
- vključuje
- Vključno
- inkrementalno
- Industrija
- Infrastruktura
- inovativne
- namestitev
- Navodila
- Povezovanje
- integracija
- v
- Uvedeno
- Predstavlja
- Predstavljamo
- Predstavitev
- Predstavitev
- vključujejo
- IT
- ITS
- januar
- Pridružuje
- kafka
- KDnuggets
- Ključne
- Jezero
- vodi
- UČITE
- naučili
- učencev
- učenje
- kot
- vrstica
- linux
- nalaganje
- lokalna
- si
- ljubi
- nizka
- donosen
- stroj
- strojno učenje
- MacOS
- upravljanje
- upravljanje
- obvezna
- več
- mojster
- Mastering
- materiali
- duševne
- Mentalna bolezen
- ML
- Model
- modeliranje
- modeli
- sodobna
- modul
- Moduli
- več
- več
- potrebno
- Nimate
- potrebna
- potrebe
- mreža
- mreženje
- Nevronski
- nevronska mreža
- Cilj
- of
- ponujanje
- Ponudbe
- on
- samo
- open source
- operacije
- or
- orkestracijo
- Ostalo
- naši
- Palmer
- zlasti
- pot
- Plačajte
- peer
- izvajati
- plinovod
- Platforme
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Predvajaj
- pozicije
- postgresql
- Praktično
- Praktični Aplikacije
- praksa
- vaje
- priprava
- predstaviti
- Postopek
- obdelani
- obravnavati
- Proizvajalci
- Izdelek
- strokovni
- strokovnjaki
- napreduje
- Projekt
- projekti
- zagotavlja
- zagotavljanje
- Python
- vprašanja
- povečuje
- reading
- resnični svet
- Reality
- viri
- vloga
- vloge
- tek
- s
- plače
- Lestvica
- Znanost
- Znanstvenik
- Znanstveniki
- iskanju
- izbiranje
- višji
- nastavitev
- nastavitev
- spretnosti
- Slack
- Rešitev
- nekaj
- Včasih
- prefinjeno
- Spark
- posebna
- SQL
- Začetek
- Začetek
- shranjevanje
- tok
- pretakanje
- tokovi
- strukturirano
- Boriti se
- Študenti
- studio
- precejšen
- taka
- podpora
- Preklop
- sistemi
- prilagojene
- talent
- Naloge
- tech
- tehnični
- tehnike
- Tehnologije
- Tehnologija
- telekomunikacije
- Terraform
- Testiranje
- da
- O
- Osnove
- POTEM
- ta
- skozi
- do
- danes
- orodje
- orodja
- Teme
- usposabljanje
- Prenos
- Transform
- Preoblikovanje
- transformativno
- preoblikovati
- preoblikovanje
- vaje
- dva
- razumevanje
- ameriški dolar
- uporaba
- Uporabniki
- uporabo
- Ve
- zelo
- preko
- Video posnetki
- Vizija
- vizualno
- vs
- Skladišče
- skladiščenje
- we
- Kaj
- ki
- WHO
- bo
- okna
- z
- potek dela
- delovnih tokov
- Delavnica
- Delavnice
- pisanje
- jo
- Vaša rutina za
- zefirnet










