Изображение на Freepik
Разговорный ИИ — это виртуальные агенты и чат-боты, которые имитируют взаимодействие людей и могут вовлекать людей в разговор. Использование диалогового искусственного интеллекта быстро становится образом жизни – от запросов к Алексе до «найди ближайший ресторан” попросить Сири «создать напоминание», виртуальные помощники и чат-боты часто используются для ответа на вопросы потребителей, разрешения жалоб, бронирования и многого другого.
Разработка этих виртуальных помощников требует значительных усилий. Однако понимание и решение ключевых проблем может упростить процесс развития. Я использовал свой непосредственный опыт создания зрелого чат-бота для платформы по подбору персонала в качестве отправной точки для объяснения ключевых проблем и соответствующих решений.
Для создания диалогового чат-бота с искусственным интеллектом разработчики могут использовать такие платформы, как RASA, Amazon Lex или Google Dialogflow. Большинство предпочитают RASA, когда планируют пользовательские изменения или когда бот находится на стадии зрелости, поскольку это платформа с открытым исходным кодом. Другие фреймворки также подходят в качестве отправной точки.
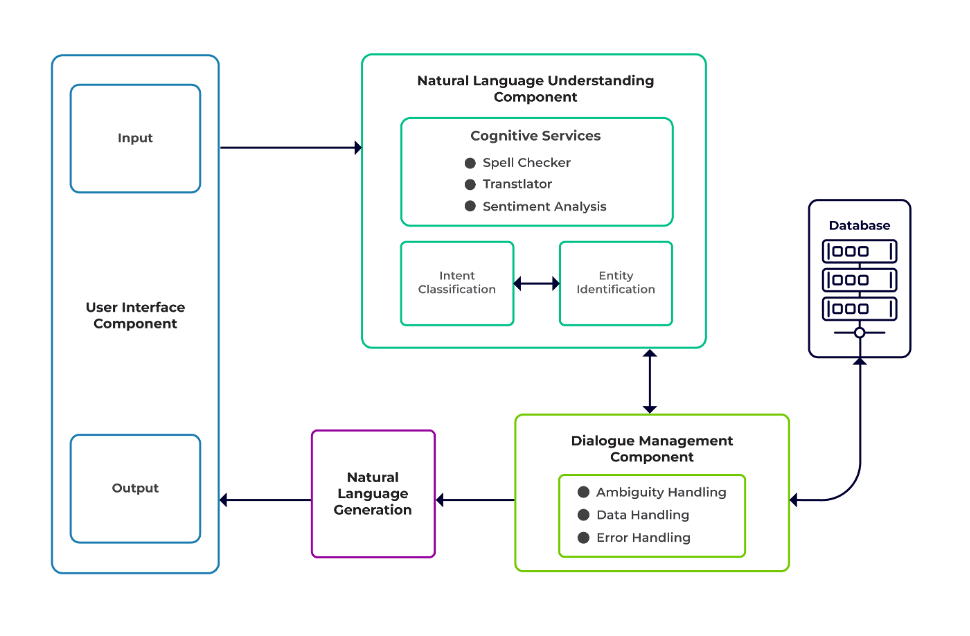
Проблемы можно разделить на три основных компонента чат-бота.
Понимание естественного языка (НЛУ) — это способность бота понимать человеческий диалог. Он выполняет классификацию намерений, извлечение сущностей и получение ответов.
Менеджер диалогов отвечает за набор действий, которые необходимо выполнить на основе текущего и предыдущего набора пользовательских данных. Он принимает намерение и сущности в качестве входных данных (как часть предыдущего разговора) и определяет следующий ответ.
Поколение естественного языка (NLG) — это процесс создания письменных или устных предложений на основе заданных данных. Он формирует ответ, который затем представляется пользователю.
Изображение из программного обеспечения Talentica
Недостаточные данные
Когда разработчики заменяют FAQ или другие системы поддержки чат-ботом, они получают приличный объем обучающих данных. Но этого не происходит, когда бота создают с нуля. В таких случаях разработчики генерируют обучающие данные синтетически.
Что делать?
Генератор данных на основе шаблонов может генерировать приличное количество пользовательских запросов для обучения. Как только чат-бот будет готов, владельцы проекта смогут предоставить его ограниченному числу пользователей, чтобы улучшить данные обучения и обновить их в течение определенного периода времени.
Неподходящий выбор модели
Соответствующий выбор модели и данные обучения имеют решающее значение для получения наилучших результатов извлечения намерений и объектов. Разработчики обычно обучают чат-ботов определенному языку и предметной области, и большинство доступных предварительно обученных моделей часто ориентированы на предметную область и обучены на одном языке.
