Этот пост написан в соавторстве с Прешеном Губиа и Йоханом Оливье из Capitec.
Apache Spark — это широко используемая система распределенной обработки с открытым исходным кодом, известная своей способностью обрабатывать крупномасштабные рабочие нагрузки с данными. Он находит частое применение среди разработчиков Spark, работающих с Амазонка ЭМИ, Создатель мудреца Амазонки, Клей AWS и пользовательские приложения Spark.
Амазонка Redshift предлагает бесшовную интеграцию с Apache Spark, что позволяет легко получить доступ к данным Redshift как в подготовленных кластерах Amazon Redshift, так и в подготовленных кластерах Amazon Redshift. Amazon Redshift без сервера. Эта интеграция расширяет возможности решений AWS для аналитики и машинного обучения (ML), делая хранилище данных доступным для более широкого круга приложений.
Для Интеграция Amazon Redshift для Apache Spark, вы можете быстро приступить к работе и без особых усилий разрабатывать приложения Spark, используя популярные языки, такие как Java, Scala, Python, SQL и R. Ваши приложения могут беспрепятственно считывать данные из хранилища данных Amazon Redshift и записывать их в него, сохраняя при этом оптимальную производительность и согласованность транзакций. Кроме того, вы получите выгоду от повышения производительности за счет оптимизации передачи данных, что еще больше повысит эффективность ваших операций.
Capitec, крупнейший розничный банк Южной Африки с более чем 21 миллионом розничных банковских клиентов, стремится предоставлять простые, доступные и доступные финансовые услуги, чтобы помочь южноафриканцам лучше осуществлять банковские операции и жить лучше. В этой статье мы обсуждаем успешную интеграцию коннектора Amazon Redshift с открытым исходным кодом командой Capitec по платформе общих сервисов. В результате использования интеграции Amazon Redshift с Apache Spark производительность разработчиков выросла в 10 раз, конвейеры создания функций были оптимизированы, а дублирование данных сведено к нулю.
Возможность для бизнеса
В подразделениях розничного кредитования Capitec планируется использовать 19 прогнозных моделей с использованием 93 функций, созданных с помощью AWS Glue. Записи функций дополняются фактами и измерениями, хранящимися в Amazon Redshift. Apache PySpark был выбран для создания функций, поскольку он предлагает быстрый, децентрализованный и масштабируемый механизм обработки данных из различных источников.
Эти производственные функции играют решающую роль в обеспечении возможности подачи заявок на срочные кредиты в режиме реального времени, заявок на кредитные карты, пакетного ежемесячного мониторинга кредитного поведения и пакетной идентификации ежедневной зарплаты в рамках бизнеса.
Проблема с источником данных
Чтобы обеспечить надежность конвейеров данных PySpark, важно иметь согласованные данные на уровне записей как из таблиц измерений, так и из таблиц фактов, хранящихся в хранилище корпоративных данных (EDW). Эти таблицы затем объединяются с таблицами из Enterprise Data Lake (EDL) во время выполнения.
Во время разработки функций инженерам данных требуется бесшовный интерфейс с EDW. Этот интерфейс позволяет им получать доступ к необходимым данным из EDW и интегрировать их в конвейеры данных, обеспечивая эффективную разработку и тестирование функций.
Предыдущий процесс решения
В предыдущем решении инженеры по обработке данных продуктовой группы тратили 30 минут на каждый запуск, чтобы вручную предоставить данные Redshift в Spark. Эти шаги включали следующее:
- Создайте предикатный запрос на Python.
- Отправить РАЗГРУЗИТЬ запрос через API данных Amazon Redshift.
- Данные каталога в каталоге данных AWS Glue через AWS SDK для Pandas с использованием выборки.
Такой подход создавал проблемы для больших наборов данных, требовал периодического обслуживания со стороны команды платформы и был сложен в автоматизации.
Обзор текущего решения
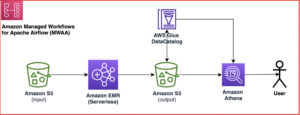
Компания Capitec смогла решить эти проблемы благодаря интеграции Amazon Redshift с Apache Spark в конвейерах создания функций. Архитектура определена на следующей диаграмме.

Рабочий процесс включает в себя следующие шаги:
- Внутренние библиотеки устанавливаются в задание AWS Glue PySpark через Артефакт кода AWS.
- Задание AWS Glue извлекает учетные данные кластера Redshift из Менеджер секретов AWS и настраивает соединение с Amazon Redshift (вводит учетные данные кластера, места выгрузки, форматы файлов) через общую внутреннюю библиотеку. Интеграция Amazon Redshift с Apache Spark также поддерживает использование Управление идентификацией и доступом AWS (IAM) для получить учетные данные и подключиться к Amazon Redshift.
- Запрос Spark преобразуется в оптимизированный запрос Amazon Redshift и отправляется в EDW. Это достигается за счет интеграции Amazon Redshift с Apache Spark.
- Набор данных EDW выгружается во временный префикс в Простой сервис хранения Amazon (Amazon S3) ведро.
- Набор данных EDW из корзины S3 загружается в исполнители Spark посредством интеграции Amazon Redshift с Apache Spark.
- Набор данных EDL загружается в исполнители Spark через каталог данных AWS Glue.
Эти компоненты работают вместе, чтобы гарантировать, что инженеры данных и производственные конвейеры данных имеют необходимые инструменты для реализации интеграции Amazon Redshift с Apache Spark, выполнения запросов и облегчения выгрузки данных из Amazon Redshift в EDL.
Использование интеграции Amazon Redshift с Apache Spark в AWS Glue 4.0
В этом разделе мы демонстрируем полезность интеграции Amazon Redshift с Apache Spark, дополняя таблицу заявок на получение кредита, находящуюся в озере данных S3, информацией о клиентах из хранилища данных Redshift в PySpark.
Ассоциация dimclient Таблица в Amazon Redshift содержит следующие столбцы:
- КлиентКлюч – ИНТ8
- КлиентАльтКей — ВАРЧАР50
- Идентификатор партииНомер — ВАРЧАР20
- Клиенткреатедате - ДАТА
- Отменено – ИНТ2
- СтрокаIsCurrent – ИНТ2
Ассоциация loanapplication Таблица в каталоге данных AWS Glue содержит следующие столбцы:
- ID записи – БИГИНТ
- ЛогДата – ВРЕМЕННАЯ МЕТКА
- Идентификатор партииНомер - НИТЬ
Таблица Redshift считывается посредством интеграции Amazon Redshift с Apache Spark и кэшируется. См. следующий код:
Записи заявок на получение кредита считываются из озера данных S3 и обогащаются dimclient таблица с информацией об Amazon Redshift:
В результате запись заявки на кредит (из озера данных S3) пополняется ClientCreateDate столбец (из Amazon Redshift).

Как интеграция Amazon Redshift с Apache Spark решает проблему источников данных
Интеграция Amazon Redshift с Apache Spark эффективно решает проблему источников данных с помощью следующих механизмов:
- Чтение «точно в срок» – Интеграция Amazon Redshift с коннектором Apache Spark считывает таблицы Redshift «точно в срок», обеспечивая согласованность данных и схемы. Это особенно ценно для Тип 2 медленно меняющийся размер (SCD) и временной интервал накопления моментальных снимков. Объединив эти таблицы Redshift с таблицами каталога данных AWS Glue исходной системы из EDL в рабочих конвейерах PySpark, соединитель обеспечивает плавную интеграцию данных из нескольких источников, сохраняя при этом целостность данных.