Могут быть случаи смешанного языка, а также случаи, когда люди являются полиглотами. Они могут вводить запросы на смешанном языке. Например, в регионе, где доминируют французы, люди могут использовать тип английского языка, представляющий собой смесь французского и английского языков.
Что делать?
Использование моделей, обученных на нескольких языках, может решить проблему. В таких случаях может быть полезна предварительно обученная модель, такая как LaBSE (встраивание предложений Берта, не зависящее от языка). LaBSE обучается более чем на 109 языках для решения задачи на сходство предложений. Модель уже знает похожие слова на другом языке. В нашем проекте это сработало очень хорошо.
Неправильное извлечение сущности
Чат-боты требуют, чтобы объекты определяли, какие данные ищет пользователь. К этим объектам относятся время, место, человек, предмет, дата и т. д. Однако боты могут не идентифицировать объект по естественному языку:
Тот же контекст, но разные сущности. Например, боты могут спутать место с объектом, когда пользователь вводит «Имя студентов из ИИТ Дели», а затем «Имя студентов из Бангалора».
Сценарии, в которых объекты неправильно прогнозируются с низкой достоверностью. Например, бот может идентифицировать ИИТ Дели как город с низкой степенью достоверности.
Частичное извлечение объекта с помощью модели машинного обучения. Если пользователь вводит «студенты из ИИТ Дели», модель может идентифицировать только «ИИТ» только как сущность вместо «ИИТ Дели».
Входные данные, состоящие из одного слова, не имеющие контекста, могут запутать модели машинного обучения. Например, такое слово, как «Ришикеш», может означать как имя человека, так и город.
Что делать?
Решением может быть добавление дополнительных обучающих примеров. Но есть предел, после которого добавление большего количества не поможет. Более того, это бесконечный процесс. Другим решением может быть определение шаблонов регулярных выражений с использованием заранее определенных слов, чтобы помочь извлекать объекты с известным набором возможных значений, таких как город, страна и т. д.
Модели имеют меньшую достоверность, если они не уверены в предсказании сущности. Разработчики могут использовать это как триггер для вызова пользовательского компонента, который может исправить объект с низкой степенью уверенности. Давайте рассмотрим приведенный выше пример. Если ИИТ Дели прогнозируется как город с низкой достоверностью, то пользователь всегда может найти его в базе данных. После неудачной попытки найти предсказанную сущность в Город таблица, модель перейдет к другим таблицам и, в конечном итоге, найдет ее в Институт table, что приводит к исправлению сущности.
Классификация неправильных намерений
С каждым пользовательским сообщением связано какое-то намерение. Поскольку намерения определяют следующий порядок действий бота, правильная классификация пользовательских запросов с намерением имеет решающее значение. Однако разработчики должны идентифицировать намерения с минимальной путаницей. В противном случае могут возникнуть случаи, когда возникает путаница. Например, "Покажите мне открытые позиции» против. "Покажите мне кандидатов на вакансию».
Что делать?
Есть два способа отличить запутанные запросы. Во-первых, разработчик может ввести поднамерение. Во-вторых, модели могут обрабатывать запросы на основе идентифицированных сущностей.
Специализированный чат-бот должен представлять собой закрытую систему, где он должен четко определять, на что он способен, а на что — нет. Разработчики должны выполнять разработку поэтапно, планируя создание чат-ботов для конкретной предметной области. На каждом этапе они могут определить неподдерживаемые функции чат-бота (через неподдерживаемое намерение).
Они также могут определить, с чем чат-бот не может справиться, находясь «вне области действия». Но могут быть случаи, когда бот путается с неподдерживаемыми и выходящими за рамки намерениями. Для таких сценариев должен быть предусмотрен резервный механизм, при котором, если достоверность намерения ниже порогового значения, модель может корректно работать с резервным намерением для обработки случаев путаницы.
Как только бот определит цель сообщения пользователя, он должен отправить ответ обратно. Бот решает ответ на основе определенного набора определенных правил и историй. Например, правило может быть таким же простым, как и полное "доброе утро" когда пользователь приветствует "Привет". Однако чаще всего разговоры с чат-ботами включают в себя последующее взаимодействие, и их ответы зависят от общего контекста разговора.
Что делать?
Чтобы справиться с этим, чат-боты снабжаются реальными примерами разговоров, называемыми «Истории». Однако пользователи не всегда взаимодействуют так, как предполагалось. Зрелый чат-бот должен корректно справляться со всеми такими отклонениями. Дизайнеры и разработчики могут гарантировать это, если при написании историй они не просто сосредотачиваются на счастливом пути, но и работают на несчастливых путях.