- Оптимизированные запросы Redshift – Интеграция Amazon Redshift с Apache Spark играет решающую роль в преобразовании плана запроса Spark в оптимизированный запрос Redshift. Этот процесс преобразования упрощает процесс разработки для команды разработчиков за счет соблюдения принципа локальности данных. Оптимизированные запросы используют возможности и оптимизацию производительности Amazon Redshift, обеспечивая эффективный поиск и обработку данных из Amazon Redshift для конвейеров PySpark. Это помогает оптимизировать процесс разработки и одновременно повысить общую производительность операций по поиску данных.
Достижение наилучшей производительности
Интеграция Amazon Redshift с Apache Spark автоматически применяет понижение уровня предикатов и запросов для оптимизации производительности. Вы можете повысить производительность, используя формат Parquet по умолчанию, используемый для выгрузки с помощью этой интеграции.
Дополнительные сведения и примеры кода см. Новинка — интеграция Amazon Redshift с Apache Spark.
Преимущества решения
Внедрение интеграции принесло команде несколько существенных преимуществ:
- Повышенная продуктивность разработчиков – Интерфейс PySpark, предоставляемый в результате интеграции, повысил производительность разработчиков в 10 раз, обеспечивая более плавное взаимодействие с Amazon Redshift.
- Устранение дублирования данных – В озере данных были исключены повторяющиеся таблицы Redshift и таблицы Redshift, каталогизированные AWS Glue, что привело к созданию более оптимизированной среды данных.
- Снижение нагрузки EDW – Интеграция облегчила выборочную выгрузку данных, минимизировав нагрузку на ЕДА за счет извлечения только необходимых данных.
Используя интеграцию Amazon Redshift с Apache Spark, компания Capitec проложила путь к улучшенной обработке данных, повышению производительности и более эффективной экосистеме разработки функций.
Заключение
В этом посте мы обсудили, как команда Capitec успешно реализовала интеграцию Apache Spark с Amazon Redshift для Apache Spark, чтобы упростить рабочие процессы вычисления функций. Они подчеркнули важность использования децентрализованных и модульных конвейеров данных PySpark для создания функций прогнозной модели.
В настоящее время интеграция Amazon Redshift с Apache Spark используется в 7 конвейерах производственных данных и 20 конвейерах разработки, что демонстрирует ее эффективность в среде Capitec.
В дальнейшем команда платформы общих сервисов Capitec планирует расширить внедрение интеграции Amazon Redshift с Apache Spark в различных сферах бизнеса, стремясь к дальнейшему расширению возможностей обработки данных и продвижению эффективных методов разработки функций.
Дополнительную информацию об использовании интеграции Amazon Redshift с Apache Spark см. на следующих ресурсах:
Об авторах
 Прешен Губиа — ведущий инженер по машинному обучению функциональной платформы в Capitec. Он занимается проектированием и созданием компонентов Feature Store для корпоративного использования. В свободное время любит читать и путешествовать.
Прешен Губиа — ведущий инженер по машинному обучению функциональной платформы в Capitec. Он занимается проектированием и созданием компонентов Feature Store для корпоративного использования. В свободное время любит читать и путешествовать.
 Йохан Оливье — старший инженер по машинному обучению в модельной платформе Capitec. Он предприниматель и энтузиаст решения проблем. В свободное время он любит музыку и общение.
Йохан Оливье — старший инженер по машинному обучению в модельной платформе Capitec. Он предприниматель и энтузиаст решения проблем. В свободное время он любит музыку и общение.
 Судипта Багчи — старший специалист по архитектуре решений в Amazon Web Services. Он имеет более чем 12-летний опыт работы в области данных и аналитики и помогает клиентам проектировать и создавать масштабируемые и высокопроизводительные аналитические решения. Вне работы он любит бегать, путешествовать и играть в крикет. Свяжитесь с ним на LinkedIn.
Судипта Багчи — старший специалист по архитектуре решений в Amazon Web Services. Он имеет более чем 12-летний опыт работы в области данных и аналитики и помогает клиентам проектировать и создавать масштабируемые и высокопроизводительные аналитические решения. Вне работы он любит бегать, путешествовать и играть в крикет. Свяжитесь с ним на LinkedIn.