Взаимодействие пользователей с чат-ботами во многом зависит от ответов чат-ботов. Пользователи могут потерять интерес, если ответы будут слишком роботизированными или слишком знакомыми. Например, пользователю может не понравиться ответ типа «Вы ввели неправильный запрос» на неправильный ввод, даже если ответ правильный. Ответ здесь не соответствует личности помощника.
Что делать?
Чат-бот служит помощником и должен обладать определенным характером и тоном голоса. Они должны быть гостеприимными и скромными, и разработчики должны соответствующим образом оформлять разговоры и высказывания. Ответы не должны звучать роботизированно или механически. Например, бот может сказать: «Извините, похоже, у меня нет никаких подробностей. Не могли бы вы еще раз ввести свой запрос?» для устранения неправильного ввода.
Чат-боты на основе LLM (Large Language Model), такие как ChatGPT и Bard, меняют правила игры и улучшают возможности диалогового искусственного интеллекта. Они не только хороши в ведении открытых разговоров, похожих на человеческие, но и могут выполнять различные задачи, такие как резюмирование текста, написание абзацев и т. д., которые раньше можно было выполнить только с помощью определенных моделей.
Одной из проблем традиционных систем чат-ботов является классификация каждого предложения по намерениям и соответствующее решение ответа. Такой подход непрактичен. Ответы типа «Извините, я не смог вас достать» часто раздражают. Бессмысленные системы чат-ботов — это путь вперед, и LLM могут сделать это реальностью.
LLM могут легко достичь самых современных результатов в распознавании общих именованных объектов, за исключением распознавания определенных объектов, специфичных для предметной области. Смешанный подход к использованию LLM с любой структурой чат-ботов может вдохновить на создание более зрелой и надежной системы чат-ботов.
Благодаря последним достижениям и постоянным исследованиям в области диалогового искусственного интеллекта чат-боты становятся лучше с каждым днем. Много внимания уделяется таким областям, как решение сложных задач с несколькими целями, например «Забронировать рейс в Мумбаи и заказать такси до Дадара».
Вскоре персонализированные беседы будут проводиться на основе характеристик пользователя, чтобы поддерживать его заинтересованность. Например, если бот обнаруживает, что пользователь недоволен, он перенаправляет разговор к реальному агенту. Кроме того, благодаря постоянно растущему объему данных чат-ботов методы глубокого обучения, такие как ChatGPT, могут автоматически генерировать ответы на запросы с использованием базы знаний.
Суман Саурав работает специалистом по данным в Talentica Software, компании по разработке программных продуктов. Он является выпускником NIT Agartala и имеет более чем 8-летний опыт разработки и внедрения революционных решений искусственного интеллекта с использованием НЛП, разговорного искусственного интеллекта и генеративного искусственного интеллекта.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :имеет
- :является
- :нет
- :куда
- 8
- a
- способность
- О нас
- выше
- соответственно
- Достигать
- достигнутый
- через
- действия
- добавить
- Дополнительно
- адрес
- адресация
- достижения
- После
- Агент
- агенты
- AI
- AI chatbot
- Alexa
- Все
- уже
- причислены
- выпускник
- всегда
- количество
- an
- и
- Другой
- ответ
- любой
- подхода
- МЫ
- области
- AS
- спрашивающий
- помощник
- помощники
- связанный
- At
- внимание
- автоматически
- доступен
- избежать
- назад
- Использование темпера с изогнутым основанием
- основанный
- BE
- становление
- существ
- ниже
- ЛУЧШЕЕ
- Лучшая
- Бот
- изоферменты печени
- боты
- строить
- но
- by
- призывают
- под названием
- CAN
- не могу
- возможности
- способный
- случаев
- категоризации
- определенный
- проблемы
- изменения
- характеристика
- Chatbot
- chatbots
- ChatGPT
- Город
- классификация
- классифицированный
- явно
- закрыто
- Компания
- жалобы
- комплекс
- компонент
- компоненты
- постигать
- доверие
- спутанный
- заблуждение
- замешательство
- Рассматривать
- контекст
- (CIJ)
- Разговор
- диалоговый
- разговорный ИИ
- Беседы
- исправить
- правильно
- соответствующий