 Сайед Хумайр — старший специалист по архитектуре аналитических решений в Amazon Web Services (AWS). Он имеет более чем 17-летний опыт работы в области корпоративной архитектуры с упором на данные и искусственный интеллект/ML, помогая клиентам AWS по всему миру удовлетворять их бизнес- и технические требования. Вы можете связаться с ним по LinkedIn.
Сайед Хумайр — старший специалист по архитектуре аналитических решений в Amazon Web Services (AWS). Он имеет более чем 17-летний опыт работы в области корпоративной архитектуры с упором на данные и искусственный интеллект/ML, помогая клиентам AWS по всему миру удовлетворять их бизнес- и технические требования. Вы можете связаться с ним по LinkedIn.
 Вуиса Масвана — старший архитектор решений в AWS в Кейптауне. Vuyisa уделяет особое внимание оказанию помощи клиентам в создании технических решений для решения бизнес-задач. Он поддерживает Capitec на пути AWS с 2019 года.
Вуиса Масвана — старший архитектор решений в AWS в Кейптауне. Vuyisa уделяет особое внимание оказанию помощи клиентам в создании технических решений для решения бизнес-задач. Он поддерживает Capitec на пути AWS с 2019 года.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/
- :имеет
- :является
- $UP
- 06
- 1
- 10
- 100
- 12
- 16
- 17
- 19
- 20
- 2019
- 30
- 7
- a
- в состоянии
- доступ
- доступной
- выполнено
- через
- дополнительный
- Дополнительная информация
- Дополнительно
- адрес
- адреса
- придерживаясь
- Принятие
- доступной
- AI / ML
- Стремясь
- Цель
- Позволяющий
- позволяет
- причислены
- Amazon
- Amazon Web Services
- Веб-службы Amazon (AWS)
- среди
- an
- аналитика
- и
- апаш
- Apache Spark
- Применение
- Приложения
- применяется
- подхода
- архитектура
- МЫ
- области
- AS
- At
- автоматизировать
- автоматически
- AWS
- Клей AWS
- Банка
- Банковское дело
- основанный
- , так как:
- поведение
- польза
- Преимущества
- ЛУЧШЕЕ
- Лучшая
- между
- Крупнейшая
- Повышенный
- изоферменты печени
- шире
- строить
- Строительство
- построенный
- бизнес
- by
- CAN
- возможности
- мыс
- карта
- каталог
- изменения
- клиент
- клиентов
- Кластер
- CO
- код
- Column
- Колонки
- комбинируя
- комплекс
- компоненты
- вычисление
- Свяжитесь
- связи
- последовательный
- содержит
- контекст
- Конверсия
- преобразование
- Создайте
- Создающий
- Полномочия
- кредит
- кредитная карта
- крикет
- решающее значение
- изготовленный на заказ
- Клиенты
- ежедневно
- данным
- Озеро данных
- обработка данных
- информационное хранилище
- Наборы данных
- децентрализованная
- По умолчанию
- определенный
- демонстрировать
- Проект
- проектирование
- подробнее
- развивать
- Застройщик
- застройщиков
- Развитие
- различный
- Размеры
- размеры
- обсуждать
- обсуждается
- распределенный
- Разное
- легко
- экосистема
- фактически
- эффективность
- затрат
- эффективный
- легко
- устранен
- подчеркнул
- позволяет
- позволяет
- инженер
- Проект и
- Инженеры
- повышать
- повышение
- обогащенный
- обогащение
- обеспечивать
- обеспечение
- Предприятие
- энтузиаст
- Предприниматель
- Окружающая среда
- существенный
- Эфир (ETH)
- существующий
- Расширьте
- раскрываться
- опыт
- содействовал
- облегчается
- факт
- фактор
- Факты
- БЫСТРО
- Особенность
- Особенности
- Файл
- финансовый
- финансовые услуги
- находит
- Фокус
- внимание
- фокусировка
- после
- Что касается
- формат
- вперед
- частое
- от
- Функции
- далее
- Gain
- поколение
- получить
- GitHub
- ГЛОБАЛЬНО
- Управляемость
- Есть
- he
- помощь
- помощь
- помогает
- его
- его
- Как
- HTML
- HTTP
- HTTPS
- IAM
- Идентификация
- Личность
- осуществлять
- в XNUMX году
- Импортировать
- значение
- улучшенный
- улучшение
- in
- включены
- включает в себя
- расширились
- информация
- интегрировать
- интеграции.