- может
- страна
- курс
- Создайте
- Создающий
- решающее значение
- Текущий
- изготовленный на заказ
- данным
- ученый данных
- База данных
- Время
- день
- приличный
- Решение
- глубоко
- глубокое обучение
- определять
- определенный
- Дели
- зависеть
- выводить
- Проект
- дизайнеры
- проектирование
- подробнее
- Застройщик
- застройщиков
- Развитие
- диалог
- Диалог
- различный
- дифференцировать
- do
- не
- домен
- Dont
- каждый
- Ранее
- легко
- усилие
- вложения
- Бесконечный
- заниматься
- занятый
- обязательство
- Английский
- повышать
- Enter
- лиц
- организация
- и т.д
- Даже
- со временем
- постоянно растет
- Каждая
- каждый день
- пример
- Примеры
- опыт
- Объяснять
- извлечение
- добыча
- FAIL
- отсутствии
- знакомый
- БЫСТРО
- Особенности
- ФРС
- Найдите
- находит
- полет
- Фокус
- Что касается
- вперед
- Рамки
- каркасы
- Французский
- от
- Общие
- порождать
- порождающий
- поколение
- генеративный
- Генеративный ИИ
- генератор
- получить
- получающий
- данный
- хорошо
- гарантия
- обрабатывать
- Управляемость
- происходить
- счастливый
- Есть
- имеющий
- he
- сильно
- помощь
- полезный
- здесь
- Как
- How To
- Однако
- HTTPS
- человек
- скромный
- i
- идентифицированный
- идентифицирует
- определения
- if
- Осуществляющий
- улучшенный
- in
- включают
- инновации
- вход
- затраты
- внушать
- пример
- вместо
- предназначенных
- намерение
- взаимодействовать
- взаимодействие
- взаимодействие
- интерес
- в
- вводить
- IT
- JPG
- всего
- КДнаггетс
- Сохранить
- Основные
- Вид
- знания
- известный
- знает
- язык
- Языки
- большой
- последний
- изучение
- ЖИЗНЬЮ
- такое как
- ОГРАНИЧЕНИЯ
- Ограниченный
- терять
- Низкий
- ниже
- машина
- обучение с помощью машины
- основной
- сделать
- Создание
- Совпадение
- зрелый
- Май..
- me
- значить
- механический
- механизм
- сообщение
- может быть
- минимальный
- смешивать
- смешанный
- модель
- Модели
- БОЛЕЕ
- Более того
- самых
- много
- с разными
- Мумбай
- должен
- my
- имя
- Названный
- натуральный
- Естественный язык
- следующий
- гульденов
- НЛП
- НЛУ
- нет
- номер
- of
- .
- on
- консолидировать
- только
- открытый
- с открытым исходным кодом
- or
- Другое
- в противном случае
- наши
- за
- общий
- Владельцы
- часть
- путь
- пути
- паттеранами
- Люди
- выполнять
- выполнены
- выполняет
- период
- человек
- Персонализированные
- фаза
- фаз
- Часть
- план
- планирование
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пожалуйста
- Точка
- должность
- обладать
- возможное
- практическое
- предсказанный
- прогноз
- предпочитать
- представлены
- предыдущий
- Проблема
- продолжить
- процесс
- Продукт
- разработка продукта
- Проект
- Запросы
- Вопросы
- R
- раса
- готовый
- реальные
- Реальность
- на самом деле
- признание
- набор
- уменьшить
- ссылка
- понимается
- область
- полагаться
- напоминание
- замещать
- требовать
- требуется
- исследованиям
- решение
- ответ
- ответы
- ответственный
- в результате
- Итоги
- революционный
- надежный
- Правило
- условиями,
- то же
- сообщили
- Сценарии
- Ученый
- поцарапать
- Поиск
- поиск
- кажется
- выбор
- Отправить
- предложение
- служит
- набор
- Поделиться
- должен
- аналогичный
- просто
- с
- одинарной
- краб
- Software
- Решение
- Решения
- некоторые
- Звук
- конкретный
- говорят
- Этап
- Начало
- современное состояние
- Истории
- упорядочить
- Студенты
- существенный
- такие
- подходящее
- поддержка
- Системы поддержки
- Убедитесь
- синтетически
- система
- системы
- T
- ТАБЛИЦЫ
- взять
- принимает
- Сложность задачи
- задачи
- снижения вреда
- текст
- чем
- который
- Ассоциация
- их
- Их
- тогда
- Там.
- Эти
- они
- этой
- хоть?
- три
- порог
- время
- в
- TONE
- Тон голоса
- слишком
- традиционный
- Train
- специалистов
- Обучение
- вызвать
- два
- напишите
- Типы
- понимание
- модернизация
- использование
- используемый
- Информация о пользователе
- пользователей
- через
- обычно
- Наши ценности
- с помощью
- Виртуальный
- Режимы
- vs
- W
- Путь..
- способы
- приветствуя
- ЧТО Ж
- Что
- когда
- когда бы ни
- который
- в то время как
- будете
- Word
- слова
- Работа
- работавший
- бы
- письмо
- письменный
- Неправильно
- лет
- являетесь
- ВАШЕ
- зефирнет