- целостность
- взаимодействие
- Интерфейс
- в нашей внутренней среде,
- в
- вопросы
- IT
- ЕГО
- Java
- работа
- присоединиться
- присоединился
- путешествие
- озеро
- Языки
- большой
- крупномасштабный
- вести
- изучение
- оставил
- библиотеки
- Библиотека
- такое как
- жить
- загрузка
- варианты
- места
- любит
- машина
- обучение с помощью машины
- сохранение
- техническое обслуживание
- Создание
- способ
- вручную
- механизм
- механизмы
- миллиона
- минимизация
- минут
- ML
- модель
- Модели
- модульный
- Мониторинг
- ежемесячно
- БОЛЕЕ
- более эффективным
- с разными
- Музыка
- необходимо
- of
- Предложения
- оливковый
- on
- только
- открытый
- с открытым исходным кодом
- Операционный отдел
- оптимальный
- Оптимизировать
- оптимизированный
- заказ
- внешнюю
- за
- общий
- панд
- особенно
- Пароль
- для
- производительность
- план
- Планы
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- игры
- играет
- Популярное
- поставленный
- возможности,
- После
- практиками
- интеллектуального
- предыдущий
- принцип
- Проблема
- решение проблем
- проблемам
- процесс
- обработка
- Продукт
- Производство
- производительность
- продвижении
- обеспечивать
- при условии
- Питон
- Запросы
- быстро
- R
- ассортимент
- Читать
- Reading
- реального времени
- запись
- учет
- повторяющихся
- Цена снижена
- относиться
- надежность
- Знаменитый
- требовать
- обязательный
- Требования
- решение
- Полезные ресурсы
- результат
- в результате
- розничный
- Розничные банковские услуги
- Роли
- Run
- Бег
- заработная плата
- SC
- масштаб
- масштабируемые
- сфера
- SDK
- бесшовные
- легко
- секреты
- Раздел
- посмотреть
- выбранный
- выбор
- селективный
- старший
- Услуги
- Наборы
- несколько
- общие
- Showcasing
- значительный
- просто
- упростить
- упрощение
- с
- Медленно
- гладкой
- Снимок
- So
- общение
- Решение
- Решения
- РЕШАТЬ
- Решает
- Источник
- Источники
- Об
- Южная
- Искриться
- специалист
- потраченный
- SQL
- и политические лидеры
- Шаги
- диск
- хранить
- упорядочить
- обтекаемый
- строка
- сильный
- представленный
- успешный
- Успешно
- Поддержанный
- Поддержка
- система
- ТАБЛИЦЫ
- команда
- Технический
- временный
- Тестирование
- который
- Ассоциация
- Источник
- их
- Их
- тогда
- Эти
- они
- этой
- Через
- время
- в
- вместе
- инструменты
- город
- транзакционный
- Путешествие
- URL
- использование
- используемый
- через
- утилита
- использовать
- Использующий
- ценный
- с помощью
- Склады
- законопроект
- Путь..
- we
- Web
- веб-сервисы
- были
- в то время как
- в
- Работа
- работать вместе
- рабочий
- Рабочие процессы
- работает
- записывать
- лет
- дали
- являетесь
- ВАШЕ
- зефирнет
- нуль